1. Introduction
Changes in land use and land cover have great implications on a range of ecosystem functions [
1,
2,
3]. Particularly changes in forest areas have received considerable research attention in recent years, due to their impacts on biodiversity and carbon pools [
4,
5]. Resultantly, the development of reliable and timely systems for monitoring forest change across different spatial and temporal scales has become a central task in forestry. Primary motives have been the provision of data for national users such as government and conservation agencies, forest organizations and industries, and international reporting in accordance with treaties and conventions. Although forest changes typically are monitored in national programs [
6,
7] and reported at a national level, forest management decisions that directly induce those changes are made locally, namely at the level of municipalities, forest properties, and stands, i.e., treatment units. At such local scales, sampling rates of national monitoring programs are too low to obtain the necessary information [
8], and local inventories are carried out to inform forest management.
Remote sensing provides a means to collect large amounts of information on forest attributes, and recent decades have witnessed substantial innovations in remote sensing technologies and data processing algorithms [
9,
10]. This has greatly facilitated the use of remotely sensed data for forest monitoring across various spatial and temporal scales. At global and national levels, coarse resolution optical satellite imagery provides useful information for estimating forest cover [
11,
12] and biomass [
13,
14]. At the level of forest properties and stands, high-resolution three-dimensional data have proven particularly useful for forest inventory applications [
15]. Airborne laser scanning (ALS) provides accurate three-dimensional data on terrain surface and vegetation height, and in forest management inventories in numerous countries across the globe, it is common practice to use ALS data in estimating and mapping forest attributes [
16] for local management needs.
ALS-based forest management inventories typically cover areas in the range of 100–1000 km
2 per project [
17], in which forest attributes are commonly estimated and mapped using the area-based approach [
18,
19]. This approach involves developing statistical relationships between forest attributes and ALS metrics at the level of sample plots and predicting the attributes over a grid tessellating the entire inventory area into smaller cells. In stand-level forest inventories, model predictions for grid cells within stands are typically aggregated to obtain stand estimates. Alternatively, cell-level predictions can be used for wall-to-wall mapping of forest attributes [
20], or as auxiliary information in probability-based sampling designs [
21]. Parametric modeling techniques such as linear regression have widely been used due to their familiarity and practicality; however, they require assumptions regarding the distribution of the response variable, the model errors, and the absence of multicollinearity and autocorrelation. Because such assumptions may be violated in certain forest inventory applications for which remotely sensed data are used, nonparametric approaches have been studied extensively, such as nearest neighbor methods [
22], regression trees [
23], and neural networks [
24]. Among these, nearest neighbor methods have become very popular in the field of forest inventory because they can easily be used for a wide range of applications, including classification, univariate and multivariate prediction, imputation, mapping, and inference [
25].
The availability of multitemporal ALS data is increasing as ALS-based forest inventories are repeated through multiple cycles. Bitemporal ALS data have proven useful for estimating forest height growth [
26,
27] and aboveground biomass (AGB) change [
28,
29,
30]. Although the quantification of changes in the mentioned attributes is highly relevant for forest planning, many applications in forestry require classification into discrete categories. Categorical variables such as dominant tree species, forest development class, and forest productivity have long been fundamental in forest planning. As ALS-based forest inventories are starting to be repeated in many countries, possibilities for new classification systems emerge that allow for temporal change monitoring.
A range of forest inventory applications may benefit from change classification. First, recent studies have shown that canopy height growth as depicted by bitemporal ALS data enables the estimation of forest productivity [
31,
32,
33]. Forest productivity is among the most essential variables in forest management and is expensive to record in field surveys. The estimation of forest productivity requires the height of dominant trees (Hdom) to have increased during the observation period, as forest productivity would be underestimated in cases where Hdom growth has been disrupted. This calls for a classification of forest into positive and negative Hdom development prior to the estimation of forest productivity itself. Second, AGB change classes can be used as post-strata in AGB change estimation [
34], and changes can be projected spatially to identify areas where changes have occurred, their spatial extents alone being relevant reporting units. Third, forest disturbance events such as storm damage and harvest have gained relevance due to their impacts on forest ecosystems [
35,
36,
37,
38] and carbon balances [
30,
39]. Finally, classification of forestry activities such as untouched, partial harvest, and clearcut are crucial for estimating and reporting net forest carbon fluxes, given that carbon emissions and removals must be attributed to certain offset activities [
34].
