Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images




Abstract
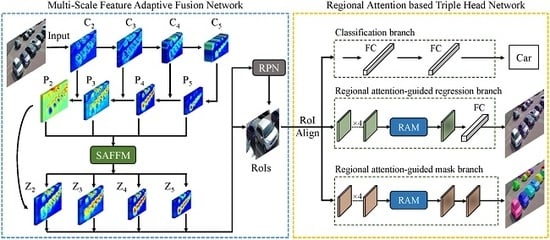
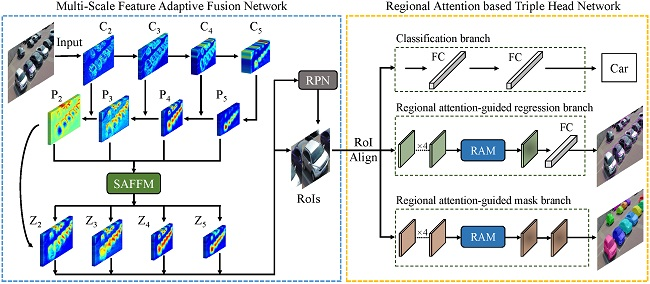
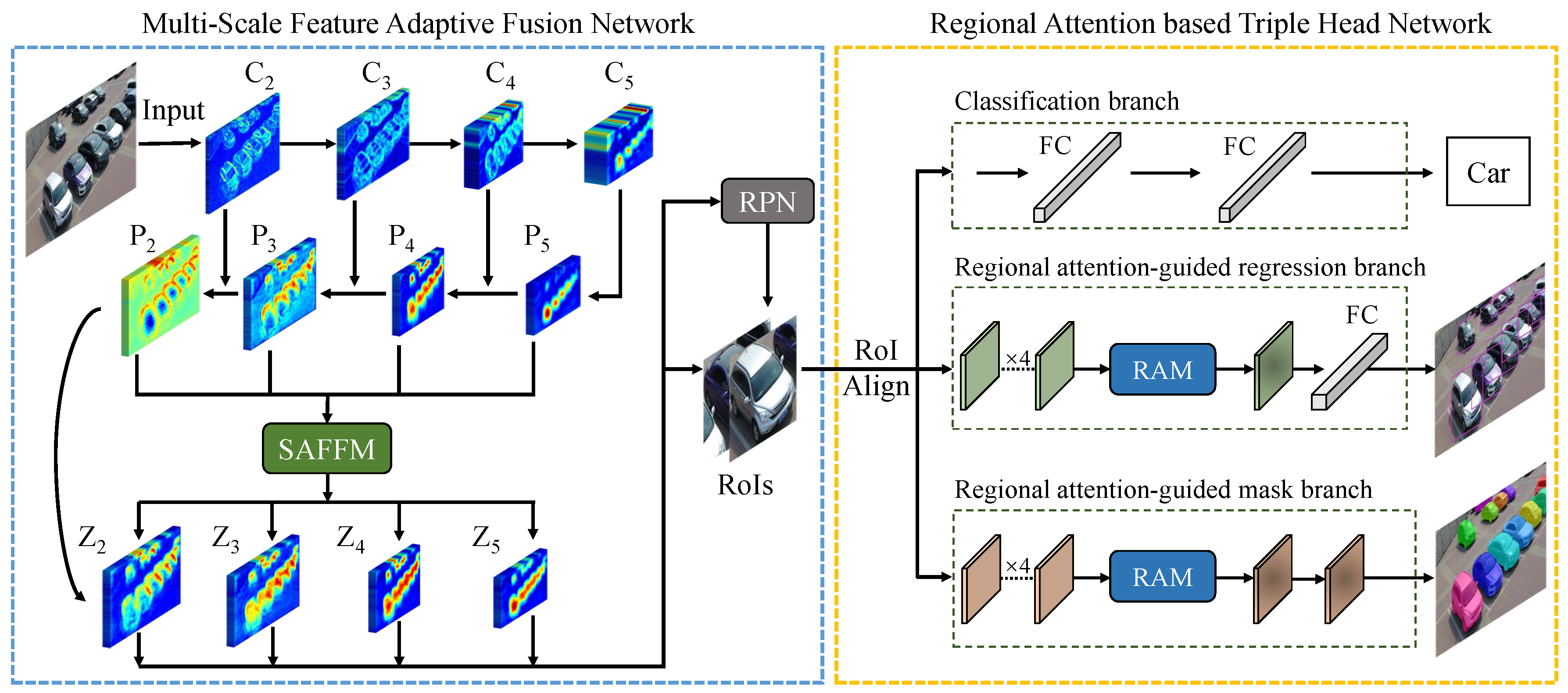
:
1. Introduction
- Arbitrary orientations: Vehicles in images captured by UAV often appear with arbitrary orientations due to the viewpoint change and height change.
- Huge scale variations: With a wide range of cruising altitudes of UAV, the scale of captured vehicles changes greatly.
