Crop Classification Based on a Novel Feature Filtering and Enhancement Method



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Study Site and Data
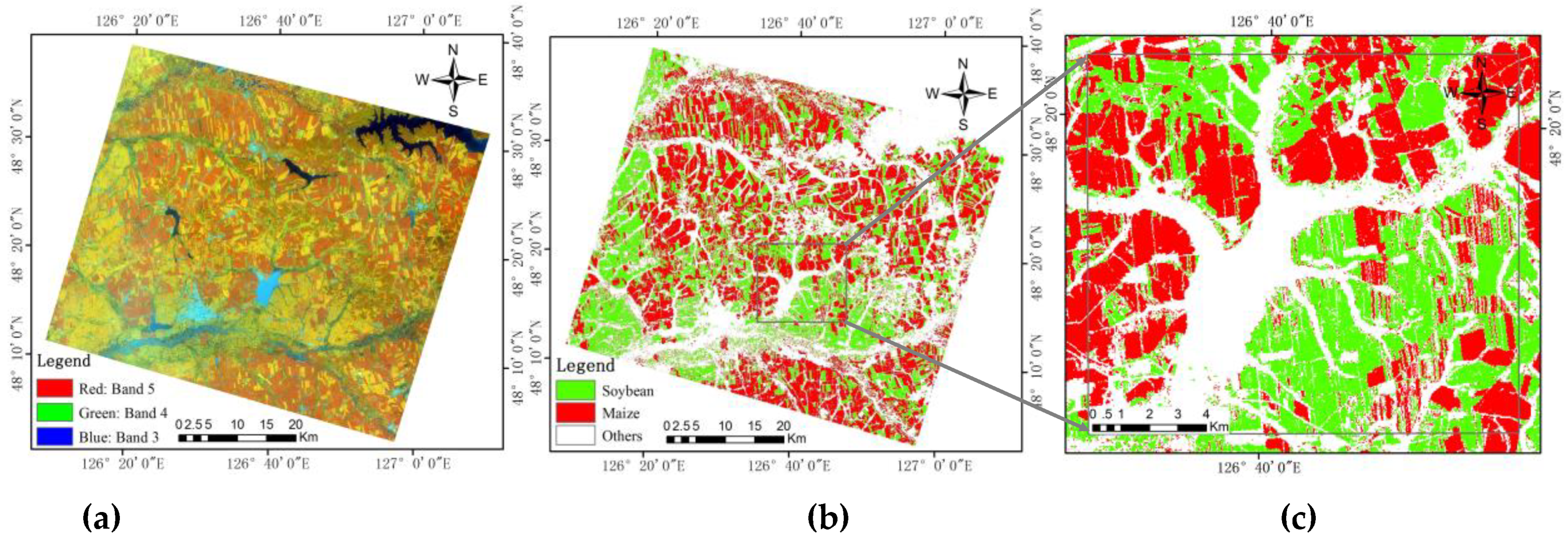
2.1. Study Site
2.2. Phenology of Maize and Soybean
2.3. Remote sensing Data
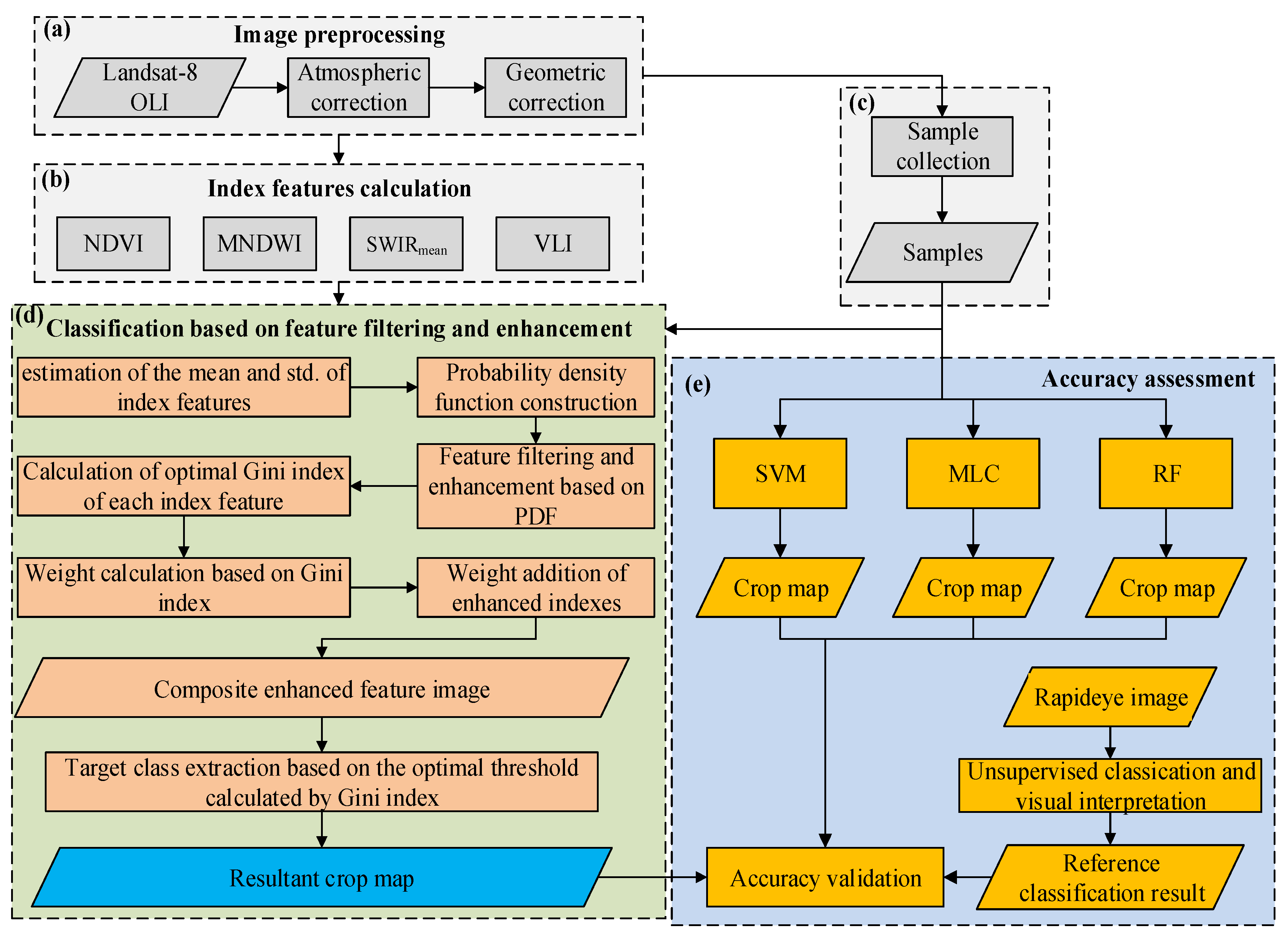
3. Methods
3.1. Image pre-Processing and Index Computing
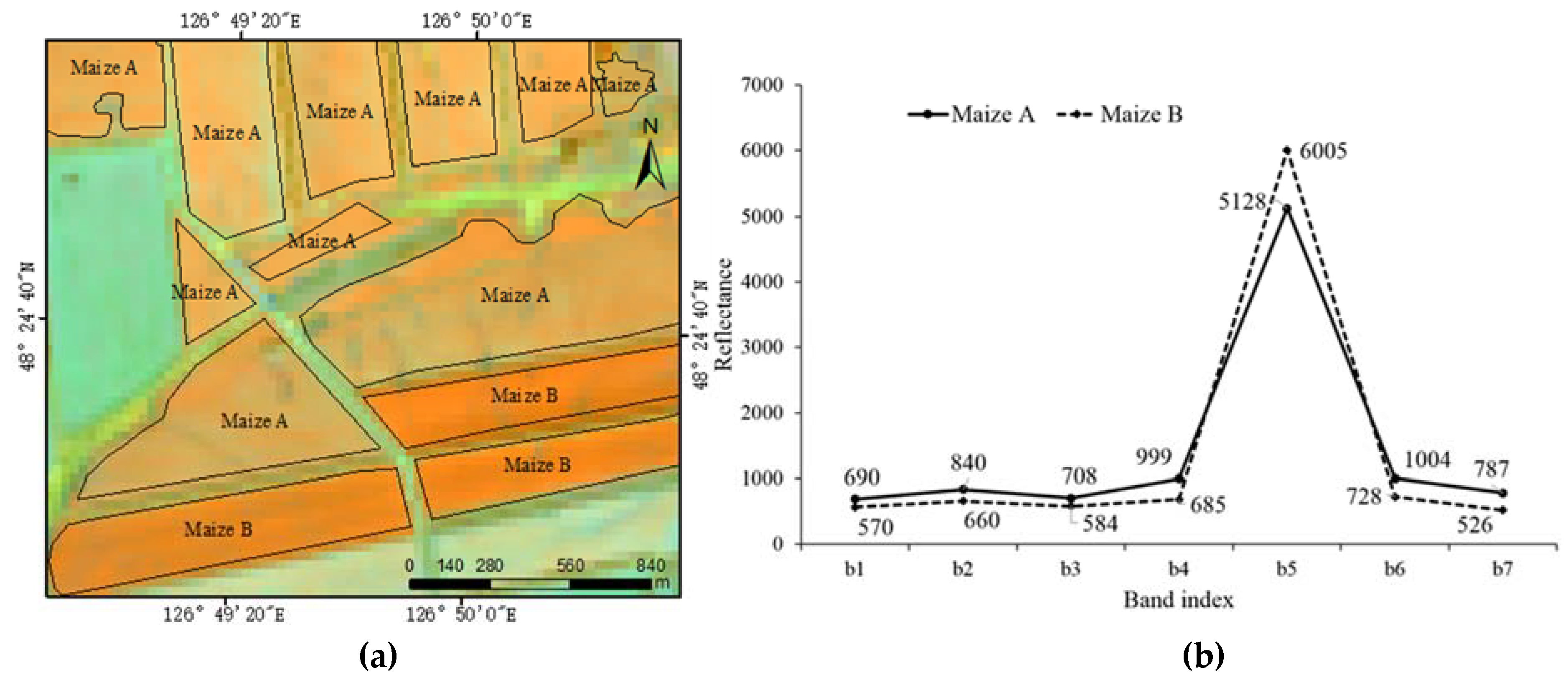
3.2. Sampling
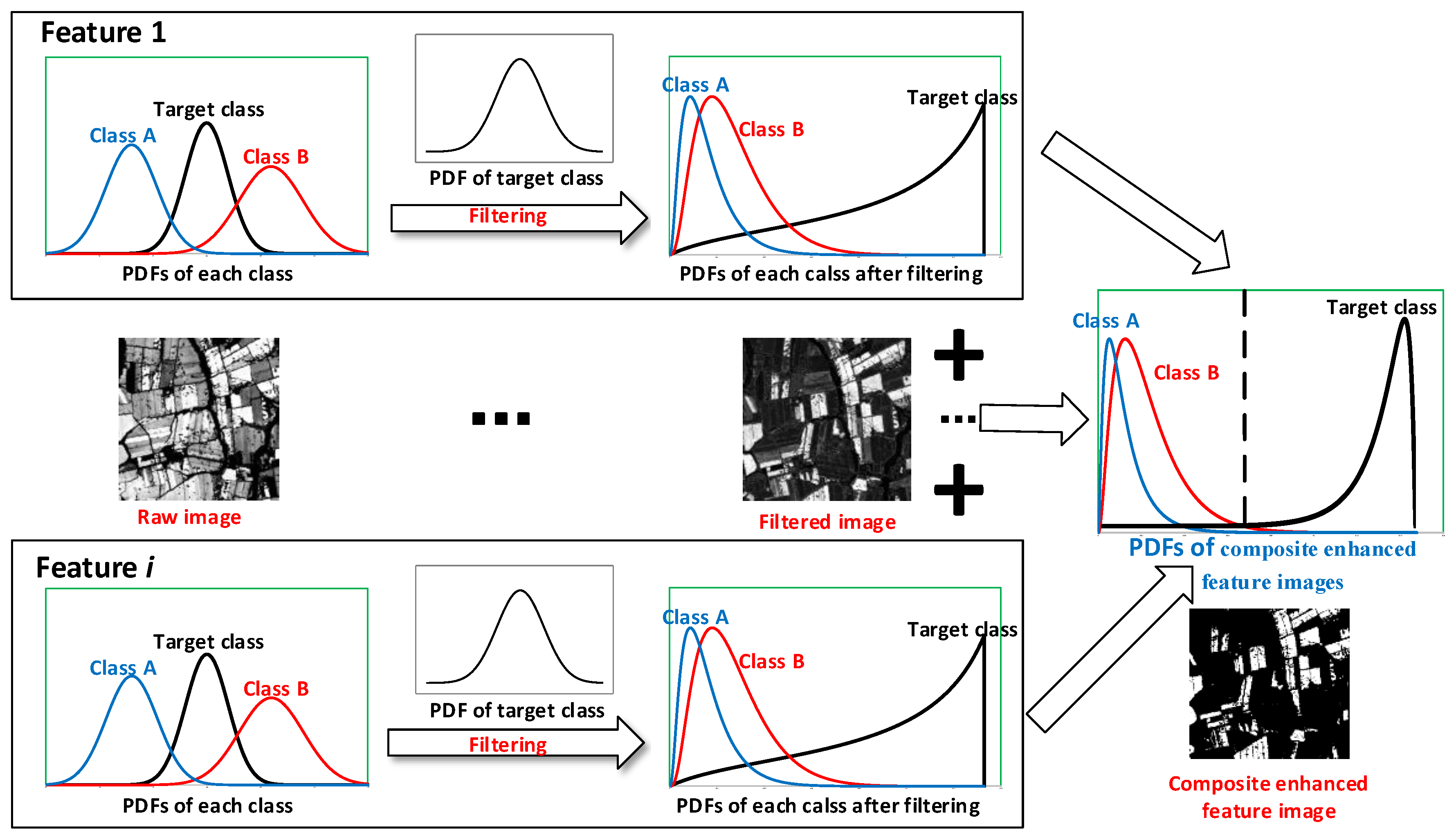
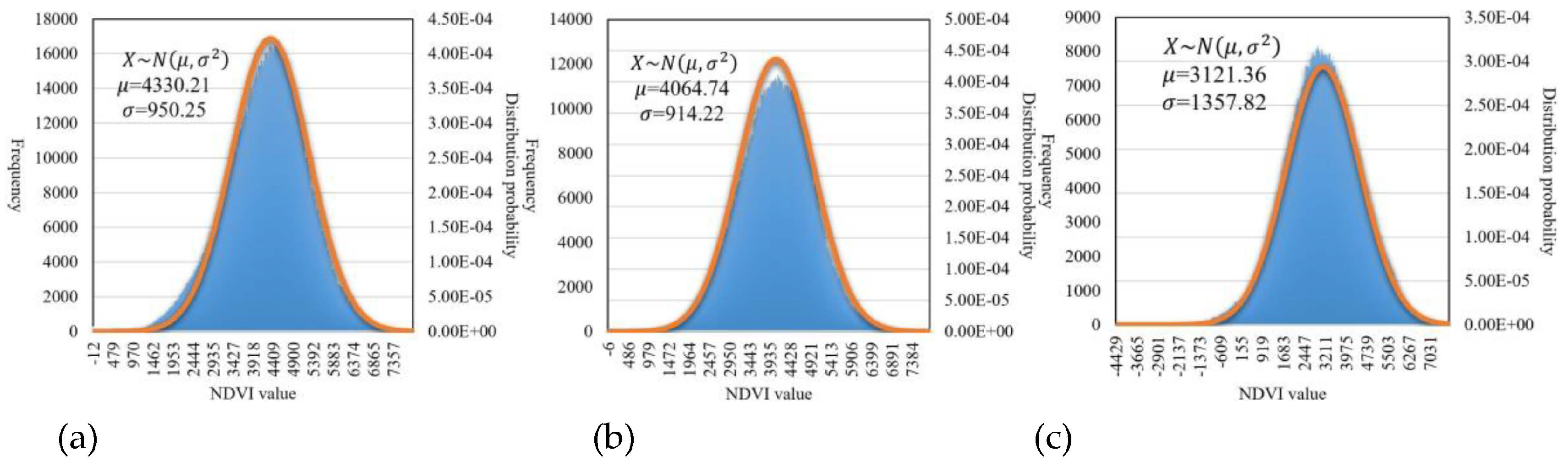
3.3. Feature Filtering and Enhancement Based on Probability Density Function
3.4. Weighted Addition of Index Features and Crop Classification
3.5. Accuracy Assessment
4. Results and Discussion
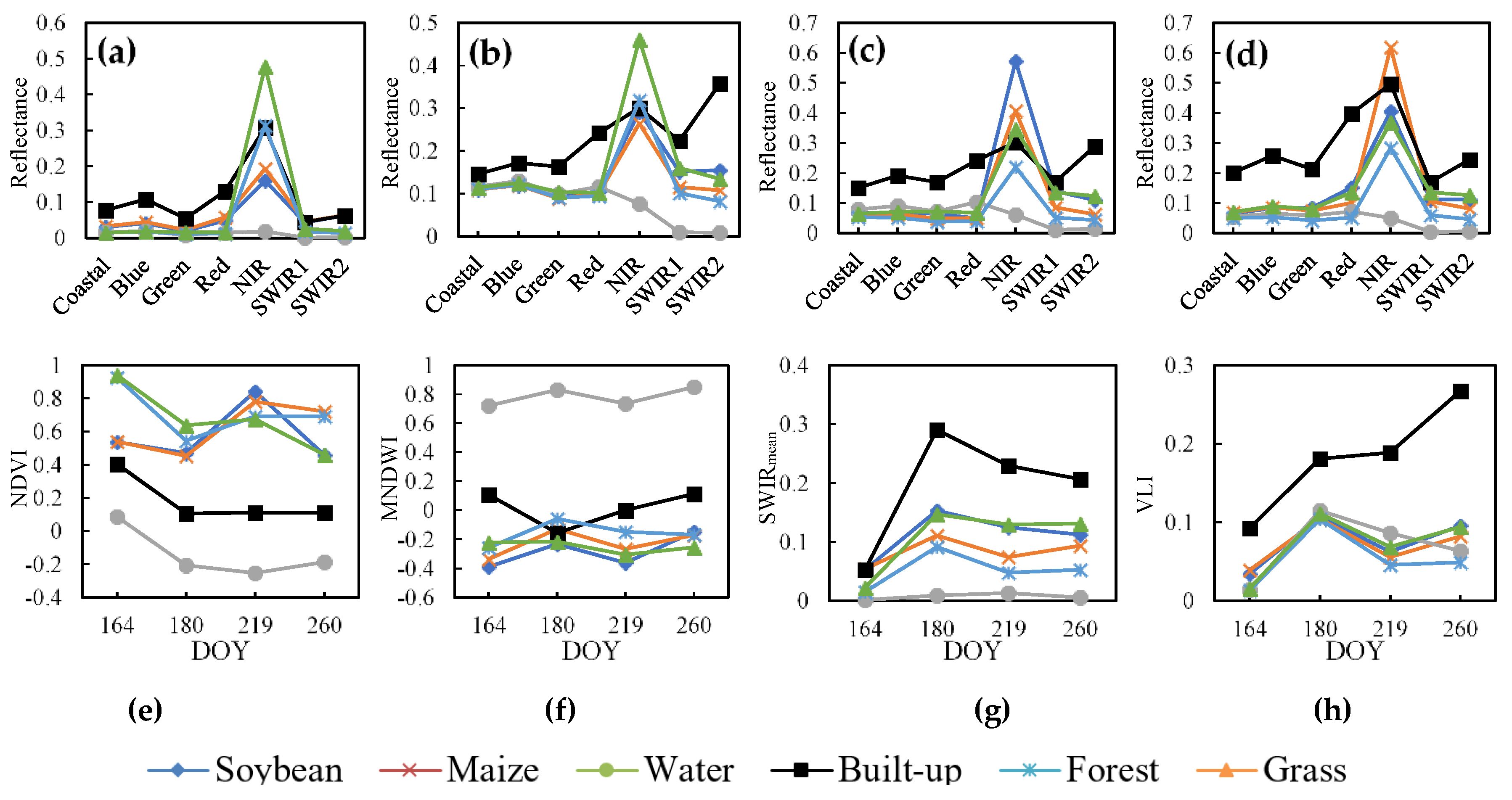
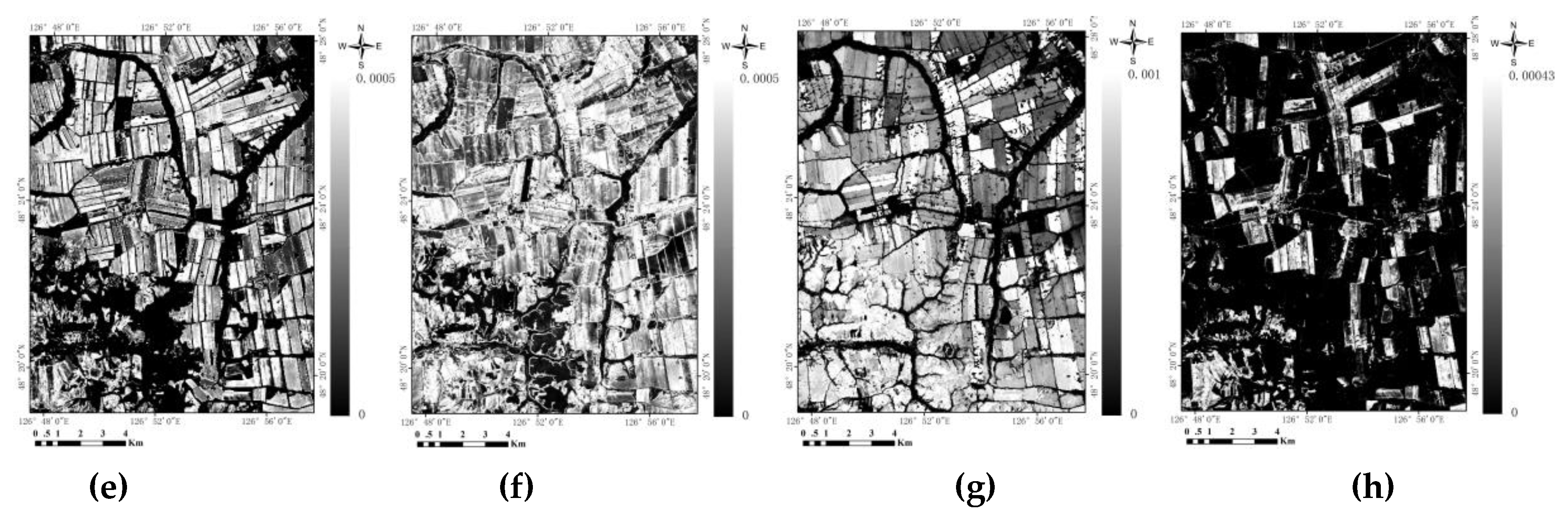
4.1. Vegetation Index Calculation
4.2. Distribution and probability Density Function (PDF) for three target classes
4.3. FFE-Based Classification
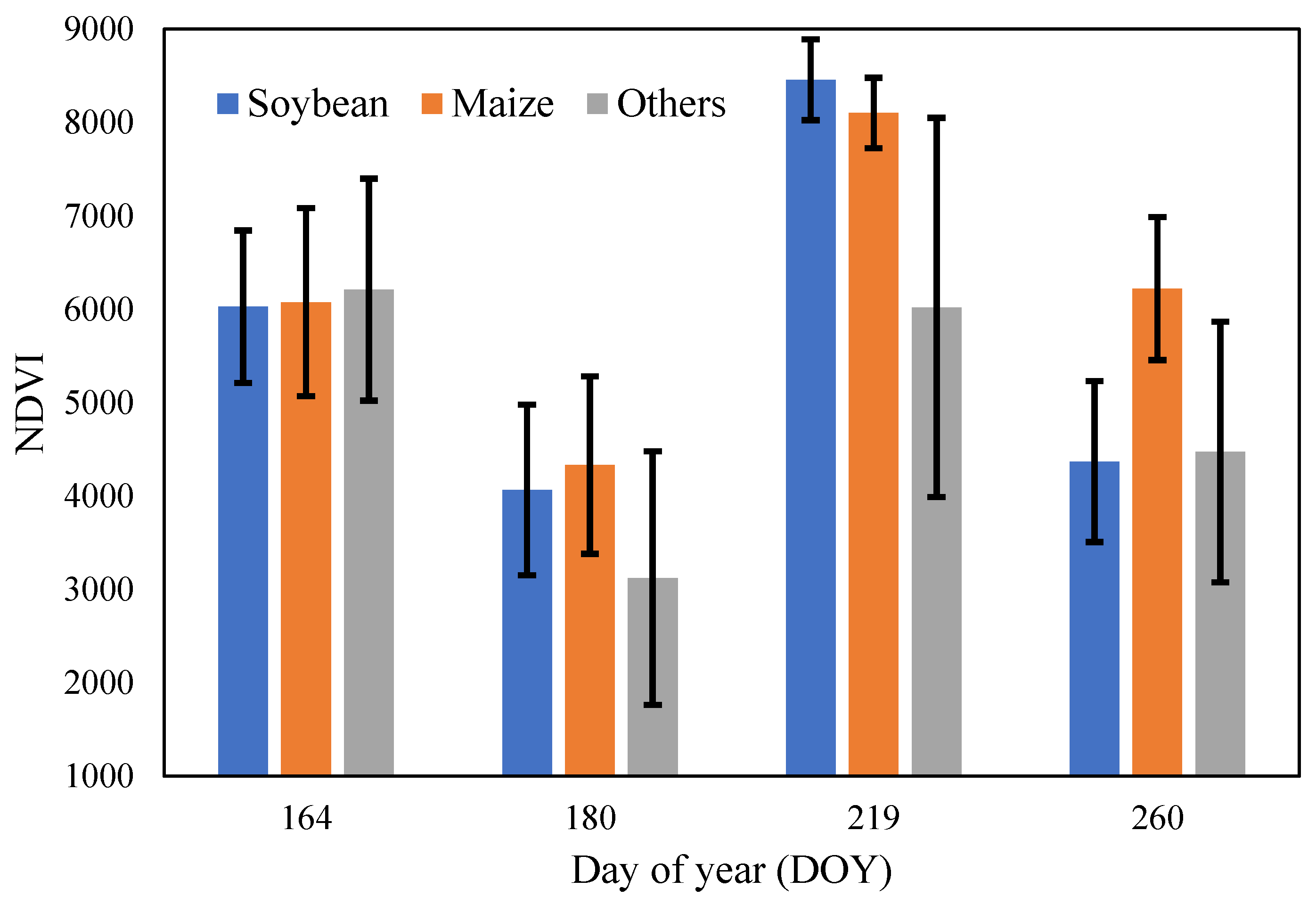
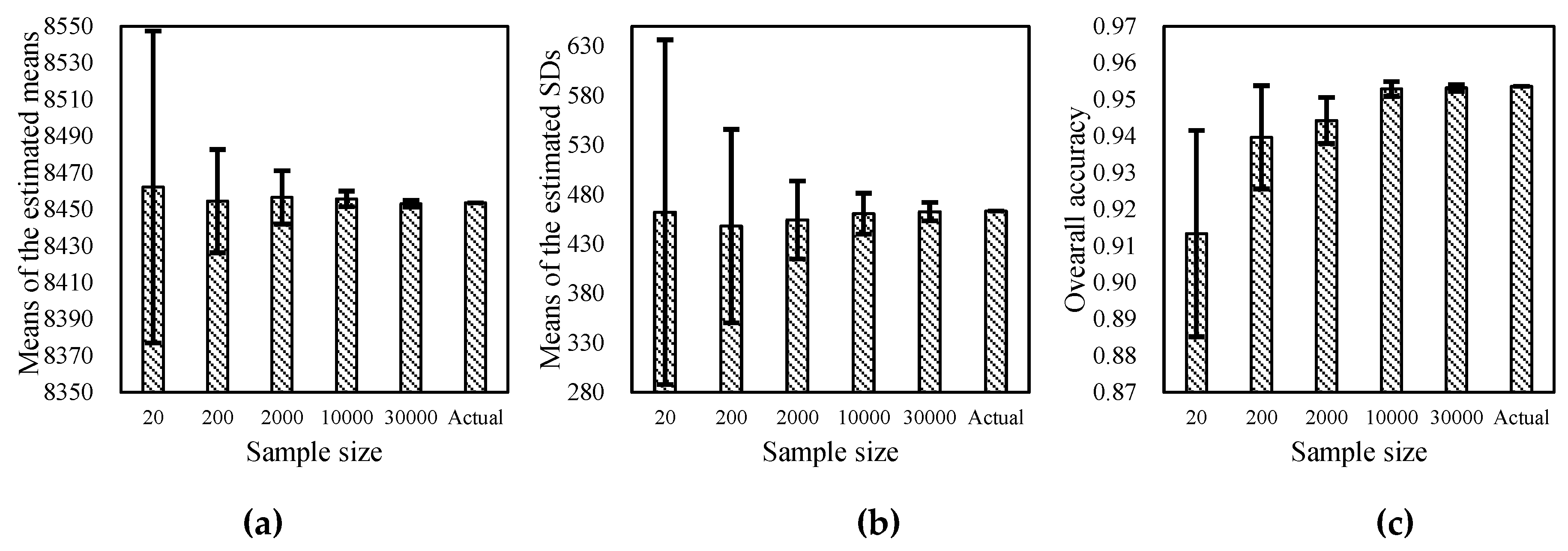
4.4. The Impact of Sample Size on Probability Density Function
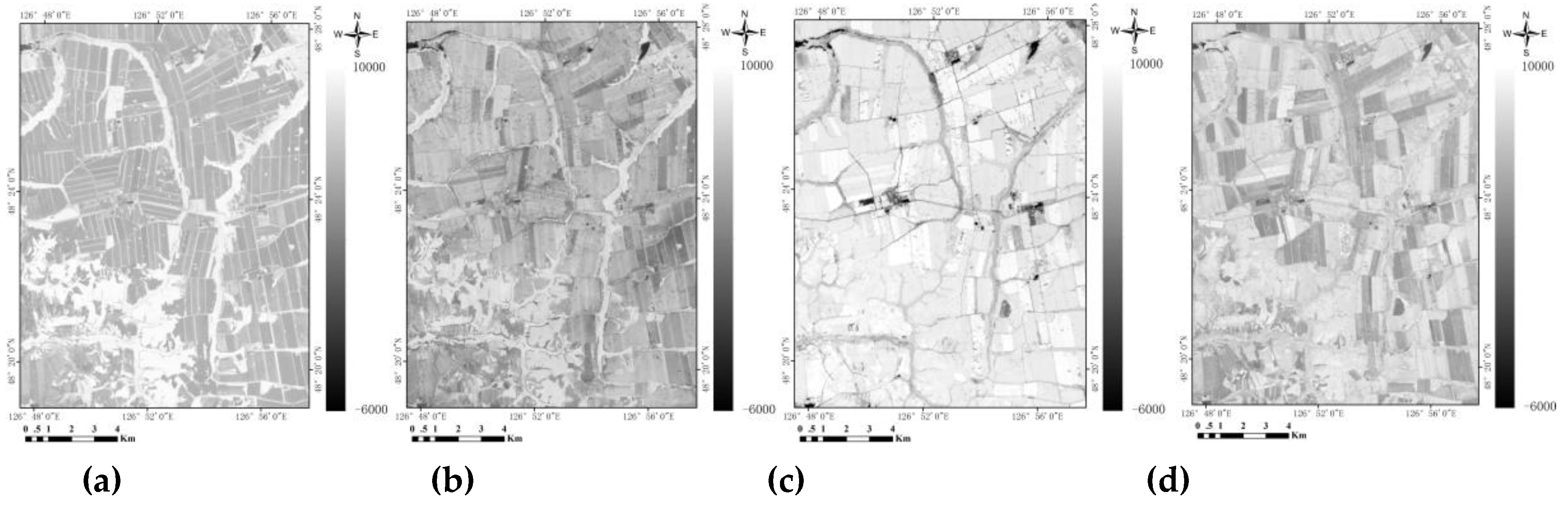
4.5. Calculate PDF Based on the Bookup Table (LUT) Method Instead of Normal Distribution Function
