1. Introduction
Since smart devices with good performance were penetrated, since high-speed wired and wireless network technologies were developed, and since small-sized display devices with good image quality were developed, people have easily acquired various types of media content, such as pictures, animation, music files, user created contents (UCC), and videos, at any time and any place through the Internet [
1,
2,
3,
4,
5]. Such acquired media content is usefully applied to various application fields, including big data analysis, image security, deep learning-based artificial intelligence, sustainable anticipatory computing, media content indexing and retrieval, and Internet of Things (IoT) [
6,
7,
8,
9,
10,
11,
12].
Unfortunately, media content that includes objects with exposed personal information, such as a human face, a resident registration number, a telephone number, a license plate, or an address, can easily be acquired and distributed through the Internet so that the problem is a big social issue [
13,
14]. In particular, since such media content is spread fast, people whose personal information is exposed severely suffer psychological damage.
Accordingly, one of the recent subjects of research is how to detect accurately the corresponding target object including exposed personal information from various types of still or video input content first; then to effectively block the detected target object through image processing-based blurring effects, grid-type mosaic processing, and virtual object insertion; and thereby to effectively hide the exposed critical personal information [
15].
As presented in the references, there are previous studies on how to detect a target object from a color image and to block the detected object. In one study [
16], color features were analyzed in the space of YC
bC
r and the regions presenting human skin color distribution were detected from an input color image. Subsequently, whether the detected regions included critical naked human body regions was judged with the use of the geometrical features of the detected skin color regions. In another study [
17], a fuzzy clustering technique was applied to extract a block-based mosaic region. This technique is used to extract an edge from an input color image, to obtain clustering features, and then to find a general image region and a mosaic region using a fuzzy clustering algorithm. In Reference [
18], a novel Bayesian framework was applied to detect a human facial region in a fast occluding environment. This algorithm utilized the omega shape formed by the human head and shoulders in order to deal with occlusion of the head effectively. In a test, this algorithm detected a facial region in a relatively accurately occluding environment. In Reference [
19], a new proposal generation acceleration framework was suggested in order to detect the human face in real time with the use of global and local features. In the method, the convolution neural network cascade was used as a baseline and the acceleration scheme for accelerating an inference time was developed. Aside from the techniques described above, object detection and blocking methods continue to be introduced [
20].
However, most of the existing object detection and blocking approaches are not yet very complete and include many internal and external constraints. Moreover, studies to detect and block a target object with personal information are relatively few in number compared to studies on other technical methods. Therefore, this paper proposes a new algorithm that makes it possible to detect a target object region with personal information on the basis of deep neural computing and to effectively block the detected object through grid-type mosaic processing.
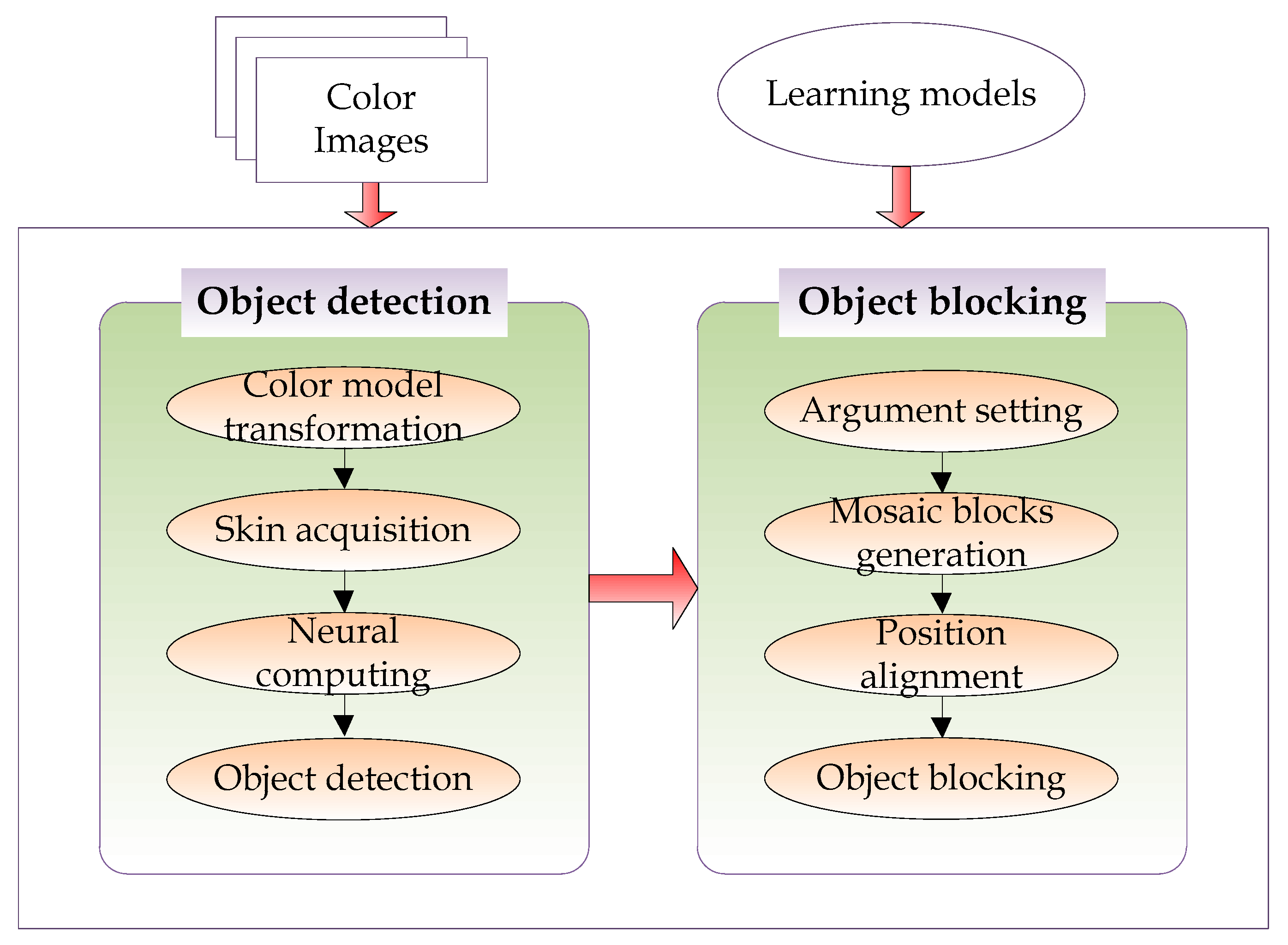
Figure 1 illustrates an overview of the proposed target object blocking technique.
