1. Introduction
A synthetic aperture radar (SAR) is a coherent imaging sensor, which can access a wide range of high-quality massive surface data. Moreover, with the ability to operate at night and in adverse weather conditions such as thin clouds and haze, SAR has gradually become a significant source of remote sensing data in the fields of geographic mapping, resource surveying, and military reconnaissance. However, SAR images are inherently affected by multiplicative noise, i.e., speckle noise, which is caused by the coherent nature of the scattering phenomena [
1]. The presence of speckle severely affects the quality of SAR images, and greatly reduces the utilization efficiency in SAR image interpretation, retrieval, and other applications [
2,
3,
4]. Consequently, SAR image speckle reduction is an essential preprocessing step and has become a hot research topic.
For the purpose of removing the speckle noise of SAR images, scholars firstly proposed spatial linear filters such as the Lee filter [
5], Kuan filter [
6], and Frost filter [
7]. These methods usually assume that the image filtering result values have a linear relationship with the original image, through searching for a relevant combination of the central pixel intensity in a moving window with a mean intensity of the filter window. Thus, the spatial linear filters achieve a trade-off between balancing in homogeneous areas and a constant all-pass identity filter in edge included areas. The results have confirmed that spatial-domain filters are adept at suppressing speckle noise for some critical features. However, due to the nature of local processing, the spatial linear filter methods often fail to integrally preserve edges and details, which exhibit the following deficiencies: (1) unable to preserve the average value, especially when the equivalent number of look (ENL) of the original SAR image is small; (2) the powerfully reflective specific targets like points and small surficial features are easily blurred or erased; and (3) speckle noise in dark scenes is not removed [
8].
Except for the spatial-domain filters above, wavelet theory has also been applied to speckle reduction. Starck et al. [
9] primarily employed ridgelet transform as a component step, and implemented curvelet sub-bands using a filter bank of the discrete wavelet transform (DWT) filters for image denoising. For the case of speckle noise, Solbo et al. [
10] utilized the DWT of the log-transformed speckled image in homomorphic filtering, which is empirically convergent in a self-adaptive strategy and calculated in the Fourier space. In summary, the major weaknesses of this type of approach are the backscatter mean preservation in homogeneous areas, details preservation, and producing an artificial effect that is incorporated into the results, such as ring effects [
11].
Aimed at overcoming these deficiencies, the nonlocal means (NLM) algorithm [
12,
13,
14] has provided a breakthrough in detail preservation in SAR image despeckling. The basic idea of the NLM-based methods [
12] is that natural images have self-similarity and there are similar patches repeating over and over throughout the whole image. For SAR images, Deledalle et al. [
13] modified the choice of weights, which can be iteratively determined based on both the similarity between noisy patches and the similarity of patches extracted from the previous estimate. Besides, Parrilli et al. [
14] used the local linear minimum mean square error (LLMMSE) criterion and undecimated wavelet transform considering the peculiarities of SAR images, allowing for a sparse Wiener filtering representation and an effective separation between original signal and speckle noise through predefined thresholding, which has become one of the most effective SAR despeckling methods. However, the low computational efficiency of the similar patch searching restricts its application.
In addition, the variational-based methods [
15,
16,
17,
18] have gradually been utilized for SAR image despeckling because of their stability and flexibility, which break through the traditional idea of filters by solving the problem of energy optimization. Then, the despeckling task is cast as the inverse problem of recovering the original noise-free image based upon reasonable assumptions or prior knowledge of the noise observation model with log-transform, such as the total variation (TV) model [
15], sparse representation [
16], and so on. Although these variational methods have achieved a good reduction of speckle noise, the result is usually dependent on the choice of model parameters and prior information, and is often time-consuming. In addition, the variational-based methods cannot accurately describe the distribution of speckle noise, which also constraints the performance of speckle noise reduction.
In general, although many SAR despeckling methods have been proposed, they sometimes fail to preserve sharp features in domains of a complicated texture, or even create some block artifacts in the speckled image. In this paper, considering that image speckle noise can be expressed more accurately through non-linear models than linear models, and to overcome the above-mentioned limitations of the linear models, we propose a novel deep neural network-based approach for SAR image despeckling, learning a non-linear end-to-end mapping between the speckled and clean SAR images by a dilated residual network (SAR-DRN). Our despeckling model employs dilated convolutions, which can both enlarge the receptive field and maintain the filter size and layer depth with a lightweight structure. Furthermore, skip connections are added to the despeckling model to maintain the image details and avoid the vanishing gradient problem. Compared with the traditional despeckling methods in both simulated and real SAR experiments, the proposed approach shows a state-of-the-art performance in both quantitative and visual assessments, especially for strong speckle noise.