Previous research has shown that single-date ALS data can be used to indicate past forest disturbances and silvicultural operations. For example, d’Oliveira et al. [
40] used structural ALS metrics over a tropical forest in Brazil to identify selective logging. Other studies using single-date ALS data discriminated between forest development classes [
41,
42,
43] and forest/non-forest classes for the purpose of stand delineation [
44,
45,
46]. To monitor changes in forest structure over time, however, multitemporal data are needed. Bitemporal ALS data have been used to identify single harvested trees [
47] and monitor canopy gap dynamics [
48,
49,
50]. Næsset et al. [
34] used bitemporal ALS data with a temporal resolution of 11 years to classify untouched, partial harvest, and clearcut forest at plot-level in a boreal forest in southeastern Norway using multinomial logistic regression. To the best of our knowledge, however, no further research has been done on the use of multitemporal ALS data for forest change classification. Here, we present the first study assessing the use of bitemporal ALS data for classification of various changes in forest structure. We used data acquired as part of repeated operational inventories carried out by a forest owner’s cooperative and demonstrated how such data can be used for local forest change monitoring.
The objective of this study was to assess the utility of bitemporal ALS data for classification of Hdom change, AGB change, forest disturbances and forestry activities. We distinguished between the following change classes: (i) increasing versus decreasing Hdom, (ii) increasing versus decreasing AGB, (iii) undisturbed versus disturbed forest and (iv) forestry activities namely untouched, partial harvest and clearcut.
2. Material and Methods
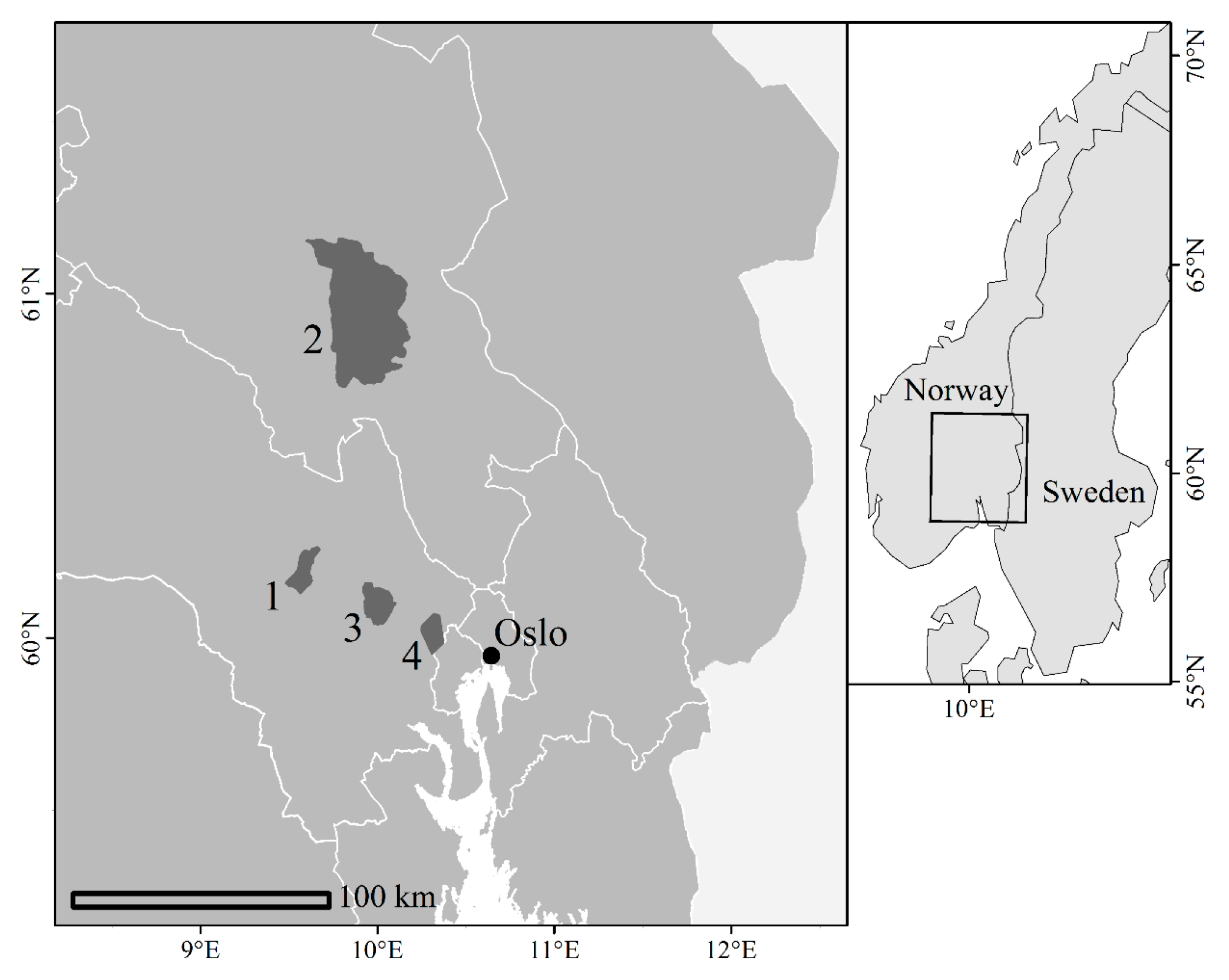
2.1. Study Areas
We used bitemporal field and ALS data acquired as part of four repeated forest inventories in southeastern Norway (
Figure 1). The inventories were carried out by Viken Skog SA, a Norwegian forest owner’s cooperative, and were among the first commercial ALS-based trials in the early 2000s [
