1. Introduction
Recently, with the rapid development of remote sensing technology and the growing deployment of remote sensing instruments, we have the opportunities to obtain a huge number of high-resolution remote sensing images [
1,
2,
3,
4]. This phenomenon generates a large demand for automatic and precise identification and classification of land-use and land-cover (LULC) scenes from these remote sensing images [
5,
6,
7,
8,
9,
10]. Aerial scene classification, which aims to automatically label an aerial scene image according to a set of semantic categories, has a wide range of applications, from civil to military purposes [
11]. At the same time, aerial scene classification has drawn much attention from the remote sensing community.
Generally, effective feature extraction is the key for accurate aerial scene classification. Besides traditional methods using hand-crafted features [
12,
13,
14,
15], deep convolutional neural network (CNN)-based approaches yield amazing performance in recent years [
16,
17,
18,
19]. The frequently-used CNN models include CaffeNet [
20], AlexNet [
21], VGG Net [
22], GoogLeNet [
23], and ResNet [
24]. So far, CNNs have demonstrated outstanding ability to extract high-level discriminative features on aerial scene classification task. One can refer to [
25,
26,
27] for more details.
Despite the impressive results achieved with CNN-based methods, learning effective features from aerial scene images still poses various challenges. First, unlike natural images, aerial scene images have high intra-class variations. Specifically, objects in the same scene category may appear at different sizes and different orientations. In addition, due to the different imaging conditions, e.g., the altitude of the imaging devices and the solar elevation angles, the appearance of the same scene may also be different. Second, the scene images belonging to different classes may share similar objects and structural variations, which results in small inter-class dissimilarity. Generally speaking, a good representation of aerial scene images is the key to success in this area. In other words, what features we use and how to use these features are becoming more and more important in the field of aerial scene classification.
In this paper, we propose two effective architectures to further improve the classification performance for aerial scene images, in which we employ a pre-trained CNN (GoogLeNet) as a feature extractor. The first architecture, i.e., texture coded two-stream deep architecture, uses raw RGB network stream and mapped local binary patterns (LBP) coded network stream to extract two different sets of features and fuses these two sets of features by using a novel deep feature fusion model. The second architecture, i.e., saliency coded two-stream deep architecture, investigates to what extent saliency coded network stream complement the raw RGB network stream and combines them using the same deep feature fusion model as the first architecture. In the experiments, we evaluate our architectures and compare them with several recent methodologies on three publicly available remote sensing scene datasets. Experimental results demonstrate that our proposed methods outperform the baseline methods and achieve state-of-the-art results on these three utilized datasets.
The remainder of this paper is arranged as follows.
Section 2 represents the related works including aerial scene classification methods and feature fusion methods.
Section 3 provides details about our proposed frameworks for aerial scene classification. The experimental results and analysis are presented in
Section 4, followed by a discussion in
Section 5. Finally,
Section 6 summarizes this paper.
2. Related Works
In this section, we briefly review the methods for aerial scene classification and feature fusion.
2.1. Methods for Aerial Scene Classification
Generally speaking, the methods in the field of aerial scene classification can be categorized three sorts of methods, i.e., methods based on low-level scene features, methods based on mid-level scene features and methods based on high-level scene features, as shown in
Figure 1. In what follows, we review these methods in detail.
Methods based on low-level scene features: In these methods, the way of characterizing input image patches is to apply low-level scene features such as texture feature, structure feature, and spectral feature, to name a few. Four low-level methods are commonly utilized, including LBP [
28], Scale Invariant Feature Transform (SIFT) [
29], Color Histogram (CH) [
30] and GIST [
31]. However, one type of low-level features may work badly in some cases; therefore, researchers investigate a combination of different types of low-level visual features to improve the results. Luo et al. [
32] combined the radiometric features, the Gray Level Co-Occurrence Matrix (GLCM) features and the Gaussian wavelet features to produce a multiple-feature representation.
Methods based on mid-level scene features: Mid-level methods are more suitable for representing the complex image textures and structures with more compact feature vectors. Bag of Visual Words (BoVW) [
33] is one of the most popular encoding approaches. Because of its good performance, this approach and its modifications have been widely used for obtaining mid-level representation of aerial scene images [
34,
35,
36,
37,
38].
Furthermore, other approaches, e.g., Spatial Pyramid Matching (SPM) [
39], Locality-constrained Linear Coding (LLC) [
40], probabilistic Latent Semantic Analysis (pLSA) [
41], Latent Dirichlet Allocation (LDA) [
42], Improved Fisher Kernel (IFK) [
43], and Vector of Locally Aggregated Descriptors (VLAD) [
44] have also been proposed to produce mid-level scene features for aerial scene images.
Methods based on high-level scene features: Compared with the low- and mid-level scene features based approaches, deep learning based methods have the ability to obtain more significant and informative features, which results in better performance [
45,
46]. Aryal et al. [
47] proposed a novel deep learning data analytics approach, i.e., restricted Boltzmann machine network, to learn urban objects from high resolution image. Moreover, Dutta et al. [
48] utilized deep recurrent Elman neural network for accurately estimating continental fire incidence from climate data.
CNN is one of the most widely used deep learning algorithms, which is skilled in image processing. Therefore, we only focus on the CNN model in our manuscript. The deep features extracted by CNN are called high-level features. The methods based on high-level features can be divided into the following five groups:
- (1)
The approaches in the first group use the pre-trained CNNs to extract features from the input aerial scene images. In this group, all CNN models are pre-trained on the ImageNet 2012 dataset [
49]. Penatti et al. [
45] demonstrated the generalization ability of CNN models, i.e., OverFeat [
50] and CaffeNet [
20], in the scenario of aerial scene classification. Recently, two new large-scale aerial scene image datasets, i.e., Aerial Image Dataset (AID) [
51] and Northwestern Polytechnical University-REmote Sensing Image Scene Classification 45 (NWPU-RESISC45) [
52], have been constructed, and pre-trained CNN models achieved higher accuracies over the low- and mid-level features based methods.
- (2)
The methods in the second group train the CNN models from scratch, in which the filter weights are all randomly initialized and then trained for the target remote sensing scene datasets. In [
53,
54], the authors investigated the performance of the trained-from-scratch CNN models in the field of aerial scene classification, and the results showed that the trained-from-scratch CNN models get a drop in classification accuracy compared to the pre-trained CNN models. The authors thought that the relatively low performance of the trained-from-scratch CNN models was mainly due to the limited training data.
- (3)
The methods in the third group fine-tune the pre-trained CNN models on the target aerial scene datasets and use the fine-tuned architectures to extract features for classification. In [
52,
53,
54], the authors fine-tuned some popular-used CNN models, and the experimental results pointed that the fine-tuning strategy can help the CNN models get much higher classification accuracies than both the full-training strategy and the “using pre-trained CNN models as feature extractors” strategy. In addition, Liu et al. [
55] proposed a novel scene classification method through triplet networks, in which the triplet networks were pre-trained on ImageNet [
49] and followed by fine-tuning over the target datasets. Their triplet networks reported a state-of-the-art performance in aerial scene classification tasks.
