
Automatic Creation of Storm Impact Database Based on Video Monitoring and Convolutional Neural Networks


Abstract
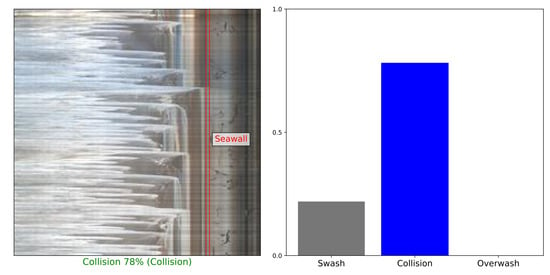
:
1. Introduction
2. Study Sites and Data
- Swash regime: all the waves in the timestack are confined to the beach;
- Collision regime: at least one wave in the timestack collides with the bottom of the seawall;
- Overwash regime: at least one wave in the timestack completely overtops the seawall.
2.1. Grande Plage de Biarritz
2.1.1. Site Characteristics
2.1.2. Timestack Image Preprocessing
2.2. Zarautz
2.2.1. Site Characteristics
2.2.2. Timestacks Images Preprocessing
3. Convolutional Neural Networks
3.1. General Concept
- Inception v3, an improved version of the GoogleNet from Szegedy et al. [37] which won the ILSVRC in 2014. It relies on inception modules, which perform convolutions with filters of multiple size and concatenate their results (Table A4). In addition, the convolution operation with filters of large size inside an inception module are made by using filters to reduce computational cost. This results in deeper networks with significantly fewer parameters to learn.
3.2. Training the CNN
3.2.1. Data Processing
- Random vertical flip: new timestack with inverted time;
- Random shift in the RGB image color to decrease the dependence on lighting conditions;
- Normalization of pixel values to 0–1 for faster training
3.2.2. Class Imbalance Problem
3.2.3. Transfer Learning
3.2.4. Application to the Datasets
3.3. CNN Accuracy Assessment
4. Results
4.1. CNN Performances
4.1.1. Architectures
4.1.2. Class Imbalance
4.1.3. Pre-Training
4.1.4. Best Models
4.2. Investigating the Errors
4.3. Transferability between Sites
4.4. Sensitivity Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural networks |
| GBP | Grande Plage of Biarritz |
Appendix A. CNN Architectures
Appendix A.1. Custom CNN

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Block1 Conv (Conv2D) | (None, 111, 111, 32) | 896 |
| Block1 Pool (MaxPooling2D) | (None, 55, 55, 32) | 0 |
| Block2 Conv2d (Conv2D) | (None, 53, 53, 64) | 18,496 |
| Block2 Pool (MaxPooling2D) | (None, 26, 26, 64) | 0 |
| Block3 Conv2d (Conv2D) | (None, 24, 24, 128) | 73,856 |
| Block4 Pool (MaxPooling2D) | (None, 12, 12, 128) | 0 |
| Block5 Conv2d (Conv2D) | (None, 10, 10, 256) | 295,168 |
| Block5 Pool (MaxPooling2D) | (None, 5, 5, 256) | 0 |
| Flatten (Flatten) | (None, 6400) | 0 |
| Dense1 (Dense) | (None, 512) | 3,277,312 |
| Dropout1 (Dropout) | (None, 512) | 0 |
| Dense2 (Dense) | (None, 256) | 131,328 |
| Dropout2 (Dropout) | (None, 256) | 0 |
| Dense3 (Dense) | (None, 128) | 32,896 |
| Dropout3 (Dropout) | (None, 128) | 0 |
| Output (Dense) | (None, 3) | 387 |
- Total params: 3,830,339
- Trainable params: 3,830,339
- Non-trainable params: 0
Appendix A.2. AlexNet
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Block1 Conv (Conv2D) | (None, 54, 54, 96) | 34,944 |
| Block1 Pool (MaxPooling2D) | (None, 27, 27, 96) | 0 |
| Block2 Conv (Conv2D) | (None, 17, 17, 256) | 2,973,952 |
| Block2 Pool (MaxPooling2D) | (None, 8, 8, 256) | 0 |
| Block3 Conv (Conv2D) | (None, 6, 6, 384) | 885,120 |
