Improving Wi-Fi Fingerprint Positioning with a Pose Recognition-Assisted SVM Algorithm



Abstract
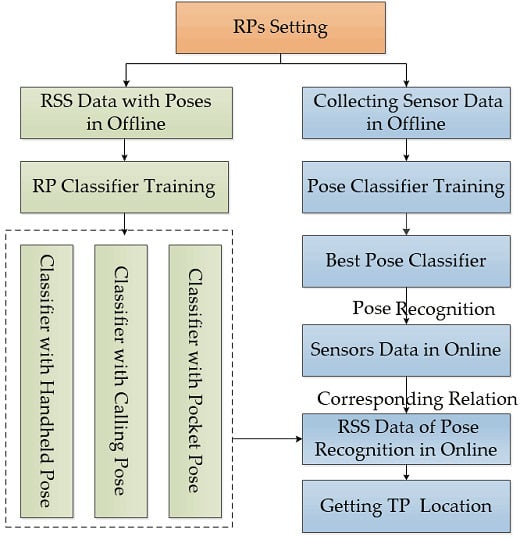
:
1. Introduction
2. Materials and Methods
2.1. Impact of Poses on Fingerprint Positioning
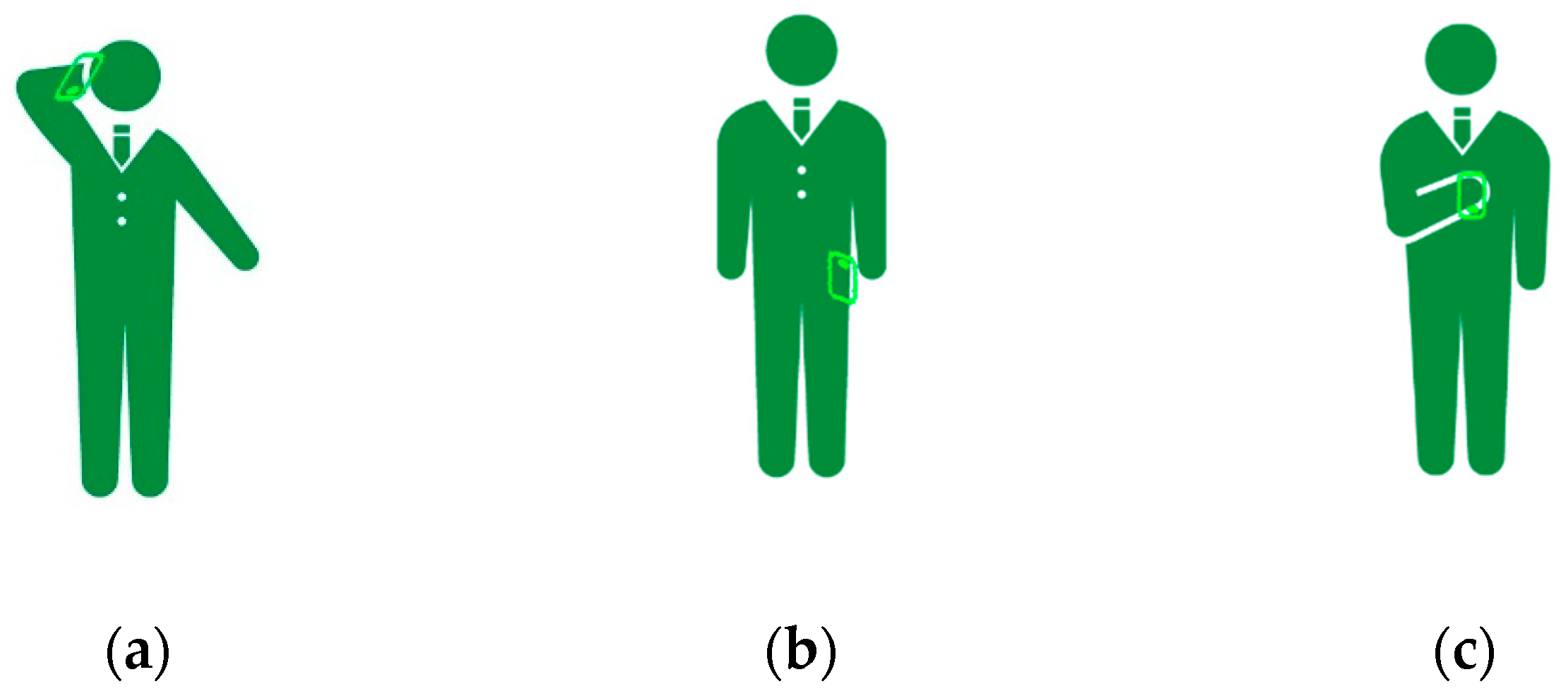
2.1.1. Definition of User Poses
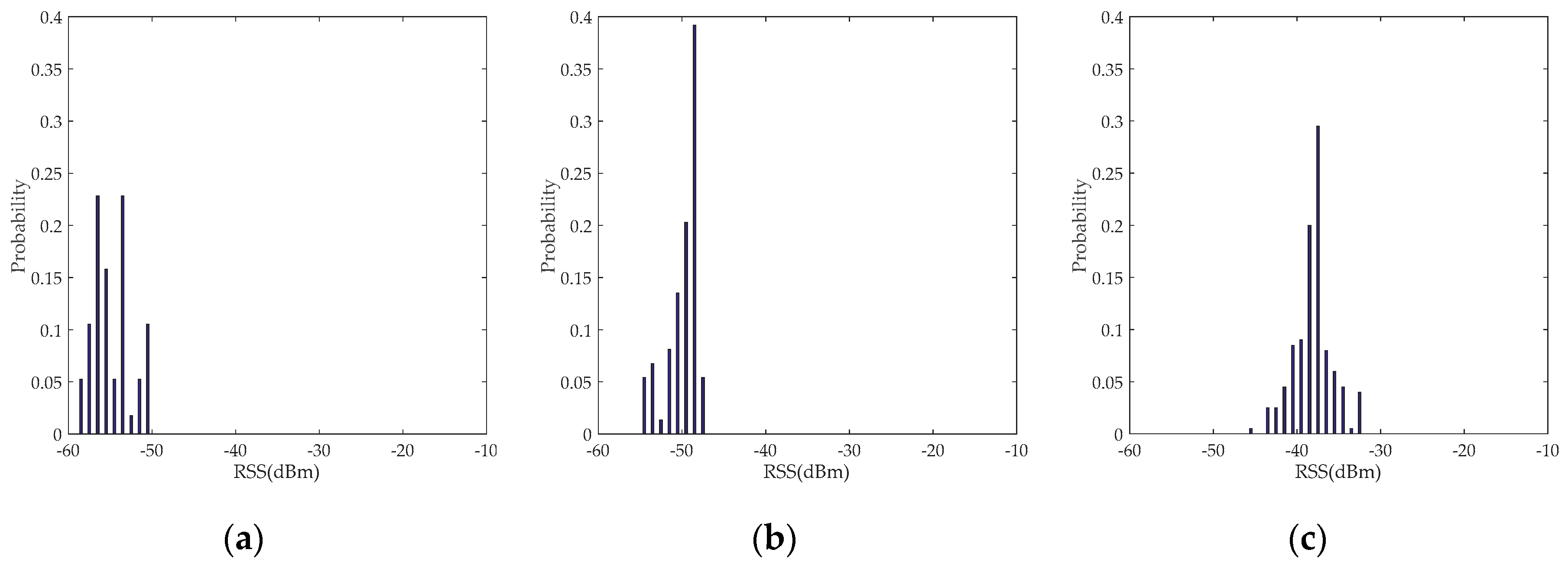
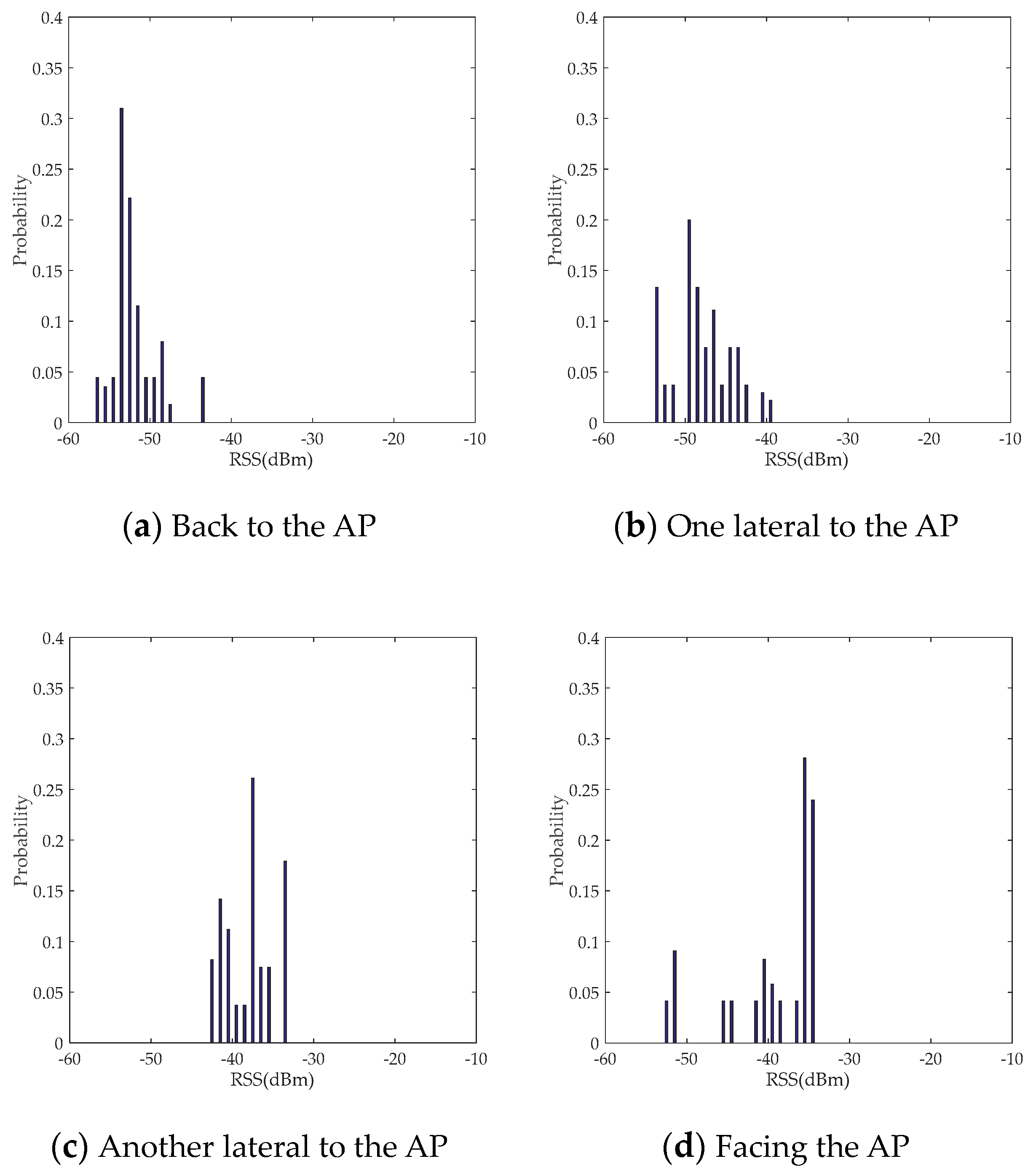
2.1.2. Influence of Different Poses on RSS Data
2.1.3. Influence of Body Shadowing on RSS Data
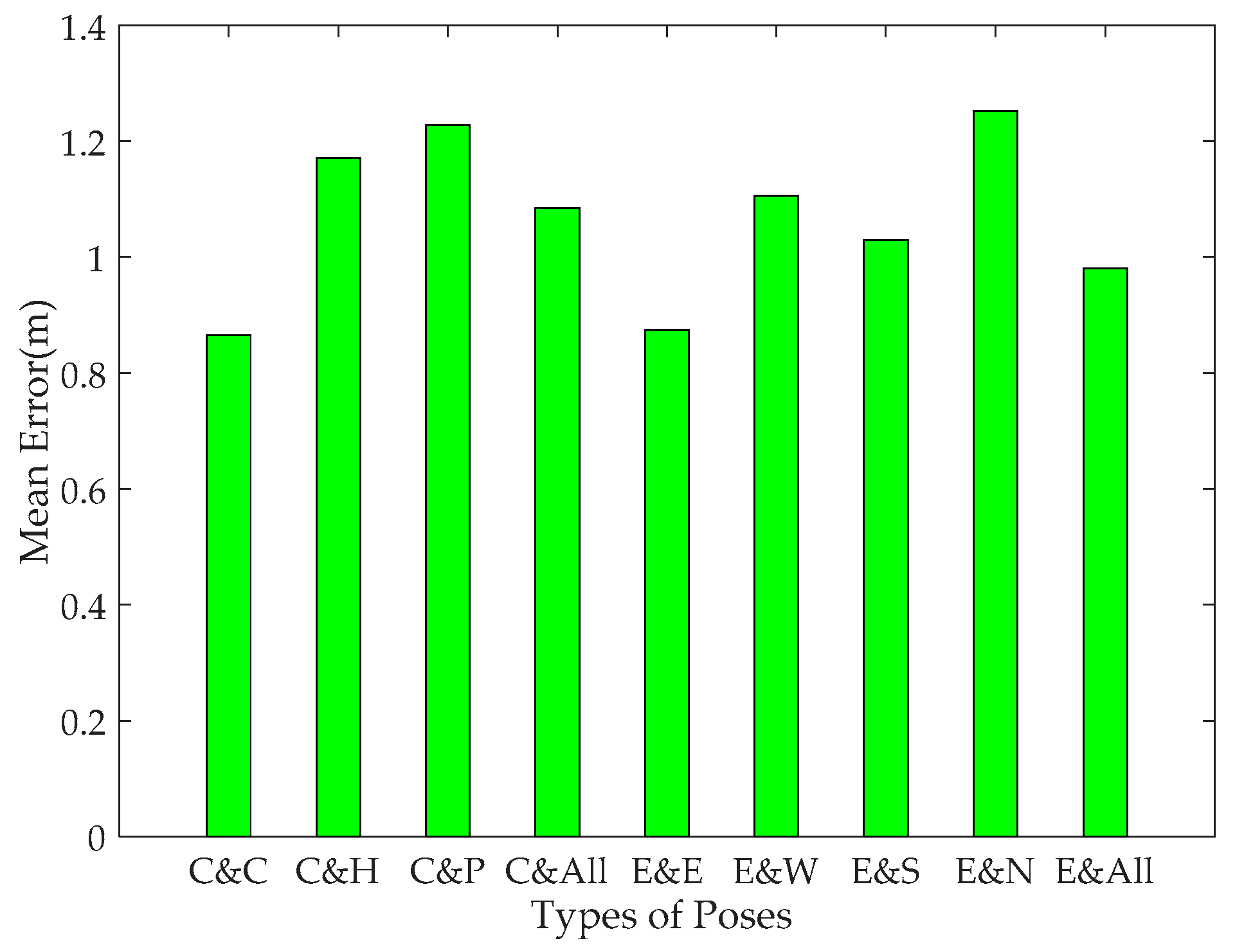
2.1.4. Comparison of Positioning Error with Different Cardinal Orientations and Poses
2.2. PRASVM Algorithm for Fingerprint Positioning
2.2.1. Principle of PRASVM Algorithm
2.2.2. Pose Recognition with the SVM Algorithm
2.2.3. Positioning Algorithm with Pose Information
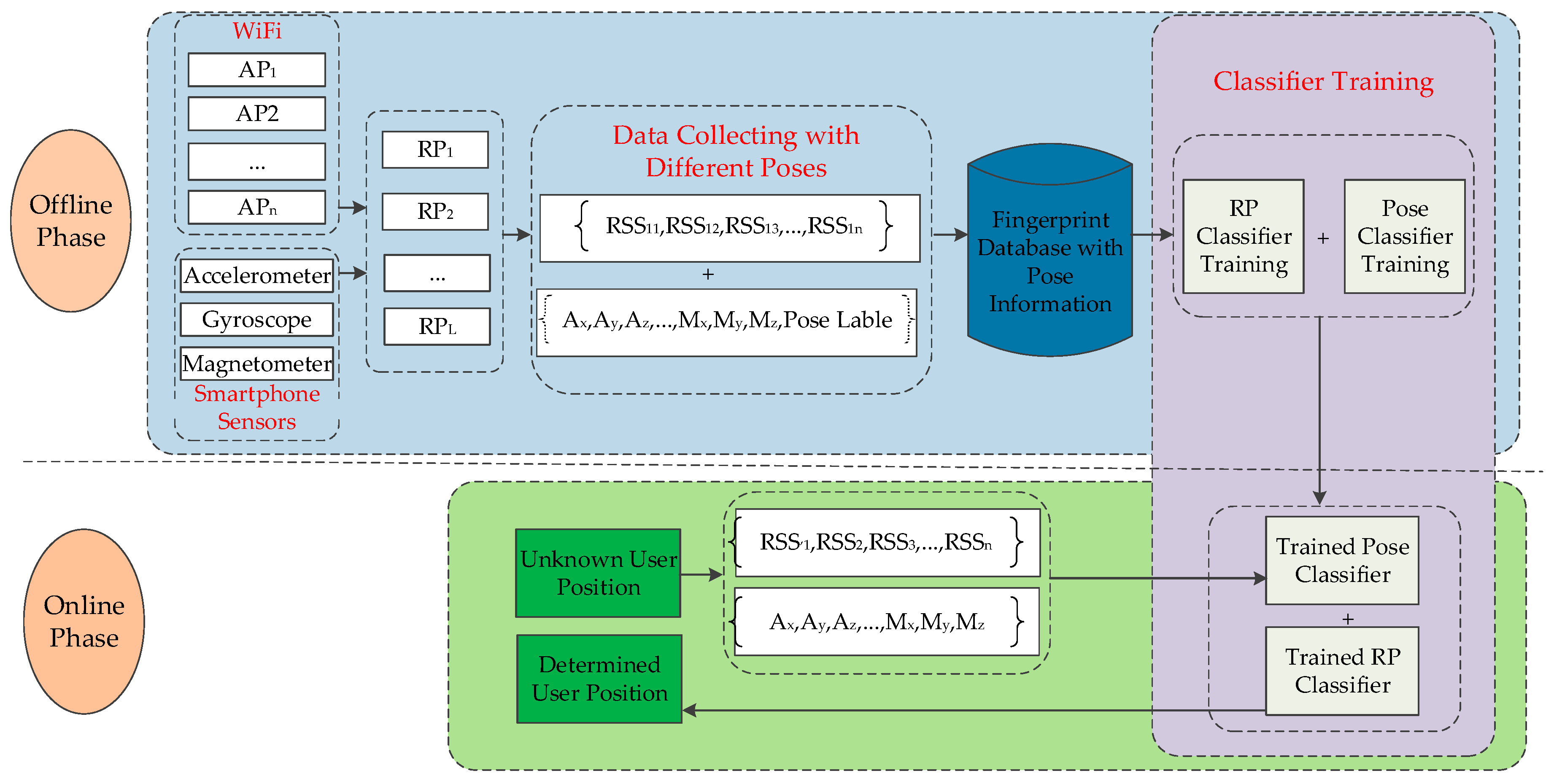
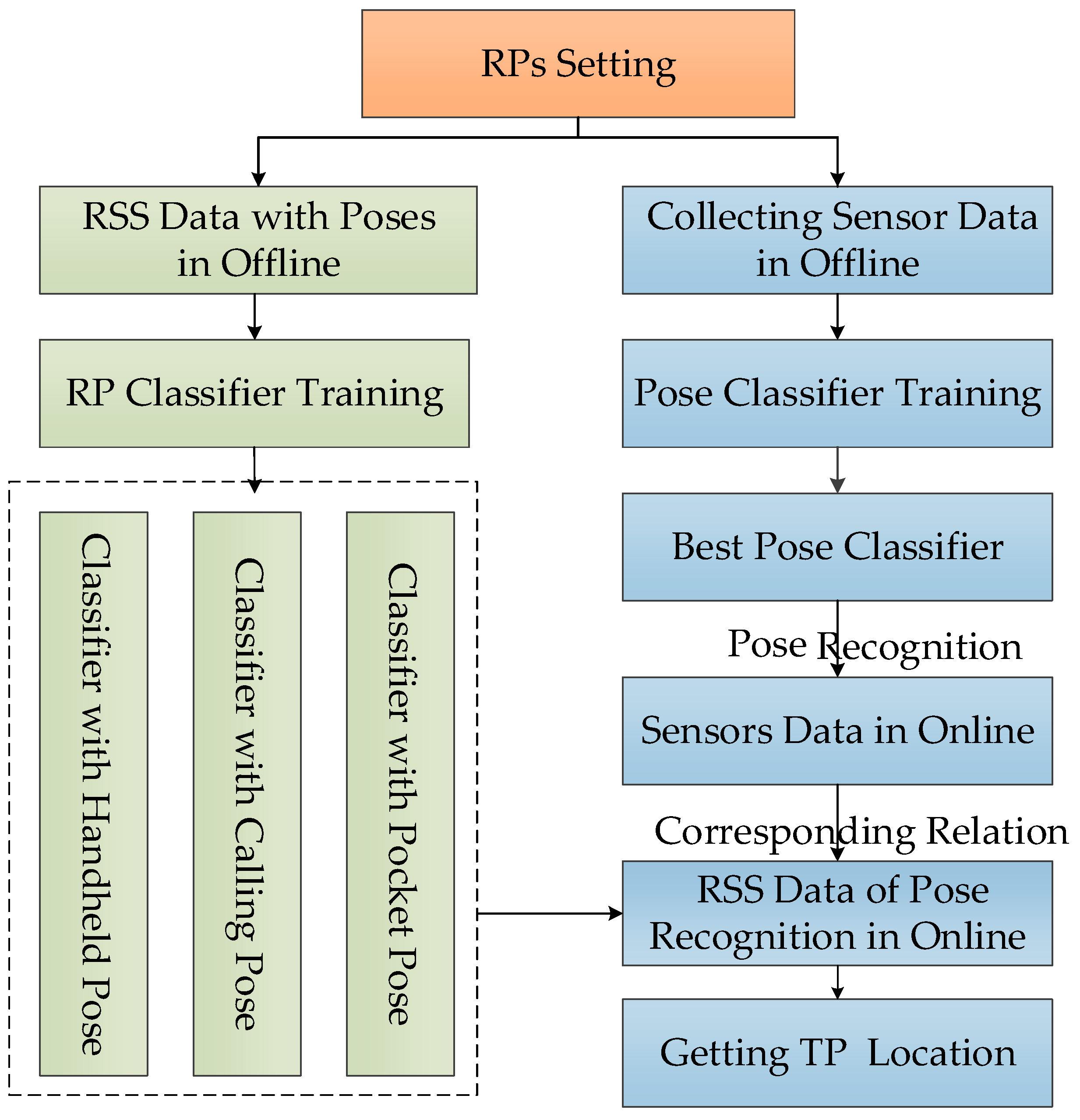
2.2.4. Implementation of the PRASVM Algorithm
3. Results
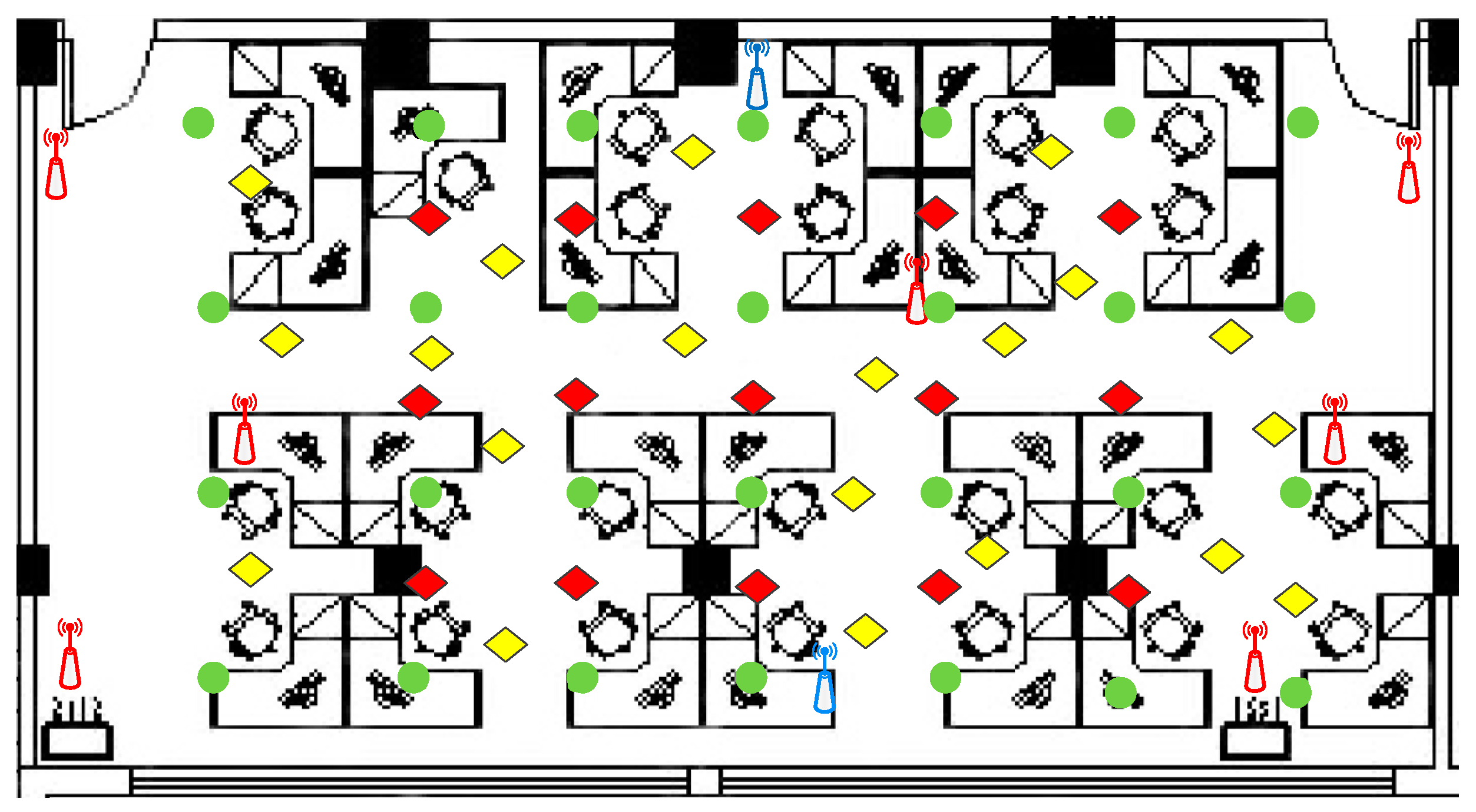
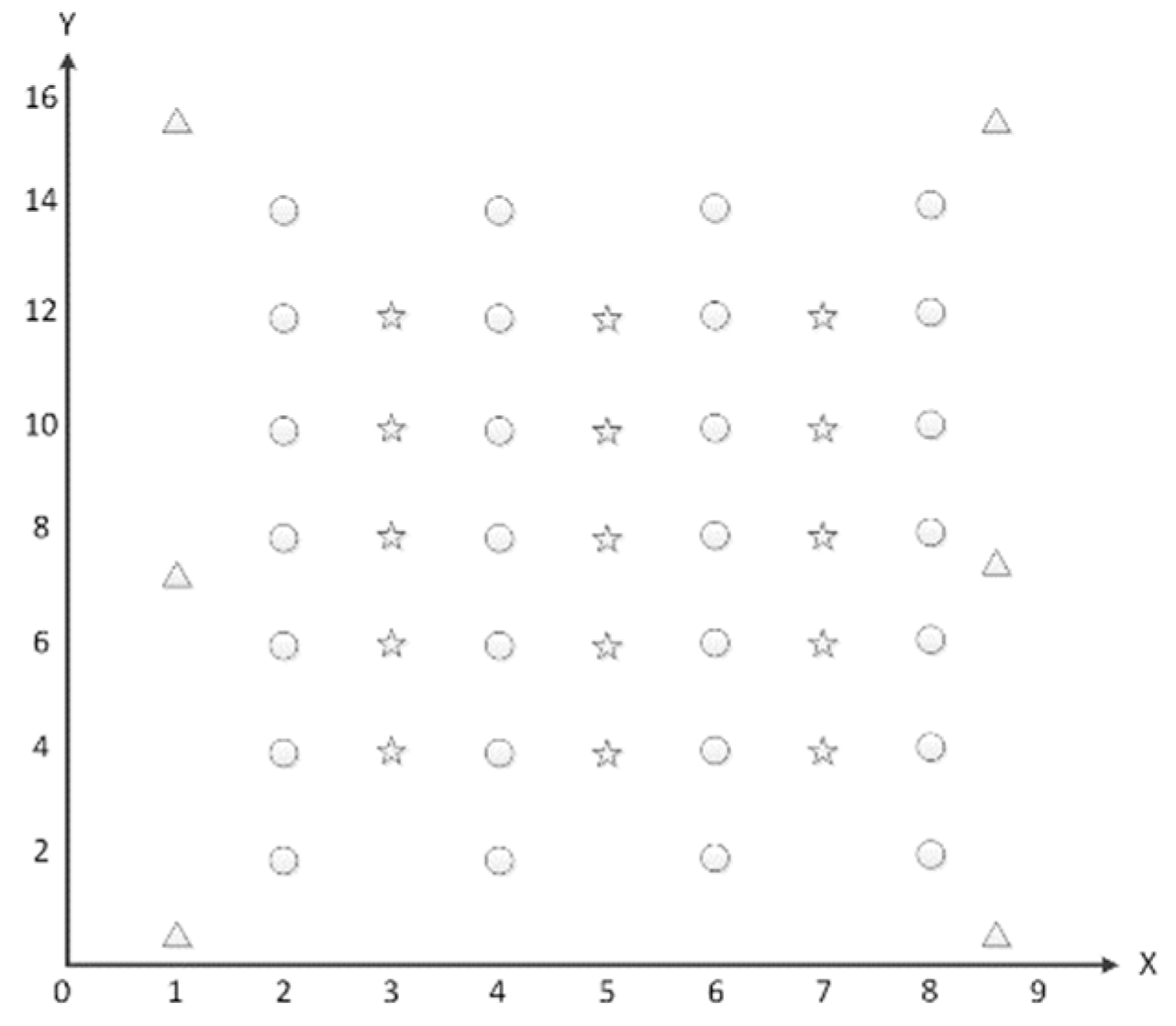
3.1. Experimental Setup
3.2. Performance Evaluations of Pose Recognition
3.2.1. Evaluation Metrics of Poses Recognition
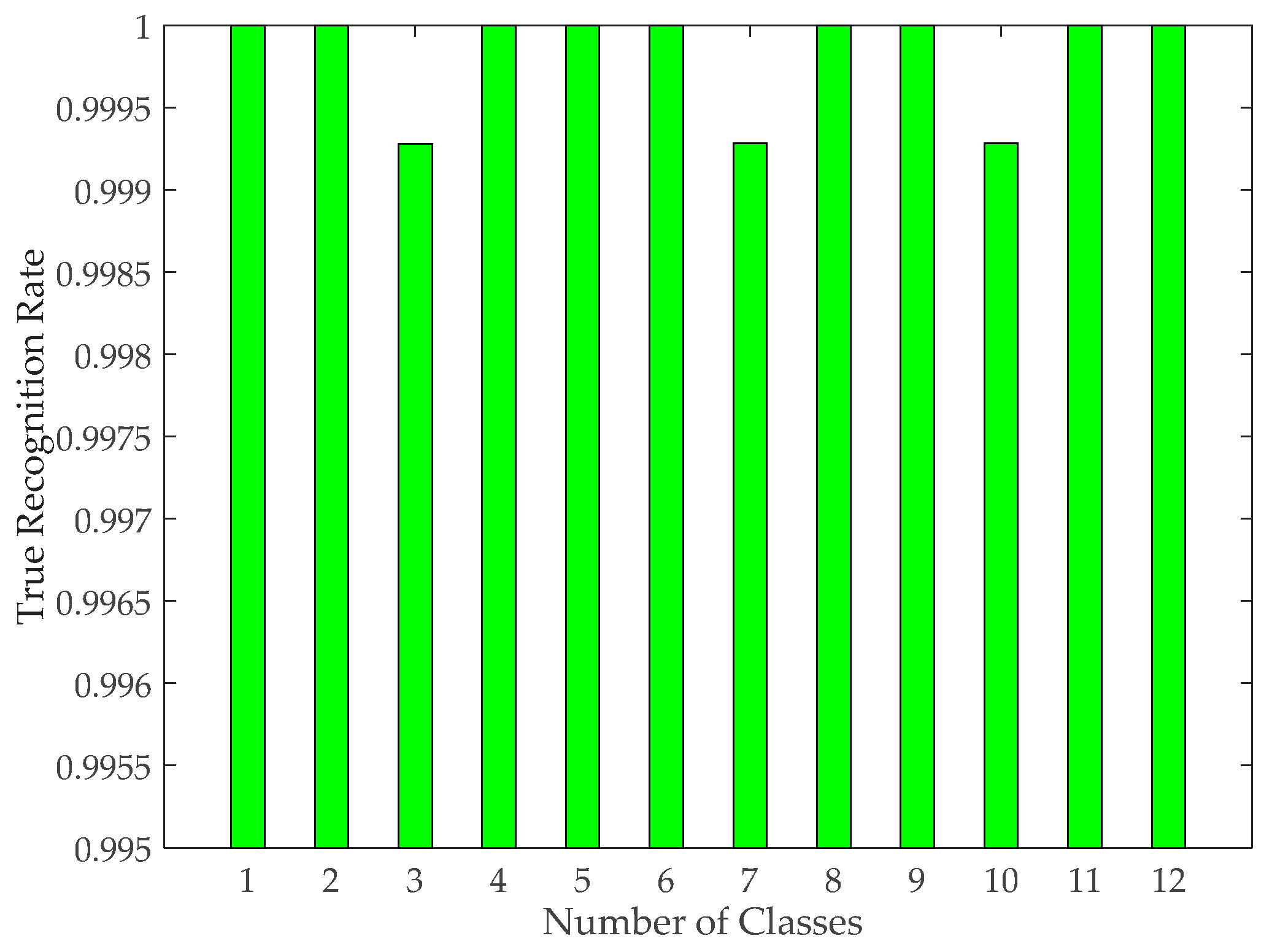
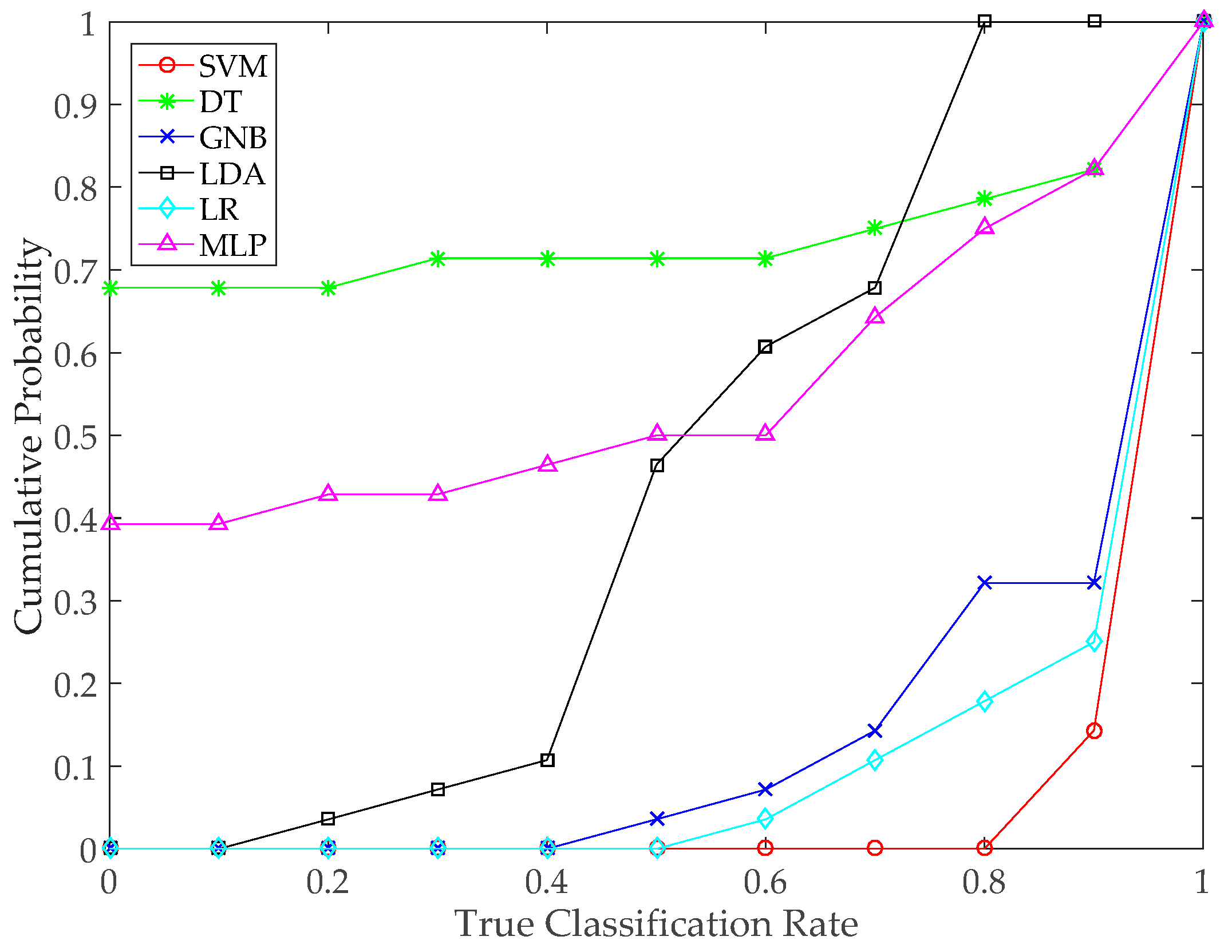
3.2.2. Pose Recognition Results
3.3. Analysis of Positioning Performance When Considering Pillars of the Room and Wi-Fi Frequency Bands
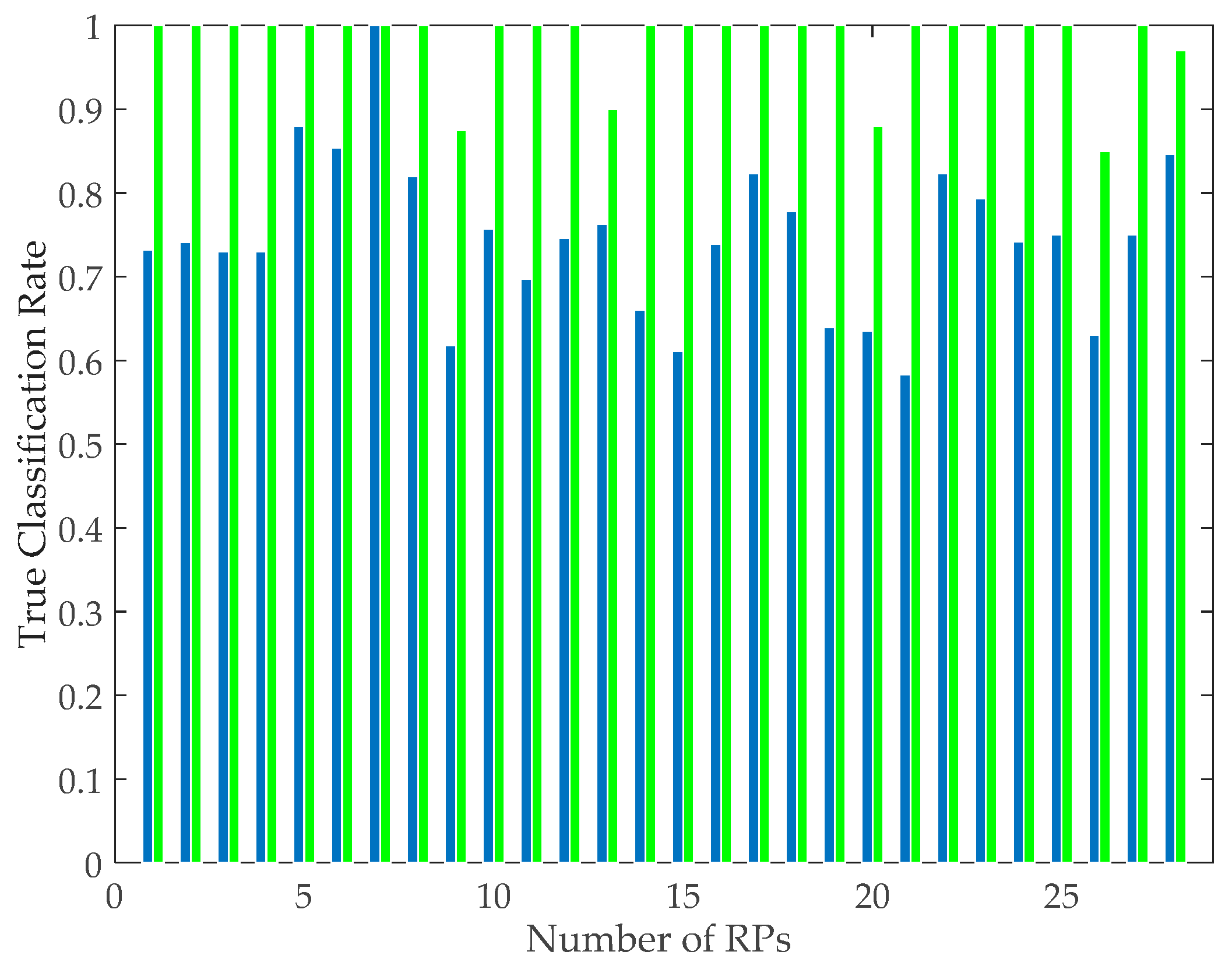
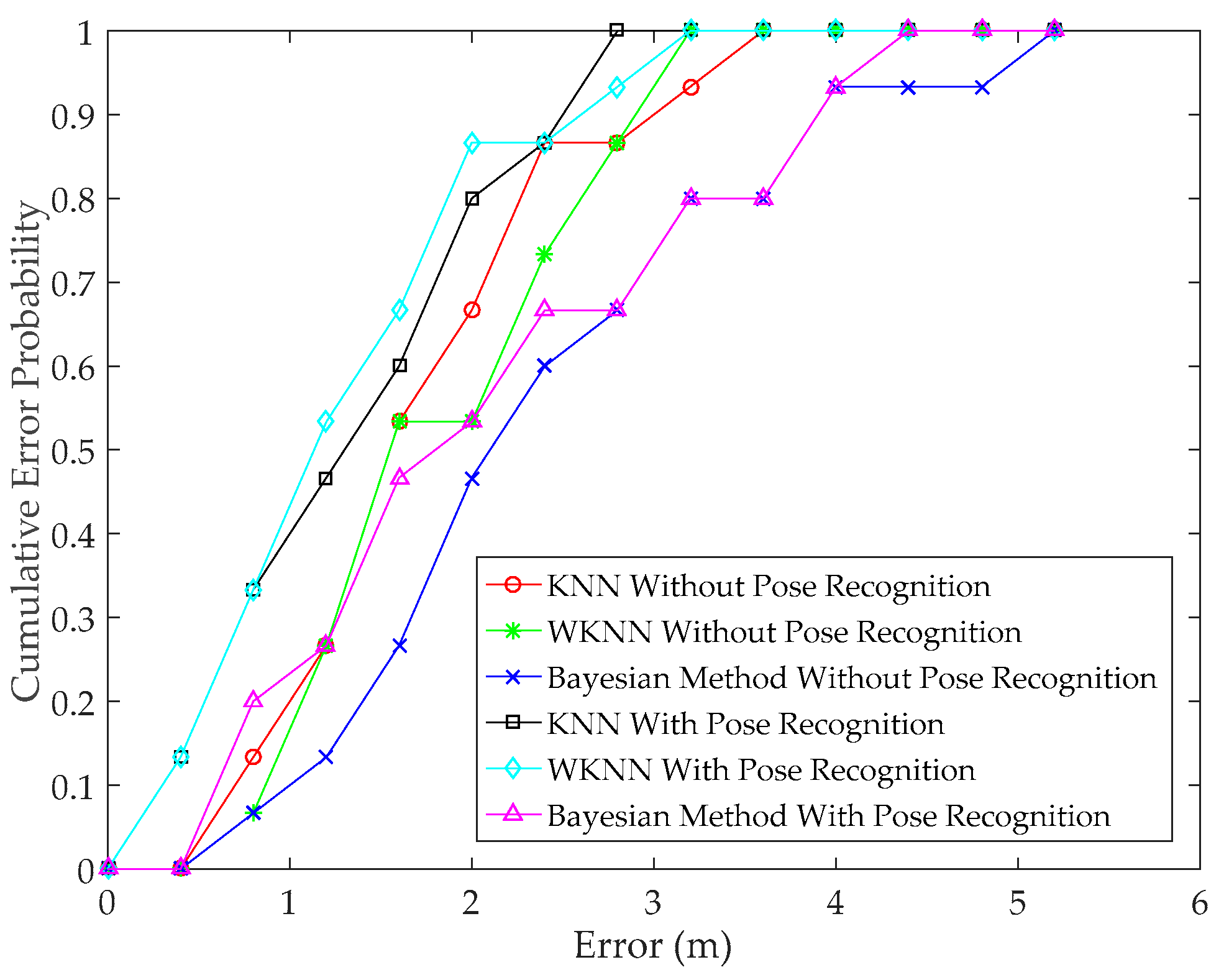
3.4. Performance Evaluations of Positioning Algorithms with Pose Recognition
3.4.1. Performance of Pose Recognition-Assisted Conventional Positioning Methods
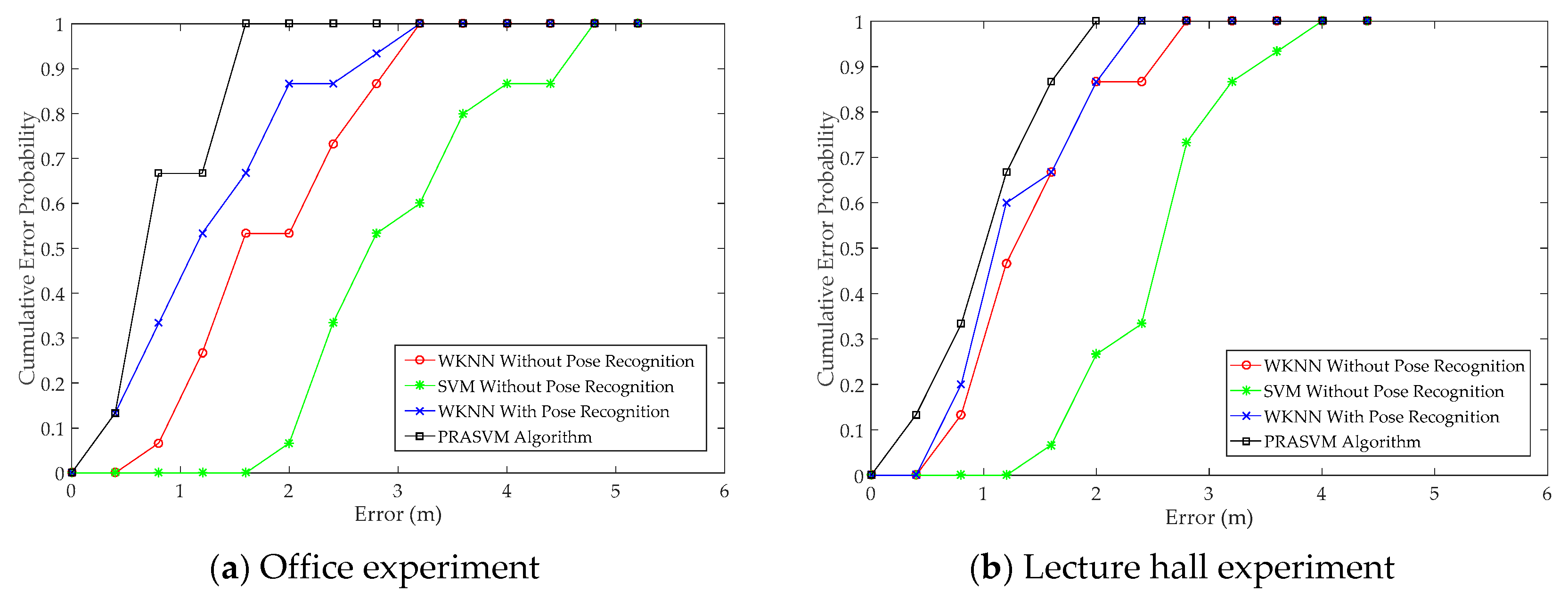
3.4.2. Performance of the PRASVM Algorithm
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Enge, R.P.; Misra, P. Special issue on global positioning system. Proc. IEEE 1999, 87, 3–15. [Google Scholar] [CrossRef]
- John, N.B.; Heidemann, J.; Estrin, D. GPS-less low cost outdoor positioning for very small devices. IEEE Pers. Comm. Mag. 2000, 7, 28–34. [Google Scholar]
