
Forecasting Amazon Rain-Forest Deforestation Using a Hybrid Machine Learning Model




Abstract
:1. Introduction
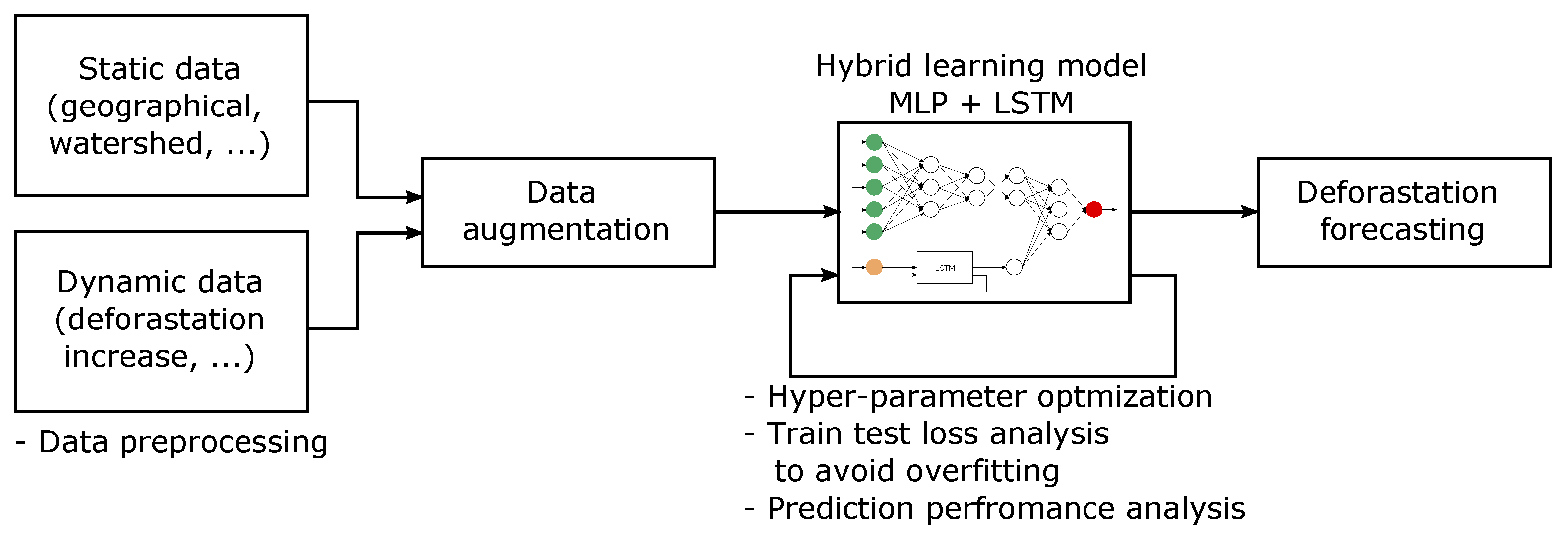
2. Materials and Method
2.1. Data Description
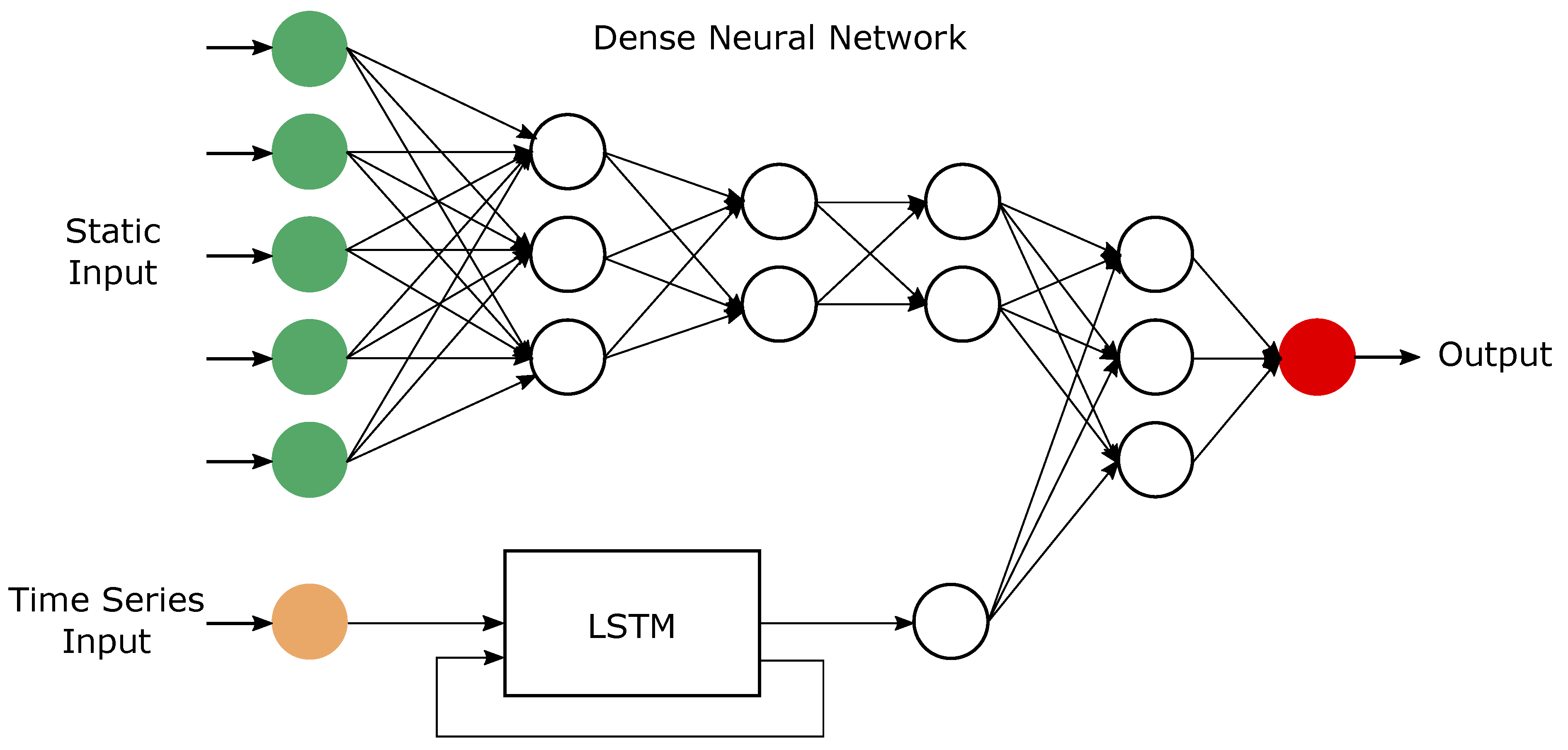
2.2. Hybrid Learning Model
