An Effective Lunar Crater Recognition Algorithm Based on Convolutional Neural Network

Abstract
:
1. Introduction
2. Materials and Methods
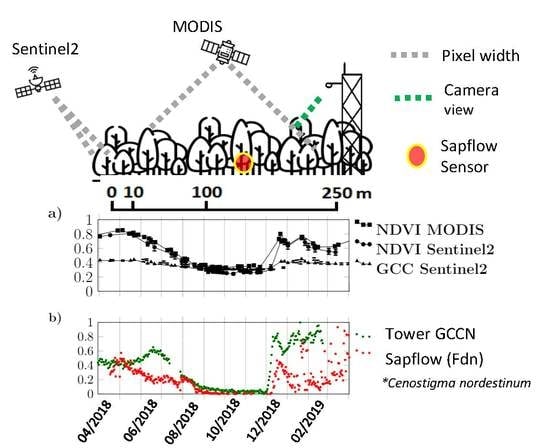
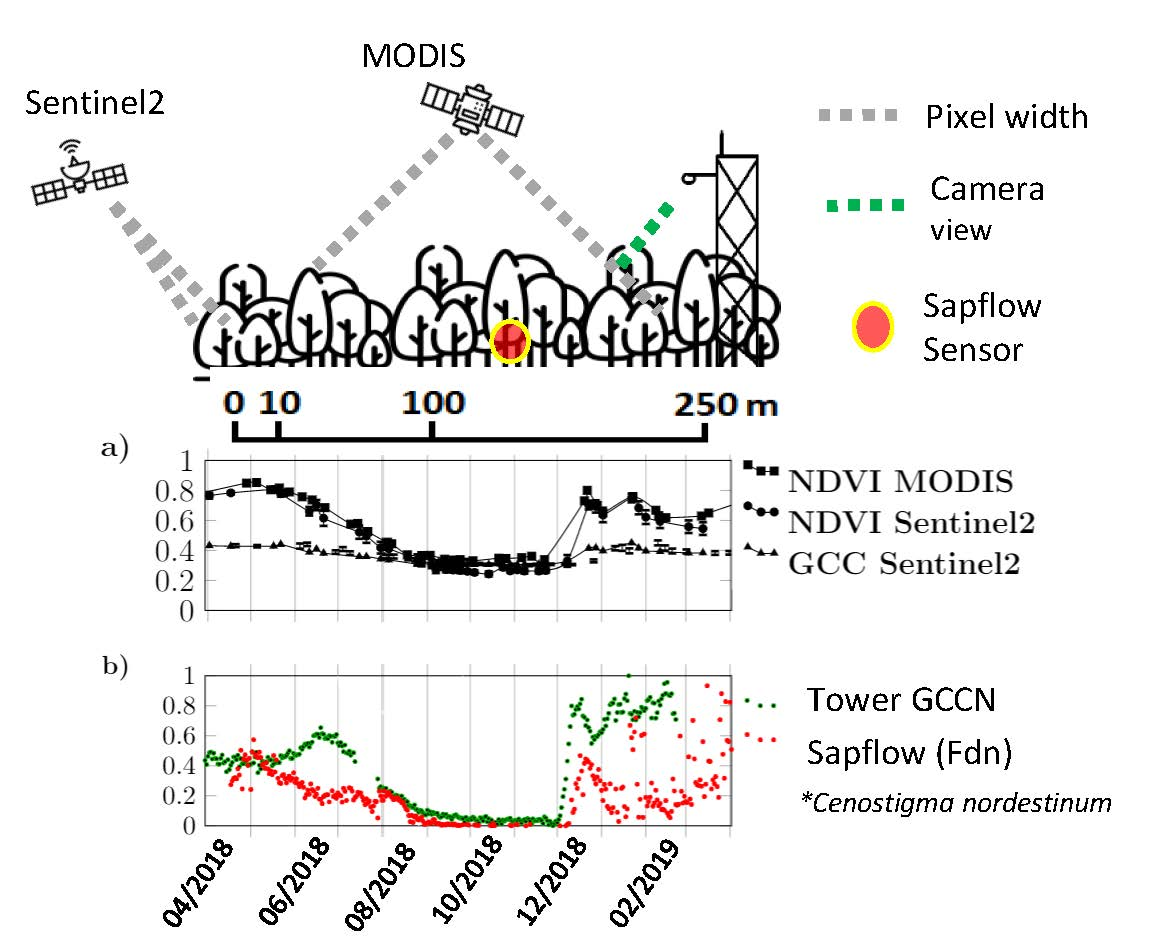
2.1. Experimental Data
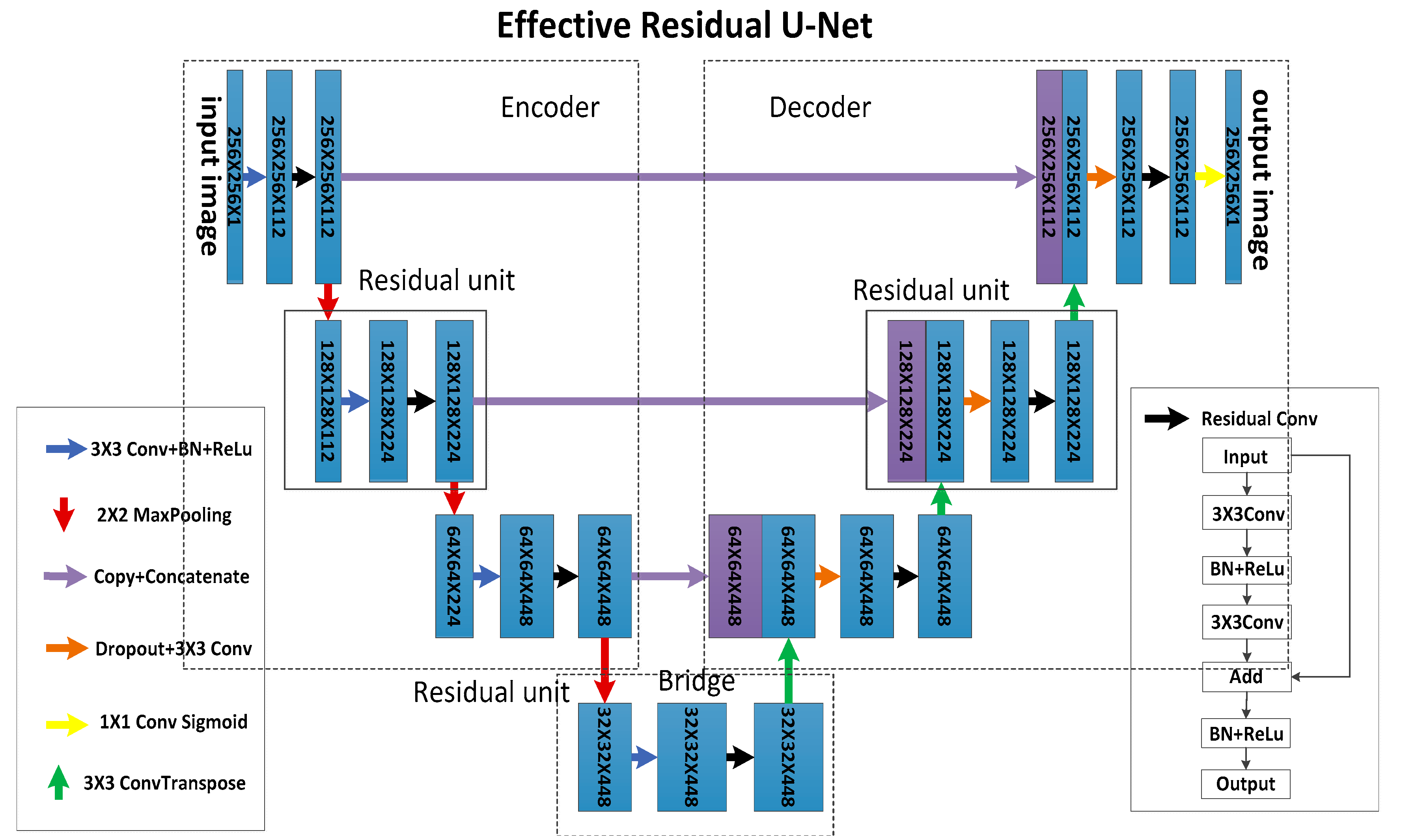
2.2. Network Architecture
2.3. Loss Computation
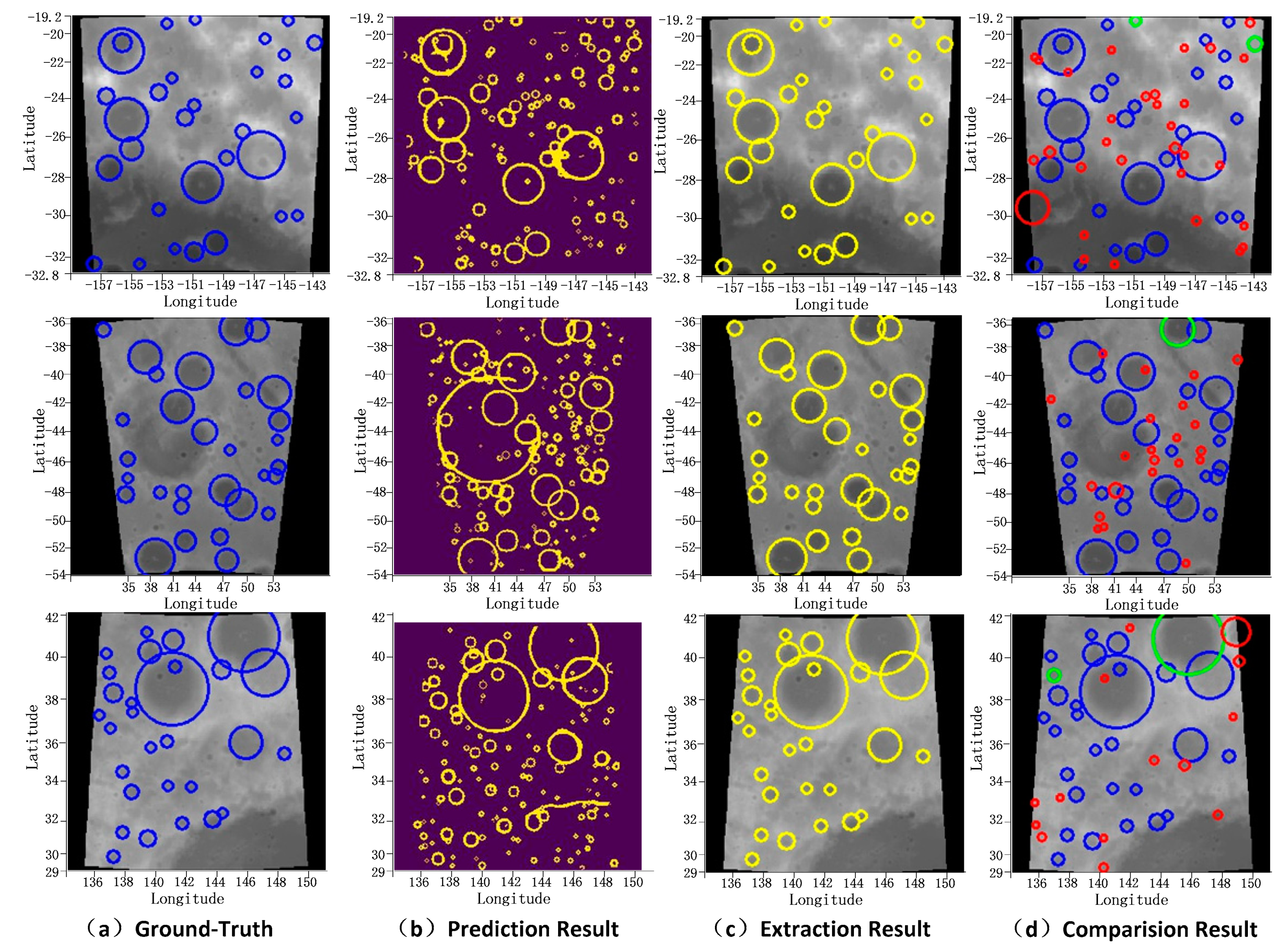
2.4. Crater Extraction
2.5. Evaluation Method
3. Results
3.1. Training
3.2. Experimental Results
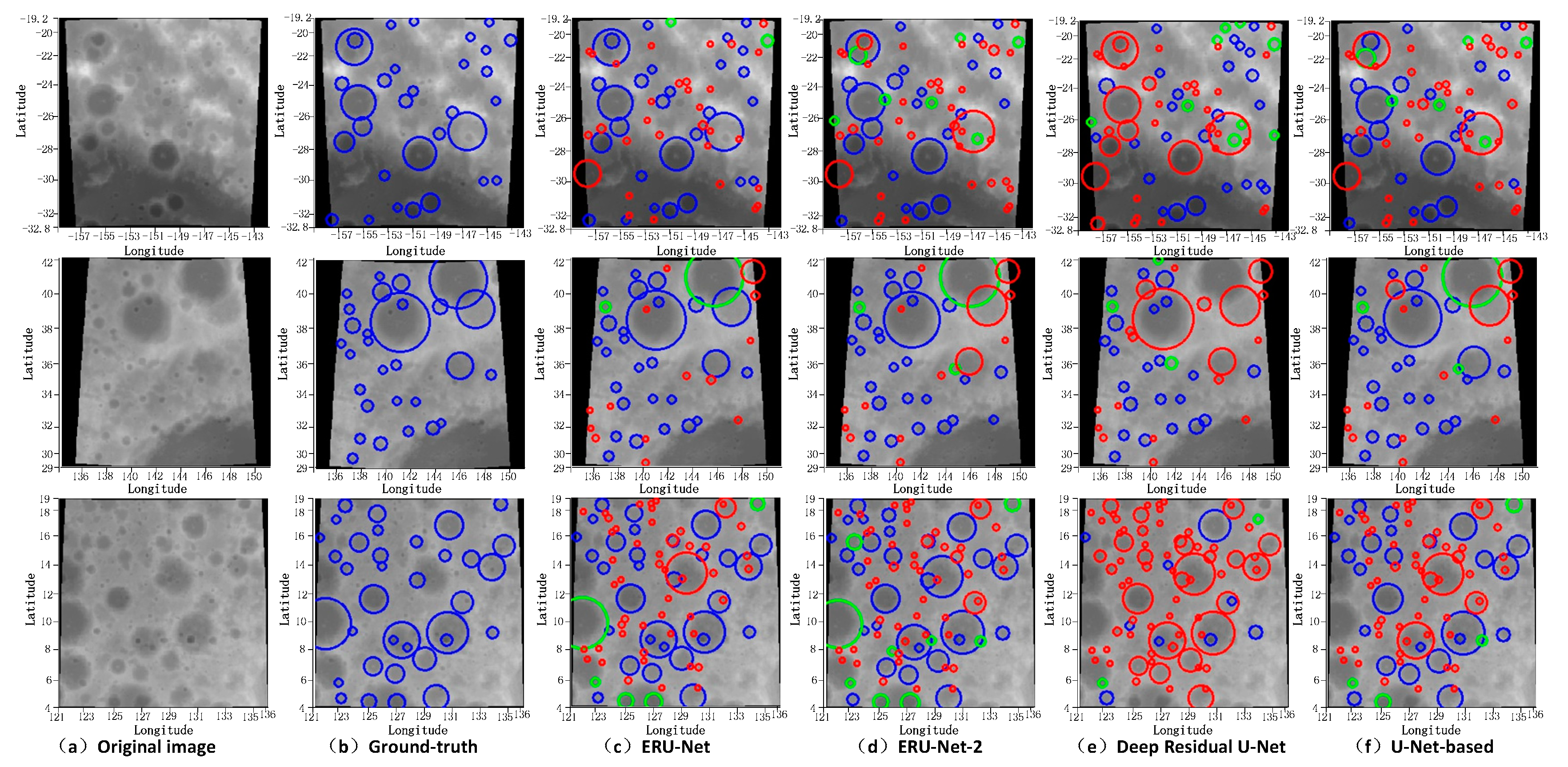
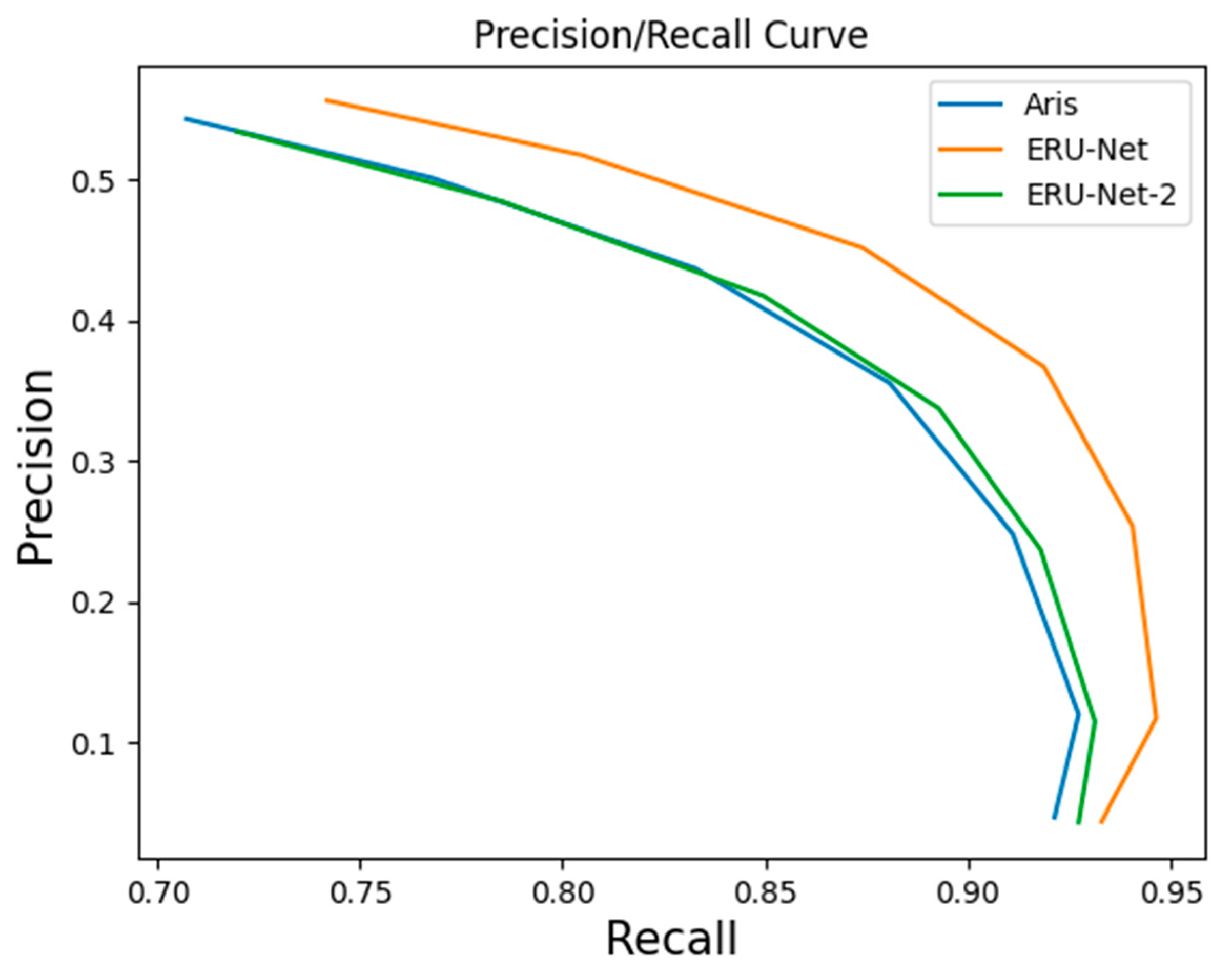
3.2.1. Performance Comparison of Networks
3.2.2. Fewer Train Data
3.2.3. Deepening Network Structure
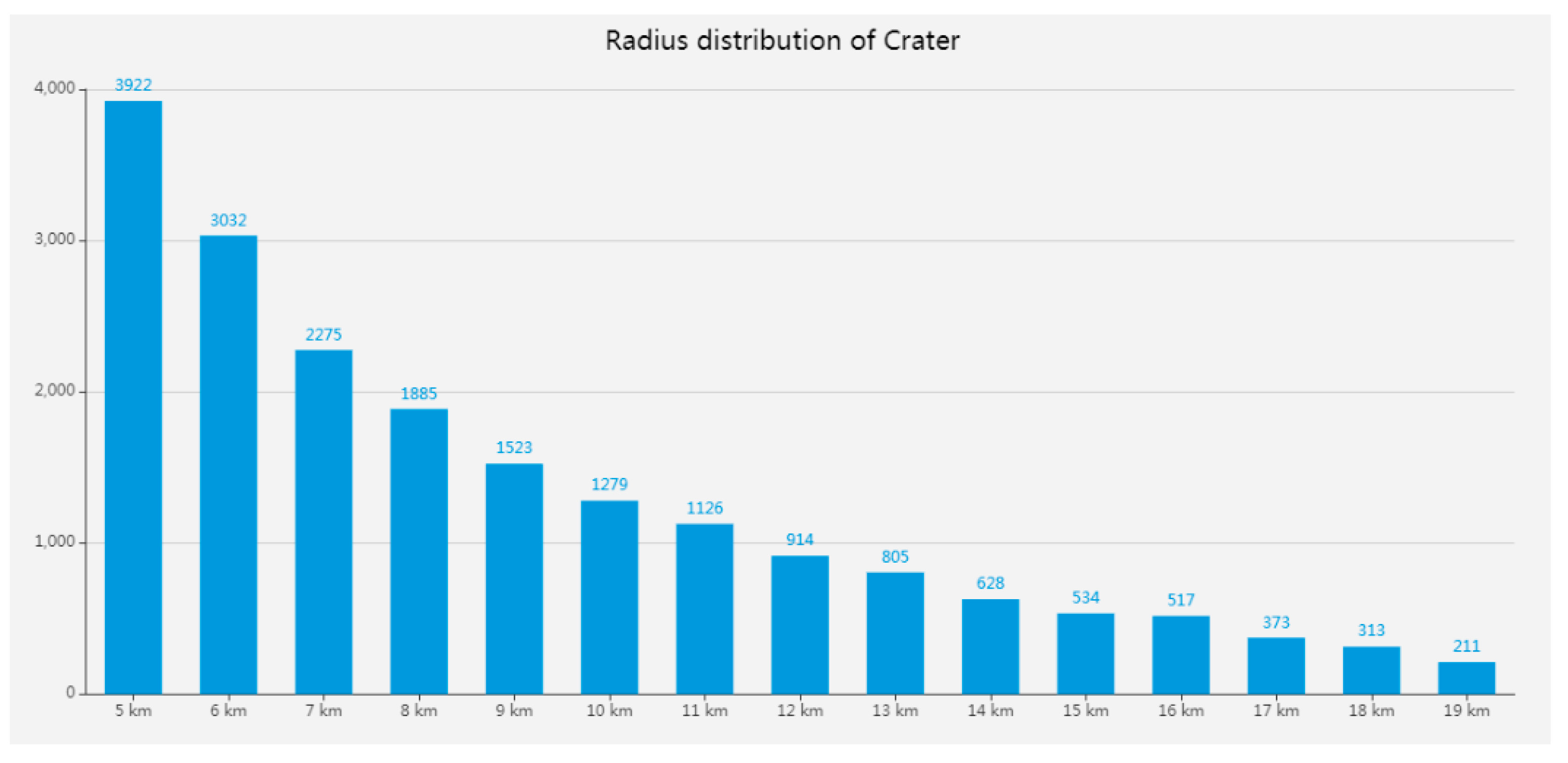
