1. Introduction
Remote sensing images can provide inexpensive, fine-scale information with multi-temporal coverage which has proven to be useful in terms of urban planning, land-cover mapping, and environmental monitoring. To enable high-resolution satellite image interpretation, it is important to label image pixels with their semantic classes. Intensive studies have been conducted in high-resolution image classification and labeling [
1,
2,
3]. Pixel-based image classification methods were initially developed to label each pixel for the entire image, with methods such as the maximum likelihood classifiers (MLC) or support vector machine (SVM). In order to obtain more accurate classification results, it is common to apply representative feature extraction techniques (such as gray-level co-occurrence matrix (GLCM) [
4] or morphological attribute profiles (MAPs) [
5,
6]) as standard preprocessing steps. However, due to the variability in high-resolution images, it is difficult to find robust and representative feature representations for efficient image classification [
7,
8]. In addition, the pixel-based classification methods suffer from the salt-and-pepper phenomenon, since they overlook the rich spatial information of the high-resolution images.
In order to utilize the rich spatial information and improve classification performance, object-based image classification methods [
9,
10] have been intensively investigated. Instead of directly classifying the whole image in a pixel-wise fashion, the object-based methods effectively interpret the complex high-resolution images in terms of image segments. More specifically, the object-based methods first split an image into several homogeneous objects and then infer the semantic label of each segment by applying a majority voting strategy. Thus, it overcomes the salt-and-pepper defect characteristic of pixel-based methods. However, it is difficult to accurately segment complex scenes into meaningful parts, due to the complexity of high-resolution remote sensing images. For example, building roofs are frequently segmented into shadowed areas, small objects (such as chimneys, windows) etc., Alternatively, graph-based random field methods have been used to interpret high-spatial resolution images by considering spatial interactions between neighboring pixels. As a representative, the Markov random fields (MRF) was first introduced as the graph-based image analysis method and has been successfully applied in remote sensing image classification [
11,
12]. But, the MRF is a generative model that only considers joint distributions in the label domain. To improve the performance of MRF, a technique known as conditional random fields (CRF) was proposed to directly model the posterior distribution by considering the joint distribution of both the label and observed data domain at the same time [
13]. In other words, the potential functions in CRF-based algorithms are designed to measure the trade-off between spectral and spatial contextual cues. For instance, the support vector conditional random field classifier [
14,
15] was widely used to incorporate spatial information at the pixel-level which effectively overcomes the salt-and-pepper classification noise. Moreover, in order to improve the processing efficiency of high-resolution image classification, the object-based CRF model [
16,
17] was proposed and has successfully been used to classify images.
Although object- and graph-based image interpretation strategies have already been successfully applied in many applications, the challenges of accurate high-resolution image classification yet to be treated. There are two factors that heavily impact the traditional image classification accuracies: (1) The representations of complex geographical objects, (2) Contextual information utilization. For the first one, low-level feature descriptors often fail to represent complex geographical objects, due to the spectral variabilities of high-resolution images. For instance, building roofs in an urban area often contain antennas, chimneys, and shadows. Moreover, the traditional feature descriptors which only consider the spectral distribution, shape or texture of neighboring pixels and suffer from the variable nature of high-resolution imagery. Besides, the object- or graph-based models that built on heterogeneously low-level features are often too fragmented to depict accurate contours of complex geographical objects, let alone capture high-level contextual information. Therefore, we integrated the CNN-based deep features with low-level image segments, thus produce meaningful semantic segments which accurately capture geographical objects. In addition, we propose a graph-based class co-occurrence model in order to capture the rich contextual information in high-resolution images. More specifically, we investigated a convolutional neural network (CNN) with five layers to explore robust deep features which later have been used to generate semantic segments. Since geographical objects already can be accurately described by semantic segments, we further construct a semantic graph in order to get a better grasp of the contextual information in high-resolution images. Last but not least, we further proposed a higher-order co-occurrence CRF model (HCO-CRF) in addition to semantic segments in order to improve image classification accuracy.
The rest of paper is organized as follows: The related work such as CNN framework and the traditional CRF model is briefly introduced in
Section 2. Then, the HCO-CRF model with considering class dependencies and label HCO-occurrences is presented in
Section 3. In
Section 4, the experimental setting, results, and analysis are illustrated. Finally, the conclusion is presented in
Section 5.