2.2.1. Dense Network: Multi-Layer Perceptron for Static Data
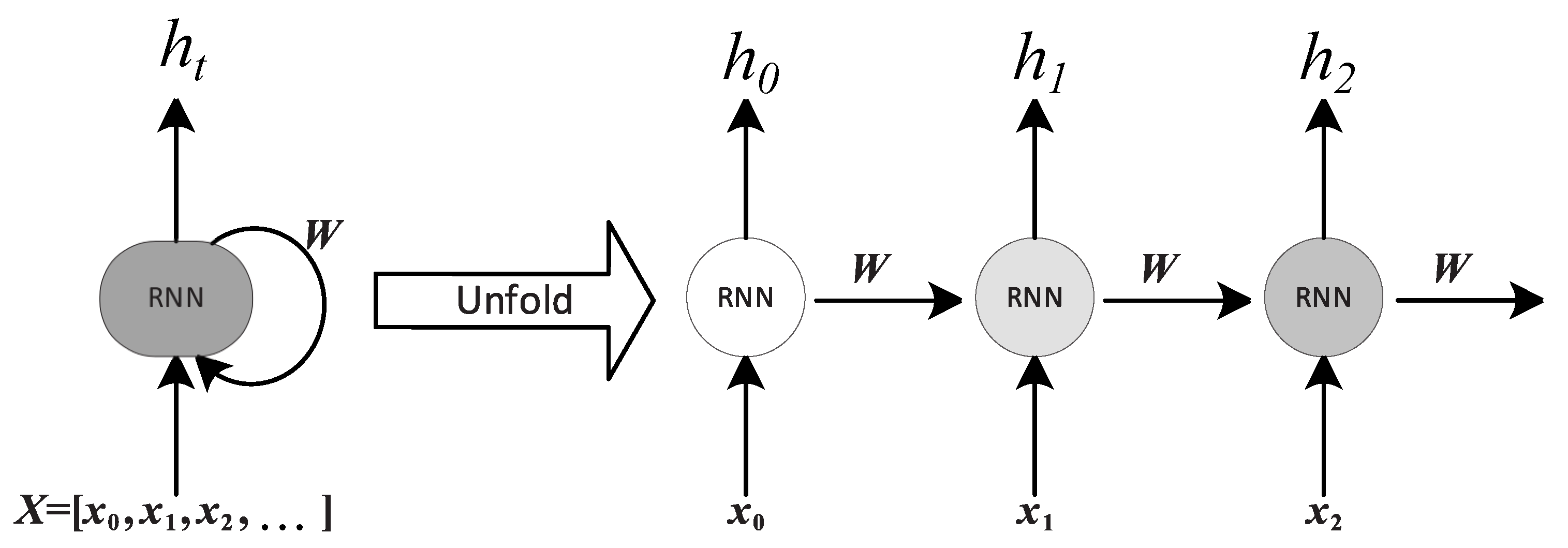
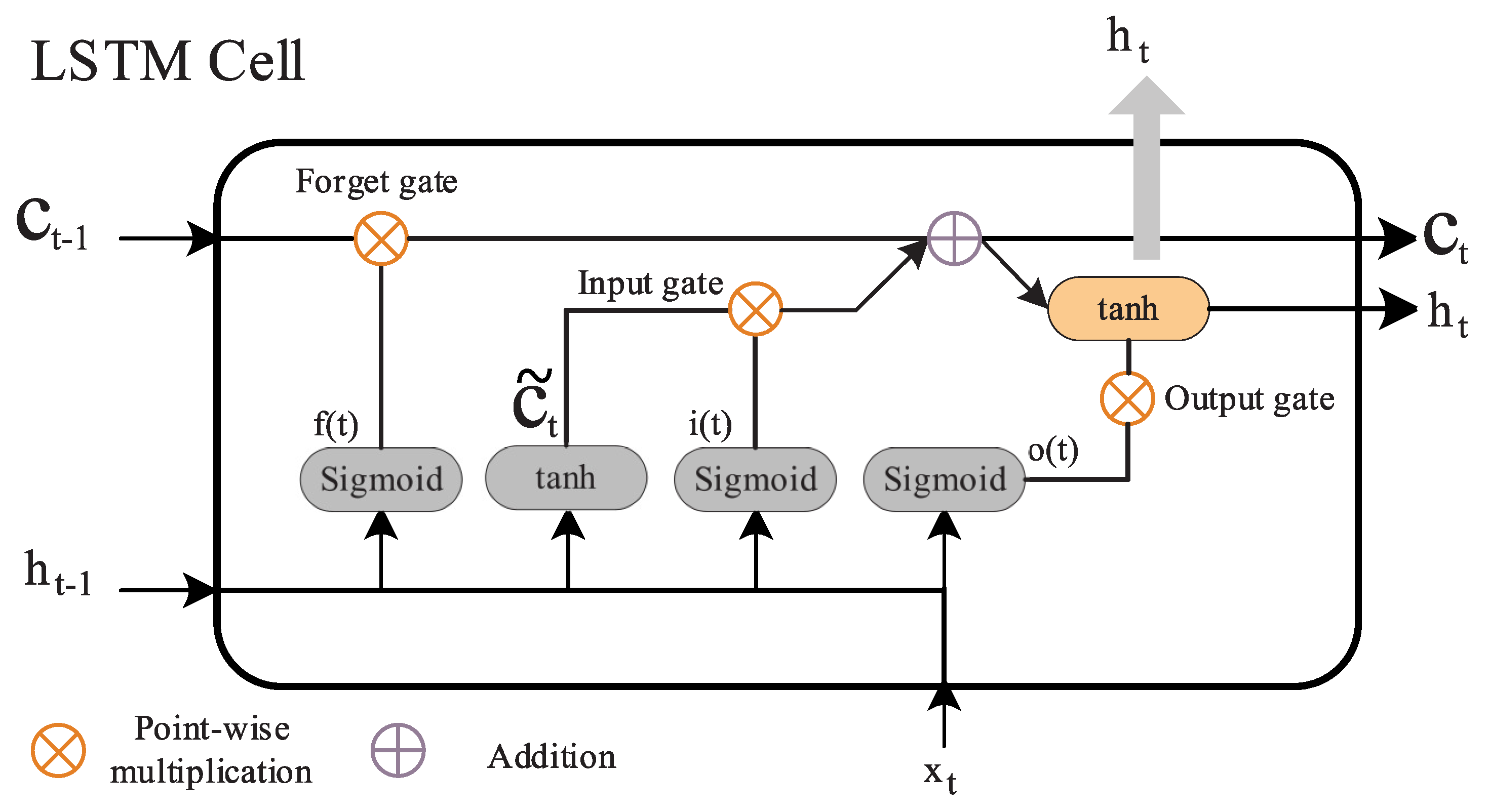
2.2.2. Long-Short Term Memory for Temporal Data
3. Results
3.1. Data Pre-Processing and Augmentation
- Static data (input of the MLP):
- –
- One Hot Encoding of the “State” variable. The State variable is transformed to a binary vector of the same size as the set of states, where a 1 is used for the belonging state and 0 otherwise.
- –
- Min-max scaling: to assign the numeric variables a value between 0 and 1.
