1. Introduction
According to the first-year data from the 7th National Health and Nutrition Survey (2016), Korea’s obesity rate is increasing every year and accounts, as of 2016, for 34.8% of the total population. The Organization for Economic Cooperation and Development (OECD) has predicted that Korea’s already highly obese population will double by 2030 [
1]. The cost of obesity in social losses, such as medical costs, reached 9.2 trillion Korean won, as of 2015. This is more than just a problem of excess weight; obesity also results in orthopedic problems, as well as diseases related to most organs, such as asthma, diabetes, high blood pressure, cardiovascular disease, and depression, with short and long-term consequences [
2,
3]. Most people are aware that obesity can cause physical problems, but they do not know how badly their bodies are damaged or understand how to improve their condition. In 2011, the authors conducted an investigation on the perception of body shape and subjective health conditions, asking college students in the Seoul area to rate, on a five-point scale, their health-related habits, such as exercise, diet, and lifestyle. The study found that the difference between people who subjectively considered themselves healthy versus those who did not was satisfaction with their weight [
4]. Many overweight or obese people have negative views about their health and are sensitive to changes in their weight.
However, when people are sensitive about their weight they can easily measure and are less sensitive about their body shape. The reason is that most people use the body mass index (BMI) and body fat (BF) percentage indicators, which are thought of as the gold standard, when they measure obesity. According to the World Health Organization (WHO), these obesity standards are defined as follows: BMI is calculated as kg/m
2 (weight in kilograms divided by height squared in meters) and has four categories: underweight (BMI < 18.5 kg/m
2); normal weight (18.5 kg/m
2 ≤ BMI < 23.0 kg/m
2); overweight (23.0 kg/m
2 ≤ BMI < 25.0 kg/m
2); and obese (25.0 kg/m
2 ≤ BMI) [
5]. Further, the BF percentage is largely divided into four classes, and unlike BMI, which only measures obesity by height and weight, the BF rate can be added to measure obesity more accurately. However, there are difficulties in measuring the exact level of obesity because the BMI and BF values do not account for differences in muscle mass or body shape [
6].
There is a need to modify obesity values in order for them to be stricter than the international obesity standard defined by the WHO [
7]. Therefore, various research studies on obesity values or body shape values that can supplement BMI have been conducted and new measures have been proposed, including a body shape index (ABSI), which is an indicator to assess health effects through height, weight, and waist circumference of a given human body that measures mortality based on the correlation between height, weight, and waist circumference [
8]. The Brugsch’s index is a measure of physical health that uses weight and height [
9]. The weight of Kaup’s index, and the presence of height, is proportionally determined by body type, such as obesity [
10]. While there are many different methods of measurement, people usually use BMI, which is easy to calculate, because it is a simple method derived from a single body size approximation. The BMI method has also been supplemented with the anthropometric risk indicator (ARI) index [
11]. However, it is difficult for people to judge the body area that has the problem, especially compared to simply checking a chart to confirm a perception about weight. Despite the abovementioned methods being effective in calculating obesity in specific body parts, their calculation methods are complex. Therefore, many people judge their obesity levels through BMI, which is easily calculated. Furthermore, the fact that obesity can be measured differently, using various indices, may be a cause for confusion.
For example, myopic obesity (internal equipment only) often results in a convex form in the arm, leg, and abdomen, which is either thin or normal in terms of BMI, but in reality, is abdominal obesity. Another case of misclassifying obesity is muscular obesity. Musculoskeletal obesity can be concluded in case of a very athletic person who has a lot of muscle mass, typically with broad shoulders and large muscle presence in certain areas, which is judged by BMI standards to be overweight or obese, despite actually being within the normal range.
This makes it difficult to find hidden obesity and muscular obesity. There is a hidden obesity in judging obesity hidden obesity is a body type that appears when BMI values are 25% or less for men and 35% for women, and BF values are 18.5–25%. Muscular obesity refers to body types that are in fact obese, but appear normal or slim. If BMI is less than 10% for men, or less than 20% for women, and more than 25% for the BF value, it may be considered normal but be obese. However, the BMI may actually belong to a normal, muscular category, and not the obese category. For this reason, people need to obtain accurate obesity information that reflects their body type. In addition, the National Health and Nutrition Survey 2015 found that the data diagnosing obesity through BMI was misdiagnosed about 7% of the time, as compared to the data of the population diagnosed with obesity using BMI calculations based on expert advice.
Hence, it is necessary to create an accurate classification model. Information such as body component analysis and skeletal muscle mass is required to accurately determine hidden obesity, or musculature obesity. While BMI alone is not able to categorize obesity exactly, it is often used because it is easy to measure weight or height. However, in comparison, collecting information on body parts, or skeletal muscle mass, is relatively difficult.
Therefore, this study aims to develop a model that easily measures and accurately classifies obesity by body size, using input information such as weight, height skeletal muscle, and body fat, as well as measuring the length and circumference of six body parts (chest, waist, hip, thigh, calf, and arms). This method offered a new insight into obesity, and was compared to the existing BMI method.
Using this method, it was possible to diagnose obesity more accurately than when diagnosed by the BMI [
12] and WHtR methods [
13]. This study divided the body parts into various age groups, into six sections (i.e., chest, waist, hip, thigh, calf, and arm); measured the length and width of each body part; used variables such as weight, height, skeletal muscle mass, and body-fat mass to check for obesity; and examined whether the resulting prediction of likely/unlikely obesity, based on the learned data, which leads to a more accurate evaluation in comparison the traditional BMI method. Further, using the data gathered, we evaluated the subjects’ obesity using the lengths of the body parts.
This study determined complex body obesity conditions by only using body sizes that are recognized and easily measurable by themselves, as opposed to measuring body conditions and obesity using only one specific area. The purpose of this study is to use the length and circumference information of major body parts to create a model that can accurately classify obesity conditions. In summary, this study used information on the length and circumference of six major body parts to categorize groups that had been incorrectly diagnosed as normal, when they are obese, and to develop algorithms that can diagnose muscular obesity as normal.
This research is presented as follows:
Section 2 presents the existing studies and studies on various indexes for measuring obesity and obesity information related to obesity information and explains the direction of this study.
Section 3 presents methods for data definition, data pre-processing, and variable selection to be used in the analysis of this study, and suggests criteria for obesity using the web service presented in this study.