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Boryan, C.G.; Yang, Z. A new land cover classification based stratification method for area sampling frame construction. In Proceedings of the International Conference on Agro-Geoinformatics, Shanghai, China, 2–4 August 2012; pp. 639–644. [Google Scholar]
- Gallego, J.; Bamps, C. Using CORINE land cover and the point survey LUCAS for area estimation. Int. J. Appl. Earth Obs. 2008, 10, 467–475. [Google Scholar] [CrossRef]
- Shen, K.; He, H.; Meng, H.; Guannan, S. Review on Spatial Sampling Survey in Crop Area Estimation. Chin. J. Agric. Resour. Reg. Plan. 2012, 33, 11–16. [Google Scholar]
- Tatsumi, K.; Yamashiki, Y.; Morales Morante, A.K.; Ramos Fernandez, L.; Apaclla Nalvarte, R. Pixel-based crop classification in Peru from Landsat 7 ETM+ images using a Random Forest model. J. Agric. Meteorol. 2016, 72, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Pan, J.; Zhang, P.; Wei, S.; Han, T. Mapping Winter Wheat with Multi-Temporal SAR and Optical Images in an Urban Agricultural Region. Sensors 2017, 17, 1210. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Kou, W.; Qin, Y.; Zhang, G.; Li, L.; Jin, C.; Zhou, Y.; Wang, J.; Biradar, C. Tracking the dynamics of paddy rice planting area in 1986–2010 through time series Landsat images and phenology-based algorithms. Remote Sens. Environ. 