Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition



Abstract
:1. Introduction
2. Related Work
2.1. Behavior Recognition with Trajectory
2.2. Behavior Recognition without Trajectory
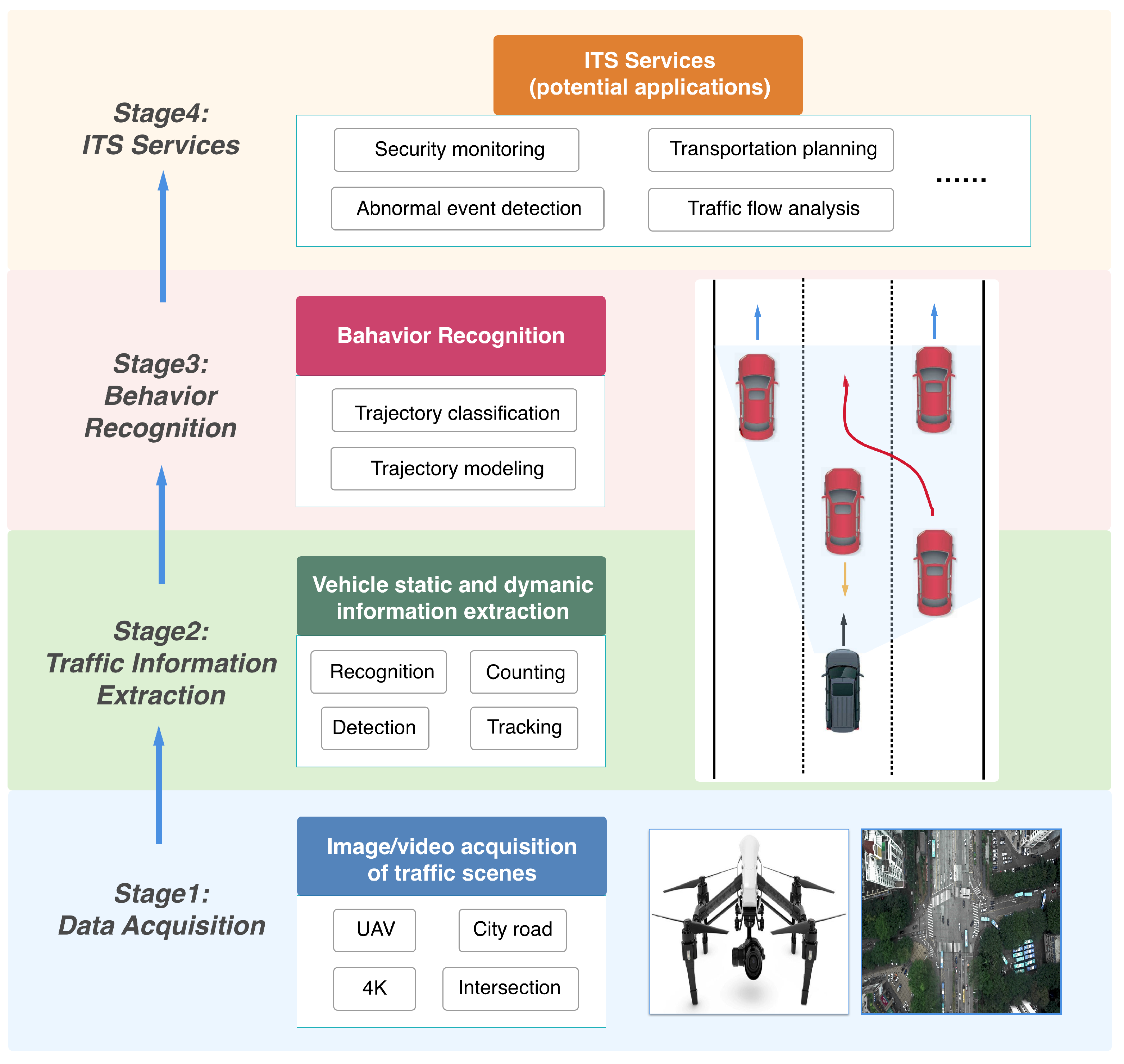
3. The Deep Vehicle Behavior Recognition Framework
3.1. Vehicle Trajectory Extraction
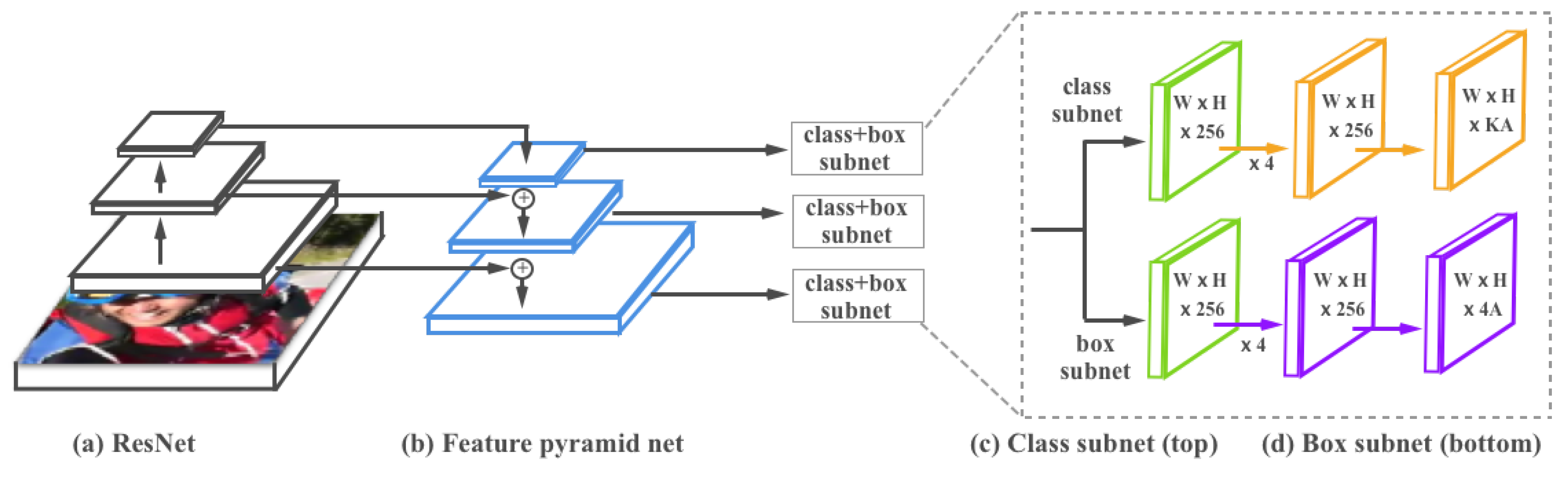
3.1.1. Vehicle Detection
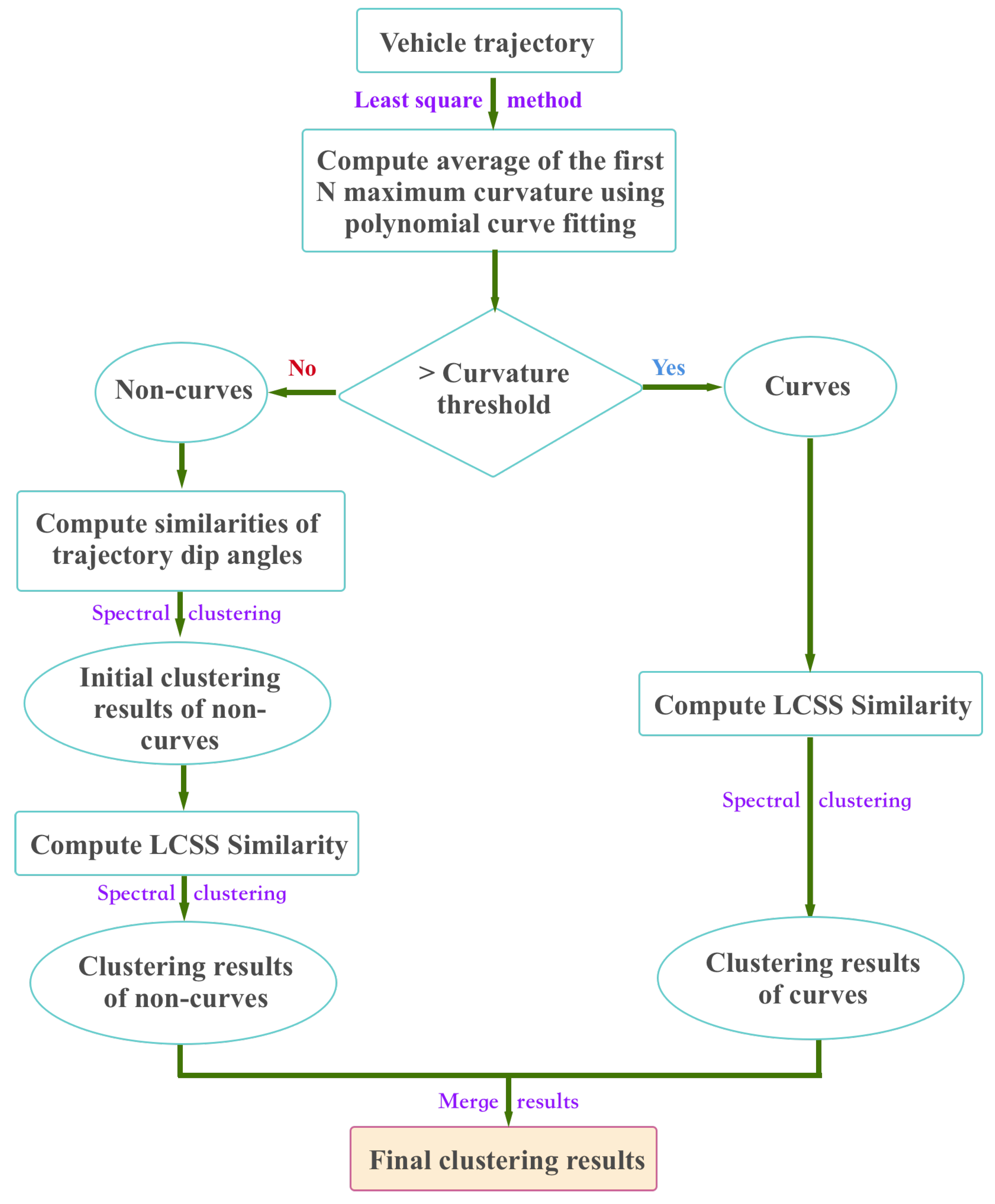
3.1.2. Trajectory Modeling and Extraction
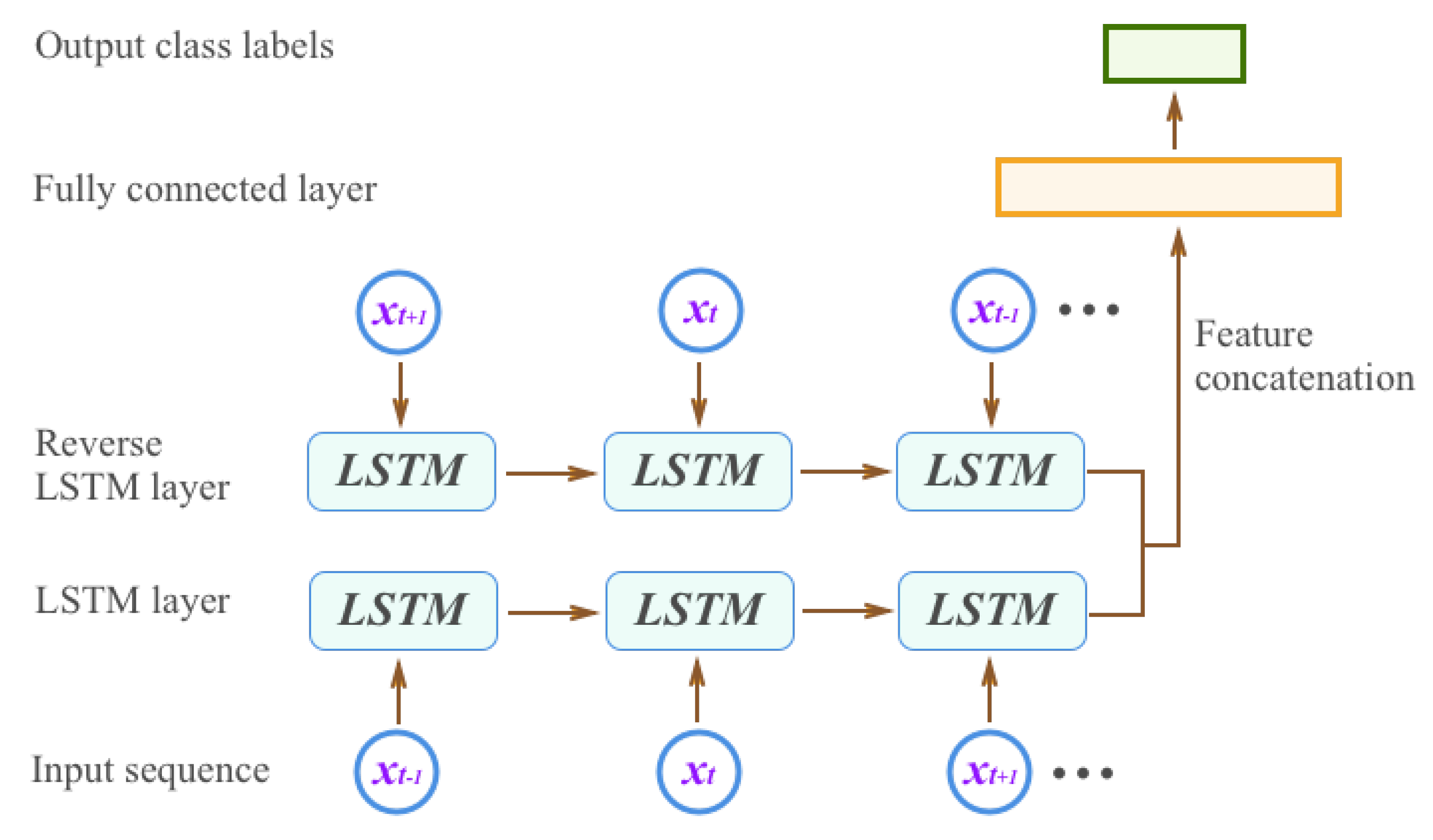
3.2. Vehicle Behavior Recognition
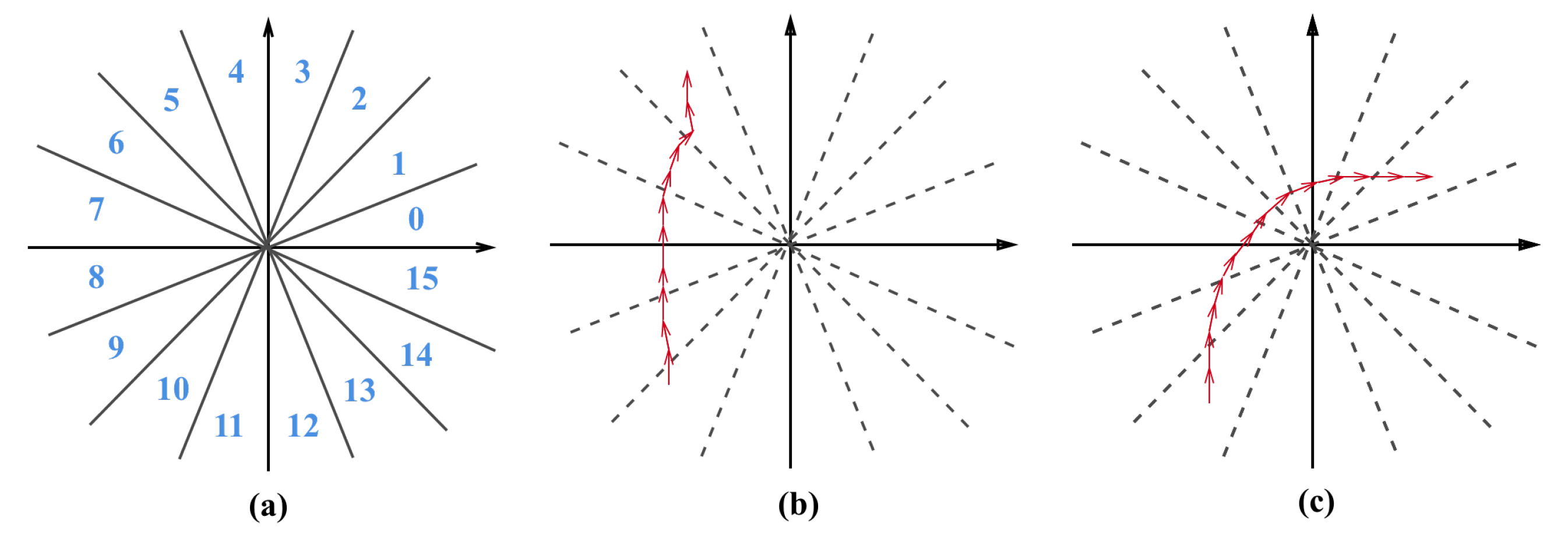
3.2.1. Behavior Recognition Based on Nearest Neighbor Search
3.2.2. Behavior Recognition by Classification
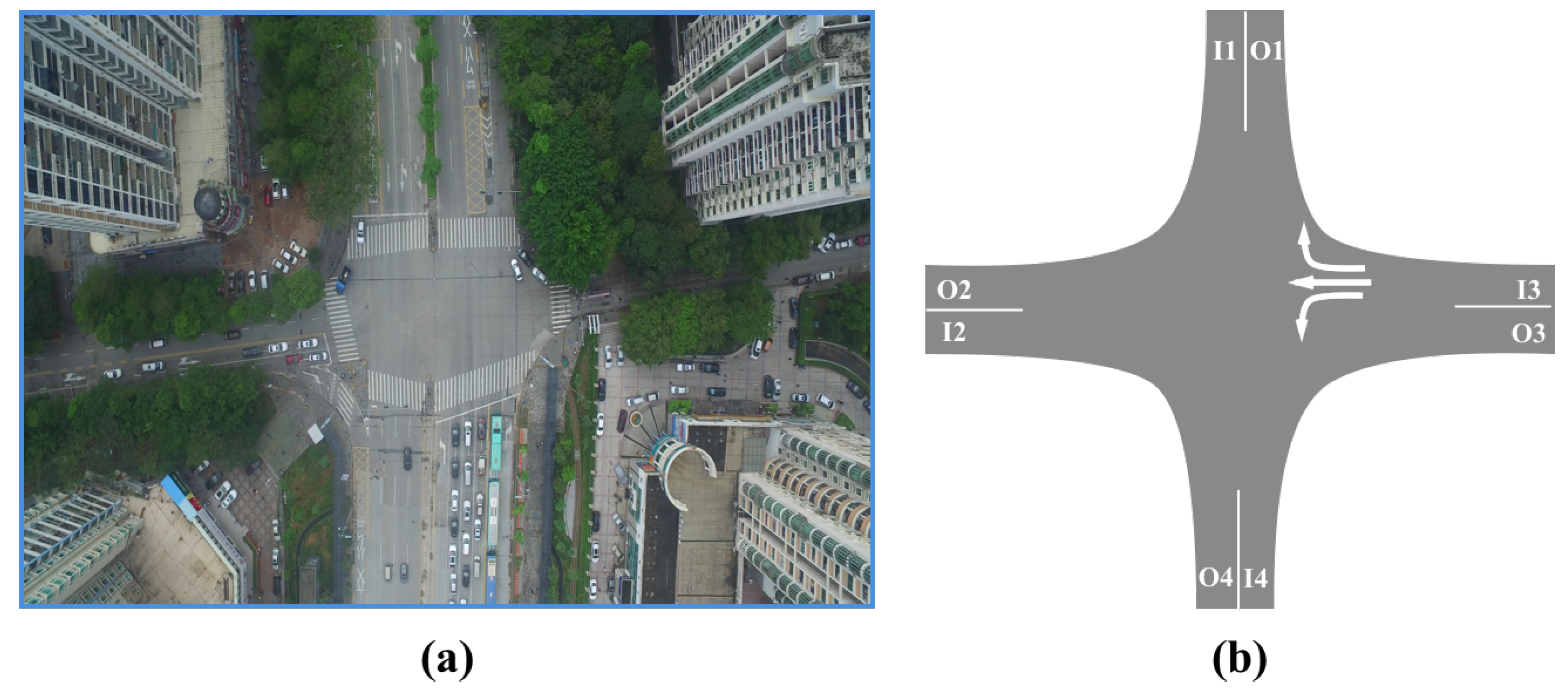
4. Experiment and Discussion
4.1. Vehicle Trajectory Extraction
4.1.1. Vehicle Detection
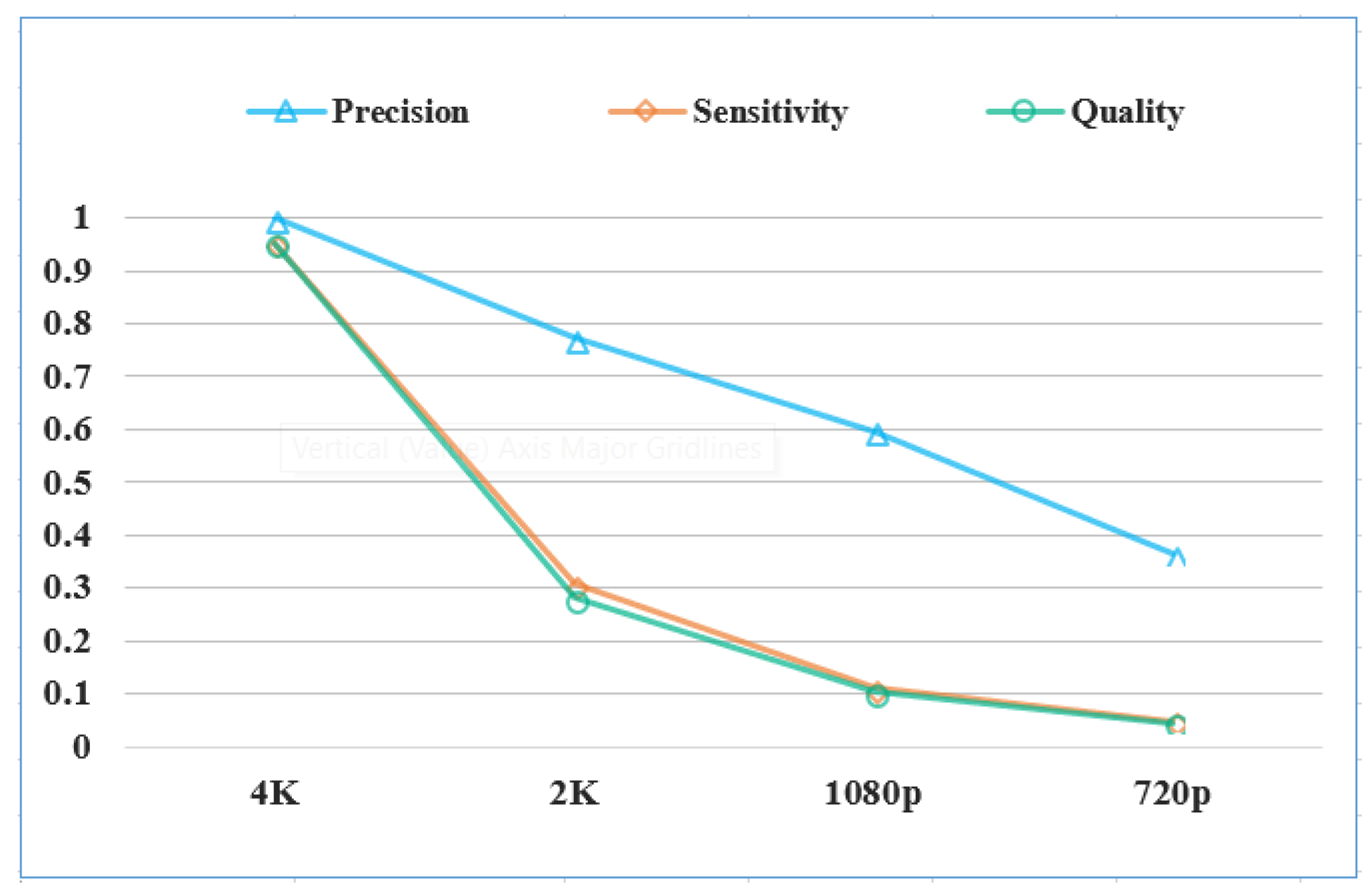
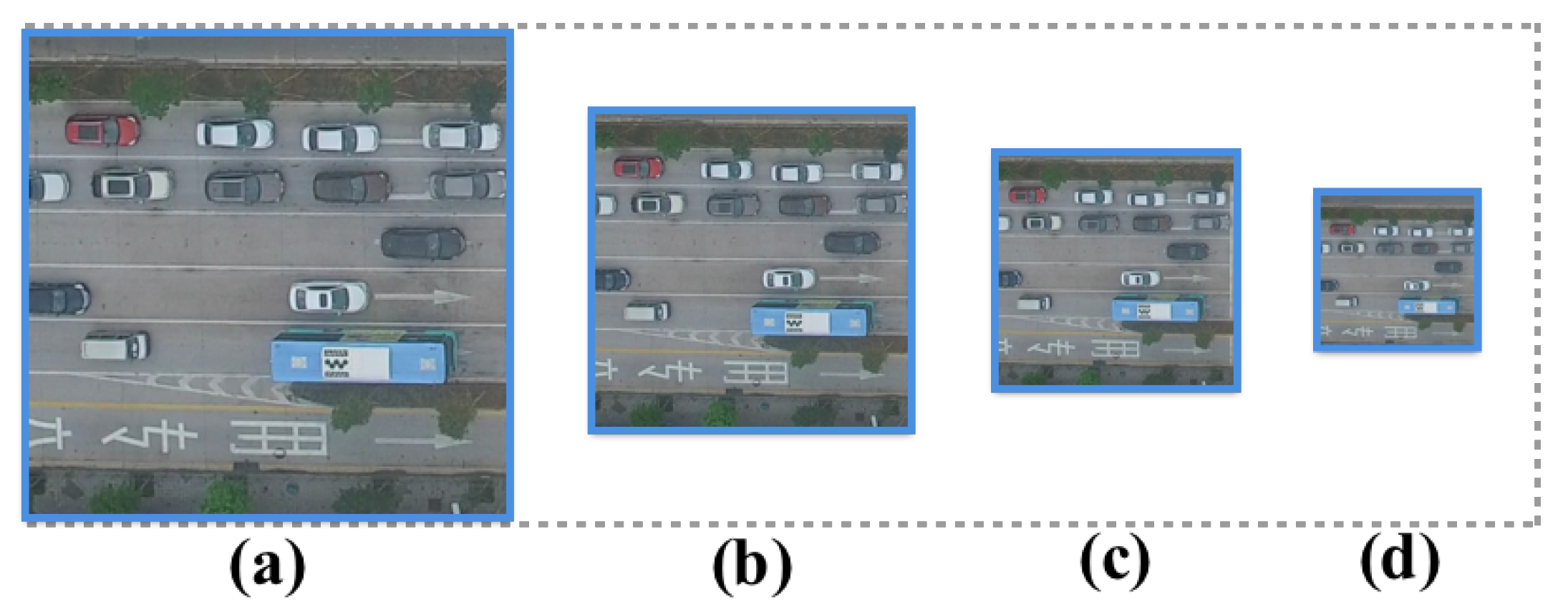
4.1.2. The Impact of Image Resolution
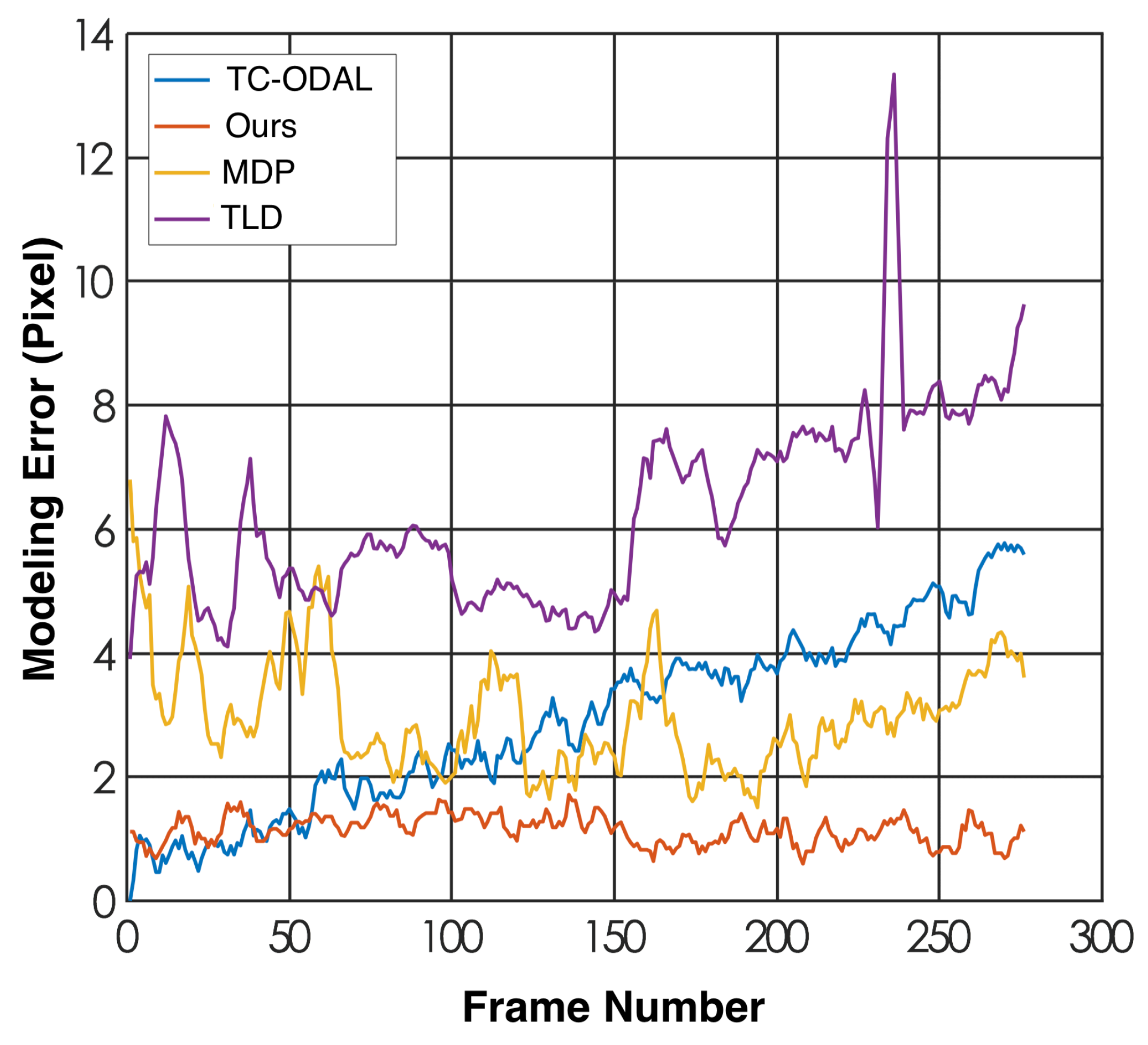
4.1.3. Vehicle Trajectory Modeling
4.2. Vehicle Behavior Recognition
4.2.1. Behavior Recognition by Nearest Neighbor Search
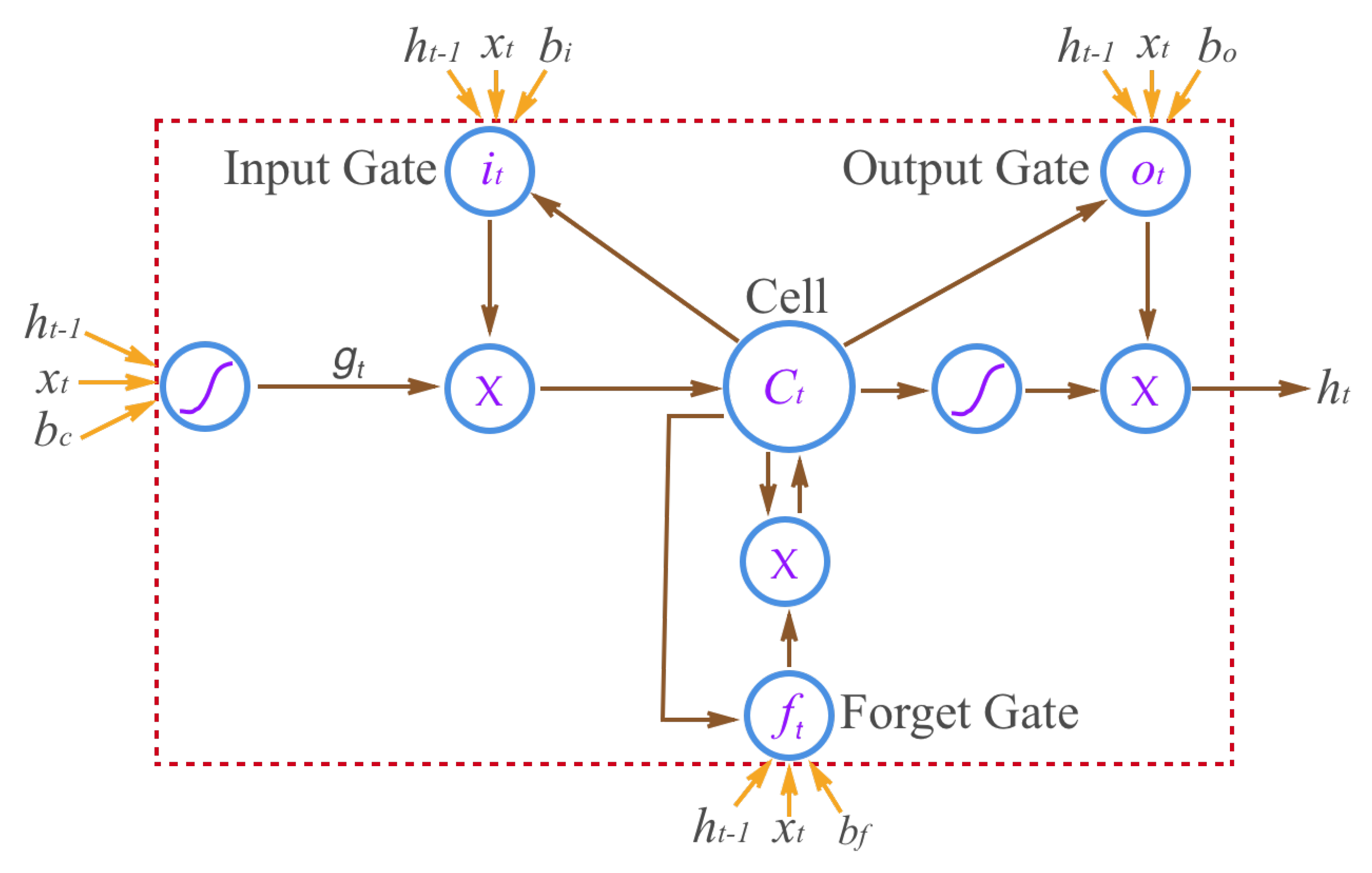
4.2.2. Behavior Recognition by Bidirectional Long Short-Term Memory
5. Concluding Remarks
Author Contributions
Conflicts of Interest
References
- Choi, E.H. Crash Factors in Intersection-Related Crashes: An on-Scene Perspective; Technical Report; The National Highway Traffic Safety Administration: Washington, DC, USA, 2010. [Google Scholar]
