A Geostatistical Approach for Modeling Soybean Crop Area and Yield Based on Census and Remote Sensing Data

 ,
, 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Acquisition and Processing
2.3. Proposition of the Soybean Enhanced Index
2.4. Geostatistical Analysis
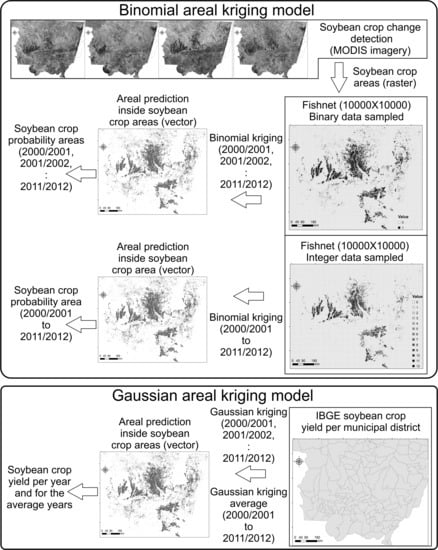
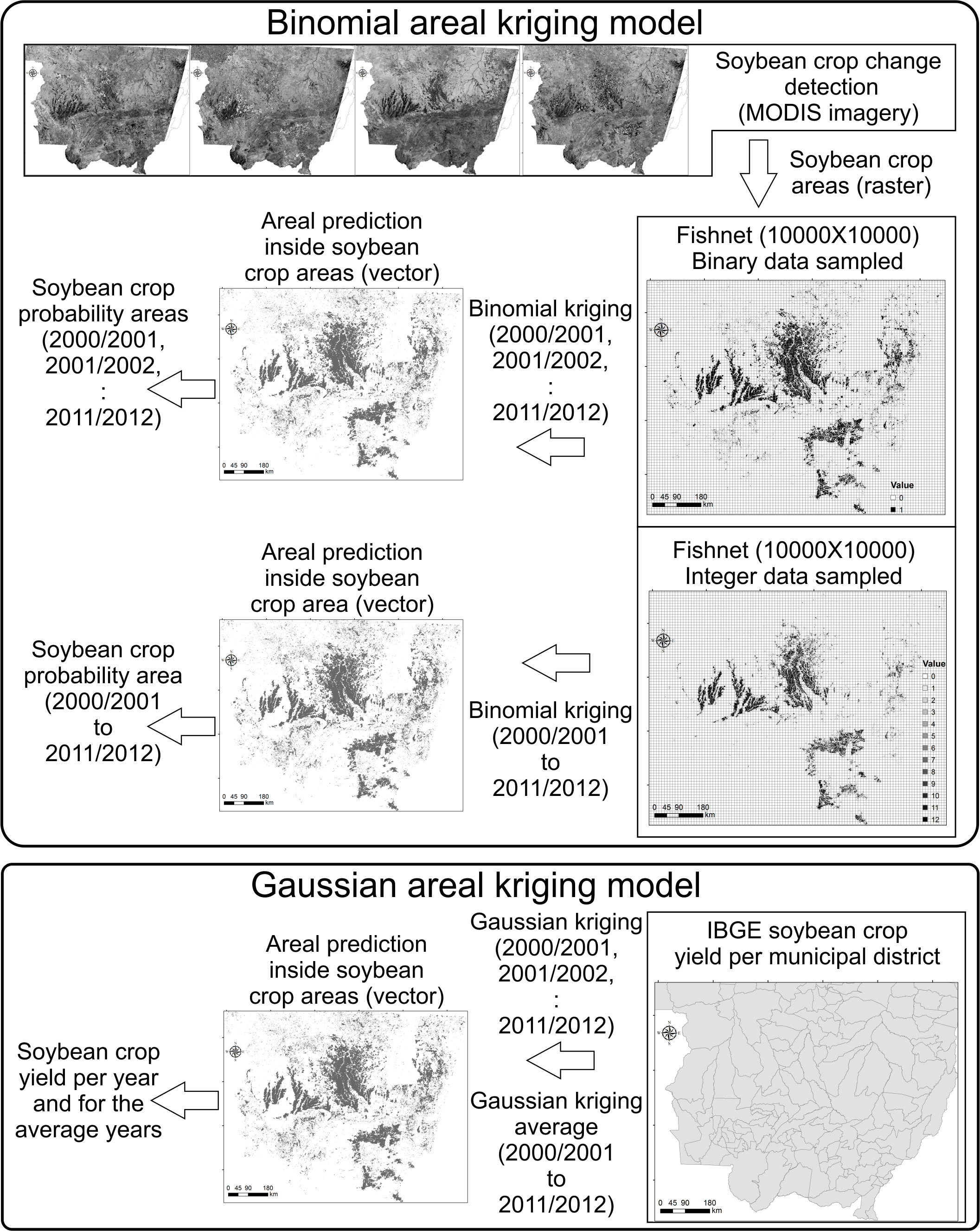
2.4.1. Binomial Areal Kriging Model
2.4.2. Gaussian Areal Kriging Model
2.4.3. Block Kriging Model
2.4.4. Modeling Semivariogram and Covariance Function
2.5. Validation Phase
2.5.1. Soybean Crop Area Validation Phase
2.5.2. Soybean Crop Yield Validation Phase
3. Results
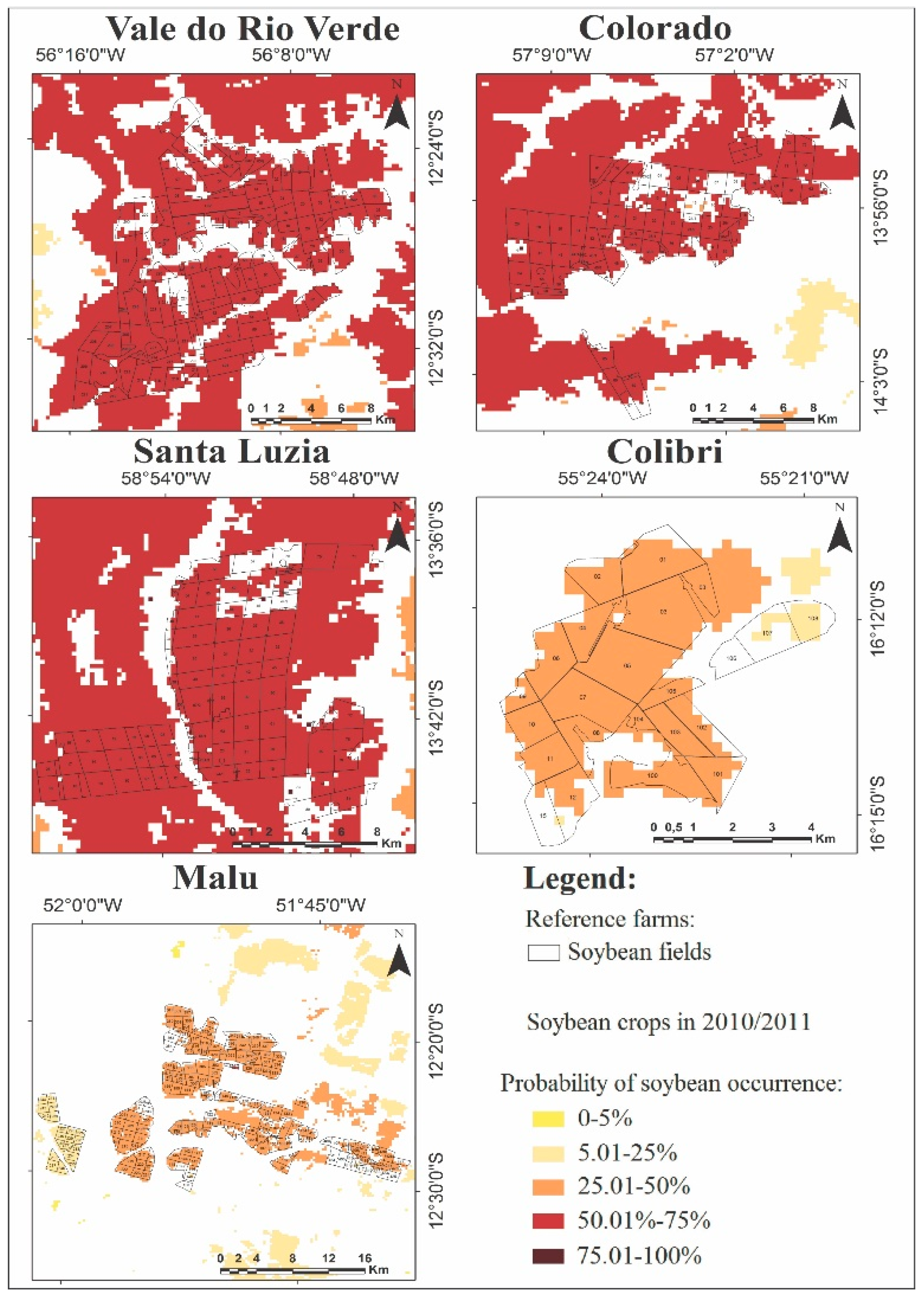
3.1. Soybean Crop Area Results
Binomial Areal Kriging Model for Soybean Crop Area Identification
3.2. Accuracy Assessment of Soybean Crop Area Results
3.3. Soybean Crop Yield Results
Gaussian Areal Kriging Model for Yield Prediction
3.4. Accuracy Assessment of Soybean Crop Yield Results
4. Discussion
4.1. Soybean Crop Area Results
Binomial Areal Kriging Model
4.2. Accuracy Assessment of Soybean Crop Area Results
4.3. Soybean Crop Yield Results
4.3.1. Gaussian Areal Kriging Model
4.4. Accuracy Assessment of Soybean Crop Yield Results
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Gotway, C.A.; Young, L.J. Combining incompatible spatial data. J. Am. Stat. Assoc. 2002, 97, 632–648. [Google Scholar] [CrossRef]