Section 4 classifies obesity information through the proposed classification method based on the selected variables, and builds a web service using the model with the highest accuracy for obesity information based on the derived results. By building a web service, we provide a service that can derive obesity information using only in vitro information that people can recognize. In
Section 5, the obesity information derivation system is tested through the experimental group, and the final result is compared with the existing obesity information prediction model.
3. Materials and Methods
This study incorporated internal and extracorporeal information when only extracorporeal information was input. It was able to derive similar body information when only extracorporeal information (such as body size) was input, and combined previously learned body information with the obesity diagnosis. Analyses were conducted using anthropometric data from Size Korea [
1]. In examining the data structure used in the analysis, the data collected in 2015 was used to analyze 148 variables from 6413 subjects (3192 men and 3221 women), in ages ranging from 20s to 60s. KS A7003 was selected by the Korea Institute of Standards and Science (KRISS) as the measurement item for 120 anthropometric measurement items and established Korean standards (see the
Supplementary Material). The data were collected in a total of 28 regions in Korea, and bodies were measured by direct measurement, which was verified by KS A7003 [
26]. Body composition analysis is also a group of detailed measurements of a single human body, along with detailed human dimensional data, such as the whole body, feet, head, and hands by digital technology. For our measurement investigation protocol for data collection, the authors considered the statistical method for deciding measurement subjects based on ISO 15,535 in order to calculate the minimum number of measurement subjects with relative accuracy (1–3%), using the maximum variation value of data by body type.
Table 1 shows the demographics of obesity information in the National Health and Nutrition Survey data. Looking at
Table 1, we can see the value of obesity from teenagers to people in their 60s for the four types of obesity information. The data provided in
Table 1 are the body data provided by the 2015 National Health and Nutrition Survey (NHNS). It provides accurate information about obesity information through a thorough investigation of the data. Therefore, we used the obesity information provided in this data as a reference.
Table 2 shows a total of 6413 obesity-related data received from NHNS in 2015 that were used to measure obesity on a variety of obesity information. NHNS’s data are those that contain body information measured through the KS A7003. Using this data, values for various body parts were derived for BMI, body fat percentage, WHR, and WHtR. The NHNS also represents specialized statistics, which are shown for 6413 obesity information derived from human body measurement and obesity examination by experts at NHNS agencies. Thus, the error rate was presented to indicate the error compared to the previously derived estimates of obesity information. Compared to
Table 2, it shows the difference between the degree of obesity and the error rate for obesity, measured by the existing obesity index. A total of four measures of obesity were used to compare the differences, with the obesity indices measured by specialized institutions. The data measured by the specialized institutions were made into four clusters for men and women (normal weight, underweight, overweight, and obese), and were compared to the existing obesity index; each criterion was underweight (BMI < 18.5 kg/m
2); normal weight (18.5 kg/m
2 < BMI < 23.0 kg/m
2); overweight (23.0 kg/m
2 < BMI < 25.0 kg/m
2); and obese (25.0 kg/m
2 ≤ BMI). WHtR (obese over 0.63, overweight over 0.63, overweight under 0.63, normal weight over 0.43, under 0.53, underweight for women over 0.63, overweight over 0.63, under 0.63 over 0.63, underweight under 0.43 over 0.42), WHR (obese over 1, 0.9, overweight, under 0.95, normal weight, under 0.85, underweight women under 0.92, obese, over 0.9, over 0.92, overweight, 0.76, and under 0.9, underweight, under 0.76). Body fat percentage is based on males over 25 obese, over 20 over 25, overweight, over 14 over 20 normal weight, under 14 underweight, over 27 over obese, over 23 over 27, over 17 over 23 normal weight, under 17. As shown in the table below, as a result of judging obesity through various indices of obesity, there are a lot of errors with the diagnosis of obesity that are derived from body information, such as body composition at a specialized institution. It can be seen that the reason for the error is that the obesity index is used to predict obesity based on only one part of the body. Therefore, in this study, by learning various internal and external information measurements by a specialized institution, when only the body size information is input, the service provides a service to determine obesity based on the previously learned information. Not only can you receive knowledge, you can easily diagnose your obesity without the use of machines, such as body composition and muscle mass analysis.
3.1. Data Definition
Original body data were gathered for various body parts using basic measuring tools: rulers and a body-composition analyzer. The variables were divided into two large groups: intracorporeal data and extracorporeal data. Intracorporeal data are body information obtained by taking internal measurements using various machines; in our study, the variables were skeletal-muscle mass, body-fat mass, body water, minerals, body-fat ratio, and basal metabolism variables. Extracorporeal data are external information; we processed the data from Size Korea for the length and width of each of the six body parts. In measuring the length and width, we divided the areas in order to obtain no overlapping lengths between any of the six parts. All body-part measurements were in millimeters (mm). The total number of variables acquired was 30. The data were all human measurement data provided by Korean Size 2015. It consisted of a total of 148 variables, including gender, height, weight, and length of each body part. Of the 148 variables, the remaining variables were removed from the analysis, except those included in
Table 3. Unlike the traditional methods of using BMI and (WHtR), the information on the values of the body parts given in
Table 3 were disaggregated and used to perform obesity prediction analyses. The obesity information defined was based on this standard by learning the intracorporeal and extracorporeal information, and was evaluated using the difference from the deduction of obesity using the existing obesity measurement methods when information about body shape was input. The variables selected are listed in
Table 3.