17]. They were also among the first repeated ALS-based inventories. District 1 was part of the municipality of Krødsherad (60°10′N 9°35′E, 130–660 m above sea level) and comprised about 5000 ha productive forest [
51]. The dominant tree species in the area are Norway spruce (
Picea abies (L.) Karst.) and Scots pine (
Pinus sylvestris L.). District 2 comprised about 49,000 ha productive forest in the municipality of Nordre Land (60°50′N 10°5′E, 140–900 m above sea level) [
52], also mainly composed of Norway spruce and Scots pine. District 3, the district of Tyristrand (60°6′N 10°2′E, 150–480 m above sea level), comprised about 13,000 ha productive forest where Scots pine is the main species [
17]. Lastly, District 4 was part of the municipality of Hole (60°1′N 10°20′E, 240–540 m above sea level) which comprises 6500 ha productive forest, dominated by Norway spruce [
53].
2.2. Field Data
During the first inventory cycle (t
1), circular sample plots were distributed systematically throughout the districts by means of systematic stratified sampling designs. The sample plots had a radius of 8.61 m for district 1 and 8.92 m for the remaining districts, resulting in plot sizes of 233 m
2 and 250 m
2, respectively (
Table 1). These are typical plot sizes in Norwegian operational forest inventories [
54]. Stratification was carried out according to dominant tree species, site productivity, and forest development class as interpreted from aerial images, for details see [
17,
51,
52,
53]. In Norway, development classes represent the succession of production forest [
55], where class 1 represents clear-felled stands, class 2 represents regeneration forests, typically with a height <10 m, class 3 represents young forest, class 4 represents mature forest, and class 5 represents forest ready for harvest. Development class 1 was omitted from the inventories, and at t
1, development class 2 was only included in the inventory of district 1. During the second inventory cycle (t
2), all plots were revisited, and they were remeasured unless a final harvest recently had taken place. For plots that had been subject to final harvest, those for which sufficient time had passed for regeneration to occur were remeasured if the regenerated forest had reached a height >0.5 m.
