4.1. Estimation of Plot Total Volume, Weibull Parameters, Percentiles and Moments
In this study, we proposed a framework for providing an enhanced ABM to generate predictions of individual tree volume distributions from PPM, PPRM, and MPRM approaches using airborne LiDAR data in relatively complex forest stands within a subtropical forest. The results demonstrated that airborne LiDAR could be timely and effectively applied to derive the volume distributions in such forest conditions. Holmgren et al. (2004) [
87] estimated the stand volume (
RMSE = 31 m
3/ha,
rRMSE = 11.00%) using the 90th height percentile metrics derived from LiDAR data in a boreal forest over southwestern Sweden. Montealegre et al. (2016) [
88] estimated management-related forest stand-level attributes, including total volume, using airborne LiDAR data in Mediterranean Aleppo pine forests. The results showed that timber volume (
R2 = 0.90,
RMSE = 11.01 m
3/ha) was well predicted by the height-related metrics (e.g., 95th percentile of height and kurtosis of height) and the density-related metrics (i.e., percentage of all returns above 1 m). Other studies have also demonstrated that the height and density metrics were effective predictors of stand volume [
74,
89,
90,
91]. In our study, volume models were developed by standard metrics (i.e.,
hvar,
hcv,
hmax), indicating these height metrics were sensitive to volume and other regressed models also included the standard metrics (e.g.,
h25,
h50,
hkurtosis), however, the standard metrics reported by their studies are not well explained by biophysical mechanisms [
56]. In addition, standard metrics, such as height-related percentile metrics, usually have inter-related relationships, and these metrics rely on plot sizes and LiDAR point density [
10,
92]. Compared to boreal forests with a much higher homogeneous composition and more discernible canopy architecture, the subtropical forests are commonly multi-layered and encompass some stands with considerable variability in tree height and stem density, which may lead that these traditional standard metrics have a relatively low transferability and are hard to capture forest vertical structural heterogeneity [
56,
93].
Canopy is a vital constituent of forest structure, and canopy structure is critical for estimates of forest structural parameters [
76,
77]. Therefore, a few metrics based on canopy structure were developed to estimate forest structural attributes because these metrics take into account the canopy geometry and tree architecture [
37]. As one of the means to quantify and analyze complex forest canopy structure, canopy vertical profile can be used to extract relevant metrics for further characterizing the potential heterogeneity of forest spatial structure [
66]. For instance, Lefsky et al.(1999) [
77] developed canopy volume metrics (i.e., open gap, closed gap, euphotic, oligophotic, filled, and empty) derived from canopy volume profiles (CVPs) to characterize the 3D canopy structure by quantifying the total canopy volume component and the spatial arrangement of the canopy material (e.g., branch, stem, and foliage) in a grid unit. The canopy volume metrics have proven to be useful for structural attributes, including the estimation of volume. The rumple index, referred to as the canopy surface roughness, has been proposed to capture the heterogeneity of the outer canopy surface with respect to the plot area. This metric has shown to be highly sensitive to variation within a heterogeneous canopy structure [
94]. Bouvier et al. (2015) [
37] proposed that the coefficient of variation of the LAD (
CvLAD) metric contained more distribution information on the forest vertical structure of a stand and found that the
CvLAD was more sensitive to volume. Canopy cover is also useful for developing a better characterization of the 3D canopy structures [
17,
95,
96]. The utilization of canopy metrics could provide more heterogeneous 3D information on canopy structure than can standard metrics [
37]. Thus, these canopy metrics, including canopy volume, coefficient of variation of vertical LAD, rumple and canopy cover, were also employed for the regression models in this study. Overall, the results showed that most of the developed models included the canopy metrics, such as
Filled of the total volume (
V) models,
Rumple of the scale (
b) models,
CC2m of the 24th percentile
models, and mean volume (
) models; exceptions included the shape (
c) models, 93rd percentile
models, and quadratic mean volume (
) models. The results indicated that the inclusion of canopy metrics could effectively improve the estimations of forest structural attributes, which was concluded in some previous studies [
22,
56,
97]. Zhang et al. (2017) [
56] demonstrated the usability of canopy volume metrics derived from CVPs for enhancing the estimates of forest structural parameters (e.g., volume) in same study area.
Filled metric actually represents overall canopy volume and was highly related with stem volume [
78,
98], which may be a reason for explaining that
Filled metric was selected by volume models. Our results found that canopy volume metrics only used for volume models (
V) whereas most of developed models selected other canopy metrics (
Rumple and
CC2m). Actually, canopy volume metrics described in previous literatures have the potential to provide information on vertical heterogeneity because they were directly derived from vertical profiles.