- Partial occlusion: With similar structure and colors in some scenarios, it is hard to separate vehicles that are crowded or partial occluded with each other.
- The innovative MSOA-Net segmentation structure is proposed for addressing the special problems for UAV based vehicle detection and segmentation.
- The multi-scale feature adaptive fusion network is proposed to adaptively integrate the low-level location information and high-level semantic information to better deal with scale change.
- The regional attention based triple head network is proposed to better focus on the region of interest, reducing the influence of occlusions.
- The new large comprehensive dataset called UVSD is released, which is the first public detection and segmentation dataset for UAV-captured vehicles.
2. Related Work
2.1. Generic Object Instance Segmentation
2.2. UAV-Based Datasets
3. Dataset Description
3.1. Dataset Properties
- The proposed dataset is extremely challenging. The vehicle instances in UVSD have the characteristics of viewpoint changes, huge scale variations, partial occlusion, densely distribution, illumination variations, etc.
- There are many images with dense vehicles (more than 150 vehicles per image) in UVSD. Therefore, the UVSD also can be used for other vision-based tasks, e.g., vehicle counting.
- In addition to visual data and pixel-level instance annotations, UVSD includes other format annotations (i.e., pixel-level semantic, OBB and HBB annotations). UVSD also can be used for semantic segmentation task, HBB and OBB based vehicle detection tasks.
3.2. Dataset Collection
3.3. Annotation Principles
- All clearly visible vehicles that appear in an image need to be labeled using the same software.
- If the truncation rate of a vehicle exceeds 80%, this vehicle does not need to be labeled and tested.
- If a vehicle partly appears in an image, we label the mask inside the image and estimate the truncation ratio based on the region inside the image.
- Images should be zoomed in, when necessary, to obtain annotations with refined boundaries.