3.2. Data Processing
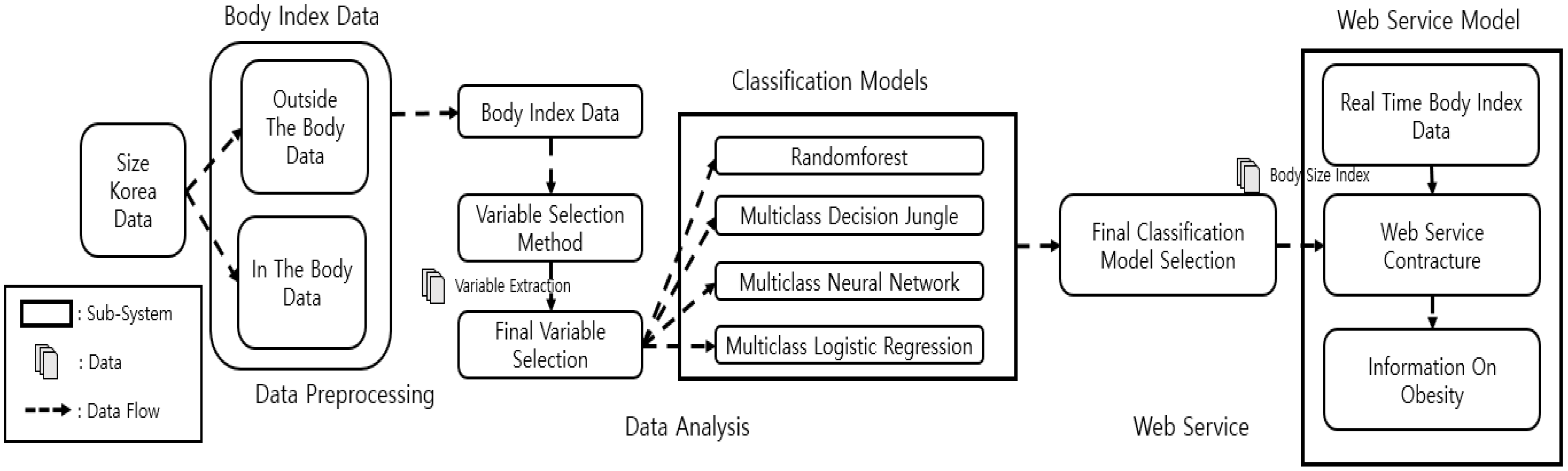
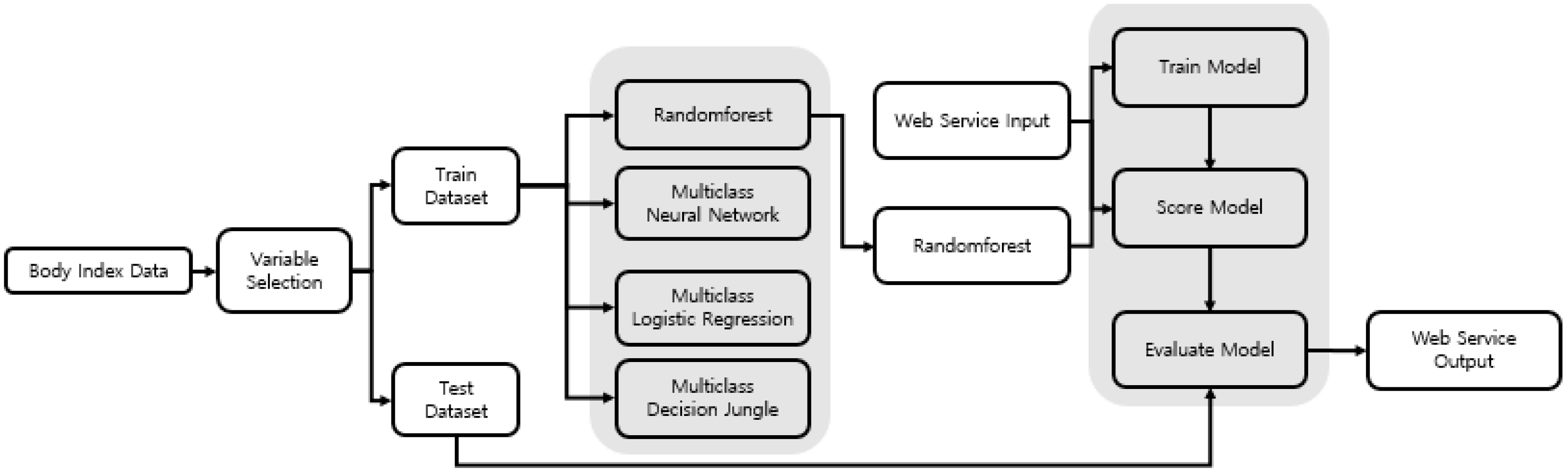
Figure 1 shows the overall process of this research, which comprises three stages: data preprocessing, data analysis, and web servicing. In the data preprocessing stage, the intracorporeal data were divided from the extracorporeal data (from Size Korea) into chest, waist, hip, arm, thigh, and calf, and the variables were selected using the variable selection model. We drew the final variables selected from the results of the variable selection. In the data analysis stage, we used the selected variables to create a total of four types of classification methods in order to find the model with the highest accuracy. After finding the model with the highest accuracy, in the web service stage, we built a web-based application that used body-part measurements and BMI information to show the obesity information. In the web services phase, information about obesity was derived from the models that were built in the data analysis phase and were configured based on the best model found.