Table 1 provides an overview of the inventories and the number of plots within forest development classes.
2.3. Plot Positioning
At t
1, plot center coordinates were determined using differential global navigation satellite systems (dGNSS) with Javad Legacy 20-channel receivers. The receivers measured pseudorange and carrier phase observables of the global positioning system (GPS) and the global navigation satellite system (GLONASS). A Javad Legacy served as a local base station. During post-processing, the coordinates were corrected against the collected reference data, and average accuracies of the planimetric plot center coordinates were <50 cm according to the positional standard errors reported by the Pinnacle 1.0 post-processing software. Plot centers were marked with wooden sticks. Upon revisiting the plots at t
2, a 226-channel Topcon HiPer SR was used in real-time kinematic mode to navigate to the plot centers. In case the wooden stick was not found, the position was remeasured using a Topcon Legacy E 40-channel receiver. During post-processing, the coordinates were corrected against reference data from the base stations of the Norwegian Mapping Authority using the software Magnet Tools [
56].
2.4. Tree Measurements
On plots within forest development classes 3–5, the diameter at breast height (DBH) of trees exceeding given lower caliper limits was measured using a caliper during both inventory cycles. The lower caliper limits varied across districts and forest development classes, however on all plots, trees with a DBH ≥10 cm were calipered. For consistency, we excluded trees with a DBH <10 cm from the analysis across all districts and development classes. Furthermore, a sample of about 10 trees per plot was selected using a relascope and their heights were measured using a Vertex hypsometer.
On regeneration plots in district 1 and 2, four circular subplots of 40 m2 were measured in cardinal directions from the plot center at a distance of 5.10 m. In district 3 and 4, three subplots of 40 m2 were measured in north, southwest, and southeast directions at a distance of 5.35 m from the plot center. The radius around subplot centers was determined using a telescopic rod of 3.57 m. The subplots were divided into four quadrants in cardinal directions, and tree measurements were carried out within the separate quadrants. DBHs were not measured, as plot volumes were not calculated for regeneration plots in the inventories. The heights of the first tree in each quadrant, counting in a clockwise direction, and the first subjectively chosen dominant tree in each quadrant were measured using a height pole for trees with a height <8 m and a Vertex hypsometer for taller trees. A maximum of two dominant trees were selected in each quadrant.
2.5. Computation of Forest Attributes
Tree heights had only been measured for sample trees on plots of development classes 3–5. Thus, we estimated the heights of all calipered trees using a ratio estimator described in detail in Ørka et al. [
57], based on the ratio between heights predicted with empirical DBH-height models and field-measured heights. We then computed Hdom as the mean predicted height of the trees corresponding to the largest 100 trees per ha, according to DBH [
58]. Furthermore, we computed N as the number of calipered trees on each plot, scaled to a per hectare basis. Lastly, we predicted the AGB of individual trees using allometric models estimated by Marklund [
59], and computed plot-level AGB as the sum of biomass predictions scaled to a per hectare basis.
For regeneration plots, we computed Hdom as the mean heights of dominant trees. We assumed values of AGB on regeneration plots to be negligible and thus zero. A summary of the computed field plot data is shown in
Figure 2.
2.6. Field Data Classification
We assigned forest change classes to each plot according to changes in the computed forest attributes, dividing the plots into distinct change classes for the four classification schemes. The classification schemes were aimed at distinguishing between different changes in forest structure with increasing complexity. For classification of Hdom change, we discriminated between plots on which Hdom had increased and decreased during the observation period (
Table 2). For classification of AGB change, the classes were defined as increased or decreased AGB. For the classification of forest disturbance, the classes were defined as undisturbed plots or disturbed plots, using changes in forest structure as proxies for disturbances. We applied the rule that a decrease in Hdom or AGB, or a reduction in N of at least 30% indicated that a disturbance had taken place during the observation period. Such reductions in forest attributes would rule out a natural succession and corresponding growth and mortality rates, and would therefore indicate that a substantial disturbance such as storm damage or thinning had occurred. For the classification of forestry activity, we further separated these changes by distinguishing between untouched, partial harvest and clearcut classes. The untouched class comprised plots on which no activity had taken place, i.e., undisturbed plots. The partial harvest class included plots that had been subject to a temporary reduction in Hdom, AGB, or N. The undisturbed class comprised plots on which the same reductions had occurred, and additionally, a reduction in AGB of at least 90%.