- Miller, T.; Kolosh, K.; Fearn, K.; Porretta, K. Injury Facts; 2015 Edition; Technical Report; National Safety Council: Itasca, IL, USA, 2015. [Google Scholar]
- Kim, Z.; Malik, J. Fast vehicle detection with probabilistic feature grouping and its application to vehicle tracking. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; p. 524. [Google Scholar]
- Morris, B.T.; Trivedi, M.M. A survey of vision-based trajectory learning and analysis for surveillance. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1114–1127. [Google Scholar] [CrossRef]
- Cucchiara, R.; Piccardi, M.; Mello, P. Image analysis and rule-based reasoning for a traffic monitoring system. IEEE Trans. Intell. Transp. Syst. 2000, 1, 119–130. [Google Scholar] [CrossRef]
- Wang, L.; Chen, F.; Yin, H. Detecting and tracking vehicles in traffic by unmanned aerial vehicles. Autom. Constr. 2016, 72, 294–308. [Google Scholar] [CrossRef]
- Brooks, C.; Dobson, R.; Banach, D.; Dean, D.; Oommen, T.; Wolf, R.; Havens, T.; Ahlborn, T.; Hart, B. Evaluating the Use of Unmanned Aerial Vehicles for Transportation Purposes; Technical Report; Department of Transportation (MDOT): Michigan City, IN, USA, 2015. [Google Scholar]
- Zhou, H.; Kong, H.; Wei, L.; Creighton, D.C.; Nahavandi, S. Efficient Road Detection and Tracking for Unmanned Aerial Vehicle. IEEE Trans. Intell. Transp. Syst. 2015, 16, 297–309. [Google Scholar] [CrossRef]
- Hinz, S. Detection and counting of cars in aerial images. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; Volume 3, pp. 997–1000. [Google Scholar]