- –
- Each static instance is an array of size 760 × 14: 760 municipalities with their respective variables “Latitude”, “Longitude”, “Total area”, “Non-forest area”, “Hydrography” and 9 possible states (PA, MA, TO, RO, AP, MT, AM, AC, RR).
- Temporal data (input of the LSTM network):
- –
- Min-max scaling: to assign the numeric temporal variables a value between 0 and 1.
- –
- The temporal instances values are of size 760 × 6 × window_size-1: 760 municipalities with their respective variables “Deforestation increment”, “Cumulative deforestation”, “Forest area”, “Cloud cover”, “Not observed”, “Check” for window_size-1 years.
- –
- The label Y: the values of “Deforestation increment”, which is the variable to predict, in the window_size year. This will serve to contrast the output of the model with the real values, with the purpose of using supervised learning in the training of the model.
Data Augmentation
- Latitude, Longitude: ±10% of the standard deviation.
- Length: ±10% of the standard deviation.
- Total area: ±30% of the total area, this allows a greater variation in the area to create a sample with small and large municipalities.
- No forest: the proportion with respect to the total area is maintained ±10%.
- Hydrography: the proportion with respect to the total area is maintained ±10%.
- Deforestation increment: the proportion with respect to the total area is maintained ±5%, with this the rest of the temporary variables can be calculated.
3.2. Model Hyper-Parameter Optimization
- Window size: LSTM temporal window size of the input to model the temporal output.
- Number of municipalities: augmented data, according the number of replicas .
- Batch size: number of samples processed before the model is updated.
- Hidden layers: Hidden layers in the MLP.
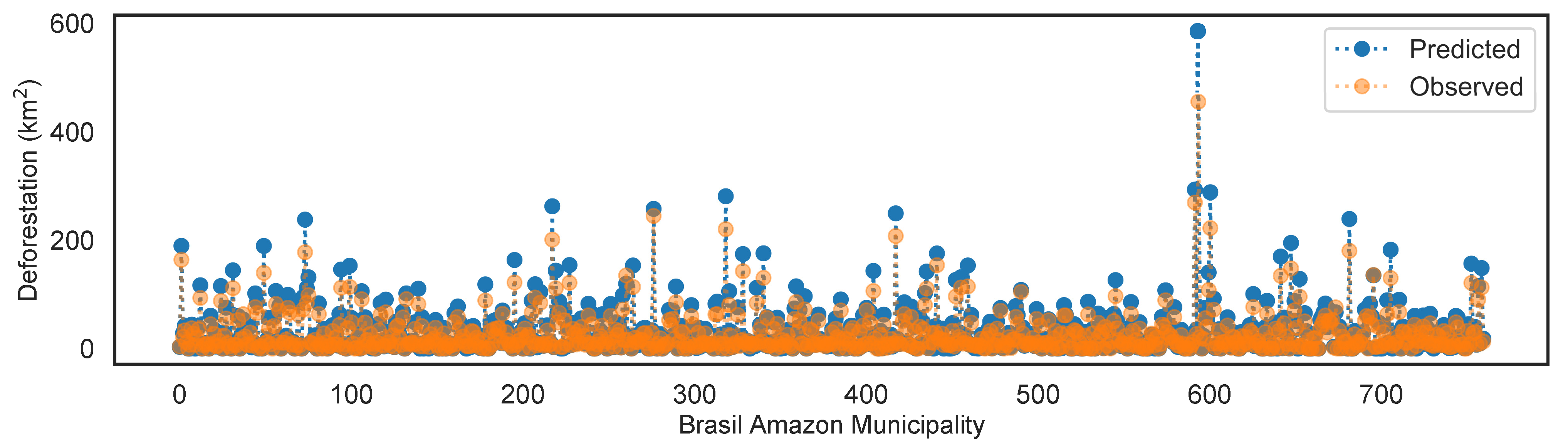
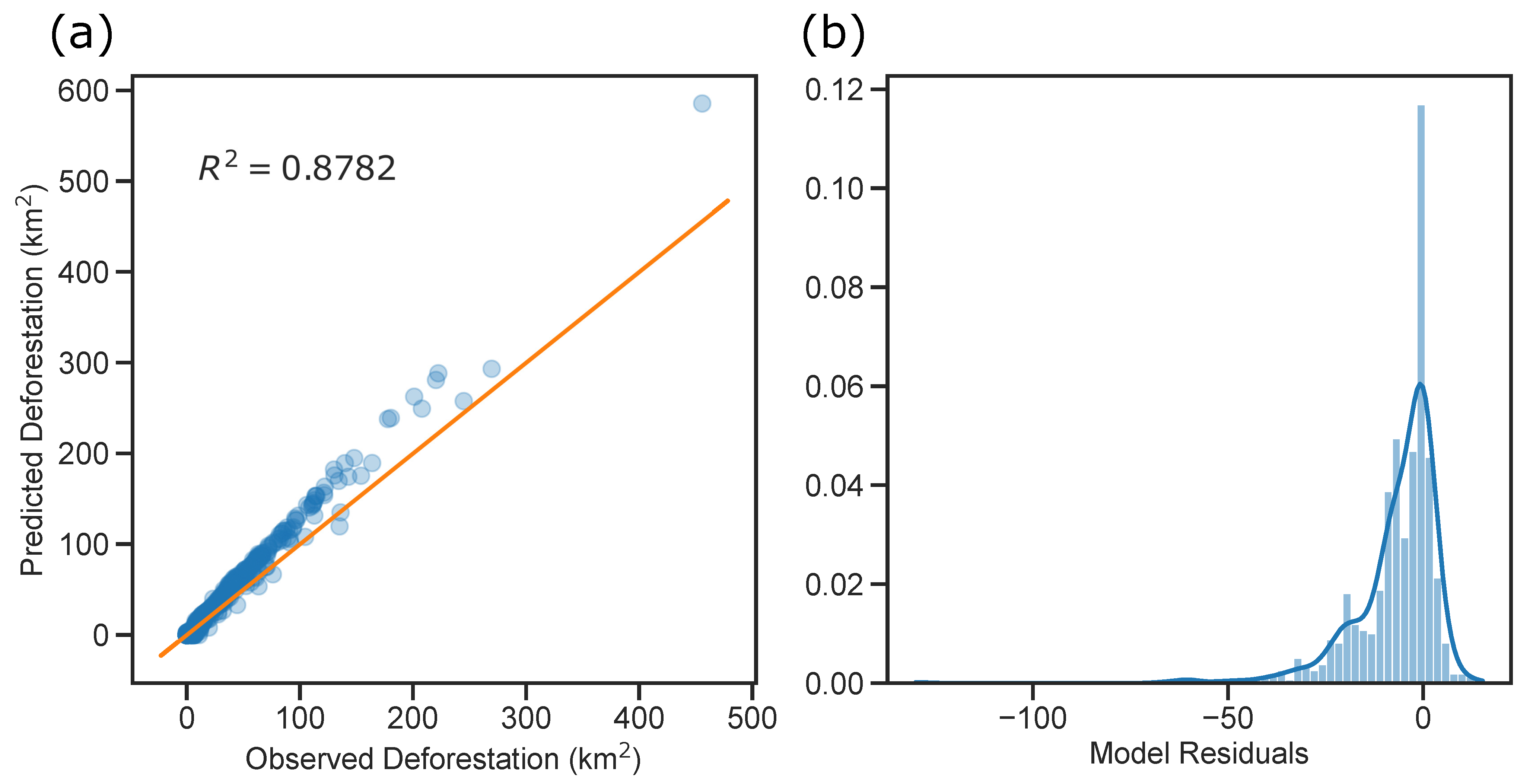
3.3. Model Performance
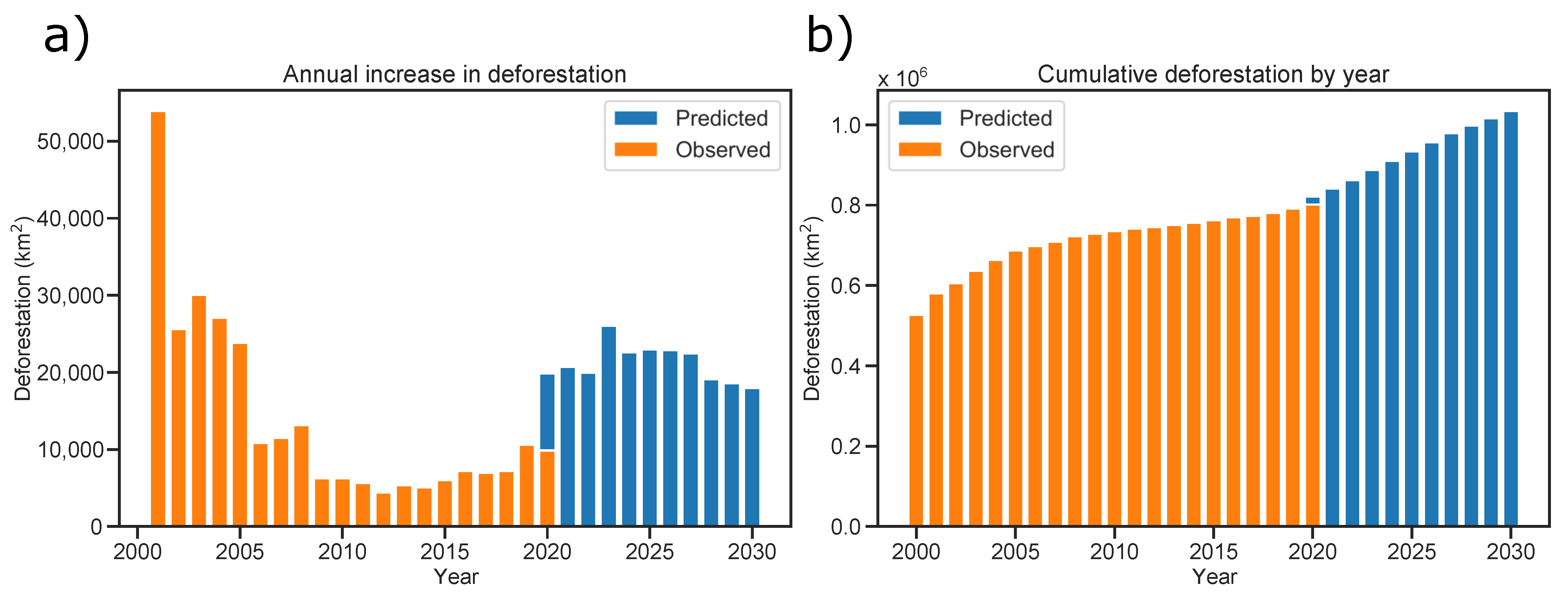
3.4. Deforestation Forecasting
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| LSTM | Long-short term memory |
| MLP | Multilayer perceptron |
| RNN | Recurrent Neural Network |
| R | R-squared score |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| SDGs | Sustainable Development Goals |
References
- Carrasco, L.R.; Le Nghiem, T.P.; Chen, Z.; Barbier, E.B. Unsustainable development pathways caused by tropical deforestation. Sci. Adv. 2017, 3, e1602602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moya-Clemente, I.; Ribes-Giner, G.; Pantoja-Díaz, O. Configurations of sustainable development goals that promote sustainable entrepreneurship over time. Sustain. Dev. 2020, 28, 572–584. [Google Scholar] [CrossRef]