- Atkinson, P.M. Downscaling in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2013, 22, 106–114. [Google Scholar] [CrossRef]
- Krivoruchko, K.; Gribov, A.; Krause, E. Multivariate areal interpolation for continuous and count data. Proc. Environ. Sci. 2011, 3, 14–19. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tate, N.J. Spatial scale problems and geostatistical solutions: A review. Prof. Geogr. 2000, 52, 607–623. [Google Scholar] [CrossRef]
- Gotway, C.A.; Young, L.J. A geostatistical approach to linking geographically aggregated data from different sources. J. Comput. Graph. Stat. 2007, 16, 15–35. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem; Concepts and Techniques in Modern Geography, No. 38; GeoBooks: Norwich, UK, 1984. [Google Scholar]
- Goovaerts, P. Combining areal and point data in geostatistical interpolation: Applications to soil science and medical geography. Math. Geosci. 2010, 42, 535–554. [Google Scholar] [CrossRef] [PubMed]
- Arvor, D.; Jonathan, M.; Meirelles, M.S.P.; Dubreuil, V.; Durieux, L. Classification of MODIS EVI time series for crop mapping in the state of Mato Grosso, Brazil. Int. J. Remote Sens. 2011, 32, 7847–7871. [Google Scholar] [CrossRef]
- Kastens, J.H.; Brown, J.C.; Coutinho, A.C.; Bishop, C.R.; Esquerdo, J.C.D.M. Soy moratorium impacts on soybean and deforestation dynamics in Mato Grosso, Brazil. PLoS ONE 2017, 12, e0176168. [Google Scholar] [CrossRef] [PubMed]
- Brown, J.C.; Kastens, J.H.; Coutinho, A.C.; de Castro Victoria, D.; Bishop, C.R. Classifying multiyear agricultural land use data from Mato Grosso using time-series MODIS vegetation index data. Remote Sens. Environ. 2013, 130, 39–50. [Google Scholar] [CrossRef]
- Gusso, A.; Arvor, D.; Ducati, J.R.; Veronez, M.R.; Silveira Junior, L.G. Assessing the MODIS Crop Detection Algorithm for Soybean Crop Area Mapping and Expansion in the Mato Grosso State, Brazil. Sci. World J. 2014. [Google Scholar] [CrossRef] [PubMed]
- Davidson, E.A.; Araújo, A.C.; Artaxo, P.; Balch, J.K.; Brown, I.F.; Bustamante, M.M.C.; Coe, M.T.; DeFries, R.S.; Keller, M.; Longo, M.; et al. The Amazon basin in transition. Nature 2012, 481, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Raucci, G.S.; Moreira, C.S.; Alves, P.A.; Mello, F.F.C.; Frazão, L.A.; Cerri, C.E.P.; Cerri, C.C. Greenhouse gas assessment of Brazilian soybean production: A case study of Mato Grosso State. J. Clean. Prod. 2015, 96, 419–425. [Google Scholar] [CrossRef]
- Brazilian Institute of Geography and Statistics (IBGE), 2017. Geociências: Produtos, IBGE. Available online: http://downloads.ibge.gov.br/downloads_geociencias.htm (accessed on 18 January 2017).