- Yao, W.; Stilla, U. Comparison of two methods for vehicle extraction from airborne LiDAR data toward motion analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 607–611. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 785–800. [Google Scholar]
- Coifman, B.; McCord, M.; Mishalani, R.G.; Redmill, K. Surface transportation surveillance from unmanned aerial vehicles. In Proceedings of the 83rd Annual Meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2004. [Google Scholar]
- Puri, A. A Survey of Unmanned Aerial Vehicles (UAV) for Traffic Surveillance; Department of Computer Science and Engineering, University of South Florida: Tampa, FL, USA, 2005; pp. 1–29. [Google Scholar]
- Moranduzzo, T.; Melgani, F. Automatic car counting method for unmanned aerial vehicle images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Salvo, G.; Caruso, L.; Scordo, A. Urban traffic analysis through a UAV. Procedia-Soc. Behav. Sci. 2014, 111, 1083–1091. [Google Scholar] [CrossRef] [Green Version]
- Kanistras, K.; Martins, G.; Rutherford, M.J.; Valavanis, K.P. Survey of unmanned aerial vehicles (UAVs) for traffic monitoring. In Handbook of Unmanned Aerial Vehicles; Springer: Dordrecht, The Netherlands, 2015; pp. 2643–2666. [Google Scholar]
- Gallagher, K.; Lawrence, P. Unmanned systems and managing from above: the practical implications of UAVs for research applications addressing urban sustainability. In Urban Sustainability: Policy and Praxis; Springer: Cham, Switzerland, 2016; pp. 217–232. [Google Scholar]