- For each vehicle, we use as many mark points as possible to get the fine edges of the vehicle.
- Each picture after annotation needs to be reviewed twice by different members of the verification team.
- In order to protect the privacy of residents, the privacy areas such as human faces are blurred, and all image metadata, including device information and GPS locations, are removed.
4. Proposed Method
4.1. Multi-Scale Feature Adaptive Fusion Network
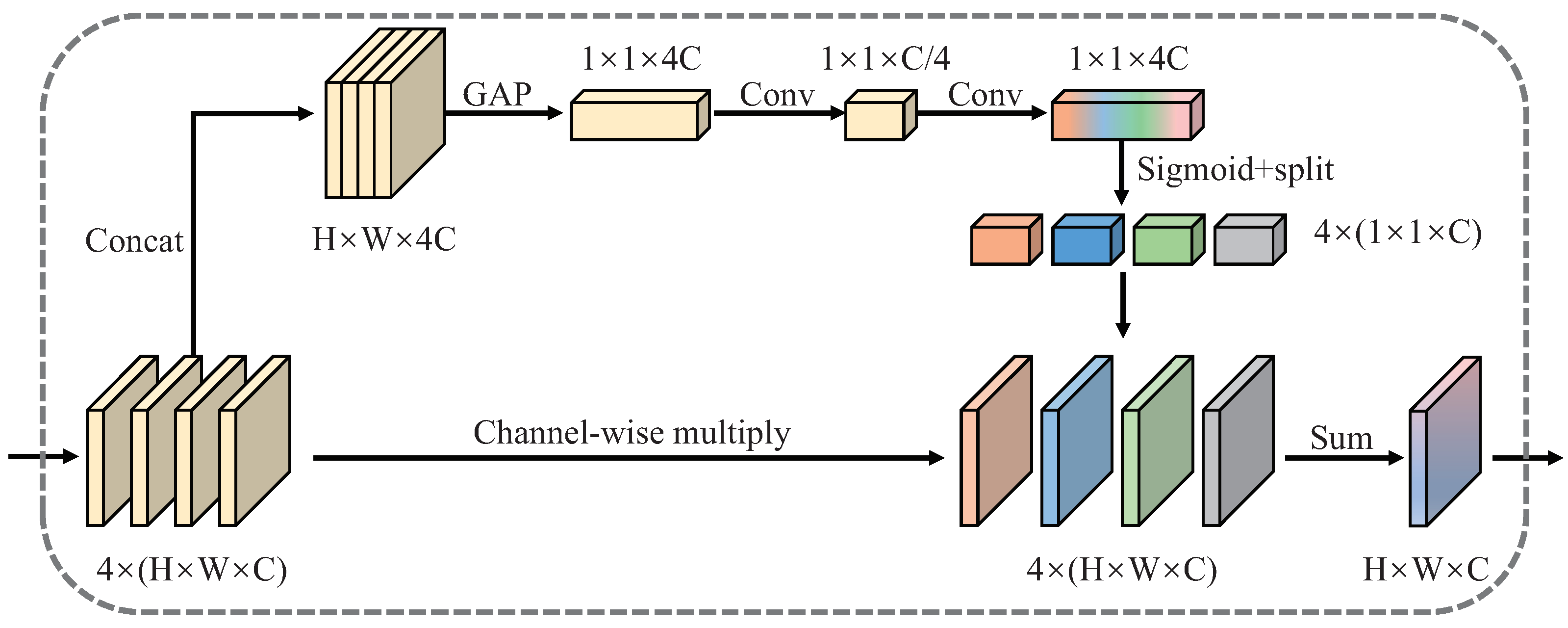
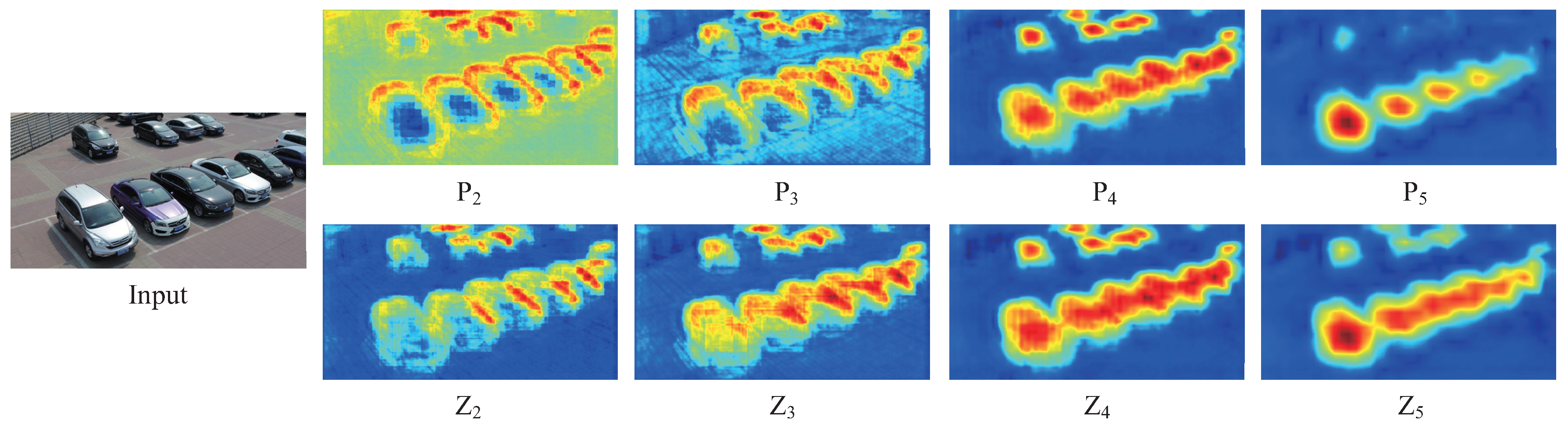
4.1.1. Self-Adaptive Feature Fusion Module
4.1.2. Region Proposal Network
4.2. Regional Attention Based Triple Head Network
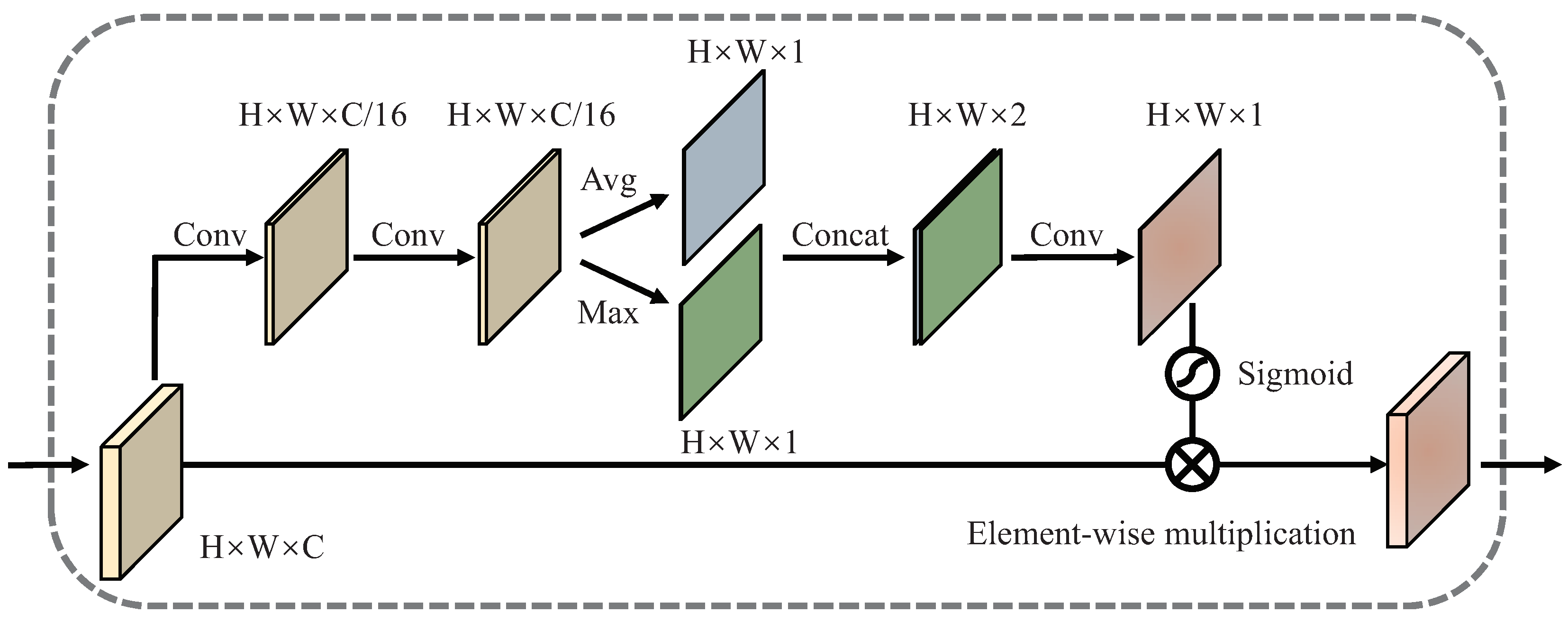
4.2.1. Regional Attention Module
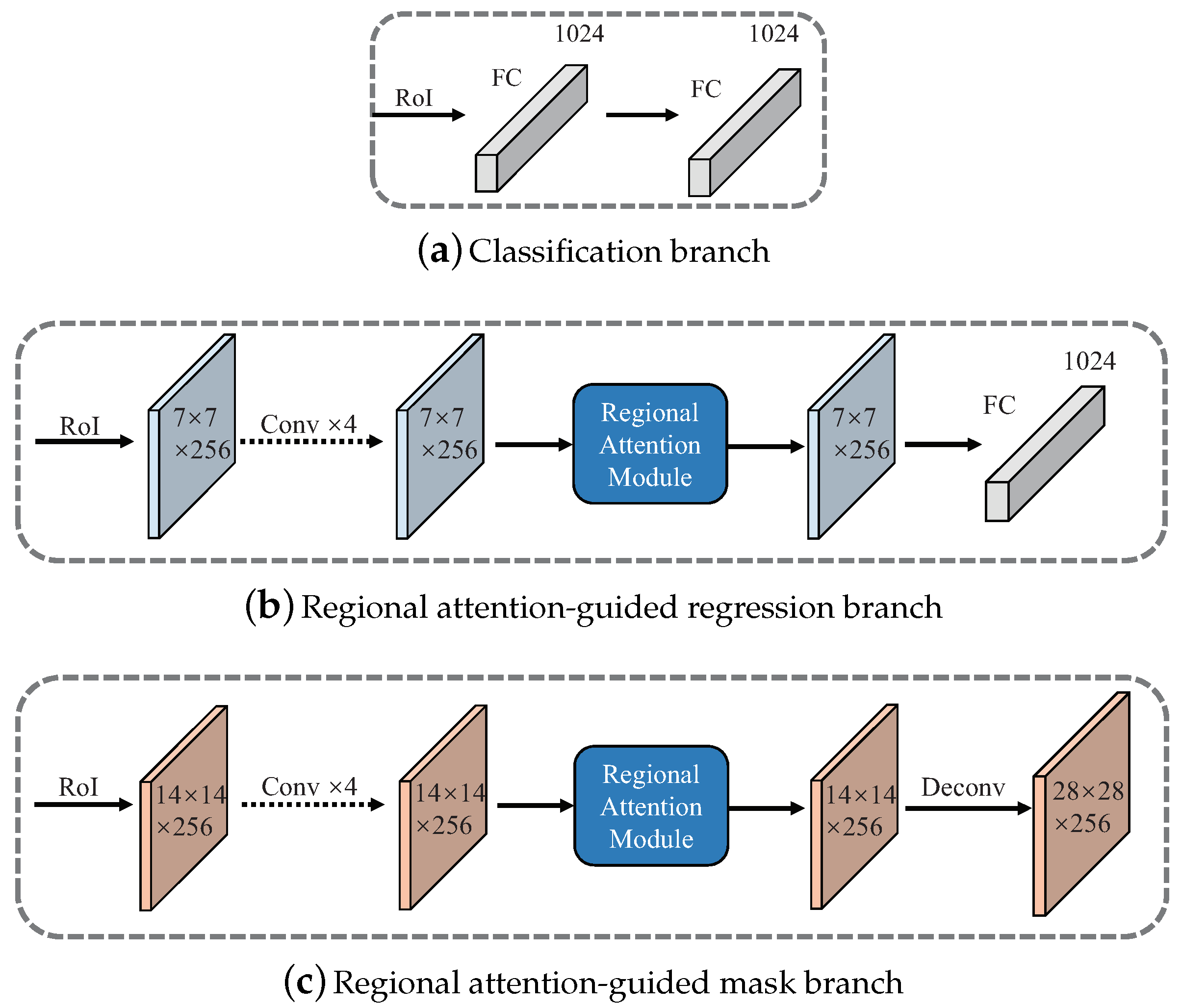
4.2.2. Classification Branch
4.2.3. Regional Attention-Guided Regression Branch
4.2.4. Regional Attention-Guided Mask Branch
5. Experiments
5.1. Dataset and Evaluation Metrics
5.2. Experimental Setup
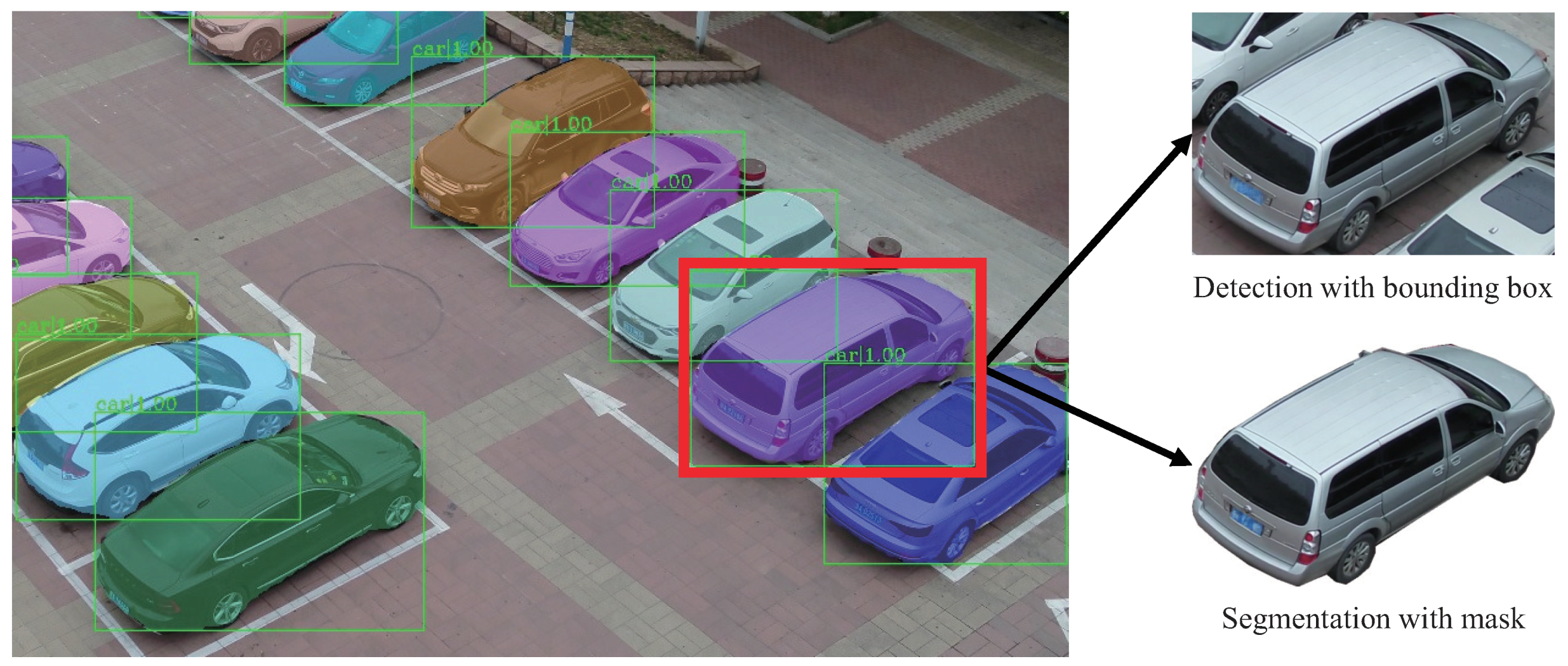
5.3. Evaluation of Our Segmentation Task
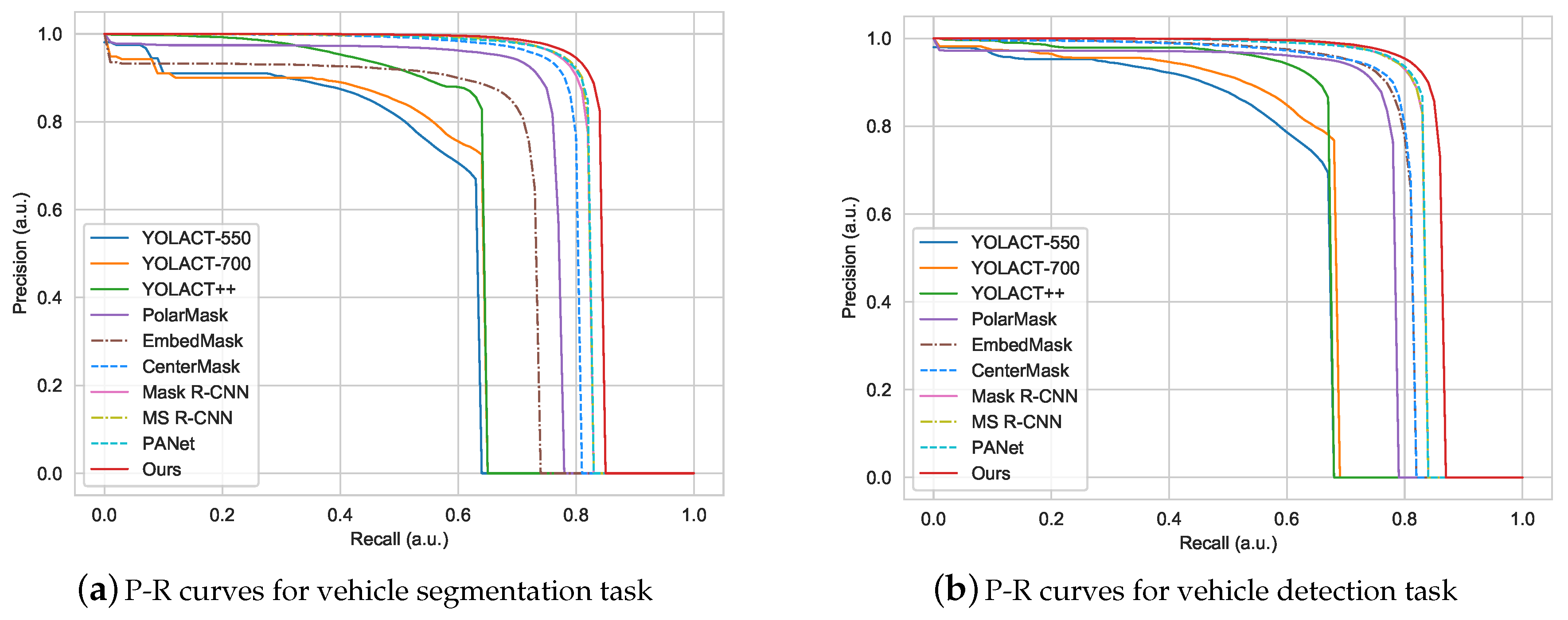