- Miyamoto, M. Poverty reduction saves forests sustainably: Lessons for deforestation policies. World Dev. 2020, 127, 104746. [Google Scholar] [CrossRef]
- United Nations. United Nations Sustainable Development Goal 15. 2018. Available online: https://sdgs.un.org/goals (accessed on 1 December 2021).
- Pacheco, P.; Hospes, O.; Dermawan, A. Zero Deforestation and Low Emissions Development: Public and Private Institutional Arrangements under Jurisdictional Approaches; Center for International Forestry Research: Bogor Regency, Indonesia, 2017. [Google Scholar]
- Mahari, W.A.W.; Azwar, E.; Li, Y.; Wang, Y.; Peng, W.; Ma, N.L.; Yang, H.; Rinklebe, J.; Lam, S.S.; Sonne, C. Deforestation of rainforests requires active use of UN’s Sustainable Development Goals. Sci. Total Environ. 2020, 742, 140681. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Vásquez, M.; Arias, P.A.; Martínez, J.A.; Espinoza, J.C. Effects of Amazon basin deforestation on regional atmospheric circulation and water vapor transport towards tropical South America. Clim. Dyn. 2020, 54, 4169–4189. [Google Scholar] [CrossRef]
- Farias, M.H.C.S.; BeltrÃo, N.E.S.; Santos, C.A.; Cordeiro, Y.E.M. Impact of rural settlements on the deforestation of the Amazon. Mercator 2018, 17, 1–17. [Google Scholar] [CrossRef]
- Nicholson, S.E. Evolution and current state of our understanding of the role played in the climate system by land surface processes in semi-arid regions. Glob. Planet. Chang. 2015, 133, 201–222. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, W.D.; Mustin, K.; Hilário, R.R.; Vasconcelos, I.M.; Eilers, V.; Fearnside, P.M. Deforestation control in the Brazilian Amazon: A conservation struggle being lost as agreements and regulations are subverted and bypassed. Perspect. Ecol. Conserv. 2019, 17, 122–130. [Google Scholar] [CrossRef]
- Reydon, B.P.; Fernandes, V.B.; Telles, T.S. Land governance as a precondition for decreasing deforestation in the Brazilian Amazon. Land Use Policy 2020, 94, 104313. [Google Scholar] [CrossRef]
- Tole, L. Sources of deforestation in tropical developing countries. Environ. Manag. 1998, 22, 19–33. [Google Scholar] [CrossRef]
- Zemp, D.; Schleussner, C.F.; Barbosa, H.; Rammig, A. Deforestation effects on Amazon forest resilience. Geophys. Res. Lett. 2017, 44, 6182–6190. [Google Scholar] [CrossRef] [Green Version]
- González, M.; del Mar Alonso-Almeida, M.; Avila, C.; Dominguez, D. Modeling sustainability report scoring sequences using an attractor network. Neurocomputing 2015, 168, 1181–1187. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [Green Version]