- Karegar, P.A. Wireless fingerprint indoor positioning using affinity propagation clustering methods. Wirel. Netw. 2017, 3, 1–9. [Google Scholar]
- Bisio, I.; Cerruti, M.; Lavagetto, F.; Marchese, M.; Pastorino, M.; Randazzo, A. A Trainingless Wi-Fi fingerprint positioning method over mobile devices. IEEE Antennas Wirel. Propag. Lett. 2014, 13, 832–835. [Google Scholar] [CrossRef]
- Niculescu, D.; Nath, B. Ad Hoc Positioning System (APS) Using AOA. In Proceedings of the Twenty-Second Annual Joint Conference of the IEEE Computer and Communications Societies, San Francisco, CA, USA, 30 March–3 April 2003; pp. 1734–1743. [Google Scholar]
- Li, X.; Pahlavan, K. Super-resolution TOA Estimation with diversity for indoor geolocation. IEEE Trans. Wirel. Commun. 2004, 3, 224–234. [Google Scholar] [CrossRef]
- Amar, A.; Leus, G. A Reference-Free Time Difference of Arrival Source Positioning Using a Passive Sensor Array. In Proceedings of the IEEE Sensor Array Multichannel Signal Process, Workshop (SAM), Jerusalem, Israel, 4–7 October 2010; pp. 157–160. [Google Scholar]
- Dakkak, M.; Nakib, A.; Daachi, B. Indoor positioning method based on RTT and AOA using coordinates clustering. Comput. Netw. 2011, 55, 1794–1803. [Google Scholar] [CrossRef]
- Li, Z.; Liu, J.; Wang, Z.; Chen, R.Z. A Novel Fingerprinting Method of WiFi Indoor Positioning Based on Weibull Signal Model. In Proceedings of the China Satellite Navigation Conference (CSNC) 2018 Proceedings, Harbin, China, 23–25 May 2018; pp. 297–309. [Google Scholar]
- Tran, D.N.; Phan, D.D. Human Activities Recognition in Android Smartphone Using Support Vector Machine. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 64–68. [Google Scholar]
- Yang, J. Toward Physical Activity Diary: Motion Recognition Using Simple Acceleration Features with Mobile Phones. In Proceedings of the 1st International Workshop on Interactive Multimedia for Consumer Electronics, Beijing, China, 23–23 October 2009; pp. 1–10. [Google Scholar]