- Khan, M.A.; Ectors, W.; Bellemans, T.; Janssens, D.; Wets, G. UAV-Based Traffic Analysis: A Universal Guiding Framework Based on Literature Survey. Transp. Res. Procedia 2017, 22, 541–550. [Google Scholar] [CrossRef]
- Coifman, B.; McCord, M.; Mishalani, R.G.; Iswalt, M.; Ji, Y. Roadway traffic monitoring from an unmanned aerial vehicle. IEE Proc.-Intell. Transp. Syst. 2006, 153, 11–20. [Google Scholar] [CrossRef]
- Skoglar, P.; Orguner, U.; Törnqvist, D.; Gustafsson, F. Road target search and tracking with gimballed vision sensor on an unmanned aerial vehicle. Remote Sens. 2012, 4, 2076–2111. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting Cars in UAV Images With a Catalog-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef] [Green Version]
- Veeraraghavan, H.; Papanikolopoulos, N.P. Learning to recognize video-based spatiotemporal events. IEEE Trans. Intell. Transp. Syst. 2009, 10, 628–638. [Google Scholar] [CrossRef]
- Porter, B.E.; England, K.J. Predicting red-light running behavior: A traffic safety study in three urban settings. J. Saf. Res. 2000, 31, 1–8. [Google Scholar] [CrossRef]
- Kasper, D.; Weidl, G.; Dang, T.; Breuel, G.; Tamke, A.; Wedel, A.; Rosenstiel, W. Object-oriented Bayesian networks for detection of lane change maneuvers. IEEE Intell. Transp. Syst. Mag. 2012, 4, 19–31. [Google Scholar] [CrossRef]
- Hu, W.; Xiao, X.; Xie, D.; Tan, T. Traffic accident prediction using vehicle tracking and trajectory analysis. In Proceedings of the 2003 IEEE International Conference on Intelligent Transportation Systems, Shanghai, China, 12–15 October 2003; Volume 1, pp. 220–225. [Google Scholar]