Rumple metrics used in our study actually provided more horizontal heterogeneity information on canopy structure, which may explain that this metric was selected by scale models. In addition, as Yushan forest is in secondary succession, the forest canopy surface became more uneven, which may lead
Rumple (representing canopy surface roughness) was more sensitive to scale parameters. Prediction models for estimating Weibull parameters, percentiles, and moments were derived from airborne LiDAR data. Indeed, all of these predicted parameter LiDAR-derived metrics were based on stand-level volume information. For instance, the Weibull parameters and percentiles were derived from fitted volume distributions and field reference volume distributions, respectively; therefore, they provided information on individual tree volume distributions, while two moments represented stand-level information on the mean and variance of volume, which provides an empirical linkage into the management of stand density and construction of yield tables. In terms of the performance of predictive models, the PPM models (
b and
c) (
R2 = 0.57–0.87
rRMSE = 16.56%–35.19%) performed slightly lower than did the MPRM (
R2 = 0.62–0.91,
rRMSE = 14.20%–32.40%) (
and
vq) and PPRM (
R2 = 0.59–0.87,
rRMSE = 10.65%–36.82%) (
and
) models (
Table 3,
Table 4 and
Table 5). This result is likely because the two Weibull parameters were directly derived from the continuous curves of the fitted volume distributions, which could compound systematic error distributions fitted to LiDAR data in complex forest stands (e.g., an uneven-sized volume composition stand).
Additionally,
b (i.e., Weibull scale parameter) and
c (i.e., Weibull shape parameter) performed relatively worse than percentiles, which was in accordance with the results of Gobakken and Naesset (2004) [
48]. Similar to Thomas et al. (2008) [
49], Tompalski et al. (2015) [
99] and Mulverhill et al. (2018) [
52], the
b models (
R2 = 0.76–0.88,
rRMSE = 16.58%–23.60%) obtained relatively better performance than did the
c models (
R2 = 0.35–0.78,
rRMSE = 23.16%–49.70%) in this study. The
c value can control the shape of the distribution, which could be an exponential, normal, or inverse-J distribution [
39], while the change in
b involved a scale size of the distribution. However, the shape of the distribution is more difficult to precisely characterize than is the scale parameter. In addition, shape of the volume distribution actually represents more horizontal information on tree volume distributions within a stand, but most of LiDAR-derived metrics used in this study only provided more vertical structure information rather than horizontal structure information, which may explain that the lower performance of shape models. The LiDAR metrics, i.e.,
h20,
h50,
hkurtosis, and
CC2m, were selected in the final
b estimation models (
Table 3), indicating that these metrics were sensitive to
b. Similarly, Mulverhill et al. (2018) [
52] reported that
h90,
hkurtosis, and
CC2 were especially suitable for predicting
b. In our study, the inclusion of
hkurtosis and
CC2 in model
b is likely explained by the kurtosis of the height and canopy cover involving the scale range of forest canopy structure (e.g., volume and biomass) within a stand in certain conditions. The significance of using the
h20 and
h50 metrics to predict
b may be explained by more information on tree volume with increasing tree height.
In this study, the estimated general models of all plots (
R2 = 0.35–0.80,
rRMSE = 23.60%–49.70%) produced relatively lower estimation accuracies than did the type-specific models (
R2 = 0.56–0.91,
rRMSE = 10.65%–39.81%) for the seven parameters (i.e.,
V,
b,
c,
,
,
and
), indicating that the use of separate models based on stratified plot data according to different forest types can improve the estimates of forest structural attributes. Tonolli et al. (2011) [
90] combined LiDAR and multispectral data to estimate timber volume in subtropical forests (located in the southern Italian Alps). They found that the stratification of various forest types can improve the estimated results (
rRMSE = 15.5%–21.3%). Naesset (2004) [
100] and Eskelson et al. (2008) [
101] reported that the method of stratifying field plots according to forest type or species composition did not have any significant impact on the estimations of forest structural attributes in boreal forests. However, due to the more complex forest structure (e.g., multi-layered and uneven canopies, shrubby understory) and the greater species diversity of subtropical forests in local study sites, the effects of forest types (tree-species composition) became more significant for estimating forest structural attributes. In addition, the metrics derived from the relatively low point density of the LiDAR data may be difficult to indirectly distinguish between unimodal and multimodal volume distributions in plots. Hence, stratifying the field plot data according to different forest types could refine the information on unimodal and multimodal volume distributions and improve the performance of predictive models [
102]. In general, coniferous models were relatively more accurate in all predictive models than were broadleaved forest plots and mixed forest plots. The relationships between forest structure and estimated structural attributes are usually species-dependent, and coniferous forests are easily characterized by relatively simple and even conical crown structures [
37,
56].
