Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery


Abstract
:1. Introduction
2. Data and Methods
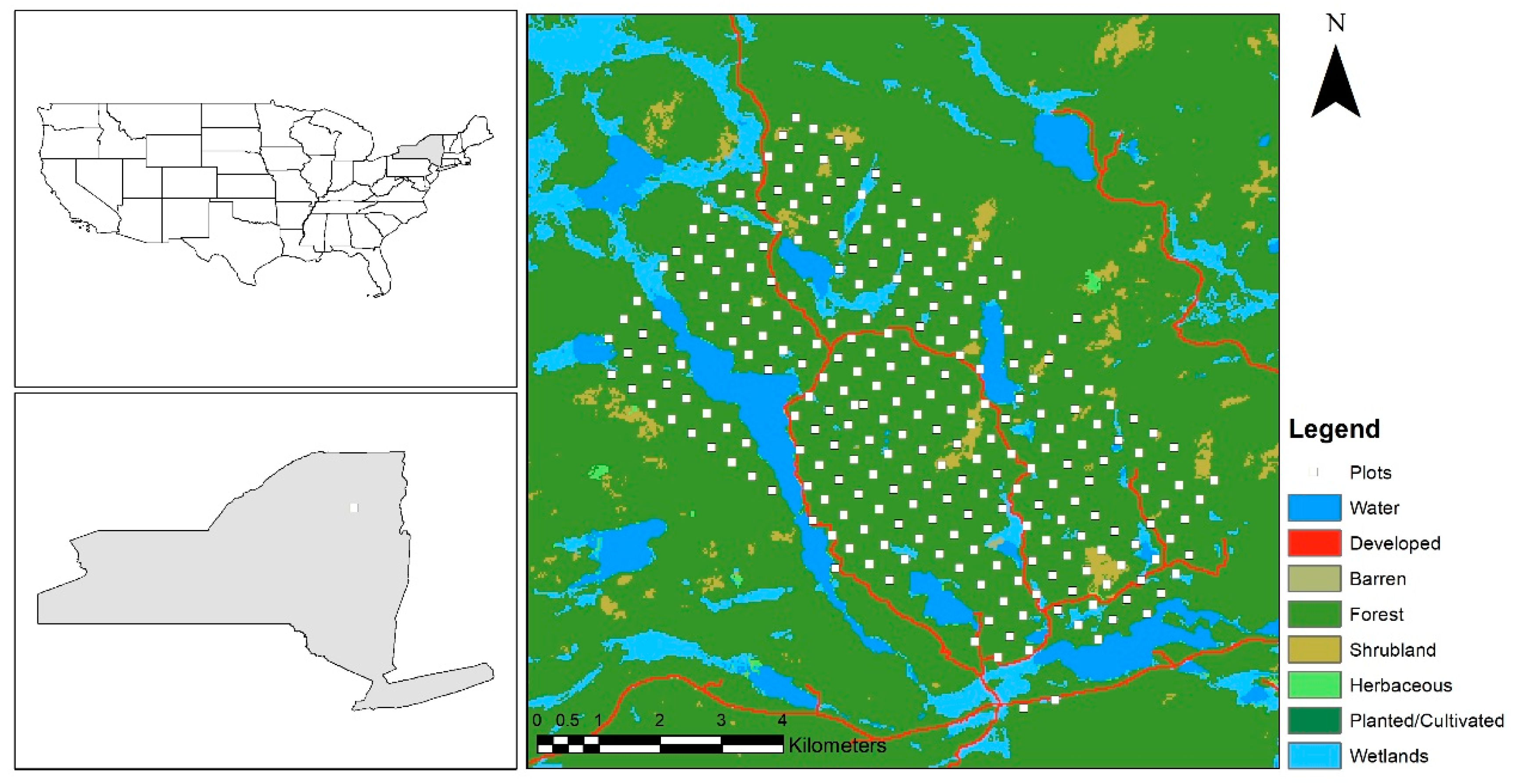
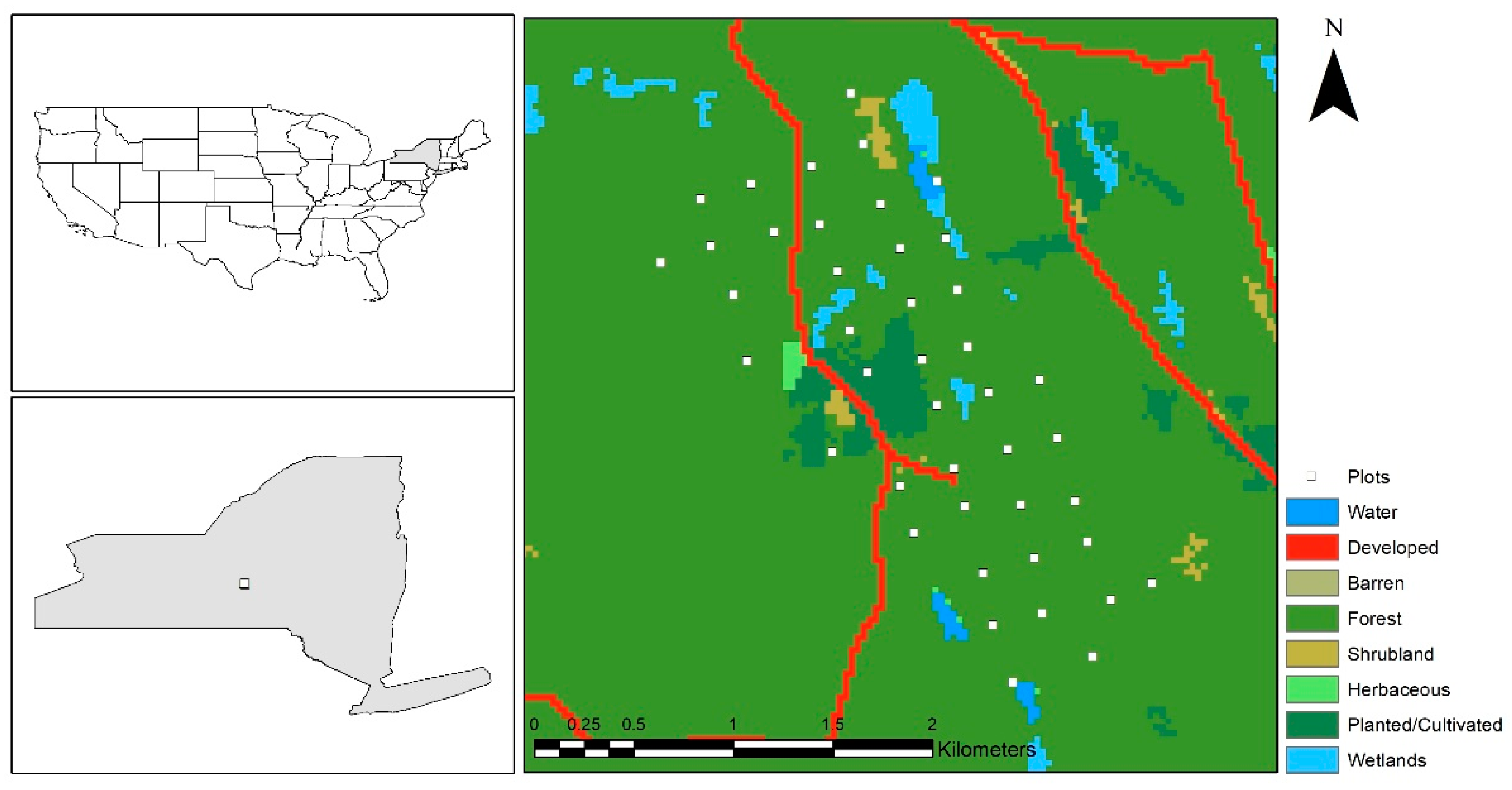
2.1. Study Areas
2.1.1. Main Study Area: Huntington Wildlife Forest
2.1.2. Test Study Area: Heiberg Memorial Forest
2.2. Field Inventory Data
2.3. Lidar Data and Processing
2.4. Landsat Data and Processing
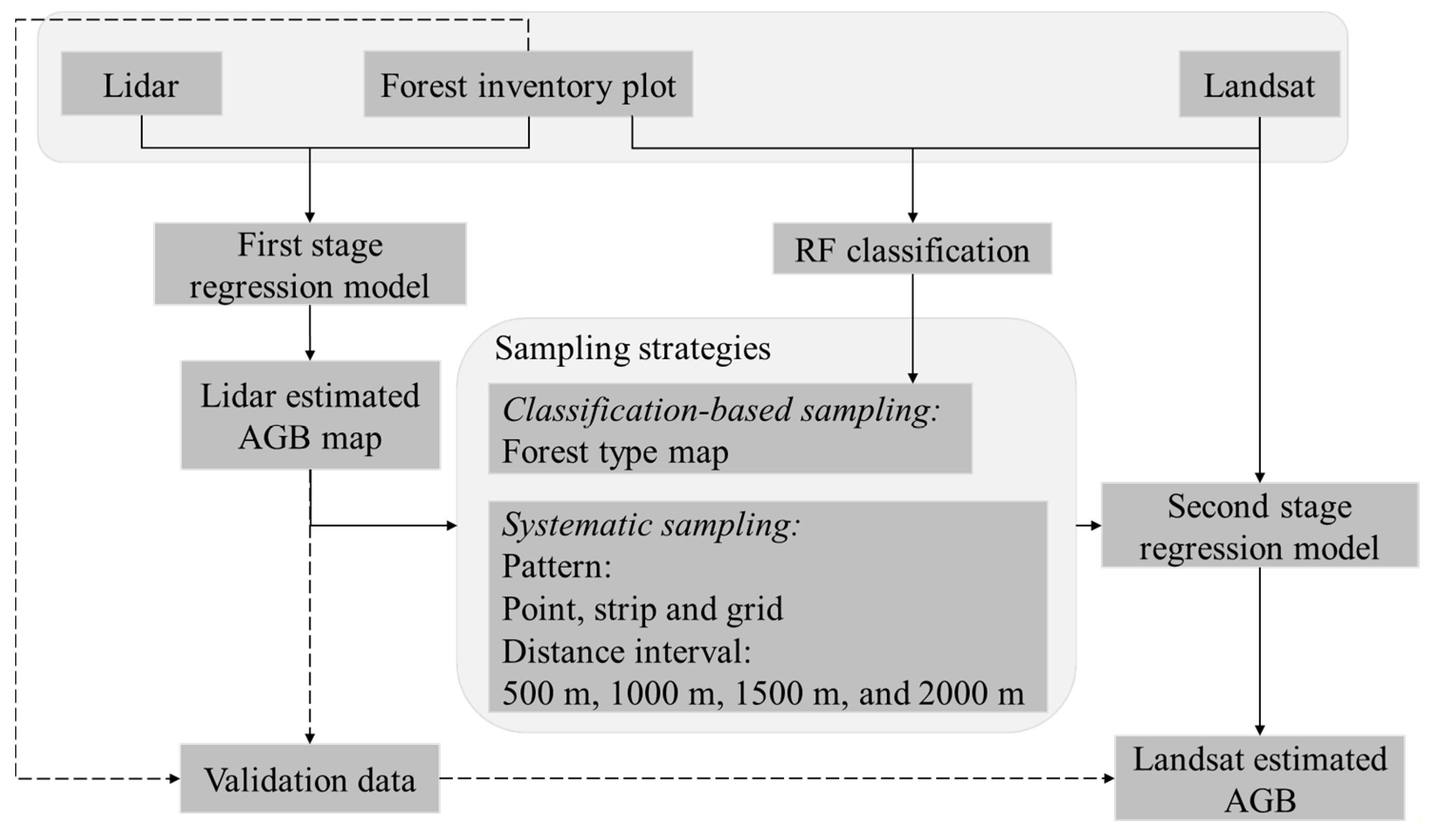
2.5. Lidar and Landsat Fusion Procedure
2.5.1. Overview
2.5.2. Regression and Variable Selection
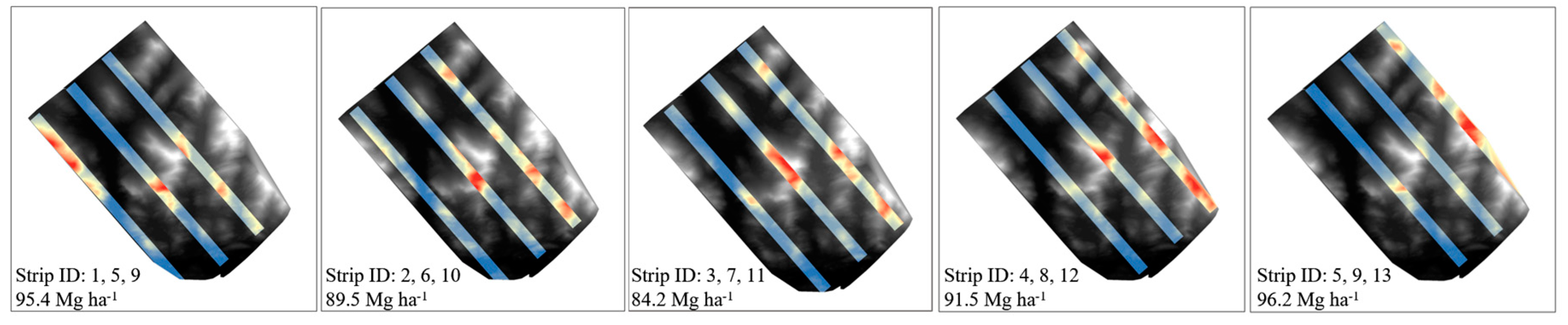
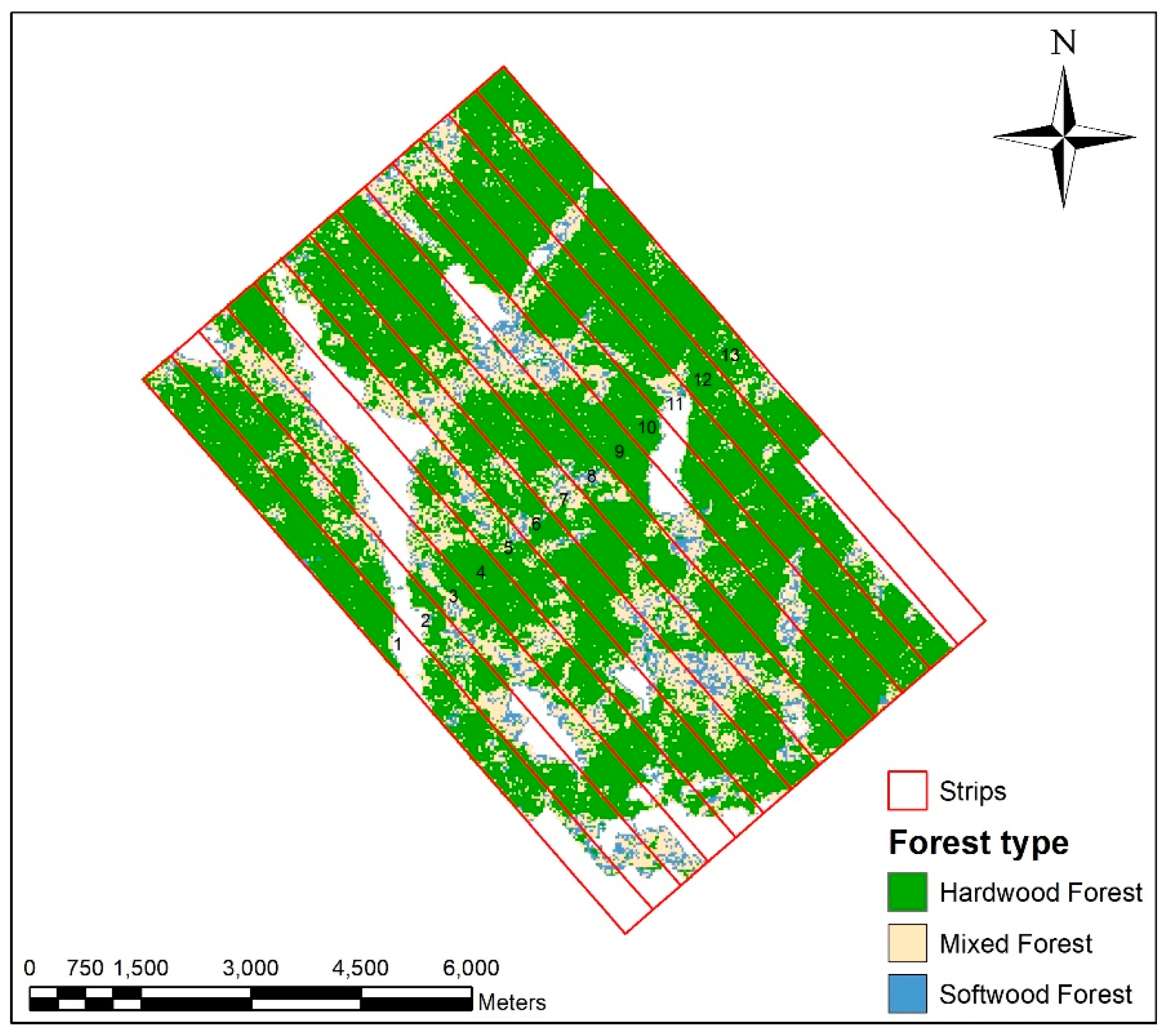
2.5.3. Lidar Sampling Strategies
2.5.4. RF Classification of Forest Type for Classification-Based Sampling
2.5.5. Chi-Square Test for Selecting Classification-Based Samples
2.5.6. Accuracy Assessment for Second Stage Regression Models
3. Results
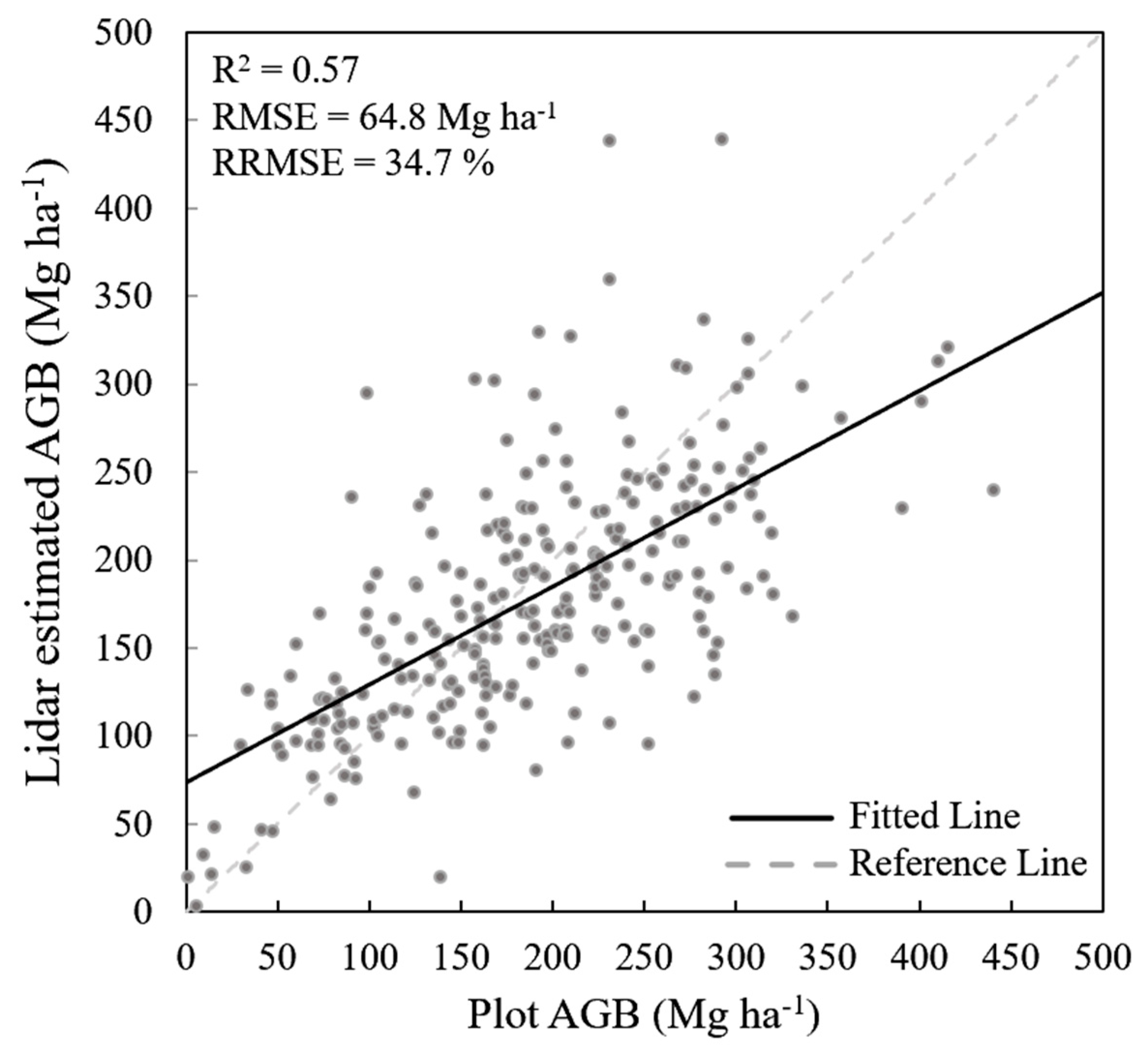
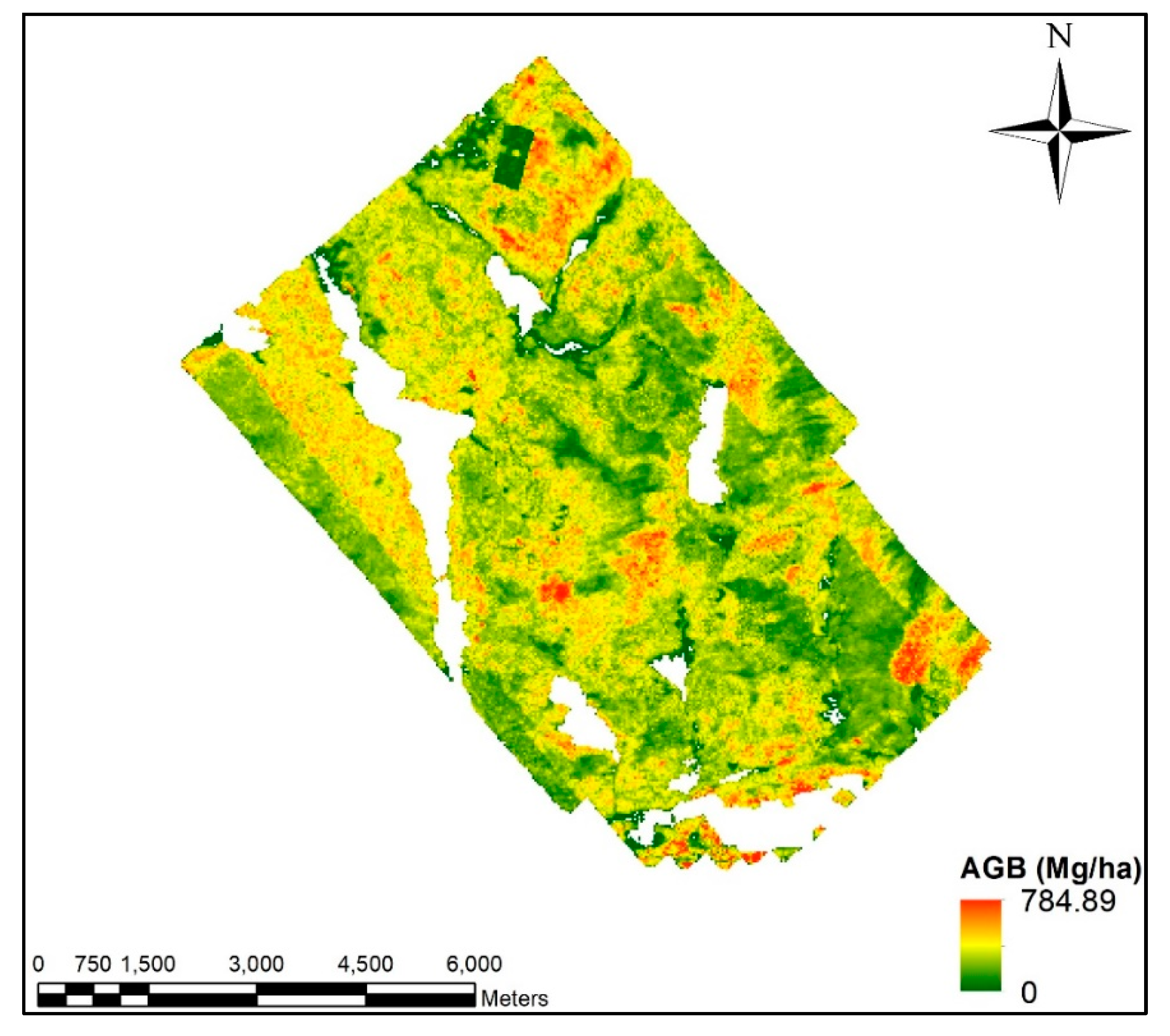
3.1. Full Lidar Coverage AGB Estimation
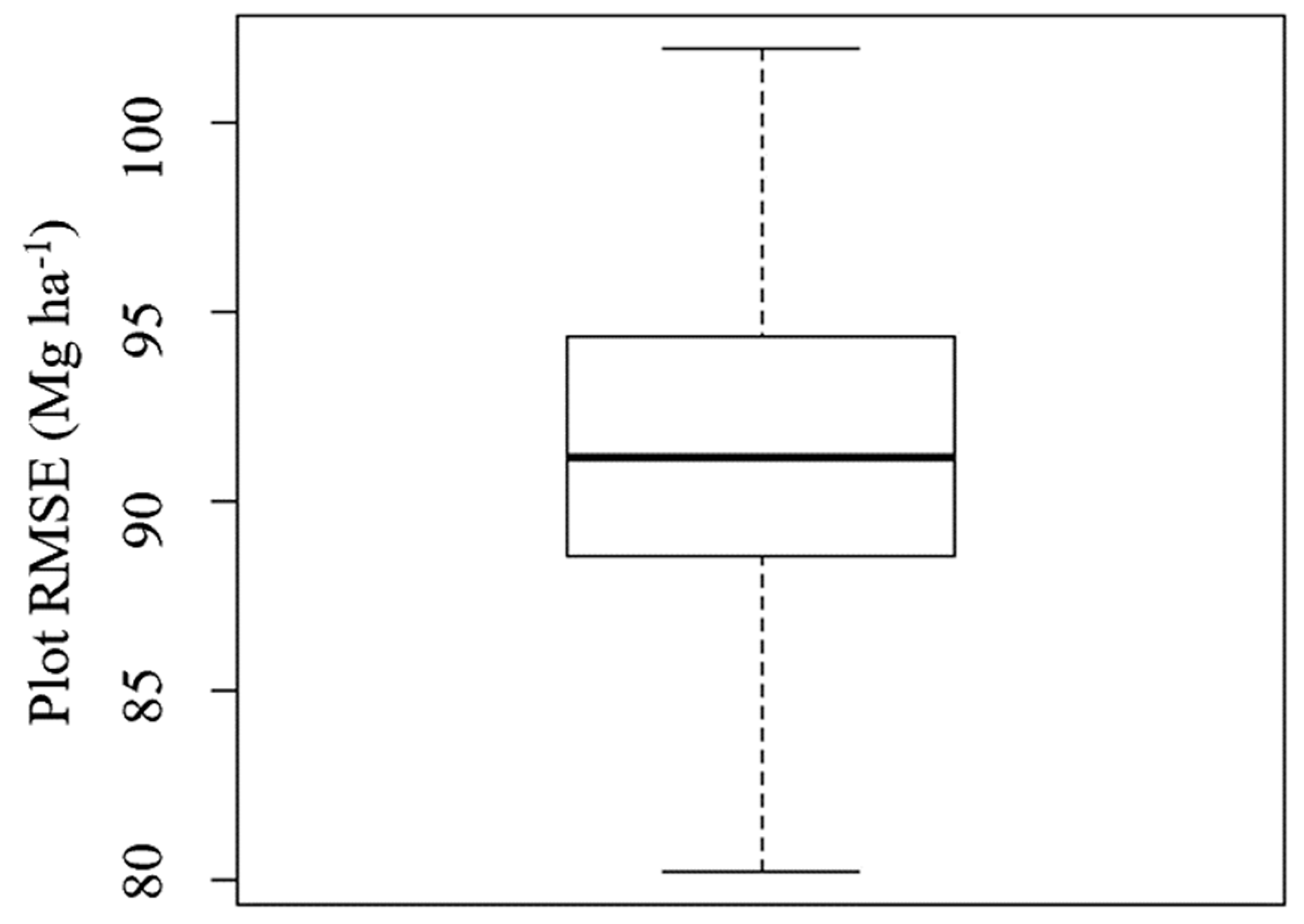
3.2. Systematic Sampling AGB Estimation for the Huntington Area
3.3. Classification-Based Sampling AGB Estimation for the Huntington Area
3.4. Testing Classification-Based Sampling for the Heiberg Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Zald, H.S. Large-area mapping of Canadian boreal forest cover, height, biomass and other structural attributes using Landsat composites and lidar plots. Remote Sens. Environ. 2018, 209, 90–106. [Google Scholar] [CrossRef]