- González, M.; del Mar Alonso-Almeida, M.; Dominguez, D. Mapping global sustainability report scoring: A detailed analysis of Europe and Asia. Qual. Quant. 2018, 52, 1041–1055. [Google Scholar] [CrossRef]
- Wang, K.; Li, K.; Zhou, L.; Hu, Y.; Cheng, Z.; Liu, J.; Chen, C. Multiple convolutional neural networks for multivariate time series prediction. Neurocomputing 2019, 360, 107–119. [Google Scholar] [CrossRef]
- Dominguez, D.; Pantoja, O.; Pico, P.; Mateos, M.; del Mar Alonso-Almeida, M.; González, M. Panama Papers’ offshoring network behavior. Heliyon 2020, 6, e04293. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Gong, C.; Yang, L.; Chen, Y. DSTP-RNN: A dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst. Appl. 2020, 143, 113082. [Google Scholar] [CrossRef]
- Mayfield, H.J.; Smith, C.; Gallagher, M.; Hockings, M. Considerations for selecting a machine learning technique for predicting deforestation. Environ. Model. Softw. 2020, 131, 104741. [Google Scholar] [CrossRef]
- Jaffé, R.; Nunes, S.; Dos Santos, J.F.; Gastauer, M.; Giannini, T.C.; Nascimento, W., Jr.; Sales, M.; Souza, C.M.; Souza-Filho, P.W.; Fletcher, R.J. Forecasting deforestation in the Brazilian Amazon to prioritize conservation efforts. Environ. Res. Lett. 2021, 16, 084034. [Google Scholar] [CrossRef]
- Ortega Adarme, M.; Queiroz Feitosa, R.; Nigri Happ, P.; Aparecido De Almeida, C.; Rodrigues Gomes, A. Evaluation of deep learning techniques for deforestation detection in the Brazilian Amazon and cerrado biomes from remote sensing imagery. Remote Sens. 2020, 12, 910. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.H.; Han, K.J.; Lee, K.; Lee, K.J.; Oh, K.Y.; Lee, M.J. Classification of Landscape Affected by Deforestation Using High-Resolution Remote Sensing Data and Deep-Learning Techniques. Remote Sens. 2020, 12, 3372. [Google Scholar] [CrossRef]
- Brus, J.; Pechanec, V.; Machar, I. Depiction of uncertainty in the visually interpreted land cover data. Ecol. Inform. 2018, 47, 10–13. [Google Scholar] [CrossRef]
- De Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change detection of deforestation in the Brazilian Amazon using landsat data and convolutional neural networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef] [Green Version]
- Maretto, R.V.; Fonseca, L.M.; Jacobs, N.; Körting, T.S.; Bendini, H.N.; Parente, L.L. Spatio-temporal deep learning approach to map deforestation in amazon rainforest. IEEE Geosci. Remote Sens. Lett. 2020, 18, 771–775. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An Experimental Review on Deep Learning Architectures for Time Series Forecasting. arXiv 2021, arXiv:2103.12057. [Google Scholar] [CrossRef] [PubMed]