4.2. Estimation of Stem Density
Stem density, defined as the number of trees per unit area, and information on the spatial arrangement of individual tree attributes (e.g., DBH, tree height, basal area, and timber volume), is fundamental for forest growth and yield [
103]. Therefore, reliable estimates of stem densities can also be profound for guiding forest management operations and informing decision making in managed forest ecosystems [
104]. Operationally, stem density management (e.g., selective thinning) indeed affects the rate of volume production. Drew and Flewelling (1979) [
105] proposed the empirical relationship between mean volume and stem density using stem density management diagrams (SDMDs) to estimate thinning yields. Previous studies have demonstrated that stand total volume could be calculated based on this relationship between mean volume and stem density [
103,
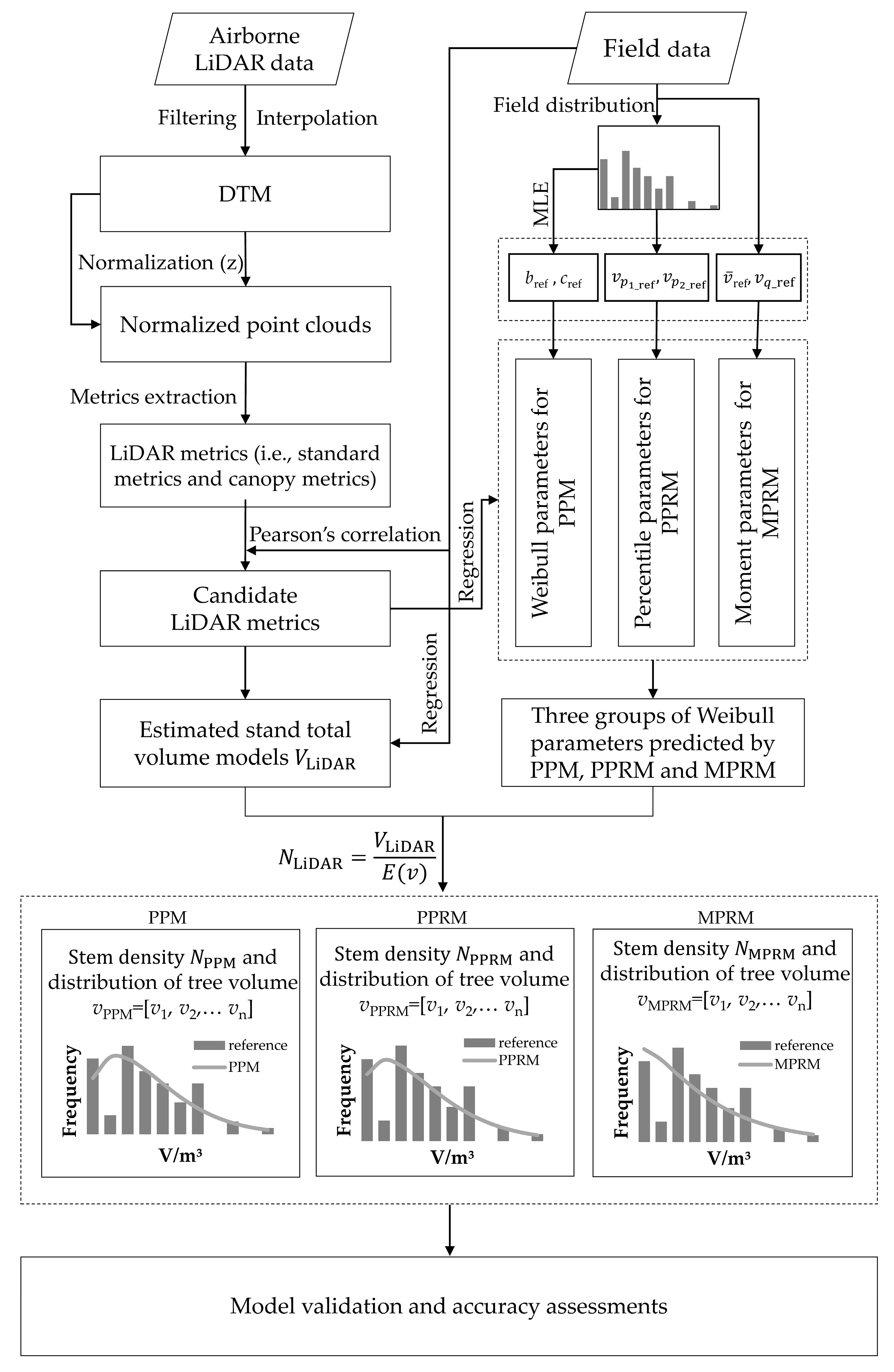
106]. In this study, we also predicted stem density by dividing the estimated plot total volume by the mean tree volume (i.e., mean value of distributions) generated from the two LiDAR-estimated Weibull parameters based on the PPM, PPRM, and MPRM.