| Block3 Conv (Conv2D) | (None, 4, 4, 384) | 1,327,488 |
| Block4 Conv (Conv2D) | (None, 2, 2, 256) | 884,992 |
| Block4 Pool (MaxPooling2D) | (None, 1, 1, 256) | 0 |
| Flatten (Flatten) | (None, 256) | 0 |
| Dense1 (Dense) | (None, 4096) | 1,052,672 |
| Dropout1 (Dropout) | (None, 4096) | 0 |
| Dense2 (Dense) | (None, 4096) | 16,781,312 |
| Dropout2 (Dropout) | (None, 4096) | 0 |
| Output (Dense) | (None, 3) | 12,291 |
- Total params: 23,952,771
- Trainable params: 23,952,771
- Non-trainable params: 0
Appendix A.3. VGG16
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Input (Input Layer) | (None, 224, 224, 3) | 0 |
| Block1 Conv1 (Conv2D) | (None, 224, 224, 64) | 1792 |
| Block1 Conv2 (Conv2D) | (None, 224, 224, 64) | 36,928 |
| Block1 Pool (MaxPooling2D) | (None, 112, 112, 64) | 0 |
| Block2 conv1 (Conv2D) | (None, 112, 112, 128) | 73,856 |
| Block2 Conv2 (Conv2D) | (None, 112, 112, 128) | 147,584 |
| Block2 Pool (MaxPooling2D) | (None, 56, 56, 128) | 0 |
| Block3 Conv1 (Conv2D) | (None, 56, 56, 256) | 295,168 |
| Block3 Conv2 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| Block3 Conv3 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| Block3 Pool (MaxPooling2D) | (None, 28, 28, 256) | 0 |
| Block4 Conv1 (Conv2D) | (None, 28, 28, 512) | 1,180,160 |
| Block4 Conv2 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| Block4 Conv3 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| Block4 Pool (MaxPooling2D) | (None, 14, 14, 512) | 0 |
| Block5 Conv1 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| Block5 Conv2 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| Block5 Conv3 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| Block5 Pool (MaxPooling2D) | (None, 7, 7, 512) | 0 |
| Flatten (Flatten) | (None, 2048) | 0 |
| Dense1 (Dense) | (None, 512) | 262,656 |
| Dropout1 (Dropout) | (None, 512) | 0 |
| Output (Dense) | (None, 3) | 1539 |
- Total params: 14,978,883
- Trainable params: 14,978,883
- Non-trainable params: 0
Appendix A.4. Inception v3
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Inceptionv3 (Model) | (None, 2048) | 21,802,784 |
| Flatten (Flatten) | (None, 2048) | 0 |
| Dense1 (Dense) | (None, 512) | 1,049,088 |
| Dropout1 (Dropout) | (None, 512) | 0 |
| Output (Dense) | (None, 3) | 1539 |
- Total params: 22,853,411
- Trainable params: 22,818,979
- Non-trainable params: 34,432
Appendix B. Investigating the Errors
| Test | |||||
| Splash | Lighting | Misclass. | Hard to classify | Vertical | |
| 2 | 1 | 5 | 3 | 5 | |
| Validation | |||||
| Splash | Misclass. | Sand bags ? | Splash | Hard to classify | Vertical |
| 1 | 2 | 1 | 2 | 2 | 4 |
| Test | ||||||
| Hard to classify | Lighting | Misclass. | SI | SI + Light | Splash | Vertical |
| 10 | 30 | 7 | 22 | 2 | 14 | 1 |
| Validation | ||||||
| Hard to classify | Lighting | Misclass. | SI | SI + Light | Sandbag ? | Splash |
| 5 | 27 | 3 | 26 | 2 | 4 | 4 |
References
- Valchev, N.; Andreeva, N.; Eftimova, P.; Trifonova, E. Prototype of Early Warning System for Coastal Storm Hazard (Bulgarian Black Sea Coast). CR Acad. Bulg. Sci. 2014, 67, 977. [Google Scholar]