2015, 160, 99–113. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lemoine, G.; Gallego, F.J.; Skakun, S.V. Parcel-Based Crop Classification in Ukraine Using Landsat-8 Data and Sentinel-1A Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 9, 2500–2508. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Wu, M.; Zhang, X.; Huang, W.; Niu, Z.; Wang, C.; Li, W.; Hao, P. Reconstruction of daily 30 m data from HJ CCD, GF-1 WFV, Landsat, and MODIS data for crop monitoring. Remote Sens. 2015, 7, 16293–16314. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Siachalou, S.; Mallinis, G.; Tsakiri-Strati, M. A hidden Markov models approach for crop classification: Linking crop phenology to time series of multi-sensor remote sensing data. Remote Sens. 2015, 7, 3633–3650. [Google Scholar] [CrossRef]
- Gaertner, J.; Genovese, V.B.; Potter, C.; Sewake, K.; Manoukis, N.C. Vegetation classification of Coffea on Hawaii Island using WorldView-2 satellite imagery. J. Appl. Remote Sens. 2017, 11, 046005. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar Sentinel-1 and optical Sentinel-2 imagery for crop mapping: A case study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef]
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of Different Machine Learning Algorithms for Scalable Classification of Tree Types and Tree Species Based on Sentinel-2 Data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef]
- Li, Q.; Wang, C.; Zhang, B.; Lu, L. Object-based crop classification with Landsat-MODIS enhanced time-series data. Remote Sens. 2015, 7, 16091–16107. [Google Scholar] [CrossRef]
- Chi, M.; Rui, F.; Bruzzone, L. Classification of hyperspectral remote-sensing data with primal SVM for small-sized training dataset problem. Adv. Space Res. 2008, 41, 1793–1799. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (Tist) 2011, 2, 27. [Google Scholar] [CrossRef]
- Tan, C.P.; Hong, T.E.; Chuah, H.T. Agricultural crop-type classification of multi-polarization SAR images using a hybrid entropy decomposition and support vector machine technique. Int. J. Remote Sens. 2011, 32, 7057–7071. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Ok, A.O.; Akar, O.; Gungor, O. Evaluation of random forest method for agricultural crop classification. Eur. J. Remote Sens. 2012, 45, 421–432. [Google Scholar] [CrossRef]
- Lebourgeois, V.; Dupuy, S.; Vintrou, É.; Ameline, M.; Butler, S.; Bégué, A. A Combined Random Forest and OBIA Classification Scheme for Mapping Smallholder Agriculture at Different Nomenclature Levels Using Multisource Data (Simulated Sentinel-2 Time Series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef]