3.3. Data Description and Feature Selection
As shown in
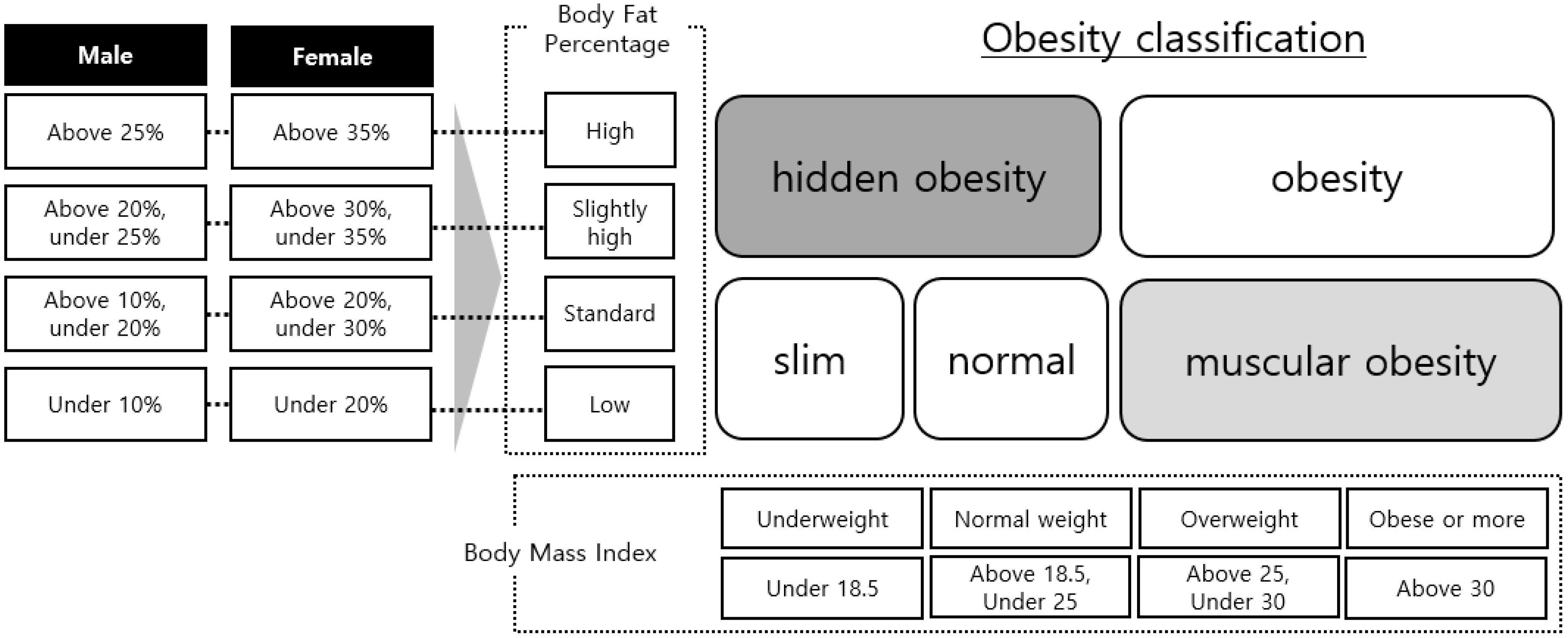
Figure 1, the information input identifies obesity based on the Size Korea data. The relationship between BMI and the BF percentage was identified, and a standard for obesity was established through WHO standards in that relationship [
27]. As shown in
Figure 2, we defined the BF ratio separately for men and women. Using the defined BF ratio information and BMI, we created five classes: slim, normal, hidden obesity, muscular obesity, and obesity. The drawn obesity information was converted to the following patterns: slim→underweight, normal→healthy range, hidden obesity→overweight, muscular obesity→obese, and obesity→obese, which were identical to the standard variables of BMI and WHtR, and were in line with the class values of BMI and WHtR to be compared.
We chose variables that affect obesity through a regression model, which is one of the ways in which we select variables. Since the regression model is the most widely used model to identify the relationships between the various numerical categorical independent variables for a single dependent variable, a variable selection was made using it. Therefore, a regression model was used to conduct variable selection, extracting variables from among 30 extracorporeal and intracorporeal variables that influence obesity. For the variable selection method, a stepwise regression, which is a multiple regression model, was used. In variable selection, we found the section with the highest adjusted value, and the section with the lowest value, to select the number of variables. Data preprocessing was completed by selecting the variables using the regression analysis.
The coefficient of determination in
is an increasing function that also increases in size if the number of independent variables increases; thus, it has the disadvantage of the coefficient of determination increasing, regardless of significance, if the number of independent variables increases [
28]. In adjusted
, the unexplained variation coefficient decreases and
also decreases when the sum-of-square error increases, and is neither an increasing nor decreasing function, as shown in Equation (1); therefore, it is shown that adjusted
is not an increasing function.
The
statistic value is a measure of how close the regression model of
regressors is to the target model. We selected the model in which
had the value closest to
and had few variables in the
p-regressor regression model [
29].
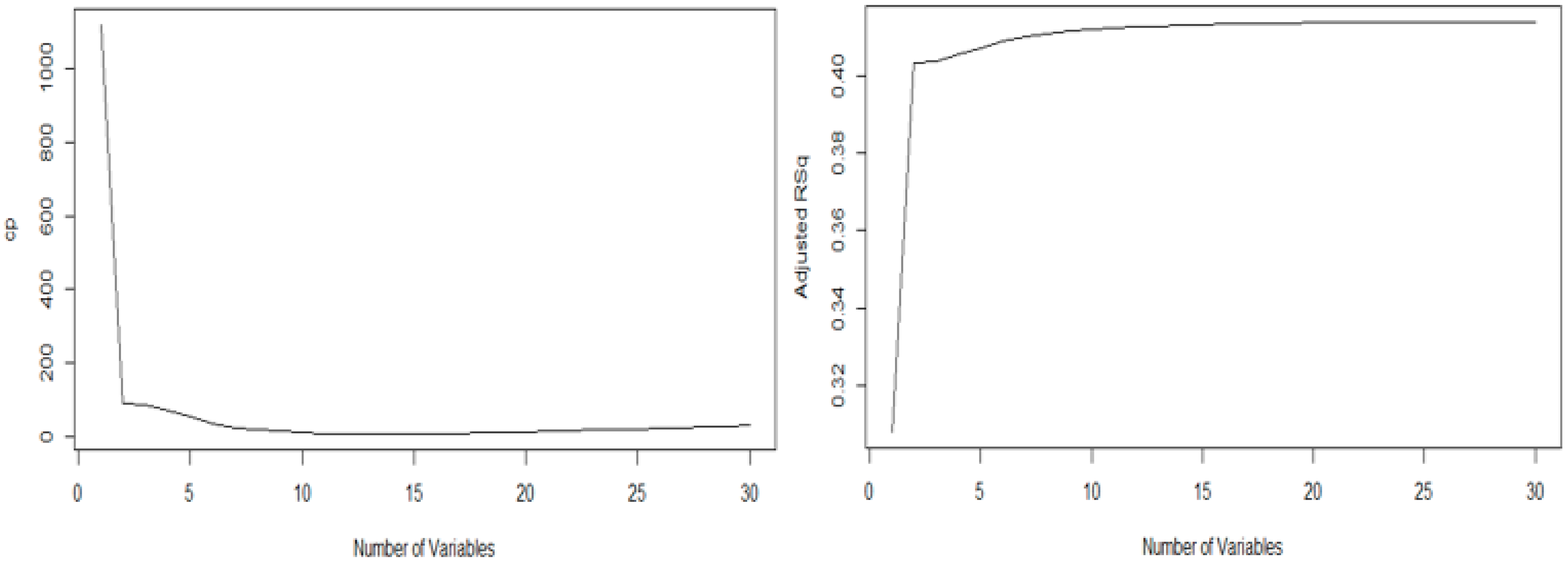
Therefore, the graphs of the
statistic and the adjusted R-squared were each generated. Equation (2), which shows the sum of the residual squares (SSE) and the residual square mean (MSE), represents the sum of the residual squares of the model with each selected explanatory variable—the
is the number of explanatory variables selected and the
value is the total number of explanatory variables. Therefore, this represents the estimator of the sum of the residual squares. Moreover, the minimum value of the
statistic in this graph is 16, and the maximum value of the adjusted
in this graph is also 16, as shown in
Figure 3. Therefore, based on the above-mentioned two values, we performed optimal variable selection using the
in the regression analysis method. As a result, the following variables were selected for obesity analysis: gender, body-fat mass, body water, minerals, BMI, body-fat ratio, height, weight, waist circumference, hip breadth, hip vertical length, chest breadth, chest circumference, chest girth, thigh circumference, and calf circumference.