- (4)
The methods in the fourth group generate the final image representation by reprocessing the features extracted from the pre-trained CNN models. In [
56], the multiscale dense convolutional features extracted from pre-trained CNNs were fed into four main parts, i.e., visual words encoding, correlogram extraction, correlation encoding, and classification, and state-of-the-art results were achieved. Cheng et al. [
57] proposed a feature representation method for remote sensing image scene classification, termed bag of convolutional features (BoCF), which encodes the convolutional feature descriptors. Moreover, Yuan et al. [
58] encoded the extracted deep feature by using the locality-constrained affine subspace coding (LASC) method, which can obtain more discriminative deep features than directly extracted from CNN models. In addition, Liu et al. [
59] concatenated the extracted convolutional features to generate the deeply local descriptors, and subsequently, selected a feature encoding method, i.e., Fisher encoding with Gaussian mixture model (GMM) clustering, to process the deeply local descriptors. In another work, Liu et al. [
60] proposed a linear transformation of deep features, in which the discriminative convolution filter (DCF) learning approach was performed on the local patches obtained from raw deep features.
- (5)
The methods in the fifth group use some fusion technologies to conduct the aerial scene classification. Anwer et al. [
61] constructed a texture coded two-stream deep architecture which fuses both raw RGB features and texture coded features. However, its fusion approach is based on conventional concatenation strategy. Moreover, Chaib et al. [
62] proposed to use discriminant correlation analysis (DCA) to process the extracted two sets of features, and combine the processed features through conventional fusion strategy, i.e., concatenation and addition. Li et al. [
63] proposed to use a PCA/spectral regression kernel discriminant analysis (SRKDA) method to fuse the multiscale convolutional features encoded by a multiscale improved Fisher kernel coding method and the features of fully connected layers. In addition, Ye et al. [
64] utilized the features from intermediate layers, and subsequently, created a parallel multi-stage (PMS) architecture formed by three sub-models, i.e., the low CNN, the middle CNN and the high CNN. The study [
65] adaptively combined the features from lower layers and fully connected layers, in which the feature fusion operation was performed via a linear combination instead of concatenation. Their classification results all showed significant advantages over those “stand-alone” approaches. At the same time, some score-level fusion approaches [
11,
66] were proposed for aerial scene classification, which can also achieve impressive performance on the publicly available remote sensing scene datasets.
2.2. Feature Fusion
In the section of methods based on high-level scene features, we have introduced some popular feature-level fusion methods for aerial scene classification. Nevertheless, creating a superior feature-level fusion strategy for higher aerial scene classification accuracy is still a challenging task. In this section, we briefly review some feature fusion methods which are mainly used in video action recognition tasks and face recognition tasks. The idea of these methods can provide guidance for designing our new feature-level fusion method for aerial scene classification task.
Chowdhury et al. [
67] used one intriguing new architecture termed bilinear CNN (BCNN) [
68] to conduct face recognition, in which fusion of two CNN features was achieved by computing the outer product of convolutional-layer outputs. BCNN was also used for video action recognition [
69]. Moreover, Park et al. [
70] proposed to apply element-wise product to fuse multiple sources of knowledge in deep CNNs for video action recognition. In addition, a neural network based feature fusion method has been proposed in [
71] where the spatial and the motion features are fused for video classification. In another work, Bodla et al. [
72] also proposed a deep feature fusion network to fuse the features generated by different CNNs for template-based face recognition.
3. Proposed Architecture
Here, we first give the description of the methods of mapping LBP codes and saliency detection. Then, we describe the texture coded two-stream deep architecture and the saliency coded two-stream deep architecture. In the end, we propose a novel two-stream deep feature fusion model.
3.1. Mapping LBP Codes
LBP codes have been widely used in the field of texture recognition. At the same time, LBP is one of the most commonly used methods for the description of texture. In addition to the texture recognition and description, LBP codes have also been used for tasks such as person detection, face recognition, and image retrieval, to name a few.
LBP codes capture the local gray-scale distribution, produced by applying thresholds on the intensity values of the pixels in small neighborhoods by the intensity value of each neighborhood’s central pixel as the threshold. The resulting codes are binary numbers ((0) lower than threshold value or (1) higher than the threshold value). The LBP codes which is used for describing the image texture features are calculated by,
where
denotes the
N sampling points in the circular region,
is the center of the circular region,
is a binomial factor for each sign
, and R is the radius of this region. The thresholding function
is defined as follows:
The sign function describes not only the two states between the center point and its neighbors, but also shorten the difference value range of the joint distribution. In this way, the simple values can represent the joint distribution.
Under circumstances of the neighborhood containing eight other pixels, the binary string through the LBP code computation is treated as an eight-bit number between 0 and 255. The final representation is acquired by computing the histogram of LBP codes from the entire image region. The final representation normalizes for translation and is invariant to monotonic photometric transformations.
The unordered nature of the LBP code values is not suited as the input of CNN models. Levi et al. [
73] proposed a LBP code mapping method which uses the Multi Dimensional Scaling (MDS) [
74,
75] to transform the unordered LBP code values to points in a metric space. The dissimilarity matrix
can be defined as:
where
and
are the LBP codes,
and
are the mapping of codes
and
, respectively.
denotes the distance (dissimilarity) between LBP codes
and
. The code-to-code dissimilarity score is based on an approximation to the Earth Mover’s Distance (EMD) [
76]. The EMD can account for both the different bit values and their locations.
where
is the Cumulative Distribution Function (CDF) of the bit values,
is the L1 norm. The authors of [
73] also account for the cyclic nature of LBP codes. The modified, cyclic distance,
is defined as:
where
and
denote the modified codes through appending a single 0-valued bit as the new least significant bit of each code. The distance
is computed by Equation (
5) and the
operation can rearrange code values in reverse order.
3.2. Saliency Detection
In general, the actual remote sensing scene image usually contains a large amount of interference information in addition to the distinctive visual region. Cognitive psychology studies have shown that the human visual system adopts a serial computing strategy in the analysis of a complex input scene image. This strategy employs the selective visual attention mechanism [
77,
78] to select the specific area of the scene, i.e., the distinctive visual region, according to the local characteristics of the image, and then move the region to the foveal area with high resolution through the rapid eye movement scan, which can achieve attention to the region for more detailed observation and analysis. The selective visual attention mechanism can help the brain to filter out the plain region and focus on the distinctive visual region. Zheng et al. [
79] proposed a saliency detection model that could emulate the human visual attention. By employing the saliency detection model, we have the opportunity to obtain more significant and informative features.
The saliency value of patch can be obtained through two stages, i.e., the global perspective and the local perspective.
The global perspective is obtained by computing the histogram of word occurrence:
where
k represents the word index,
denotes the occurrence frequency of the visual word
,
f represents the feature in the feature set
F and
is the visual vocabulary.
Then, the novelty factor
is calculated through the “repetition suppression principle” [
80]:
Finally, the local perspective can get the dissimilarities between one local patch and the global image. The saliency value of patch
is computed as follows:
where
denotes the frequency of occurrence of the word
for the local patch
.
3.3. Two-Stream Deep Architecture
It is well known that a large proportion of noted CNNs take RGB images in the ImageNet dataset [
49] as input. Of course, the mapped LBP images and the processed images through saliency detection can also be fed into the CNN models, which can obtain texture coded features and saliency coded features, respectively.