- Chen, Q.; Laurin, G.V.; Battles, J.J.; Saah, D. Integration of airborne lidar and vegetation types derived from aerial photography for mapping aboveground live biomass. Remote Sens. Environ. 2012, 121, 108–117. [Google Scholar] [CrossRef]
- Maltamo, M.; Eerikäinen, K.; Packalén, P.; Hyyppä, J. Estimation of stem volume using laser scanning-based canopy height metrics. Forestry 2006, 79, 217–229. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Chen, Q.; Wang, G.; Moran, E.; Batistella, M.; Zhang, M.; Vaglio Laurin, G.; Saah, D. Aboveground forest biomass estimation with Landsat and LiDAR data and uncertainty analysis of the estimates. Int. J. For. Res. 2012, 2012, 1–16. [Google Scholar] [CrossRef]
- Zhang, Y.; Liang, S.; Sun, G. Forest biomass mapping of northeastern China using GLAS and MODIS data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 140–152. [Google Scholar] [CrossRef]
- Baghdadi, N.; Le Maire, G.; Bailly, J.S.; Osé, K.; Nouvellon, Y.; Zribi, M.; Lemos, C.; Hakamada, R. Evaluation of ALOS/PALSAR L-band data for the estimation of eucalyptus plantations aboveground biomass in Brazil. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3802–3811. [Google Scholar] [CrossRef]
- Knapp, N.; Huth, A.; Kugler, F.; Papathanassiou, K.; Condit, R.; Hubbell, S.P.; Fischer, R. Model-assisted estimation of tropical forest biomass change: A comparison of approaches. Remote Sens. 2018, 10, 731. [Google Scholar] [CrossRef]