- Holloway, J.; Mengersen, K. Statistical Machine Learning Methods and Remote Sensing for Sustainable Development Goals: A Review. Remote Sens. 2018, 10, 1365. [Google Scholar] [CrossRef]
- Tang, K.; Zhu, W.; Zhan, P.; Ding, S. An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sens. 2018, 10, 193. [Google Scholar] [CrossRef]
- Nagaraja, A.; Sahoo, R.N.; Usha, K.; Gupta, V.K. Estimation of mango growing areas using remote sensing. Indian J. Hortic. 2017, 74, 184–188. [Google Scholar] [CrossRef]
- Ouyang, L.; Mao, D.; Wang, Z.; Li, H.; Man, W.; Jia, M.; Liu, M.; Zhang, M.; Liu, H. Analysis crops planting structure and yield based on GF-1 and Landsat8 OLI images. Trans. Chin. Soc. Agric. Eng. 2017, 33, 147–156. [Google Scholar]
- Wang, L.; Chen, X.; Qi, L.; Wu, D.; Zhang, T. Phenology Extraction of Winter Wheat Based on Different time Series Vegetation Index Reconstructing Methods in Jiangsu Province. Sci. Technol. Eng. 2017, 17, 192–199. [Google Scholar]
- Wardlow, B.D.; Egbert, S.L. A comparison of MODIS 250-m EVI and NDVI data for crop mapping: A case study for southwest Kansas. Int. J. Remote Sens. 2010, 31, 805–830. [Google Scholar] [CrossRef]
