Building Extraction in Very High Resolution Imagery by Dense-Attention Networks


 , and
, and 
Abstract
:
1. Introduction
2. Related Works
2.1. Semantic Segmentation of Remote-Sensing Images
2.2. Attention Mechanism
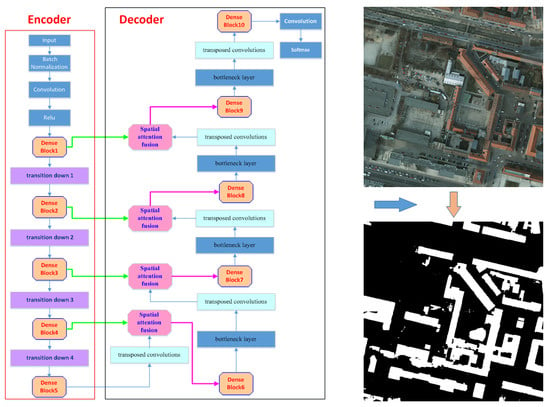
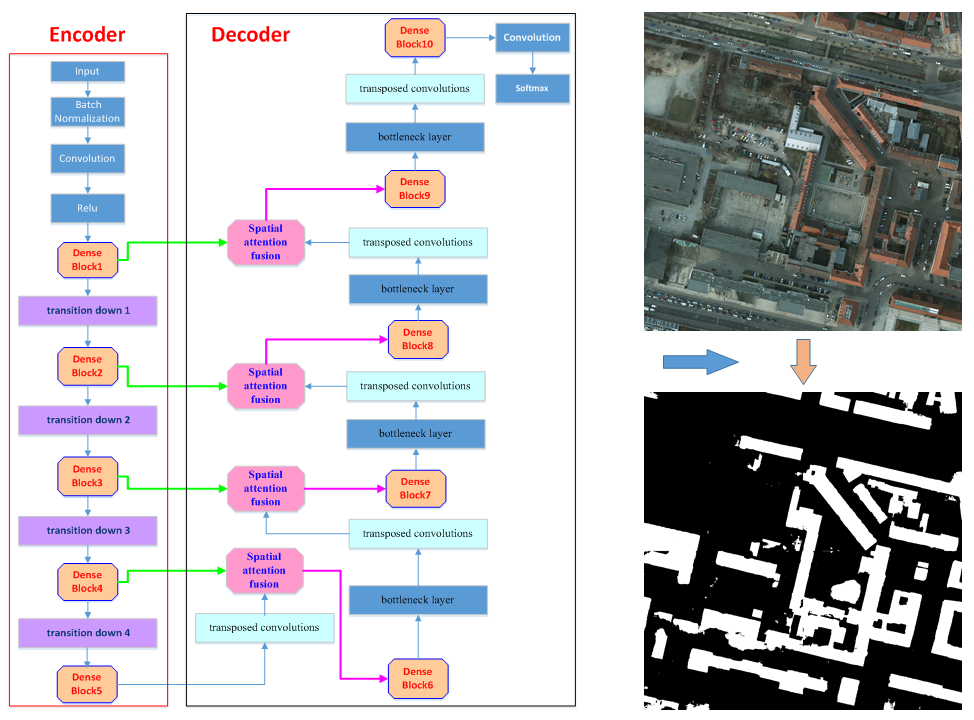
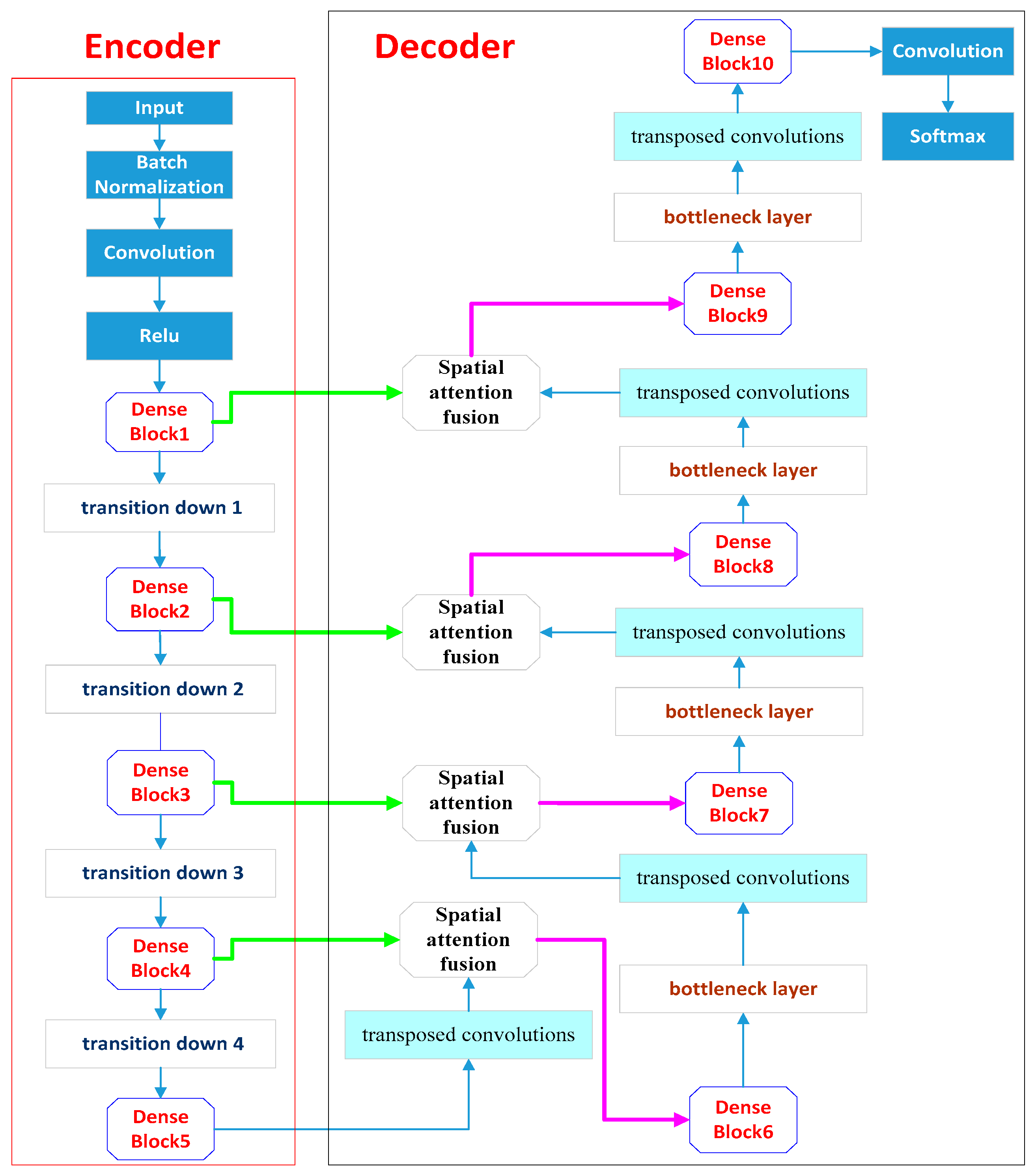
3. Methods
