1. Introduction
In the past 30 years, the Antarctic and Southern Ocean Marine ecosystems have been undergoing great changes [
1]. Turel [
2] statistically analyzed the meteorological data of 17 stations in Antarctica and disclosed that the Amundsen Sea’s low pressure significantly warmed the Antarctic Peninsula by changing the radial component of the wind, which certainly had important implications for the Antarctic ecosystem.
As the largest species of birds in Antarctica, penguins are labeled as “biological indicators” [
3]. Environmental changes influence their survival and reproduction. Therefore, it is of great significance to monitor the changes in the penguin population, which can provide bases for discovering an environmental urgency [
4]. On the other hand, the Commission for the Conservation of Antarctic Marine Living Resources (CCAMLR) revised the Ecosystem Monitoring Program [
5], including four species of penguins (Adelie penguin, chinstrap penguin, gentoo penguin and macaroni penguin) as dependent species that rely on harvested species for survival. By studying various life parameters, such as population size, breeding success and foraging behavior, changes in the abundance of harvested species (e.g., krill) can be detected. Thus, monitoring penguin populations provides valuable information to implement sustainable commercial fishing plans. In this paper, based on the characteristics of our dataset, we concentrate on investigating changes in the Adelie penguin’s population size from the perspective of statistical penguin counting.
Currently, research data on penguins mainly include satellite remote sensing, aviation and field investigation [
6]. Due to the limitations of climate and time costs, field investigation is mostly abandoned. Remote sensing images have emerged as the primary means for investigation of penguin distribution evolution. However, the ground resolution is low even in high-resolution satellite remote sensing images. Often penguins cannot be directly observed from images and an indirect regression relationship was established to count penguins. A variety of remote sensing data, such as Landsat and Quickiro-2, have been used to determine the changes in the penguin population [
7,
8]. Medium-resolution Landsat-7 is commonly used to map Adelie penguin colonies on a continental scale and high-resolution satellite images taken by Worldview can be used for detection of single or multiple penguin species. Witharana et al. used seven fusion algorithms to further enhance the resolution of high-resolution images [
9].
In the 1980s, M.R. et al. [
10] proposed to identify the guano region through satellite remote sensing images and then established a linear regression relationship between the area of guano and the size of Adelie penguin populations. Since then, scholars adopt supervised classification and object-oriented methods to extract fecal areas. Ref. [
11] proposed a semantic segmentation network to improve the accuracy of feces extraction. However, the cost of acquiring satellite images is high; aerial images can be used as its substitute, whose ground resolution is higher. An unmanned aerial vehicle (UAV) system was used in [
12] to observe the active nests of Southern Giant Petrel (SGP) on the Antarctic Specially Managed Area no. 1, Admiralty Bay, King George Island. In contrast, the penguin population has a larger community and dense distribution, which requires a large (if not prohibitive) amount of manpower and time to obtain sufficiently accurate data statistics in Antarctica. To overcome it, Ref. [
13] suggested a method called Population Counting with Overhead Robotic Networks (POPCORN) to optimize the flying trajectory of UAV. Eventually, they used five drones to complete the sampling of 300,000 penguin burrows (
~) on Ross Island, Antarctica within 3 h. In addition, Clarel developed a semi-automated workflow for counting individuals by fusing multi-spectral and thermal images by UAV [
14], proving that the method was effective in most cases but may produce large errors in large population sizes. Based on those fused aerial images, an object-oriented method was developed to distinguish penguins from rock shadows [
15], achieving an average accuracy of 91%.
The above indirect counting method relies heavily on manual design and prior knowledge. When the environment changes, the model may deviate significantly from reality. In 2012, convolution (Conv) was first introduced into machine learning [
16], significantly improving accuracy and speed over traditional algorithms in image classification. Since then, the convolutional neural network (CNN) has played a dominant role in computer vision research and applications. By leveraging deep learning-based image processing methods to accurately locate each penguin, we can not only count the numbers but also achieve better explanatory power and robustness.