As shown in
Figure 1, the algorithm proposed in this study first utilizes the artificial neural network-based deep learning algorithm to robustly detect a target object region with personal information like human facial regions and naked body parts from various types of input color images. Our algorithm then generates grid-like mosaic blocks and lets the generated mosaic blocks overlap the detected object region naturally so as to hide the target object region with personal information from being exposed to others.
In
Section 1, the overview and background of this study are explained. In
Section 2, previous studies on target object blocking in the fields of pattern recognition and image processing are described. In
Section 3, the technique of detecting an object with personal information from an input color image robustly on the basis of artificial neural computing is described. In
Section 4, the technique of generating a grid-like mosaic block and then letting the generated mosaic region overlap the detected target object region in order to cover the object effectively is explained. In
Section 5, we show the experimental results for comparative evaluation of the performance of the proposed object blocking algorithm. In
Section 6, the conclusion of this study and the future research plan are described.
2. Related Work
With the development of small- and high-quality display devices, the penetration of excellent mobile devices, the lowered prices of large storage devices, and the development of high-speed wired and wireless network technologies like 5th generation mobile telecommunication, it has been easy to obtain various kinds of media content like pictures or videos. In this circumstance, media content including target objects with exposed personal information, such as the human face or a resident registration number, is freely distributed through the Internet, which is a big social issue. For this reason, it has been requested to develop a novel technique of detecting and blocking an object region with exposed personal information from a variety of input color images effectively. Many different studies on target object detection and blocking, which are presented in references, are described as follows:
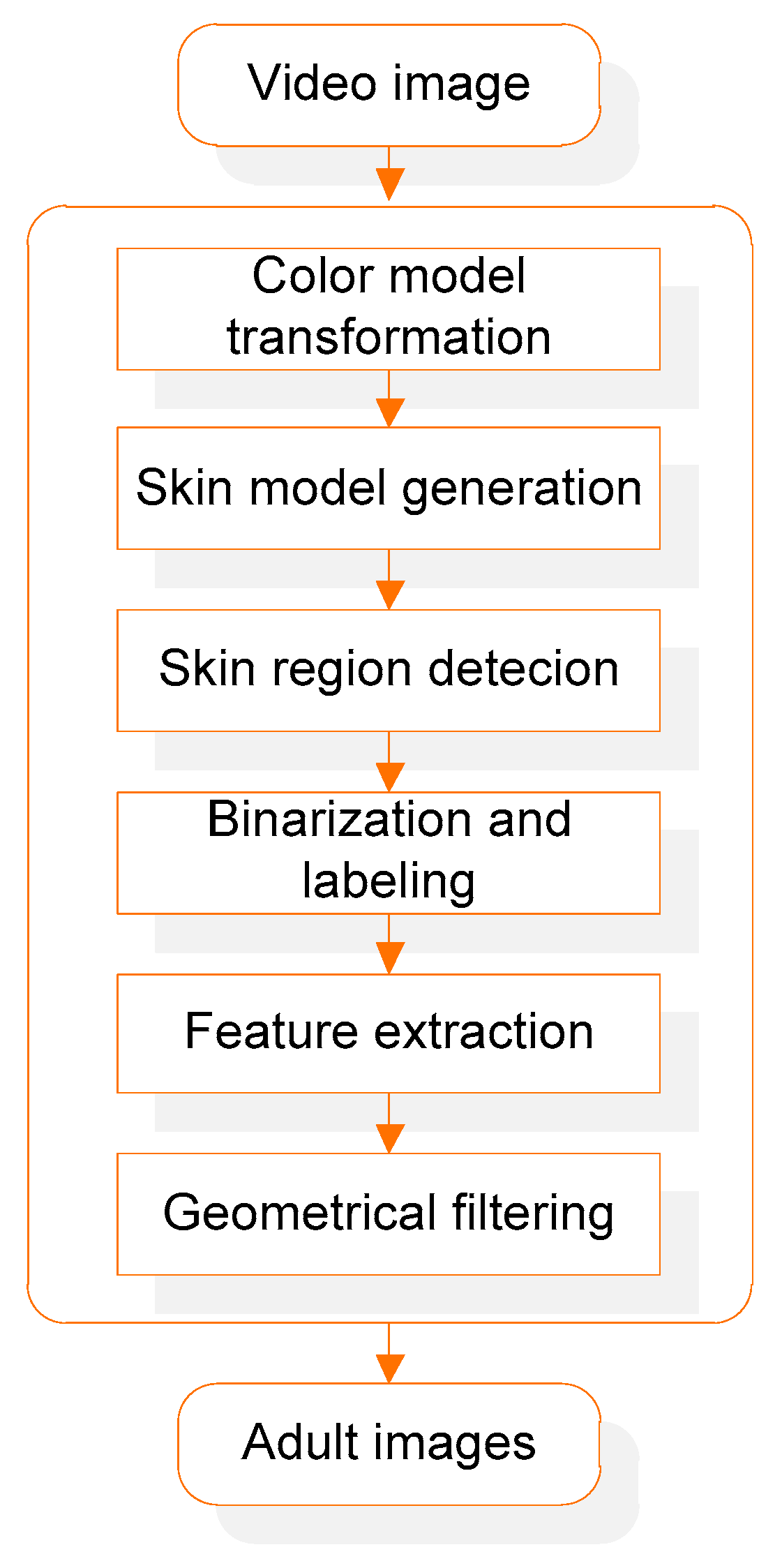
The color feature distribution modeling-based method [
16] introduces a new algorithm to identify an adult image in order to filter naked human body images in the Internet effectively. This algorithm first detects the eyes, which are known to be one of the most noticeable components of the human face, and selects a reliable skin color sample pixel in the facial region around the detected eyes in order to make a statistical skin color distribution model from each input color image directly. The skin color region of the whole image is robustly segmented with the use of the online skin color distribution model. The method then extracts a series of typical features such as size, aspect ratio, and compactness representing the naked body from the segmented skin regions and checks the regions including the naked body regions through multi-layer perceptron (MLP) neural network-based learning and inference of typical features. The proposed adult image detection method provides experimental results in order to prove that it is able to identify various types of nude images effectively more than other conventional methods. In the method, although the skin color extraction algorithm is not relatively complicated and is much used, it can be somewhat sensitive to changing surroundings like noise or lighting conditions.