3.1. Lightweight DenseNets
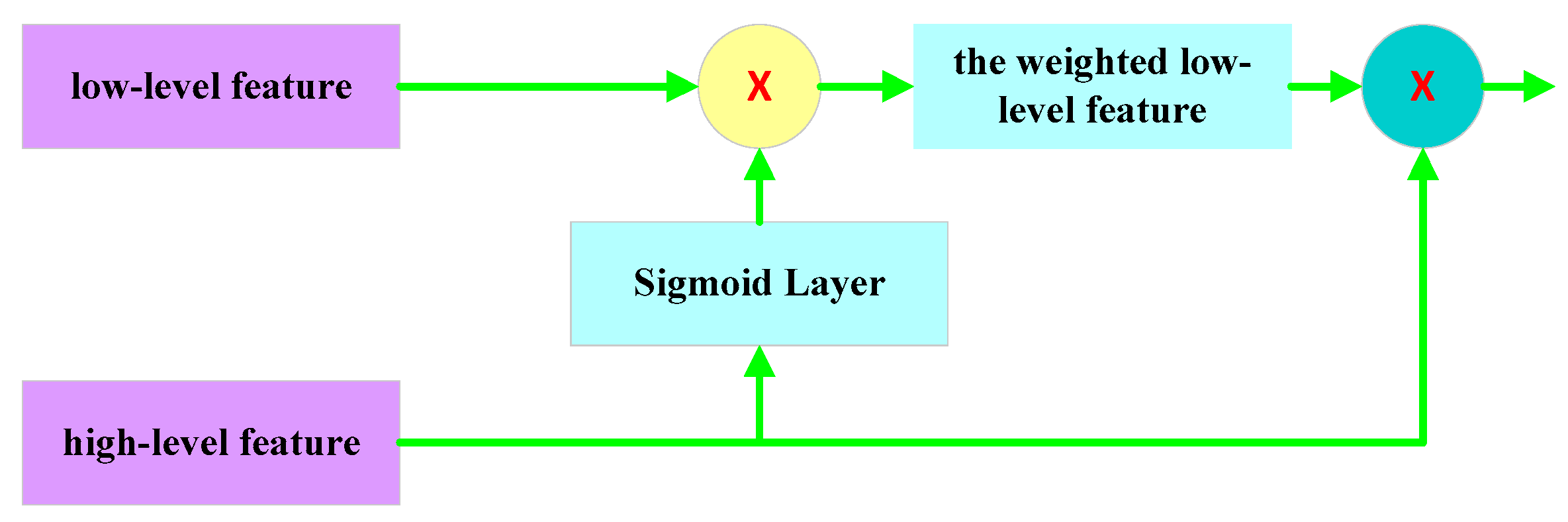
3.2. Spatial Attention Fusion Module
3.3. The Architecture’s Decoder Part
4. Experiments
4.1. Training Details
4.1.1. Dataset
4.1.2. Dataset Preprocessing
4.1.3. Implementation Details
4.1.4. Evaluation
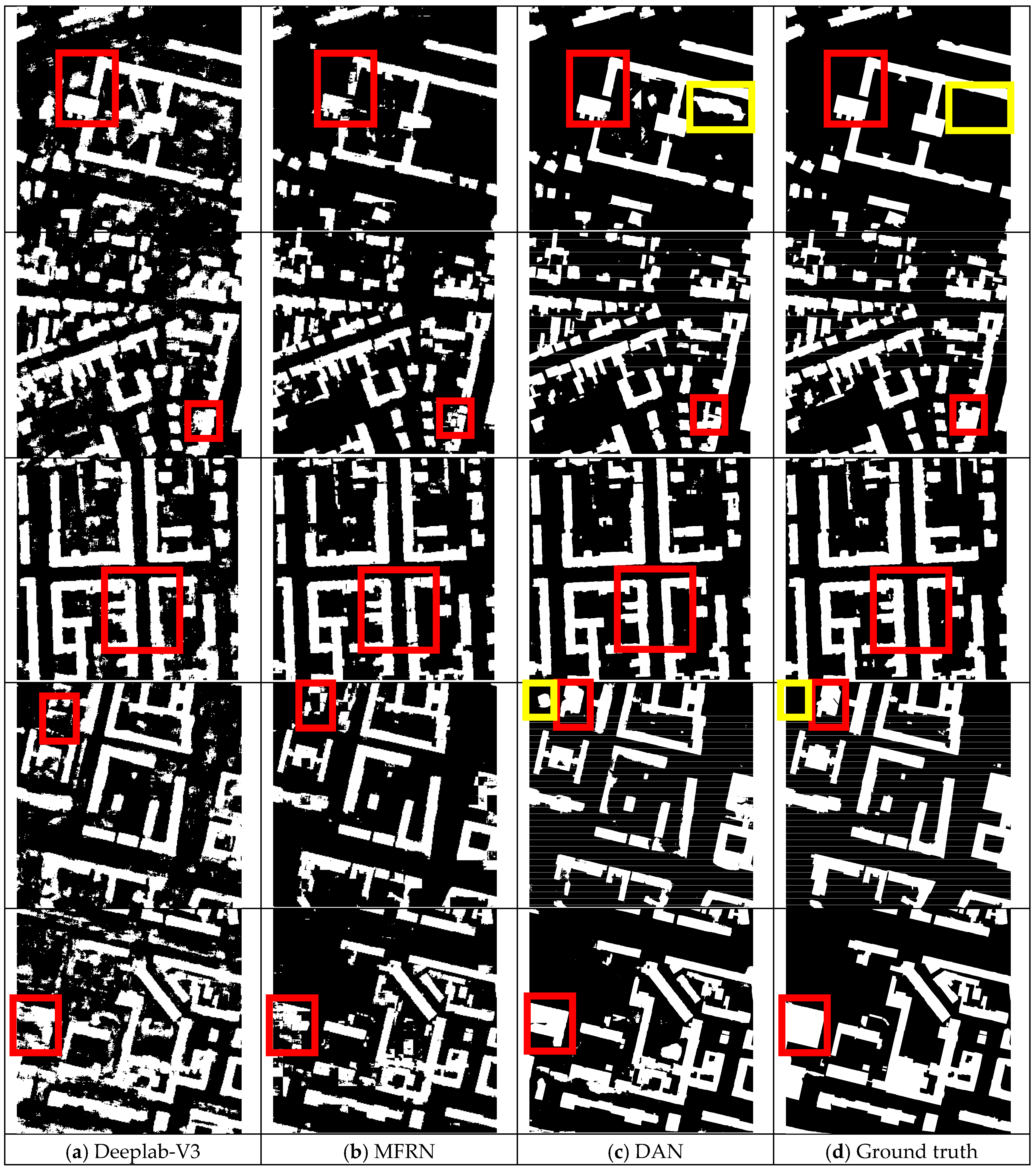
4.2. Extraction Results