Traditionally, the correlation between airborne LiDAR-derived metrics and stem density was poorer than that between other structural attributes (i.e., tree height and biomass), which was demonstrated by a few studies [
74,
91,
107]. However, the accuracy of this method in which stem density was predicted directly using metrics as explanatory normally depends on forest structure, and the results are commonly underestimated, likely because the LiDAR signals for detecting information on understory structure were suppressed by the higher frequency of larger trees or the clustered crown structure [
108]. Thus, we investigated the utilization of the established relationships between the LiDAR-estimated plot total volume and calculated mean tree volume (generated from the predicted Weibull parameters of individual tree volume distributions) for more accurate estimates of stem density. In our case, most of the stem density models (except for the general model based on the PPM) (
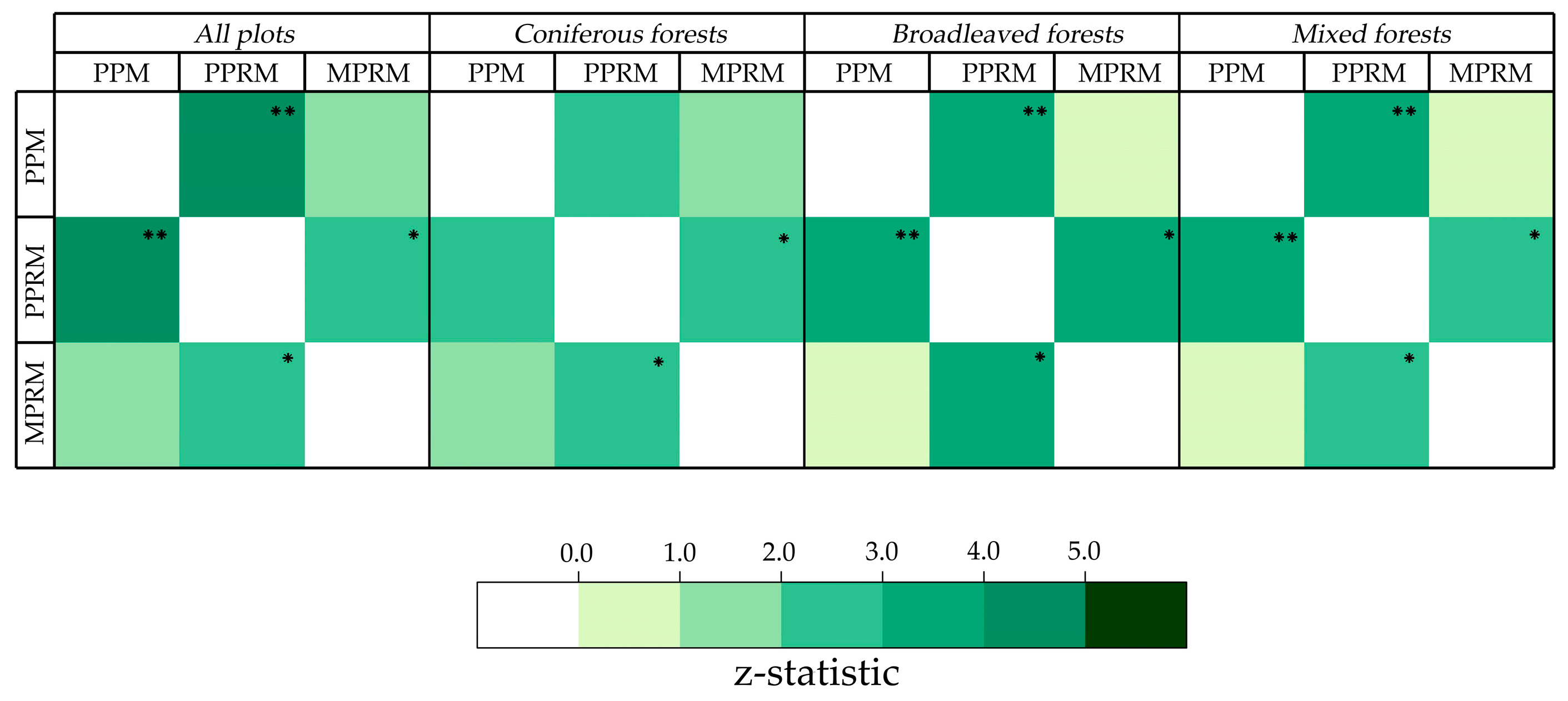
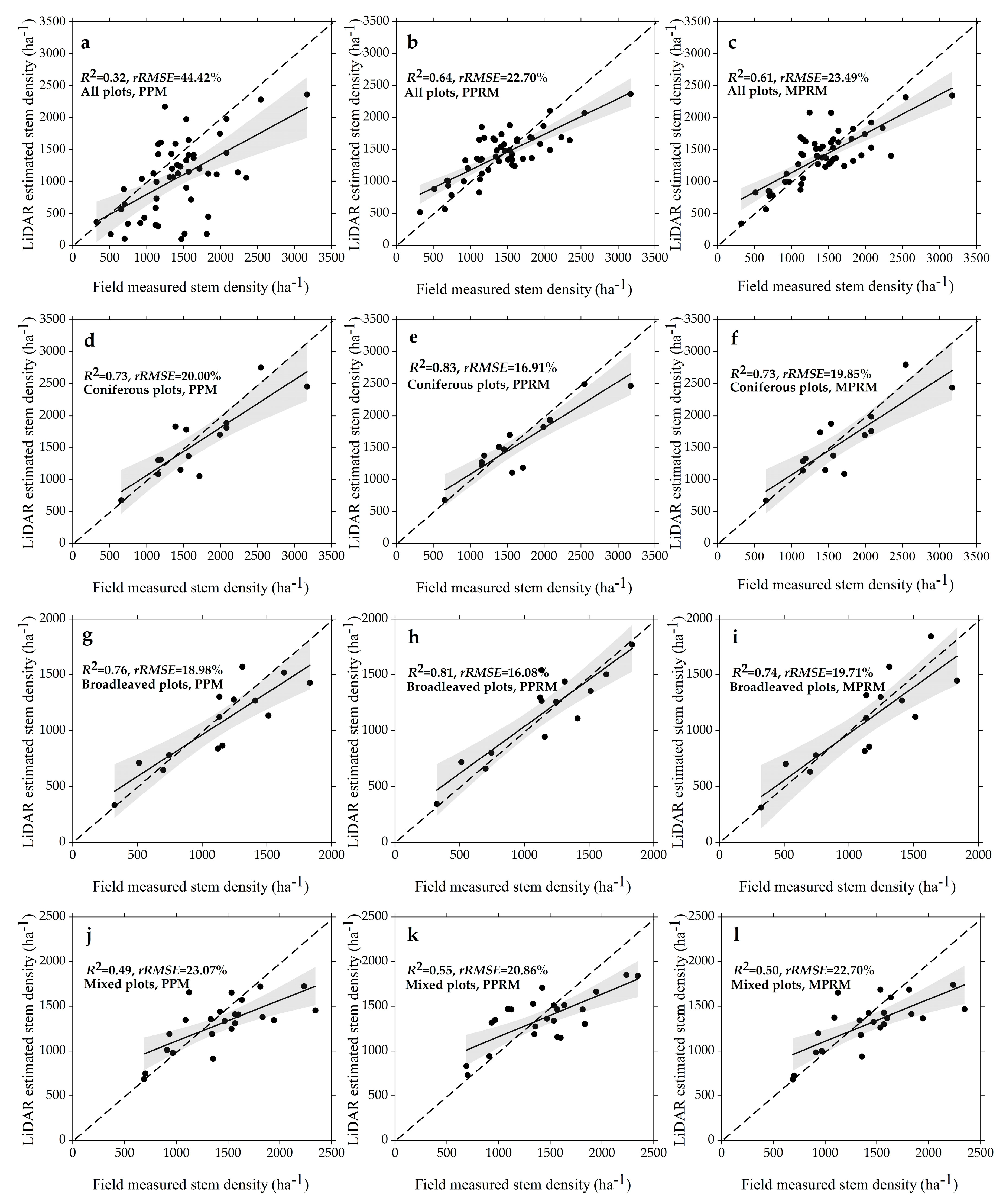
R2 = 0.49–0.83,
rRMSE = 16.08%–44.42%) performed better than did the results (
R2 = 0.45–0.64,
rRMSE = 20.07%–28.90%) reported by Zhang et al. (2017) [
56] at the same study site. The results indicated that stem density could be effectively estimated by converting the predicted plot total volume and mean tree volume. Moreover, the results revealed that predictive forest-type-specific models (
R2 = 0.49–0.83,
rRMSE = 16.08%–23.07%) performed relatively better than did predictive general models at all plots (
R2 = 0.32–0.64,