- Mitchard, E.T.; Saatchi, S.S.; Woodhouse, I.H.; Nangendo, G.; Ribeiro, N.; Williams, M.; Ryan, C.M.; Lewis, S.L.; Feldpausch, T.; Meir, P. Using satellite radar backscatter to predict above-ground woody biomass: A consistent relationship across four different African landscapes. Geophys. Res. Lett. 2009, 36, L23401. [Google Scholar] [CrossRef]
- Hajj, M.; Baghdadi, N.; Fayad, I.; Vieilledent, G.; Bailly, J.-S.; Minh, D. Interest of integrating spaceborne LiDAR data to improve the estimation of biomass in high biomass forested areas. Remote Sens. 2017, 9, 213. [Google Scholar] [CrossRef]
- Kelly, M.; Di Tommaso, S. Mapping forests with Lidar provides flexible, accurate data with many uses. Calif. Agric. 2015, 69, 14–20. [Google Scholar] [CrossRef]
- Erdody, T.L.; Moskal, L.M. Fusion of LiDAR and imagery for estimating forest canopy fuels. Remote Sens. Environ. 2010, 114, 725–737. [Google Scholar] [CrossRef]
- Ediriweera, S.; Pathirana, S.; Danaher, T.; Nichols, D. Estimating above-ground biomass by fusion of LiDAR and multispectral data in subtropical woody plant communities in topographically complex terrain in North-Eastern Australia. J. For. Res. 2014, 25, 761–771. [Google Scholar] [CrossRef]
- Ørka, H.O.; Wulder, M.A.; Gobakken, T.; Næsset, E. Subalpine zone delineation using LiDAR and Landsat imagery. Remote Sens. Environ. 2012, 119, 11–20. [Google Scholar] [CrossRef]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Mauya, E.W.; Bollandsås, O.M.; Gregoire, T.G.; Ståhl, G.; Zahabu, E. Large-scale estimation of aboveground biomass in miombo woodlands using airborne laser scanning and national forest inventory data. Remote Sens. Environ. 2016, 186, 626–636. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T.; Nelson, R. Sampling and mapping forest volume and biomass using airborne LIDARs. In Proceedings of the 8th Annual Forest Inventory and Analysis Symposium, Monterey, CA, USA, 16–19 October 2006; McRoberts, R.E., Reams, G.A., Van Deusen, P.C., McWilliams, W.H., Eds.; Gen. Tech. Report WO-79. United States Department of Agriculture, Forest Service: Washington, DC, USA, 2009; Volume 79, pp. 297–301. [Google Scholar]
- Hudak, A.T.; Lefsky, M.A.; Cohen, W.B.; Berterretche, M. Integration of lidar and Landsat ETM+ data for estimating and mapping forest canopy height. Remote Sens. Environ. 2002, 82, 397–416. [Google Scholar] [CrossRef] [Green Version]
- Boudreau, J.; Nelson, R.; Margolis, H.; Beaudoin, A.; Guindon, L.; Kimes, D. Regional aboveground forest biomass using airborne and spaceborne LiDAR in Québec. Remote Sens. Environ. 2008, 112, 3876–3890. [Google Scholar] [CrossRef]
- Holmgren, J. Prediction of tree height, basal area and stem volume in forest stands using airborne laser scanning. Scand. J. For. Res. 2004, 19, 543–553. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J. An airborne lidar sampling strategy to model forest canopy height from Quickbird imagery and GEOBIA. Remote Sens. Environ. 2011, 115, 1532–1542. [Google Scholar] [CrossRef]
- Tsui, O.W.; Coops, N.C.; Wulder, M.A.; Marshall, P.L. Integrating airborne LiDAR and space-borne radar via multivariate kriging to estimate above-ground biomass. Remote Sens. Environ. 2013, 139, 340–352. [Google Scholar] [CrossRef]