- Pei, L.; Liu, J.B.; Guinness, R. Using LS-SVM Based Motion recognition for smartphone indoor wireless positioning. Sensors 2012, 12, 6155–6175. [Google Scholar] [CrossRef]
- Tran, D.A.; Nguyen, T. Positioning in wireless sensor networks based on support vector machines. IEEE Trans. Parallel Dis. Syst. 2008, 19, 981–994. [Google Scholar] [CrossRef]
- Wu, Z.L.; Li, C.H.; Ng, K.Y. Location estimation via support vector regression. IEEE Trans. Mob. Comput. 2007, 6, 311–321. [Google Scholar] [CrossRef]
- Brunato, M.; Battiti, R. Statistical learning theory for location fingerprint in wireless LANs. Comput. Netw. 2005, 47, 825–845. [Google Scholar] [CrossRef]
- Sang, N.; Yuan, X.Z.; Zhou, R. Wi-Fi indoor location based on SVM classification and regression. Comput. Appl. 2014, 31, 1820–1823. [Google Scholar]
- Yu, F.; Jiang, M.H.; Liang, J. An indoor positioning of Wi-Fi based on support vector machines. Adv. Mater. Res. 2014, 4, 926–930. [Google Scholar]
- Khalajmehrabadi, A.; Gatsis, N.; Akopian, D. Modern WLAN Fingerprinting indoor positioning methods and deployment challenges. IEEE Commun. Surv. Tutor. 2017, 19, 1974–2002. [Google Scholar] [CrossRef]
- Lu, W.; Teng, J.; Zhou, Q. Stress Prediction for distributed structural health monitoring using existing measurements and pattern recognition. Sensors 2018, 18, 419. [Google Scholar] [CrossRef]
- Bovio, I.; Monaco, E.; Arnese, M. Damage detection and health monitoring based on vibration measurements and recognition algorithms in real-scale aeronautical structural components. Key Eng. Mater. 2003, 519–526. [Google Scholar] [CrossRef]
- Barnachon, M.; Bouakaz, S.; Boufama, B. Ongoing human action recognition with motion capture. Pattern Recognit. 2014, 47, 238–247. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, G.; Kriegman, D.J. A Real-time approach to the spotting, representation, and recognition of hand gestures for human-computer interaction. Comput. Vis. Image Underst. 2002, 85, 189–208. [Google Scholar] [CrossRef]