rRMSE = 22.70%–44.42%), which was similar to the results reported by Naesset (2002) [
74]. However, as
Table 6 shows, the results of cross-validation reveal that most of the stem density models slightly underestimated the ground truth by 1.00–27.03 ha
−1, with relatively low standard deviations (195.35–453.75 ha
−1), except for the general model based on the PPM and the broadleaved models based on the PPM and PPRM. As a comparison, a larger bias (−103–15 ha
−1) and standard deviation (128–400 ha
−1) of stem density were found in a boreal forest by Naesset (2002) [
74], suggesting that our approach based on volume could result in minimally biased predictions of stem density. One reason the bias was not completely eliminated may still be that individual volume distributions predicted by LiDAR-derived Weibull parameters had difficulty fully capturing the small trees suppressed in multi-layered forests. On the other hand, the errors may originate from the predicted total volume and mean tree volume, and the errors did not fully cancel each other out to a certain extent. Although the biases and deviations of the predicted total volume and mean tree volume could be quite small, uncertainties of accumulative errors in this model would also result in an overestimation of stem density, such as that in the general model based on the PPM (
Table A4).
4.3. Estimation of Tree Volume Distribution
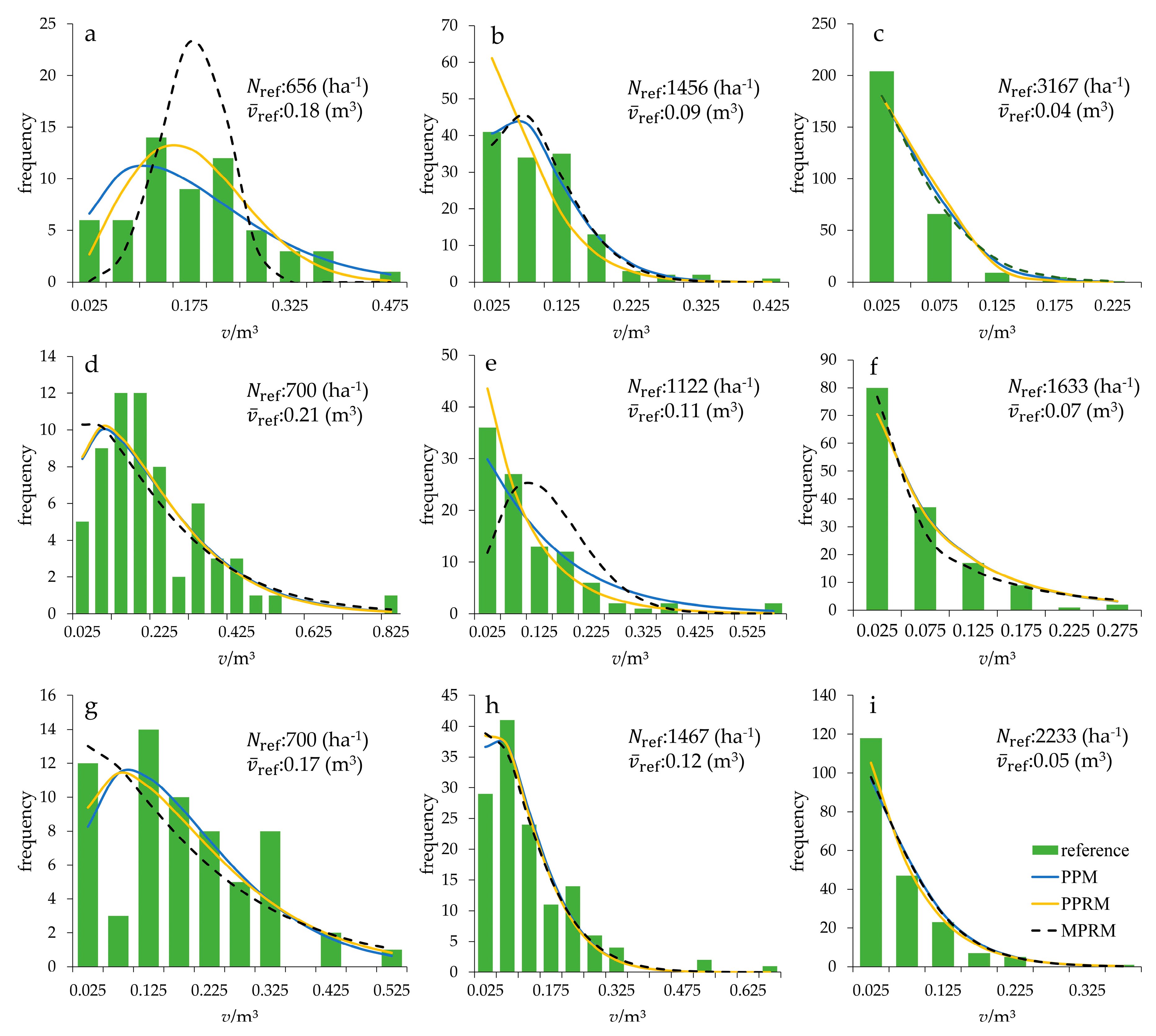
In this study, three parameter predictions (i.e., PPM, PPRM, and MPRM) for characterizing tree volume distributions with different stem densities (i.e., low, moderate, and high) are exhibited in
