Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms

 , ,
, ,  ,
, 
Abstract
:
1. Introduction
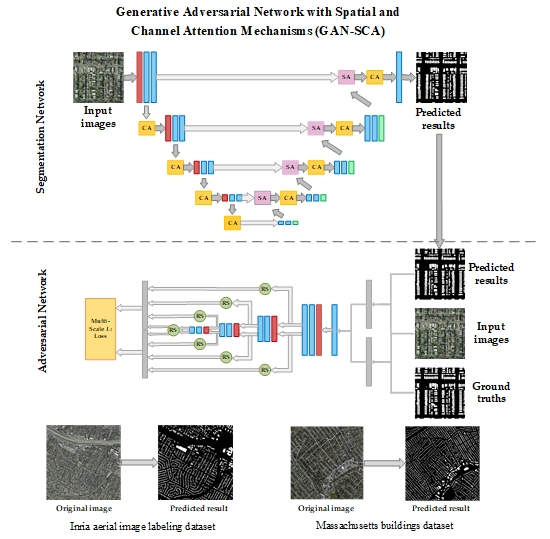
- A GAN-based network called GAN-SCA is proposed for building extraction from high-resolution aerial imagery. The architecture is composed of a segmentation network and an adversarial network. The segmentation network aims to predict pixel-wise labeling maps that are similar to ground truths, while the adversarial network is set to discriminate different characteristics of different label maps to further enhance the high-frequency continuity of the prediction maps.
- Spatial and channel attention mechanisms are embedded in the proposed GAN-SCA architecture to enable selectively attaching important features from both the spatial dimension and channel relationship.
- The adversarial network and segmentation network are trained to optimize a multi-scale L1 loss and multiple cross entropy losses combined with a multi-scale L1 loss alternatively. With no requirements for any post-processing, our proposed network improved the state-of-the-art performance on both the Inria aerial image labeling dataset and Massachusetts buildings dataset.
2. Methods
2.1. Proposed Network GAN-SCA
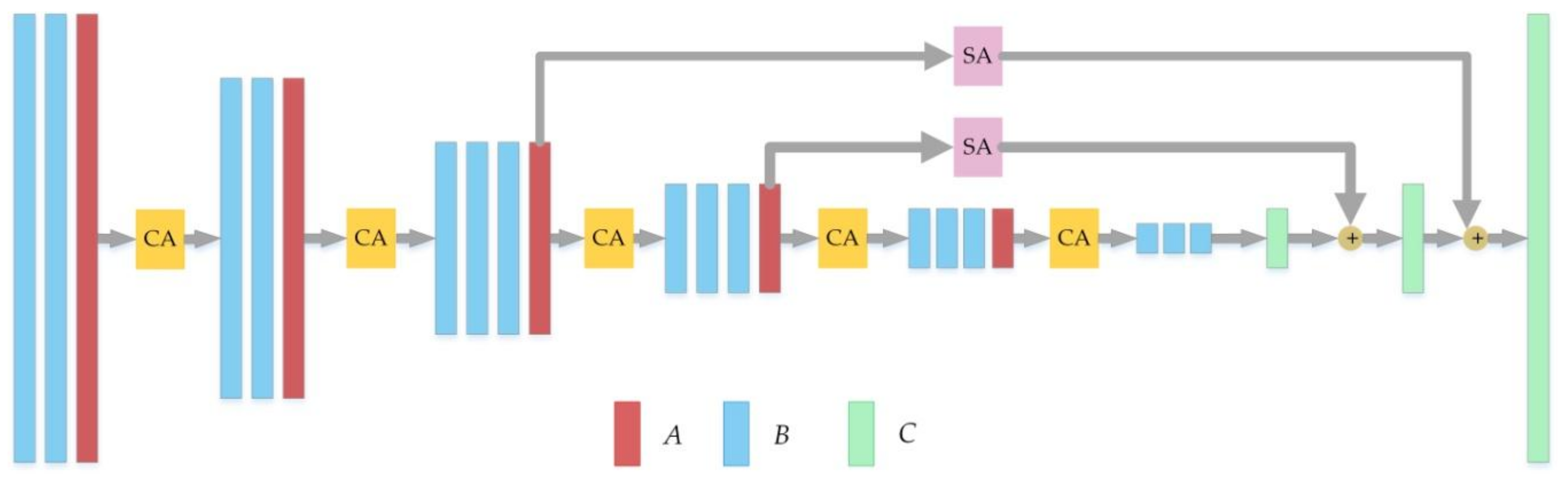
2.1.1. Segmentation Network
2.1.2. Adversarial Network
2.2. Training Strategy
3. Datasets and Evaluation Metrics
3.1. Datasets
3.2. Evaluation Metrics
4. Experiments
4.1. Ablation Study
4.2. Comparison to State-of-the-Art Methods
4.2.1. Inria Aerial Image Labeling Dataset
4.2.2. Massachusetts Buildings Dataset
4.3. Experiments on FCN based GAN-SCA
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rees, W.G. Physical Principles of Remote Sensing; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Computer Sci. 2014, 4, 357–361. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.; Saber, E. Dense semantic labeling of very-high-resolution aerial imagery and LiDAR with fully-convolutional neural networks and higher-order crfs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1561–1570. [Google Scholar]
- Liu, Y.; Minh Nguyen, D.; Deligiannis, N.; Ding, W.; Munteanu, A. Hourglass-shape network based semantic segmentation for high resolution aerial imagery. Remote Sens. 2017, 9, 522. [Google Scholar] [CrossRef]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Maggiori, E.; Charpiat, G.; Tarabalka, Y.; Alliez, P. Recurrent Neural Networks to Correct Satellite Image Classification Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4962–4971. [Google Scholar] [CrossRef] [Green Version]
- Bergado, J.R.; Persello, C.; Stein, A. “Recurrent Multiresolution Convolutional Networks for VHR Image Classification,”. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6361–6374. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Qc, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv, 2016; arXiv:161108408. Available online: https://arxiv.org/abs/1611.08408(accessed on 1 April 2018).
