1. Introduction
High-resolution remote sensing images have been increasingly popular and widely used in many geoscience applications, including automatic mapping of land use or land cover types, and automatic detection or extraction of small objects such as vehicles, ships, trees, roads, buildings, etc. [
1,
2,
3,
4,
5,
6]. As one of these geoscience applications, the automatic extraction of building footprints from high-resolution imagery is beneficial for urban planning, disaster management, and environmental management [
7,
8,
9,
10]. The spatial distributions of buildings are also essential for monitoring urban settlements, modeling urban demographics, updating the geographical database, and many other aspects [
11,
12]. Due to the diversity of buildings (e.g., in color, shape, size, materials, etc.) in different regions and the similarity of buildings to the background or other objects [
9], developing reliable and accurate building extraction methods has become an important and challenging research issue receiving greater attention.
Over the past few decades, many building extraction studies were based on traditional image processing methods, such as shadow-based methods, edge-based methods, object-based methods, and more [
13,
14,
15]. For instance, Belgiu and Drǎguţ [
16] proposed and compared supervised and unsupervised multi-resolution segmentation methods combined with the random forest (RF) classifier for building extraction using high-resolution satellite images. Chen et al. [
17] proposed edge regularity indices and shadow line indices as new features of building candidates obtained from segmentation methods, and employed three machine learning classifiers (AdaBoost, RF, and support vector machine (SVM)) to identify buildings. Huang and Zhang [
18] proposed the morphological shadow index (MSI) to detect shadows (used as a spatial constraint of buildings) and proposed dual-threshold filtering to integrate the information from the morphological building index with the one from MSI. Ok et al. [
19] proposed a novel fuzzy landscape generation method that models the directional spatial relationship of the building and its shadow for automatic building detection. These studies were based on traditional methods and focused on extracting buildings in a relatively small study region. However, the methods have not been evaluated in complex regions with a high diversity of buildings.
In recent years, deep learning methods have been broadly utilized in various remote sensing image–based applications, including object detection [
2,
3,
20], scene classification [
21,
22], land cover, and land use mapping [
23,
24]. Since it was proposed in 2014, deep convolutional neural network (CNN)-based semantic segmentation algorithms [
25] have been applied to many pixel-wise remote sensing image analysis tasks, such as road extraction, building extraction, urban land use classification, maritime semantic labeling, vehicle extraction, damage mapping, weed mapping, and other land cover mapping tasks [
5,
6,
26,
27,
28,
29,
30,
31]. Several recent studies used semantic segmentation methods for building extraction from remote sensing images [
9,
10,
11,
12,
32,
33,
34,
35,
36,
37,
38]. For example, Shrestha et al. [
10] proposed a fully connected network-based building extraction approach combined with the exponential linear unit (ELU) and conditional random fields (CRFs) using the Massachusetts building dataset. Lu et al. [
32] employed the richer convolutional features network–based approach to detect building edges using the Massachusetts building dataset. Xu et al. [
12] proposed a building extraction method based on the Res-U-Net model combined with guided filters using the ISPRS (International Society for Photogrammetry and Remote Sensing) 2D semantic labeling dataset. Sun et al. [
7] proposed a building extraction method that combines the SegNet model with the active contour model using the ISPRS Potsdam dataset and the proposed Marion dataset. These existing studies demonstrated the excellent performance of the semantic segmentation algorithms for building extraction tasks.
As an essential part of the semantic segmentation algorithms, the public semantic labeling datasets used in previous state-of-the-art building extraction studies can be summarized as follows: (1) The Massachusetts building dataset [
39] (used in References [
10,
32,
35]) contains 151 aerial images (at 100 cm spatial resolution, with red/green/blue (RGB) bands, each with a size of 1500 × 1500 pixels) of the Boston area. (2) The ISPRS Vaihingen and Potsdam datasets [
40] (used in References [
7,
12]) contain 38 image patches (at 5 cm resolution, each at a size of around 6000 × 6000 pixels) and 33 image patches (at 9 cm resolution, each with a size of around 2500 × 2500 pixels) with the near infrared, red, and green bands and the corresponding digital surface model (DEM) data. (3) The Inria dataset [
41] (used in References [
36,
37]) contains aerial images covering 10 regions in the USA and Austria (at 30 cm resolution, with RGB bands). (4) The WHU (Wuhan University) building dataset [
42] (used in Reference [
38]) includes an aerial dataset containing 8189 image patches (at 30 cm resolution, with RGB bands, each with a size of 512 × 512 pixels) and a satellite dataset containing 17,388 image patches (at 270 cm resolution, with the same bands and size as the aerial dataset). (5) The AIRS (Aerial Imagery for Roof Segmentation) dataset [
43] contains aerial images covering the area of Christchurch city in New Zealand (at 7.5 cm resolution, with RGB bands).