Figure 2 shows the flowchart of the color distribution model-based method.
The clustering-based method [
17] utilized a fuzzy clustering algorithm to extract a block-based mosaic region from a color image accurately. In general, clustering is usually the process of grouping observations with similar attributes to classify the entire data into several groups. With the development of broadcasting and video network, a digital video broadcast monitoring system has been of more importance. To detect a low-quality video data in a television monitoring system, a digital image recognition technology is widely applied. Usually, a mosaic signal is easily generated in TV signals and lowers the video quality. A conventional block-based mosaic detection algorithm is unable to differentiate a Chinese character from a mosaic block. To solve the problem, the method detects a mosaic block through the fuzzy C-means clustering algorithm. It has three major steps. In the first step, a frame is processed by the Sobel edge detection algorithm in order to obtain an edge image. In the second step, a fuzzy C-means clustering algorithm extracts clustering features. In the last step, a mosaic block is effectively differentiated from all general image blocks through fuzzy C-means clustering. Experimental results revealed that the proposed algorithm detected mosaic blocks relatively robustly.
In the Bayesian framework-based method [
18], a human facial region was quickly detected in an occluding environment. Crimes related to automatic teller machines (ATM) draw more attention, and criminals intentionally hide their faces to avoid their identity. The method utilizes a fast and robust facial occlusion detection algorithm for robust ATM monitoring and was proved to be effective and efficient in processing an occluded face. The algorithm applied the omega shape formed by the human head and shoulders in order to deal with the head’s occlusion effectively. More specifically, a new energy function for detecting the elliptical head outline is first designed. Secondly, the fast and robust head tracking algorithm using gradient and shape signals in a Bayesian framework is newly developed. Lastly, in order to check if the detected head is occluded, the AdaBoost algorithm is applied to integrate information on the skin color distribution and human facial structure. Experimental results with actual data showed that the proposed algorithm had relatively high accuracy of facial detection and of facial occlusion detection. However, there is some false detection in the situation of suddenly changing lighting.
Figure 3 shows the block diagram of the Bayesian framework-based method.
In the global and local features-based method [
19], a proposal generation acceleration framework was newly suggested for real-time human facial region detection. Human facial recognition has widely been researched over the last several tens of years. The artificial deep neural network solution has greatly improved it. However, it is hard to directly apply the deep neural network technology to mobile devices due to limited calculation and memory. This method uses the convolution neural network cascade as a baseline, and the acceleration system for accelerating an inference time is developed. In the acceleration scheme, the calculation bottleneck of the baseline occurs in the proposal generation step, which was derived from the observation that each level of high-density image pyramid needs to pass the network. To solve the problem, the proposed method utilizes local facial features, for example, all of the global face and facial regions, to reduce the number of levels of the image pyramid. In the test with opened facial data sets, the proposed scheme was found to detect the face quickly. Nevertheless, there are several constraints to resolve. Introducing facial parts for classification requires extra data collection. The training of the proposal network also becomes harder since the amount of data in each category is likely to be unbalanced.
Aside from the methods described earlier, many new methods related to how to detect a target object with personal information continue to be introduced [
20]. Most of the conventional methods utilize human skin color distribution modeling in order to detect the human face robustly. Although such existing methods using human skin color distribution as the main feature are simple, they have a certain limitation in detecting a facial region from the input color images taken in diverse situations by using skin color regions only. In addition, conventional methods have yet to be perfect and include many internal and external constraints. Furthermore, there are relatively fewer studies on how to detect and block a target object with personal information than studies on other research methods.
4. Blocking through Mosaic Processing
In general, digital content makers sometimes generate a grid-type mosaic region and insert it into a variety of image data on purpose [
54]. In other words, makers of adult image content, like human nudity pictures, effectively hide the critical body regions of an adult image through mosaic processing in order to pass a motion picture rating board’s deliberation. In addition, mosaic processing is intentionally applied to the faces of persons whose portrait rights are protected in Internet blogs, smoking scenes, tattoo, sharp and deadly weapons like knives, particular companies’ trademarks irrelevant to indirect advertising, cruel scenes, actual names, resident registration numbers, home addresses, car license plates, and other personal information in still or dynamic color images.
In this study, we generate a grid-type mosaic first and then naturally overlap the generated mosaic [
55] on the target object region detected in the previous step, as shown in
Figure 8, so that the target object region with exposed personal information is effectively blocked. In other words, since a grid-type mosaic is generated on the exposed personal information area, damage caused by the exposure of personal information can be prevented.
In general, a mosaic block has a rectangular shape in which all pixels have the same color. In this study, a mosaic is generated in the unit of blocks [
54,
56] rather than the unit of pixels. In this case, it is important to let the mosaic overlap a detected target object region properly in terms of position and size. In addition, making the mosaic-overlapped target object region and its neighboring region natural by image processing is one of significant factors.
In this study, the filter with the size of N × N pixels is applied to replace the detected target object region with an average pixel value so as to generate a mosaic. Recently, the techniques of removing a mosaic from a digital color image are often found. For example, the technique of removing a mosaic from a digital image with the use of Google Brain, one of Google’s artificial intelligence research projects, was announced [
15]. More specifically, the 32 × 32 pixel-sized input color image was divided in the unit of 8 × 8-pixel size in order to generate a mosaic, and the divided images were recovered to its original image again. As such, a general mosaic technique can predict the shape of a mosaic region by putting the average value of pixels in the 8 × 8 pixel-sized region. When the recovered image is compared with ground truth, it is found that the recovered image is greatly similar to the original input image. Therefore, this study tries to apply a mosaic processing technique that does not allow recovery in order to robustly block a target region with exposed personal information.