Object detection is meant to find all objects of interest from images, extracting the image features through, for example, CNN and returning the categories in detection boxes. Recently, multiple high-performance algorithms such as region convolutional neural network (R-CNN) series [
17,
18,
19], Yolo series [
20,
21,
22,
23,
24,
25,
26] and Vision Transformer (ViT) [
27,
28] have exceeded the accuracy of human vision in detecting small targets.
R-CNN [
17] was the first deep learning detector that used the selective search method to generate around 2000 proposals where objects might exist. Linear regression was then used to refine the target position after a Support Vector Machine (SVM). While R-CNN outperformed other detectors, it had poor computational efficiency. To speed up training, Fast R-CNN [
18] adopted the spatial pyramid pool layer to extract features from the entire image and Faster R-CNN [
19] proposed using a region proposal network to replace the selective search method, significantly improving speed. Despite satisfying visual detection needs, the R-CNN series’ speed has always been a concern.
In contrast, Yolo [
20] was another method that used a single CNN network to regress detection boxes and categories by fusing two steps in R-CNN, resulting in higher speed with the same network size. However, the number of detections was limited. Yolov2 [
21] divided feature maps into grids, with each grid producing nine preset bounding boxes (Anchors) that were friendly for dense detection. It predicted the offset of Anchors to acquire more detections. In 2018, Yolov3 [
19] fused multi-scale features to predict features with three different sizes, surpassing Faster R-CNN in both speed and accuracy. Moreover, Yolov4 [
23], Yolov5 [
24], Yolov6 [
25], and Yolov7 [
26] integrated more tricks to achieve better speed and accuracy. With its excellent balance between speed and accuracy, the Yolo series has been widely applied in target detection, especially for small objects. For example, Refs. [
29,
30] improved the detection performance of road cracks and potholes on the basis of Yolov3 by optimizing multi-scale fusion modules, k-means, and loss functions. The former increased F1 by 8.8%, while the latter further increased F1 by 15.4% by combining data augmentation techniques. Yolov4 was first introduced in oil derrick detection in [
31], achieving excellent performance. Refs. [
32,
33,
34] utilized Yolov5 to perform pedestrian detection in aerial images, surpassing other SOTA (state of the art) algorithms. Ref. [
35] improved the Backbone of Yolov7 by space-to-depth convolution to reduce feature loss for small targets during down-sampling, further enhancing the accuracy of pedestrian detection. To increase the amount of information, an adaptive illumination-driven input-level fusion module was proposed in [
36] to fuse infrared and RGB images. Similarly, Ref. [
37] added an attention module during feature fusion to focus more on the scattered information, improving the accuracy of ship detection in synthetic aperture radar images.
Remote sensing image object detection has the same theoretical basis as general detectors. However, there are also differences in the detailed implementation according to the objects’ characteristics. The penguin detection case has the following difficulties:
The scale variation of objects is large;
The target distribution is dense and the pixel size can be very small (width < 10 pixels);
High-resolution imaging of large areas (hundreds of millions of pixels) leads to huge hardware overhead.
In order to solve problems similar to those above, YOLT [
38] divided the remote sensing image (millions of pixels) into blocks size of
by a sliding window with 15% pixels overlap. The improved Yolov2 network was trained to detect cars with five pixels in size with a detection accuracy (e.g., F1 score) of 85%. An unsupervised two-stage detection method [
39] enhanced the accuracy of small ships (a few tens of pixels) by scanning for potential target areas of the ship first. This was followed by a detector to execute localization and classification, significantly reducing data annotation costs. In addition, deformable convolutions [
40] and parallel Region Proposal networks (RPN) [
41] are incorporated into the Feature Pyramid Networks (FPN) [
42] to integrate multi-scale features in order to counteract the scale variations in remote sensing imagery, remarkably boosting the detection performance of vehicles which are densely dispersed.
Furthermore, several studies are investigating the use of deep learning applications for wildlife monitoring with the aid of aerial images. Duporge et al. [
43] used Faster R-CNN to identify elephants in satellite images, exceeding human vision with an F1 of 0.75. Ref. [
44] compared the accuracies of three detection algorithms in recognizing six species (elephant, buffalo, African water antelope, corner wildebeest, warthog, and African oryx). Ref. [
45] detects large marine animals such as dolphins that are easily confused with sunlight by abnormal thermal images. Moreover, small and medium-sized animals such as rabbits, kangaroos, wild boars [
46], domestic cattle [
47] and birds [
48] can be rapidly detected with an accuracy rate of over 90% from in UAV-required images.