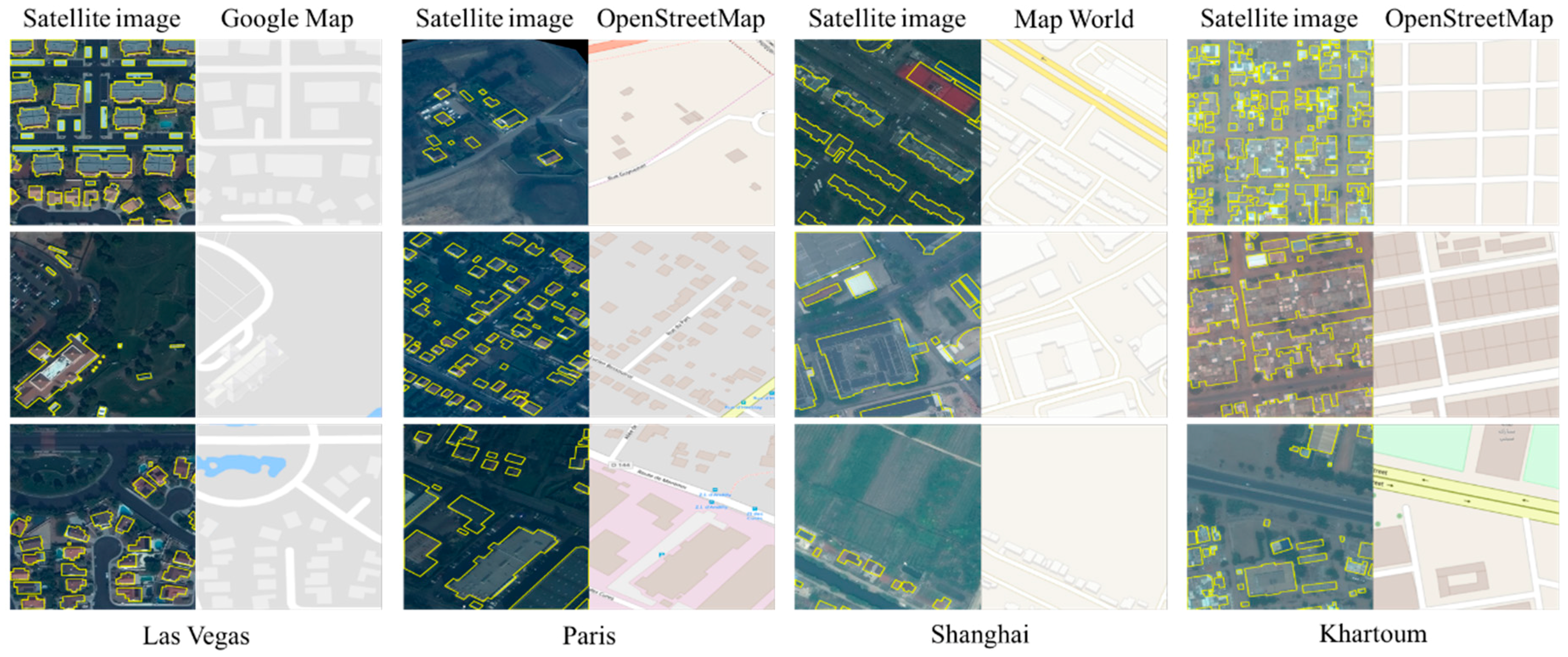
In this study, our proposed building extraction method is trained and evaluated based on the SpaceNet building dataset [
44] proposed in 2017 and further explored in the 2018 DeepGlobe Satellite Image Understanding Challenge [
11]. The SpaceNet building dataset provided in the DeepGlobe Challenge contains WorldView-3 multispectral imagery and the corresponding building footprints of four cities (Las Vegas, Paris, Shanghai, and Khartoum) located on four continents. The buildings in the SpaceNet dataset are much more diverse compared with the five datasets mentioned above. Details of the SpaceNet dataset are described in
Section 2.