- Van Dongeren, A.; Ciavola, P.; Martinez, G.; Viavattene, C.; Bogaard, T.; Ferreira, O.; Higgins, R.; McCall, R. Introduction to RISC-KIT: Resilience-increasing strategies for coasts. Coast. Eng. 2018, 134, 2–9. [Google Scholar] [CrossRef] [Green Version]
- Sallenger, A.H.J. Storm Impact Scale for Barrier Islands. J. Coast. Res. 2000, 16, 890–895. [Google Scholar]
- de Santiago, I.; Morichon, D.; Abadie, S.; Reniers, A.J.; Liria, P. A Comparative Study of Models to Predict Storm Impact on Beaches. Nat. Hazards 2017, 87, 843–865. [Google Scholar] [CrossRef]
- Haigh, I.D.; Wadey, M.P.; Gallop, S.L.; Loehr, H.; Nicholls, R.J.; Horsburgh, K.; Brown, J.M.; Bradshaw, E. A user-friendly database of coastal flooding in the United Kingdom from1915 to 2014. Sci. Data 2015, 2, 1–13. [Google Scholar] [CrossRef]
- Garnier, E.; Ciavola, P.; Spencer, T.; Ferreira, O.; Armaroli, C.; McIvor, A. Historical analysis of storm events: Case studies in France, England, Portugal and Italy. Coast. Eng. 2018, 134, 10–23. [Google Scholar] [CrossRef] [Green Version]
- Abadie, S.; Beauvivre, M.; Egurrola, E.; Bouisset, C.; Degremont, I.; Arnoux, F. A Database of Recent Historical Storm Impact on the French Basque Coast. J. Coast. Res. 2018, 85, 721–725. [Google Scholar] [CrossRef]
- André, C.; Monfort, D.; Bouzit, M.; Vinchon, C. Contribution of insurance data to cost assessment of coastal flood damage to residential buildings: Insights gained from Johanna (2008) and Xynthia (2010) storm events. Nat. Hazards Earth Syst. Sci. 2013, 13, 2003. [Google Scholar] [CrossRef] [Green Version]
- Naulin, J.P.; Moncoulon, D.; Le Roy, S.; Pedreros, R.; Idier, D.; Oliveros, C. Estimation of insurance-related losses resulting from coastal flooding in France. Nat. Hazards Earth Syst. Sci. 2016, 16, 195–207. [Google Scholar] [CrossRef]
- Ciavola, P.; Harley, M.; den Heijer, C. The RISC-KIT storm impact database: A new tool in support of DRR. Coast. Eng. 2018, 134, 24–32. [Google Scholar] [CrossRef]
- Holman, R.A.; Stanley, J. The history and technical capabilities of Argus. Coast. Eng. 2007, 54, 477–491. [Google Scholar] [CrossRef]
- Nieto, M.A.; Garau, B.; Balle, S.; Simarro, G.; Zarruk, G.A.; Ortiz, A.; Tintoré, J.; Álvarez-Ellacuría, A.; Gómez-Pujol, L.; Orfila, A. An open source, low cost video-based coastal monitoring system. Earth Surf. Process. Landforms 2010, 35, 1712–1719. [Google Scholar] [CrossRef]
- Splinter, K.D.; Harley, M.D.; Turner, I.L. Remote sensing is changing our view of the coast: Insights from 40 years of monitoring at Narrabeen-Collaroy, Australia. Remote Sens. 2018, 10, 1744. [Google Scholar] [CrossRef] [Green Version]
- Buscombe, D.; Carini, R.J. A data-driven approach to classifying wave breaking in infrared imagery. Remote Sens. 2019, 11, 859. [Google Scholar] [CrossRef] [Green Version]
- Senechal, N.; Coco, G.; Bryan, K.R.; Holman, R.A. Wave runup during extreme storm conditions. J. Geophys. Res. Ocean. 2011, 116. [Google Scholar] [CrossRef] [Green Version]
- Vousdoukas, M.I.; Wziatek, D.; Almeida, L.P. Coastal Vulnerability Assessment Based on Video Wave Run-up Observations at a Mesotidal, Steep-Sloped Beach. Ocean. Dyn. 2012, 62, 123–137. [Google Scholar] [CrossRef]