5.4. Comparison with State-of-the-Art Methods
6. Discussion
6.1. Ablation Study
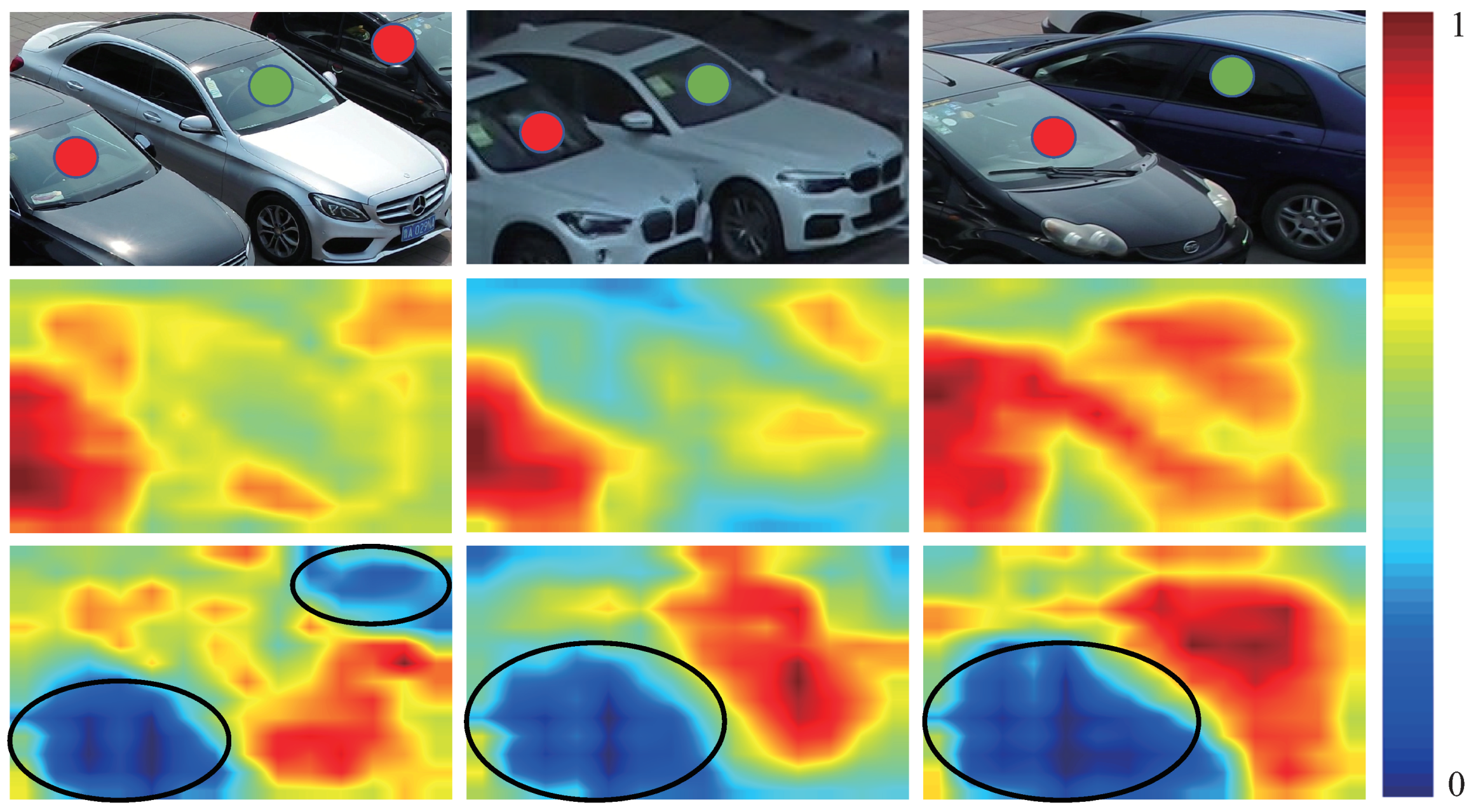
6.2. Failure Cases
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kanistras, K.; Martins, G.; Rutherford, M.J.; Valavanis, K.P. A survey of unmanned aerial vehicles (UAVs) for traffic monitoring. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 28–31 May 2013; pp. 221–234. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2015; pp. 91–99. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7363–7372. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In Defense of Two-Stage Object Detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Wang, P.; Jiao, B.; Yang, L.; Yang, Y.; Zhang, S.; Wei, W.; Zhang, Y. Vehicle Re-Identification in Aerial Imagery: Dataset and Approach. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 460–469. [Google Scholar]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Liang, T.; Wang, Y.; Zhao, Q.; Zhang, H.; Tang, Z.; Ling, H. MFPN: A Novel Mixture Feature Pyramid Network of Multiple Architectures for Object Detection. arXiv 2019, arXiv:1912.09748. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, C.; Guo, Y.; Li, S.; Chang, F. ACFBased Region Proposal Extraction for YOLOv3 Network Towards High-Performance Cyclist Detection in High Resolution Images. Sensors 2019, 19, 2671. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Chen, X.; Girshick, R.B.; He, K.; Dollár, P. TensorMask: A Foundation for Dense Object Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2061–2069. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-time instance segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations. arXiv 2019, arXiv:1912.04488. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. PolarMask: Single Shot Instance Segmentation with Polar Representation. arXiv 2019, arXiv:1909.13226. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. arXiv 2019, arXiv:1911.06667. [Google Scholar]
- Ying, H.; Huang, Z.; Liu, S.; Shao, T.; Zhou, K. EmbedMask: Embedding Coupling for One-stage Instance Segmentation. arXiv 2019, arXiv:1912.01954. [Google Scholar]
- Miyoshi, G.T.; Arruda, M.S.; Osco, L.P.; Marcato Junior, J.; Gonçalves, D.N.; Imai, N.N.; Tommaselli, A.M.G.; Honkavaara, E.; Gonçalves, W.N. A Novel Deep Learning Method to Identify Single Tree Species in UAV-Based Hyperspectral Images. Remote Sens. 2020, 12, 1294. [Google Scholar] [CrossRef] [Green Version]
- Bozcan, I.; Kayacan, E. AU-AIR: A Multi-modal Unmanned Aerial Vehicle Dataset for Low Altitude Traffic Surveillance. arXiv 2020, arXiv:2001.11737. [Google Scholar]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4145–4153. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 549–565. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 375–391. [Google Scholar]
- Barekatain, M.; Martí, M.; Shih, H.; Murray, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2153–2160. [Google Scholar]
- Li, S.; Yeung, D.Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4140–4146. [Google Scholar]
- DJI Matrice 200. Available online: https://www.dji.com/be/matrice-200-series (accessed on 21 May 2020).