- Mansaray, L.; Huang, W.; Zhang, D.; Huang, J.; Li, J. Mapping Rice Fields in Urban Shanghai, Southeast China, Using Sentinel-1A and Landsat 8 Datasets. Remote Sens. 2017, 9, 257. [Google Scholar] [CrossRef]
- Li, J.; Xi, B.; Li, Y.; Du, Q.; Wang, K. Hyperspectral Classification Based on Texture Feature Enhancement and Deep Belief Networks. Remote Sens. 2018, 10, 396. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, J.; Zhao, Z.; Li, H.; Zhang, Y. Block-regression based fusion of optical and SAR imagery for feature enhancement. Int. J. Remote Sens. 2010, 31, 2325–2345. [Google Scholar] [CrossRef]
- Heihe Statistical Bureau Heihe Social and Economic Statistics Yearbook; China Statistical Publishing House: Beijing, China, 2014.
- Harris Geospatial Solutions The Environment for Visualizing Images (ENVI), 5.3; Interlocken Crescent: Broomfield, CO, USA, 2015.
- Rouse, J.W.J.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with Erts. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.; Stone, C.J. Classification and Regression Trees. Encycl. Ecol. 1984, 57, 582–588. [Google Scholar]
- Decision Tree Flavors: Gini Index and Information Gain. Available online: http://www.learnbymarketing.com/481/decision-tree-flavors-gini-info-gain/ (accessed on 27 February 2016).
