1. Introduction
SAR, as any coherent imaging system, generates speckled images. Speckle itself carries crucial information about the observed surface. This information is usually exploited by popular interferometric processing techniques of SAR image pairs [
1]. However, as shown in
Figure 1, speckle acts as noise on a single detected SAR image since it hides many details of the observed scene. At the beginning of the SAR era, when only detected images were considered, the speckle was referred to as speckle noise. Thus, speckle noise should be removed in all those Earth Observation (EO) applications where only detected images are considered.
Recently, a massive amount of SAR images has been made available by new SAR missions with systematic observation capability. The two Sentinel-1 satellites, for example, provide medium resolution SAR images of a large part of the Earth every six days (or even less if we consider both ascending and descending passes). The number of looks usually exploited to reduce the speckle should be kept as low as possible to guarantee a good spatial resolution. Such an amount of regularly repeated observations can be used to improve land cover classification, environmental monitoring, emergency response, and military surveillance. In most of these applications, despeckled SAR images are requested, as testified by the presence in the literature of many algorithms that have been proposed and used as a pre-processing step to mitigate the effects of speckle noise since the 1980s.
Adaptive spatial domain filters like Lee [
2], Kuan [
3], Frost [
4], operate on the value of the pixels by running a window, or kernel, over the entire image. Both Lee and Kuan filters, remove speckle noise by computing a linear combination of the central pixel intensity and the average intensity of neighbour pixels within the moving window. The Frost filter adopts a similar approach by using an exponentially damped kernel that behaves in a fashion similar to a low-pass filter or an identity filter, depending on whether the local coefficient of variation is small or large, respectively [
5]. Lope et al. [
6] presented the enhanced Lee and Frost filters operating in a similar way but introduced three classes for the coefficient of variation, namely homogeneous regions, heterogeneous regions, and isolated points. Although spatial domain filters proved to be effective in removing speckle from images under specific local conditions, their performance is highly constrained on the choice of the moving window. In general, they are applicable only in homogeneous areas and are characterised by blurring artefacts.
Another class of despeckling methodologies is based on the wavelet transform, in which the noise is reduced by thresholding the coefficients of the discrete wavelet transform (DWT) of the log-transformed single look image. In [
7], the wavelet Bayesian denoising technique is integrated with an image regularisation procedure based on Markov random fields (MRF), achieving better performance than the enhanced Lee filter. In [
8] authors investigate a despeckling and texture extraction method which uses a Gauss-MRF, while in [
9] authors introduce a speckled reduction method for PolSAR imagery based on adaptive Gaussian MRF. On the other hand, the method used by Argenti et al. [
10] outperforms the Kuan filter by applying a minimum mean-square error (MMSE) filtering in the undecimated wavelet domain. A different approach by Solbo et al. [
11] introduces the homomorphic wavelet maximum a posteriori (Γ-WMAP) filter improving the performance of the original Γ-MAP filter [
12]. A good smoothing capability in homogeneous regions is achieved by using a priori statistical information about the radar cross section (RCS). The major weaknesses of wavelet transform methods are still the backscatter mean preservation in homogeneous areas, details preservation, and the generation of artificial artefacts.
In order to overcome the issues mentioned before, more recent nonlocal (NL) filtering methods have been introduced in which noise reduction is performed by assigning each pixel a weight according to its similarity with the reference pixel. The nonlocal means (NL means) filter [
13] computes the value of a pixel as a weighted average of all the pixels in the image, where the weights are a function of the Euclidean distance between local patches of fixed size centred in the reference pixels. Deledalle et al. [
14] adapt the above method to SAR images by proposing a probabilistic patch-based (PPB) filter in which the similarity between noisy patches is defined from the noise distribution. Then, the obtained weights are refined, including the similarity between the restored patches. The block-matching 3-D (BM3D) image denoising algorithm [
15] groups image patches into 3-D arrays based on their similarity and performs a collaborative filtering procedure to obtain the 2-D estimates for all grouped blocks. Parrilli et al. [
16] modify the above algorithm to deal with SAR images (SAR-BM3D) by grouping the image patches through an ad hoc similarity measure that takes into account the actual statistics of the speckle and by adopting the local linear MMSE (LLMMSE) criterion in the estimation step. Despite its good results, this framework is one of the most computationally intensive.
Popular approaches are also the ones based on the total variation (TV) denoising procedure [
17] that combines a data fitting term with a regularisation term which encourages smooth solutions while preserving edges. TV-based methods differ because of the choice of the data fitting term and of the application domain, i.e., intensity or log-transformed intensity. In [
18], authors propose a new variational method in the original intensity domain based on a MAP approach, assuming a Gamma distribution for the speckle and a Gibbs prior for the original image. The variational model by Steidl et al. [
19] operates on images contaminated by multiplicative Gamma noise, by considering the I-divergence as data fitting term and applying the Douglas-Rachford splitting techniques to solve the minimisation problem. Other works apply TV regularisation in the logarithmic domain to overcome the difficulty of defining strictly convex TV problems in the original intensity domain [
20,
21]. A critical task in TV regularisation is the choice of the regularisation parameter that controls the degree of smoothing, i.e., large values for the parameter lead to over-smoothed results while small values do not sufficiently remove the noise. In [
22], the authors employ an adaptive TV (ATV) regularisation method consisting in adapting the regularisation parameter based on the speckle intensity. Another work by Palsson et al. [
23] proposes to select the regularisation parameter by minimising the Monte Carlo Stein’s Unbiased Risk Estimate (MCSURE), showing good results on real SAR images.