3. Proposed Method
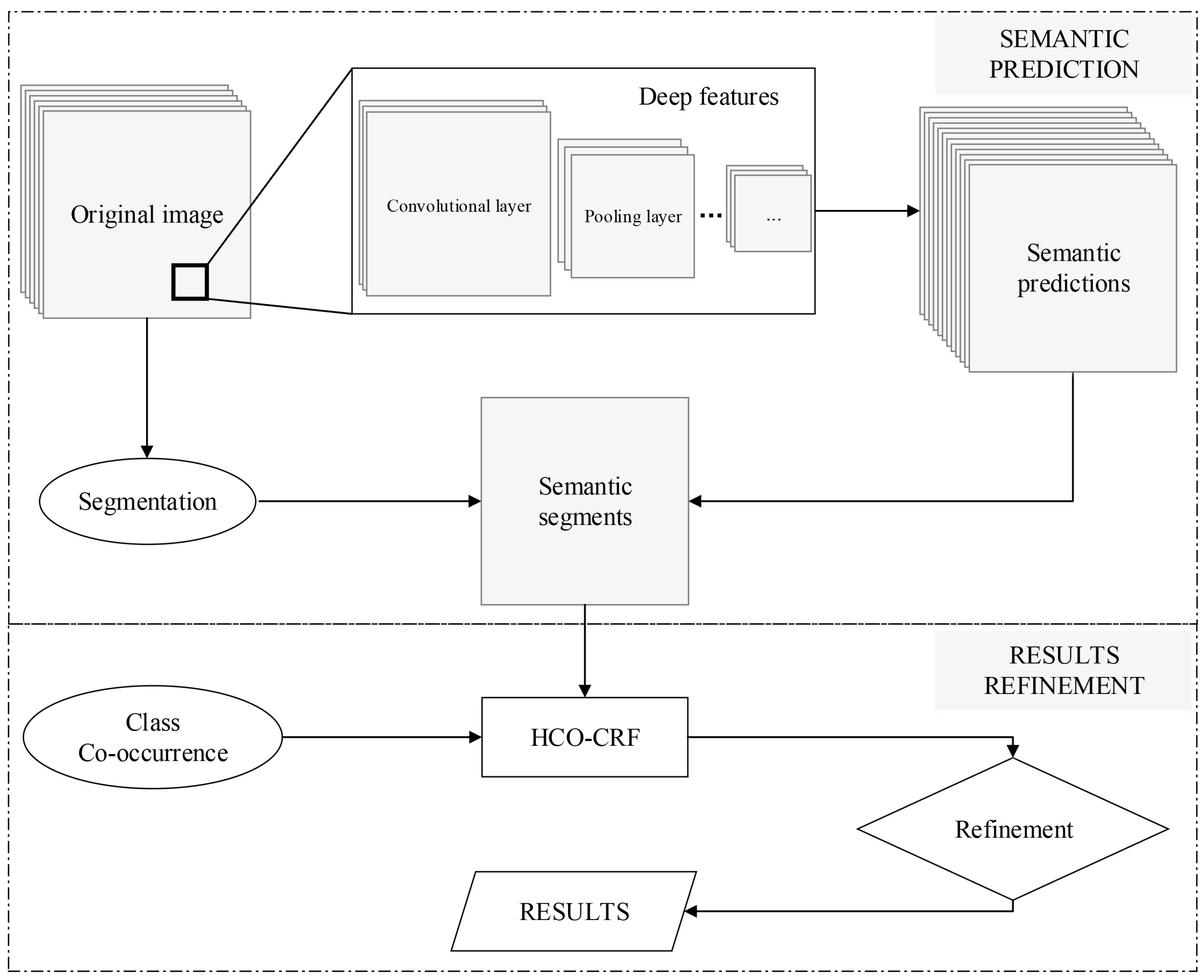
In this section, we build a higher-order co-occurrence graph model with the help of a semantic segmentation strategy. The proposed method is mainly constituted by two processing stages, i.e., semantic prediction and results refinement, as shown in
Figure 1. For the process of semantic prediction, a CNN with five layers was trained using the reference dataset. After the training stage, the well-trained CNN can be directly applied to predict semantic labels for each pixel of the original image. Meanwhile, the predicted results of pixels were integrated with segments generated by the image segmentation algorithm. The integration of segments and semantic prediction results will produce semantic segments which are initial probabilistic per-class labeling predictions for each geographical object. Then, for the results refinement, the higher-order graph model can be constructed on top of semantic segments. It effectively formulates contextual information that could be further utilized to correct false predictions with the help of class co-occurrences and dependencies.