In addition, many studies employed data-fusion strategies that integrate different data to improve the building extraction results. Airborne light detection and ranging (LiDAR) data are among the most broadly utilized data in numerous building extraction studies [
7,
45,
46,
47,
48,
49,
50,
51,
52,
53]. For instance, Awrangjeb et al. [
52] proposed a rule-based building roof extraction method from a combination of LiDAR data and multispectral imagery. Pan et al. [
53] proposed a semantic segmentation network–based method for semantic labeling of the ISPRS dataset using high-resolution aerial images and LiDAR data. However, public and free LiDAR datasets are still very limited. On the other hand, GIS data (e.g., OpenStreetMap) has been utilized in several building extraction and semantic labeling studies [
54,
55,
56,
57] as either the reference map of the labeled datasets [
54,
55] or auxiliary data combined with satellite images [
56,
57]. For instance, Audebert [
56] investigated different ways of integrating OpenStreetMap data and semantic segmentation networks for semantic labeling of aerial and satellite images. Du et al. [
57] proposed an improved random forest method for semantic classification of urban buildings, which combines high-resolution images with GIS data. Nevertheless, OpenStreetMap data still cannot provide enough building information for many places in the world, including the selected regions in Las Vegas, Shanghai, and Khartoum of the SpaceNet building dataset used in our study.
In this research, we propose a semantic segmentation–based building footprint extraction method using the SpaceNet building dataset provided in the CVPR 2018 DeepGlobe Satellite Challenge. Several public GIS map datasets (OpenStreetMap [
58], Google Maps [
59], and MapWorld [
60]) are integrated with the provided WorldView-3 satellite datasets to improve the building extraction results. The proposed method obtains an overall F1-score of 0.704 for the validation dataset, which achieved fifth place in the DeepGlobe Building Extraction Challenge. Our main contributions can be summarized as follows:
(1) To the best of our knowledge, this is the first attempt conducted to explore the combination of multisource GIS map datasets and multispectral satellite images for building footprint extraction in four cities that demonstrates great potential for reducing extraction confusion caused by overlapping objects and improving the extraction of building outlines.
(2) We propose a U-Net–based semantic segmentation model for building footprint extraction. Several strategies (data augmentation, post-processing, and integration of GIS map data and satellite images) are designed and combined with the semantic segmentation model, which increases the F1-score of the standard U-Net–based method by 3.0% to 9.2%.
(3) The effect of each proposed strategy, the final building footprint extraction results, and the potential causes are analyzed comprehensively based on the actual situation of four cities. Even compared with the top three solutions in the SpaceNet Building Detection Competition, our proposed method improves the total F1-score by 1.1%, 6.1%, and 12.5%.
The rest of the paper is organized as follows.
Section 2 introduces the study area and the datasets of this research, including the SpaceNet building dataset provided in the DeepGlobe Challenge and the auxiliary GIS map data.
Section 3 introduces our proposed method, including data preparation and augmentation, the semantic segmentation model for building footprint extraction, and the integration and post-processing of results.
Section 4 describes the building footprint extraction results of the proposed method.
Section 5 discusses and analyzes the building footprint extraction results obtained from different methods and proposed strategies, and the potential causes for each city.
Section 6 summarizes the conclusions of this research.
3. Materials and Methods
In this study, we designed a semantic segmentation–based approach for building footprint extraction.