- Song, H.S.; Lu, S.N.; Ma, X.; Yang, Y.; Liu, X.Q.; Zhang, P. Vehicle behavior analysis using target motion trajectories. IEEE Trans. Veh. Technol. 2014, 63, 3580–3591. [Google Scholar] [CrossRef]
- Barth, A.; Franke, U. Estimating the driving state of oncoming vehicles from a moving platform using stereo vision. IEEE Trans. Intell. Transp. Syst. 2009, 10, 560–571. [Google Scholar] [CrossRef]
- Saligrama, V.; Konrad, J.; Jodoin, P.M. Video anomaly identification. IEEE Signal Process. Mag. 2010, 27, 18–33. [Google Scholar] [CrossRef]
- Huang, H.; Cai, Z.; Shi, S.; Ma, X.; Zhu, Y. Automatic detection of vehicle activities based on particle filter tracking. In Proceedings of the Second Symposium International Computer Science and Computational Technology (ISCSCT ’09), Huangshan, China, 26–28 December 2009; pp. 381–384. [Google Scholar]
- Pucher, M.; Schabus, D.; Schallauer, P.; Lypetskyy, Y.; Graf, F.; Rainer, H.; Stadtschnitzer, M.; Sternig, S.; Birchbauer, J.; Schneider, W.; et al. Multimodal highway monitoring for robust incident detection. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 837–842. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR ’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 Jun 2014; pp. 2147–2154. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Mills-Tettey, G.A.; Stentz, A.; Dias, M.B. The Dynamic Hungarian Algorithm for the Assignment Problem with Changing Costs; Carnegie Mellon University: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Atev, S.; Miller, G.; Papanikolopoulos, N.P. Clustering of vehicle trajectories. IEEE Trans. Intell. Transp. Syst. 2010, 11, 647–657. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kamijo, K.i.; Tanigawa, T. Stock price pattern recognition—A recurrent neural network approach. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; pp. 215–221. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Hanson, J.; Yang, Y.; Paliwal, K.; Zhou, Y. Improving protein disorder prediction by deep bidirectional long short-term memory recurrent neural networks. Bioinformatics 2016, 33, 685–692. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2, pp. 207–212. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2006; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Leitloff, J.; Rosenbaum, D.; Kurz, F.; Meynberg, O.; Reinartz, P. An operational system for estimating road traffic information from aerial images. Remote Sens. 2014, 6, 11315–11341. [Google Scholar] [CrossRef] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4705–4713. [Google Scholar]
- Chollet, F. Github. Available online: https://github.com/fchollet/keras (accessed on 5 June 2018).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Designand Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Hervieu, A.; Bouthemy, P.; Le Cadre, J.P. A HMM-based method for recognizing dynamic video contents from trajectories. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; Volume 4, pp. IV-533–IV-536. [Google Scholar]
- Morris, B.T.; Trivedi, M.M. Trajectory learning for activity understanding: Unsupervised, multilevel, and long-term adaptive approach. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2287–2301. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Ruan, T.; Wu, J.; Dong, T. Vehicle Behavior Recognition Method Based on Quadratic Spectral Clustering and HMM-RF Hybrid Model. Comput. Sci. 2016, 43, 288–293. [Google Scholar]
- Altché, F.; De La Fortelle, A. An LSTM network for highway trajectory prediction. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 353–359. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | TP ↑ | FP ↓ | FN ↓ | Precision ↑ | Sensitivity ↑ | Quality ↑ |
|---|---|---|---|---|---|---|
| Faster-RCNN | 49 | 6 | 36 | 0.890 | 0.576 | 0.538 |
| SSD | 68 | 2 | 17 | 0.971 | 0.80 | 0.782 |
| YOLOv3 | 71 | 0 | 14 | 1.0 | 0.835 | 0.835 |
| RetinaNet | 81 | 0 | 4 | 1.0 | 0.953 | 0.953 |
| Model | Faster-RCNN | SSD | YOLOv3 | RetinaNet |
|---|---|---|---|---|
| Training Time ↓ | 37 h 29 m | 24 h 58 m | 18 h 29 m | 20 h 15 m |
| Testing Speed ↑ | 15.3 | 44.1 fps | 72.3 fps | 60.2 fps |
| TLD | TC-ODAL | MDP | Ours | |
|---|---|---|---|---|
| Overall Error (pixel) ↓ | 1743 | 796 | 632 | 316 |
| Method | TC-ODAL | MDP | TLD | Ours |
|---|---|---|---|---|
| Tracking speed (fps) | 78.9 | 65.1 | 58.4 | 82.5 |
| Bebavior | LCSS-KMeans | LCSS-Spectral | DSC (Ours) |
|---|---|---|---|
| Go straight | 0.813 | 0.802 | 0.910 |
| Right turn | 0.727 | 0.764 | 0.857 |
| Left turn | 0.667 | 0.769 | 0.882 |
| Average | 0.756 | 0.782 | 0.899 |
| Method | LCSS-KMeans | LCSS-Spectral | DSC (Ours) |
|---|---|---|---|