3.1. Semantic Segmentation with CNN
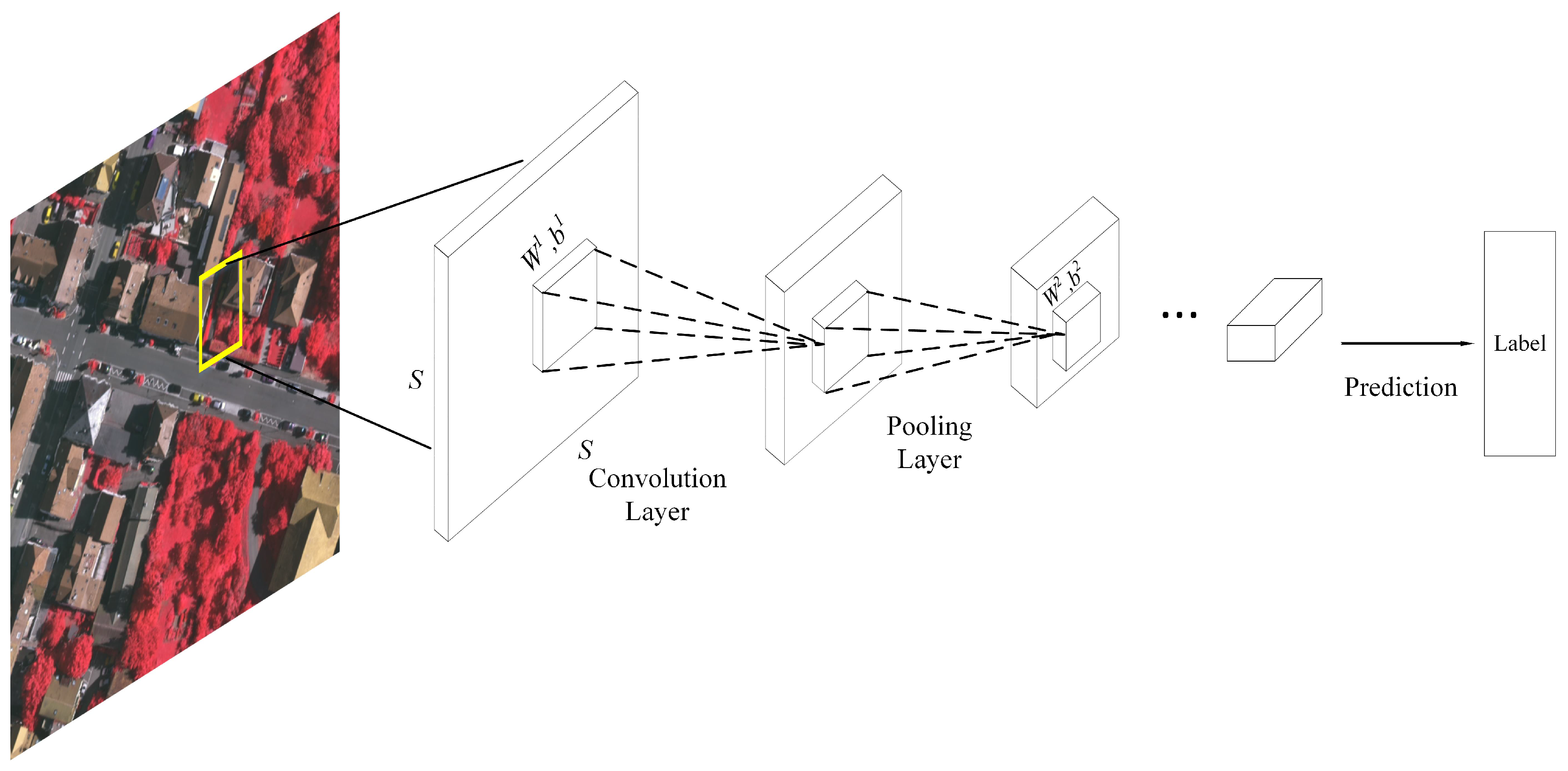
In this study, in order to obtain deep and robust feature representations of high-resolution imagery, we proposed an
L-layer convolutional neural network, as shown in
Figure 2. Given an image
I and its corresponding reference map
R. Since the CNN only feeds using square image patches, we split the input image
I using a fixed square window with the sizes of
with having targeted pixel in the center. For a pixel
i in the original image, the extracted image patch can be represented as
and its label
obtained from the reference map. Before CNN can be used to extract deep features, two types of trainable parameters should be determined, i.e., convolutional filters
and the biases
. Before training, we initialized all parameters with a zero mean and variance [
24]. For the process of the feed-forward pass, the output of
th,
layer is given by
here,
ℓ denotes the current layer, the output activation function
is usually chosen to be the hyperbolic tangent function
. For a multi-class problem with
c classes and
N training samples. The square-loss function used for CNN training can be written as
where
denotes the final output of the
th layer CNN framework. In order to minimize the loss function, the back-propagation algorithm is applied.