Finally, it is worth to mention an additional framework where despeckling is achieved by using the information contained in multi-temporal SAR data stacks. The extracted temporal statistics are used to develop space-adaptive filters which are then used on the single image. Ferretti et al. [
24] propose a despeckling algorithm, referred to as DespecKS. Statistically homogeneous population (SHP) is identified by applying the two-sample Kolmogorov–Smirnov (KS) test within an estimation window where pixels share the same statistics of the considered centre pixel. Then, the obtained SHPs identify homogeneous areas in the image and their intensities are averaged to reduce the speckle while preserving point-wise permanent scatters (PS). In [
25] Chierchia et al. deal with multi-temporal data by integrating a nonlocal temporal filter (NLTF) with the SAR-BM3D filtering method, thus developing a multi-temporal oriented version of the latter. Another approach by Zhao et al. [
26] applies a single-image denoising procedure to the ratio image (residual speckle) obtained dividing the considered speckled image by the super-image computed by temporally averaging the images in the data stack. The speckle-free SAR image is then obtained by multiplying the denoised ratio image with the original super-image. This framework tends to fail in low stationarity scenarios, and it cannot perform denoising in a single-image environment.
Our work aims at the single SAR image despeckling problem using a Deep Learning (DL) approach. The U-Net convolutional neural network [
27], initially proposed in 2015 for biomedical image segmentation, has been modified and adapted here for the SAR image despeckling task. Unlike previous DL approaches (see
Section 2), which do not explicitly impose to maintain the image structure during the despeckling, the proposed network allows by design to preserve edges, and permanent scatter points while producing smooth solutions in homogeneous regions. This is a desirable property in the specific problem, which requires high-quality filtered images with no additional artefacts. Experimental results demonstrate that the proposed approach achieves better performances than other methods and gives more reliable results even with respect to a multi-temporal despeckling algorithm.
The rest of the paper is organised as follows.
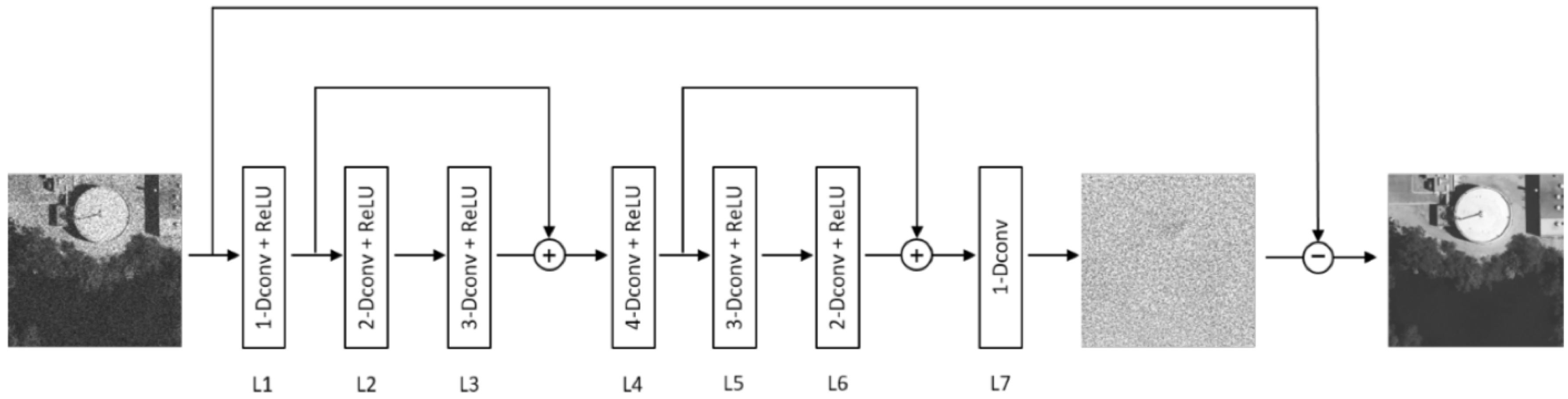
Section 2 provides an overview of the existing Deep Learning methods with a particular focus on the SAR-DRN convolutional neural network, which is used as the baseline method in our experiments.
Section 3 gives a theoretical background about the SAR speckle modelling with particular emphasis on the model used to generate synthetic speckle in our training procedure.
Section 4 introduces the proposed method by detailing both the used architecture and the adopted learning strategy. In
Section 5, we describe the suite of experiments, accurately designed to validate our approach, together with the datasets generation process and the analysis of the obtained results. Finally, we derive our conclusions and outline possible future work in
Section 6.
2. Related Works
The increase of data availability, together with the development of more powerful computing devices, led to surprising advances in machine learning (ML) methods allowing systems to reach very high performance in many complex tasks, e.g., image classification [
28,
29,
30,
31,
32], object detection [
33,
34], and semantic segmentation [
35,
36,
37]. In particular, Deep Learning methods have been employed in remote sensing tasks [
38,
39,
40,
41] due to the capability of Deep Neural Networks to automatically learn suitable features from images in a data-driven approach, without manually setting the parameters of specific algorithms.