2.7. ALS Data
At t
1, four ALS surveys were carried out using the Optech instruments ALTM 1233 and ALTM 3100 in the years 2001–2005, the acquisition parameters are shown in
Table 3. At t
2, two ALS surveys were flown with a Riegl LMS Q-1560 scanner, where one of two surveys covered districts 1, 3, and 4. All ALS data were acquired under leaf-on conditions. The contractors Fotonor AS and TerraTec AS processed the ALS data and generated terrain surface models as triangulated irregular networks from laser returns classified as ground. Heights relative to the ground were computed for the remaining laser returns by subtracting the terrain height from ellipsoidal height.
2.8. ALS Metrics
For each plot, we extracted the laser returns for both points in time using the plot coordinates measured at t2. We computed ALS metrics from the height distributions of first returns only because we expected them to be most sensitive to canopy changes. Considering all first returns with a height >2 m relative to the ground as vegetation returns, we computed heights at the 10th, 20th, …, 90th percentiles, denoted h10, h20, …, h90, and the maximum and mean vegetation return heights, denoted hmax and hmean, respectively. Furthermore, we computed the standard deviation, kurtosis, coefficient of variation, and skewness of the vegetation return height distributions, denoted hsd, hkurt, hcv, and hskewness, respectively. We computed canopy density metrics by partitioning the range of vegetation return heights into 10 vertical fractions of equal height and dividing the cumulative number of returns within each fraction by the total number of returns. Density metrics were denoted d0, d1, …, d9. We also computed the total number of vegetation returns, denoted n. ALS metrics from the first and second inventory cycles were denoted _t1 and _t2, respectively. Finally, we computed differential (Δ) ALS metrics as the differences between corresponding ALS metrics computed for t1 and t2.
2.9. Forest Change Classification
We used the k-nearest neighbor (kNN) method [
60] to classify forest change at plot-level on the basis of the computed ALS metrics described in the previous section. The method is known to be well suited to datasets with large numbers of ALS height and density metrics that may be correlated [
61]. In kNN classification, each target unit is classified based on the k closest reference units in the feature space. The reference set comprises a set of labeled examples, and proximity must be determined on the basis of the distance between reference and target units using a given distance metric. Many distance metrics have been proposed, the Euclidian metric being the most common in forestry applications where nearest neighbor approaches are applied to remotely sensed data [
22]. We used the Minkowski metric:
where
are m-dimensional vectors of ALS metrics and p is the Minkowski parameter. Note that the Minkowski metric equals the Manhattan metric given p = 1 and the Euclidian metric given p = 2. We performed the classification for each district separately, using the kknn package in R. Allowing a maximum of three ALS metrics to avoid overfitting, we implemented a grid search over all potential combinations of ALS metrics, k = 1, 3, 5, 7, and 9, and p = 1 and 2 to select the classifier that yielded the highest kappa [
62] in leave-one-out cross-validation. We considered kappa to be a suitable criterion due to the uneven class sizes (
Table 2).
2.10. Accuracy Assessment
We assessed the performance of the classifiers according to their overall accuracy, user’s accuracy, and kappa as obtained from leave-one-out cross-validation. We computed the overall accuracy as the percentage of correct classifications, the user’s accuracy as the percentage of correct classifications in each predicted class, and the kappa as the chance-standardized version of the overall accuracy [
63]. We also computed accuracies across the four districts using aggregated confusion matrices for each classification scheme.