For the classification model, we used the following machine-learning methods to select the model with the highest accuracy as the final model: multiclass random forest, multiclass decision jungle, multiclass neural network, and multiclass logistic regression.
Table 4 shows that there are variables that have
that are not significant. However, because the optimal variable from the adjusted
value and the
statistic value were 16, we conducted the analysis using the variables drawn from variable selection.
3.4. Compare Methods
Random forest, one of the classification models, is an ensemble learning method. It outputs the classification, or mean predicted value, from the multiple decision trees that are built during the training process. One tree comprises a collection of nodes and edges in a hierarchical structure. Nodes are divided into internal nodes and terminal nodes. Therefore, it is a method to find the optimal model by using tree models that have different characteristics. When producing the first tree, the model measured the degree of inequality using the Gini coefficient in order to decide how many nodes were made. As the Gini coefficient approached 0, the distribution could be said to be equal; as it approached 1, the distribution was unequal. Therefore, in the case of the Gini coefficient decreasing, and the node’s impurity decreasing as the nodes separated, the division of the corresponding node was terminated, and the final tree model was made. Finally, the best model was drawn from the trees made in such a manner using the out-of-bag (OOB) method. When
n observed samples are sampled with replacement
n times, they are re-sampled with the probability of the following equation [
30,
31]. In Equation (3), by restoring
n observation samples
n times, the sample is capable of being duplicated in the sample, and the same size sample is taken as training data, with the other unselected objects being set as test sets. Therefore, the variables have slightly different characteristics for each tree and generalize the results, based on the predictions of each tree to improve performance. In this study, which deals with many variables, we used this method. In parameter setting of Random Forest trained each model through resampling method bagging and used 10 decision trees for training. In addition, the maximum depth of the tree was set to 32 and the number of random splits was set to 128, and 100 training was conducted.
Decision jungle is another ensemble model and is a method for detailed classification. This model refers to the combination of randomized ensembles of directed acyclic graphs (DAGs). This model has the function of a division node that obtains general information and the structure of DAGs. DAGs independently learn each root, and each root predicts accuracy using the learned nodes [
32]. In parameter setting of multiclass decision jungle, ten decision directed acyclic graphs (DAGs) layers are used and the maximum depth of the decision tree was set to 32. Also, the number of optimization steps was defined as 2048.
Equation (4) applies to multiple class classification neural networks through Cross entropy. The value derived is the cost function E. The output
value ranges from
and the Cross entropy cost function is used together as an active function.
is displayed as one-hot-vector when the answer label is correct, and the error is equal to the output value to zero, and the larger the difference between the two values, the greater the error value.
n and m mean the total number of
for each data,
value for the number of
data, and
means the
value. Thus, to calculate the probability for each data, the probability is expressed using ln, and the mean loss function is divided by
, which represents the total number of data.
is a cost function that determines how much the weight of the connection
will be reflected. Thus, even if the error is zero, the cost function will have a large value, thus solving the overcompatibility problem of the neural network by keeping the weight small.
To minimize the costs after obtaining the cost function, the backpropagation algorithm was used. The accuracy of the classification model was obtained using the optimized cost function obtained through this process [
33]. In parameter setting of multiclass neural network, there is no dropout where 100 hidden nodes are created, and all nodes are connected, and the learning rate is set to 0.001.
Logistic regression is a statistical methodology that is used to solve and predict the problem of identifying the linear relationship between independent and dependent variables, which is identical to the goal of a regular regression analysis. Logistic regression is used when the dependent variables are categorical data. When two or more dependent variables are analyzed, this is referred to as a multiclass logistic regression analysis. Logistic regression analysis faces the problem of effectively finding the linear predictor variables. Therefore, it can be represented as in Equation (5).
Logistic regression is a statistical method used to resolve and predict the problem of identifying linear relationships between independent and dependent variables just like the goals of regular regression. Logistic regression is used when the dependent variable is categorical data. Time to analyze more than one dependent variable is called multi-class logistic regression. Logistic regression is a good way to find linear predictors. Therefore, it can be expressed as in math Equation (5). The expression in logistic analysis is used to determine the effect of the regression values on the dependent variables by using a probability
with anode ratio that indicates the intersection ratio and determines whether they are true or false, and thus the regression coefficients
,
and variables are used to determine the effect of the regression values of the various analysis variables on the dependent variables and to depend on the regression values that have the greatest influence on the data classification of data [
34]. In parameter setting of multiclass logistic regression, four obesity information was designated as dependent variables, and through this, class prediction values for which data belong to each classification were derived. Multiclass logistic reserve derived 2.2 × 10
−15 with
less than 0.05 and used it to select the model.
To select the model with the best value for deriving obesity information using these four models, the performance of the four models was judged using the accuracy of the model, the precision value, and the recall value.