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. SegAN: Adversarial network with multi-scale L1 loss for medical image segmentation. Neuroinformatics 2017, 6, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Gao, L.; Zhang, B.; Yang, F.; Liao, W. High-resolution aerial imagery semantic labeling with dense pyramid network. Sensors 2018, 18, 3774. [Google Scholar] [CrossRef] [PubMed]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv, 2016; arXiv:1606.02585v1. Available online: https://arxiv.org/abs/1606.02585(accessed on 1 April 2018).
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. on Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks. Electronic Imag. 2016, 60, 10401–10402. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The Inria aerial image labeling benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. arXiv, 2017; arXiv:1709.05932. Available online: https://arxiv.org/abs/1709.05932(accessed on 27 April 2018).
- Khalel, A.; El-Saban, M. Automatic pixelwise object labeling for aerial imagery using stacked u-nets, arXiv 2018, arXiv:1803.04953. Available online: https://arxiv.org/abs/1803.04953 (accessed on 27 April 2018).
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural networkk for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 21–23 November 2016; pp. 180–196. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–3288. [Google Scholar]
- Building segmentation on satellite images. Available online: https://project.inria.fr/ aerialimagelabeling/files/2018/01/fp_ohleyer_compressed.pdf (accessed on 1 April 2018).
- Marcu, A.; Costea, D.; Slusanschi, E.; Leordeanu, M. A Multi-stage Multi-task neural network for aerial scene interpretation and geolocalization. arXiv, 2018; arXiv:1804.01322v1. Available online: https://arxiv.org/abs/1804.01322(accessed on 27 April 2018).
- Marcu, A.; Leordeanu, M. Object contra context: Dual local-global semantic segmentation in aerial images. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 146–152. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Machine Learning (ICML), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Metrics | Austin | Chicago | Kitsap | Tyrol-w | Vienna | Overall |
|---|---|---|---|---|---|---|---|
| U-Net | IoU | 79.95 ± 0.81 | 70.18 ± 0.22 | 68.56 ± 1.49 | 76.29 ± 2.06 | 79.92 ± 0.39 | 76.16 ± 0.21 |
| Acc. | 97.10 ± 0.11 | 92.67 ± 0.15 | 99.31 ± 0.03 | 98.15 ± 0.15 | 94.25 ± 0.18 | 96.31 ± 0.07 | |
| U-Net-SCA | IoU | 80.40 ± 0.43 | 71.04 ± 0.70 | 68.25 ± 0.46 | 76.77 ± 1.86 | 80.55 ± 0.40 | 76.88 ± 0.42 |
| Acc. | 97.22 ± 0.04 | 93.21 ± 0.10 | 99.30 ± 0.01 | 98.19 ± 0.15 | 94.57 ± 0.10 | 96.50 ± 0.05 | |
| U-Net-SCA +CRFs | IoU | 80.36 ± 0.76 | 71.53 ± 0.15 | 68.40 ± 0.26 | 77.04 ± 1.99 | 80.83 ± 0.16 | 77.09 ± 0.22 |
| Acc. | 97.17 ± 0.10 | 93.24 ± 0.06 | 99.31 ± 0.01 | 98.20 ± 0.15 | 94.62 ± 0.06 | 96.51 ± 0.05 | |