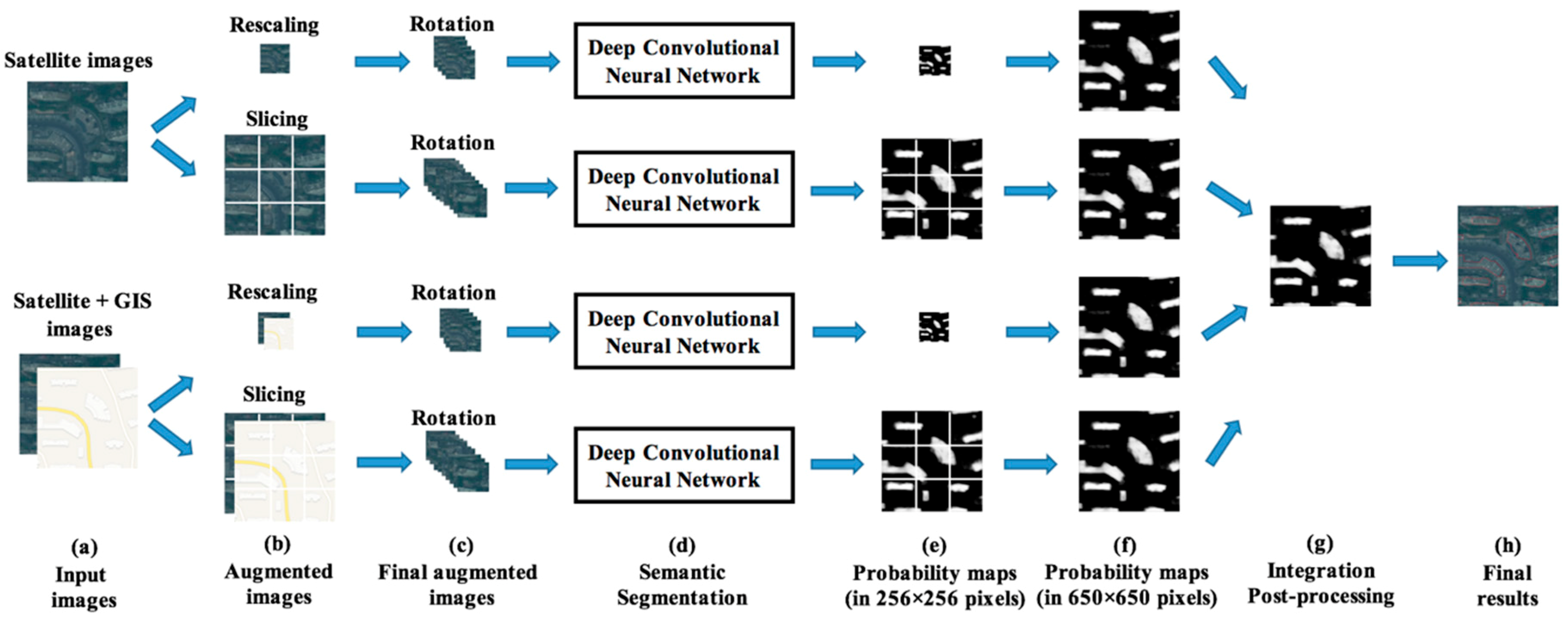
Figure 2 shows the overall flowchart of the proposed approach. It consists of 3 main stages including data preparation and augmentation, semantic segmentation for building footprint extraction, and integration and post-processing of results. In the first stage, we designed a data fusion method to make full use of both the satellite images and the extra information of GIS map data. We applied data augmentation (rescaling, slicing, and rotation) to our dataset in order to avoid potential problems (e.g., overfitting), which resulted from insufficient training samples, and to improve the generalization ability of the model. In the second stage, we trained and evaluated the U-Net–based semantic segmentation model, which is widely used in many remote sensing image segmentation studies. In the third stage, we applied the integration and post-processing strategies for further refinement of the building extraction results. Details of each stage are described in the following sections.
3.1. Data Preparation and Augmentation
3.1.1. Integration of Satellite Data and GIS Map Data
As mentioned in
Section 2, besides the WorldView-3 multispectral satellite imagery provided in the SpaceNet dataset, we also used multiple public GIS map datasets as the auxiliary data for our proposed method. Although these public GIS map datasets provide extra information for building footprint extraction, it is unreasonable to train a separate deep neural network using the 3-band map datasets. The main reason is that many buildings are not displayed on the map image (especially tiny buildings and those in Khartoum city). In many regions, the building areas or outlines displayed in map images are not consistent with the ground truth buildings annotated based on the satellite images.
In this research, the training and validation datasets were preprocessed into two collections for each city. The first collection contained the eight-band multi-spectral satellite images while the second collection integrated the multi-spectral satellite images and the GIS map dataset. In order to unify the structure of the semantic segmentation network for the 2 dataset collections and enable the model trained by one dataset collection to be used as the pre-trained model for the other, we stacked the first 5 bands (red, red edge, coastal, blue, and green) of each WorldView-3 satellite image with the 3 bands (red, green, and blue) of its corresponding map image to generate an 8-band integrated image.