- Assis, L.F.; Ferreira, K.R.; Vinhas, L.; Maurano, L.; Almeida, C.; Carvalho, A.; Rodrigues, J.; Maciel, A.; Camargo, C. TerraBrasilis: A spatial data analytics infrastructure for large-scale thematic mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 513. [Google Scholar] [CrossRef] [Green Version]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Chauvin, Y.; Rumelhart, D.E. Backpropagation: Theory, Architectures, and Applications; Psychology Press: Hove, UK, 2013. [Google Scholar]
- Sibi, P.; Jones, S.A.; Siddarth, P. Analysis of different activation functions using back propagation neural networks. J. Theor. Appl. Inf. Technol. 2013, 47, 1264–1268. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. JA1 4 rgen Schmidhuber. “Long Short-Term Memory”. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2020, 1–26. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Sirsat, M.S.; Cernadas, E.; Alawadi, S.; Barro, S.; Febrero-Bande, M. An extensive experimental survey of regression methods. Neural Netw. 2019, 111, 11–34. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Static Variables | |||
|---|---|---|---|
| Notation | Variable | Type of Data | Values/Description |
| Municipality | Categorical | Amazon: AM, Roraima: RR, Acre: AC, Rondonia: RO, Mato | |
| Groso: MT, Amapá: AP, Pará: PA, Tocatins: TO, Maranhão: MA. | |||
| Latitude | Numerical | Geographical coordinate | |
| Longitude | Numerical | Geographical coordinate | |
| Total Area | Numerical (km) | Total area of the municipality | |
| Non-forest land area | Numerical (km) | Non-forest land use (i.e., agriculture) | |
| Hydrography area | Numerical (km) | Area covered by rivers and lakes | |
| Temporal Variables | |||
| Notation | Variable | Type of Data | Values/Description |
| Year | Numerical | Temporal index of the data | |
| Deforestation increment | Numerical (km) | Deforestation area that occurred in that year | |
| Cumulative deforestation | Numerical (km) | Total accumulated deforestation area up to that year | |
| Forest area | Numerical (km) | Forest area in that year | |
| Cloud cover | Numerical (km) | Area covered by clouds in that year | |
| Not observed | Numerical (km) | Area not observed in that year | |
| Consistency check | Numerical (km) | Difference between municipality area and all area variables. | |
| State | Forest in 2000 (km) | Forest in 2020 (km) | Forest Lost (km) | Percent Lost |