Although the extracted deep features are able to describe complex image patterns, the interspersed geographic objects in high-resolution images are still unreachable, due to the large gap between pixels and geographical objects. Meanwhile, the object-based image classification method bridges the gap between image pixel and geographical objects for high-resolution imagery interpretation. Instead of using low-level image features, we segment the heterogeneous imagery with the extracted deep features, in order to obtain meaningful semantic segments (segments with semantic labels). For pixel
in the original image, the extracted deep feature vector has the form of
. Then, we use the graph-based image segmentation algorithm to split the whole image
into
N image segments using deeply extracted image features. Each image segment can be represented as
, and, there are
M pixels
inside each image object
. Thus, each image segment only has one significant semantic label.
3.2. Contextual Refinement with HCO-CRF
Once the high-resolution image is delineated into meaningful regions, the complex geographical objects can be easily represented by semantic segments. As mentioned above, contextual information is vital for successful image labeling and understanding. Meanwhile, class co-occurrences as one of the most popular contextual feature descriptors in image classification has been widely used to exploit the contextual information, especially for high-resolution images [
25]. Instead of using pixel-based CRF models, we constructed the segment-based CRF model with semantic segments. In the segment-based CRF model, each node represents a semantic segment. The weights of the neighboring matrix for segment-based CRF are determined by shared boundaries between adjacent semantic segments. In this way, the segment-based CRF model can effectively alleviate the phenomenon of local minima since it exploits contextual information at larger scales. At the same time, the usage of co-occurrence correction in the post-processing stage increased the label consistency between semantic segments also avoid the local minimum.
Instead of pixel-based CRF, we use semantic segments as the building blocks of the segment-based CRF. Therefore, the unary term potential for a semantic segment
which contains
K image pixels can be formulated as
where
is the label of the semantic segment
, and
represents the extracted deep features from the CNN framework.
is the output function with soft-max classifier which is given by
. In this unary potential, each semantic segment consists of a different number of image pixels. Therefore, the unary potentials of semantic segments are the sum of their pixels’ unary cost. Similarly, the pairwise potentials of Co-CRF have the form of
here,
and
are two averaged deep features which are located in semantic segments
and
, respectively. Therefore, the entire cost function of the traditional CRF can be formulated as
However, the contextual information which is a key condition for accurate image labeling, which still remains to be exploited. In order to improve the accuracy of image classification, the co-occurrence of considering neighboring regions is naturally integrated with pairwise potentials. At the same time, class co-occurrence as prior information could easily be acquired from reference maps. To calculate the class co-occurrence, instead of using image segments, we count the adjacent pixels and their labels bilaterally through training images. As a result, the neighboring co-occurrence matrix of
can be built on sample statistics. Let
denote the number of co-existing labels of
k and
l, where both
. Thus, the frequency of co-occurrence labels
is
, where
represents the number of all possible co-occurrence label pairs. Based on the co-occurrence matrix, we can rewrite CRF pairwise potentials form
Although the revised CRF algorithm incorporates pairwise potentials and the label co-occurrence cost that fit the prior knowledge, the contextual information that lies in larger scale ranges still remain unexploited. In order to formulate the class-dependencies at larger scales, it is important to introduce the higher-order co-occurrence CRF (HCO-CRF) model, as shown in
Figure 3. Different from the traditional CRF, the HCO-CRF captures class co-occurrences on top of semantic segments and avoids the ambiguities by incorporating higher-level context. An additional regulation term that describes higher order cliques has been added to the co-occurrence CRF model. Therefore, the formulation of HCO-CRF can be written as
Here,
T represents the set of semantic segments obtained from the process of semantic segmentation, and, the term
denotes higher order potentials which are defined over the segments. In order to formulate higher order terms, the
Potts potential has been widely applied. It formulates as
The is the number of pixels inside of the segment that take different labels from the dominant label. Meanwhile, the counts the number of pixels inside of the segment. Q is the truncation parameter that controls the heterogeneity inside of the segment. In our experiments, the parameters Q and can be determined by applying cross-validation. Finally, the expansion algorithm is applied to minimize the cost function in an iterative way.