- den Bieman, J.P.; de Ridder, M.P.; van Gent, M.R. Deep learning video analysis as measurement technique in physical models. Coast. Eng. 2020, 158, 103689. [Google Scholar] [CrossRef]
- Stringari, C.E.; Harris, D.L.; Power, H.E. A Novel Machine Learning Algorithm for Tracking Remotely Sensed Waves in the Surf Zone. Coast. Eng. 2019. [Google Scholar] [CrossRef]
- Valentini, N.; Saponieri, A.; Molfetta, M.G.; Damiani, L. New algorithms for shoreline monitoring from coastal video systems. Earth Sci. Inform. 2017, 10, 495–506. [Google Scholar] [CrossRef]
- Almar, R.; Cienfuegos, R.; Catalán, P.A.; Michallet, H.; Castelle, B.; Bonneton, P.; Marieu, V. A new breaking wave height direct estimator from video imagery. Coast. Eng. 2012, 61, 42–48. [Google Scholar] [CrossRef]
- Andriolo, U.; Mendes, D.; Taborda, R. Breaking wave height estimation from Timex images: Two methods for coastal video monitoring systems. Remote Sens. 2020, 12, 204. [Google Scholar] [CrossRef] [Green Version]
- Ondoa, G.A.; Almar, R.; Castelle, B.; Testut, L.; Leger, F.; Sohou, Z.; Bonou, F.; Bergsma, E.; Meyssignac, B.; Larson, M. Sea level at the coast from video-sensed waves: Comparison to tidal gauges and satellite altimetry. J. Atmos. Ocean. Technol. 2019, 36, 1591–1603. [Google Scholar] [CrossRef]
- Holman, R.; Plant, N.; Holland, T. cBathy: A robust algorithm for estimating nearshore bathymetry. J. Geophys. Res. Ocean. 2013, 118, 2595–2609. [Google Scholar] [CrossRef]
- Simarro, G.; Calvete, D.; Luque, P.; Orfila, A.; Ribas, F. UBathy: A new approach for bathymetric inversion from video imagery. Remote Sens. 2019, 11, 2722. [Google Scholar] [CrossRef] [Green Version]
- Thuan, D.H.; Binh, L.T.; Viet, N.T.; Hanh, D.K.; Almar, R.; Marchesiello, P. Typhoon impact and recovery from continuous video monitoring: A case study from Nha Trang Beach, Vietnam. J. Coast. Res. 2016, 75, 263–267. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Almar, R.; Blenkinsopp, C.; Almeida, L.P.; Cienfuegos, R.; Catalan, P.A. Wave runup video motion detection using the Radon Transform. Coast. Eng. 2017, 130, 46–51. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Valentini, N.; Balouin, Y. Assessment of a smartphone-based camera system for coastal image segmentation and sargassum monitoring. J. Mar. Sci. Eng. 2020, 8, 23. [Google Scholar] [CrossRef] [Green Version]
- Morichon, D.; de Santiago, I.; Delpey, M.; Somdecoste, T.; Callens, A.; Liquet, B.; Liria, P.; Arnould, P. Assessment of Flooding Hazards at an Engineered Beach during Extreme Events: Biarritz, SW France. J. Coast. Res. 2018, 85, 801–805. [Google Scholar] [CrossRef]
- Abadie, S.; Butel, R.; Mauriet, S.; Morichon, D.; Dupuis, H. Wave Climate and Longshore Drift on the South Aquitaine Coast. Cont. Shelf Res. 2006, 26, 1924–1939. [Google Scholar] [CrossRef]
- De Santiago, I.; Morichon, D.; Abadie, S.; Castelle, B.; Liria, P.; Epelde, I. Video monitoring nearshore sandbar morphodynamics on a partially engineered embayed beach. J. Coast. Res. 2013, 65, 458–463. [Google Scholar] [CrossRef]