3. Results
The ALS metrics and classification parameters that yielded the highest kappa values are shown in
Table 4. Differential ALS metrics were selected for most classifiers, frequently in combination with an ALS metric from t
1 or t
2. For most classifications, the highest kappa was obtained by including three ALS metrics and one or three nearest neighbors. In most cases, a Minkowski distance parameter of 2 was selected, although in many cases, a Minkowski parameter of 1 and/or other combinations of ALS metrics produced similar or identical values of kappa.
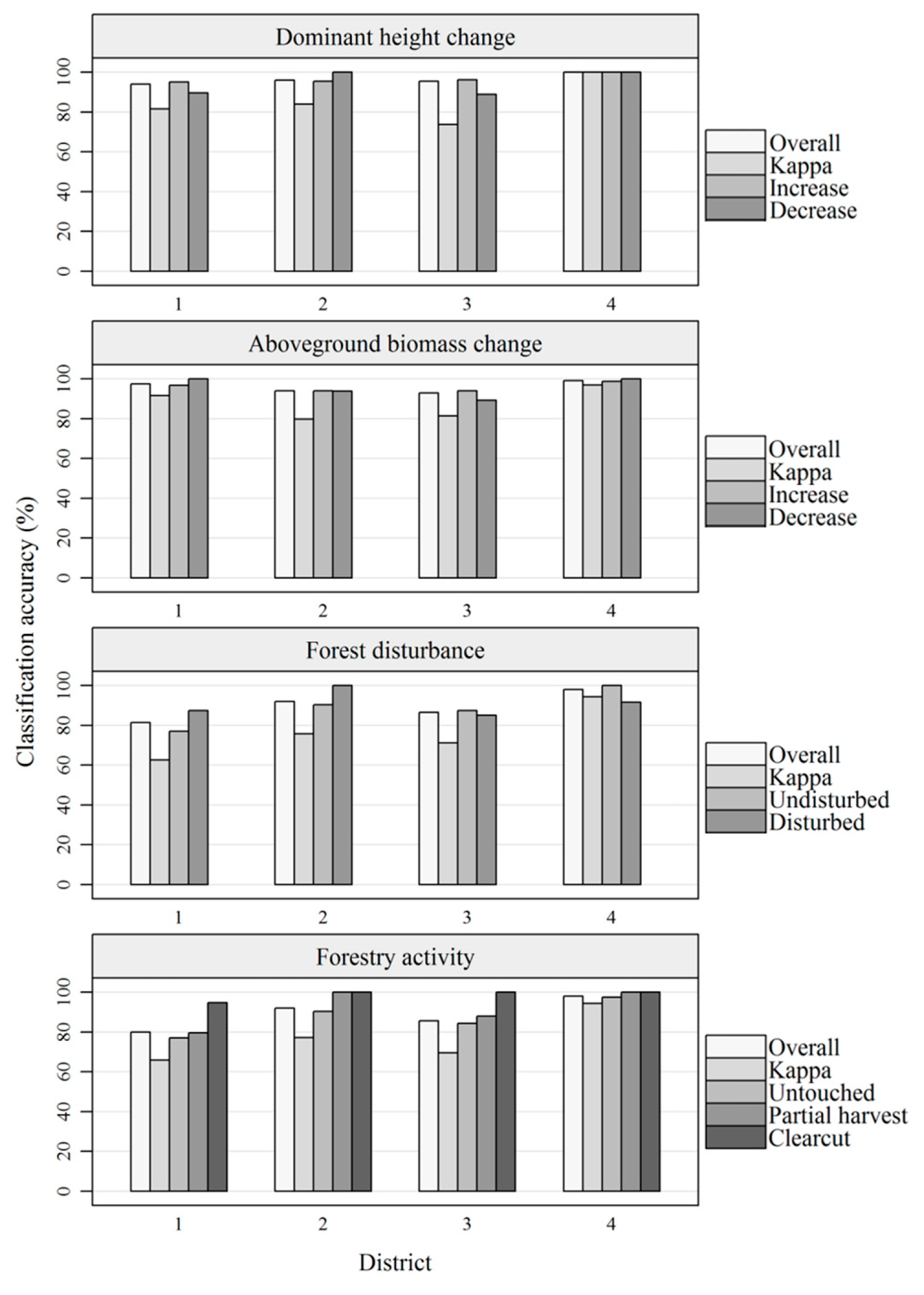
Overall accuracies obtained for Hdom and AGB change classifications were similar across the four districts, however, highest for district 4 (
Figure 3). For forest disturbance and forestry activity classifications, overall accuracies differed substantially across districts, also being highest for district 4. For the classification of forestry activity, the lowest accuracies were obtained for class A, i.e., untouched forest. Classifications of clearcut plots were 100% accurate in districts 2, 3, and 4; however, in district 1, one clearcut plot was misclassified as partially harvested.