3.1.2. Data Augmentation
Data augmentation was proven to be an effective strategy to avoid potential problems (e.g., overfitting) resulting from insufficient training samples and to improve the generalization ability of deep learning models in many previous studies [
9,
10,
32]. Considering the large number of hyper-parameters in the semantic segmentation model and the relatively small number of training samples in the SpaceNet building dataset (fewer than 5000 samples for each city), we applied the following data augmentation strategy (rescaling, slicing, and rotation) in order to increase the quantity and diversity of training samples and semantic segmentation models. Each dataset collection described in
Section 3.1.1 was further preprocessed into 2 formats of input images for the training of each semantic segmentation model. First, each image with a size of 650 × 650 pixels was rescaled into an image of 256 × 256 pixels. Second, each image with a size of 650 × 650 pixels was sliced into 3 × 3 sub-images of 256 × 256 pixels. Moreover, we further augmented the training dataset through four 90° rotations. Consequently, we obtained 4 collections of preprocessed and augmented input datasets for each city, which we used for training and evaluating each deep convolutional neural network.
3.2. Semantic Segmentation Model for Building Footprint Extraction
3.2.1. Architecture of Semantic Segmentation Model for the Building Extraction
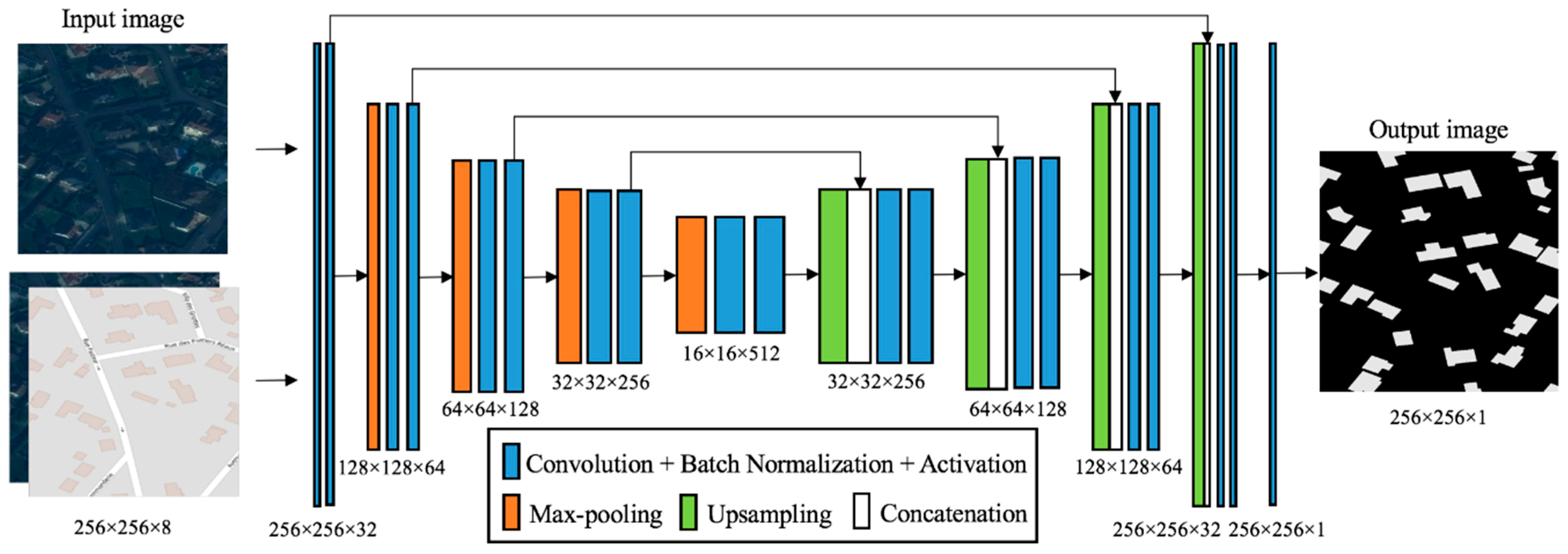
In this study, the semantic segmentation model for the building extraction is based on the U-Net architecture [
61]. U-Net is a popular deep convolutional neural network architecture for semantic segmentation and has been used in several satellite image segmentation studies [
5,
12,
30,
62]. Since U-Net was initially designed for the binary segmentation of biomedical images with a relatively small number of training samples, it is a good choice for the building extraction task in this study as well. We modified the size of layers in the U-Net architecture to fit our building extraction task. We also added a batch normalization layer behind each convolutional layer.
