
An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
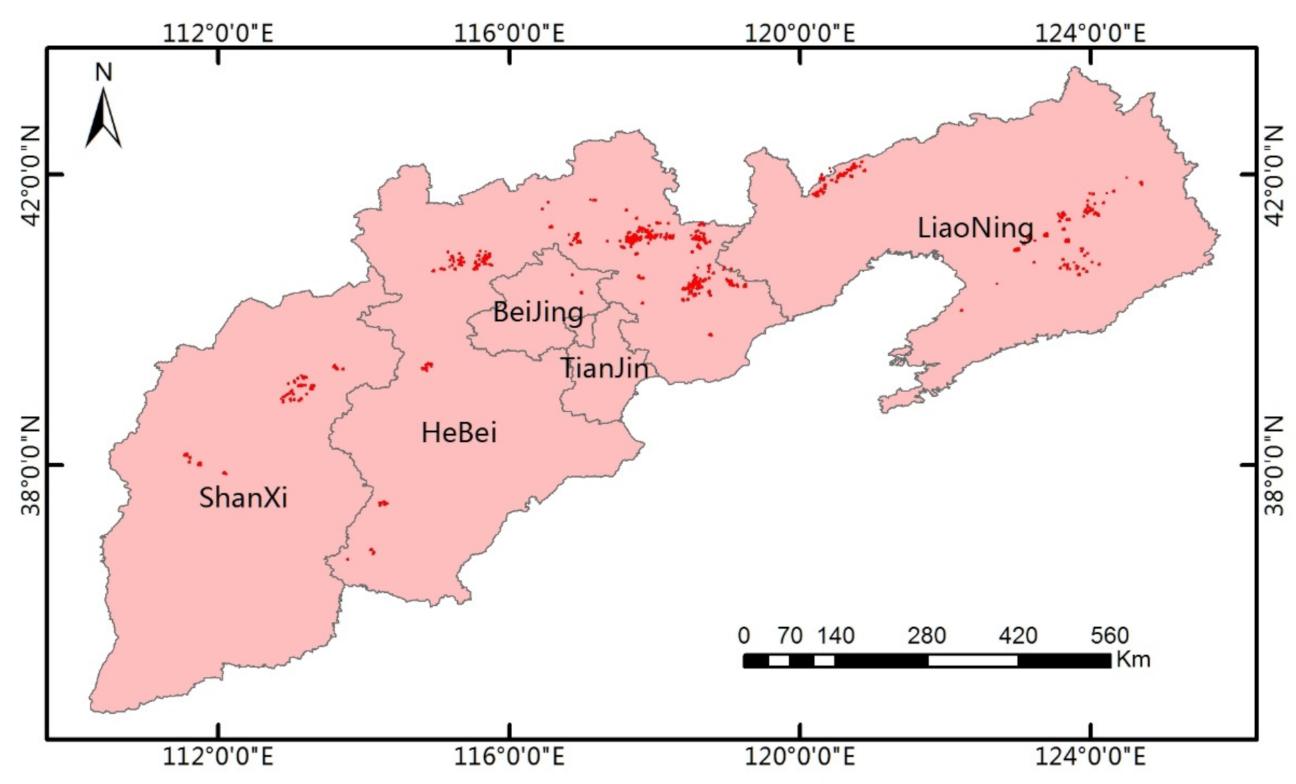
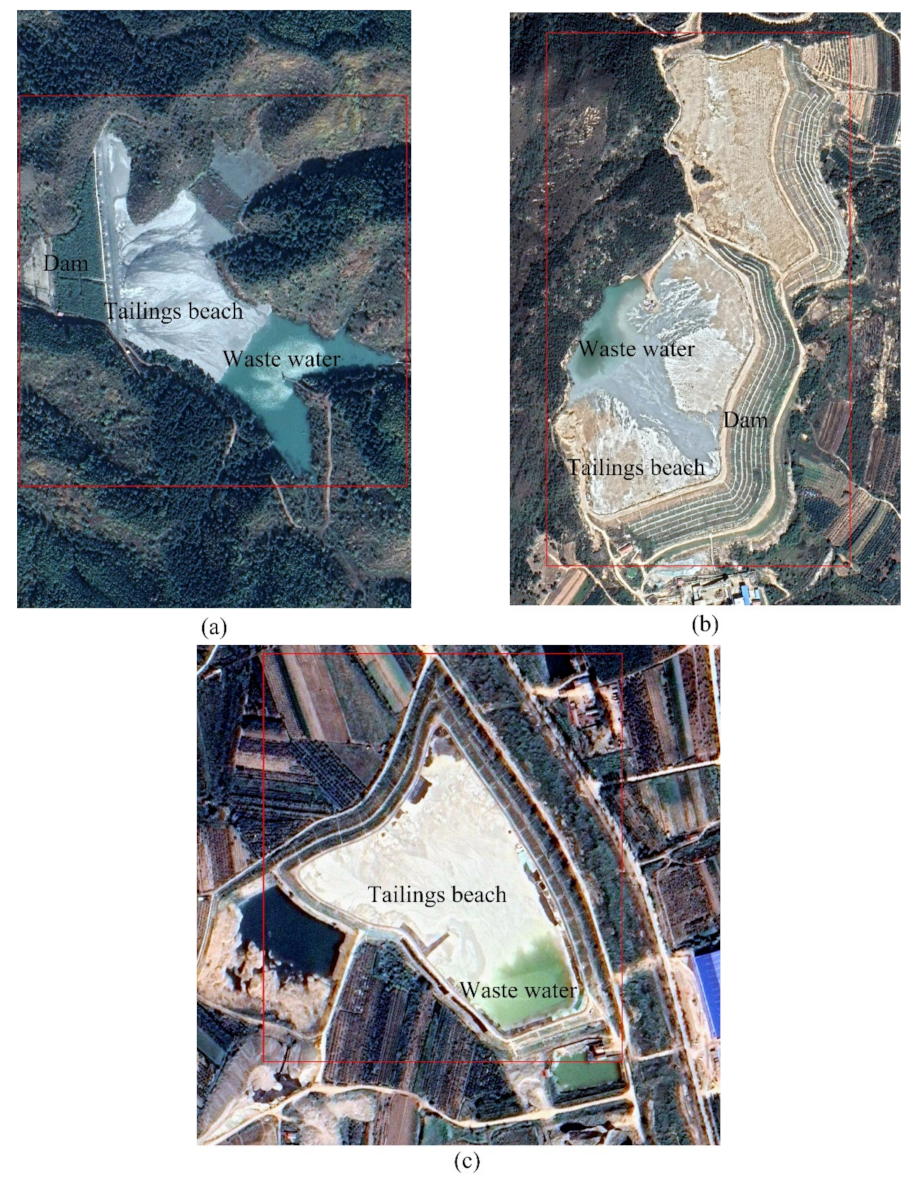
2.1. Sampling Data Generation
2.2. Methodology
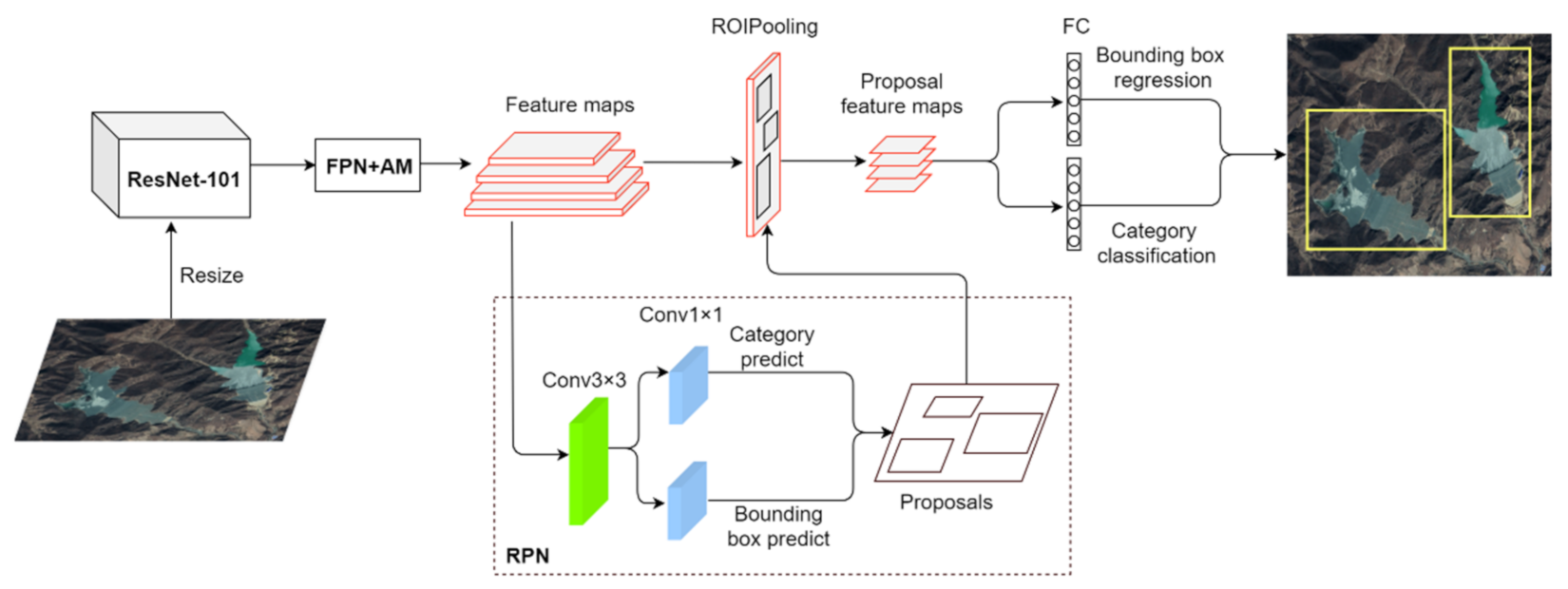
2.2.1. Proposed Optimized Method
Attention Mechanism (AM)
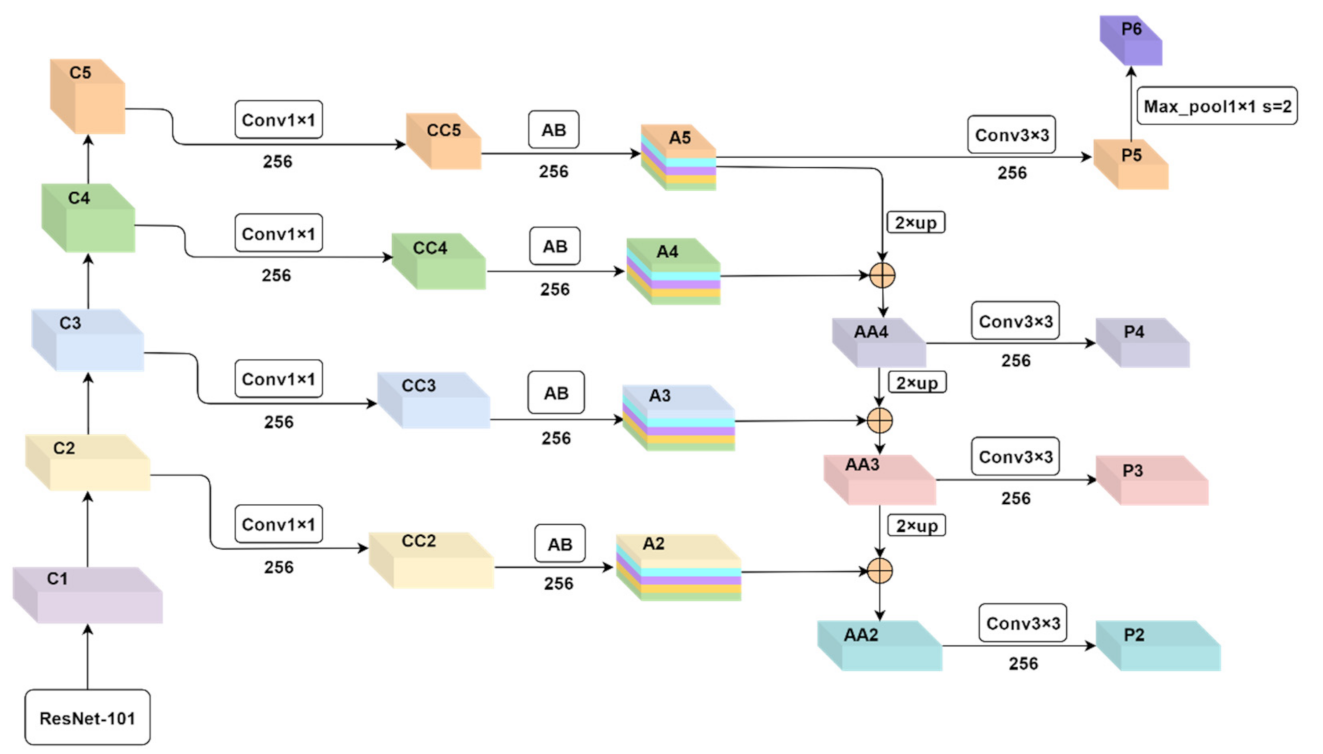
Proposed Feature Pyramid Network (FPN)
Region Proposal Network (RPN)
2.2.2. Accuracy Assessment
2.2.3. Loss Function
2.2.4. Training and Optimization
3. Results and Discussion
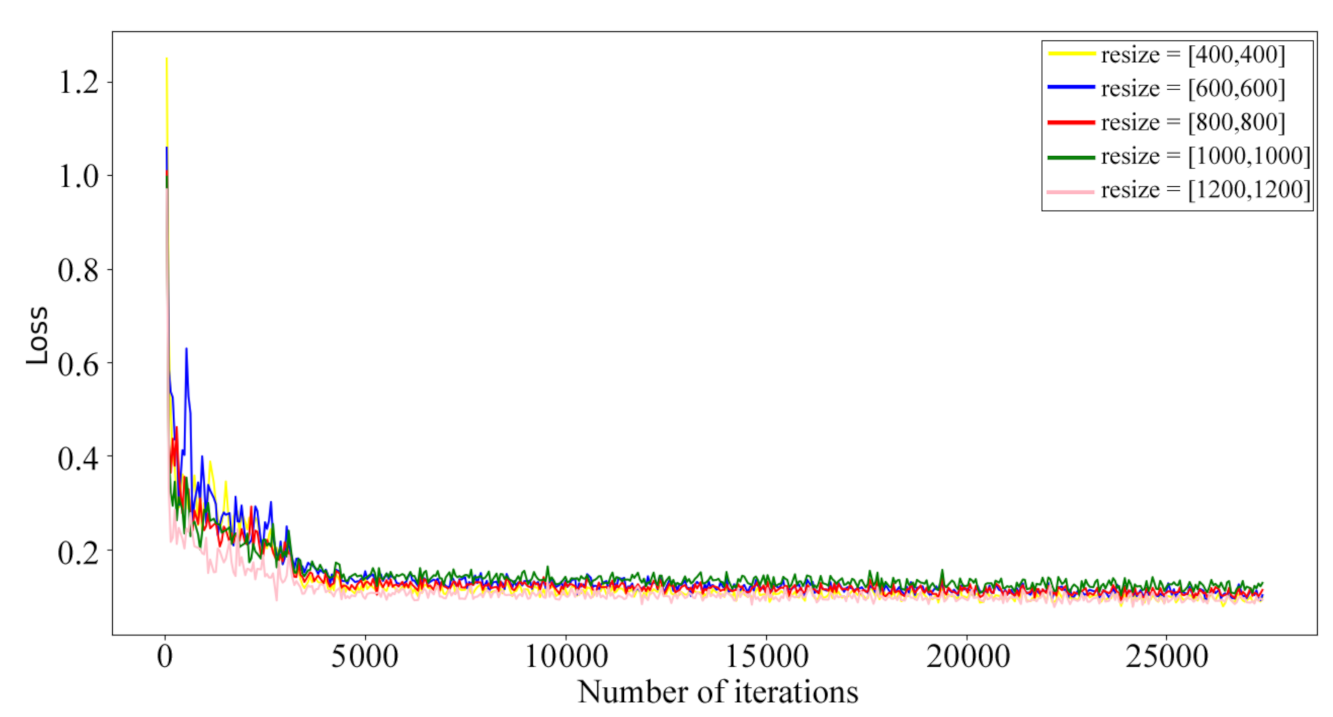
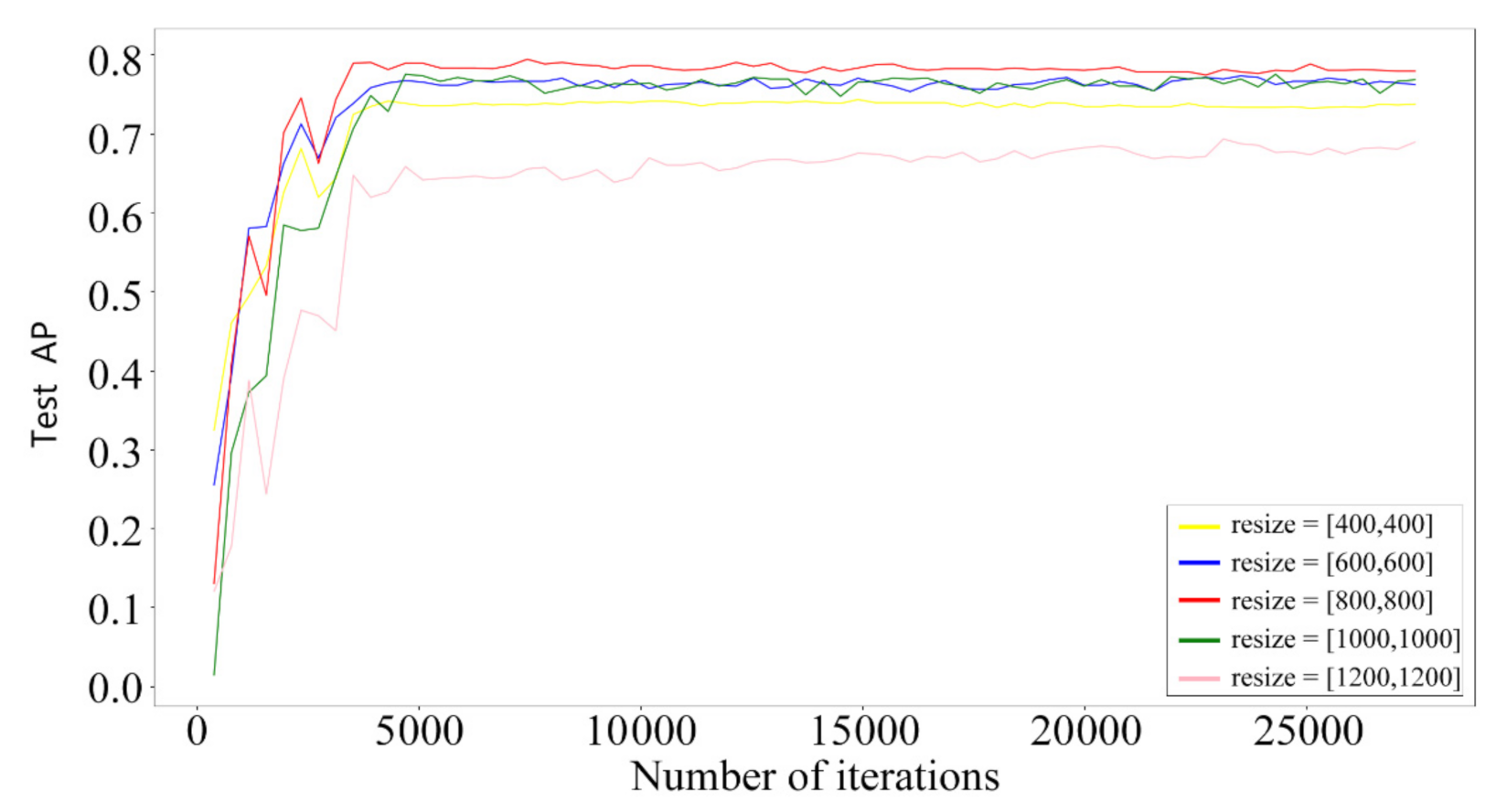
3.1. Effect of Different Input Sizes
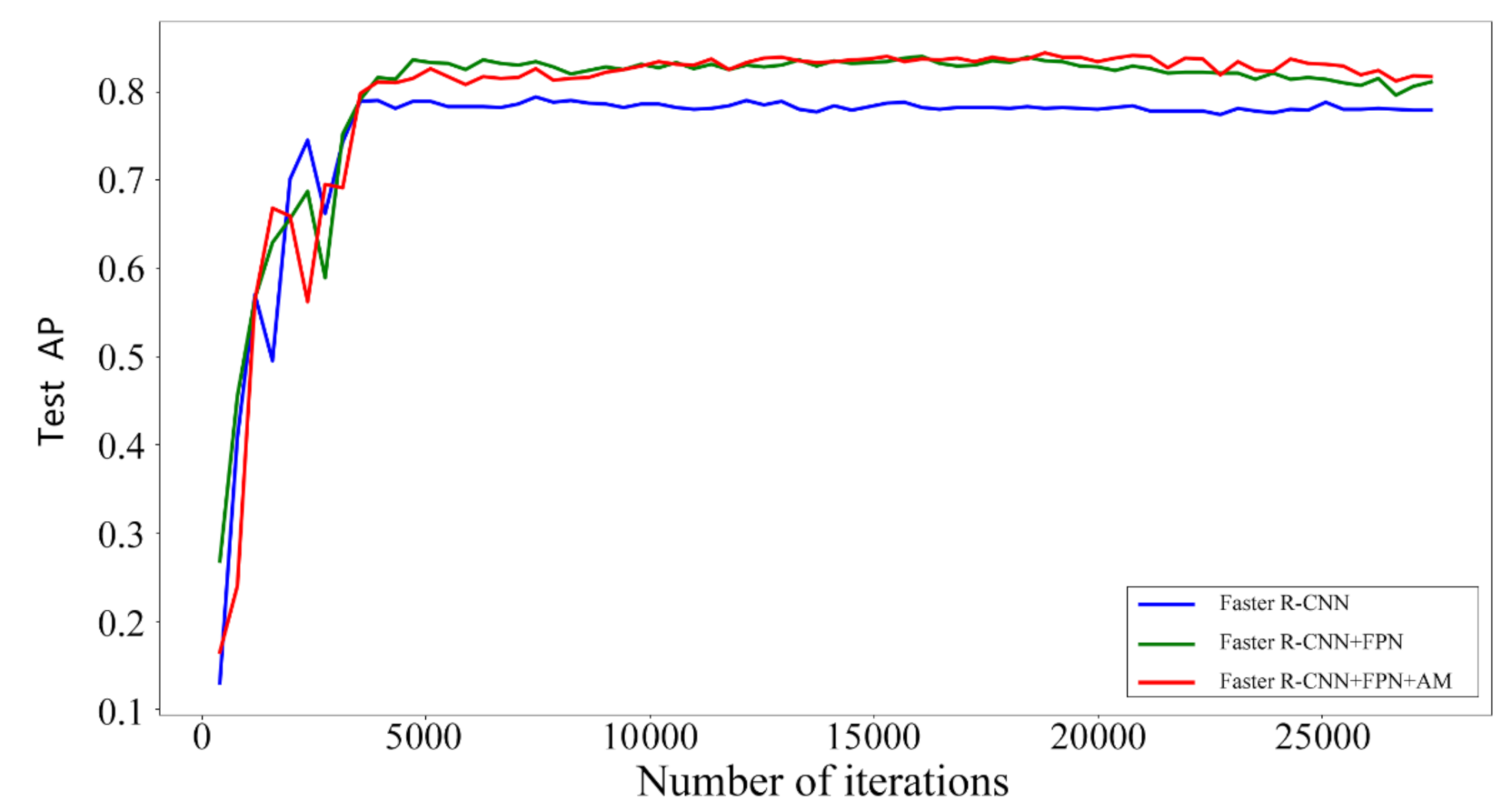
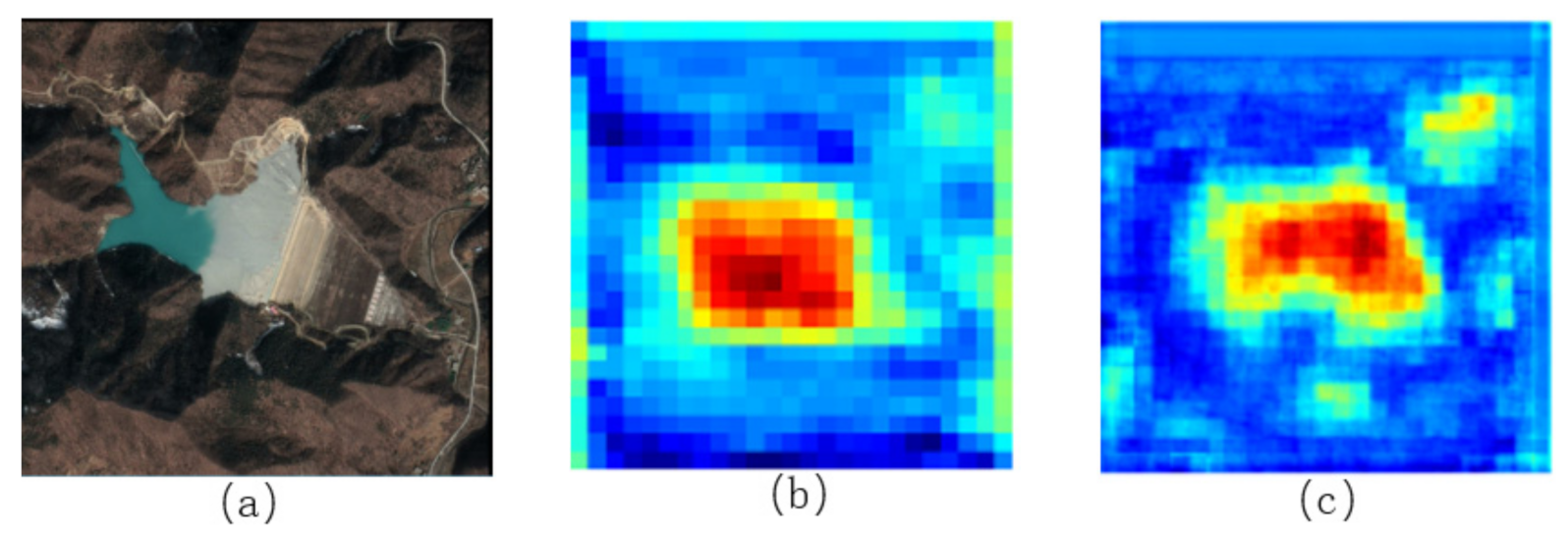
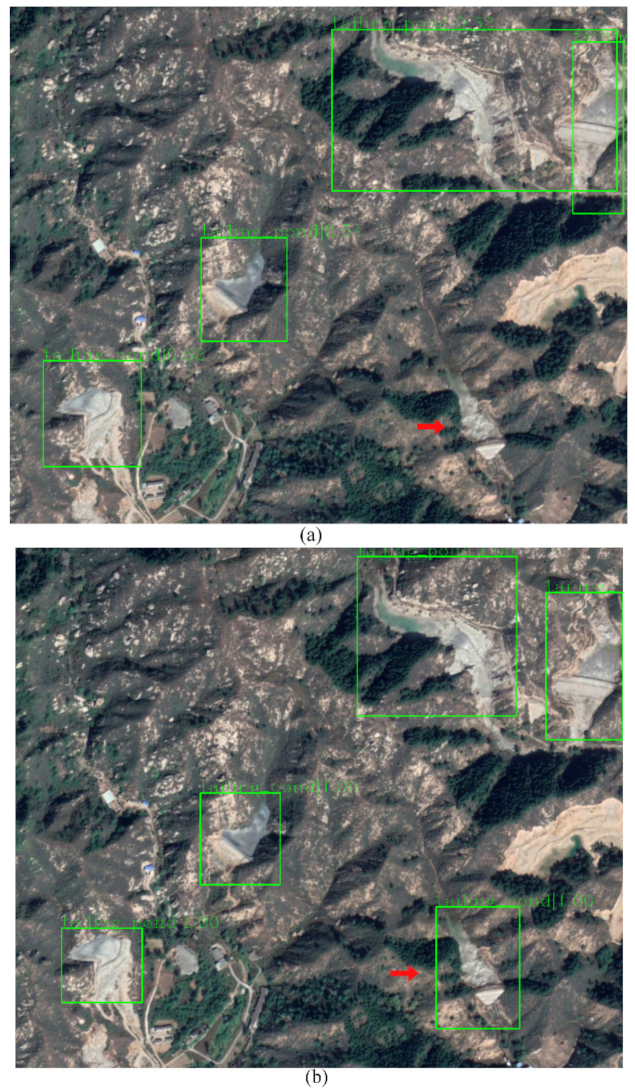
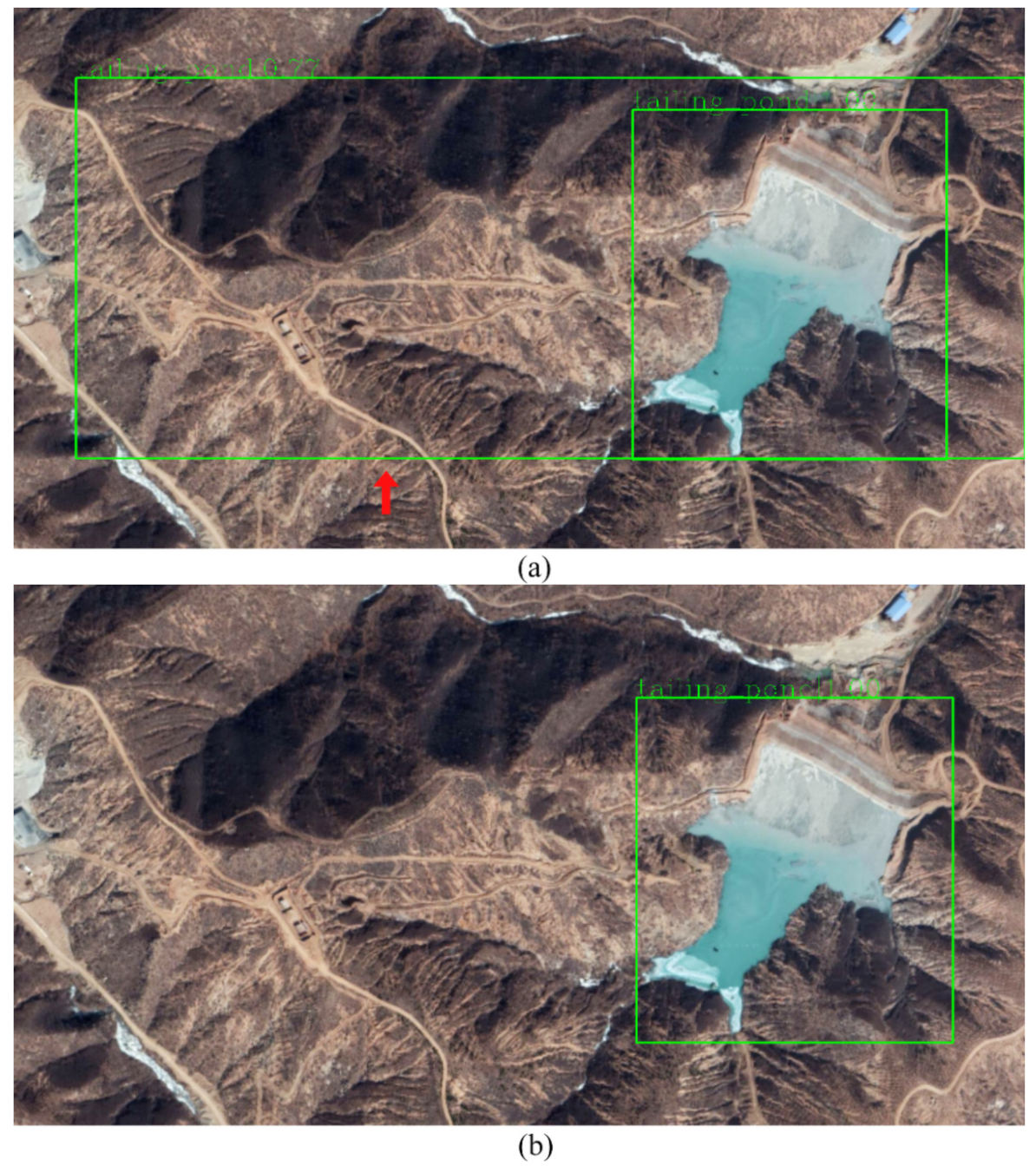
3.2. Analysis of Model Improvement Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ILSVRC | ImageNet large-scale visual recognition challenge |
| CNN | convolutional neural network |
| FC | fully connected layers |