In general, the two-stream deep architecture contains an RGB based CNN model, an auxiliary CNN model and a feature fusion model. In this work, we investigate approaches to complement the RGB based CNN model using different auxiliary models, i.e., the mapped LBP coded CNN model and the saliency coded CNN model.
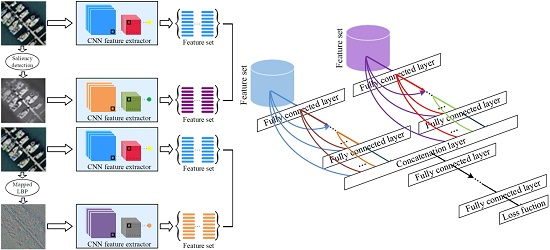
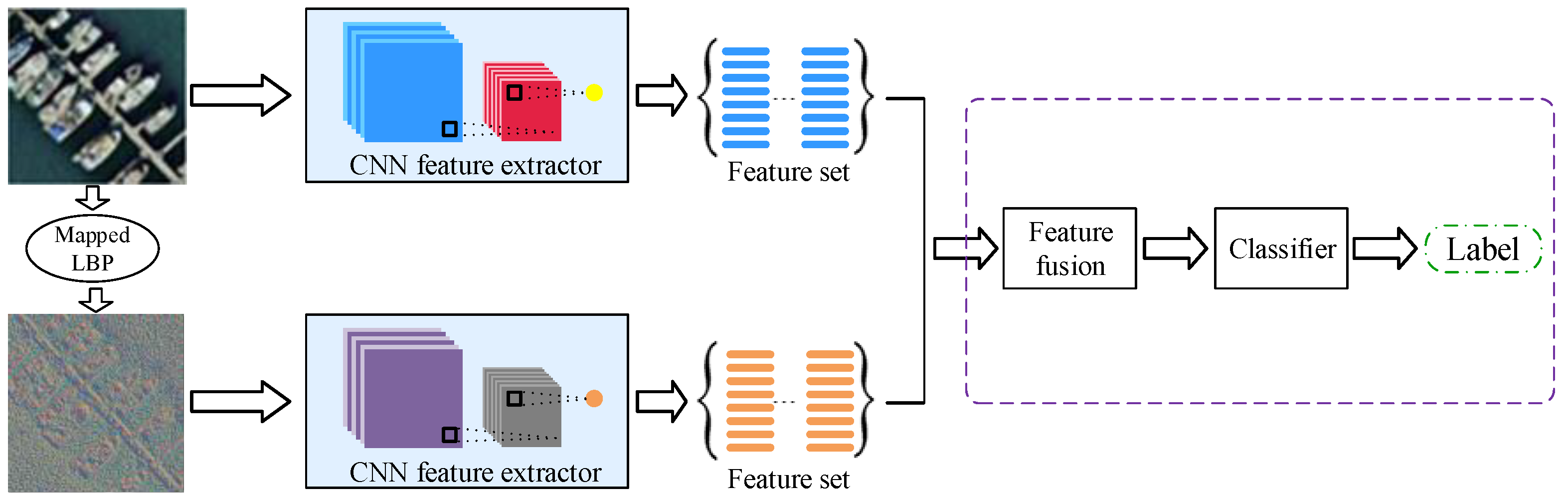
3.3.1. Texture Coded Two-Stream Deep Architecture
Anwer et al. [
61] proposed a deep model, i.e., TEX-Net-LF, by designing a two-stream architecture in which texture coded mapped images are used as the second stream and fuse it with the RGB image stream. However, the feature fusion strategy of the TEX-Net-LF model is a conventional concatenation strategy. In this part, the mapped LBP coded CNN model is used as the auxiliary model, which complements the raw RGB coded CNN model. Here, we propose an effective texture coded two-stream deep architecture which combines the RGB and mapped LBP coded networks by using a novel deep feature fusion strategy. The raw RGB network stream and the mapped LBP coded network stream can capture the appearance and texture information respectively. In this architecture, we employ pre-trained CNN model as feature extractor to deal with the raw RGB images and the mapped LBP images.
Figure 2 shows this texture coded two-stream deep architecture designed to combine the raw RGB network stream and the mapped LBP coded network stream. The raw RGB network stream takes RGB images as input, whereas the mapped LBP coded network stream takes mapped LBP images as input. In our framework, both raw RGB network stream and mapped LBP coded network stream are trained separately on the ImageNet ILSVRC 2012 dataset [
49].
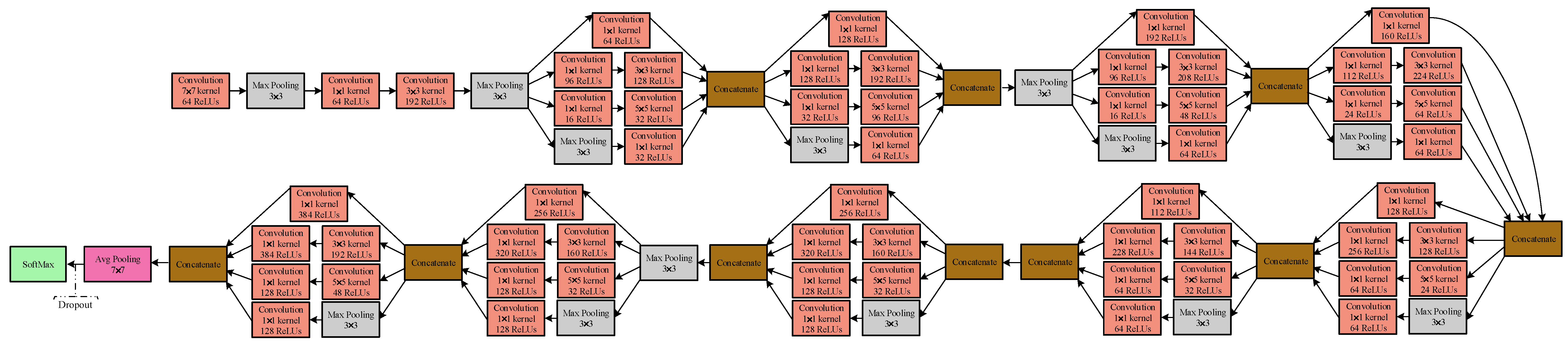
The GoogLeNet model can get more informative features because of its deeper architecture. Therefore, the GoogLeNet model is applied as feature extractor in our architecture. The schematic view of the GoogLeNet model is depicted in
Figure 3. The GoogLeNet model [
23], a 22-layer CNN architecture, contains more than 50 convolutional layers distributed in the inception modules. In this work, a pre-trained GoogLeNet model is employed as a feature extractor to extract features from the last pooling layer, which results in a vector of 1024 dimensions for an input image.