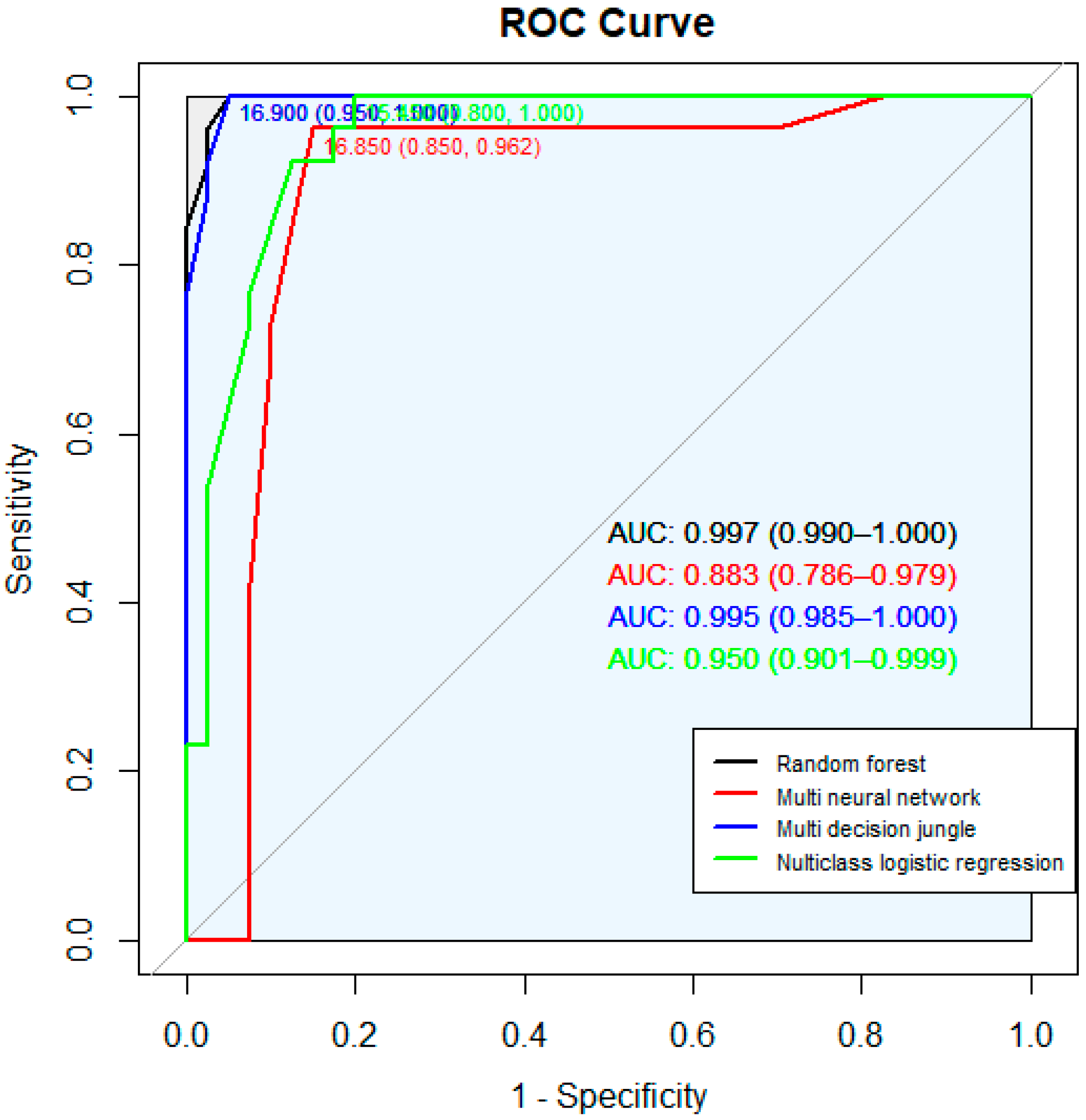
Table 5 lists the accuracies of the four models. In
Table 5, the accuracy of these data was derived by randomly extracting 100 data for four types of obesity information in order to select the model that produces the highest accuracy for the four classification models and the model that derives the highest accuracy for the obesity information. As a result, a total of 100 data were derived for the four obesity information (normal weight: 40, underweight: 26, overweight: 20, obese: 14) and random forest and multiclass decision jungle produced the highest accuracy and chose the random forest model. The values extracted from
Table 5 are the representations of the average values of the four types of obesity information. Therefore, as shown in
Figure 4, each ROC curve for each of the four models was derived, and the random forest with the highest accuracy was selected as the final model.
4. Results and Discussion
Using the selected variables and the four types of models, we generated each classification model, and then selected the most accurate model. In the analysis, we used the Azure statistics module provided by Microsoft, based on R. For the analysis models, we used the multiclass random forest, multiclass decision jungle, multiclass neural network, and multiclass logistic regression. Prior to analyzing each classification model, we conducted a model construction. Here, we modified the construction values so that all the models had identical conditions.
Random forest: This is a resampling method known as bagging, which is used to select multiple samples and trains them to each model in order to aggregate the result. We used ten decision trees; the maximum depth of the decision tree was set to 32; the number of random splits per node was set to 128; and the minimum number of samples per leaf node was defined as one. Bagging performs a restoration random sampling of the target data and sorts the extracted data into a sample group, which then collects the predictor variables of the learned models in order to generate a model [
31] the multiclass neural network. For this, we set the hidden layer specification to be a fully connected case, with 100 hidden nodes being generated, and the learning rate was defined as 0.001. We performed 100 iterations. As with random forest, the resampling for the multiclass decision jungle model was completed via bagging. Ten decision DAGs were used. The maximum depth of the decision DAGs were set to 32, the number of random splits per node was set to 128, and the number of optimization steps per decision DAG layer was defined as 2048.
Multiclass logistic regression model: This was defined by using a value of 20 as the limited-memory Broyden Fletcher Goldfarb Shanno (L-BFGS) memory size. After defining the models, as mentioned, analyses were conducted. The analysis process was generated, as shown in
Figure 5.
The total number of data values in the analysis models was 6382, which is divided into a Train set (70%) and a Test set (30%). A total of 16 variables were used to conduct the analyses. A total of 16 variables were used to conduct the analyses. 16 variables were used in the analysis using the variables shown in
Table 4, and 16 variables included body-specific variables affecting obesity information and extracorporeal information affecting obesity. We aimed to select the model with the highest accuracy from among the four models in order to conduct obesity information extraction through body size information.
Table 5 lists the accuracies of the four models. The values extracted from
Table 5 are the representations of the average values of the four types of obesity information.
The results from evaluating the four levels of accuracy in the obesity information from each model showed that random forest produced the highest accuracy. Therefore, we used that model to machine-learn the data for the 16 variables (nine external variables: information including body length information and circumference information. Seven internal variables: information on the body’s internal body characteristics and numbers) and used this learning model to conduct obesity-information extraction using the extracorporeal data. Out of 16, 11 extracorporeal data variables were used, excluding intracorporeal data—fat mass, body water, minerals, BMI, and body fat (%)—in order to conduct a prediction analysis of obesity information. Based on real-time results, we used the Azure web application via the construction, in the process shown in
Figure 5, to generate the web service process.