| RPN | region proposal network |
| FPN | feature pyramid network |
| AM | attention mechanism |
| AB | channel attention mechanism block |
| GT | ground truth bounding box |
| PT | predicted bounding box |
| IOU | intersection over union |
| AP | average precision |
| mAP | mean average precision |
| PRC | precision-recall curve |
References
- Wang, T.; Hou, K.P.; Guo, Z.S.; Zhang, C.L. Application of analytic hierarchy process to tailings pond safety operation analysis. Rock Soil Mech. 2008, 29, 680–687. [Google Scholar]
- Xiao, R.; Lv, J.; Fu, Z.; Sheng, W.; Xiong, W.; Shi, Y.; Cao, F.; Yu, Q. The Application of Remote Sensing in the Environmental Risk Monitoring of Tailings pond in Zhangjiakou City, China. Remote Sens. Technol. Appl. 2014, 29, 100–105. [Google Scholar]
- Santamarina, J.C.; Torres-Cruz, L.A.; Bachus, R.C. Why coal ash and tailings dam disasters occur. Science 2019, 364, 526. [Google Scholar] [CrossRef] [PubMed]
- Jie, L. Remote Sensing Research and Application of Tailings Pond–A Case Study on the Tailings Pond in Hebei Province; China University of Geosciences: Beijing, China, 2014. [Google Scholar]
- Gao, Y.; Hou, J.; Chu, Y.; Guo, Y. Remote sensing monitoring of tailings ponds based on the latest domestic satellite data. J. Heilongjiang Inst. Technol. 2019, 33, 26–29. [Google Scholar]
- Tan, Q.L.; Shao, Y. Application of remote sensing technology to environmental pollution monitoring. Remote. Sens. Technol. Appl. 2000, 15, 246–251. [Google Scholar]
- Dai, Q.W.; Yang, Z.Z. Application of remote sensing technology to environment monitoring. West. Explor. Eng. 2007, 4, 209–210. [Google Scholar]
- Wang, Q. The progress and challenges of satellite remote sensing technology applications in the field of environmental protection. Environ. Monit. China 2009, 25, 53–56. [Google Scholar]
- Liu, W.T.; Zhang, Z.; Peng, Y. Application of TM image in monitoring the water quality of tailing reservoir. Min. Res. Dev. 2010, 30, 90–92. [Google Scholar]