- Arvor, D.; Dubreuil, V.; Mendez Del Villar, P.; Ferreira, C.M.; Meirelles, M.S.P. Développement, crises et adaptation des territoires du soja au Mato Grosso: l’exemple de Sorriso. Confins 2009, 6. Available online: http://confins.revues.org/index5934.html (accessed on 27 February 2017). [CrossRef]
- Arvor, D.; Meirelles, M.S.P.; Dubreuil, V.; Bégué, A.; Shimabukuro, Y.E. Analyzing the agricultural transition in Mato Grosso, Brazil, using satellite-derived indices. Appl. Geogr. 2012, 32, 702–713. [Google Scholar] [CrossRef]
- Solano, R.; Didan, K.; Jacobson, A.; Huete, A. MODIS Vegetation Index (MOD 13) C5 User’s Guide; The University of Arizona: Tucson, AZ, USA, 2010; p. 38. [Google Scholar]
- Risso, J.; Rizzi, R.; Rudorff, B.F.T.; Adami, M.; Shimabukuro, Y.E.; Formaggio, A.R.; Epiphanio, R.D.V. Modis vegetation indices applied to soybean area discrimination. Pesq. Agropec. Bras. 2012, 47, 1317–1326. [Google Scholar] [CrossRef]
- Galford, G.L.; Mustard, J.F.; Melillo, J.; Gendrin, A.; Cerri, C.C.; Cerri, C.E.P. Wavelet analysis of MODIS time series to detect expansion and intensification of row-crop agriculture in Brazil. Remote Sens. Environ. 2008, 112, 576–587. [Google Scholar] [CrossRef]
- Zhu, C.; Lu, D.; de Castro Victoria, D.; Dutra, L.V. Mapping Fractional Cropland Distribution in Mato Grosso, Brazil using time series MODIS Enhanced Vegetation Index and Landsat Thematic Mapper data. Remote Sens. 2016, 8, 22. [Google Scholar] [CrossRef]
- Rudorff, B.F.T.; Adami, M.; Aguiar, D.A.; Moreira, M.A.; Mello, M.P.; Fabiani, L.; Amaral, D.F.; Pires, B.M. The soy moratorium in the Amazon biome monitored by remote sensing images. Remote Sens. 2011, 3, 185–202. [Google Scholar] [CrossRef]
- Huete, A.R.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Yu, L.; Gong, P.; Biging, G.S. Automated mapping of soybean and corn using phenology. ISPRS J. Photogramm. Remote Sens. 2016, 119, 151–164. [Google Scholar] [CrossRef]
- Yan, H.; Xiao, X.; Huang, H.; Liu, J.; Chen, J.; Bai, X. Multiple cropping intensity in China derived from agro-meteorological observations and MODIS data. Chin. Geogr. Sci. 2014, 24, 205–219. [Google Scholar] [CrossRef]
- Huete, A.R.; Liu, H.Q.; Batchily, K.; van Leewen, W. A comparison of vegetation indices over a global set of TM images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Roy, D.P.; Borak, J.S.; Devadiga, S.; Wolfe, R.E.; Zheng, M.; Descloitres, J. The MODIS Land product quality assessment approach. Remote Sens. Environ. 2002, 83, 62–76. [Google Scholar] [CrossRef]
- National Aeronautics and Space Administration (NASA). Land Processes Distributed Active Archive Center (LP DAAC), MOD13Q1; USGS/Earth Resources Observation and Science (EROS) Center: Sioux Falls, SD, USA, 2001.
- Brazilian Institute of Geography and Statistics (IBGE), 2011. Sistema IBGE de Recuperação Automática, Produção Agrícola Municipal. Instituto Brasileiro de Geografia e Estatística. Available online: https://sidra.ibge.gov.br/home/lspa/brasil (accessed on 18 January 2017).