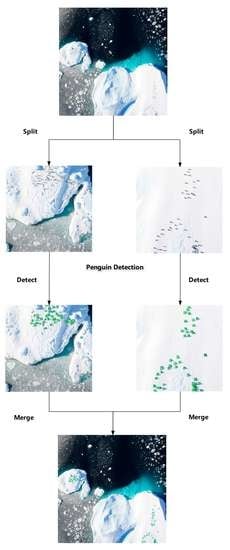
Note that, in contrast to the cars, ships, rabbits or other animals in remote sensing images, penguins appear to be smaller and the harsh conditions in Antarctica result in a higher cost for obtaining images. These challenges make it difficult to develop direct methods for penguin recognition in images. Fortunately, with the support of the Polar Research Institute of China, we obtain high-resolution aerial remote-sensing images of Adelie penguins in Antarctica. When viewed from above, penguins appear as black dots that contrast with the white snow and rocks background, making them easily detectable in images. Motivated by the deep learning method, we establish a penguin detection dataset and propose a new network for counting Adelie penguins based on their characteristics. Our overall contributions call be summarized as follows:
We explore the flexibility of directly counting penguins from remote-sensing images. Based on deep learning method, a penguin detection dataset is established, which includes 58 high-resolution images of 9504 × 6336 captured over the Antarctic island.
To address the challenges of detecting tiny penguins from significant background interference, we propose an automatic detection network, named YoloPd, for counting penguins directly and investigate its performances in the dataset we established.
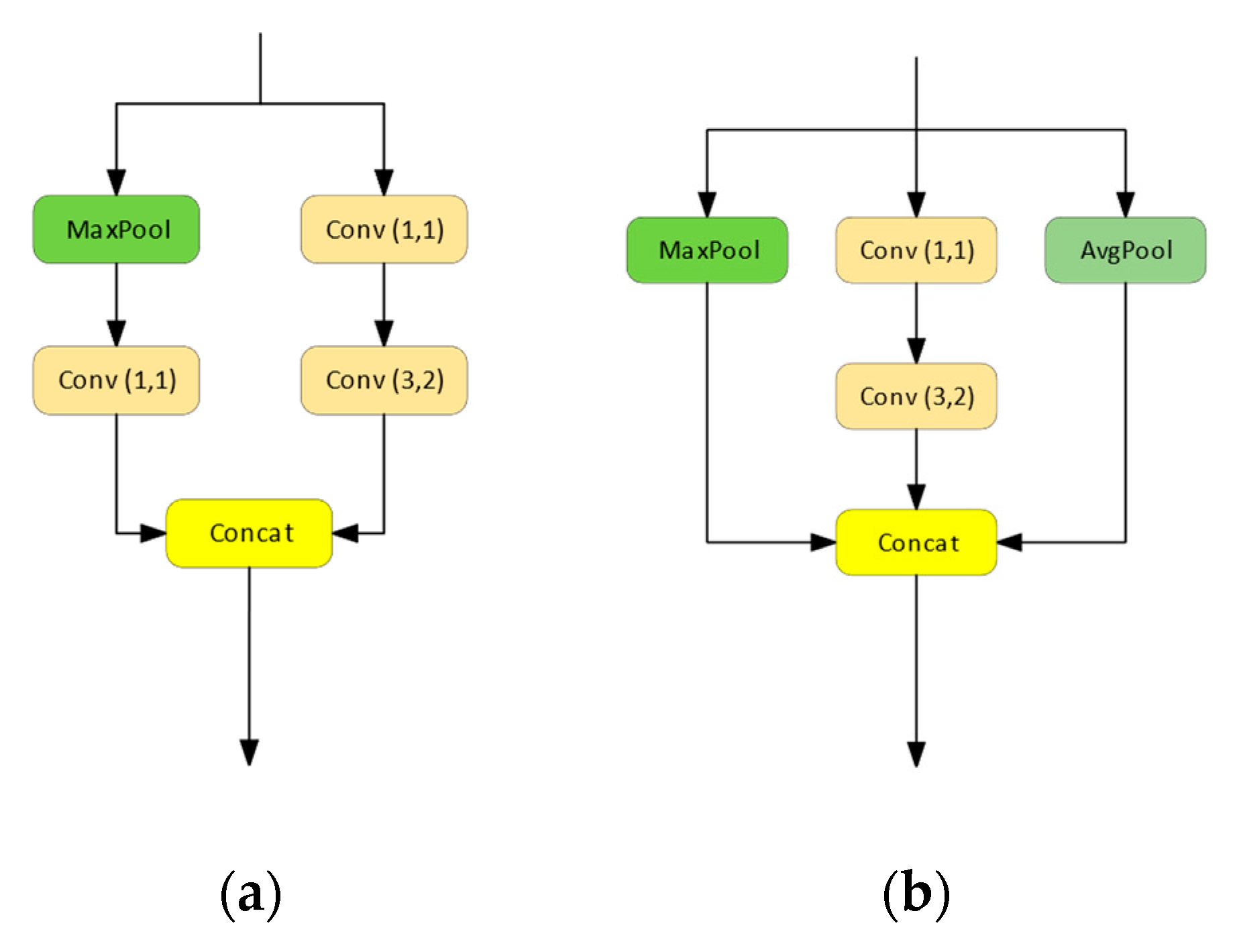
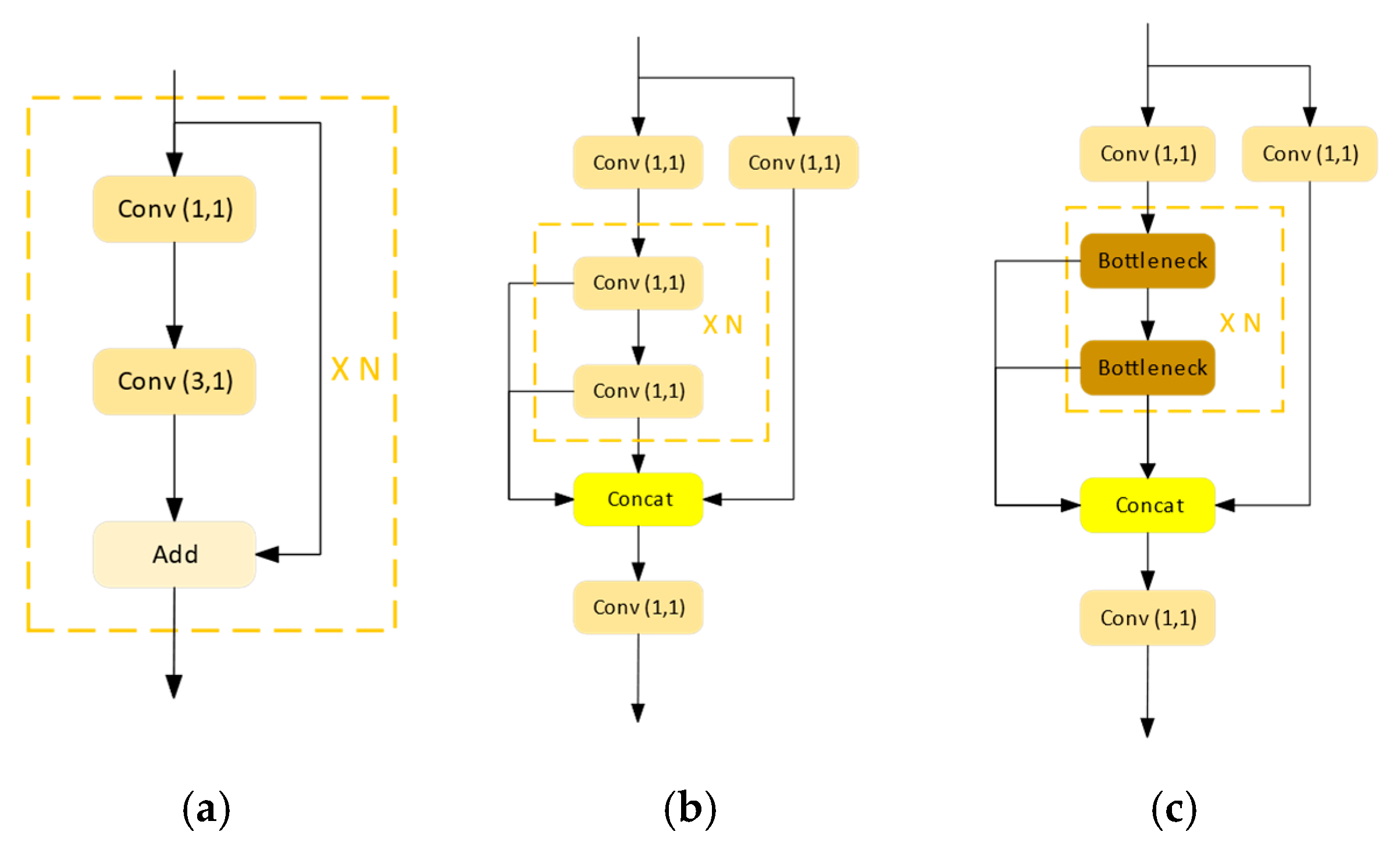