Regarding the accuracies calculated from aggregated confusion matrices for the four districts, user’s accuracies tended to be similar across classes (
Table 5,
Table 6,
Table 7, and
Table 8). However, the forestry activity class “clearcut” stood out with particularly high accuracy. The misclassifications of forestry activity were mainly caused by confusion between “untouched” and “partial harvest” classes.
4. Discussion
Our results show that bitemporal data acquired as part of repeated ALS-based forest inventories are highly suitable for plot-level forest change classification. Forest planning systems in Norway, as well as many other countries, rely on information acquired in local forest inventories, and monitoring forest change at local levels is fundamental for sustainable forest management. The kNN method proved to be a practical and effective way of classifying the different changes in forest structure and yielded high accuracies. This is encouraging because the availability of bitemporal datasets will increase as local ALS-based forest inventories are repeated. The area-based approach is the most common method for predicting forest attributes from ALS data, and the methods proposed here can thus easily be applied in repeated ALS-based inventories.
Changes in ALS data proved to be good indicators of various types of forest change. This was expected because the ALS metrics that we computed characterize the height and density of the canopy at t1 and t2, and changes therein. Some sources of uncertainty must, however, be anticipated at the separate points in time, such as measurement errors, co-location errors between field and ALS data, and allometric errors. Moreover, additional sources of uncertainty arise when employing bitemporal field and ALS data for change detection, such as co-location errors between t1 and t2 plot center coordinates which may have influenced classifications negatively. Although state of the art positioning systems were used during both inventory cycles, the locations of plot centers differed in cases where the center mark was not found at t2. In those cases, mean distances between post-processed t1 and t2 center coordinates were minimal, i.e., 1.1, 0.5, 0.3, and 0.5 m for districts 1–4, respectively. Nevertheless, even small positional errors will likely result in trees being in- or excluded in the plot data from the respective inventory cycles, and will therefore have caused inconsistencies in the classification of field data into change classes. Furthermore, changes in boundary effects may have added to this uncertainty. Different portions of the canopy returns within plots will have belonged to trees of which the stem was located outside of the plot and vice versa, and such boundary effects will not have been constant for t1 and t2.
In spite of the abovementioned challenges, classifications of Hdom change yielded high overall accuracies, and even 100% accuracy for both Hdom change classes in district 4. Local differences in species compositions may partly explain the obtained accuracies being particularly high in district 4, as it is spruce-dominated and noticeably homogenous compared to other districts. Resultantly, the forest canopy structure can also be expected to be relatively homogeneous. Crown shapes of spruce and pine trees differ, which is known to influence the values of ALS height and density metrics [
64]. Tree crowns of spruce trees are narrower, longer, and more cone-shaped than those of pine and deciduous trees, which will generally skew ALS height and density metrics toward lower values [
51]. Therefore, stratification according to species and forest productivity is common practice in Norwegian forest inventories, and the two are strongly linked because spruce typically grows on high productivity sites and pine on poorer sites. Stratification can potentially improve the accuracy of ALS-based predictions [
65], and stratification by dominant tree species may have improved classification accuracies in other districts. However, we chose to pool all plots together to maintain large reference sets covering a broad and continuous range of forest change examples, and thus to limit the number of classifications for target units of which ALS metrics fall outside the range of the reference set.