- Lajaunie, C. Local Risk Estimation for a Rare Non Contagious Disease Based on Observed Frequencies; Note N-36/91/G; Centre de Geostatistique de l’Ecole des Mines de Paris: Fontainebleau, France, 1991. [Google Scholar]
- Waller, L.A.; Gotway, C.A. Applied Spatial Statistics for Public Health Data; John Wiley and Sons: Hoboken, NJ, USA, 2004; p. 494. [Google Scholar]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications, 3rd ed.; Springer: Berlin, Germany, 2003; p. 388. [Google Scholar]
- Webster, R.; Oliver, M.; Muir, K.; Mann, J. Kriging the Local Risk of a Rare Disease from a Register of Diagnoses. Geogr. Anal. 1994, 26, 168–185. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data, 1st ed.; Wiley Interscience: New York, NY, USA, 1993; p. 903. [Google Scholar]
- Chilès, J.P.; Delfiner, P. Geostatistics: Modeling spatial uncertainty, 1st ed.; Wiley Interscience: New York, UY, USA, 1999; p. 695. [Google Scholar]
- Goovaerts, P. Kriging and semivariogram deconvolution in the presence of irregular geographical units. Math. Geosci. 2008, 40, 101–128. [Google Scholar] [CrossRef]
- Kerry, R.; Goovaerts, P.; Rawlins, B.G.; Marchant, B.P. Disaggregation of legacy soil data using area to point kriging for mapping soil organic carbon at the regional scale. Geoderma 2012, 170, 347–358. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sentelhas, P.C.; Battisti, R.; Câmara, G.M.S.; Farias, J.R.B.; Hampf, A.C.; Nendel, C. The soybean yield gap in Brazil—Magnitude, causes and possible solutions for sustainable production. J. Agric. Sci. 2015, 65, 1–18. [Google Scholar] [CrossRef]
- Ronchail, J.; Cochonneau, G.; Molinier, M.; Guyot, J.L.; de Miranda Chaves, A.G.; Guimaraes, W.; de Oliveira, E. Rainfall variability in the Amazon Basin and SSTs in the tropical Pacific and Atlantic oceans. Int. J. Climatol. 2002, 22, 1663–1686. [Google Scholar] [CrossRef]
- Almeida, C.A.; Coutinho, A.C.; Esquerdo, J.C.D.M.; Adami, M.; Venturieri, A.; Diniz, C.G.; Dessay, N.; Durieux, L.; Gomes, A.R. High spatial resolution land use and land cover mapping of the Brazilian Legal Amazon in 2008 using Landsat-5/TM and MODIS data. Acta Amazon. 2016, 46, 291–302. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remote Sensing Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009; p. 200. [Google Scholar]
- Ghilani, C.D.; Wolf, P.R. Elementary Surveying: An Introduction to Geomatics, 13th ed.; Prentice Hall: Boston, MA, USA, 2012; p. 958. [Google Scholar]
- Gusso, A.; Formaggio, A.R.; Rizzi, R.; Adami, M.; Rudorff, B.F.T. Soybean crop area estimation by MODIS/EVI data. Pesq. Agropec. Bras. 2012, 47, 425–435. [Google Scholar] [CrossRef]
- Souza, C.H.W.; Mercante, E.; Johann, J.A.; Lamparelli, R.A.C.; Uribe-Opazo, M.A. Mapping and discrimination of soya bean and corn crops using spectro-temporal profiles of vegetation indices. Int. J. Remote Sens. 2015, 36, 1809–1824. [Google Scholar] [CrossRef]
- De Victoria, D.C.; da Paz, A.R.; Coutinho, A.C.; Kastens, J.; Brown, J.C. Cropland area estimates using Modis NDVI time series in the state of Mato Grosso, Brazil. Pesq. Agropec. Bras. 2012, 47, 1270–1278. [Google Scholar] [CrossRef]
- Gibbs, H.K.; Rausch, L.; Munger, J.; Schelly, I.; Morton, D.C.; Noojipady, P.; Soares-Filho, B.; Barreto, P.; Micol, L.; Walker, N.F. Brazil’s Soy Moratorium. Science 2015, 347, 377–378. [Google Scholar] [CrossRef] [PubMed]