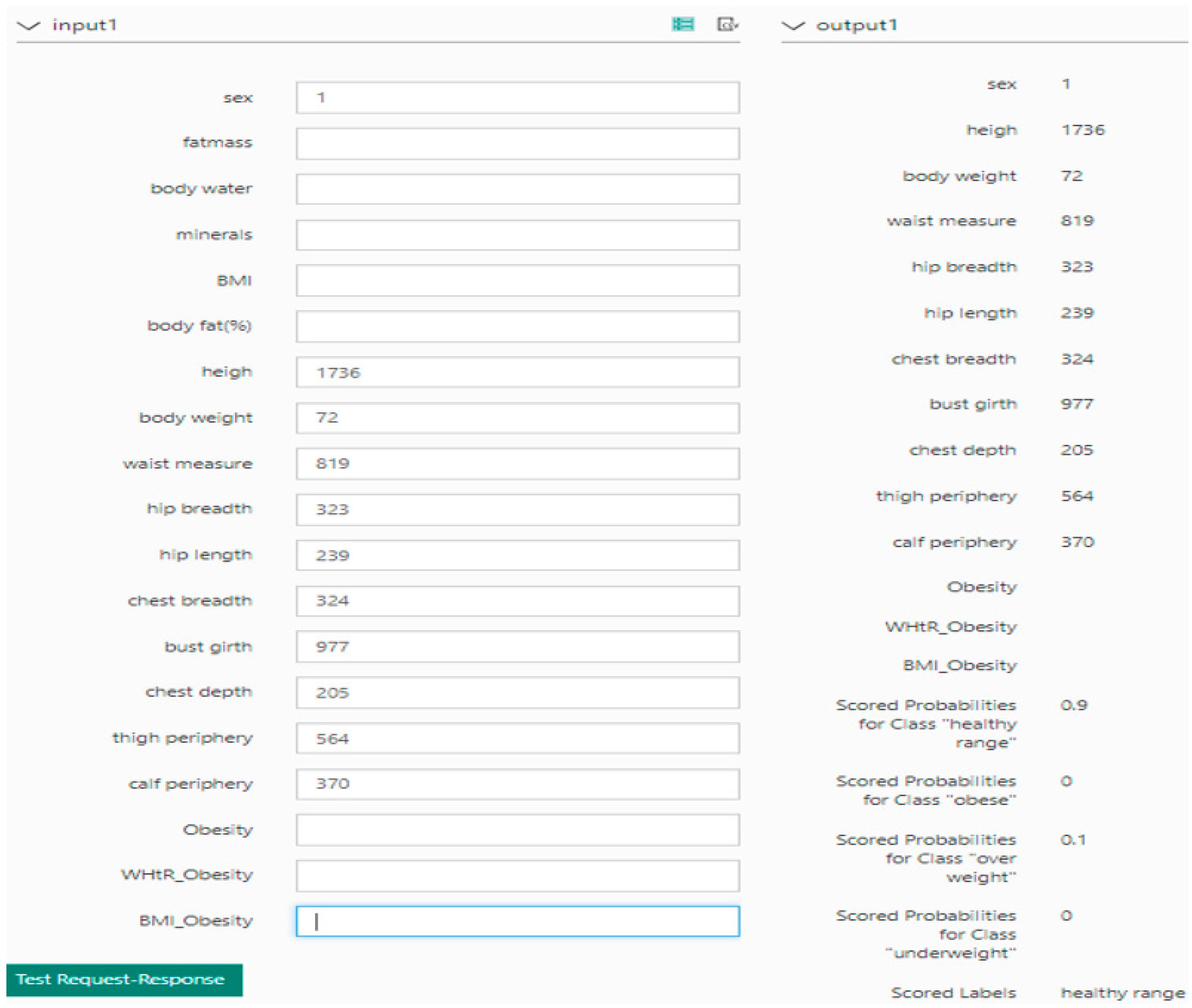
The prediction results using the process shown in
Figure 5 in the Azure web environment are shown in
Figure 6. In
Figure 6, when the values are entered, the value of the Web Service input is then input to the value of the Score model, which is produced by the train model. The output value in the Web service is derived from the value received by the score model, in the Train model, as the output value in the Web service. Test data were randomly extracted 100 times from the data collected in 2014 from Size Korea, such as analysis data and the conducted tests.
The results using information learned from the random forest model and the body index data entered into the web page showed that obesity information was accurately predicted in 85 out of the 100 extracorporeal data values tested. Further, when we compared the histograms and boxplot with the obesity information, based solely on BMI and WHtR, the values from the obesity information differed greatly, and the comparison of the boxplot for each of the obesity measures, based on the BMI values, revealed different values and criteria. Depending on the measurement method, the obesity information extracted was shown to be different. The standards for BMI were defined as follows: (a) underweight: BMI < 18.5 kg/m2; (b) healthy range: 18.5 kg/m2 ≤ BMI < 23.0 kg/m2; (c) overweight: 23.0 kg/m2 ≤ BMI < 25.0 kg/m2; and (d) obese: 25.0 kg/m2 ≤ BMI. The standards for WHtR were defined as follows: (a) underweight: WHtR < 0.43; (b) healthy range: 0.43 ≤ WHtR ≤ 0.53; (c) overweight: 0.53 ≤ overweight ≤ 0.58; and (d) obese, 0.58 ≤ obese.