- Shepard, J.P.; Mitchell, M.J.; Scott, T.J.; Zhang, Y.M.; Raynal, D.J. Measurements of wet and dry deposition in a Northern Hardwood forest. Water Air Soil Pollut. 1989, 48, 225–238. [Google Scholar] [CrossRef]
- Multi-Resolution Land Characteristics Consortium. Available online: https://www.mrlc.gov/ (accessed on 21 July 2019).
- Jenkins, J.C.; Chojnacky, D.C.; Heath, L.S.; Birdsey, R.A. National-scale biomass estimators for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- UNECE/FAO. Forest Resources of Europe, CIS, North America, Australia, Japan and New Zealand (Industrialized Temperate/Boreal Countries): UN-ECE/FAO Contribution to the Global Forest Resources Assessment 2000; United Nations: New York, NY, USA; Geneva, Switzerland, 2000. [Google Scholar]
- Software for Processing Point Clouds and Images. Available online: https://www.terrasolid.com/home.php (accessed on 15 July 2017).
- FUSION Version Check. Available online: http://forsys.cfr.washington.edu/fusion/fusionlatest.html (accessed on 8 April 2018).
- McGaughey, R.J. FUSION/LDV: Software for LIDAR Data Analysis and Visualization; United States Department of Agriculture, Forest Service, Pacific Northwest Research Station: Seattle, WA, USA, 2019.
- EarthExplorer. Available online: https://earthexplorer.usgs.gov/ (accessed on 9 March 2018).
- Harris Geospatial Solutions. Available online: http://www.harrisgeospatial.com/Home.aspx (accessed on 9 March 2018).