In recent years, the use of Deep Learning has also been investigated for image denoising tasks. In [
42] the authors propose to train a feed-forward denoising convolutional neural network (DnCNN) following a residual learning approach [
30], paired with batch normalisation (BN) [
43]. Residual learning methods, by focusing on predicting the residual image, i.e., the noise, instead of directly producing a noise-free image, often allow achieving better performance. Applying a residual learning approach, indeed, helps to improve training, since neural networks tend to learn better when asked to give an output which is significantly different from the input [
42].
Chierchia et al. [
44] extend the concept of residual learning to SAR images by proposing a convolutional neural network (SAR-CNN) trained in a homomorphic setting, i.e., when the speckle is extracted from the log-transformed original image. The restored image is then obtained by mapping back the speckle-free image to the original domain through the exponential function. On the other hand, the image-despeckling convolutional neural network (ID-CNN) proposed in [
45] works directly in the original domain of the image, by assuming a multiplicative speckle noise, recovering the filtered image through a component-wise division-residual layer. Besides, they proposed to jointly minimise both the Euclidean loss and the total variation (TV) loss to provide smooth results.
In contrast to previous approaches, where log-transform is used [
44] or the training loss function is modified to solve the specific problem [
45], in [
46] authors work in an end-to-end fashion. By not relying on any a priori knowledge about either the noise or the image, and by leveraging a significant amount of simulated data during training, this approach is capable of automatically learning the hidden non-linear relations without having to rely on hand-crafted parameters. To accomplish this, they build a dilated residual network (SAR-DRN) showing better performance with respect to the state-of-the-art methods in case of high-level speckle noise. One of the key ingredients of SAR-DRN is the use of dilated convolutions [
47], which allows enlarging the receptive field [
48] by maintaining the filter size and the depth of the architecture. Skip connections are finally used, as shown in
Figure 2, to facilitate the learning process.
5. Experimental Results
In order to evaluate the performance of our model, we designed a suitable set of experiments which covers synthetic and real image despeckling domains. In particular, we built two types of datasets, one for each domain, to asses the quality of our predictions, both when dealing with synthetic images and real SAR ones. The synthetic dataset allows to numerically compare the quality of our predictions with state-of-the-art approaches, while the latter is intended to demonstrate how the proposed architecture can be successfully employed in a real despeckling scenario. In the following, we give an overview of the datasets we generated to run the experiments, and we present our main results together with the comparison with state-of-the-art methods.
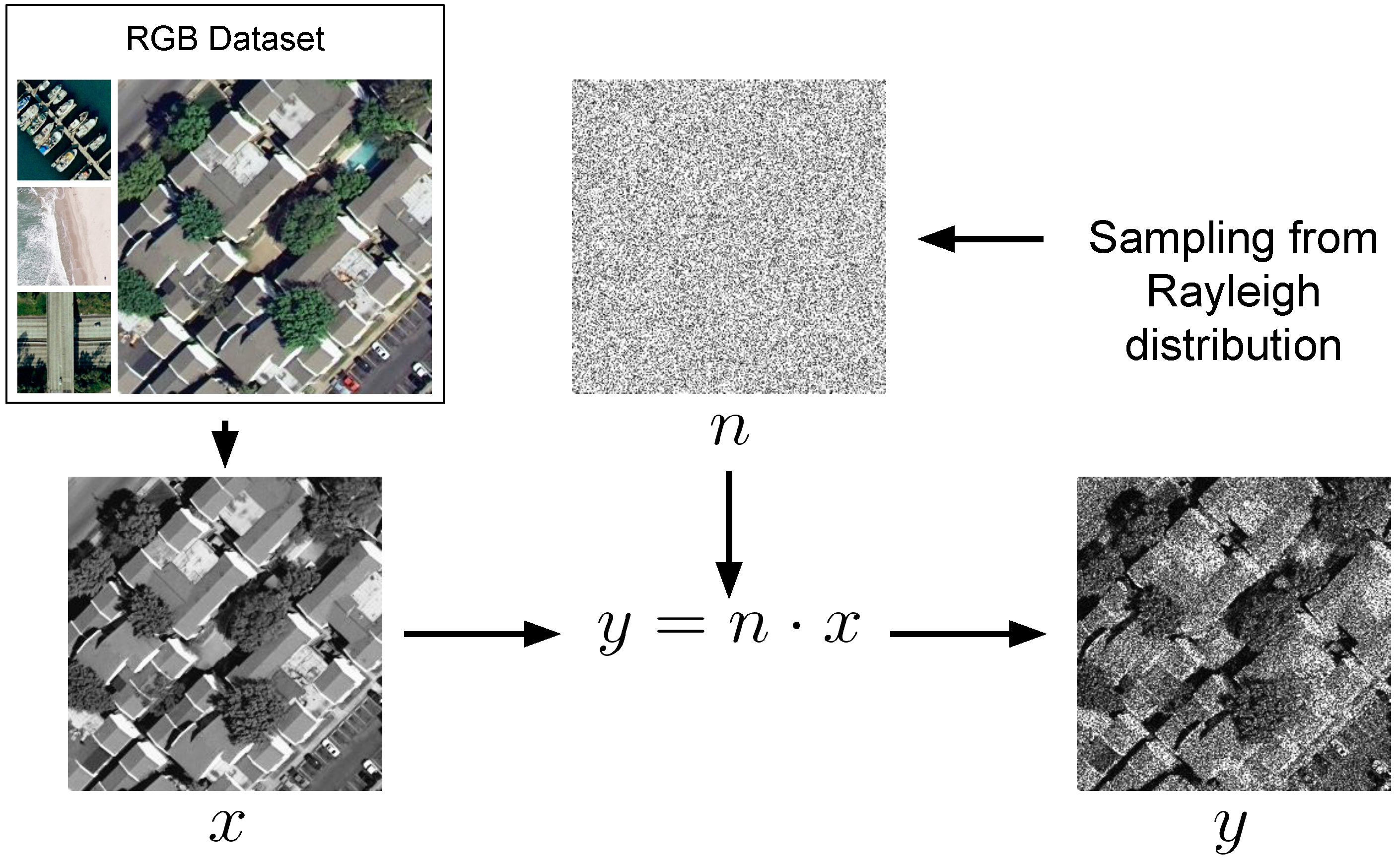
5.1. Synthetic Dataset
The synthetic dataset has been built using aerial images from the UC Merced dataset [
55] created for land use classification. The original dataset is composed of RGB images taken from the USGS National Map Urban Area Imagery collection and subdivided into 21 classes depending on the type of the land. From this dataset, we selected 1409 images from which we extracted 238,121 patches of 64 × 64 pixels as the training set. Furthermore, we selected 294 images of 256 × 256 pixels from three classes (Airplane, Buildings, and River) that are not used for training to perform the validation. Besides, we built a test set for the very final validation using four images from the PatternNet dataset [