In order to let a mosaic overlap a target object region with personal information as shown in
Figure 8, the MER (Minimum Enclosing Rectangle) [
57,
58,
59,
60] of the detected target object region is first calculated. Subsequently, the image region in the MER is equally divided in the block unit of N × N pixels, and each block is filled with the color values generated by the corresponding mosaic processing technique.
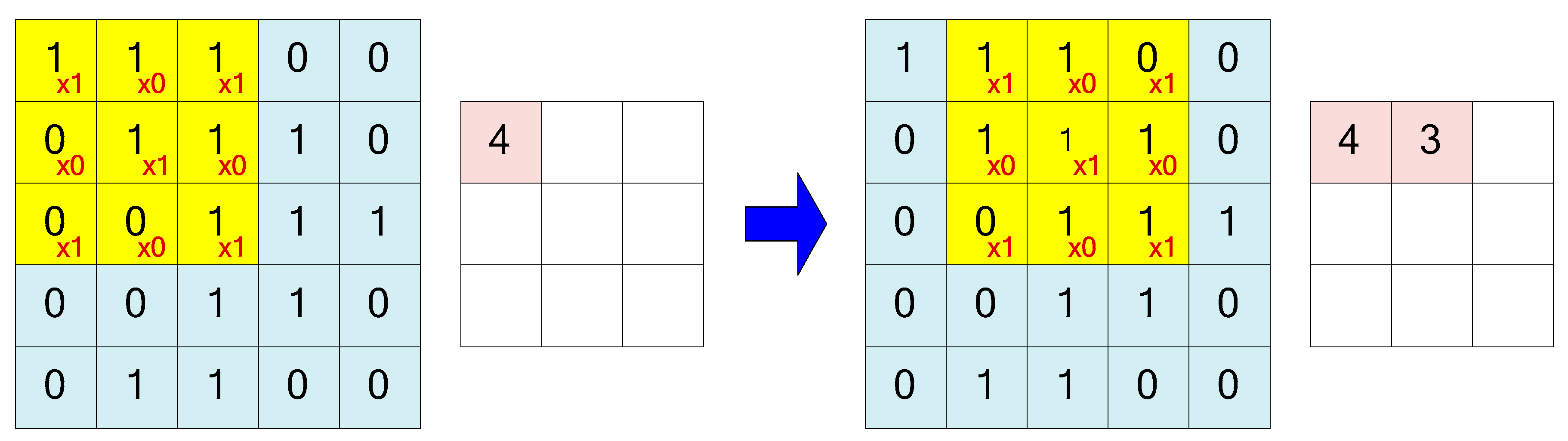
In this study, a block-based mosaic region can be generated in three major methods. The first method is the most general one. In the method, the mean of the pixels located in the detected target object region is calculated with Equation (7) and it is then entered in the blocks of the mosaic, as shown in
Figure 9.
In Equation (7),
n means the length or width size of a mosaic block.
r(
x,
y),
g(
x,
y), and
b(
x,
y) represent
r,
g, and
b color values of the pixels located at the (
x,
y) position of the input image. In addition,
rmean,
gmean, and
bmean are the average red, the average green, and the average blue color values of the pixels in a block.
Secondly, as shown in Equation (8), pixels in the region with personal information are randomly selected so as to generate mosaic blocks. In Equation (8),
Cmosaic(
x,
y) represents the color value in the (
x,
y) position of the generated mosaic region.
Cimage(
x,
y) means the color value in the (
x,
y) position of the input color image.
random() is the random data function for selecting a value randomly in a corresponding group.
Rtarget is the extracted target object region. If this mosaic generation method is utilized, it is difficult to predict the form of the original target object. In addition, this method can bring about a more natural result than the third mosaic generation method.
Thirdly, as shown in Equation (9),
r,
g, and
b pixel values are randomly applied in each divided mosaic region. In Equation (9), (
ri,
gi,
bi) represents the
r,
g, and
b color values randomly selected from the total set of
R,
G, and
B colors by the function r
andom(). If this mosaic generation method is applied, the original image colors prior to the generation of a mosaic have relatively low correlations with the generated mosaic colors and, therefore, it is hard to recover the original target object region. When the mosaic-applied target object region is compared with its neighboring regions, colors rapidly change in the mosaic region and a somewhat unnatural visual result is shown.
Therefore, if the different mosaic generation methods aforementioned are adaptively used depending on the internal and external features of an input color image to which the block-unit-based mosaic is applied, it is possible to block a target region with exposed personal information more effectively. For instance, if an input color image has many noises or is low quality due to lighting influence of the surrounding environment, the mean-based mosaic generation method can be applied to block a target object area. If there are relatively low correlations between the feature values of a detected target object and its neighboring regions, it is possible to generate a mosaic block by selecting the color values in the target object region randomly. If a target object area and its neighboring regions have relatively high correlations in terms of feature values, it is necessary to select one of all color values randomly and to generate a mosaic in order to make it difficult to remove the mosaic.
The strategy of adaptively selecting the most effective of the three mosaic generation methods will be further studied. At present, we plan to dynamically select three mosaic methods based on the characteristics of the target object region. In other words, the more we choose from the first method to the third method, the harder it is to restore the original target object area. In addition, as we choose from the first method to the third method, the color value is changed abruptly in the area where the block-based mosaic is located when compared with the areas around the target object region, resulting in unnatural results. Therefore, the basic strategy of dynamically selecting one of the three methods will be to select a mosaic generation method according to the type of corresponding target object area.
Besides, if the target object requires less security, the first mosaic generation method is used. If the target object needs more security, the third method is selected. In other words, if you need stronger security, such as naked images or cell phone numbers, the third method is chosen. If you need less security, such as car license plates, the first method is utilized. The second mosaic block is created for target objects that require intermediate security, such as faces. In addition, the setting of security strength can be adjusted according to the type of target object area.
We plan to extend the types of objects to be detected to human faces, body parts, cell phone numbers, and license plates. Also, we plan to detect these objects automatically and to then dynamically determine how to generate the mosaic blocks based on the type of detected objects.
5. Experimental Results
In this study, the personal computer used for the experiment has the following specification: Intel Core(TM) i7-6700 3.4 GHz CPU, 16 GB main memory, 256 GB SSD (solid state drive), and Galaxy Geforce GTX 1080 Ti graphics card with NVIDIA GPU GP104. As an operating system, Microsoft Windows 10 was used. As an integrated development environment (IDE), Microsoft Visual Studio Version 2015 was used and OpenCV open source computer vision library and Dlib C++ library were used to implement the proposed method.