- Wang, G.; Li, Q.; Wang, L. Impact of Sliding window length in indoor human motion modes and pose pattern recognition based on smartphone sensors. Sensors 2018, 18, 1965. [Google Scholar] [CrossRef]
- Guo, G.; Chen, R.; Ye, F. A Pose awareness solution for estimating pedestrian walking speed. Sensors 2019, 11, 55. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, W.; Shen, Q. A handheld inertial pedestrian navigation system with accurate step modes and device poses recognition. IEEE Sens. J. 2015, 15, 1421–1429. [Google Scholar] [CrossRef]
- Oh, J.; Kim, J. Adaptive K-nearest neighbour algorithm for WiFi fingerprint positioning. ICT Express 2018, 4, 91–94. [Google Scholar] [CrossRef]
- Liu, H.H. The Quick radio fingerprint collection method for a Wi-Fi-based indoor positioning system. Mob. Netw. Appl. 2015, 22, 1–11. [Google Scholar]
- Caso, G.; Nardis, L.D. Virtual and oriented Wi-Fi Fingerprint indoor positioning based on multi-wall multi-floor propagation models. Mob. Netw. Appl. 2017, 22, 825–833. [Google Scholar] [CrossRef]
- Ma, R.; Guo, Q.; Hu, C. An Improved Wi-Fi indoor positioning algorithm by weighted fusion. Sensors 2015, 15, 21824–21843. [Google Scholar] [CrossRef] [PubMed]
- Nuñomaganda, M.A.; Herrerarivas, H.; Torreshuitzil, C. On-device learning of indoor location for Wi-Fi fingerprint method. Sensors 2018, 18, 1–14. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s Bayes—Not so stupid after all? Int. Stat. Rev. 2010, 69, 385–398. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical machine learning tools and techniques with java implementations. ACM Sigmod Rec. 2011, 31, 76–77. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, D.; Li, B.; Guo, B.; Li, S. Activity Recognition on an Accelerometer Embedded Mobile Phone with Varying Positions and Orientations. In Proceedings of the 7th International Conference on Ubiquitous Intelligence and Computing, Xi’an, China, 26–29 October 2010; pp. 548–562. [Google Scholar]