Figure 4. The stem densities of forest stands are varied in successive cuttings [
109], resulting in dynamic and changing volume distributions. The reference volume distributions of the 9 sample plots selected according to forest type and stem density were relatively well fit (
eR = 16.59–65.48,
eP = 0.07–0.33), with the scale parameters in the range of 0.05–0.23 and the shape parameters in the range of 0.64–4.21 (
Table A5).
SK has been recognized to measure asymmetry. Negative
SK values indicate a left-skewed distribution with a long tail to the left, while positive values represent a right-skewed distribution with a long tail to the right.
KT is generally considered a relative measure of the peak of a distribution, with
KT values being larger under distributions with a larger peak [
70]. Siipilehto and Mehtätalo (2013) [
110] compared the PPM and MPRM for fitting the diameter distributions with various stem densities over a boreal forest, and they found that the
SK and
KT of predicted diameter distributions increased with increasing stem density. Because there was a positive correlation between volume and DBH, consistent results were also reported in our study. In this study, we summarized the mean value of the Packalén error index
ep across tree volume classes of all plots for each forest type using predicted tree volume distributions based on the PPM, PPRM, and MPRM. Similar to other studies that focused on DBH or basal area distributions [
47,
48], the highest values of the mean
eP were observed in the smallest tree volume class of the volume distributions (
Figure 8). However, the three approaches generally provided relatively consistent results in terms of