In this paper, the face data set produced by VGG (visual geometry group) of Oxford University [
61] was used as image data for the deep learning-based detection of facial regions. The VGG face dataset consists of 2622 files, and each file contains URL paths and face information containing face images. We randomly sampled and downloaded one image from each of the 2622 files. We attempted to use 80% of the 2622 files as training data, 10% as validation data, and 10% as test data. However, there were some invalid URLs among the image URL paths contained in each file. Therefore, a total of 2484 images, including 2268 images for training and verification and 216 images for testing, were downloaded. For various kinds of learning, 2268 face data and 3605 face information (x, y, w, h) were used. For the test, 216 face data and 314 face information (x, y, w, h) were used. As background images, areas with sizes ranging from 40 × 40 pixels to 200 × 200 pixels were randomly extracted except for face areas from input color images.
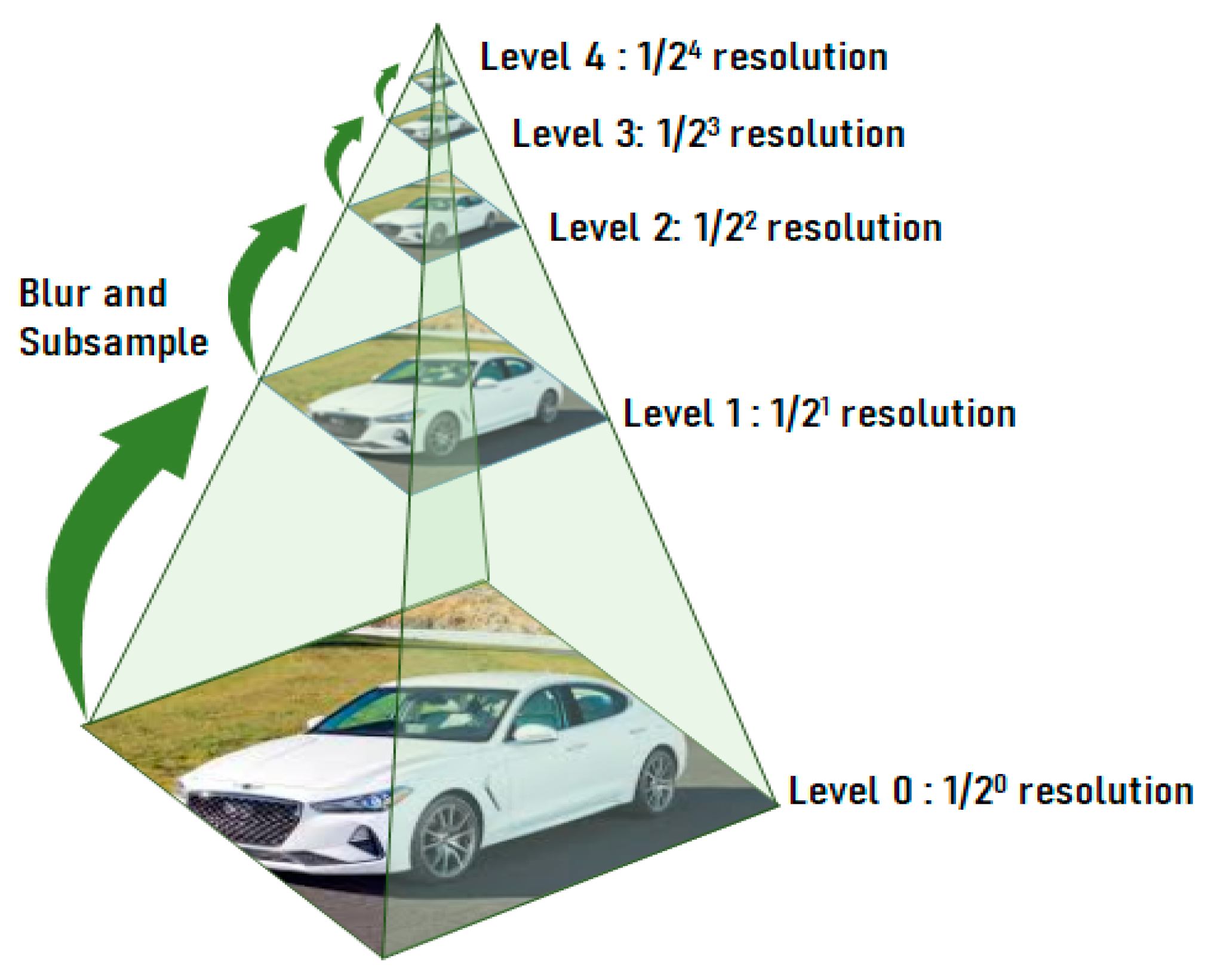
The learning rate used for deep learning began from 0.1 and sequentially decreased to 0.0001. The number of deep learning layers was 21, and the face normalization size was based on the 40 × 40 pixels. Six levels of image pyramids were generated first and then were used as an input of the proposed deep learning algorithm. A total of 183,745 learning steps were used. The average resolution of the image was 463 × 413 pixels, and the size of the window was 40 × 40 pixels. The window was moved by 2 pixels or 1 pixel. The number of learning steps is affected by the hyperparameters used in the proposed model, that is, the initial values of the learning rate and weight, and depends on when the learning converges. In addition, we used cross-validation to raise confidence in the validation of the algorithm.
Figure 10a illustrates an example of the input color image that includes the exposed facial region.
Figure 10b shows the image generated by extracting skin color distribution pixels with the use of the predefined elliptical skin color distribution model and by applying morphological operation for post-processing.
Figure 10c presents the image generated by detecting the facial region from the extracted skin color distribution region with the use of the proposed deep neural computing algorithm. In
Figure 10c, the square box is the MER of the detected facial region.
Figure 10d shows the image with the blocked personal information, which was generated by creating the mean color-based mosaic for the detected facial region with the use of the deep learning technique and by letting the grid-type mosaic overlay the detected facial region.
Figure 11a is another input color image.
Figure 11b shows the image created by calculating the average value of pixels located in the detected object area and then by generating and overlaying a mosaic region.