The rest of this paper is organized as follows. The SAR image speckling noise degradation model and the related deep convolution neural network method are introduced in
Section 2. The network architecture of the proposed SAR-DRN and details of its structure are described in
Section 3. Then, the results of the despeckling assessment in both simulated and real SAR image experiments are presented in
Section 4. Finally, the conclusions and future research are summarized in
Section 5.
3. Proposed Method
In this paper, rather than using log-transform [
28] or modifying training loss function like [
29], we propose a novel network for SAR image despeckling with a dilated residual network (SAR-DRN), which is trained in an end-to-end fashion using a combination of dilated convolutions and skip connections with a residual learning structure. Instead of relying on a pre-determined image, a
priori knowledge, or a noise description model, the main superiority of using the deep neural network strategy for SAR image despeckling is that the model can directly acquire and update the network parameters from the training data and the corresponding labels, which need not manually adjust critical parameters and can automatically learn the complex internal non-linear relations with trainable network parameters from the massive training simulative data.
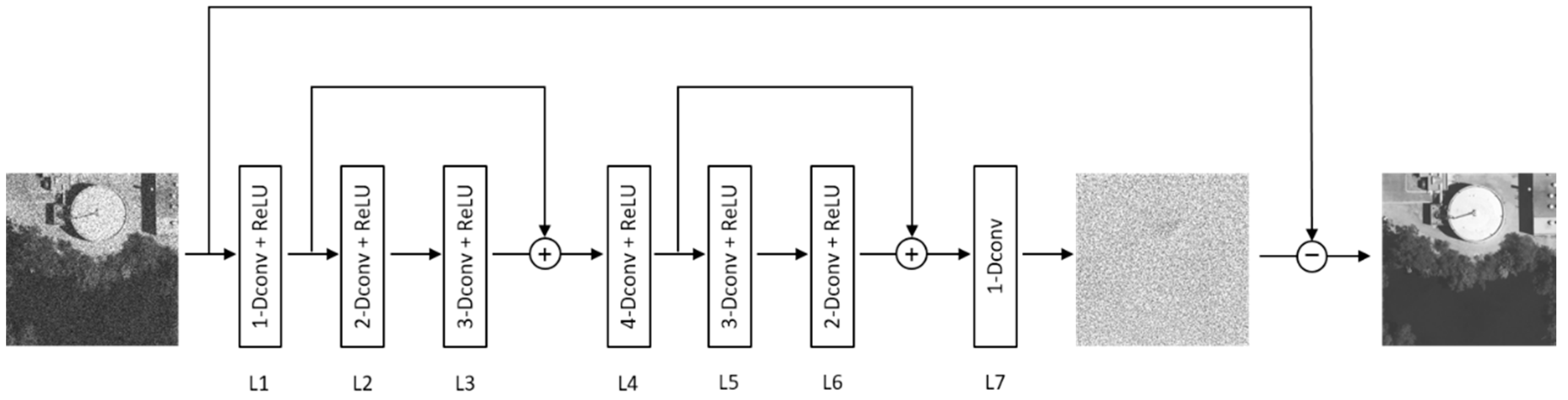
The proposed holistic neural network model (SAR-DRN) for SAR image despeckling contains seven dilated convolution layers and two skip connections, as illustrated in
Figure 1. In addition, the proposed model uses a residual learning strategy to predict the speckled image, which adequately utilizes the non-linear expression ability of deep learning. The details of the algorithm are described in the following.
3.1. Dilated Convolutions
In image restoration problems such as single-image super-resolution (SISR) [
30], denoising [
31], and deblurring [
32], contextual information can effectively facilitate the recovery of degraded regions. In deep convolutional networks, the contextual information is mainly augmented through enlarging the receptive field. Generically, there are two ways to achieve this purpose: (1) increasing the network depth; and (2) enlarging the filter size. Nevertheless, as the network depth increases, the accuracy becomes “saturated” and then degrades rapidly. Enlarging the filter size can also lead to more convolution parameters, which greatly increases the calculative burden and training times.