|---|---|---|---|---|
| MT | 371,093.3 | 302,392.35 | 68,700.95 | 18.51 |
| MA | 68,806.3 | 30,346.30 | 38,460.00 | 55.90 |
| AP | 105,764.7 | 87,863.31 | 17,901.39 | 16.93 |
| RR | 156,588.4 | 88,778.64 | 67,809.76 | 43.30 |
| AM | 1,462,388.9 | 1,343,017.65 | 119,371.25 | 8.16 |
| PA | 944,248.1 | 761,848.27 | 182,399.83 | 19.32 |
| RO | 149,807.7 | 117,760.03 | 32,047.67 | 21.39 |
| TO | 10,755.7 | 9975.25 | 780.45 | 7.26 |
| AC | 154,785.5 | 129,185.17 | 25,600.33 | 16.54 |
| Year | Deforestation Increment (km) | Cumulative Deforestation (km) |
|---|---|---|
| 2001 | 53,925.0 | 53,925.0 |
| 2002 | 25,607.0 | 79,532.0 |
| 2003 | 30,076.0 | 109,608.0 |
| 2004 | 27,082.0 | 136,690.0 |
| 2005 | 23,852.0 | 160,542.0 |
| 2006 | 10,834.0 | 171,376.0 |
| 2007 | 11,480.0 | 182,856.0 |
| 2008 | 13,173.0 | 196,029.0 |
| 2009 | 6253.0 | 202,282.0 |
| 2010 | 6252.0 | 208,534.0 |
| 2011 | 5659.0 | 214,193.0 |
| 2012 | 4401.0 | 218,594.0 |
| 2013 | 5373.0 | 223,967.0 |
| 2014 | 5100.0 | 229,067.0 |
| 2015 | 6042.0 | 235,109.0 |
| 2016 | 7225.0 | 242,334.0 |
| 2017 | 6955.0 | 249,289.0 |
| 2018 | 7193.0 | 256,482.0 |
| 2019 | 10,608.0 | 267,090.0 |
| 2020 | 9858.0 | 276,948.0 |
| 2020 | 19,852.94 | 19,852.94 |
| 2021 | 20,693.28 | 40,546.22 |
| 2022 | 19,957.98 | 60,504.20 |
| 2023 | 26,050.42 | 86,554.62 |
| 2024 | 22,584.03 | 109,138.65 |
| 2025 | 23,004.20 | 132,142.85 |
| 2026 | 22,899.16 | 155,042.01 |
| 2027 | 22,478.99 | 177,521.00 |
| 2028 | 19,117.65 | 196,638.65 |
| 2029 | 18,592.44 | 215,231.09 |
| 2030 | 17,962.18 | 233,193.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dominguez, D.; del Villar, L.d.J.; Pantoja, O.; González-Rodríguez, M. Forecasting Amazon Rain-Forest Deforestation Using a Hybrid Machine Learning Model. Sustainability 2022, 14, 691. https://doi.org/10.3390/su14020691
Dominguez D, del Villar LdJ, Pantoja O, González-Rodríguez M. Forecasting Amazon Rain-Forest Deforestation Using a Hybrid Machine Learning Model. Sustainability. 2022; 14(2):691. https://doi.org/10.3390/su14020691
Chicago/Turabian StyleDominguez, David, Luis de Juan del Villar, Odette Pantoja, and Mario González-Rodríguez. 2022. "Forecasting Amazon Rain-Forest Deforestation Using a Hybrid Machine Learning Model" Sustainability 14, no. 2: 691. https://doi.org/10.3390/su14020691
APA StyleDominguez, D., del Villar, L. d. J., Pantoja, O., & González-Rodríguez, M. (2022). Forecasting Amazon Rain-Forest Deforestation Using a Hybrid Machine Learning Model. Sustainability, 14(2), 691. https://doi.org/10.3390/su14020691