3.2.4. Crater Distribution
3.2.5. Best Model of Our ERU-Net
4. Discussion
4.1. Discussion: Experiment Result
4.2. Discussion: Image Segment
4.3. Discussion: Crater Extraction
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Moon LRO LOLA DEM 118m v1

Appendix B
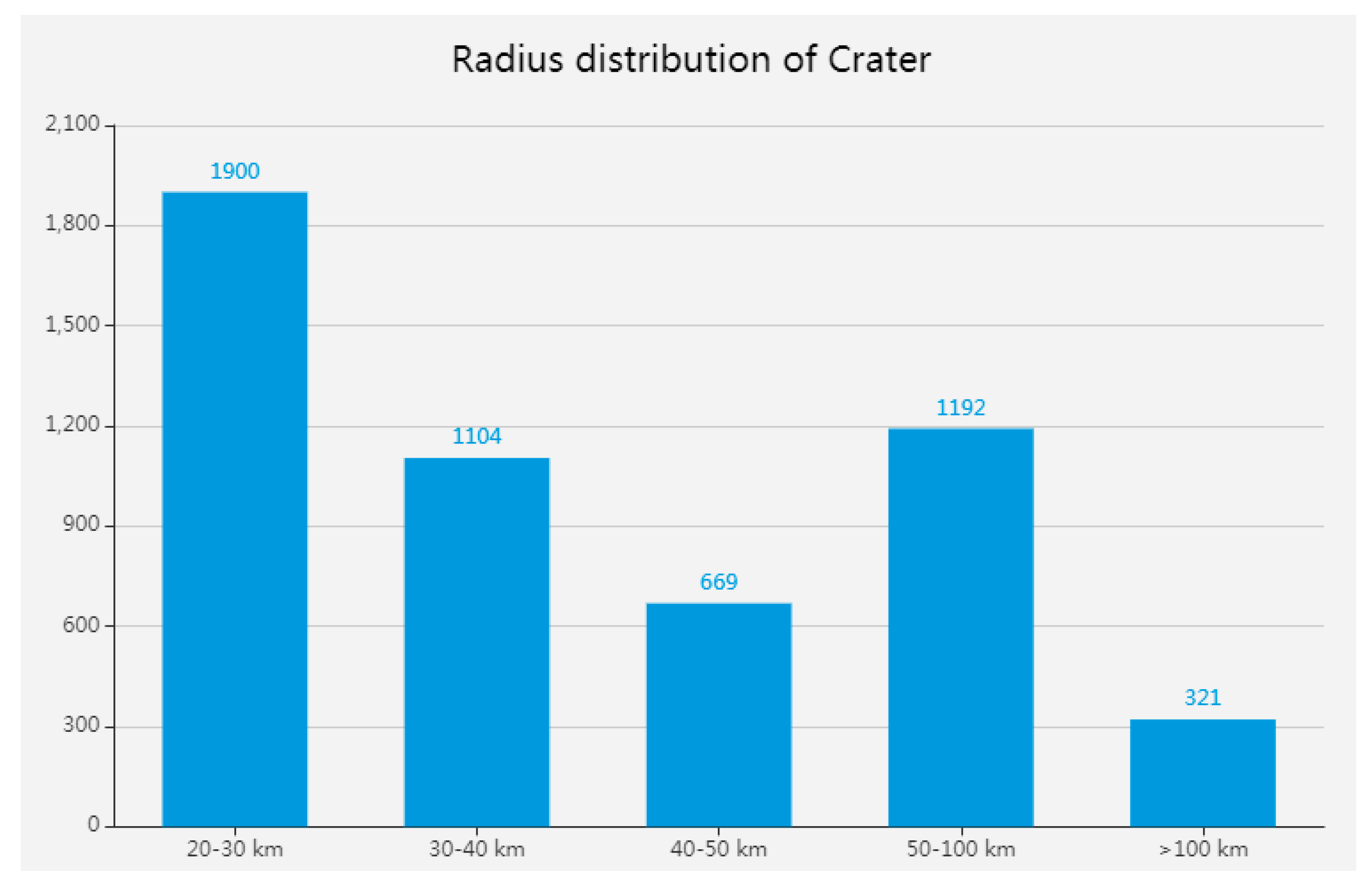
Crater Statistics


References
- He, S.; Chen, J.; Li, K. The Morphological classification and distribution characteristics of craters in the LQ-4Area. Earth Sci. Front. 2012, 19, 83–89. [Google Scholar]
- Robbins, S.J.; Antonenko, I.; Kirchoff, M.R.; Chapman, C.R.; Fassett, C.I.; Herrick, R.R.; Singer, K.; Zanetti, M.; Lehan, C.; Huang, D.; et al. The variability of crater identification among