56], which are taken from unseen classes (Transformer Station, Basketball Court, Tree Farm, and Bridge). The test set is used to compare our performance with state-of-the-art methods.
As anticipated in
Section 3.2, we use the training set to generate single look synthetic speckled images using the online procedure depicted in
Figure 3. Furthermore, at each training step the samples are augmented before to be fed to the network by randomly combining horizontal and vertical flipping, 90° and 270° rotation, and changes in image contrast. As shown in the ablation study, the performance increases as the data augmentation becomes more severe.
5.2. Real SAR Dataset
We built an additional dataset to fine-tune the learned model on the specific real SAR domain, which is characterised by high-resolution images. The challenge to be faced was to create the corresponding pairs of speckled and target images for training that had to be as similar as possible to real images. Since it is not physically possible to obtain a despeckled realisation of SAR images, we adopted an alternative strategy to obtain a speckle free reference to train the model. Specifically, we considered the point-wise temporal average over a stack of SAR images as the target image. The noise is then generated synthetically as in the case of aerial data. Even if the data is simulated, the obtained dataset provides samples that are close to the real ones, allowing the model to handle high-resolution images better.
We considered two large temporal stacks provided by the Sentinel-1 mission that have been averaged to generate two despeckled images with a resolution of 20 × 5 m (VV polarisation). The dimensions of the two images are 31,576 × 7251 and 40,439 × 15,340 pixels, respectively. We extracted 167,713 patches of 64 × 64 pixels as training set and 16,856 patches as the validation set. The latter has been incremented with additional unseen images computed with the simulation process for a total of 26,901 validation patches. Finally, we built a suitable test set to evaluate the proposed approach on real single look SAR images. To this purpose, we collected other Sentinel-1 images and also images coming from different constellations, in the specific COSMO-SkyMed (CSK) and RADARSAT (HH polarisation), to evaluate the generalisation capability of the network on different resolutions.
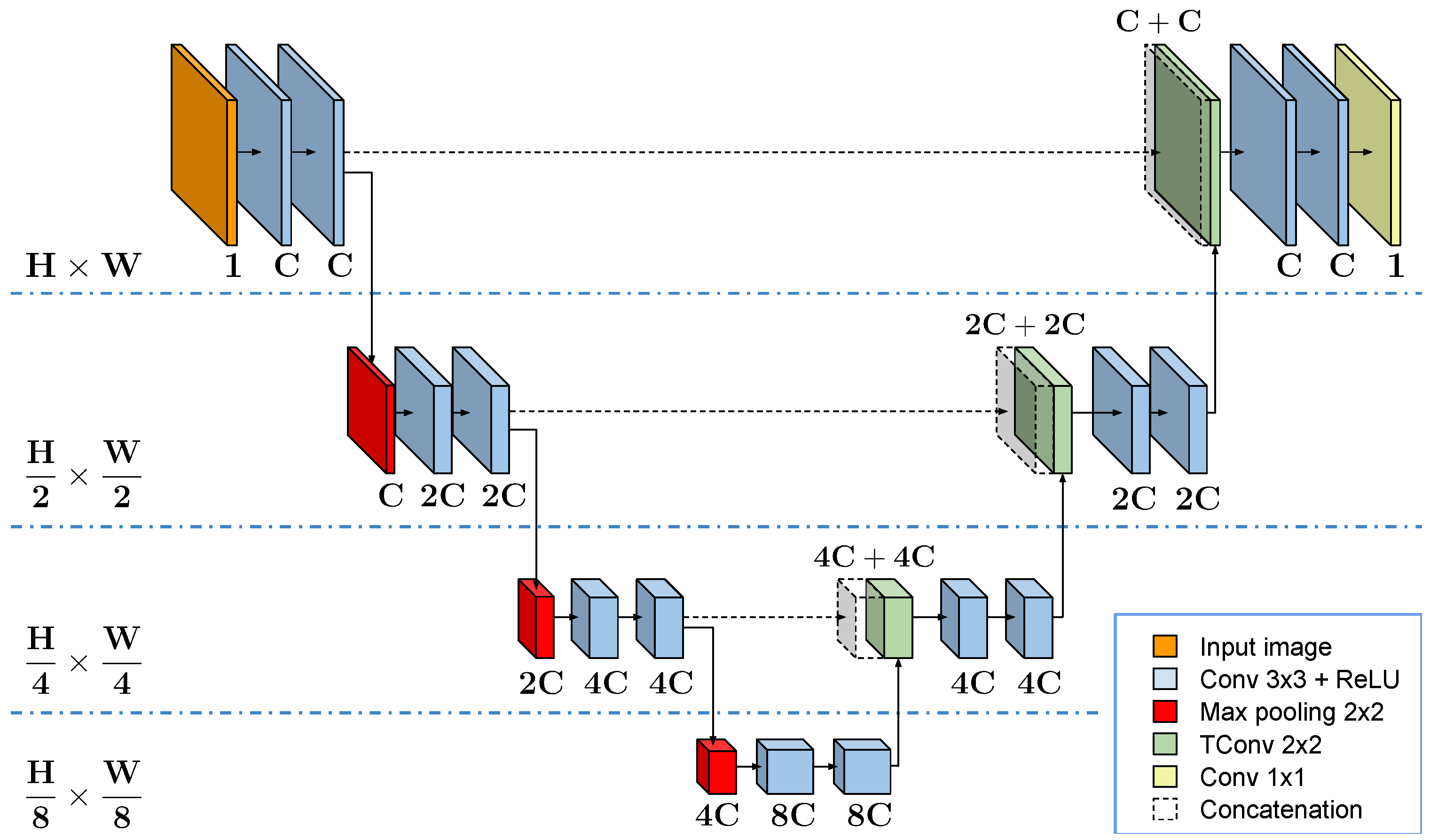
5.3. Training
Our best result is achieved by using the four-level U-Net configuration with 64 features extracted at the first encoding layer. We employed a minibatch learning procedure by creating batches of 128 samples. The update of the network parameters was performed using the Adam [
57] gradient-based optimisation algorithm with
β1 = 0.9,
β2 = 0.999, and
ϵ = 10
−8, where
β1 and
β2 are the exponential decay rates for the first and second moment estimates respectively while
ϵ prevents any division by zero in the implementation. Thus, at each iteration
t, the network parameters are updated using the following formulation
where
η is the learning rate and
and
are the bias-corrected first and second raw moment estimates defined as
where
gt+1 are the gradients of the objective function at time
t with respect to the network parameters
θ. In particular, denoting the MSE function introduced in Equation (
10) as the data fitting loss