- Vanderzee, D.; Ehrlich, D. Sensitivity of ISODATA to changes in sampling procedures and processing parameters when applied to AVHRR time-series NDV1 data. Int. J. Remote Sens. 1995, 16, 673–686. [Google Scholar] [CrossRef]
- Zhu, C.; Lu, D.; Victoria, D.; Dutra, L. Mapping Fractional Cropland Distribution in Mato Grosso, Brazil Using Time Series MODIS Enhanced Vegetation Index and Landsat Thematic Mapper Data. Remote Sens. 2015, 8, 22. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classification of remotely sensed data. Remote Sens. Environ. 1991, 37, 270–279. [Google Scholar] [CrossRef]
- HAY, A.M. The derivation of global estimates from a confusion matrix. Int. J. Remote Sens. 1988, 9, 1395–1398. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Gašparović, M.; Jogun, T. The effect of fusing Sentinel-2 bands on land-cover classification. Int. J. Remote Sens. 2018, 39, 822–841. [Google Scholar] [CrossRef]
- Raju, P.V. Classification of wheat crop with multi-temporal images: Performance of maximum likelihood and artificial neural networks. Int. J. Remote Sens. 2003, 24, 4871–4890. [Google Scholar]
- Strahler, A.H. The use of prior probabilities in maximum likelihood classification of remotely sensed data. Remote Sens. Environ. 1980, 10, 135–163. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by AIRSAR data using support vector machine and index of entropy models in Cameron Highlands, Malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Wang, L.; Jia, L.; Yang, L.; Yang, F.; Fu, C. Impact of short infrared wave band on identification accuracy of corn and soybean area. Trans. Chin. Soc. Agric. Eng. 2016, 32, 169–178. [Google Scholar]
















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Dong, Q.; Yang, L.; Gao, J.; Liu, J. Crop Classification Based on a Novel Feature Filtering and Enhancement Method. Remote Sens. 2019, 11, 455. https://doi.org/10.3390/rs11040455
Wang L, Dong Q, Yang L, Gao J, Liu J. Crop Classification Based on a Novel Feature Filtering and Enhancement Method. Remote Sensing. 2019; 11(4):455. https://doi.org/10.3390/rs11040455
Chicago/Turabian StyleWang, Limin, Qinghan Dong, Lingbo Yang, Jianmeng Gao, and Jia Liu. 2019. "Crop Classification Based on a Novel Feature Filtering and Enhancement Method" Remote Sensing 11, no. 4: 455. https://doi.org/10.3390/rs11040455
APA StyleWang, L., Dong, Q., Yang, L., Gao, J., & Liu, J. (2019). Crop Classification Based on a Novel Feature Filtering and Enhancement Method. Remote Sensing, 11(4), 455. https://doi.org/10.3390/rs11040455