- Khan, A.M.; Lee, Y.K.; Lee, S.; Kim, T.S. Human Activity Recognition via an Accelerometer-Enabled-Smartphone Using Kernel Discriminant Analysis. In Proceedings of the 5th International Conference on Future Information Technology, Busan, Korea, 21–23 May 2010; pp. 1–6. [Google Scholar]
- Wu, C.L.; Fu, L.C.; Lian, F.L. WLAN Location Determination in E-home via Support Vector Classification. In Proceedings of the IEEE International Conference on Networking, Sensing and Control, Taipei, Taiwan, 21–23 March 2004; pp. 1026–1031. [Google Scholar]
- Li, N.; Yang, D.; Jiang, L. Combined use of FSR sensor array and SVM classifier for finger motion recognition based on pressure distribution map. J. Bionic Eng. 2012, 9, 39–47. [Google Scholar] [CrossRef]
- Li, J.; Hu, G.Q.; Zhou, Y.H.; Zou, C.; Peng, W. A Temperature compensation method for piezo-resistive pressure sensor utilizing chaotic ions motion algorithm optimized hybrid kernel LSSVM. Sensors 2016, 16, 1707. [Google Scholar] [CrossRef]
- Selvakumari, N.A.S.; Radha, V. A Voice Activity Detector Using SVM and Naïve Bayes Classification Algorithm. In Proceedings of the 2017 International Conference on Signal Processing and Communication (ICSPC), Coimbatore, India, 28–29 July 2017; pp. 1–6. [Google Scholar]
- Burges, J.C. A Tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Singh, R.; Macchi, L.; Regazzoni, C.S. A Statistical Modelling Based Location Determination Method Using Fusion Technique in WLAN. In Proceedings of the IEEE International Workshop on Wireless Ad-hoc Networks (IWWAN), London, UK, 23–26 May 2005; pp. 1–5. [Google Scholar]
- Ge, X.; Qu, Z. Optimization WI-FI Indoor Positioning KNN Algorithm Location-based Fingerprint. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science, Beijing, China, 26–28 August 2016; pp. 135–137. [Google Scholar]
- Ma, J.; Li, X.; Tao, X.P.; Lu, J. Cluster filtered KNN: A WLAN-based Indoor Positioning Scheme. In Proceedings of the 2008 International Symposium on a World of Wireless, Mobile and Multimedia Networks, Newport Beach, CA, USA, 23–26 June 2008; pp. 1–8. [Google Scholar]