Figure 11c illustrates the image generated by selecting the pixel values of the detected face region randomly and then by creating and overlaying a mosaic.
Figure 11d presents the image created by randomly applying the
r,
g, and
b color pixel values and then by creating and overlaying a mosaic area. As shown in
Figure 10 and
Figure 11, if the first or second mosaic generation method is used, it is possible to predict a blocked target object region roughly and, if the third method is used, it is difficult to predict a blocked object with personal information because a color value is selected randomly.
We applied the proposed algorithm not only for still images but also for dynamic images.
Figure 12 shows an example of detecting a face region in video data and continuously covering the detected face regions using block-based mosaics. The proposed blocking algorithm is effective enough to process video data.
To quantitatively evaluate and compare the performance of the proposed deep neural network-based target object blocking technique, this study utilized such accuracy scale ways as those in Equations (10) and (11), where N
TP means the number of accurately detected target regions, N
FP is the number of regions which are not target regions but are incorrectly detected as target areas, and N
FN is the number of regions which are target areas but are not detected. In Equation (10), R
precision represents the relative rate of the accurately detected target regions for the total detected target object regions. In Equation (11), R
recall means the relative rate of the accurately detected target object regions for the total target regions existing in an input color image.
To evaluate the accuracy of the proposed algorithm to block a target object region with personal information, this study compared the conventional skin color-based method, the general learning-based method [
17], and the proposed deep neural computing-based method. In terms of implementation, we took full advantage of the source code published on GitHub to implement the existing methods.
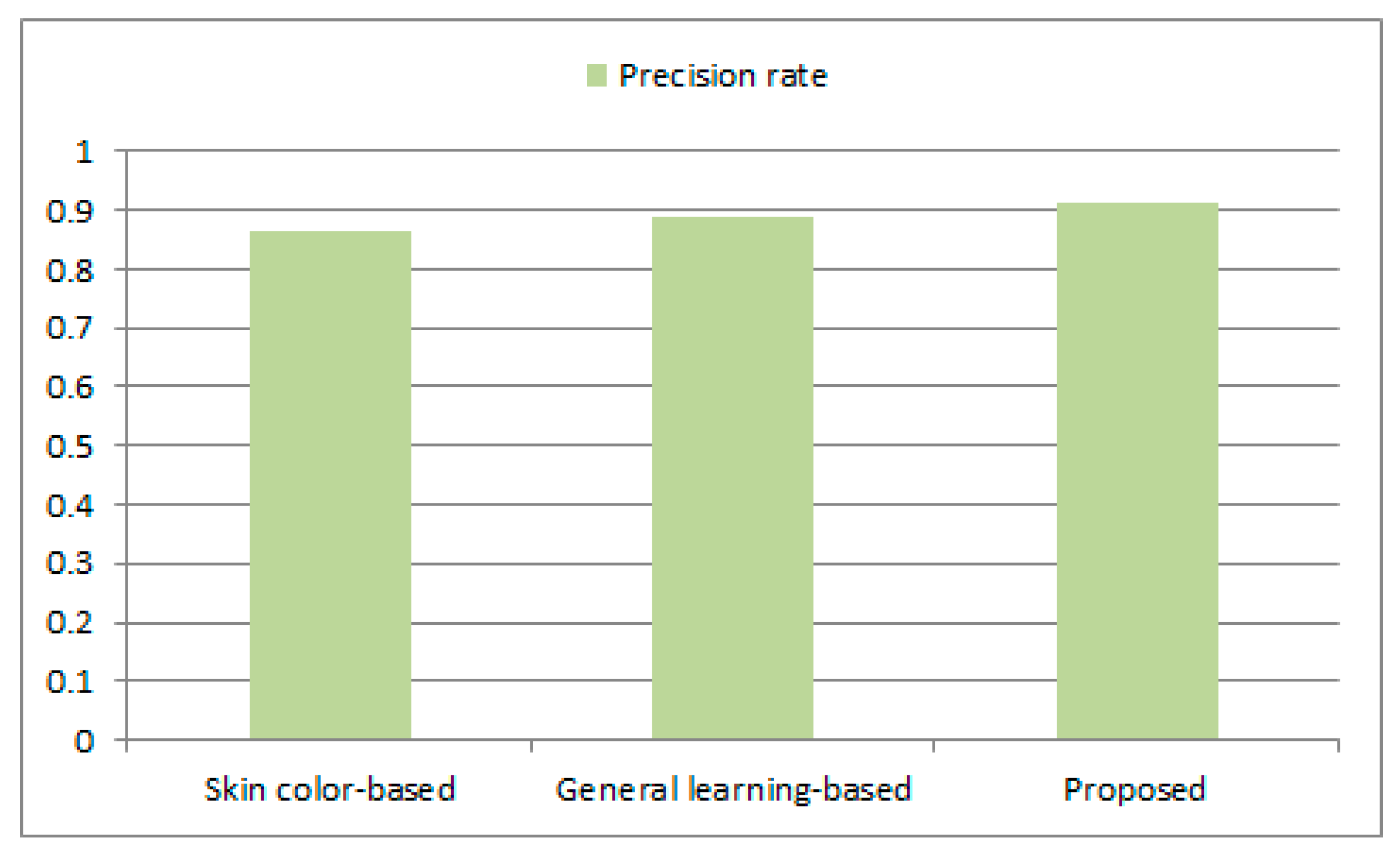
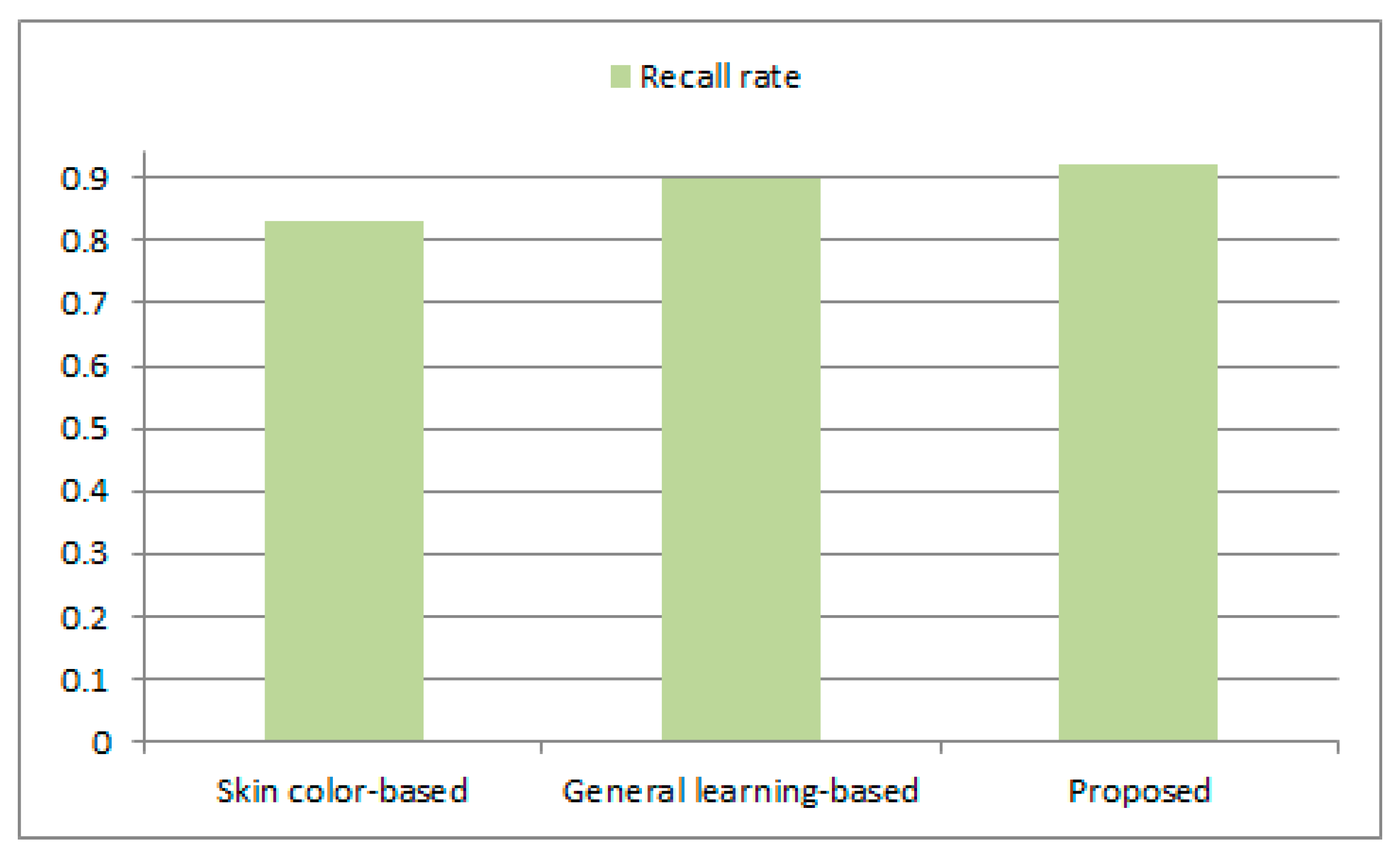
Figure 13 and
Figure 14 illustrate the accuracy measurement graphs of the target object area blocking algorithms, which were obtained in Equation (10) and (11). The proposed method improves the precision rate by about 0.05 and 0.02, respectively, and the recall rate by 0.09 and 0.02, respectively, compared to the conventional skin color-based and general learning-based methods. As shown in
Figure 13 and
Figure 14, the proposed method of blocking a target object region on the basis of skin color detection and deep neural network learning was capable of reducing wrong detection of target object regions and of blocking the areas with personal information more accurately.