LD, the gradients are computed as
The network has been trained on the synthetic dataset for 50 epochs, for a total of 93,050 training steps, using η = 0.001 as starting learning rate. We further adopted a learning rate decay schedule by decreasing it of 0.5 at intervals of 10 epochs.
For what concern the experiments on real SAR images, we used the parameters learned on the aerial dataset as initialisation, instead of training a new model from scratch. In this way, we took advantage of the already acquired capability of the model to extract relevant features for noise removal, and we fine-tuned the network parameters to deal with images in the real domain. This process is also known as domain adaptation, and it requires only a few additional training steps. Also, in this case, we employed a minibatch learning using batches of 128 samples each. The network has been fine-tuned for 15 epochs using a learning rate of 5 · 10−6 and the Adam optimiser with the same hyper-parameters of the synthetic experiments.
In the real domain, the speckle noise has some properties that are not fully captured by the synthetically generated images. For this reason, despite the good capability of the network in filtering the speckle, the generated images still contain some blurry artefacts. Thus, we introduce a Total Variation (TV) regularisation loss during the training with the goal of removing the artefacts and producing smoother results while preserving the structure and the details of the images. The TV loss is defined as
where
and
are the gradients of the reconstructed image on the horizontal and vertical directions, respectively, and are defined as
while
and
are the gradients computed on the speckle-free reference image on the same directions. The role of the former is to minimise the difference among neighbouring pixels while the latter allows avoiding over-smoothed results in correspondence of the edges. The total cost function becomes
where
LD is the data fitting term defined in Equation (
10) while
λTV is the hyper-parameter governing the importance of the regularisation. We initially performed a random search to find the range of values of
λTV for which TV gives a relevant contribution, finding 1·10
−4 ≤
λTV ≤ 5·10
−4. Finally, we found
λTV = 2·10
−4 to give the best regularisation incidence in our experiments. Also in this case we compute the gradients
gt+1 of the objective function at time
t as
where
are computed as in Equation (
14), while the gradients of the total variation are given by
5.4. Metrics for Evaluation
In the aerial dataset, the target corresponding to each noisy image is available since the latter are generated synthetically. Thus, it is possible to evaluate the quality of the provided approach by computing two kinds of metrics that are typically used in image denoising tasks. They are the peak signal-to-noise ratio (PSNR) and the structural similarity (SSIM) index. The PSNR expresses the ratio between the maximum signal power and the power of the noise affecting its quality. It measures how closely the reconstructed image represents the original one and is given by
where
MAXI is the maximum signal power, i.e., 255 for grayscale images and the
MSE is computed between the noise-free target image and its reconstruction. The SSIM measures instead of the similarity between two images from the point of view of their structural information, i.e., the structure of objects in the scene, regardless of the changes in contrast and luminance. Given two images
x and
y, it is defined as
where
μi is the mean of
i,
σi is the variance of
i, and
ci is a constant introduced to avoid instabilities.