- Bacour, C.; Bréon, F.M.; Maignan, F. Normalization of the directional effects in NOAA–AVHRR reflectance measurements for an improved monitoring of vegetation cycles. Remote Sens. Environ. 2006, 102, 402–413. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of leaf-area index from quality of light on the forest floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.; Kerr, Y.; Sorooshian, S. A modified soil adjusted vegetation index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Li, M.; Im, J.; Beier, C. Machine learning approaches for forest classification and change analysis using multi-temporal Landsat TM images over Huntington Wildlife Forest. GISci. Remote Sens. 2013, 50, 361–384. [Google Scholar] [CrossRef]
- Ali, A.; Lin, S.L.; He, J.K.; Kong, F.M.; Yu, J.H.; Jiang, H.S. Tree crown complementarity links positive functional diversity and aboveground biomass along large-scale ecological gradients in tropical forests. Sci. Total Environ. 2019, 656, 45–54. [Google Scholar] [CrossRef] [PubMed]
- Van Vinh, T.; Marchand, C.; Linh, T.V.K.; Vinh, D.D.; Allenbach, M. Allometric models to estimate above-ground biomass and carbon stocks in Rhizophora apiculata tropical managed mangrove forests (Southern Vietnam). For. Ecol. Manag. 2019, 434, 131–141. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Richardson, H.J.; Hill, D.J.; Denesiuk, D.R.; Fraser, L.H. A comparison of geographic datasets and field measurements to model soil carbon using random forests and stepwise regressions (British Columbia, Canada). GISci. Remote Sens. 2017, 54, 573–591. [Google Scholar] [CrossRef]
- R Project. Available online: http://www.R-project.org (accessed on 17 March 2018).