- Bengio, Y.; Goodfellow, I.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017; Volume 1. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A Systematic Study of the Class Imbalance Problem in Convolutional Neural Networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Uchida, S.; Ide, S.; Iwana, B.K.; Zhu, A. A further step to perfect accuracy by training CNN with larger data. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 405–410. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Dodge, S.; Karam, L. A study and comparison of human and deep learning recognition performance under visual distortions. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–7. [Google Scholar]
- Simarro, G.; Bryan, K.R.; Guedes, R.M.; Sancho, A.; Guillen, J.; Coco, G. On the use of variance images for runup and shoreline detection. Coast. Eng. 2015, 99, 136–147. [Google Scholar] [CrossRef]
- Andriolo, U.; Sánchez-García, E.; Taborda, R. Operational use of surfcam online streaming images for coastal morphodynamic studies. Remote Sens. 2019, 11, 78. [Google Scholar] [CrossRef] [Green Version]
- Mole, M.A.; Mortlock, T.R.; Turner, I.L.; Goodwin, I.D.; Splinter, K.D.; Short, A.D. Capitalizing on the surfcam phenomenon: A pilot study in regional-scale shoreline and inshore wave monitoring utilizing existing camera infrastructure. J. Coast. Res. 2013, 1433–1438. [Google Scholar] [CrossRef]
- Andriolo, U. Nearshore wave transformation domains from video imagery. J. Mar. Sci. Eng. 2019, 7, 186. [Google Scholar] [CrossRef] [Green Version]
- Poelhekke, L.; Jäger, W.; van Dongeren, A.; Plomaritis, T.; McCall, R.; Ferreira, Ó. Predicting Coastal Hazards for Sandy Coasts with a Bayesian Network. Coast. Eng. 2016, 118, 21–34. [Google Scholar] [CrossRef]
- Plomaritis, T.A.; Costas, S.; Ferreira, Ó. Use of a Bayesian Network for Coastal Hazards, Impact and Disaster Risk Reduction Assessment at a Coastal Barrier (Ria Formosa, Portugal). Coast. Eng. 2018, 134, 134–147. [Google Scholar] [CrossRef]






| (a) Biarritz | ||||||
|---|---|---|---|---|---|---|
| CNN | Training Time (min) | Epochs | Time per Epoch (s) | Precision | Recall | -Score |
| Baseline | ||||||
| Custom CNN | 16.1 | 100 | 9.7 | / | 0.333 | 0.328 |
| AlexNet | 17.2 | 100 | 10.3 | / | 0.333 | 0.328 |
| VGG16 | 81.4 | 89 | 54.9 | / | 0.481 | 0.476 |
| Inception v3 | 40.0 | 69 | 34.8 | 0.721 | 0.714 | 0.713 |
| Class weights | ||||||
| Custom CNN | 4.6 | 28 | 9.9 | / | 0.603 | 0.474 |
| AlexNet | 3.8 | 21 | 10.9 | 0.568 | 0.777 | 0.609 |
| VGG16 | 43.4 | 46 | 56.6 | 0.574 | 0.832 | 0.645 |
| Inception v3 | 23.2 | 39 | 35.8 | 0.563 | 0.798 | 0.631 |
| Oversampling | ||||||
| Custom CNN | 10.6 | 26 | 24.6 | 0.642 | 0.880 | 0.718 |
| AlexNet | 11.8 | 27 | 26.1 | 0.716 | 0.885 | 0.777 |
| VGG16 | 69.6 | 28 | 149.1 | 0.783 | 0.851 | 0.813 |
| VGG16 Transfer | 49.9 | 20 | 149.6 | 0.869 | 0.865 | 0.866 |
| Inception v3 | 59.6 | 38 | 94.1 | 0.679 | 0.767 | 0.717 |
| Inception v3 Transfer | 34.5 | 21 | 98.6 | 0.777 | 0.786 | 0.780 |
| (b) Zarautz | ||||||
| CNN | Training Time (Min) | Epochs | Time per Epoch (s) | Precision | Recall | -Score |
| Baseline | ||||||
| Custom CNN | 22.5 | 49 | 27.5 | / | 0.637 | 0.616 |
| AlexNet | 24.0 | 48 | 30.0 | / | 0.628 | 0.616 |
| VGG16 | 202.1 | 72 | 168.4 | / | 0.635 | 0.617 |