Since a speckle-free reference is not available in the real domain, it is not possible to compute the metrics introduced above. A different approach is thus required. One option remains the visual inspection of the reconstructed images, for which we provide several results on different scenarios. Another common approach, that we adopted in this work, is to evaluate the degree of smoothing in a homogeneous region by computing the equivalent number of looks (ENL) defined as
where
μI and
σI are the mean and standard deviation of the considered image portion
I respectively. The main difficulty in the computation of this metric is the ability to find a considerable homogeneous region inside the image under evaluation.
5.5. Results on Synthetic Images
We compare the performance of our approach with the one of two methods: SAR-BM3D, belonging to the class of algorithms of non-learned filters, and SAR-DRN, which is, to the best of our knowledge, the state-of-the-art method among DL approaches. For the former we used the publicly available MATLAB code
http://www.grip.unina.it/research/80-sar-despeckling/80-sar-bm3d.html, setting the parameters as suggested in the original paper. For what concern SAR-DRN, instead, no public code is available. We thus implemented and trained SAR-DRN from scratch on our dataset, following the specifics given by the authors in the reference paper.
Figure 6 shows the qualitative results of our approach on a selection of the test set, together with the ones of selected methods. Notice that, even if SAR-BM3D is quite effective in removing the speckle noise, the filtered images loosely preserve the object details and smoothness in homogeneous regions. SAR-DRN shows better performance w.r.t. SAR-BM3D, filtering out the speckle with higher accuracy. However, the produced images are still contaminated by some blurry artefacts. The proposed network, thanks to the combined action of its encoder–decoder structure and the system of skip-connections, improves the quality of the despeckled images by providing sharper results in correspondence of edges and preserving homogeneity among spatially coherent pixels (e.g., Bridge).
The qualitative improvements are reflected by the numerical results. As shown in
Table 1, our approach shows a gain in the PSNR metric of about 1.21 dB, 0.80 dB, 1.68 dB, and 1.87 dB w.r.t. SAR-BM3D algorithm for Bridge, Basketball Court, Christmas Tree Farm, and Transformer Station respectively and outperforms SAR-DRN of about 0.63 dB, 0.20 dB, 0.62 dB, and 0.28 dB in the same images. These improvements testify a better image restoration capability compared with other methods. The proposed approach outperforms the baseline methods also in terms of SSIM index, as highlighted in
Table 2, providing more accurate preservation of the image structural information.
5.5.1. Ablation Study
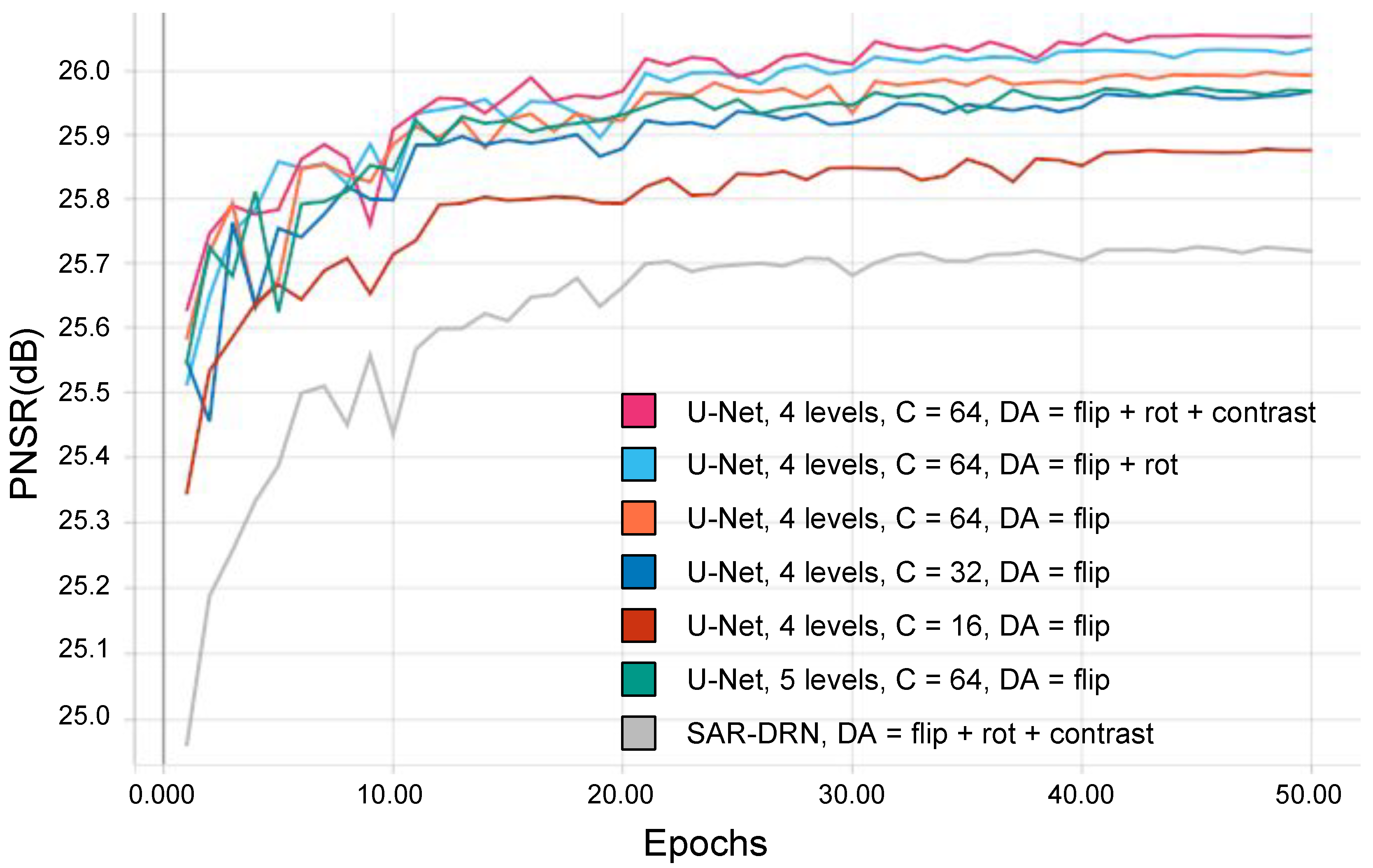
Network complexity and data augmentation.Figure 7 shows the performance of the different networks and data augmentation (DA) configurations on the validation set, evaluated at the end of each training epoch. For the sake of simplicity, only the number of features produced by the first encoding layer indicated as