eP for each individual tree volume class, always tending to decrease with the increasing tree volume class size, indicating decreasing variations in the fitted volume distributions. This result may explain why the best performance of fitting initially occurred in the smallest volume class (
Figure 4).
In this study, we employed field-measured stem density
Nref and LiDAR-estimated
NLiDAR as scaling variables to predict the distribution of individual tree volumes using estimated
b and
c. In terms of error indexes, the relationship between the predicted and reference volume distributions when the predicted frequencies of the volume distributions were scaled to ground-truth stem density was relatively stronger (mean
eR = 28.07–41.92, mean
eP = 0.14–0.21) than that when the predicted frequencies were scaled to stem density predicted from LiDAR data (mean
eR = 31.47–54.07, mean
eP = 0.15–0.21) (
Figure 5 and
Figure 6). This result was especially pronounced in all of the general models (i.e., all plots), where the mean
eR and
eP were 35.16–41.24 and 0.18–0.21 (
Figure 5), respectively, and the corresponding values for the predicted distributions using
as the scaling variable were 41.17–54.07 and 0.18–0.21, respectively (
Figure 6). These large discrepancies may partially be due to the relatively poor performance of the predicted stem density of the general models (
R2 = 0.32–0.64,
rRMSE = 22.70%–44.42%) (
Figure 3a–c). The underestimation in most stem density models could be explained by the different performances regarding the predicted volume distributions using
Nref and
NLiDAR as scaling variables.