expert and community crater analysts. Icarus 2014, 234, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Muller, J.; Van Gasselt, S.; Morley, J.; Neukum, G. Automated crater recognition, a new tool for mars cartography and chronology. Photogramm. Eng. Remote Sens. 2005, 71, 1205–1217. [Google Scholar] [CrossRef] [Green Version]
- Salamuniccar, G.; Loncaric, S. Method for crater recognition from martian digital topography data using gradient value/orientation, morphometry, vote analysis, slip tuning, and calibration. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2317–2329. [Google Scholar] [CrossRef]
- Ding, W.; Stepinski, T.F.; Mu, Y.; Bandeira, L.; Ricardo, R.; Wu, Y.; Lu, Z.; Cao, T.; Wu, X. Subkilometer crater discovery with boosting and transfer learning. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yang, G.; Guo, L. A novel sparse boosting method for crater recognition in the high resolution planetary image. Adv. Space Res. 2015, 56, 982–991. [Google Scholar] [CrossRef]
- Galloway, M.J.; Benedix, G.K.; Bland, P.A.; Paxman, J.; Towner, M.C.; Tan, T. Automated crater recognition and counting using the hough transform. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 1579–1583. [Google Scholar]
- Kang, Z.; Luo, Z.; Hu, T.; Gamba, P. Automatic extraction and identification of lunar impact craters based on optical data and dems acquired by the Chang’E satellites. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4751–4761. [Google Scholar] [CrossRef]