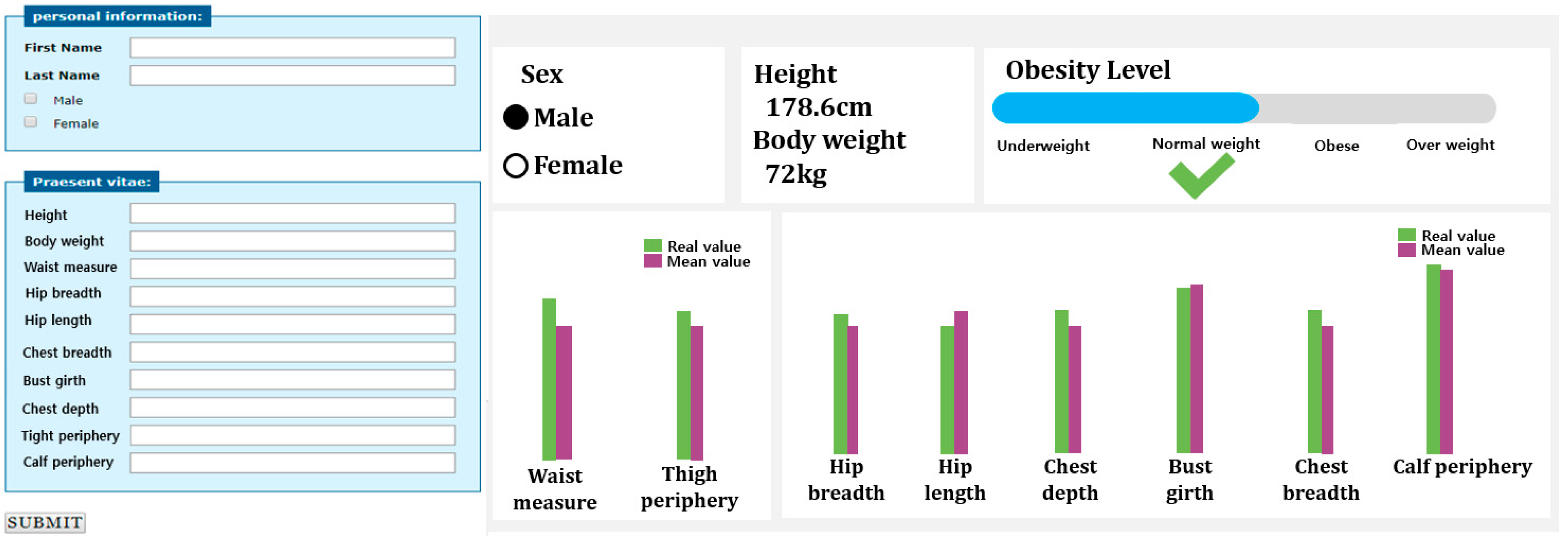
Figure 7 shows the webpage environment using the model created in
Figure 6. Therefore, if you enter 10 body sizes and press submit, the obesity information is displayed using the model that has already been learned. Therefore, by using this webpage, you can understand your own obesity information in real time and update your information in real time.
5. Conclusions
As it is difficult to obtain precise information about obesity by only using values based on existing BMI and WHtR calculations, our study used machine learning from intracorporeal and extracorporeal information to more accurately measure obesity. For measurement data, we analyzed direct-measurement anthropomorphic data from the 2015 dataset of Size Korea. The structure of the data used in the analysis comprised of 148 variables for 6413 subjects (3192 men and 3221 women) in people aged from their 20s to 60s. For measurements in the investigation protocol for data collection, we considered the statistical method to decide measurement subjects based on ISO 15535, to calculate the minimum number of measurement subjects by relative accuracy (1–3%), using the maximum variation value of data by body type.
For the data, the body-data measuring tools used were rulers and body composition analyzers that can measure various body parts. The selection of variables was in two large groups: intracorporeal and extracorporeal data. For this study, we used the variables of skeletal muscle mass, body-fat mass, body water, minerals, body-fat ratio, and basal metabolism. For the analysis variables, we considered six parts of the human body: chest, waist, hip, arm, thigh, and calf. We then conducted the analysis using breadth, circumference, height, and girth of each part.
Prior to performing the analyses, we selected the variables using a regression model. Therefore, the graphs from the statistic and the adjusted R-squared were each generated. The minimum value of the statistic in this graph was 16, and the maximum value of the adjusted R-squared in this graph was also 16. Therefore, we selected 16 variables, from among 30, for the value that had the lowest value of the statistic and the highest value of the adjusted R-squared. The selected variables for the final analysis were gender, body-fat mass, body water, minerals, BMI, body-fat ratio, height, weight, waist circumference, hip breadth, hip vertical length, chest breadth, chest circumference, chest girth, thigh circumference, and calf circumference. We experimented with four analysis models: multiclass random forest, multiclass decision jungle, multiclass neural network, and multiclass logistic regression. Prior to analyzing each classification model, we conducted model construction. Here, we modified the construction values so that all the models had identical conditions.
As the final analysis model that proceeded to machine learning, we selected the random forest model because it had the highest accuracy from among the four models. After machine learning, we used the learned model and 11 variables, with only extracorporeal data, to predict obesity information. Further, we made a web-based application that could draw conclusions from the obesity information values entered by users. In this web calculator, predictions of the four levels of obesity, as shown in
Table 6, and each of the 100 data values for web applications proposed in this paper, were predicted accurately, with an average of 90%.
Table 6 extracts 100 of data for each of the four types of obesity information (normal weight, underweight, overweight, and obese) and compares them with the existing obesity measurement method and the web application presented in this study. In comparison, BMI, body fat percentage, WHR, WHtR, and Web applications proposed in this study were compared with four types of obesity, and accuracy was compared for a total of 400 data using 100 data each with four types of obesity information. Therefore, five methods of eliciting obesity information were compared for a total of 400 data, and the results are shown in
Table 6. Therefore, we provided a predicted value of the accuracy of each measurement and how much information was classified for the measurement.
Using the final model, simple extracorporeal information, such as height, shoulder width, and weight, can be entered into the development system so that obesity can be derived, based on existing intracorporeal and extracorporeal information.
With the prediction of obesity information using extracorporeal information, real-time measurement of obesity can be made, and people can quickly receive and update their own obesity information without using high-cost equipment to measure physical information (e.g., an Inbody machine or body-composition analyzer). Our web-based obesity calculator is convenient for self-diagnosis, incurs almost no cost, and is not restricted by a user’s location. Therefore, unlike previous measurement methods, which are great for height, weight, and one characteristic of the body, this method incorporates information from various body parts and provides an obesity decision that is based on the model learned from this information. By creating a model using intracorporeal and extracorporeal data, a higher accuracy of obesity can be derived than when only using extracorporeal data. Therefore, it was possible to predict obesity more accurately than the existing method, which only assesses obesity through one value, such as height, weight, and waist circumference. With the new method, it was possible to find that body composition is normal, even though it had been shown to be hidden and muscular. However, this study focuses on Korean data to diagnose obesity according to Korean characteristics. Therefore, the failure to analyze various countries is a limitation of this study, and a better study in the future would design and analyze the criteria for obesity information in various countries. In addition, as more information about obesity and related data is collected, we expect that further research will be conducted.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}