Figure 3 shows the architecture of the semantic segmentation model for our building extraction task, including the name and size of each layer. It consists of the following 6 parts: (1) the convolutional layers for feature extraction through multiple 3 × 3 convolution kernels (denoted by Convolution); (2) the batch normalization layer for accelerating convergence during the training phase (denoted by Batch Normalization); (3) the activation function layer for nonlinear transformation of the feature maps, in which we used the widely used rectified linear unit (ReLU) in this study (denoted by Activation); (4) the max-pooling layer for downsampling of the feature maps (denoted by Max-pooling); (5) the upsampling layer for recovering the size of the feature maps that are downsampled by the max-pooling layer (denoted by Upsampling); and (6) the concatenation layer for combining the upsampled feature map in deep layers with the corresponding feature map from shallow layers (denoted by Concatenation).
For the last batch-normalized layer of the semantic segmentation model (in the same size as the input image), we applied the sigmoid function as the activation function layer and obtained the pixel-wise probability map (indicating the probability that a pixel belonged to the building type). Lastly, we binarized the probability map using a given threshold (0.5 in common cases) to obtain the predicted building footprint extraction result (the output of the semantic segmentation network), and vectorized the output image to obtain a list of predicted building polygons.
3.2.2. Training and Evaluation of Semantic Segmentation Model
To train the semantic segmentation model, we selected Adam as the optimization method and the binary cross entropy as the loss function. Due to the limited size of GPU memory, the batch size in the training phase was set to 8 in this study. The learning rate was set to 0.001 and the maximum number of epochs was set to 100. Moreover, we monitored the average Jaccard coefficient as an indicator for early stopping in order to avoid the potential problem of overfitting. Formula (1) shows the calculation process of the average Jaccard coefficient (denoted by J), in which
denotes the ground truth label of the
pixel,
denotes the predicted label of the
pixel, and
denotes the total number of pixels. The training phase was terminated before reaching the maximum number of epochs if the average Jaccard coefficient had no improvement for more than 10 epochs.
During the training phase, the semantic segmentation model was evaluated by the validation dataset at the end of each epoch. Besides the pixel-based accuracy that is commonly used in semantic segmentation tasks, we also recorded the object-based accuracy of the validation dataset in each epoch since it was the evaluation metric of the DeepGlobe challenge. For pixel-based accuracy, we compared the binarized building extraction image results predicted from the semantic segmentation model with the rasterized ground truth image. For object-based accuracy, we compared the vectorized building extraction image results (a list of predicted building polygons) with the ground truth building polygons (details are described in
Section 3.4). As described in
Section 3.1, for each city, 4 preprocessed and augmented dataset collections were used for the training and evaluation of the semantic segmentation model. For each dataset collection, the predicted building extraction results with the highest object-based accuracy were used for further integration and post-processing, which is described in the following section.
3.3. Integration and Post-Processing of Results
After training and evaluating the semantic segmentation model based on each of the 4 dataset collections, we obtained 4 groups of probability maps (each with a size of 256 × 256 pixels) for each validation sample. The value of each pixel in the probability map indicates the predicted probability that the pixel belongs to the building area. For each validation sample, the 4 groups of probability maps were obtained from (1) the satellite image with a rescaling strategy, (2) the satellite image with a slicing strategy, (3) the satellite + map image with a rescaling strategy, and (4) the satellite + map image with a slicing strategy, respectively. For the first and third groups, we rescaled the single probability map into the one at the original sample size. For the second and fourth groups, we combined 9 probability maps into a single map corresponding to the complete image. As a result, we obtained 4 probability maps (each with a size of 650 × 650 pixels) for each validation sample.
We proposed a 2-level integration strategy for integrating the results obtained from each model into the final building footprint extraction results. At the first level, for both the satellite and satellite + map image–based dataset collections, we averaged the pixel values of 2 probability maps (obtained from 2 preprocessing methods) into an integrated probability map. At the second level, the 2 integrated probability maps (obtained from the 2 dataset collections) were further averaged into the final building probability map.