We design the multiple frequency features fusion module (named MAConv) and Bottleneck efficient aggregation layer (BELAN) to increase the informative content of small penguins, providing deeper semantic features. Additionally, we incorporated a lightweight Swin-Transformer (LSViT) and attention mechanism into BELAN (named TBELAN and AELAN, respectively) to extract low-frequency information that can effectively help the network filter out complex background interference.
We reconstruct the penguin detection datasets using Gaussian kernels with varying degrees of blur and validate the feasibility of YoloPd within them. Furthermore, we also verify the robustness of YoloPd on the DOTA dataset [
49].
3. Results
To balance the speed and accuracy, we follow the design paradigm of Yolov7 to determine the size of our network. The number of BELAN and TBELAN-
i in Backbone are shown in
Table 4.
250 epochs were trained on a single V100 GPU with a batch-size of 16. An SGD optimizer is used as well with the initial learning rate of . The cosine decay strategy is used to make the learning rate reach to with 0.0005 weight decay.
As a result, YoloPd achieves an average F1 of 88.0% in sub-images. Its mAP.5 reaches 89.4% and mAP reaches 40.9%. Specific numerical results are shown in
Table 5 in
Section 4. In contrast to the F1 of detecting kobs being 64% [
44], human vision detecting elephants with 75% F1 [
43] and 85% F1 in car counting [
38], our results are remarkable, which initially meets the demand for correctly categorizing penguins. Additionally, YoloPd’s nearly 90% mAP.5 indicates its excellent positioning capabilities.
As shown in