| Inception v3 | 108.7 | 64 | 101.9 | / | 0.630 | 0.614 |
| Class weights | ||||||
| Custom CNN | 11.6 | 26 | 26.7 | 0.666 | 0.846 | 0.720 |
| AlexNet | 22.7 | 45 | 30.3 | 0.671 | 0.817 | 0.716 |
| VGG16 | 81.9 | 30 | 163.7 | 0.680 | 0.844 | 0.732 |
| Inception v3 | 89.3 | 53 | 101.1 | 0.654 | 0.838 | 0.710 |
| Oversampling | ||||||
| Custom CNN | 38.7 | 36 | 64.5 | 0.769 | 0.804 | 0.783 |
| AlexNet | 22.6 | 19 | 71.3 | 0.756 | 0.797 | 0.775 |
| VGG16 | 146.6 | 22 | 399.8 | 0.775 | 0.812 | 0.792 |
| VGG16 Transfer | 86.5 | 13 | 399.1 | 0.897 | 0.834 | 0.858 |
| Inception v3 | 97.7 | 24 | 244.2 | 0.777 | 0.801 | 0.784 |
| Inception v3 Transfer | 65.3 | 16 | 245.0 | 0.869 | 0.835 | 0.849 |
| (a) Biarritz (best model: OV VGG16 Transfer) | ||||
|---|---|---|---|---|
| Predicted | ||||
| Swash | Collision | Overwash | ||
| Observed | Swash | 1576 | 7 | 0 |
| Collision | 4 | 34 | 2 | |
| Overwash | 1 | 2 | 9 | |
| (b) Zarautz (best model: OV VGG16 Transfer) | ||||
| Predicted | ||||
| Swash | Collision | Overwash | ||
| Observed | Swash | 4265 | 40 | 0 |
| Collision | 13 | 617 | 8 | |
| Overwash | 0 | 25 | 30 | |
| CNN | Time (min) | Epochs | Time per Epoch (s) | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Biarritz | ||||||
| Best model before corr. | 49.9 | 20 | 149.6 | 0.869 | 0.865 | 0.866 |
| Best model after corr. | 60 | 24 | 150 | 0.895 | 0.833 | 0.860 |
| Zarautz | ||||||
| Best model before corr. | 86.5 | 13 | 399.1 | 0.897 | 0.834 | 0.858 |
| Best model after corr. | 88.5 | 13 | 408.5 | 0.917 | 0.859 | 0.883 |
| CNN | Time (min) | Epochs | Time per Epoch (s) | Precision | Recall | -Score |
|---|---|---|---|---|---|---|
| Biarritz | ||||||
| VGG16 (OV) | 69.6 | 28 | 149.1 | 0.783 | 0.851 | 0.813 |
| VGG16 (OV) Pretraining with ImageNet | 49.9 | 20 | 149.6 | 0.869 | 0.865 | 0.866 |
| VGG16 (OV) Pretraining with Zarautz data | 47 | 19 | 148.4 | 0.826 | 0.832 | 0.823 |
| Zarautz | ||||||
| VGG16 (OV) | 81.9 | 30 | 163.7 | 0.680 | 0.844 | 0.732 |
| VGG16 (OV) Pretraining with ImageNet | 86.5 | 13 | 399.1 | 0.897 | 0.834 | 0.858 |
| VGG16 (OV) Pretraining with Biarritz data | 92 | 14 | 394.2 | 0.909 | 0.867 | 0.885 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Callens, A.; Morichon, D.; Liria, P.; Epelde, I.; Liquet, B. Automatic Creation of Storm Impact Database Based on Video Monitoring and Convolutional Neural Networks. Remote Sens. 2021, 13, 1933. https://doi.org/10.3390/rs13101933
Callens A, Morichon D, Liria P, Epelde I, Liquet B. Automatic Creation of Storm Impact Database Based on Video Monitoring and Convolutional Neural Networks. Remote Sensing. 2021; 13(10):1933. https://doi.org/10.3390/rs13101933
Chicago/Turabian StyleCallens, Aurelien, Denis Morichon, Pedro Liria, Irati Epelde, and Benoit Liquet. 2021. "Automatic Creation of Storm Impact Database Based on Video Monitoring and Convolutional Neural Networks" Remote Sensing 13, no. 10: 1933. https://doi.org/10.3390/rs13101933
APA StyleCallens, A., Morichon, D., Liria, P., Epelde, I., & Liquet, B. (2021). Automatic Creation of Storm Impact Database Based on Video Monitoring and Convolutional Neural Networks. Remote Sensing, 13(10), 1933. https://doi.org/10.3390/rs13101933