4.3. Comparisons with Related Networks
5. Discussion
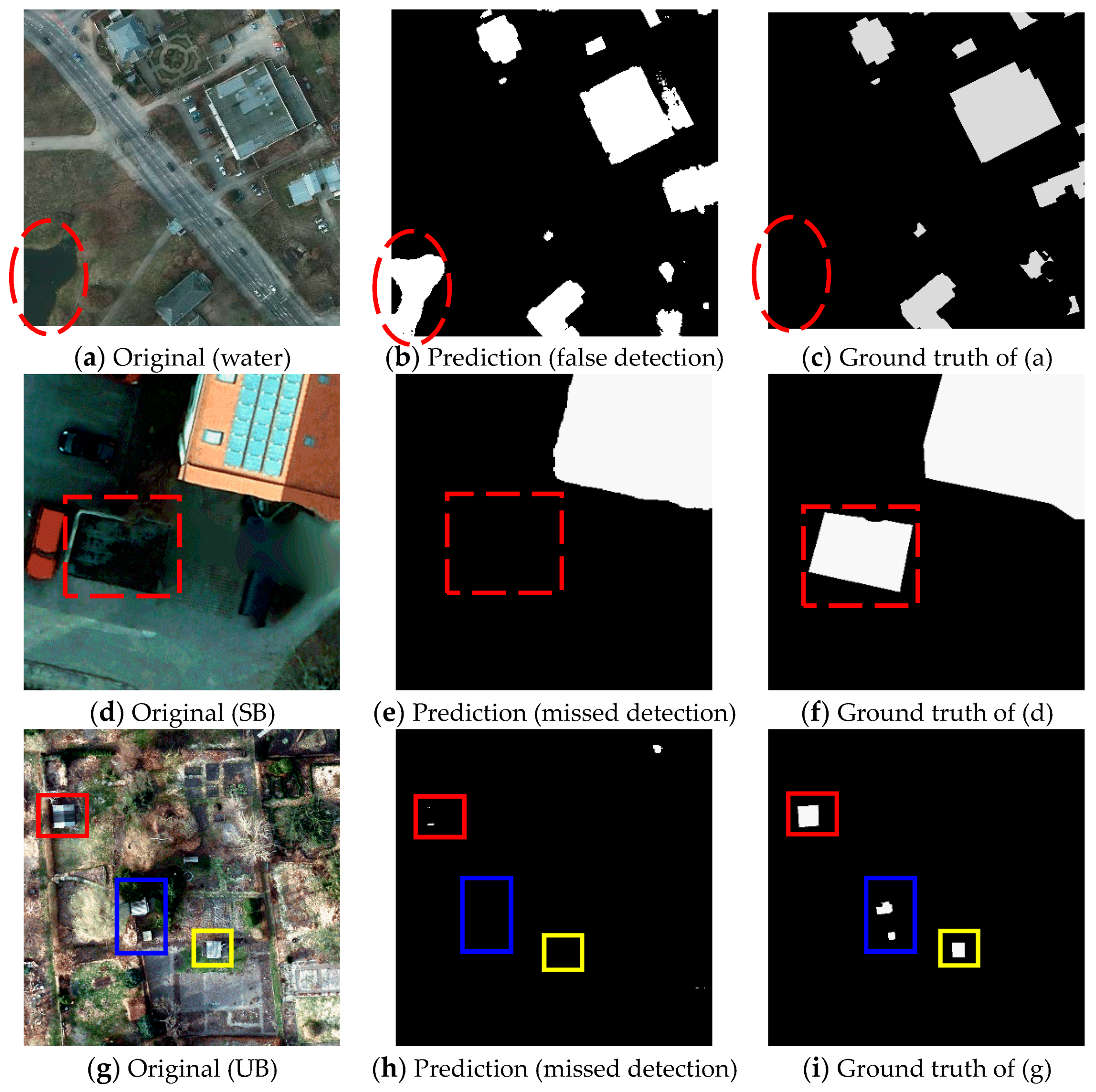
- Complex background. Although water, bare, and sparse vegetation are in the minority in some test samples, they were also detected as buildings because of the similar hue to the foreground object (building), see Figure 6c,d (yellow boxes). The complex background may cause precision to be lower than recall, see the evaluation result of dataset 1 in Table 1. In addition, the water was not included into the above six land cover classes, which makes it difficult to fully learn the characteristics of the complex background, see Figure 7a–c. The misclassification may be a main limitation of the proposed DAN.