Figure 10, in white snow areas, small and densely distributed penguins can be detected commendably with almost no errors due to obvious aberration. According to statistics, the smallest penguin occupies three pixels. In the white rocks, though the shadow of penguin gets darker which may confuse with neighboring black penguins, YoloPd can still locate the two adjacent penguins. With the complexity of the terrain, penguins become increasingly invisible to human vision. As demonstrated in
Figure 10c, penguins and their shadows can be highly similar to the background in shape and color around black rocks, even leading to missed detections by human vision. However, YoloPd can separate them that are hard to distinguish from black rocks. In particular, for the top image, some little rocks which have the same white color can be easily mistaken as penguins.
When analyzing the whole image prediction, it is important to consider both F1 and
comprehensively. To investigate the impact of
on them, we select 20 thresholds within the range of
. As shown in
Figure 11, the maximum
of 95.8% is achieved when
, whereas the maximum F1 of 94.0% is observed at
. Although large
is desirable, the false detections may lead to the inclusion of non-penguin object. On the other hand, F1 can better reflect the predicted number of real penguins. Therefore, we choose
that corresponds to the highest F1 as the optimal choice. The other one is used as a measurement of feasibility for algorithms. When
, 18 test images achieve 94.6% average
.
We select two different scenarios of the whole images to demonstrate the prediction results in
Figure 12. For the densely distributed scene (a), small penguin pixel size and overlap with shadows lead to missed and false detections. Nevertheless, the F1 of this image can reach to 93.5%. In scenario (b) with sparse penguin distribution, the
is close to 99%.