- Arvor, D.; Dubreuil, V.; Meirelles, M.S.P.; Bégué, A. Mapping and spatial analysis of the soybean agricultural frontier in Mato Grosso, Brazil, using remote sensing data. GeoJournal 2013, 78, 833–850. [Google Scholar] [CrossRef]
- Dubreuil, V.; Nédélec, V.; Arvor, D.; Le Derout, M.; Laques, A.E.; Mendez, P. Colonisation agricole et déforestation en Amazonie Brésilienne: Exemple du front pionnier du Mato Grosso. Enquêtes Rurales 2009, 12, 107–135. [Google Scholar]
- Morton, D.; DeFries, R.S.; Shimabukuro, Y.E.; Anderson, L.O.; Del Bon Espírito-Santo, F.; Hansen, M.; Carroll, M. Rapid assessment of annual deforestation in the Brazilian Amazon using MODIS data. Earth Interact. 2005, 9, 1–22. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Landis, J.; Koch, G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Lamparelli, R.A.C.; de Carvalho, W.M.O.; Mercante, E. Mapeamento de semeaduras de soja (Glycinemax (L.) Merr.) mediante dados MODIS/Terra e TM/Landsat 5: Um comparativo. Eng. Agric. 2008, 28, 334–344. [Google Scholar] [CrossRef]
- Epiphanio, R.D.V.; Formaggio, A.R.; Rudorff, B.F.T.; Maeda, E.E.; Luiz, A.J.B. Estimating soybean crop areas using spectral-temporal surfaces derived from MODIS images in Mato Grosso, Brazil. Pesq. Agropec. Bras. 2010, 45, 72–80. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; Moran, E.; Hetrick, S.; Alves, D.; Brondizio, E. Fractional forest cover mapping in the Brazilian Amazon with a combination of MODIS and TM images. Int. J. Remote Sens. 2011, 32, 1–19. [Google Scholar] [CrossRef]
- Dubreuil, V.; Laques, A.-E.; Nédélec, V.; Arvor, D.; Gurgel, H. Paysages et fronts pionniers amazoniens sous le regard des satellites: L’exemple du Mato Grosso. Espace Geographique 2008, 37, 57–74. [Google Scholar] [CrossRef]
- Openshaw, S. Ecological fallacies and the analysis of areal census data. Environ. Plan. A 1984, 16, 17–31. [Google Scholar] [CrossRef] [PubMed]
- Prasad, A.K.; Singh, R.P.; Tare, V.; Kafatos, M. Use of vegetation index and meteorological parameters for the prediction of crop yield in India. Int. J. Remote Sens. 2007, 28, 5207–5235. [Google Scholar] [CrossRef]
- Battisti, R.; Sentelhas, P.C. Drought tolerance of Brazilian soybean cultivars simulated by a simple agrometeorological yield model. Exp. Agric. 2015, 51, 285–298. [Google Scholar] [CrossRef]
- Franchini, J.C.; Costa, J.M.; Debiasi, H.; Torres, E. Importância da rotação de culturas para a produção agrícola sustentável no Paraná; Documentos 327; Embrapa Soja: Londrina, Brazil, 2011; p. 52. [Google Scholar]
- Sinclair, T.R.; Messina, C.D.; Beatty, A.; Samples, M. Assessment across the united states of the benefits of altered soybean drought traits. Agron. J. 2010, 102, 475–482. [Google Scholar] [CrossRef]
- Torrion, J.A.; Setiyono, T.D.; Cassman, K.G.; Ferguson, R.B.; Irmak, S.; Specht, J.E. Soybean root development relative to vegetative and reproductive phenology. Agron. J. 2012, 104, 1702–1709. [Google Scholar] [CrossRef]
- Franchini, J.C.; Debiasi, H.; Sacoman, A.; Nepomuceno, A.L.; Farias, J.R.B. Manejo do solo para redução das perdas de produtividade pela seca; Documentos 314; Embrapa Soja: Londrina, Brazil, 2009; p. 39. [Google Scholar]