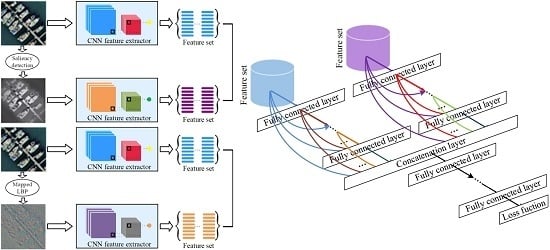
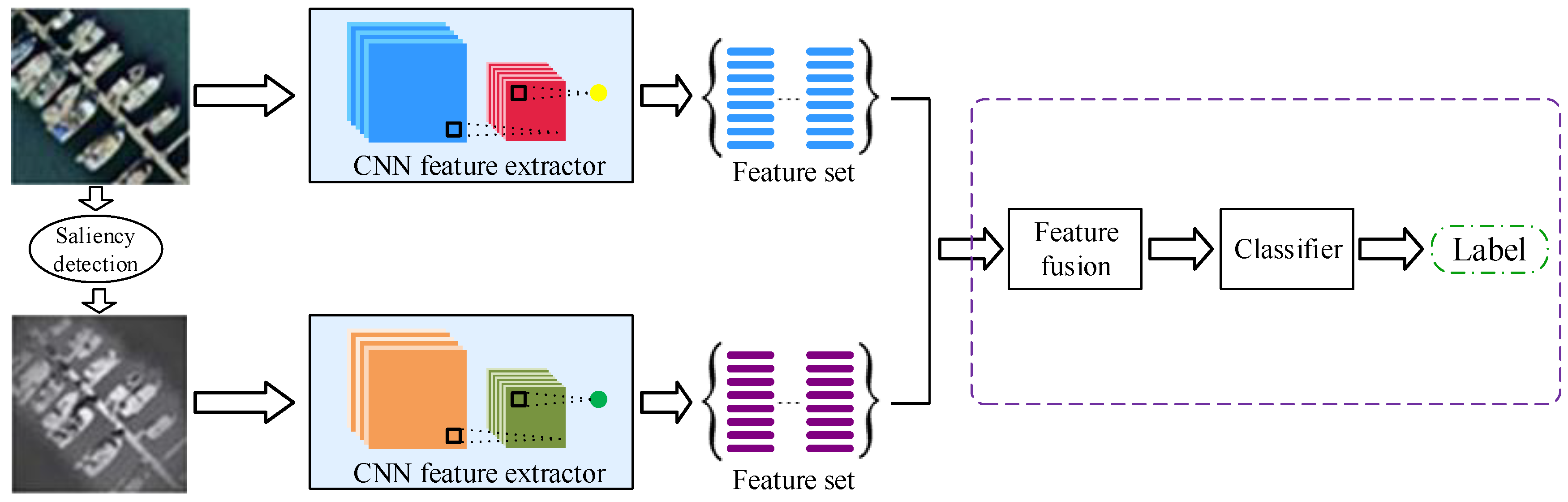
3.3.2. Saliency Coded Two-Stream Deep Architecture
Other than texture coded two-stream deep architecture, we also propose a saliency coded two-stream deep architecture using both RGB images and the processed images through saliency detection. Conspicuous information can be obtained through the saliency coded network stream, which is beneficial for accurate classification. We also use pre-trained GoogLeNet as a feature extractor by extracting features from the last pooling layer.
Figure 4 shows the saliency coded two-stream deep architecture. In this framework, we use the ImageNet dataset [
49] to train a raw RGB network stream and saliency coded network stream separately. Once separately trained, these two streams are combined using a new fusion strategy that is proposed in the next section.
3.4. Two-Stream Deep Feature Fusion Model
Up to now, feature fusion has become a robust and effective way to boost the performance of aerial scene classification. The fused features contain more rich information, which can describe the aerial scene image well. Our proposed two-stream deep feature fusion model is aimed to combine different types of features into a single feature vector with more discriminant information than the input raw features.
Concatenation and addition operations are the most commonly used strategies to fuse the two different types of extracted features. Concatenation operation, also named as serial feature fusion strategy, simply concatenates two different types of features into one single feature vector. It assumes that
and
are the two different types of extracted features with
a,
b vector dimension, respectively. Then, the fused feature vector is
with
vector dimension. Addition operation, also termed parallel feature fusion strategy, requires that the two different types of extracted features should have the same dimensionality. The fused feature vector is represented as follows:
where
i is the imaginary unit.
Two-stream deep architecture has the ability to extract two different types of features from the input scene image. Nevertheless, the existing feature fusion approaches have low utilization level of the two sets of extracted features. Hence, a novel two-stream deep feature fusion model is proposed, which is described in
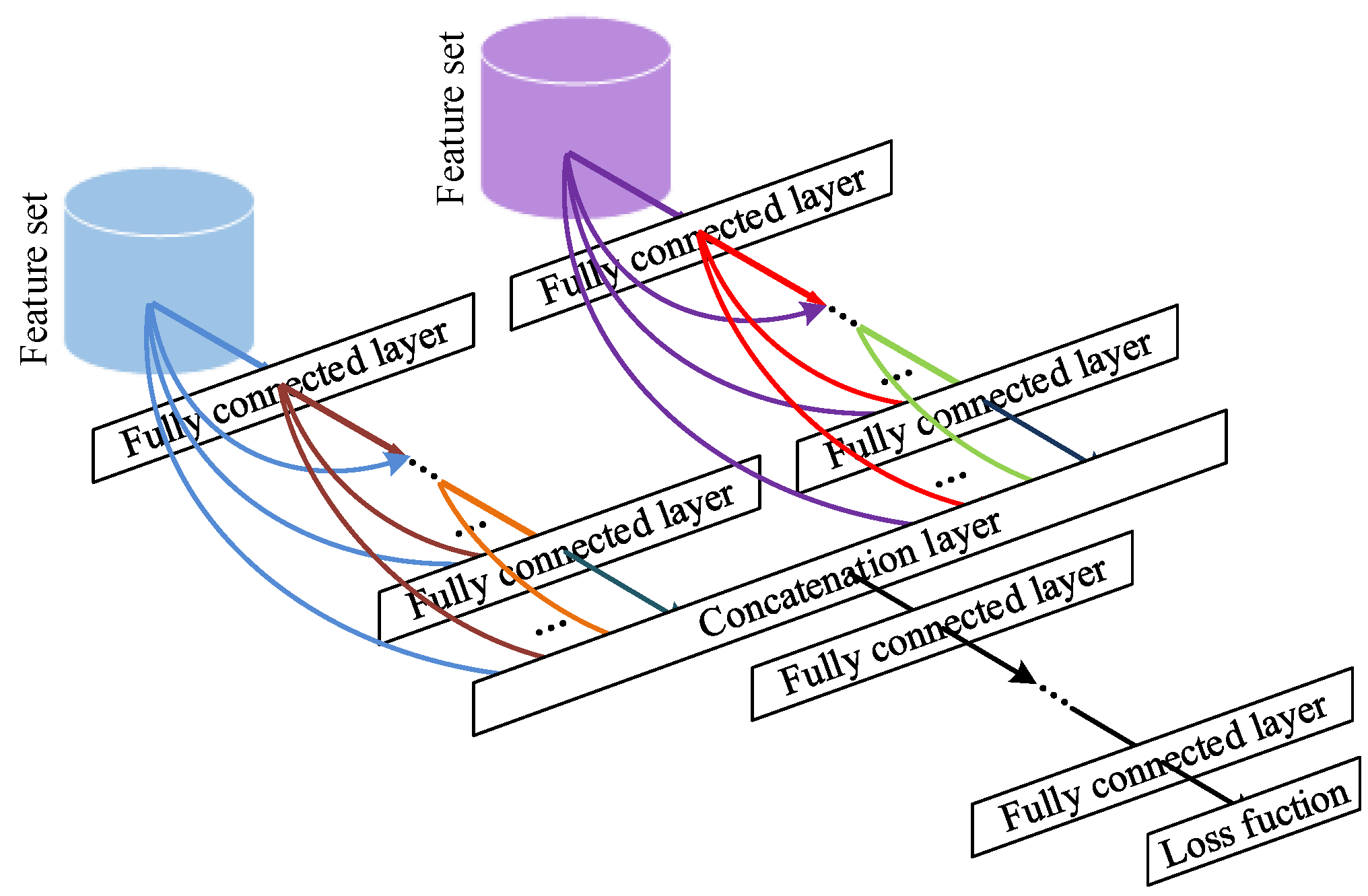
Figure 5.