- Vamshi, G.T.; Martha, T.R.; Vinod Kumar, K. An object-based classification method for automatic detection of lunar impact craters from topographic data. Adv. Space Res. 2016, 57, 1978–1988. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhao, H.; Chen, M.; Tu, J.; Yan, L. Automatic detection of lunar craters based on DEM data with the terrain analysis method. Planet. Space Sci. 2018, 160, 1–11. [Google Scholar] [CrossRef]
- Savage, R.; Palafox, L.F.; Morrison, C.T.; Rodriguez, J.J.; Barnard, K.; Byrne, S.; Hamilton, C.W. A bayesian approach to subkilometer crater shape analysis using individual HiRISE images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5802–5812. [Google Scholar] [CrossRef]
- Chen, M.; Liu, D.; Qian, K.; Li, J.Y.; Lei, M.; Zhou, Y. Lunar crater recognition based on terrain analysis and mathematical morphology methods using digital elevation models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3681–3692. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, H.; Bruzzone, L.; Benediktsson, J.A.; Liang, Y.; Liu, B.; Zeng, X.; Guan, R.; Li, C.; Ouyang, Z. Lunar Impact Craters Identification and Age Estimation with Chang’E Data by Deep and Transfer Learning. 2019. Available online: https://arxiv.org/abs/1912.01240v1 (accessed on 23 July 2020).