| Training Time (s) ↓ | 11.3 | 25.8 | 43.2 |
| Testing Speed (tps) ↑ | 62.1 | 57.5 | 55.6 |
| Behavior | HMM | A-HMM | HMM-RF | HMM-SVM | LSTM | T-BiLSTM (Ours) |
|---|---|---|---|---|---|---|
| Go straight | 0.825 | 0.893 | 0.931 | 0.832 | 0.924 | 0.965 |
| Right turn | 0.703 | 0.803 | 0.856 | 0.752 | 0.896 | 0.938 |
| Left turn | 0.671 | 0.733 | 0.832 | 0.714 | 0.875 | 0.916 |
| Average | 0.733 | 0.810 | 0.873 | 0.766 | 0.898 | 0.940 |
| Method | HMM | A-HMM | HMM-RF | HMM-SVM | LSTM (CPU/GPU) | T-BiLSTM (Ours) (CPU/GPU) |
|---|---|---|---|---|---|---|
| Training Time (s) ↓ | 296.4 | 331.1 | 395.7 | 388.5 | 1351.5/136.6 | 526.6/47.7 |
| Testing Speed (tps) ↑ | 65.2 | 62.1 | 59.9 | 58.1 | 37.1/40.3 | 38.2/59.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Sun, K.; Jia, S.; Lin, W.; Hou, X.; Liu, B.; Qiu, G. Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition. Remote Sens. 2018, 10, 887. https://doi.org/10.3390/rs10060887
Zhu J, Sun K, Jia S, Lin W, Hou X, Liu B, Qiu G. Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition. Remote Sensing. 2018; 10(6):887. https://doi.org/10.3390/rs10060887
Chicago/Turabian StyleZhu, Jiasong, Ke Sun, Sen Jia, Weidong Lin, Xianxu Hou, Bozhi Liu, and Guoping Qiu. 2018. "Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition" Remote Sensing 10, no. 6: 887. https://doi.org/10.3390/rs10060887
APA StyleZhu, J., Sun, K., Jia, S., Lin, W., Hou, X., Liu, B., & Qiu, G. (2018). Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition. Remote Sensing, 10(6), 887. https://doi.org/10.3390/rs10060887