- Zhao, Y.M. Moniter Tailings based on 3S Technology to Tower Mountain in Shanxi Province. Master’s Thesis, China University of Geoscience, Beijing, China, 2011; pp. 1–46. [Google Scholar]
- Hao, L.; Zhang, Z.; Yang, X. Mine tailing extraction indexes and model using remote-sensing images in southeast Hubei Province. Environ. Earth Sci. 2019, 78, 493. [Google Scholar] [CrossRef] [Green Version]
- Ma, B.; Chen, Y.; Zhang, S.; Li, X. Remote sensing extraction method of tailings ponds in ultra-low-grade iron mining area based on spectral characteristics and texture entropy. Entropy 2018, 20, 345. [Google Scholar] [CrossRef] [Green Version]
- Xiao, R.; Shen, W.; Fu, Z.; Shi, Y.; Xiong, W.; Cao, F. The application of remote sensing in the environmental risk monitoring of tailings pond: A case study in Zhangjiakou area of China. SPIE Proc. 2012, 8538. [Google Scholar]
- Riaza, A.; Buzzi, J.; García-Meléndez, E.; Vázquez, I.; Bellido, E.; Carrère, V.; Müller, A. Pyrite mine waste and water mapping using Hymap and Hyperion hyperspectral data. Environ. Earth Sci. 2012, 66, 1957–1971. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Z.; Zhang, B.; Li, B.; Lu, K.; Lu, L.; Guo, H. Detection of tailings dams using high-resolution satellite imagery and a single shot multibox detector in the Jing–Jin–Ji Region, China. Remote. Sens. 2020, 12, 2626. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1106–1114. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maarten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2016; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Ronghua. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A Novel Framework Based on Mask R-CNN and Histogram Thresholding for Scalable Segmentation of New and Old Rural Buildings. Remote. Sens. 2021, 13, 1070. [Google Scholar]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K. Use of Very High Spatial Resolution Commercial Satellite Imagery and Deep Learning to Automatically Map Ice-Wedge Polygons across Tundra Vegetation Types. J. Imaging 2020, 6, 137. [Google Scholar] [CrossRef]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building extraction from satellite images using mask R-CNN with building boundary regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bai, T.; Pang, Y.; Wang, J.; Han, K.; Luo, J.; Wang, H.; Lin, J.; Wu, J.; Zhang, H. An Optimized Faster R-CNN Method Based on DRNet and RoI Align for Building Detection in Remote Sensing Images. Remote Sens. 2020, 12, 762. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Cen, C.; Che, Y.; Ke, R.; Ma, Y.; Ma, Y. Detection of Maize Tassels from UAV RGB Imagery with Faster R-CNN. Remote Sens. 2020, 12, 338. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Song, C.; Pan, Y.; Li, L.; Li, R.; Lu, S. Review of new progress in tailing dam safety in foreign research and current state with development trend in China. Chin. J. Rock Mech. Eng. 2014, 33, 3238–3248. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, H.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. arXiv 2020, arXiv:1904.02874. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Buckland, M.; Gey, F. The relationship between Recall and Precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]




 represents element-wise addition.
represents element-wise addition.
represents element-wise addition.
represents element-wise addition.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Set | Spatial Resolution (m) | Size (Pixels) | Slices Number |
|---|---|---|---|
| Train set | 0.5 | 2600 × 2600 | 1697 |
| Test set | 0.5 | 2600 × 2600 | 429 |
| Hyperparameter | Learning Rate | Momentum | Weight_Decay | Batch Size |
|---|---|---|---|---|
| Value | 0.02 | 0.9 | 0.0001 | 2 |
| Resize | AP (%) | Recall (%) | Iteration Time (s) |
|---|---|---|---|
| [400, 400] | 74.3 | 51.8 | 0.105 |
| [600, 600] | 77.3 | 53.0 | 0.128 |
| [800, 800] | 80.1 | 52.0 | 0.186 |
| [1000, 1000] | 77.5 | 47.3 | 0.259 |
| [1200, 1200] | 69.3 | 41.8 | 0.345 |
| Network | AP (%) | Recall (%) | Iteration Time (s) |
|---|---|---|---|
| Faster R-CNN | 80.1 | 52.0 | 0.186 |
| Faster R-CNN + FPN | 84.3 | 62.6 | 0.273 |
| Faster R-CNN + FPN + AB | 85.7 | 62.9 | 0.279 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, D.; Li, G.; Li, X.; Zhang, H.; Lei, H.; Lu, K.; Cheng, M.; Zhu, F. An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 2052. https://doi.org/10.3390/rs13112052
Yan D, Li G, Li X, Zhang H, Lei H, Lu K, Cheng M, Zhu F. An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images. Remote Sensing. 2021; 13(11):2052. https://doi.org/10.3390/rs13112052
Chicago/Turabian StyleYan, Dongchuan, Guoqing Li, Xiangqiang Li, Hao Zhang, Hua Lei, Kaixuan Lu, Minghua Cheng, and Fuxiao Zhu. 2021. "An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images" Remote Sensing 13, no. 11: 2052. https://doi.org/10.3390/rs13112052
APA StyleYan, D., Li, G., Li, X., Zhang, H., Lei, H., Lu, K., Cheng, M., & Zhu, F. (2021). An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images. Remote Sensing, 13(11), 2052. https://doi.org/10.3390/rs13112052