- Liu, Q.; Chen, C.; Zhang, Y. Feature selection for support vector machines with RBF Kernel. Artif. Intell. Rev. 2011, 36, 99–115. [Google Scholar] [CrossRef]
- Sánchez-Rodríguez, D.; Alonso-González, I.; Ley-Bosch, C. A Simple indoor localization methodology for fast building classification models based on fingerprints. Electronics 2019, 8, 103. [Google Scholar] [CrossRef]
- Han, C.; Tan, Q.; Sun, L. CSI Frequency domain fingerprint-based passive indoor human detection. Information 2018, 9, 95. [Google Scholar] [CrossRef]
- Haider, A.; Wei, Y.; Liu, S. Pre-and post-processing algorithms with deep learning classifier for Wi-Fi fingerprint-based indoor positioning. Electronics 2019, 8, 195. [Google Scholar] [CrossRef]
- Santos, R.; Barandas, M.; Leonardo, R. Fingerprints and floor plans construction for indoor localisation based on crowdsourcing. Sensors 2019, 19, 919. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.; Fan, X.; Wang, S. Optimization-based Wi-Fi radio map construction for indoor positioning using only smart phones. Sensors 2018, 18, 3095. [Google Scholar] [CrossRef]
- Seong, J.H.; Seo, D.H. Real-time recursive fingerprint radio map creation algorithm combining Wi-Fi and geomagnetism. Sensors 2018, 18, 3390. [Google Scholar] [CrossRef]
- Garcia-Villalonga, S.; Perez-Navarro, A. Influence of Human Absorption of Wi-Fi Signal in Indoor Positioning with Wi-Fi Fingerprinting. In Proceedings of the International Conference on Indoor Positioning & Indoor Navigation, Banff, AB, Canada, 13–16 October 2015; pp. 1–10. [Google Scholar]
- He, S.; Chan, S.H.G. Wi-Fi Fingerprint-based indoor positioning: recent advances and comparisons. IEEE Commun. Surv. Tutor. 2015. [Google Scholar] [CrossRef]
- Wei, Y.; Hwang, S.H.; Lee, S.M. IoT-Aided Fingerprint Indoor Positioning Using Support Vector Classification. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, South Korea, 17–19 October 2018; pp. 973–975. [Google Scholar]