The idea of this new feature-level fusion strategy is derived from the dense connectivity in a Dense Convolutional Network (DenseNet) [
81]. The dense connectivity means the direct connections from any layer to all subsequent layers. Therefore, the current layer takes the feature maps of all preceding layers as its input. The output of the
layer in Dense Block of DenseNet is defined as follows:
where
represents the output feature maps of the
layer,
is a single image,
is a composite function which includes three operations: batch normalization (BN) [
82], rectified linear units (ReLU) [
83], and convolution,
refers to the concatenation of the feature maps produced in layers
.
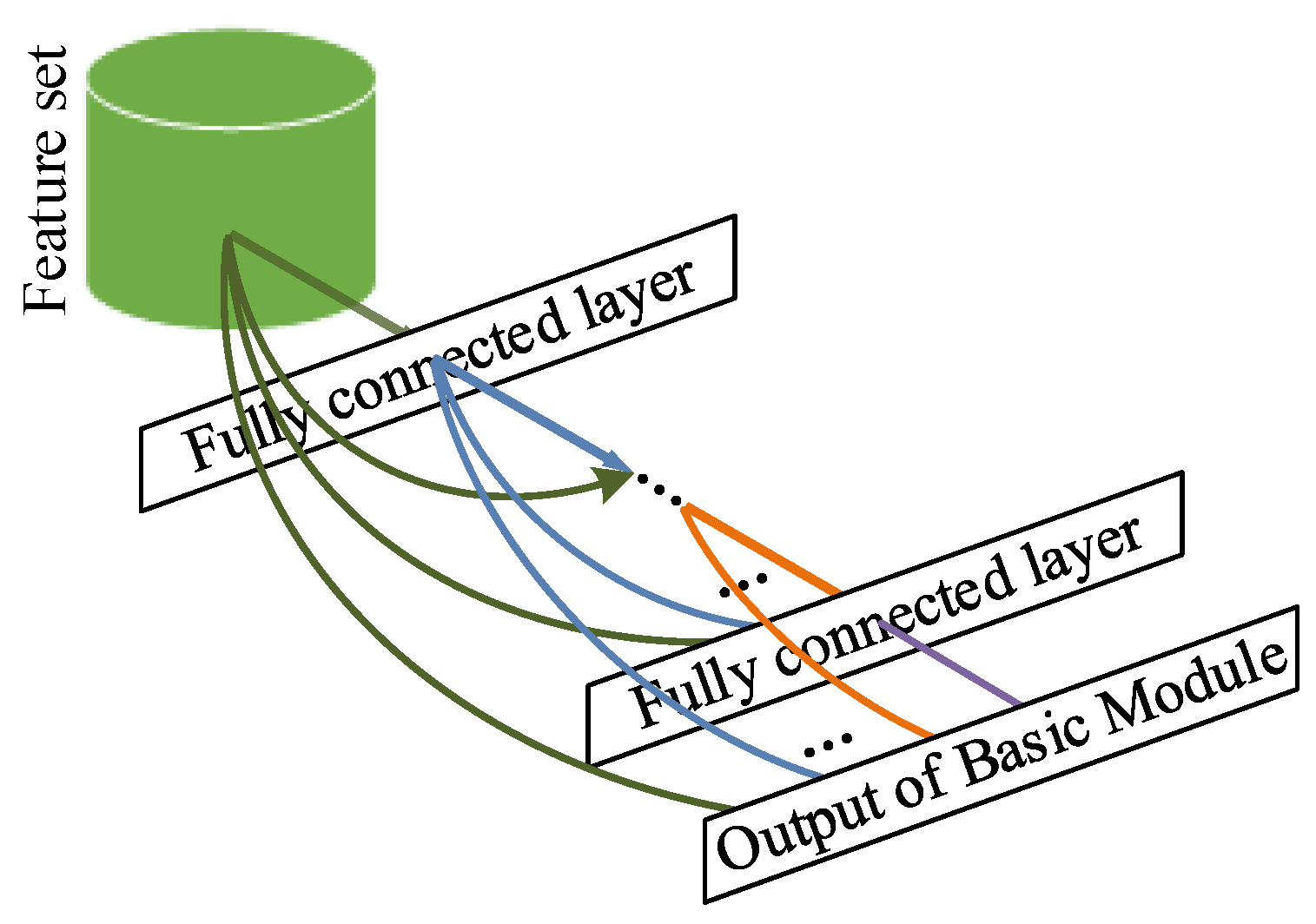
We summarize this idea as basic module of our proposed feature-level fusion strategy in
Figure 6. The input of the basic module is the feature vector extracted by the pre-trained GoogLeNet model. The basic module is comprised of a number of fully-connected layers and concatenation layers. The current fully-connected layer takes the output feature vectors of all preceding layers as its input, whose connection type is quite similar to the dense block in DenseNet. The concatenation layer is applied to concatenate the input of the fully-connected layer, which is depicted by arrows gathering in
Figure 6. In this basic module, every fully-connected layer is followed by a nonlinear activation function. The output of the
layer in basic module is defined as follows:
where
represents the output feature vector of the
layer,
is the extracted feature vector,
is a nonlinear activation function, and
is the concatenation of the output feature vectors of all preceding fully-connected layers.
As shown in
Figure 5, the two different feature sets extracted by two streams are fed into two basic modules, respectively. The outputs of the two basic modules are then concatenated together, followed by a series of fully-connected layers. Note that nonlinear activation function is connected to each fully-connected layer.
Our neural network based feature fusion approach can be regarded as a collection of nonlinear high-dimensional projections due to the fully-connected layers. Meanwhile, we borrow the idea of dense block from DenseNet into our basic module, which could encourage feature re-use and strengthen feature propagation. There is one case in which the earlier layer may collapse information to produce short-term features, and the lost information can be regained by using the architecture that has the direct connection to its preceding layer. Such feature fusion approach helps to extract more representative features since we fuse the two different types of features, and this can lead to a better classification performance.