Of the three methods, the method using skin color distribution had the lowest accuracy. That was because it simply used the feature of color to detect a target object area. In other words, the method simply using skin color distribution has some limitations in robustly detecting the target objects captured in various indoor and outdoor environments. Although the general learning-based method had a little better performance than the first method, it often failed to have enough learning and therefore caused wrong detection. The proposed method based on skin color detection and deep neural computing robustly detected target object regions including personal information from a variety of input color images and greatly reduced wrong detection, so that it showed relatively high accuracy.
The average processing time of our algorithm is 90.98 ms for an input color image. As a result, the proposed face blocking method is efficient enough for video processing. Furthermore, we plan to improve the processing speed of the suggested blocking approach by performing code optimization of the implemented algorithm and by upgrading the specifications of the personal computer used.
The proposed method is relatively robust to different skin colors because it detects human skin color distribution pixels through elliptical model-based prior learning. Therefore, if skin color training data is used for different races, our skin extraction module will work for different races. Of course, if the image contains a sudden change of lighting or severe noise, the proposed method may cause an error in face region detection. In addition, when there are many areas similar to the skin color in the background, false detection may occur. However, apart from this exceptional situation, our skin extraction module works robustly on a variety of input color images.
Human face detection using skin color causes some error in the presence of severe lighting changes. The proposed method is robust to weak light changes because it detects the face by using deep learning, but it is partially affected by severe light changes because the skin color is basically used. This problem is inevitably caused by the limitations of the camera equipment, which is one of the common problems with most image processing. This problem is expected to be solved in the future when high-performance cameras are developed that self-compensate for severe lighting changes. We plan to compensate for this problem by using an ultra-high-speed camera capable of capturing more than 1000 frames per second until a camera with such lighting self-calibration is developed.
Since the proposed blocking method targets a color image, the face detection algorithm should be changed when a black and white image is input. In other words, when a black and white image is input, instead of detecting a face region based on the skin color, the face region should be detected using the main features of the face from the input image.
Although the proposed approach is applied when one face region exists in one input image, it is also possible to block multiple face regions to a certain extent when two or more face regions do not overlap so much with each other. In other words, the proposed method first detects two or more faces simultaneously and then performs labeling. Subsequently, when the proposed method generates mosaics in units of areas corresponding to each label, multiple face areas are blocked.