- Alshamaa, D.; Mourad-Chehade, F.; Honeine, P. A Weighted Kernel-based Hierarchical Classification Method for Zoning of Sensors in Indoor Wireless Networks. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Chen, Y.C.; Chiang, J.R.; Huang, P.; Tsui, A.W. Sensor assisted Wi-Fi indoor location system for adapting to environmental dynamics. In Proceedings of the 2005 8th ACM international symposium on modeling, analysis and simulation of wireless and mobile systems, Montréal, QC, Canada, 10–13 October 2005; pp. 118–125. [Google Scholar]
- Xia, H.; Wang, X.; Qiao, Y. Using multiple barometers to detect the floor location of smart phones with built-in barometric sensors for indoor positioning. Sensors 2015, 15, 7857–7877. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Pose | Estimated Pose | |
|---|---|---|
| Target Pose | Other Pose | |
| Target Pose | True Positive (TP) | False Negative (FN) |
| Other Pose | False Positive (FP) | True Negative (TN) |
| Evaluation Parameters | Definition |
|---|---|
| Estimated TP Location | TL |
| True TP Location | TLtruth |
| Absolute Error | |
| Maximum Absolute Error | |
| Minimum Absolute Error | |
| Median Absolute Error | |
| Mean Absolute Error | |
| Standard Deviation |
| Selected AP | Frequency Band (GHz) | MAXAE (m) | MINAE (m) | MEDAE (m) | MAE (m) | STD(m) |
|---|---|---|---|---|---|---|
| All APs 1 | 5 | 2.9648 | 0.3487 | 0.7782 | 0.9774 | 0.6395 |
| 2.4 | 2.1249 | 0.1418 | 0.8161 | 0.9401 | 0.5417 | |
| 2.4 and 5 | 1.9084 | 0.3707 | 0.7848 | 0.8743 | 0.4126 | |
| Side APs | 2.4 and 5 | 1.9359 | 0.2701 | 1.0719 | 1.0929 | 0.4954 |
| Method | MAXAE (m) | MINAE (m) | MEDAE (m) | MAE (m) | STD(m) | |
|---|---|---|---|---|---|---|
| No Pose Recognition | KNN | 3.2274 | 0.5604 | 1.5576 | 1.7270 | 0.7666 |
| WKNN | 2.8413 | 0.5148 | 1.3928 | 1.7001 | 0.7399 | |
| Bayesian | 4.9406 | 0.8000 | 2.0601 | 2.3916 | 1.1886 | |
| Pose Recognition | KNN | 2.6629 | 0.1600 | 1.2625 | 1.2967 | 0.7912 |