After obtaining the integrated building probability map, we applied 2 post-processing strategies to optimize the final predicted results. In the first strategy, we adjusted the threshold of the probability (indicating whether a pixel belongs to a building area or a nonbuilding area) from 0.45 to 0.55 for each city. The optimized probability threshold was then used for vectorizing the probability map into the binary building extraction image result. In the second strategy, in order to filter out potential noise in the building extraction image results, we adjusted the threshold of the polygon size (indicating the minimal possible size of a building polygon) from 90 to 240 pixels for each city. The optimized thresholds of probability and polygon size of the validation dataset were also applied to the test dataset for each city.
3.4. Evaluation Metric
The building extraction results can be evaluated by several methods including the pixel-based and object-based methods that are the most broadly used in existing building extraction studies [
7,
63]. In the pixel-based evaluation method (used in References [
9,
10,
12]), the binary building extraction image result (predicted from the semantic segmentation network) is directly compared with the binary ground truth image. In the object-based evaluation method (often used in building edge or footprint detection studies, such as in Reference [
32]), the building extraction image result needs to be converted into the predicted building polygons for comparison with the ground truth building polygons. The DeepGlobe challenge selected the object-based method to evaluate the building footprint extraction results. Compared with the pixel-based method, the object-based method emphasizes not only the importance of accurate detection of building areas, but also the complete identification of building outlines.
In the DeepGlobe challenge, the ground truth dataset for evaluating building extraction results contained the spatial coordinates of the vertices corresponding to each annotated building footprint polygon. Thus, we needed to convert the single-band building extraction image results (the output of the semantic segmentation network) into a list of building polygons (in the same format as the ground truth dataset). Formula (2) shows the definition of the IoU (intersection over union) for evaluating whether a detected building polygon is accurate, which is equal to the intersection area of a detected building polygon (denoted by A) and a ground truth building polygon (denoted by B) divided by the union area of A and B. If a detected building polygon intersects with more than one ground truth building polygon, then the ground truth building with the highest IoU value will be selected.
The precision, recall, and F1-score were calculated according to Formulas (3)–(5), where true positive (TP) indicates the number of building polygons that are detected correctly, false positive (FP) indicates the number of other objects that are detected as building polygons by mistake, and false negative (FN) indicates the number of building polygons not detected. A building polygon will be scored as correctly detected if the IoU between the detected building polygon and a ground truth building polygon is larger than 0.5. The results of each city were evaluated independently and the final F1-score is the average value of F1-scores for each city.
6. Conclusions
In this study, we proposed a U-Net–based semantic segmentation method for building footprint extraction from high-resolution satellite images using the SpaceNet building dataset provided in the DeepGlobe Challenge. Multisource GIS map datasets (OpenStreetMap, Google Maps, and MapWorld) are explored to improve the building extraction results in four cities (Las Vegas, Paris, Shanghai, and Khartoum). In our proposed method, we designed a data fusion and augmentation method for integrating multispectral WorldView-3 satellite images with selected GIS map datasets. We trained and evaluated four U-Net–based semantic segmentation models based on augmented and integrated dataset collections. Lastly, we integrated the results obtained from the semantic segmentation models and employed a post-processing method to further improve the building extraction results.