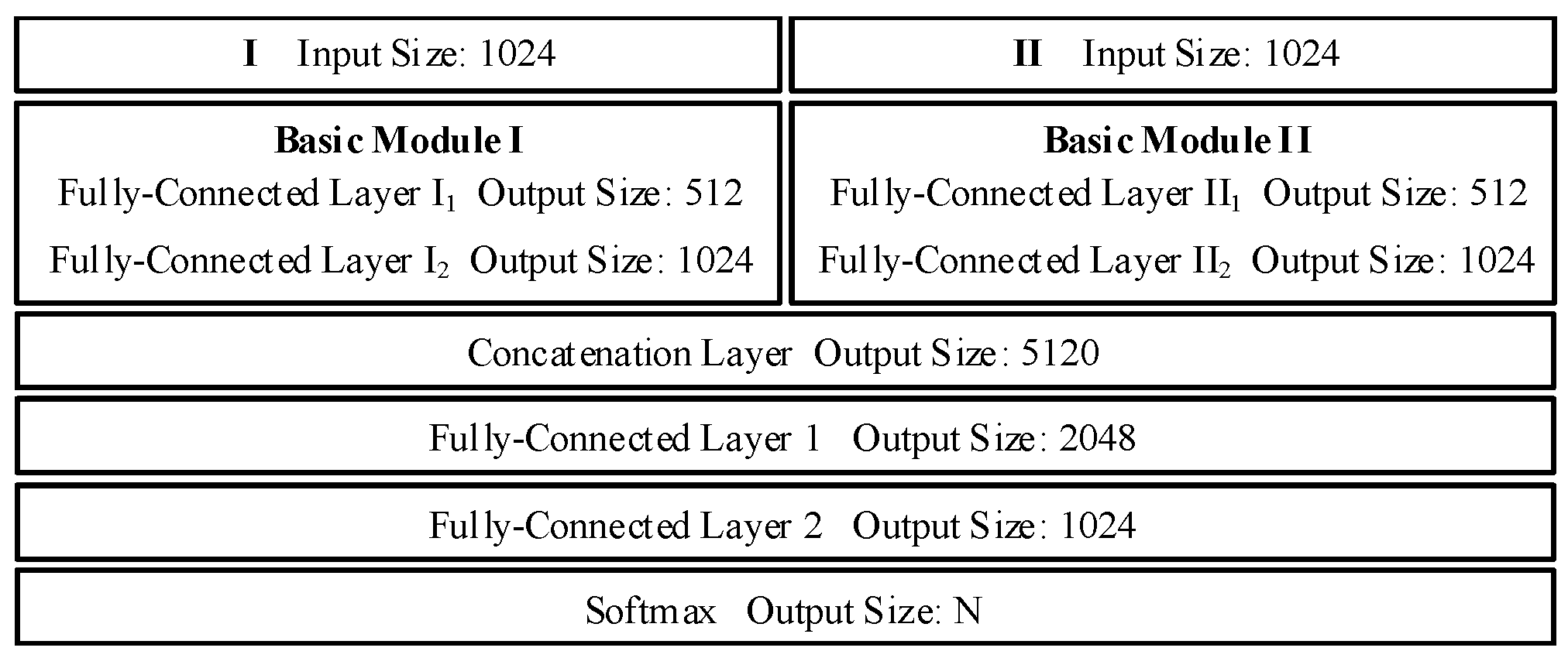
Figure 7 shows the detailed network architecture of our proposed feature fusion approach. Note that the ReLU nonlinear activation functions [
83] are not presented for brevity.
4. Experimental Design and Results
Here, we evaluate our proposed architectures on a variety of public datasets for aerial scene classification. In the rest of this section, we first give an introduction of the utilized datasets, and then introduce the experimental setup. Finally, we show the experimental results with analysis.
4.1. Description of the Utilized Datasets
4.1.1. UC-Merced Dataset
The first dataset is the well-known UC-Merced dataset [
33], which consists of 2100 overhead scene images with
pixels and a spatial resolution of 30 cm per pixel in the RGB color space selected from the United States Geological Survey (USGS) National Map. There are twenty US regions in this USGS National Map: Boston, Birmingham, Buffalo, Columbus, Dallas, Houston, Harrisburg, Jacksonville, Las Vegas, Los Angeles, Miami, Napa, New York, Reno, San Diego, Santa Barbara, Seattle, Tampa, Tucson, and Ventura. These 2100 aerial scene images are equally divided into 21 land use scene classes.
Figure 8 shows some example images from the UC-Merced dataset, with one example image per category. In this dataset, some significantly overlapping categories, e.g., medium residential, sparse residential and dense residential which only differ in the density of the structures, make this dataset challenging for classification. More information about this dataset can be obtained at
http://vision.ucmerced.edu/datasets.
4.1.2. AID Dataset
The AID dataset [
51] is acquired from Google Earth using different remote imaging sensors. This dataset contains 10,000 images associated with 30 classes, as shown in
Figure 9. For each image, it has
pixels and the spatial resolution ranging from 8 m to half a meter. The number of images per class varies from 220 to 420; see
Table 1 for details. Note that images in this dataset are obtained from different countries, i.e., China, England, France, Germany, etc., and at different seasons. Therefore, the AID has high intra-class variations. More information about this dataset can be obtained at
http://www.lmars.whu.edu.cn/xia/AID-project.html.
4.1.3. NWPU-RESISC45 Dataset
The NWPU-RESISC45 dataset [
52] is also a new large-scale dataset which keeps 31,500 aerial images spread over 45 scene classes. Each category contains 700 images with a size of
pixels in the RGB color space and the spatial resolution varying from about 30 m to 0.2 m per pixel.
Figure 10 gives some example images from this dataset. The scene images in this dataset have four remarkable characteristics including large scale, rich image variations, high within class diversity and high between class similarity. More information about this dataset can be obtained at
http://www.escience.cn/people/JunweiHan/NWPU-RESISC45.html.
4.2. Experimental Setup
During the course of our experiments, we use a workstation equipped with a 7th Generation Intel Core i9-7900X processor with 10 M of Cache and up to 4.3 GHz (10 cores and 20 threads), 64 GB DDR4 memory, a graphics processing unit (GPU) NVIDIA GeForce GTX1080Ti with a 11 GB memory, and a SAMSUNG 960 PRO NVME M.2 SSD with 1 TB of capacity.
To evaluate our proposed architectures comprehensively, we adopt two different training–testing ratios for each dataset. For UC-Merced dataset, the ratios of training–testing are 50% vs. 50% and 80% vs. 20%, respectively. For the AID dataset, the ratios are 20% vs. 80% and 50% vs. 50%, respectively. For NWPU-RESISC45 dataset, the ratios are 10% vs. 90% and 20% vs. 80%, respectively.
We employ two widely-used metrics for quantitative evaluation, i.e., overall accuracy and confusion matrix. The overall accuracy is calculated as the number of correct predictions in the testing set divided by the total number of samples in the testing set, which reveals the classification performance on the whole dataset. In the confusion matrix, each row represents the instances in an actual type, while each column represents the instances in a predicted type, which can represent a more detailed analysis than the overall accuracy. Note that, in order to achieve a stable performance and reduce the effect of randomness, we repeat the experiment ten times for each training–testing ratio and we take the mean and standard deviation over the ten times as the final performance. In each repetition, the training samples are picked randomly according to the ratio. Note also that we do not make comparisons with the results from those fine-tuned networks. We believe that this fine-tune operation can improve the performance. However, it is not within the scope of our paper. TensorFlow [
84] is chosen as the deep learning framework to implement the proposed method.