C is reported. We set different experiments to understand how network complexity affects the results together with the importance of data augmentation procedures. Compared with the original U-Net architecture, employing a five-levels depth model, the modified version, with only four encoding layers, shows better performance. As can be observed in the figure, results show how decreasing the number of parameters in the network does not help the learning, so we set the number of starting features as
C = 64. The experiments also reveal that the use of strong data augmentation increases performance. The best performance is obtained by doing random image flipping (flip), rotation (rot), and changes in image contrast. Finally, the curves show the better performance of our approach compared to SAR-DRN trained on the same augmented data.
Skip connections. We further studied the importance of skip connections in the despeckling process. We claimed that skip connections allow obtaining far deeper details in the reconstruction since they facilitate the recovering of information that could be partially lost during the encoding stage.
Table 3 and
Table 4 show the numerical results obtained during the ablation study. First, we reproduced our best experiment without using skip connections. As expected, it is possible to observe a drastic drop in performance, both in the PSNR and SSIM metrics. The decoder network is not able to restore the input image by only considering the final latent representation. In addition, in order to verify that the loss of information is less severe when reducing the depth of the network, we conducted an additional experiment in which we considered only three encoding layers and no skip connections. Also, in this case, the results confirm the expectation by showing an improved capability of the network in producing a speckle-free reconstruction from encoded information. However, it is possible to notice how the lack of skip connections mainly affects the preservation of the structural information, as shown by the SSIM index. For completeness, we also report the evaluation of the reduced network with the addition of skip connections. In conclusion, the conducted study shows that the greater the degree of compression of the input image, the more skip connections play a key role in the overall despeckling process, by allowing for a good speckle filtering and, at the same time, for good preservation of image details.
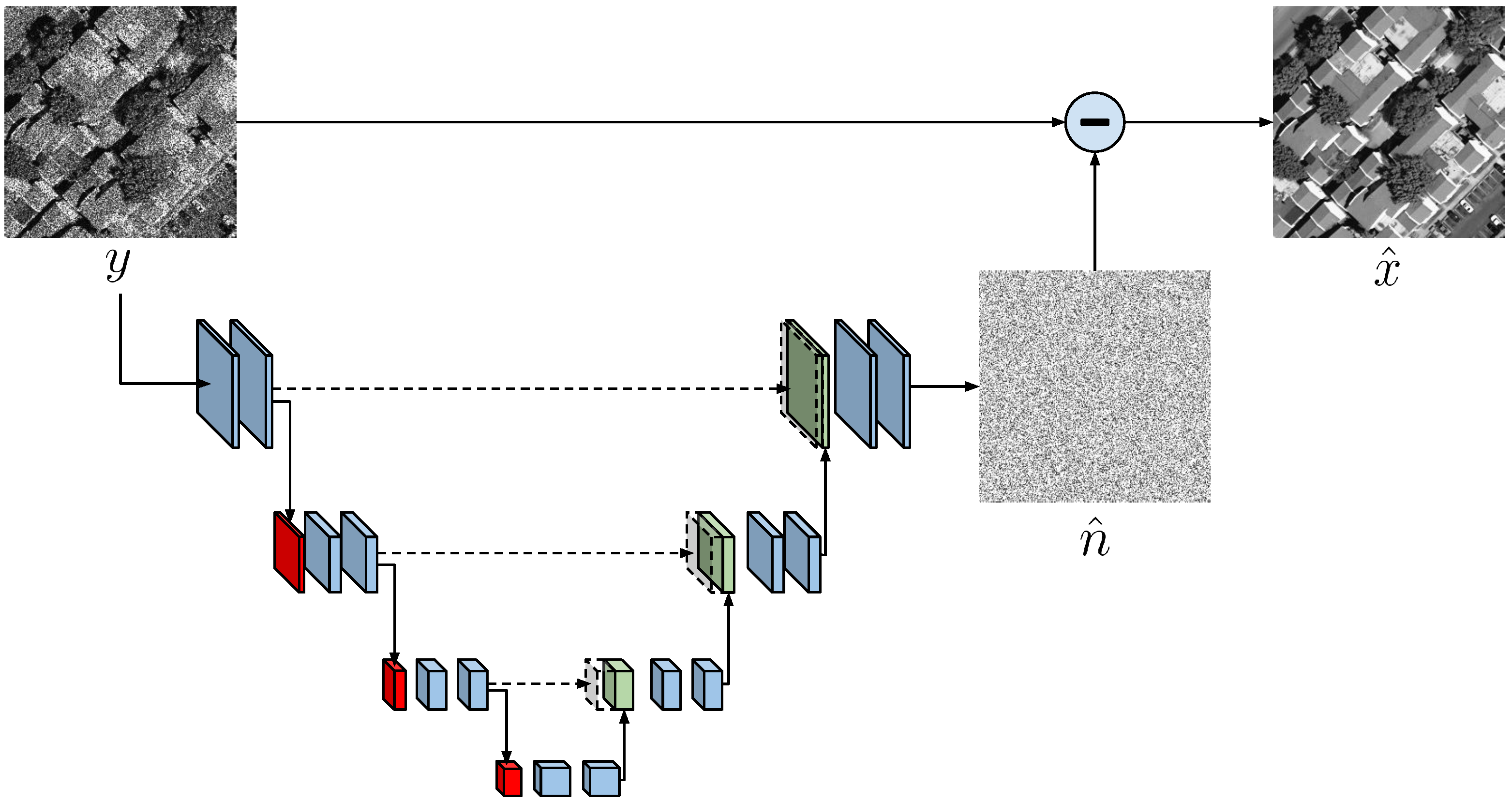
5.5.2. Results on Real SAR Images
Figure 8 shows the qualitative results on different single look SAR images. It is possible to observe how the SAR-BM3D algorithm is quite efficient in removing the speckle, but the reconstructed images still contain some residual noise as testified by the produced artefacts. The base version of the proposed U-Net architecture, i.e., without TV, shows visually better results by generating sharper images. It is interesting to notice how the proposed approach performs well also on images having a spatial resolution different from the one encountered during the training phase. The performance achieved on the Sentinel-1 image, having a resolution of 20 × 5 m, is also achieved on the COSMO-SkyMed and RADARSAT images, having a resolution of 3 × 3 and 15 × 15 m, respectively. The best results were given by the model learned with the TV regularization whose reconstructions are smoother on homogeneous areas, further removing some of the residual artefacts, while preserving the structure of the images. The quantitative results proposed in