| U-Net-SCA +Reuse | IoU | 80.76 ± 0.23 | 71.52 ± 0.30 | 68.08 ± 0.65 | 78.26 ± 0.51 | 81.36 ± 0.38 | 77.48 ± 0.30 |
| Acc. | 97.22 ± 0.04 | 93.25 ± 0.10 | 99.30 ± 0.01 | 98.30 ± 0.03 | 94.78 ± 0.08 | 96.57 ± 0.07 | |
| GAN-SCA | IoU | 80.82 ± 0.21 | 71.37 ± 0.44 | 68.67 ± 0.18 | 78.68 ± 0.09 | 81.62 ± 0.26 | 77.52 ± 0.19 |
| Acc. | 97.24 ± 0.03 | 93.32 ± 0.12 | 99.31 ± 0.01 | 98.33 ± 0.01 | 94.80 ± 0.06 | 96.60 ± 0.02 |
| Methods | Metrics | Austin | Chicago | Kitsap | Tyrol-w | Vienna | Overall |
|---|---|---|---|---|---|---|---|
| FCN [23] | IoU | 47.66 | 53.62 | 33.70 | 46.86 | 60.60 | 53.82 |
| Acc. | 92.22 | 88.59 | 98.58 | 95.83 | 88.72 | 92.79 | |
| MLP [23] | IoU | 61.20 | 61.30 | 51.50 | 57.95 | 72.13 | 64.67 |
| Acc. | 94.20 | 90.43 | 98.92 | 96.66 | 91.87 | 94.42 | |
| Mask R-CNN [32] | IoU | 65.63 | 48.07 | 54.38 | 70.84 | 64.40 | 59.53 |
| Acc. | 94.09 | 85.56 | 97.32 | 98.14 | 87.40 | 92.49 | |
| SegNet+Multi-Task Loss [24] | IoU | 76.76 | 67.06 | 73.30 | 66.91 | 76.68 | 73.00 |
| Acc. | 93.21 | 99.25 | 97.84 | 91.71 | 96.61 | 95.73 | |
| 2-Levels U-Nets [25] | IoU | 77.29 | 68.52 | 72.84 | 75.38 | 78.72 | 74.55 |
| Acc. | 96.69 | 92.40 | 99.25 | 98.11 | 93.79 | 96.05 | |
| MSMT [34] | IoU | 75.39 | 67.93 | 66.35 | 74.07 | 77.12 | 73.31 |
| Acc. | 95.99 | 92.02 | 99.24 | 97.78 | 92.49 | 96.06 | |
| GAN-SCA | IoU | 81.01 | 71.73 | 68.54 | 78.62 | 81.62 | 77.75 |
| Acc. | 97.26 | 93.32 | 99.30 | 98.32 | 94.84 | 96.61 |
| Method | F1-Measure | |
|---|---|---|
| ρ = 0 | ρ = 3 | |
| Mnih-CNN+CRFs [22] | - | 92.11% |
| Satio-multi-MA&CIS [21] | - | 92.30% |
| LG-Seg-ResNet-IL [35] | - | 94.30% |
| MTMS [34] | 83.39% | 96.04% |
| GAN-SCA | 84.79% | 96.36% |
| Methods | Metrics | Austin | Chicago | Kitsap | Tyrol-w | Vienna | Overall |
|---|---|---|---|---|---|---|---|
| FCN-8s | IoU | 67.98 | 63.43 | 53.17 | 68.13 | 72.03 | 68.05 |
| Acc. | 95.47 | 91.41 | 99.01 | 97.52 | 92.38 | 95.16 | |
| FCN-8s-SCA | IoU | 72.85 | 69.61 | 64.97 | 73.20 | 73.26 | 71.76 |
| Acc. | 96.19 | 92.36 | 99.25 | 97.94 | 92.49 | 95.65 | |
| GAN-SCA | IoU | 78.51 | 70.10 | 66.42 | 76.84 | 77.24 | 74.92 |
| Acc. | 96.90 | 92.86 | 99.27 | 98.14 | 93.46 | 96.13 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sens. 2019, 11, 917. https://doi.org/10.3390/rs11080917
Pan X, Yang F, Gao L, Chen Z, Zhang B, Fan H, Ren J. Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sensing. 2019; 11(8):917. https://doi.org/10.3390/rs11080917
Chicago/Turabian StylePan, Xuran, Fan Yang, Lianru Gao, Zhengchao Chen, Bing Zhang, Hairui Fan, and Jinchang Ren. 2019. "Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms" Remote Sensing 11, no. 8: 917. https://doi.org/10.3390/rs11080917
APA StylePan, X., Yang, F., Gao, L., Chen, Z., Zhang, B., Fan, H., & Ren, J. (2019). Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sensing, 11(8), 917. https://doi.org/10.3390/rs11080917