| WKNN | 2.8585 | 0.0211 | 1.1054 | 1.2435 | 0.8521 | |
| Bayesian | 4.3081 | 0.7999 | 1.7889 | 2.1373 | 1.2308 |
| Method | MAXAE (m) | MINAE (m) | MEDAE (m) | MAE (m) | STD (m) | |||
|---|---|---|---|---|---|---|---|---|
| Office Experiment | Test data 1 | No Pose Recognition | WKNN | 2.8413 | 0.5148 | 1.3928 | 1.7001 | 0.7399 |
| SVM | 4.6999 | 1.6081 | 2.8000 | 3.0886 | 0.8458 | |||
| Pose Recognition | WKNN | 2.8585 | 0.0211 | 1.1054 | 1.2435 | 0.8521 | ||
| PRASVM | 1.5807 | 0.1182 | 0.5808 | 0.8112 | 0.5041 | |||
| Test data 2 | No Pose Recognition | WKNN | 2.9385 | 0.8626 | 1.8522 | 1.8538 | 0.6319 | |
| SVM | 4.8902 | 1.9408 | 3.2304 | 3.2165 | 0.7751 | |||
| Pose Recognition | WKNN | 2.8930 | 0.4288 | 1.4322 | 1.4505 | 0.6476 | ||
| PRASVM | 2.0785 | 0.2340 | 1.0304 | 0.9765 | 0.5106 | |||
| Lecture hall Experiment | No Pose Recognition | WKNN | 2.7168 | 0.6887 | 1.2940 | 1.4083 | 0.5636 | |
| SVM | 3.9844 | 1.3188 | 2.5343 | 2.5412 | 0.6956 | |||
| Pose Recognition | WKNN | 2.3537 | 0.5404 | 1.1164 | 1.2861 | 0.5636 | ||
| PRASVM | 1.7888 | 0.3577 | 0.9523 | 1.0049 | 0.4089 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Guo, J.; Luo, N.; Wang, L.; Wang, W.; Wen, K. Improving Wi-Fi Fingerprint Positioning with a Pose Recognition-Assisted SVM Algorithm. Remote Sens. 2019, 11, 652. https://doi.org/10.3390/rs11060652
Zhang S, Guo J, Luo N, Wang L, Wang W, Wen K. Improving Wi-Fi Fingerprint Positioning with a Pose Recognition-Assisted SVM Algorithm. Remote Sensing. 2019; 11(6):652. https://doi.org/10.3390/rs11060652
Chicago/Turabian StyleZhang, Shuai, Jiming Guo, Nianxue Luo, Lei Wang, Wei Wang, and Kai Wen. 2019. "Improving Wi-Fi Fingerprint Positioning with a Pose Recognition-Assisted SVM Algorithm" Remote Sensing 11, no. 6: 652. https://doi.org/10.3390/rs11060652
APA StyleZhang, S., Guo, J., Luo, N., Wang, L., Wang, W., & Wen, K. (2019). Improving Wi-Fi Fingerprint Positioning with a Pose Recognition-Assisted SVM Algorithm. Remote Sensing, 11(6), 652. https://doi.org/10.3390/rs11060652