Although field-measured stem density (as scaling variables) provides relatively more accurate estimates of tree volume distribution, the use of estimated stem density (as scaling variables) is available for the purpose of remote sensing at the stand-level by airborne LiDAR technology. From
Figure 5 and
Figure 6, the results revealed that the volume distributions modelled based on the PPRM performed relatively better than did those based on the MPRM and PPM in terms of predicting errors. Liu et al. (2004) [
43] used the PPM, PPRM, and MPRM to estimate the Weibull parameters to estimate the DBH distributions in unthinned black spruce plantations. They found that the PPRM (mean
eR = 80.98) was the most suitable for estimating the distributions of DBH compared with the MPRM (mean
eR = 82.73) and PPM (mean
eR = 83.98), which was similar to our results. The main advantage of using the PPRM is that the volume percentiles derived from the ground-truth distributions and LiDAR-derived metrics (related to stand attributes) can be estimated with more confidence than when the PPM directly predicts the Weibull parameters [
48]. Siipilehto (2009) [
40] noted that one frequent disadvantage of the PPM is that the parameters of the PDFs were not closely related to the forest structural attributes. Moreover, the PPM was based on the MLE algorithm in this study. The PPM usually had an overreliance on assumed distribution models when MLE was applied, and difficulties may also arise when there are observation uncertainties in the data [
111]. Both the PPM and the MPRM had an iterative process in solving the Weibull parameters, either by an MLE or by a bisection method, which may easily be trapped in divergence if the initial value was improperly selected [
112]. The MPRM performed slightly worse than the PPRM in this study, which may be due to the overfit of the volume distribution, such as the performance of the MPRM presented in
Figure 4a,e. Moreover, the small number of trees in the large volume classes made them difficult to capture by the predicted distributions (
Figure 4d,e,h).
4.4. Implications and Future Work
The management modes of Yushan forests are multipurpose sustainable forest management. Thus, tree volume distributions are useful for optimizing timber production, stand compositions, silvicultural practices, as well as ecological monitoring purposes of the subtropical forests. Tree volume distributions can also be used directly to describe stand attributes such as structure, age, and volume, or used as inputs to estimate biomass(by converting volume with a biomass expansion factor) and carbon budget [
11]. To support these needs, airborne LiDAR technology was used to estimate tree volume distributions by LiDAR-estimated Weibull parameters in this study. While this remote sensing technology for data acquisition may produce relatively high costs, the overall cost is still lower than most of the traditional field surveys in large scale, and the wall-to-wall LiDAR data could also be used to derive and share multiple products (e.g., DTM, volume and fire risk maps etc.) for extrapolating to larger scales, thus promoting sustainable forest management [
52,
88]. In addition, the ITC approach requires relatively high pulse density of airborne LiDAR data to provide more information on individual tree distributions. In contrast, our methodology effectively estimated individual tree volume distributions with relative low pulse density and costs. As the emergence of Unmanned Aerial Vehicles (UAVs) platform technology in recent years, UAVs have the capability of acquiring high density LiDAR point clouds, which has advantages of cost-effectiveness and convenience. Thus, our future work could use UAV-LiDAR data to reduce costs.
Airborne LiDAR technology is increasingly being used to map forested terrain. In this study, LiDAR data were used to generate a DTM by calculating the average elevation from the ground returns within each rasterized cell grid (1 m spatial resolution). Actually, LiDAR metrics derived from normalized point clouds are influenced by DTM quality to some extent, thus requiring a high quality DTM is essential for minimizing uncertain impacts on estimating volume distributions [
93]. The accuracy assessments of LiDAR-derived DTMs, over different forest areas have been the focus of previous studies [
113,
114,
115,
116,
117]. The various factors including forest structure, slope, off-nadir angle, understory vegetation, and interpolation algorithms have proven to influence the accuracy of DTM [
113,
114,
115,
116,
117]. Thus, the accuracy assessments of DTM should also be considered in our future work. In addition, a unimodal Weibull distribution form in this case can be modeled to fit simple unimodal volume distributions. Thus, our future work should consider whether other models, e.g., discrete percentile-based methods [
118] or finite mixture models [
52], or other data sources could be applied to more accurately estimate multimodal tree volume distributions using airborne LiDAR data [
119].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