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.; Kobayashi, N.; Mochizuki, K. Assessing the suitability of data from Sentinel-1A and 2A for crop classification. GISci. Remote Sens. 2017, 54, 918–938. [Google Scholar] [CrossRef]
- Zhang, C.; Smith, M.; Fang, C. Evaluation of Goddard’s LiDAR, hyperspectral, and thermal data products for mapping urban land-cover types. GISci. Remote Sens. 2018, 55, 90–109. [Google Scholar] [CrossRef]
- Boisvenue, C.; Smiley, B.P.; White, J.C.; Kurz, W.A.; Wulder, M.A. Integration of Landsat time series and field plots for forest productivity estimates in decision support models. For. Ecol. Manag. 2016, 376, 284–297. [Google Scholar] [CrossRef]
- Ghosh, S.M.; Behera, M.D. Aboveground biomass estimation using multi-sensor data synergy and machine learning algorithms in a dense tropical forest. Appl. Geogr. 2018, 96, 29–40. [Google Scholar] [CrossRef]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Tian, X.; Yan, M.; van der Tol, C.; Li, Z.; Su, Z.; Chen, E.; Li, X.; Li, L.; Wang, X.; Pan, X.; et al. Modeling forest above-ground biomass dynamics using multi-source data and incorporated models: A case study over the qilian mountains. Agric. For. Meteorol. 2017, 246, 1–14. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Hopkinson, C.; Chasmer, L.; Gynan, C.; Mahoney, C.; Sitar, M. Multisensor and multispectral lidar characterization and classification of a forest environment. Can. J. Remote Sens. 2016, 42, 501–520. [Google Scholar] [CrossRef]
- Luo, S.; Chen, J.M.; Wang, C.; Xi, X.; Zeng, H.; Peng, D.; Li, D. Effects of LiDAR point density, sampling size and height threshold on estimation accuracy of crop biophysical parameters. Opt. Express 2016, 24, 11578–11593. [Google Scholar] [CrossRef]
- Saarela, S.; Grafström, A.; Ståhl, G.; Kangas, A.; Holopainen, M.; Tuominen, S.; Nordkvist, K.; Hyyppä, J. Model-assisted estimation of growing stock volume using different combinations of LiDAR and Landsat data as auxiliary information. Remote Sens. Environ. 2015, 158, 431–440. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; St-Onge, B. A GEOBIA framework to estimate forest parameters from lidar transects, Quickbird imagery and machine learning: A case study in Quebec, Canada. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 28–37. [Google Scholar] [CrossRef]
- Feng, Y.; Lu, D.; Chen, Q.; Keller, M.; Moran, E.; dos-Santos, M.N.; Bolfe, E.L.; Batistella, M. Examining effective use of data sources and modeling algorithms for improving biomass estimation in a moist tropical forest of the Brazilian Amazon. Int. J. Digit. Earth 2017, 10, 996–1016. [Google Scholar] [CrossRef]
- Li, W.; Niu, Z.; Liang, X.; Li, Z.; Huang, N.; Gao, S.; Wang, C.; Muhammad, S. Geostatistical modeling using LiDAR-derived prior knowledge with SPOT-6 data to estimate temperate forest canopy cover and above-ground biomass via stratified random sampling. Int. J. Appl. Earth Obs. Geoinf. 2015, 41, 88–98. [Google Scholar] [CrossRef]
- Skowronski, N.S.; Clark, K.L.; Gallagher, M.; Birdsey, R.A.; Hom, J.L. Airborne laser scanner-assisted estimation of aboveground biomass change in a temperate oak–pine forest. Remote Sens. Environ. 2014, 151, 166–174. [Google Scholar] [CrossRef]
- Zhao, P.; Lu, D.; Wang, G.; Wu, C.; Huang, Y.; Yu, S. Examining spectral reflectance saturation in Landsat imagery and corresponding solutions to improve forest aboveground biomass estimation. Remote Sens. 2016, 8, 469. [Google Scholar] [CrossRef]
- Nichol, J.E.; Sarker, M.L.R. Improved biomass estimation using the texture parameters of two high-resolution optical sensors. IEEE Trans. Geosci. Remote Sens. 2010, 49, 930–948. [Google Scholar] [CrossRef]
- Shen, W.; Li, M.; Huang, C.; Tao, X.; Wei, A. Annual forest aboveground biomass changes mapped using ICESat/GLAS measurements, historical inventory data, and time-series optical and radar imagery for Guangdong province, China. Agric. For. Meteorol. 2018, 259, 23–38. [Google Scholar] [CrossRef] [Green Version]
- Vaglio Laurin, G.; Pirotti, F.; Callegari, M.; Chen, Q.; Cuozzo, G.; Lingua, E.; Notarnicola, C.; Papale, D. Potential of ALOS2 and NDVI to estimate forest above-ground biomass, and comparison with lidar-derived estimates. Remote Sens. 2017, 9, 18. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C. Update of forest inventory data with lidar and high spatial resolution satellite imagery. Can. J. Remote Sens. 2008, 34, 5–12. [Google Scholar] [CrossRef]
- Almeida, D.R.A.d.; Stark, S.C.; Shao, G.; Schietti, J.; Nelson, B.W.; Silva, C.A.; Gorgens, E.B.; Valbuena, R.; Papa, D.d.A.; Brancalion, P.H.S. Optimizing the remote detection of tropical rainforest structure with airborne lidar: Leaf area profile sensitivity to pulse density and spatial sampling. Remote Sens. 2019, 11, 92. [Google Scholar] [CrossRef]
- Cao, L.; Coops, N.C.; Sun, Y.; Ruan, H.; Wang, G.; Dai, J.; She, G. Estimating canopy structure and biomass in bamboo forests using airborne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2019, 148, 114–129. [Google Scholar] [CrossRef]
- Gregoire, T.G.; Ståhl, G.; Næsset, E.; Gobakken, T.; Nelson, R.; Holm, S. Model-assisted estimation of biomass in a LiDAR sample survey in Hedmark County, Norway. Can. J. For. Res. 2010, 41, 83–95. [Google Scholar] [CrossRef]
- Zheng, D.; Rademacher, J.; Chen, J.; Crow, T.; Bresee, M.; Le Moine, J.; Ryu, S.-R. Estimating aboveground biomass using Landsat 7 ETM+ data across a managed landscape in northern Wisconsin, USA. Remote Sens. Environ. 2004, 93, 402–411. [Google Scholar] [CrossRef]