- Special buildings (SB). In some training samples, the characteristics (such as color, texture, and material) of a few buildings’ roofs were quite different from most buildings. Moreover, the shape of some buildings that were covered by trees could not be detected precisely, and some blurry and irregular boundaries were hardly classified. Therefore, it was hard to detect these buildings, see Figure 7d–f.
- Unremarkable buildings (UB). In most training samples, when compared to the background, the foreground objects were very distinct. However, in some of the test samples, a few images were covered with large amounts of bare and sparse vegetation, and small-sized buildings. These small-sized buildings were displayed in patchy distributions and were even hard to detect with the naked eye, which added to the difficulty of detection, see Figure 7g–i.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single vhr multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.J.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral geoeye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Jin, X.; Davis, C.H. Automated building extraction from high-resolution satellite imagery in urban areas using structural, contextual, and spectral information. EURASIP J. Appl. Signal Process. 2005, 14, 745309. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Automatic building extraction in dense urban areas through geoeye multispectral imagery. Int. J. Remote Sens. 2014, 35, 5094–5119. [Google Scholar] [CrossRef]
- Du, S.; Zhang, Y.; Zou, Z.; Xu, S.; He, X.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogramm. Remote Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; Romero-Soriano, A.; Gatta, C.; Camps-Valls, G.; Lagrange, A.; Saux, B.L.; Beaupere, A.; Boulch, A.; Chan-Hon-Tong, A.; Herbin, S.; et al. Processing of extremely high-resolution lidar and rgb data: Outcome of the 2015 ieee grss data fusion contest—Part A: 2-D contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 9, 5547–5559. [Google Scholar] [CrossRef]
- Vo, A.V.; Truong-Hong, L.; Laefer, D.F.; Tiede, D.; d’Oleire-Oltmanns, S.; Baraldi, A.; Shimoni, M.; Moser, G.; Tuia, D. Processing of extremely high resolution LiDAR and RGB data: Outcome of the 2015 IEEE GRSS data fusion contest—Part B: 3-D contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5560–5575. [Google Scholar] [CrossRef]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. An automatic building extraction and regularisation technique using lidar point cloud data and orthoimage. Remote Sens. 2016, 8, 258. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Aljumaily, H.; Laefer, D.F.; Cuadra, D. Urban point cloud mining based on density clustering and MapReduce. J. Comput. Civ. Eng. 2017, 31, 04017021. [Google Scholar] [CrossRef]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 906–919. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. In Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Sun, Y.; Zhang, X.; Zhao, X.; Xin, Q. Extracting Building Boundaries from High Resolution Optical Images and LiDAR Data by Integrating the Convolutional Neural Network and the Active Contour Model. Remote Sens. 2018, 10, 1459. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 60. [Google Scholar] [CrossRef]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar]
- Bittner, K.; Cui, S.; Reinartz, P. Building extraction from remote sensing data using fully convolutional networks. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, ISPRS Hannover Workshop, Hannover, Germany, 6–9 June 2017; pp. 481–486. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for scene segmentation. arXiv, 2016; arXiv:1511.00561v3. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. arXiv, 2016; arXiv:1611.06612. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sens. 2018, 10, 1350. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Yang, Y.; Zhong, Z.; Shen, T.; Lin, Z. Convolutional neural networks with alternately updated clique. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2413–2422. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017; arXiv:1706.05587v3. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. Cmputer Sci. 2015, arXiv:1502.03044. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 21–29. [Google Scholar]