Table 5 reflects the above considerations showing how the proposed approach has higher performance in speckle suppression in the considered homogeneous regions.
Figure 9 shows a qualitative comparison between our single observation approach and the DespecKS algorithm based on multi-temporal data. As highlighted by the blue circles, the proposed model has a higher capability of preserving the information contained in the image while the reference algorithm tends to lose the details due to the averaging over the temporal dimension. Our approach provides faster and more accurate results by looking only to a single image instead of processing the entire data stack.
6. Conclusions
We presented an adaptation of the U-Net convolutional neural network, originally conceived for semantic segmentation, for the problem of speckle removal in single look SAR images. Its encoder–decoder architecture allowed us to address the problem following the principles of denoising autoencoders. We built an online procedure for synthetic speckle generation, coupled with a well-designed data augmentation pipeline, and we extensively ran experiments to validate the performance of the proposed approach. We built two datasets to first pre-train the network on aerial images and then to fine-tune the model on the real SAR domain. Through the experiments, we showed how our model outperforms the state-of-the-art methods on synthetically generated images, as testified by the metrics that we were able to compute thanks to the availability of the speckle-free targets. We compared our results with SAR-BM3D, a well-known algorithm for SAR speckle filtering, and with SAR-DRN, a deep learning approach which demonstrated competitive results in this field. Compared to these methods, the proposed approach produced sharper reconstructions and showed to be less prone to generate artefacts and blur effects. We demonstrated how the learned model is effective in filtering out the speckle also from real samples with few fine-tuning steps on a specifically designed dataset. We further boosted the performance by introducing a modified version of the total variation regularisation, which allows generating smooth results in homogeneous regions while maintaining the information about the structure in the image. Additionally, the presented results show the generalisation capability of the network, which performs well on spatial resolutions not seen during training. Finally, we compared our approach with an algorithm that uses the temporal information of a whole data stack, showing how the proposed model generates more reliable results.
As future work, we plan to use a generative model to improve the quality of the simulated noise, with the aim of generating training samples more similar to the real data distribution. In addition, we want to investigate further the generalisation capability of the model by building a complete training set containing samples of different spatial resolutions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}