5. Discussion
5.1. Semantic Segments Extraction
In order to extract semantic information from the high-resolution remote sensing imagery, it is important to design accurate classification procedures to perform image labeling. At the same time, image features representatively describe the characteristics of image targets. Based on the effective descriptions of the image pattern, image targets with distinctive characters can be effectively discriminated. However, as the spatial resolution gets finer, traditional feature representations may not be distinctive enough to differentiate image targets with similar patterns, e.g., building roofs and road surface with similar materials. In this regard, we introduced a deep learning strategy to extract more robust and representative features from higher conceptual levels. To be specific, the convolutional neural network (CNN) was applied to automatically generate hierarchical features by feeding square-sized image patches. For the conventional CNN, it usually consists of convolutional layers and pooling layers. For the convolutional layer, numbers of image filters with learnable parameters are stacked together to perform image filtering. Given the outputs of the convolutional layer, the pooling layer directly shrinks the sizes of the output feature maps and further strengthen the robustness of the extracted features. Compare to the traditional image feature representations, the extracted deep features are much more effective in terms of exploiting the small differences. Therefore, we applied the CNN model to perform dense labeling of high-resolution imagery. Still, the classification results of the CNN model suffers from the spatial information loss and “salt–pepper” noise. Moreover, the classification results in mere pixel-level labeling which has no access to geographical entities. To extract semantic information from high-resolution imagery, it is necessary to map the targets at the object level. In this study, instead of using CNN to directly predict the semantic information of each pixel, we integrated the results of dense labeling and image segments. In this way, spatial information about geographical targets can be kept intact. For each image segment, the simple majority vote is applied to determine the semantic label of the segment. As a result, the high-resolution image is delineated into semantically uniform regions that each part represents a geographical target. Based on the results of semantic segmentation, rich semantic information of the high-resolution image can be automatically extracted.
5.2. Higher-Order Contextual Formulation
Given the results of semantic segmentation, it is easy to access the semantic contents of the high-resolution images. Although, the classification accuracy of the CNN-based method is usually higher than the conventional pixel- or object-based methods, still, small errors are frequently observed from CNN-based classification results. For instance, road surfaces may share similar texture or spatial patterns with building roofs which make classifiers difficult to distinguish them from each other. The reason for this phenomenon is that the CNN model is only fed with a square window that neglected the global context. To better grasp the contextual information, post-processing models such as CRF are one way to formulate the image context. CRF mainly exploits the prior knowledge such as the fact that nearby pixels (in the spatial or feature domain) likely share the same semantic label. The standard CRF model usually consists of unary and pairwise terms in a fashion of 4- or 8-connected neighborhood. With the help of the CRF model, the classification results of the high-resolution image can be further improved. For one thing, the pixel-based classification refinement often suffers from “salt-pepper” noise, therefore, it is necessary to build a CRF model on top of image segments. Image segments can capture richer contextual information than a single pixel. Also, the computational costs can be greatly reduced if one considers pairwise interactions between image segments rather than pixels. For another, the conventional CRF model only formulates the local pairwise potentials that capture interactions between pairs of image pixels or segments. Thus, the conventional CRF model works like a smoother at the local range and neglect the long-range context of the high-resolution image. To capture more contextual information at longer ranges, we formulated the CRF model with a higher order potential. It directly captures the interactions over cliques larger than just two nodes. Therefore, it provides a better way to model the co-occurrences between geographical objects and further improving classification results.
6. Conclusions
In this paper, we proposed a graph-based model to classify high-resolution images by considering higher-order co-occurrence information. To be more specific, instead of using low-level image features, we investigated the CNN-based deep features for image semantic segmentation. Then, based on the extracted semantic segments, we utilized the graph-based CRF model to capture the contextual information for better classification results. At last, we further improved the CRF-based classification results by considering higher-order co-occurrences between different geographical objects. In order to illustrate the effectiveness of the proposed method, we compared the HCO-CRF method with other commonly used high-resolution image classification methods. The classification results indicate that the HCO-CRF method can effectively refine classification based on the co-occurrence of different classes. However, the parameter of the co-occurrence matrix should be defined in prior to the loss function minimization done during the training process of the HCO-CRF training. In future research, the quantitative measurements over geographical objects, such as co-occurrences and spatial relationships should be thoroughly studied.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}