- Lemelin, M.; Daly, M.G.; Deliège, A. Analysis of the topographic roughness of the moon using the wavelet leaders method and the lunar digital elevation model from the lunar orbiter laser altimeter and selene terrain camera. J. Geophys. Res. Planets 2020, 125, e2019JE006105. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1, pp. 326–366. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, L.; Wang, G.; et al. Recent advances in convolutional neural networks. arXiv 2015, arXiv:1512.07108. [Google Scholar] [CrossRef] [Green Version]
- Jonathan, L.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object recognition via region-based fully convolutional networks. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Vijay, B.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deepresidual networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhengxin, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar]
- Silburt, A.; Ali-Dib, M.; Zhu, C.; Jackson, A.; Valencia, D.; Kissin, Y.; Tamayo, D.; Menou, K. Lunar crater identification via deep learning. Icarus 2019, 317, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever ISalakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Zheng, Y.Y.; Kong, J.; Jin, X.; Wang, X.; Su, T.; Zuo, M. CropDeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 25 June 2019).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. TensorFlow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the 12th International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; Springer International Publishing: New York, NY, USA, 2016; pp. 234–244. [Google Scholar]
- Head, J.W., 3rd; Fassett, C.I.; Kadish, S.J.; Smith, D.E.; Zuber, M.T.; Neumann, G.A.; Mazarico, E. Global distribution of large lunar craters: Implications for resurfacing and impactor populations. Science 2010, 329, 1504–1507. [Google Scholar] [CrossRef] [PubMed]
- Povilaitis, R.Z.; Robinson, M.S.; van der Bogert, C.H.; Hiesinger, H.; Meyer, H.M.; Ostrach, L.R. Crater density differences: Exploring regional resurfacing, secondary crater populations, and crater saturation equilibrium on the moon. Planet. Space Sci. 2018, 162, 41–51. [Google Scholar] [CrossRef]
- van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-image: Image processing in Python. Peer J. 2014, 2, e453. [Google Scholar] [CrossRef]
- Cyril, G.; Gaussier, E. A probabilistic interpretation of precision, recall and f-score, with implication for evaluation. Int. J. Radiat. Biol. Relat. Stud. Phys. Chem. Med. 2005, 51, 952. [Google Scholar]
- Kaggle. Airbus Ship Detection Challenge: Find Ships on Satellite Images as Quickly as Possible. 2018. Available online: https://www.kaggle.com/c/airbus-ship-detection/overview/evaluation (accessed on 17 April 2020).
- LOLA Team; Kaguya Team. LRO LOLA and Kaguya Terrain Camera DEM Merge 60N60S 512ppd (59m). 2015. Available online: https://astrogeology.usgs.gov/search/map/Moon/LRO/LOLA/Lunar_LRO_LOLA_Global_LDEM_118m_Mar2014 (accessed on 7 March 2019).
- Barker, M.K.; Mazarico, E.; Neumann, G.A.; Zuber, M.T.; Haruyama, J.; Smith, D.E. A new lunar digital elevation model from the Lunar Orbiter Laser Altimeter and SELENE Terrain Camera. Icarus 2015, 273, 346–355. [Google Scholar] [CrossRef] [Green Version]
- UK Met Office. Cartopy: A Cartographic Python Library with a Matplotlib Interface. 2015. Available online: http://scitools.org.uk/cartopy/index.html (accessed on 15 March 2019).
- Kneissl, T.; van Gasselt, S.; Neukum, G. Map-projection-independent crater size-frequency determination in GIS environments—New software tool for ArcGIS. Planet. Space Sci. 2011, 59, 1243–1254. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lichen, Z.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 192–194. [Google Scholar]
- Lin, T.; Doll’ar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Pang, R.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7704. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, J.; Chu, D.; Zhang, L.; Xu, Y.; Yang, J. Sparse Representation classifier steered discriminative projection with applications to face recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1023–1035. [Google Scholar] [CrossRef]
- Grumpe, A.; Wöhler, C. Generative template-based approach to the automated detection of small craters. In Proceedings of the European Planetary Science Congress, London, UK, 8–13 September 2013; Volume 8. [Google Scholar]
- Smith, D.E.; Zuber, M.T.; Neumann, G.A.; Lemoine, F.G.; Torrence, M.H.; McGarry, J.F.; Rowlands, D.D.; Rowlands, D.D.; Head, J.W., III; Duxbury, T.H. Initial observations from the Lunar Orbiter Laser Altimeter (LOLA). Geophys. Res. Lett. 2010, 37. [Google Scholar] [CrossRef]