We obtained high overall accuracies for classifications of AGB change. A kappa value of 0.87 across districts indicated an “almost perfect” agreement between observed and predicted classes according to Landis and Koch [
66]. This result was expected, as ALS is a proven tool for AGB estimation [
67,
68,
69,
70], and bitemporal ALS data can therefore be expected to be well suited for classification of AGB change. The classification for district 4 yielded the highest overall accuracy, likely due to the homogeneity of the species composition. Findings presented by Næsset and Gobakken [
17] also support this, as they found that tree species had a strong effect on relationships between AGB and ALS data. The classifier for district 1 performed nearly as well, with an overall accuracy of 97%, which may be explained by the relatively large portion of plots that had been harvested during the observation period (
Table 1), in which case changes in AGB are particularly distinct.
Using decreases in Hdom, AGB, and N as proxies for forest disturbances, our results demonstrated that such changes in forest structure can be detected reliably from bitemporal ALS data. The use of remotely sensed data for forest disturbance detection has been studied extensively, although most studies have focused on the use of spectral-temporal information derived from time series of satellite imagery. The overall accuracy of 89% across districts is in line with accuracies reported in many of those studies. Using the Landsat archive, high overall accuracies have been reported for stand-replacing forest disturbance classifications, for example 93% [
71], 88% [
72], 90% [
73], and 88% [
74]. However, studies that included non-stand replacing disturbances in the classification reported lower overall accuracies; 75% [
73] and 80% [
75], likely because subtle forest changes do not tend to display a clear spectral change that can be linked to a change in land cover class [
76,
77]. Thus far, however, no study has investigated the use of bitemporal ALS data for the classification of structural forest changes that indicate disturbance at plot-level, and our results demonstrate that also minor decreases in Hdom, ABG, and N can be detected reliably using such data.
It must be noted, however, that defining forest disturbance on the basis of forest inventory data is not trivial. Essentially, a forest disturbance can be any event that leads to a substantial reduction in structural forest attributes and can be caused by a range of anthropogenic or naturogenic factors. Different types and intensities of disturbances can occur, and particularly minor disturbances may be challenging to detect from bitemporal ALS data with time intervals >10 years. For example, selective harvest, disease, or insect damage may have disturbed even those plots for which field-based criteria indicated they were undisturbed. A shorter observation period may ensure that such minor disturbances are detected; Yu et al. [
47] showed that single harvested trees can be detected reliably from bitemporal ALS data with a temporal resolution of two years. In this study, however, we used bitemporal data with intervals of 11–15 years, which are common temporal resolutions in repeated ALS-based forest management inventories, meaning that minor disturbances may not always be captured.
We obtained high overall accuracies for the classification of forestry activities, which revealed that disturbed plots can reliably be further classified into “partial harvest” and “clearcut”. Clearcut plots were easily identified, which can be expected because a substantial loss of AGB should be easy to detect from changes in ALS metrics that reflect canopy height and density. Overall accuracies ranged from 80% to 98% across districts, with a mean of 88%. These results are similar to findings reported by Næsset et al. [
34], who obtained an overall accuracy of 94% for classification of the same activity classes from bitemporal ALS data. In the mentioned study, identical field-based criteria were used to define the activity classes, a temporal resolution similar to those used in this study was used; 11 years, however, the study area was substantially smaller. Comparable to their results, discriminating between untouched and partially harvested plots proved difficult in comparison to discriminating between partially harvested and clearcut plots. This may be expected as certain subtle changes in Hdom, AGB, and especially N may not be detectable from bitemporal ALS data at temporal resolutions >10 years. ALS data are poorly suited to characterize N in comparison to other forest attributes commonly estimated in forest inventories [
53], and the detection of changes in N can therefore be expected to be more challenging than changes in Hdom and AGB.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}