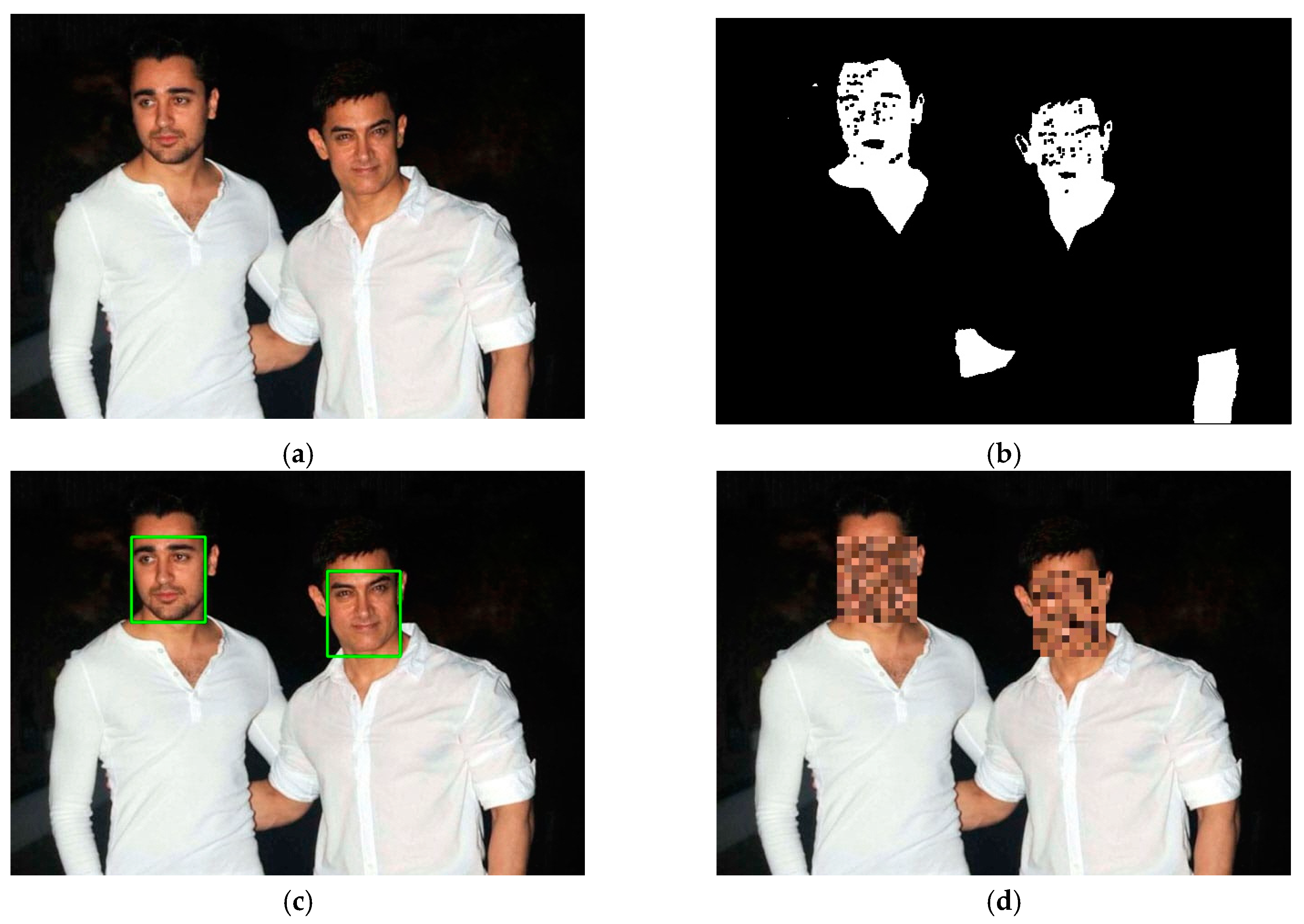
Figure 15 shows an example of detecting and blocking two face regions. In the future, much further research is needed for effectively blocking two or more face areas.
6. Conclusions
These days, it is easy to acquire various kinds of multimedia content with personal computers, tablet personal computers, and mobile devices that support high-speed wired and wireless Internet. In this circumstance, multimedia content including target objects with personal information like human face or particular body region is freely distributed, which emerges as a big social issue. Therefore, many studies have been conducted to robustly detect multimedia content with personal information and then to effectively block the detected target objects through block-based mosaic-processing.
This study proposed the method of robustly detecting target objects with exposed personal information from a variety of input color images in neural network-based learning algorithm and then effectively blocking the detected target objects. In the proposed method, the RGB color space of an image is changed to the YCbCr color space. With the use of the skin color distribution model generated with an elliptical model, background regions are excluded from an input image and only skin color distribution regions are detected. Subsequently, the artificial neural network-based deep learning algorithm is applied to accurately extract the target object region with personal information from the skin color region detected in the previous step. In the last step, a grid-like mosaic region with the same length and width sizes is generated and the generated mosaic naturally overlaps the extracted target region so as to effectively block the target object region with personal information.
In the experiment of this study, the proposed algorithm was applied to various kinds of color images captured in a general environment without particular constraints, and the accuracy performance of the proposed method was evaluated qualitatively. As a result, the proposed technique using the artificial neural network-based deep learning more accurately detected and blocked a target object area with personal information than conventional methods. In other words, the proposed blocking method based on the deep neural computing algorithm with excellent performance more robustly detected target object areas from various color images and had relatively higher accuracy than conventional methods. In addition, the proposed method showed relatively good efficiency.
Most of the conventional blocking methods are very inefficient because the user manually detects a target object from the image content and then manually blocks the detected object area using mosaics. That is, the operator directly creates and applies a mosaic to a corresponding area of the image by using an image editing tool. On the other hand, the proposed method not only automatically detects the target object area based on deep learning but also automatically generates a mosaic to effectively cover the target area. Moreover, the existing mosaic generation methods generate mosaics using only one method, whereas the proposed method attempts to adaptively select and apply three types of mosaic generation methods according to characteristics of an input color image.
The future plan is to apply the proposed neural network-based target object blocking algorithm to the input color images captured in more diverse indoor and outdoor environments without constraints and then to prove the robustness of the proposed algorithm systematically. In addition, we plan to stabilize system operation performance by adaptively tuning multiple parameters including the learning rate used in the proposed and implemented target object blocking algorithm. Aside from that, the tracking function using a predictive algorithm like Kalman filter will be added in order to detect and block a target object faster.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