4. Discussion
4.1. Method Comparison
To emphasize the advantage of our network in detecting penguins, we compare it with two SOTA methods Faster R-CNN and Yolov7. We select lightweight Backbones, ResNet-34 and ELANet-l, respectively, with similar Params. In order to show the advantage of Transformer, we also choose the smallest Backbone Swin-Transformer-tiny in Faster R-CNN. Besides, we select a stronger and larger Backbone ELANet-x as a contrast.
Firstly, as shown in
Table 5 for the most classical detector Faster R-CNN, the Backbone Swin-Transformer shows better performance in accuracy than ResNet-34. Specifically, given a similar number of parameters, the former one improves F1, mAP.5, mAP by 1.3%, 1.3% and 1.8% respectively. However, the huge hardware overhead of Transformer leads to the reduction of FPS. When the more efficient Backbone ELANet-l is adopted in Yolov7, the F1 score is improved to 85.7% and achieves real-time detection performance with 66 FPS. By combining the advantages of both, our YoloPd outperforms Faster R-CNN (ResNet-34) by 6.2% F1, 8.5% mAP. Meanwhile, in contrast to the latest detector Yolov7, our hybrid structures provide performance gains with negligible inference speed degradation. YoloPd beats it by 2.3% F1, 2.1% mAP.5 and 1.9% mAP. Even compared to Yolov7 with the larger Backbone ELANet-x, the F1 is improved from 85.9% to 88.0% with 50.3% fewer parameters, achieving a good balance between accuracy and speed. We also show the visualized results of different methods in
Figure 13.
Regarding the snow area (a), based on Faster R-CNN, the Backbone Swin-Transformer avoids a lot of false detections (penguins shadows) located by ResNet-34. From Refs. [
28,
50], this is likely due to the Transformer-based network’s ability to extract global features, enabling it to learn the difference between penguins and shadows. Additionally, Yolov7 with a stronger backbone is capable of extracting deeper features of objects, resulting in better classification accuracy. When combing both advantages, YoloPd can even detect penguins at the edges of the image correctly. Meanwhile, from the scene (b) we can see that Faster R-CNN demonstrates poor ability to detect densely distributed penguins. While equipped with the Yolo detector Head which is friendly for densely detections, YoloPd is able to reduce the number of missed penguins from 33 to five. In the complex scene (c), there exists small rocks that exhibit similar features to penguins. This can cause confusion for object detection models such as Faster R-CNN (ResNet-34), Faster R-CNN (Swin-Transformer) and Yolov7 (ELANet-l), which have mistaken five, two, and one rocks as penguins, respectively. In contrast, our network has managed to learn the subtle differences between the two, accurately detecting all penguins. Consequently, YoloPd achieves 100% F1 and
, proving to be the most effective model in this scenario.
In addition, according to our knowledge, there have been no papers published so far on using object detection algorithms to count penguins on the Antarctic islands because acquiring high resolution remote-sensing images is difficult due to their remote location. Compared to other indirect methods used for counting individuals such as Ref. [
11] which uses a semantic segmentation technique that achieves a counting accuracy of 91%, our method has competitive indices. Besides, contrast to detect other animals, such as rabbits [
46] and domestic cattle [
47] with a counting accuracy of 95%, bird detection [
48] with 90.63% mAP.5 and marine lives detection with an F1 of 79.7%, our results are remarkable. The new method initially meets the demand for correctly categorizing penguins, making this an exciting prospect for further research.
4.2. Ablation Experiments
To verify the effect of each of the improvements on the model performance, ablation experiments are conducted. For the sake of comparison, we treat BELAN and TBELAN as a unified entity BELAN during the experiment. We recorded F1, mAP.5, mAP, Params and FPS with different combination of MAConv, BELAN and AELAN based on Yolov7 (ELANet-l).