- Chen, K.; Wang, J.; Chen, L.C.; Gao, H.; Xu, W.; Nevatia, R. Abc-cnn: An attention based convolutional neural network for visual question answering. arXiv, 2015; arXiv:1511.05960v2. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4507–4515. [Google Scholar]
- Kuen, J.; Wang, Z.; Wang, G. Recurrent attentional networks for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3668–3677. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv, 2018; arXiv:1709.01507v2. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv, 2018; arXiv:1805.10180v2. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar]
- Golnaz, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 519–534. [Google Scholar]
- Pleiss, G.; Chen, D.; Huang, G.; Li, T.; Laurens, V.D.M.; Weinberger, K.Q. Memory-efficient implementation of densenets. arXiv, 2017; arXiv:1707.06990v1. [Google Scholar]
- Awrangjeb, M.; Fraser, C.S. An Automatic and Threshold-Free Performance Evaluation System for Building Extraction Techniques from Airborne LIDAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4184–4198. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Audebert, N.; Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Validation Datasets | OA (%) | F1 Score (%) | MIOU (%) | Precision | Recall |
|---|---|---|---|---|---|
| All five datasets | 96.16 | 92.56 | 90.56 | 0.9521 | 0.9066 |
| Only dataset 1 | 96.63 | 89.34 | 88.08 | 0.8573 | 0.9327 |
| Only dataset 2 | 97.21 | 95.05 | 93.38 | 0.9786 | 0.9240 |
| Only dataset 3 | 97.10 | 95.54 | 93.64 | 0.9878 | 0.9251 |
| Only dataset 4 | 95.92 | 92.45 | 90.26 | 0.9690 | 0.8839 |
| Only dataset 5 | 94.39 | 90.39 | 87.43 | 0.9342 | 0.8755 |
| Validate Data | tp | fn | fp | Cm,2.5 | Cr,2.5 | Q2.5 |
|---|---|---|---|---|---|---|
| All datasets | 159 | 30 | 32 | 0.8413 | 0.8325 | 0.7195 |
| Only dataset 1 | 22 | 4 | 14 | 0.8462 | 0.6111 | 0.55 |
| Only dataset 2 | 62 | 11 | 2 | 0.8493 | 0.9688 | 0.8267 |
| Only dataset 3 | 32 | 7 | 2 | 0.8205 | 0.9412 | 0.7805 |
| Only dataset 4 | 18 | 5 | 6 | 0.7826 | 0.75 | 0.6207 |
| Only dataset 5 | 25 | 3 | 8 | 0.8929 | 0.7576 | 0.6944 |
| OA (%) | F1 Score (%) | MIOU (%) | TT (h) | RT (s) | |
|---|---|---|---|---|---|
| Deeplab-V3 | 90.25 | 83.36 | 79.37 | 86.7 | 88.8 |
| MFRN | 95.61 | 91.80 | 89.74 | 51.4 | 85.0 |
| DAN | 96.16 | 92.56 | 90.56 | 42.1 | 77.6 |
| tp | fn | fp | Cm,2.5 | Cr,2.5 | Q2.5 | |
|---|---|---|---|---|---|---|
| Deeplab-V3 | 168 | 21 | 392 | 0.8889 | 0.3 | 0.2892 |
| MFRN | 163 | 26 | 56 | 0.8624 | 0.7443 | 0.6653 |
| DAN | 159 | 30 | 32 | 0.8413 | 0.8325 | 0.7195 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building Extraction in Very High Resolution Imagery by Dense-Attention Networks. Remote Sens. 2018, 10, 1768. https://doi.org/10.3390/rs10111768
Yang H, Wu P, Yao X, Wu Y, Wang B, Xu Y. Building Extraction in Very High Resolution Imagery by Dense-Attention Networks. Remote Sensing. 2018; 10(11):1768. https://doi.org/10.3390/rs10111768
Chicago/Turabian StyleYang, Hui, Penghai Wu, Xuedong Yao, Yanlan Wu, Biao Wang, and Yongyang Xu. 2018. "Building Extraction in Very High Resolution Imagery by Dense-Attention Networks" Remote Sensing 10, no. 11: 1768. https://doi.org/10.3390/rs10111768
APA StyleYang, H., Wu, P., Yao, X., Wu, Y., Wang, B., & Xu, Y. (2018). Building Extraction in Very High Resolution Imagery by Dense-Attention Networks. Remote Sensing, 10(11), 1768. https://doi.org/10.3390/rs10111768