- Mazarico, E.; Rowlands, D.D.; Neumann, G.A.; Smith, D.E.; Torrence, M.H.; Lemoine, F.G.; Zuber, M.T. Orbit determination of the Lunar Reconnaissance Orbiter. J. Geod. 2012, 86, 193–207. [Google Scholar] [CrossRef]
- Archinal, B.A.; A’Hearn, M.F.; Bowell, E.; Conrad, A.; Consolmagno, G.J.; Courtin, R.; Fukushima, T.; Hestroffer, D.; Hilton, J.L.; Krasinsky, G.A. Report of the IAU Working Group on cartographic coordinates and rotational elements: 2009. Celest. Mech. Dyn. Astron. 2011, 109, 101–135. [Google Scholar] [CrossRef]
- LRO Project and Lunar Geodesy and Cartography Working Group. A Standardized Lunar Coordinate System for the Lunar Reconnaissance Orbiter and Lunar Datasets: LRO Project and LGCWG White Paper. 2008; Volume 5. Available online: http://lunar.gsfc.nasa.gov/library/LunCoordWhitePaper-10-08.pdf (accessed on 20 March 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measures | ERU-Net | ERU-Net-2 | DRU-Net | Aris-CNN | D-LinkNet |
|---|---|---|---|---|---|
| Recall | 81.2% | 80.2% | 76.7% | 76.1% | 68.3% |
| Precision | 75.4% | 77.5% | 77.9% | 83.2% | 77.2% |
| F2-Score | 78.5% | 78.4% | 76.9% | 76.5% | 67.7% |
| DR1 | 18.3% | 17.0% | 22.1% | 13.3% | 17.3% |
| DR2 | 21.5% | 19.3% | 18.3% | 13.7% | 17.1% |
| Lo-err | 9.9% | 9.6% | 7.6% | 9.6% | 10.1% |
| La-err | 10.0% | 9.1% | 7.0% | 9.2% | 10.0% |
| Ra-err | 7.8% | 7.7% | 4.8% | 7.2% | 7.3% |
| Measures | ERU-Net | ERU-Net-2 | Aris-CNN |
|---|---|---|---|
| Recall | 74.5% | 71.5% | 71.2% |
| Precision | 81.0% | 84.3% | 80.2% |
| F2-Score | 74.7% | 73.0% | 71.8% |
| DR1 | 14.7% | 12.4% | 15.2% |
| DR2 | 15.2% | 11.9% | 15.3% |
| Lo-diff | 10.6% | 10.0% | 10.2% |
| La-diff | 9.6% | 9.1% | 10.0% |
| Ra-diff | 7.6% | 7.5% | 7.6% |
| Measures | ERU-Net- 56 | ERU-Net- 56-Deeper | DRU-Net-56 | DRU-Net 56-Deeper | Aris-CNN-56 | Aris-CNN-56-Deeper |
|---|---|---|---|---|---|---|
| Recall | 77.4% | 79.1% | 76.7% | 77.8% | 76.6% | 75.2% |
| Precision | 81.3% | 81.7% | 69.9% | 60.4% | 81.7% | 83.2% |
| F2-Score | 78.1 | 79.6% | 75.2% | 73.6% | 77.6% | 76.6% |
| DR1 | 18.7% | 18.3% | 30.1% | 39.6% | 18.3% | 16.8% |
| DR2 | 15.4% | 15.4% | 25.1% | 34.5% | 14.9% | 13.5% |
| Lo-err | 7.4% | 7.3% | 7.3% | 7.3% | 7.4% | 7.3% |
| La-err | 6.8% | 6.9% | 6.9% | 6.8% | 6.8% | 6.9% |
| Ra-err | 4.9% | 5.0% | 4.8% | 4.9% | 4.9% | 4.9% |
| Measures | ERU-Net | U-Net | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F2-Score | Recall | Precision | F2-Score | |
| High | 66.7% | 94.6% | 70.8% | 62.4% | 93.8% | 66.8% |
| Medium | 82.1% | 83.1% | 82.2% | 79.8% | 79.8% | 79.8% |
| Low | 90.1% | 56.4% | 80.4% | 85.2% | 59.9% | 78.5% |
| Epochs | 15 | 20 | 25 | 30 | |
|---|---|---|---|---|---|
| Measure | |||||
| Loss | 0.06021 | 0.05916 | 0.05789 | 0.05667 | |
| Recall | 82.2% | 83.2% | 83.1% | 82.9% | |
| Precision | 83.1% | 83.6% | 84.8% | 85.3% | |
| F2-Score | 81.5% | 82.5% | 82.6% | 82.6% | |
| DR1 | 13.3% | 12.9% | 12.1% | 11.7% | |
| DR2 | 14.6% | 14.2% | 13.2% | 12.7% | |
| Lo-err | 9.5% | 9.3% | 9.1% | 8.9% | |
| La-err | 9.5% | 9.2% | 8.7% | 8.7% | |
| Ra-err | 7.5% | 7.4% | 7.5% | 7.0% | |
| Epochs | 26 | 27 | 28 | 29 | |
|---|---|---|---|---|---|
| Measure | |||||
| Loss | 0.057456 | 0.056912 | 0.056792 | 0.056800 | |
| Recall | 83.7% | 83.5% | 83.6% | 83.3% | |
| Precision | 84.0% | 84.8% | 84.8% | 85.3% | |
| F2-Score | 82.9% | 83.0% | 83.1% | 82.9% | |
| DR1 | 12.6% | 12.1% | 12.1% | 11.7% | |
| DR2 | 14.1% | 13.2% | 13.2% | 12.7% | |
| Lo-err | 8.9% | 9.1% | 9.0% | 8.8% | |
| La-err | 9.1% | 8.9% | 8.6% | 8.3% | |
| Ra-err | 7.4% | 7.1% | 7.2% | 7.3% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Fan, Z.; Li, Z.; Zhang, H.; Wei, C. An Effective Lunar Crater Recognition Algorithm Based on Convolutional Neural Network. Remote Sens. 2020, 12, 2694. https://doi.org/10.3390/rs12172694
Wang S, Fan Z, Li Z, Zhang H, Wei C. An Effective Lunar Crater Recognition Algorithm Based on Convolutional Neural Network. Remote Sensing. 2020; 12(17):2694. https://doi.org/10.3390/rs12172694
Chicago/Turabian StyleWang, Song, Zizhu Fan, Zhengming Li, Hong Zhang, and Chao Wei. 2020. "An Effective Lunar Crater Recognition Algorithm Based on Convolutional Neural Network" Remote Sensing 12, no. 17: 2694. https://doi.org/10.3390/rs12172694
APA StyleWang, S., Fan, Z., Li, Z., Zhang, H., & Wei, C. (2020). An Effective Lunar Crater Recognition Algorithm Based on Convolutional Neural Network. Remote Sensing, 12(17), 2694. https://doi.org/10.3390/rs12172694