According to
Table 6, we observe that the performance metrics vary when different modules are combined. However, not all combinations of modules can result in performance gains. For instance, we notice that adding the MAConv module leads to a 0.1% decrease in F1 score compared to using the AELAN module alone. This can be attributed to the fact that each improvement technique is not entirely independent, and sometimes combining the modules can be ineffective despite effective individual modules. Therefore, we have analyzed the results of the ablation experiments in the order of optimal network performance increment: Baseline + MAConv + BELAN + AELAN.
Baseline + MAConv: Firstly, we incorporate the multi-frequency attention fusion module MAConv in the down-sampling module of the entire network. By removing redundant convolutional layers, fusing multi-frequency information and avoiding information loss caused by small targets during down-sampling, we design a structure that slightly improves the network’s performance indicators while maintaining its speed.
Baseline + MAConv + BELAN: Next, in the Backbone, we utilize the efficient Transformer and CNN hybrid module BELAN to extract more low-frequency features, significantly improving the network’s localization and classification capabilities. Compared to Yolov7, the incorporation of the two efficient modules improves F1, mAP.5, and mAP by 1.6%, 2.1% and 2.8%, respectively. However, the high computational cost of the Transformer reduces the inference speed of the network, resulting in a lowered FPS of 19.
Baseline + MAConv + BELAN + AELAN: Finally, we add the attention module AELAN in the Neck, which fuses multiscale features to produce an attention prediction feature map, further enhancing the network’s performance. Through these optimizations, we achieve an improved F1 of 88%, mAP.5 of 89.4 and mAP of 40.9 while striking a balance between speed and performance. Despite the loss of inference speed, the network maintained real-time inference performance at 43 FPS.
In conclusion, our proposed network with efficient modules showed improved performance in object detection while maintaining real-time inference speed. The incorporation of the MAConv, BELAN and AELAN modules contributed to the enhancement of the network’s performance in various aspects. Future work can focus on improving the network’s efficiency and performance further.
4.3. Exclusive Performance Comparison Experiments
In order to better demonstrate the advantages of YoloPd in recognizing smaller penguin compared to other SOTA method, we define
to record the rate of detected penguins whose pixel size range in
to labeled penguins, it is calculated as following:
where
and
represent the number of predicted penguins that are true positive samples and labelled penguins, respectively. The pixel size is range in
.
As shown in
Table 7, we conducted an experiment to compare the accuracy of Yolov7 (ELANet-l) and YoloPd in identifying penguins of different sizes. The former cannot recognize tiny penguins with pixels less than five, while YoloPd can accurately locate 4.8% of penguins that have been labelled. As pixels increase to 6–10, YoloPd outperforms Yolov7 in
by 2% even though small penguins still provide limited information. When the pixel of the penguin is greater than 10, YoloPd can locate 98.6% of labelled penguins resulting in better recognition performance in detecting small objects. While YoloPd shows lower accuracy than Yolov7 in detecting larger penguins, it displays better average accuracy, which suggests that improving the detection performance of large objects could be a viable direction for subsequent optimization.
In addition, to evaluate our net’s ability of filtering out interference from complex backgrounds, we visualize the heat maps of the output feature (
) from YoloPd and Yolov7 in
Figure 14. From the three scenes with different backgrounds, it is apparent that YoloPd can rapidly capture penguin features and separate them from complex backgrounds. Specifically, in the white snow area (a), Yolov7 assigns more weight to cracks with color features similar to the penguins, while our network is able to accurately locate each penguin, resulting in higher recognition accuracy. In the rock areas (b) and (c), as previously mentioned, many black stones and their shadows have features extremely similar to the penguins, which confuses Yolov7’s ability to recognize them and leading to many false detections. However, YoloPd learns the global features of the interaction between penguin and their surroundings, thus greatly reducing the occurrence of missed and false detections. Furthermore, we also observed that when the background texture becomes more complex, such as having many scratched stones or cracked ice surfaces, YoloPd assigns relatively more attention to these backgrounds due to its ability of extracting low-frequency texture information. Fortunately, the attention weight of these backgrounds was much lower than that of the penguins we are interested in, so they could not significantly affect the detection performance.