To solve this problem effectively, dilated convolutions were first proposed in [
33], which can both enlarge the receptive field and maintain the filter size. Let
be an input discrete two-dimensional matrix such as an image, and let
be a discrete convolution filter of size
. Then, the original discrete convolution operator
can be given as
After defined this convolution operator
, let
be a dilation factor and let
be equivalent to
where
is served as the dilated convolution or a
-dilated convolution. Particularly, the common discrete convolution
can be regarded as the
-dilated convolution. Setting the size of the convolutional kernel with 3 × 3 as an example, let
be the discrete 3 × 3 convolution filters. Consider applying the filters with exponentially increasing dilation as
where
,
, and
represents the size of the receptive field. The common convolution receptive field has a linear correlation with the layer depth, in that the receptive field size:
. By contrast, the dilated convolution receptive field has an exponential correlation with the layer depth, where the receptive field size:
. For instance, when
,
, while
with the same layer depth.
Figure 2 illustrates the dilated convolution receptive field size, which: (a) corresponds to the one-dilated convolution, which is equivalent to the common convolution operation at this point; (b) corresponds to the two-dilated convolution; and (c) corresponds to the four-dilated convolution.
In the proposed SAR-DRN model, considering that trade-off between feature extraction ability and reducing training time, the dilation factors of the 3 × 3 dilated convolutions from layer 1 to layer 7 are respectively set to 1, 2, 3, 4, 3, 2, and 1, empirically. Compared with other deep neural networks, we propose a lightweight model with only seven dilated convolution layers, as shown in
Figure 3.
3.2. Skip Connections
Although the increase of network layer depth can help to obtain more data feature expressions, it often results in the vanishing gradient problem, which makes the training of the model much harder. To solve this problem, a new structure called skip connection [
34] has been created for the DCNNs, to obtain better training results. The skip connection can pass the previous layer’s feature information to its posterior layer, maintaining the image details and avoiding or reducing the vanishing gradient problem. For the
-th layer, let
be the input data, and let
be its feed-forward propagation with trainable parameters. The output of the
-th layer with
-interval skip connection is recursively defined as follows:
For clarity, in the proposed SAR-DRN model, two skip connections are employed to connect layer 1 to layer 3 (as shown in
Figure 4a) and layer 4 to layer 7 (as shown in
Figure 4b), whose effects are compared with no skip connections in the discussion section.
3.3. Residual Learning
Compared with traditional data mapping, He et al. [
35] found that residual mapping can acquire a more effective learning effect and rapidly reduce the training loss after passing through a multi-layer network, which has achieved a state-of-the-art performance in object detection [
36], image super-resolution [
37], and so on. Essentially, Szegedy et al. [
38] demonstrated that residual networks take full advantage of identity shortcut connections, which can efficiently transfer various levels of feature information between not directly connected layers without attenuation. In the proposed SAR-DRN model, the residual image
is defined as follows:
As the layer depth increases, the degradation phenomenon manifests that common deep networks might have difficulties in approximating identical mappings by stacked non-linear layers like the Conv-BN-ReLU block. By contrast, it is reasonable to consider that most pixel values in residual image are very close to zero, and the spatial distribution of the residual feature maps should be very sparse, which can transfer the gradient descent process to a much smoother hyper-surface of loss to filtering parameters. Thus, searching for an allocation which is on the verge of the optimal for the network’s parameters becomes much quicker and easier, allowing us to add more trainable layers to the network and improve its performance. The learning procedure with a residual unit is easier to approximate to the original multiplicative speckle noise through the deeper and intrinsic non-linear feature extraction and expression, which can better weaken the range difference between optical images and SAR images.