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F. Hybrid Cascade Structure for License Plate Detection in Large Visual Surveillance Scenes. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2122–2135. [Google Scholar] [CrossRef]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Ngan, K.N.; Shi, H. A2RMNet: Adaptively Aspect Ratio Multi-Scale Network for Object Detection in Remote Sensing Images. Remote Sens. 2019, 11, 1594. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–15 December 2015; pp. 1440–1448. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT++: Better Real-time Instance Segmentation. arXiv 2019, arXiv:1912.06218. [Google Scholar]
- Milz, S.; Rüdiger, T.; Süss, S. Aerial GANeration: Towards Realistic Data Augmentation Using Conditional GANs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 59–72. [Google Scholar]
- Hong, S.; Kang, S.; Cho, D. Patch-Level Augmentation for Object Detection in Aerial Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 127–134. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Fu, K.; Chen, Z.; Zhang, Y.; Sun, X. Enhanced Feature Representation in Detection for Optical Remote Sensing Images. Remote Sens. 2019, 11, 2095. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|
| Ours (detection) | 24.7 | 82.4 | 4.9 | 16.8 | 26.0 | 26.7 |
| Ours (segmentation) | 77.0 | 91.5 | 83.3 | 32.8 | 65.4 | 93.1 |
| Method | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLACT-550 [23] | 50.3 | 74.6 | 55.1 | 5.3 | 38.3 | 69.7 | 53.4 | 81.1 | 61.0 | 14.4 | 43.9 | 68.8 |
| YOLACT-700 [23] | 51.5 | 73.4 | 56.4 | 6.1 | 41.5 | 69.8 | 55.3 | 78.6 | 63.5 | 14.9 | 45.8 | 71.3 |
| YOLACT++ [47] | 55.7 | 72.2 | 61.6 | 2.1 | 37.5 | 78.0 | 55.5 | 74.8 | 65.5 | 5.0 | 43.4 | 74.8 |
| EmbedMask [27] | 62.0 | 88.1 | 66.9 | 20.0 | 54.3 | 76.6 | 72.3 | 92.1 | 79.0 | 29.2 | 61.7 | 88.6 |
| PolarMask [25] | 64.8 | 87.5 | 74.1 | 15.0 | 55.2 | 83.8 | 67.7 | 89.2 | 75.1 | 20.4 | 57.2 | 86.7 |
| CenterMask [26] | 72.7 | 88.1 | 78.9 | 23.3 | 59.5 | 91.8 | 71.7 | 88.9 | 79.1 | 27.4 | 60.6 | 88.6 |
| Mask R-CNN [19] | 74.3 | 90.4 | 81.2 | 28.7 | 62.8 | 90.9 | 74.7 | 91.4 | 82.2 | 33.4 | 64.5 | 89.5 |
| MS R-CNN [21] | 74.4 | 90.2 | 81.2 | 28.9 | 63.0 | 90.5 | 74.9 | 91.4 | 82.3 | 33.9 | 64.5 | 89.8 |
| PANet [17] | 74.7 | 90.5 | 81.2 | 30.2 | 61.5 | 91.8 | 75.0 | 90.6 | 82.3 | 35.6 | 63.5 | 90.3 |
| Ours | 77.0 | 91.5 | 83.3 | 32.8 | 65.4 | 93.1 | 78.2 | 92.3 | 85.1 | 38.6 | 68.0 | 92.5 |
| Baseline | MSFAF-Net | TH-Net | RAM | AP | AP | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 74.3 | 28.7 | 62.8 | 90.9 | 74.7 | 33.4 | 64.5 | 89.5 | |||
| ✓ | ✓ | 74.8 | 29.7 | 63.1 | 91.4 | 75.3 | 35.0 | 64.7 | 90.3 | ||
| ✓ | ✓ | ✓ | 76.2 | 31.8 | 64.6 | 92.7 | 77.1 | 37.5 | 66.8 | 92.2 | |
| ✓ | ✓ | ✓ | ✓ | 77.0 | 32.8 | 65.4 | 93.1 | 78.2 | 38.6 | 68.0 | 92.5 |
| Method | AP | AP | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|
| FPN [16] | 74.3 | 28.7 | 62.8 | 90.9 | 74.7 | 33.4 | 64.5 | 89.5 |
| PAFPN [17] | 74.5 | 29.3 | 63.2 | 91.0 | 74.8 | 34.1 | 64.5 | 89.7 |
| MSFAF-Net | 74.8 | 29.7 | 63.1 | 91.4 | 75.3 | 35.0 | 64.7 | 90.3 |
| Ratios of Weighted Parameters | AP | AP |
|---|---|---|
| : : = 2 : 2 : 1 | 75.5 | 77.0 |
| : : = 1 : 2 : 2 | 75.9 | 76.9 |
| : : = 1 : 1 : 1 | 76.0 | 77.0 |
| : : = 1 : 1 : 2 | 76.2 | 77.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Liu, C.; Chang, F.; Song, Y. Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images. Remote Sens. 2020, 12, 1760. https://doi.org/10.3390/rs12111760
Zhang W, Liu C, Chang F, Song Y. Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images. Remote Sensing. 2020; 12(11):1760. https://doi.org/10.3390/rs12111760
Chicago/Turabian StyleZhang, Wang, Chunsheng Liu, Faliang Chang, and Ye Song. 2020. "Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images" Remote Sensing 12, no. 11: 1760. https://doi.org/10.3390/rs12111760
APA StyleZhang, W., Liu, C., Chang, F., & Song, Y. (2020). Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images. Remote Sensing, 12(11), 1760. https://doi.org/10.3390/rs12111760