4.3. Experimental Results and Analysis
4.3.1. Comparison with the Baseline Methods
In order to comprehensively evaluate our proposed method, we present the baseline comparisons on three publicly available remote sensing scene datasets. In these baseline comparisons, we adopt three different fusion strategies, i.e., concatenation, addition and our proposed fusion approach, to combine the different types of features. With regard to the first two fusion strategies, we use the extreme learning machine (ELM) as a classifier. Here, we employ an ELM classifier rather than a linear support vector machine (SVM) [
85] classifier because ELM classifier could achieve better performance, which has been validated by [
86].
Table 2,
Table 3 and
Table 4 present these baseline comparisons on the UC-Merced dataset (
Table 2), AID dataset (
Table 3) and NWPU-RESISC45 dataset (
Table 4). The best values are marked in bold. TEX-TS-Net and SAL-TS-Net denote texture coded two-stream architecture and saliency coded two-stream architecture, respectively. Based on these results in
Table 2,
Table 3 and
Table 4, our observations are listed as follows.
- (1)
For the concatenation fusion strategy, the classification accuracies of saliency coded two-stream architecture achieve 94.46%, 96.17%, 89.15%, 91.25%, 79.69%, and 81.46% on the UC-Merced dataset (50% and 80% training samples), the AID dataset (20% and 50% training samples), and the NWPU-RESISC45 dataset (10% and 20% training samples), respectively, which are higher than the results of texture coded two-stream architecture, i.e., 94.31%, 95.71%, 88.46%, 90.15%, 79.58%, and 81.13%. At the same time, the saliency coded two-stream architecture also performs better than texture coded two-stream architecture with regard to the other two fusion strategies. The reason is mainly that the method of saliency detection has the ability of focusing more attention on the image regions that are most informative and dominate the class. Therefore, the features extracted from the saliency coded network stream are more informative and significant than that from the mapped LBP coded network stream.
- (2)
For the texture coded two-stream architecture, the classification accuracies of using our proposed feature fusion strategy can rank 97.55%, 98.40%, 93.31%, 95.17%, 84.77%, and 86.36% on the aforementioned datasets, respectively, which are higher than 95.25%, 96.62%, 88.56%, 90.29%, 79.63%, and 81.22%, obtained by applying the addition fusion strategy. The method with the concatenation fusion strategy has the lowest classification accuracies, i.e., 94.31%, 95.71%, 88.46%, 90.15%, 79.58%, and 81.13%. Meanwhile, we can get the same comparison results in the saliency coded two-stream architecture, in which the concatenation fusion strategy takes the third place, the addition fusion strategy takes the second place, and our proposed fusion model has the highest accuracies. It can be seen from the comparison results that our proposed deep feature fusion model can enhance the representational ability of the extracted features and improve the classification performance.
- (3)
The saliency coded two-stream deep architecture with our proposed feature fusion model outperforms all the other baseline approaches over these three utilized datasets, having the highest accuracies.
- (4)
The overall accuracies on the UC-Merced dataset are almost saturated. This is because this dataset is not very rich in terms of image variations. The AID dataset and the NWPU-RESISC45 dataset have higher intra-class variations and smaller inter-class dissimilarity; therefore, the results on them are still more challenging.
4.3.2. Confusion Analysis
In addition, we also report the confusion matrix and detail classification accuracy for each scene label. For the limited article space, we only present the confusion matrixes for the UC-Merced dataset (80% training samples), the AID dataset (50% training samples), and the NWPU-RESISC45 dataset (20% training samples) using saliency coded two-stream architecture with our proposed fusion model and texture coded two-stream architecture with our proposed fusion model, which are the best and the second best methods on these three utilized datasets.
Figure 11,
Figure 12 and
Figure 13 present these confusion matrixes. Based on these confusion matrixes, our observations are listed as follows.
- (1)
Over the UC-Merced dataset (see
Figure 11), most of the scene categories can achieve the classification accuracy close to or even equal to 1. In the confusion matrix of our feature fusion model based texture coded two-stream architecture, categories with classification accuracy lower than 1 include agriculture (0.95), dense residential (0.95), intersection (0.95), medium residential (0.95), river (0.9) and tennis court (0.95). In the confusion matrix of our feature fusion model based saliency coded two-stream architecture, categories with classification accuracy lower than 1 include buildings (0.95), dense residential (0.9), golf course (0.95) and tennis court (0.95). The scene categories in the confusion matrix of saliency coded two-stream architecture with our proposed fusion model obtain a better performance compared to the confusion matrix of the other method. For example, the agriculture, intersection, medium residential, and river scenes, which are confused in texture coded two-stream architecture with our proposed fusion model, are fully recognized by saliency coded two-stream architecture with our proposed fusion model.
- (2)
Over the AID dataset (see
Figure 12), it should be noted that our methods can get the classification accuracy rate of more than 0.95 under most scene categories, including bare land (a: 0.96, b: 0.96), baseball field (a: 1, b: 0.99), beach (a: 0.98, b: 1), bridge (a: 0.97, b: 0.98), desert (a: 0.97, b: 0.97), farmland (a: 0.96, b: 0.98), forest (a: 0.99, b: 0.99), meadow (a 0.99, b: 0.99), mountain (a: 0.99, b: 0.99), parking (a: 0.99, b: 1), playground (a: 0.98, b: 0.98), pond (a: 0.98, b: 0.99), sparse residential (a: 1, b: 1), port (a: 0.97, b: 0.98), river (a: 0.96, b: 0.99), stadium (a: 0.97, b: 0.99), storage tanks (a: 0.98, b: 0.96), and viaduct (a: 0.99, b: 1). At the same time, our methods can obtain relatively good performance under some scene categories that are difficult to recognize. For instance, from the results obtained by using the multilevel fusion method [
66], we can see the scene categories with low accuracy, i.e., school (0.77), square (0.80), resort (0.74), and center (0.80). In
Figure 12a, the classification accuracy rates of these four scene categories are improved by our method, i.e., school (0.83), square (0.82), resort (0.81), and center (0.85). In
Figure 12b, the results about these four scene classes are listed as follows: school (0.83), square (0.85), resort (0.80), and center (0.89).