- Anderson, M.C.; Zolin, C.A.; Sentelhas, P.C.; Hain, C.R.; Semmens, K.; Yilmaz, M.T.; Gao, F.; Otkin, J.A.; Tetrault, R. The Evaporative Stress Index as an indicator of agricultural drought in Brazil: An assessment based on crop yield impacts. Remote Sens. Environ. 2016, 174, 82–99. [Google Scholar] [CrossRef]
- Arvor, D.; Dubreuil, V. Etude par Télédétection de la Dynamique du soja et de L’impact des Précipitations sur les Productions au Mato Grosso (Brésil). Ph.D. Thesis, Université Rennes 2, Rennes, France, 2009. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agglomerate | Soybean Classified as Soybean | Soybean Classified as Non-soybean | Non-Soybean Classified as Soybean | Crop Fields in 2010/2011 | Accuracy Ratio |
|---|---|---|---|---|---|
| Santa Luzia | 57 | 0 | 10 | 67 | 85.1% |
| Colorado | 61 | 1 | 6 | 68 | 89.8% |
| Vale do Rio Verde | 77 | 0 | 12 | 89 | 86.6% |
| Colibri | 21 | 1 | 0 | 22 | 95.5% |
| Malu | 151 | 17 | 14 | 182 | 83.0% |
| Total | 367 | 19 | 42 | 428 | 85.8% |
| Classified Data | Reference Data | ||||
|---|---|---|---|---|---|
| Soybean | Non-Soybean | References | Commission Errors | User’s Accuracy | |
| Soybean | 367 | 42 | 409 | 0.10 | 0.90 |
| Non-soybean | 19 | 344 | 363 | 0.05 | 0.95 |
| References | 386 | 386 | 772 | ||
| Omission errors | 0.05 | 0.11 | |||
| Producer’s accuracy | 0.95 | 0.89 | |||
| Overall accuracy | 0.92 | ||||
| Kappa Index | 0.84 | ||||
| Agglomerate | Soybean Crop Fields | Correct Class of Soybean Crop Yield | Standard Deviation | Accuracy Ratio |
|---|---|---|---|---|
| Santa Luzia | 57 | 13 | 23.33 | 22.80% |
| Colorado | 61 | 16 | 23.69 | 26.22% |
| Vale do Rio Verde | 77 | 38 | 23.33 | 49.35% |
| Colibri | 21 | 10 | 23.69 | 47.61% |
| Malu | 151 | 129 | 23.33 | 85.43% |
| Total | 367 | 206 | 23.54 | 56.13% |
| Agglomerate | Crop Fields | Standard Deviation | 50% Error | Correct Class of Soybean Crop Yield | Accuracy RATIO |
|---|---|---|---|---|---|
| Santa Luzia | 67 | 23.33 | ±15.74 | 57 | 85.00% |
| Colorado | 68 | 23.69 | ±15.98 | 67 | 98.53% |
| Vale do Rio Verde | 89 | 23.33 | ±15.74 | 85 | 95.51% |
| Colibri | 22 | 23.69 | ±15.98 | 21 | 95.45% |
| Malu | 182 | 23.33 | ±15.74 | 177 | 97.25% |
| Total | 428 | 23.54 | ±15.84 | 407 | 95.09% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaves, M.E.D.; De Carvalho Alves, M.; De Oliveira, M.S.; Sáfadi, T. A Geostatistical Approach for Modeling Soybean Crop Area and Yield Based on Census and Remote Sensing Data. Remote Sens. 2018, 10, 680. https://doi.org/10.3390/rs10050680
Chaves MED, De Carvalho Alves M, De Oliveira MS, Sáfadi T. A Geostatistical Approach for Modeling Soybean Crop Area and Yield Based on Census and Remote Sensing Data. Remote Sensing. 2018; 10(5):680. https://doi.org/10.3390/rs10050680
Chicago/Turabian StyleChaves, Michel Eustáquio Dantas, Marcelo De Carvalho Alves, Marcelo Silva De Oliveira, and Thelma Sáfadi. 2018. "A Geostatistical Approach for Modeling Soybean Crop Area and Yield Based on Census and Remote Sensing Data" Remote Sensing 10, no. 5: 680. https://doi.org/10.3390/rs10050680
APA StyleChaves, M. E. D., De Carvalho Alves, M., De Oliveira, M. S., & Sáfadi, T. (2018). A Geostatistical Approach for Modeling Soybean Crop Area and Yield Based on Census and Remote Sensing Data. Remote Sensing, 10(5), 680. https://doi.org/10.3390/rs10050680