Specifically for the proposed SAR-DRN, we choose a collection of
training image pairs
from the training data sets as described in 4.1 below, where
is the speckled image, and
is the network parameters. Our model uses the mean squared error (MSE) as the loss function:
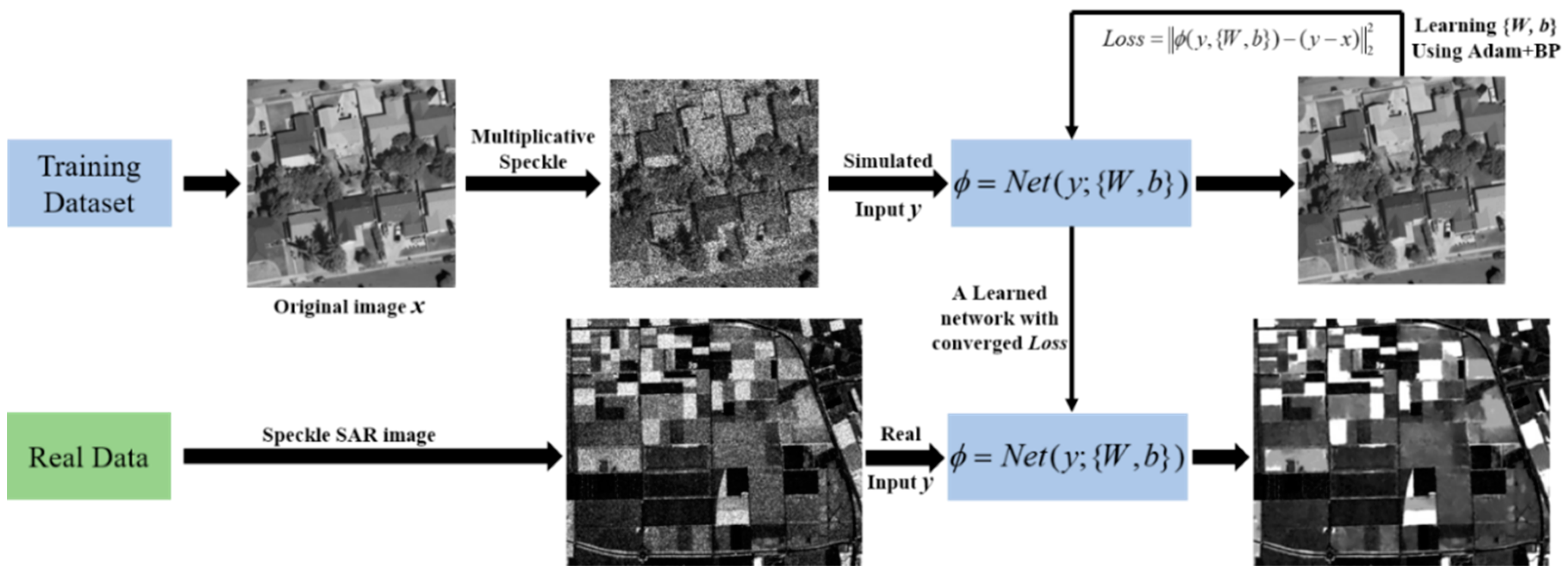
In summary, with the dilated convolution, skip connections and residual learning structure, the flowchart of learning a deep network for the SAR image despeckling process is described in
Figure 5. To learn the complicated non-linear relation between the speckled image
and original image
, the proposed SAR-DRN model is employed with converged loss between the residual image
and the output
, then preparing for real speckle SAR image processing as illuminated in
Figure 5.
5. Conclusions
In this paper, we have proposed a novel deep learning approach for the SAR image despeckling task, learning an end-to-end mapping between the noisy and clean SAR images. Differently from common convolutions operation, the presented approach is based on dilated convolutions, which can both enlarge the receptive field and maintain the filter size with a lightweight structure. Furthermore, skip connections are added to the despeckling model to maintain the image details and avoid the vanishing gradient problem. Compared with the traditional despeckling methods, the proposed SAR-DRN approach shows a state-of-the-art performance in both simulated and real SAR image despeckling experiments, especially for strong speckle noise.
In our future work, we will investigate more powerful learning models to deal with the complex real scenes in SAR images. Considering that the training of our current method performed for each number of looks, we will explore an integrated model to solve this problem. Furthermore, the proposed approach will be extended to polarimetric SAR image despeckling, whose noise model is much more complicated than that of single-polarization SAR. Besides, for better reducing speckle noise in more complex real SAR image data, some
prior constraint like multi-channel patch matching, band selection, location
prior, and locality adaptive discriminant analysis [
45,
46,
47,
48], can also be considered to improve the precision of despeckling results. In addition, we will try to collect enough SAR images and then train the model with multi-temporal data [
49] for SAR image despeckling, which will be sequentially explored in future studies.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}