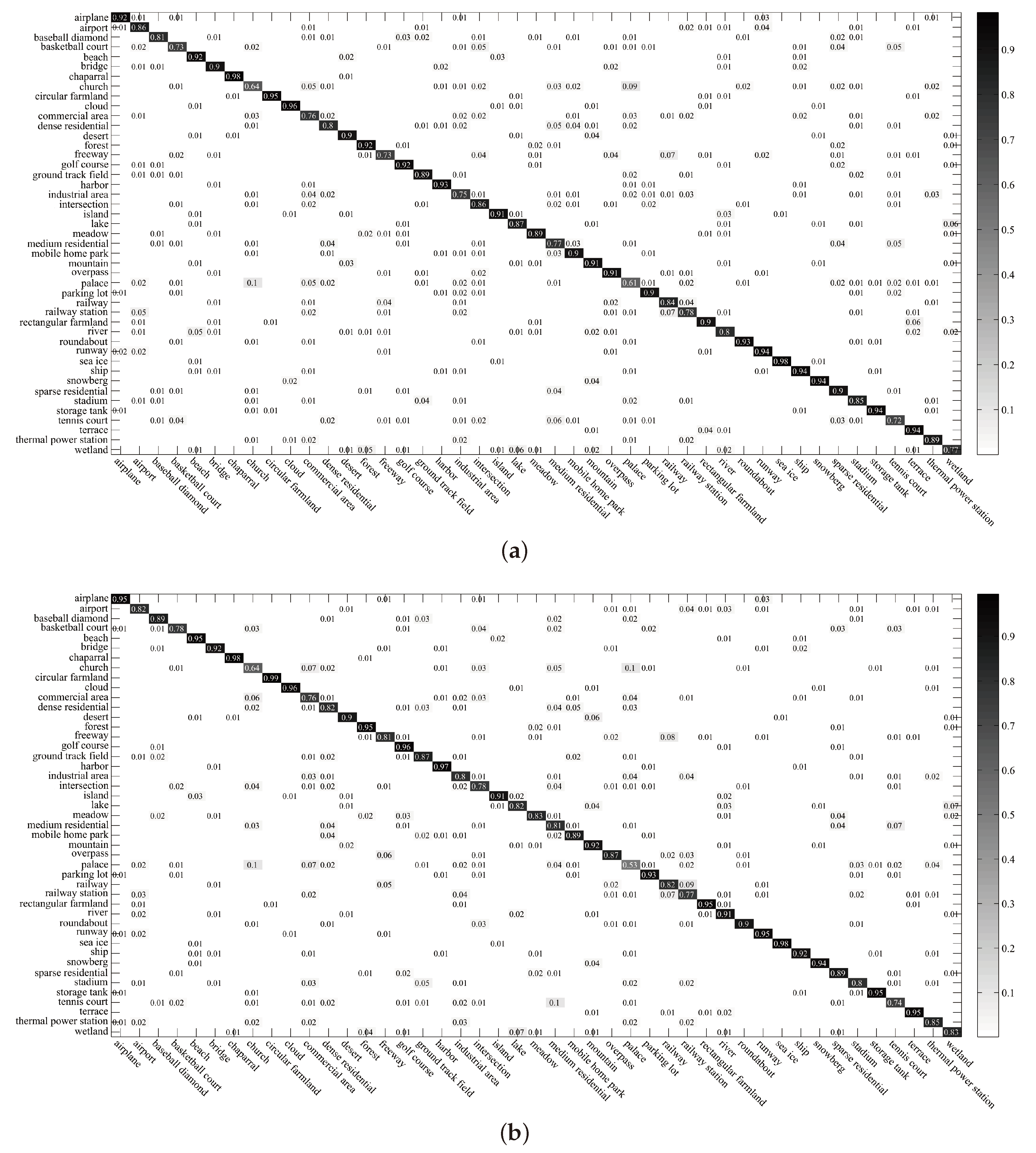
- (3)
Over the NWPU-RESISC45 dataset (see
Figure 13), compared with the confusion matrix of BoCF (VGGNet-16) [
57], our approaches provide consistent improvement in performance on most scene categories, i.e., commercial area (BoCF (VGGNet-16): 0.68, a: 0.76, b: 0.76), freeway (BoCF (VGGNet-16): 0.69, a: 0.73, b: 0.81), tennis court (BoCF (VGGNet-16): 0.57, a: 0.72, b: 0.74), palace (BoCF (VGGNet-16): 0.46, a: 0.61, b: 0.53), etc.
5. Discussion
Extensive experiments present that our feature fusion model based saliency coded two-stream architecture, which integrates raw RGB network stream and saliency coded network stream by using a dense connectivity based feature fusion network, is very effective for representing the aerial scene images.
For the sake of comprehensive evaluation, we compare our best numerical results with the most recent results obtained from the state-of-the-art approaches.
Table 5,
Table 6 and
Table 7 present the comparisons with the state-of-the-art methods on the UC-Merced dataset, the AID dataset, and the NWPU-RESISC45 dataset. The best values are marked in bold. As can be seen in
Table 5,
Table 6 and
Table 7, our feature fusion model based saliency coded two-stream architecture can achieve remarkable classification results when compared with the state-of-the-art methods. The detailed comparison and analysis on each dataset are presented as follows.
- (1)
On the UC-Merced dataset (see
Table 5), our best architecture outperforms all the other aerial scene classification approaches with an increase in overall accuracy of 1.54%, 0.57% over the second best methods, Aggregate strategy 2 [
59] and SHHTFM [
95], using 50% and 80% training ratios, respectively.
- (2)
On the AID dataset (see
Table 6), our best architecture performs better than the state-of-the-art approaches and the margins are generally rather large. Our accuracies are higher than the second best results, i.e., TEX-Net-LF [
61] and Multilevel fusion [
66], by 3.22% and 1.82%, under the training ratios of 20% and 50%, respectively.
- (3)
On the NWPU-RESISC45 dataset (see
Table 7), our best architecture remarkably improves the performance when compared with the state-of-the-art results. Specifically, our method gains a large margin of overall accuracy improvements with 2.37%, 2.69% over the second best method, BoCF (VGGNet-16) [
57], using 10% and 20% labeled samples per class as training ratio, respectively.
In this paper, the strengths of our work are listed as follows. Firstly, we apply different auxiliary models, i.e., the mapped LBP coded CNN model and the saliency coded CNN model, to provide complementary information to the conventional RGB based CNN model. This operation can provide more evidence to the classification process. Secondly, the proposed two-stream deep feature fusion model combines different types of features based on dense connectivity, which can achieve a higher utilization level of the extracted features and produce more informative representations for the input scene images. Additionally, our architectures have general applicability, which could be used for solving other tasks, such as traffic-sign recognition and face recognition.
6. Conclusions
In this paper, we construct two novel two-stream deep architectures based on the idea of feature-level fusion. The first architecture, a texture coded two-stream deep architecture, uses the mapped LBP coded network stream as the auxiliary stream and we fuses it with the raw RGB network stream using a novel deep feature fusion model. The two-stream deep feature fusion model adopts the connection type of dense block in DenseNet. The second architecture, saliency coded two-stream deep architecture, is very similar to the texture coded two-stream deep architecture except that the auxiliary stream is the saliency coded network stream. Finally, we conduct extensive experiments on three publicly available remote sensing scene datasets. The experimental results demonstrate that the two-stream deep architectures with our feature fusion model yield better classification performance against state-of-the-art methods. Our best architecture, our feature fusion model based saliency coded two-stream architecture, can achieve 97.79%, 98.90%, 94.09%, 95.99%, 85.02%, and 87.01% on the UC-Merced dataset (50% and 80% training samples), the AID dataset (20% and 50% training samples), and the NWPU-RESISC45 dataset (10% and 20% training samples), respectively. Inspired by our current promising results on aerial scene classification task, in the future, we plan to extend our architectures to other applications. Meanwhile, we believe that the current performance could be further improved by exploring better auxiliary features or feature fusion strategies.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}