4.4. Stability and Robustness Verification Experiments
As widely acknowledge, the quality of remote-sensing data is crucial to the recognition results. To ensure high-quality data, we employed the most advanced camera available. However, in the actual shooting process, external conditions such as camera, lighting and weather may significantly affect the quality of the captured images. To validate the stability of our proposed YoloPd, we follow the method in Ref. [
38] and convolve the original images with Gaussian kernels of different sizes to simulate real-world situations to reduce the image quality. Specifically, we construct the blurred datasets by Gaussian kernels of sizes 3 × 3, 5 × 5 and 7 × 7. For clarity, we denote the original dataset as
and the blurred dataset as
, where
respectively, corresponding to different levels of blurriness.
We train them on Yolov7l and YoloPd as presented in
Table 8. Our analysis reveals that as image quality deteriorates, Yolov7’s performance remains comparatively steady without any notable metric drop, whereas accuracy falls noticeable in YoloPd from validation set. Conversely, despite such shortcomings, YoloPd outperform yolov7 in terms of performance when tested on similar datasets. Results given in
Figure 15, visualizing the effects of Gaussian Blur value, show that YoloPd can efficiently handle guillemot count requirements, as advancements in technology have significantly reduced the occurrence of images with low clarity levels. Moreover, our methodology leaves ample room for future improvements.
To evaluate the robustness of YoloPd and its ability to predict small targets from complex backgrounds, further experiments are conducted on other datasets. Since similar animal detection data are not publicly available and to ensure that the targets have similar sizes to penguins, we select the smallest category “small vehicle” in the DOTA dataset. The data processing followed the same procedure as the penguin detection dataset, where the images are cropped to a size of 640 × 640. A total of 9206 training set images and 2779 validation set images are obtained.
Table 9 presents the experimental results of Yolov7 and YoloPd.
From results available it can be seen that YoloPd surpasses yolov7 by around 0.9% on F1 metric while demonstrating comparable mAP values. Although YoloPd doesn’t perform well for detecting cars as guillemots yet it possesses advantages in statistical smaller object counts. With respect to larger targets like discussed before. it may perform relatively lesser than Yolov7, but still satisfies our needs for counting penguins.
Meanwhile, it can be observed that our penguin detection dataset belongs to the category of small sample datasets, compared to the DOTA dataset, which has a training set of 9000 images. Generally speaking, networks trained on large datasets demonstrate enhanced robustness and accuracy on the same dataset, avoiding the problems of underfitting and overfitting. Fortunately, through careful selection, our validation set and training set have no overlap, achieving a better ratio of training set to validation set. This highlights the network’s adaptability to new scenarios, even with a smaller dataset. Therefore, overfitting is not a concern due to the smaller dataset size. Consequently, exploring methods to expand the dataset is also a direction for our future research.
5. Conclusions
In summary, our study showcases the effectiveness of automatic object detection in counting penguins from aerial remote-sensing images. Unlike traditional datasets, our dataset presents its own set of challenges, such as tiny penguins with intricate backgrounds. However, we are able to address these obstacles by introducing our novel object detection network, YoloPd, which is specifically designed to balance accuracy and speed. Our results show an impressive average counting accuracy of 94.6% across 18 images using YoloPd. This work highlights the potential of automatic object detection as a good automatic detection and identification tool for the Antarctic penguins. It can be used in practice to save human time, create new training data and establish initial, rapid population counts, with human verification of detected individuals as post-processing. Meanwhile, we also aim to apply our research to the study of species closely related to the Antarctic climate, such as seals, migratory birds and other organisms, with the commitment to accurately detect climate change and protect Antarctic wildlife.
However, there is still much potentials for improvement. Our dataset, in comparison to the commonly used remote-sensing dataset DOTA, is not sufficiently large to ensure solid interpretability. Therefore, further collection and annotation of penguin images is required, likely on a multi-year basis, to expand the dataset and improve accuracy as well as robustness. Additionally, improving the accuracy of large penguin detection is also a key optimization direction for us, so we can study the evolution of penguin distribution over time. Furthermore, investigation reveals that the number of active penguin nests has a significant impact on the population of penguins. Due to different data collection methods, we are unable to locate the position of nests from the images. In our future work, we aim to obtain high-quality, utilizing a combination of activate nest counting and individual counting methods to accurately detect population changes.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}