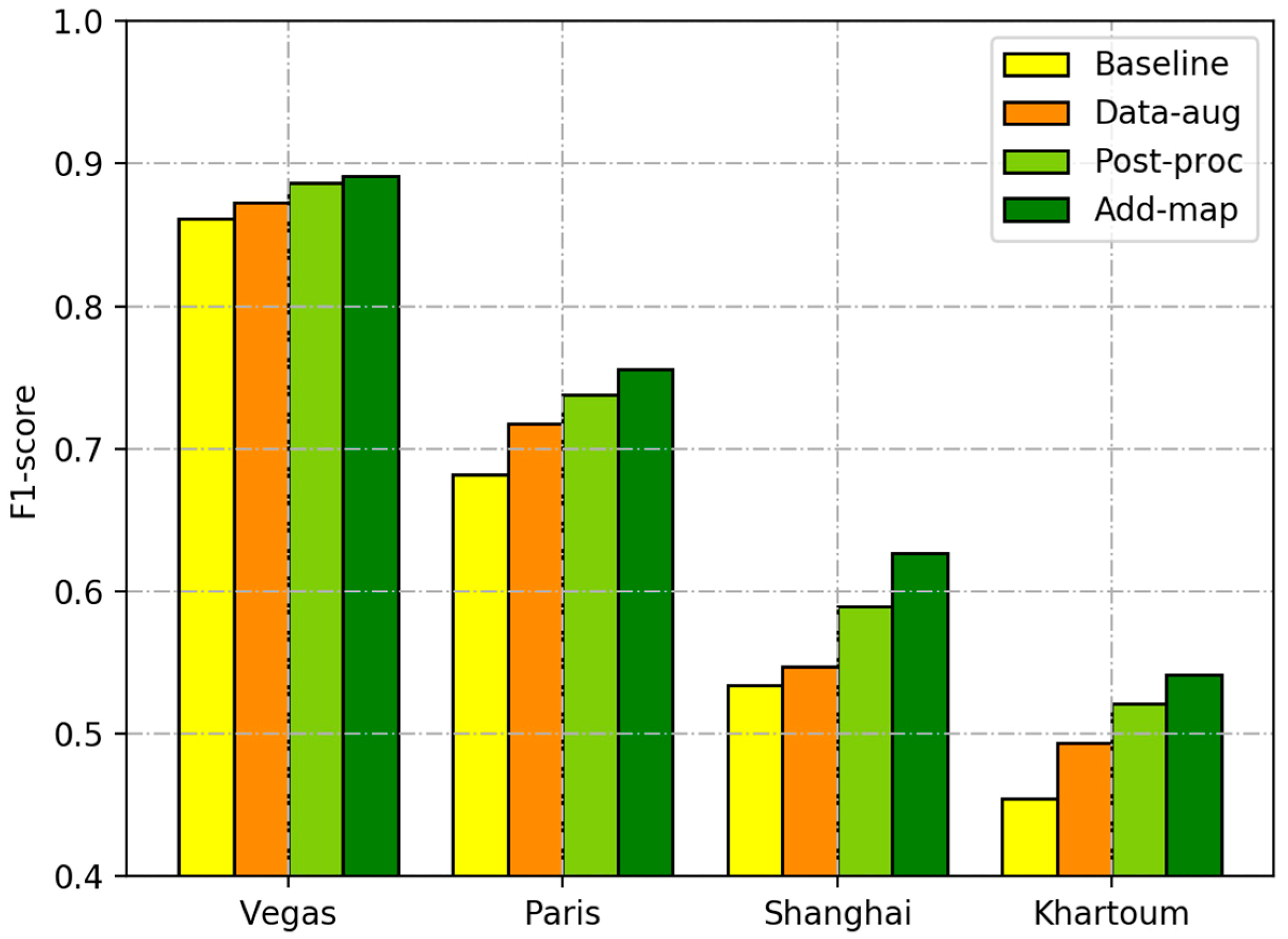
The experimental results show that our proposed method improves the total F1-score by 1.1%, 6.1%, and 12.5% when compared with the top three solutions in the SpaceNet Building Detection Competition. The F1-scores of Las Vegas, Paris, Shanghai, and Khartoum are 0.8911, 0.7555, 0.6266, and 0.5415, respectively. The significant difference in the results is due to many possible aspects, including the consistency or the diversity of buildings in a city (e.g., construction area, building height, and architectural style), the similarity between buildings and background, and the number of training samples. We also analyze the effects of proposed strategies on the building extraction results. Our proposed strategies improved the F1-score by 3.01% to 9.24% for the four cities compared with those obtained from the baseline method, which achieved precise building outlines and less confusion between tiny buildings and noise. The data augmentation strategy improves the F1-scores greatly for Paris and Khartoum, with fewer training samples, and slightly for Las Vegas and Shanghai, with more training samples. The post-processing strategy brings more improvement for Shanghai and Khartoum, with lower initial F1-scores, than for Las Vegas and Paris, with higher initial F1-scores. The strategy of integrating satellite and GIS data brings the most improvement for Shanghai, with a low initial F1-score and substantial building information in GIS map data. In our future research, we will try to combine the semantic segmentation model with other image processing algorithms (e.g., traditional image segmentation and edge detection algorithms) to further improve the extraction of building outlines. We will also explore different data fusion strategies for combining satellite images and GIS data, and other state-of-the-art semantic segmentation models for building footprint extraction using the SpaceNet building dataset.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}