- Zheng, G.; Chen, J.M.; Tian, Q.J.; Ju, W.M.; Xia, X.Q. Combining remote sensing imagery and forest age inventory for biomass mapping. J. Environ. Manag. 2007, 85, 616–623. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Yanai, R.D.; See, C.R.; Arthur, M.A. Sampling effort and uncertainty in leaf litterfall mass and nutrient flux in northern hardwood forests. Ecosphere 2017, 8, e01999. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Forest Type | Plot Count | AGB (Mg ha−1) | ||||
|---|---|---|---|---|---|---|---|
| Mean | Median | Standard Deviation | Min | Max | |||
| Huntington | Total | 270 | 186.6 | 186.3 | 82.5 | 0.9 | 440.3 |
| Hardwood | 194 | 182.3 | 184.5 | 81.8 | 0.9 | 440.3 | |
| Mixed | 60 | 211.9 | 208.7 | 73.9 | 68.8 | 390.7 | |
| Softwood | 16 | 144.3 | 133.9 | 98.8 | 9.1 | 314.7 | |
| Heiberg | Total | 43 | 212.6 | 215.9 | 98.4 | 2.0 | 375.8 |
| Hardwood | 31 | 220.8 | 249.7 | 98.5 | 2.0 | 375.8 | |
| Mixed | 9 | 220.3 | 249.0 | 88.6 | 76.4 | 323.9 | |
| Softwood | 3 | 104.9 | 59.5 | 86.9 | 50.1 | 205.1 | |
| Study Site | Huntington | Heiberg |
|---|---|---|
| Scan field of view (FOV) | 24° | 28° |
| Outgoing pulse width | 4 ns | 4 ns |
| Flying altitude | 540 m | 487 m |
| Swath width | ~542 m | ~554 m |
| Average point density | >10 pts/m2 | >7 pts/m2 |
| Laser pulse rate | 218.7 kHz | 183.8 kHz |
| Acquisition date | 10 September 2011 | 10 August 2010 |
| Variable Name | Description | Variable Name | Description |
|---|---|---|---|
| Pt_total | Total number of returns | ht_P50 | 50th percentile of height |
| Pt_first | Count of first returns | ht_P60 | 60th percentile of height |
| Pt_second | Count of second returns | ht_P70 | 70th percentile of height |
| Pt_third | Count of third returns | ht_P75 | 75th percentile of height |
| ht_min | Height minimum | ht_P80 | 80th percentile of height |
| ht_max | Height maximum | ht_P90 | 90th percentile of height |
| ht_mean | Height mean | ht_P95 | 95th percentile of height |
| ht_mode | Height mode | ht_P99 | 99th percentile of height |
| ht_stddev | Height standard deviation | Per-first-5 m | Percentage of first returns above 5 m |
| ht-variance | Height variance | Per-first-mean | Percentage of first returns above mean |
| ht-CV | Height coefficient of variation | Per-first-mode | Percentage of first returns above mode |
| ht-skewness | Height skewness | Per-all-5 m | Percentage of all returns above 5 m |
| ht-hurtosis | Height kurtosis | Per-all-mean | Percentage of all returns above mean |
| ht-AAD | Height absolute deviation from mean | Per-all-mode | Percentage of all returns above mode |
| ht_P01 | 1st percentile of height | First-abv-mean | First returns above mean |
| ht_P05 | 5th percentile of height | First-abv-mode | First returns above mode |
| ht_P10 | 10th percentile of height | All-abv-mean | All returns above mean |
| ht_P20 | 20th percentile of height | All-abv-mode | All returns above mode |
| ht_P25 | 25th percentile of height | First-returns | Total first returns |
| ht_P30 | 30th percentile of height | All-returns | Total all returns |
| ht_P40 | 40th percentile of height | Canopy relief ratio | ((mean-min)/(max-min)) |
| Vegetation Index | Equation | Source |
|---|---|---|
| DVI | B4 − B3 | Bacour et al. [30] |
| RVI | B4/B3 | Jordan [31] |
| NDVI | (B4 − B3)/(B4 + B3) | Tucker [32] |
| SAVI | 1.5 × (B4 − B3)/(B4 + B3 + 0.5) | Huete [33] |
| MASVI | Qi et al. [34] |
| Sampling Strategy | Model Fitting | Model Testing | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Plot Based Reference | Lidar Based Reference | ||||||||
| Pixel Count | R2 | MAE (Mg Ha−1) | RMSE (Mg Ha−1) | RRMSE (%) | MAE (Mg Ha−1) | RMSE (Mg Ha−1) | RRMSE (%) | ||
| Point | 500 m | 14,772 | 0.20 | 71.5 | 89.3 | 47.8 | 55.4 | 71.7 | 41.6 |
| 1000 m | 6880 | 0.30 | 73.8 | 92.8 | 49.7 | 58.6 | 76.5 | 44.4 | |
| 1500 m | 3906 | 0.41 | 74.6 | 93.9 | 50.3 | 62.0 | 81.1 | 47.0 | |
| 2000 m | 3268 | 0.31 | 71.8 | 90.1 | 48.3 | 56.9 | 74.3 | 43.1 | |
| Strip | 500 m | 29,743 | 0.24 | 72.0 | 89.7 | 48.1 | 55.7 | 72.2 | 41.9 |
| 1000 m | 19,727 | 0.23 | 74.2 | 92.5 | 49.6 | 57.5 | 74.6 | 43.3 | |
| 1500 m | 15,335 | 0.19 | 67.3 | 84.2 | 45.1 | 54.0 | 70.5 | 40.9 | |
| 2000 m | 15,193 | 0.14 | 69.8 | 87.3 | 46.8 | 55.2 | 70.8 | 41.0 | |
| Grid | 500 m | 45,962 | 0.22 | 71.6 | 89.3 | 47.9 | 55.4 | 71.9 | 41.7 |
| 1000 m | 34,185 | 0.24 | 73.0 | 91.0 | 48.8 | 56.4 | 73.3 | 42.5 | |
| 1500 m | 27,316 | 0.22 | 70.8 | 88.7 | 47.5 | 55.3 | 72.1 | 41.8 | |
| 2000 m | 24,735 | 0.19 | 73.4 | 91.8 | 49.2 | 56.8 | 73.4 | 42.6 | |
| Sampling Strategy | Model Fitting | Model Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| Plot Based Reference | Lidar Based Reference | |||||||
| Pixel Count | R2 | MAE (Mg Ha−1) | RMSE (Mg Ha−1) | RRMSE (%) | MAE (Mg Ha−1) | RMSE (Mg Ha−1) | RRMSE (%) | |
| Strip 6, 7, 8 | 16,446 | 0.26 | 70.1 | 87.4 | 47.0 | 54.7 | 70.9 | 41.0 |
| Sampling Strategy | Model Fitting | Model Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| Plot Based Reference | Lidar Based Reference | |||||||
| Pixel Count | R2 | MAE (Mg ha−1) | RMSE (Mg ha−1) | RRMSE (%) | MAE (Mg ha−1) | RMSE (Mg ha−1) | RRMSE (%) | |
| Strip 2, 4, 7 | 2097 | 0.40 | 91.8 | 108.2 | 50.4 | 121.2 | 136.0 | 63.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Quackenbush, L.J.; Im, J. Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery. Remote Sens. 2019, 11, 1906. https://doi.org/10.3390/rs11161906
Li S, Quackenbush LJ, Im J. Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery. Remote Sensing. 2019; 11(16):1906. https://doi.org/10.3390/rs11161906
Chicago/Turabian StyleLi, Siqi, Lindi J. Quackenbush, and Jungho Im. 2019. "Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery" Remote Sensing 11, no. 16: 1906. https://doi.org/10.3390/rs11161906
APA StyleLi, S., Quackenbush, L. J., & Im, J. (2019). Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery. Remote Sensing, 11(16), 1906. https://doi.org/10.3390/rs11161906