1. Introduction
As a new active remote sensing technology, Light Detection and Ranging (LiDAR) technology has been developing very rapidly in recent years. Compared with the traditional passive optical remote sensing measurements, LiDAR technology can obtain data quickly and accurately [
1]. Moreover, it is less affected by the external light conditions and can obtain laser pulses from the earth around 24 h [
2,
3,
4]. The laser pulses emitted from the LiDAR system can partially penetrate the vegetation canopy to the ground [
5,
6]. Thus, the three-dimensional (3D) structure of the canopy and the terrain under the forest can be measured [
7,
8,
9]. Therefore, LiDAR technology has more advantages in detecting the structure and function of the forest ecosystem. Nowadays, terrestrial LiDAR has become an important technique for forest resource surveying and monitoring [
10,
11,
12,
13].
In forest resources, individual trees constitute the basic units of the forest. Their spatial structure and corresponding vegetation parameters are the main factors of forest resource surveying and ecological environmental modeling [
14]. Individual tree extraction is the process of realizing the recognition and extraction of single trees from LiDAR point clouds [
15,
16], which is the premise and basis for estimating vegetation parameters, such as spatial position [
17], tree height [
18], diameter at breast height (DBH) [
19], and crown diameter [
20,
21], etc. Traditional measurements usually adopt tape, caliper or altimeter to measure the tree parameters manually. Obviously, the process is labor-intensive and time-consuming [
22]. As a contrast, terrestrial LiDAR technology can measure the 3D spatial structure of trees by obtaining backscattered signals from laser pulses. Then, individual trees can be segmented from the LiDAR point clouds and vegetation parameters can be estimated subsequently [
23,
24,
25]. However, the individual tree segmentation is still prone to over-segmentation or under-segmentation, especially in densely distributed vegetation areas. Inaccurate individual tree extraction results will seriously affect the subsequent vegetation parameters to be estimated. Therefore, it is of great practical significance and production application value to explore an accurate, efficient and robust method of individual tree extraction.
Generally, the individual tree extraction methods can be divided into two classes, namely raster-based and point-based methods [
26,
27]. The raster-based methods need to first calculate the canopy height model (CHM). The CHM can be obtained by calculating the difference between digital surface model (DSM) and digital terrain model (DTM). The DSM is generated by interpolation of 3D point clouds data, while the DTM is acquired by applying point clouds filtering methods [
28]. Then the classical two-dimensional (2D) image processing methods, such as local maximum methods, region growing methods and watershed segmentation methods, can be adopted to detect treetops and extract individual trees [
29,
30]. Hyppa et al. [
31] presented a region growing method to extract individual trees. CHM is first filtered by low pass convolution to remove noise points. Then the local highest points are selected as the seeds for growing individual trees. Chen et al. [
32] proposed a marker-based watershed segmentation method. In their method, treetops were first detected from CHM using the windows with varying sizes. The treetops were then used as markers to prevent over-segmentation when the traditional watershed segmentation method was employed. Mongus and Žalik [
33] also used the marker-based watershed segmentation method for the individual tree extraction. However, in the implementation, the treetop acquisition was realized by applying the local surface fitting to CHM and detecting the concave neighborhood. Yang et al. [
34] pointed out that the interpolated CHM often losses the 3D information of vegetation. To improve the accuracy of individual tree extraction, the authors combined the marker-based watershed segmentation method with the 3D spatial distribution information of point clouds. Generally speaking, the raster-based individual tree extraction method has high implementation efficiency. However, it is prone to over-segmentation or under-segmentation when using traditional image segmentation methods. In addition, it is not easy to detect undergrowth in forest areas covered by multiple layers [
35].
The point-based methods do not need to transform the 3D point clouds into the 2D raster images. This kind of method can directly cluster the LiDAR points to realize the individual tree extraction. Many experts apply the Mean shift methods for extracting individual tree [
8,
29,
35,
36]. The Mean shift is a kernel density estimation algorithm, which clusters point clouds by iterative searching for modal points [
37]. Compared with raster-based methods, the Mean shift methods extraction performance is greatly influenced by fine-tuning several parameters, such as kernel shape, bandwidth and weight. Ferraz et al. [
38] have investigated the influence of kernel function parameters on the results of individual tree extraction. In their study, a cylindrical kernel function was applied to segment individual tree. To make the points within an identical crown converge to the vertex position of the crown by mean shift vector, the kernel function is divided into horizontal domain and vertical domain. By setting different bandwidth functions, the horizontal kernel function can detect the local maximum of density and the vertical kernel function can detect the local maximum of height. For multi-level covered tropical forest areas, Ferraz et al. [
39] proposed an adaptive Mean shift individual tree segmentation method. Here, the effect of the bandwidth parameter on the results of individual tree segmentation in the Mean shift method was investigated. In their work, the bandwidth of the kernel function can be adaptively adjusted according to the allometric growth function. Dai et al. [
36] also applied the Mean Shift method for extracting individual trees. Both spatial and multispectral domains are adopted for solving the under-segmentation phenomenon. Generally, the bandwidth parameter has a great influence on the results of individual tree segmentation in the Mean shift method. Chen et al. [
40] first extracted the trunk and then estimated the bandwidth with the spatial location information of the trunk to obtain accurate bandwidth parameters.
In addition to the Mean Shift-based methods, some other researchers realize the individual tree extraction based on the geometric characteristics. For instance, Li et al. [
41] separated individual tree according to the horizontal spacing between trees. The points belonging to a tree can be added gradually if its relative spacing is smaller than that of other trees. Zhong et al. [
42] first conducted spatial clustering to point clouds based on octree node connectivity. Then, tree stems were detected by finding the local maxima. According to the extracted tree stems, initial segmentation can be achieved, which will be further revised based on Ncut segmentation. Xu et al. [
14] proposed a supervoxel approach for extracting individual tree. In their method, point clouds are first voxelized to be supervoxles. Then, the individual trees are extracted based on the minimum distance rule. Although the point-based methods do not need to convert 3D point clouds into 2D raster images, these methods require iterative calculation and thus computationally expensive. Besides, when encountering large amounts of point clouds, the clustering process becomes time-consuming. In addition, many parameter settings and adjustments make implementation of the methods not conducive.
It has generally been recognized that the performance of the existing individual tree extraction methods are still not good especially when encountering complex forest environments. In continuance of that, many methods involve complex parameter settings which reduce the degree of automation of the methods. To tackle these problems, this paper proposed an individual tree extraction method based on the transfer learning and Gaussian mixture model separation. In this method, transfer learning and Gaussian mixture model separation were combined for extracting accurate individual tree, which will provide a good foundation for forest parameters estimation.
The main contributions of this paper are as follows:
Transductive transfer learning was applied to extract the initial trunk points based on linear features, which shows that trunk points can be extracted effectively using the constructed model even if no training samples are selected from the target domain.
Accurate number of clustered components was achieved by first conducting PCA transformation on the canopy points followed by kernel density function estimation. In doing so, the parameter setting to determine the number of clusters is eliminated.
The mixed canopy points were assumed to be Gaussian mixture model. By separating Gaussian mixture model using Expectation-Maximization algorithm, the canopy points for each individual tree can be extracted automatically.
Point density barycenter is proposed and used to help optimize over-segmentation canopy points. Hereafter, trunk points are optimized based on the vertical continuity in a top-down manner.
The remainder of this paper is organized as follows.
Section 2 describes the main principle of the proposed method.
Section 3 shows the experimental results and comparison analysis.
Section 4 makes a discussion. Finally, the main findings of this paper are summarized in
Section 5.
2. Methodology
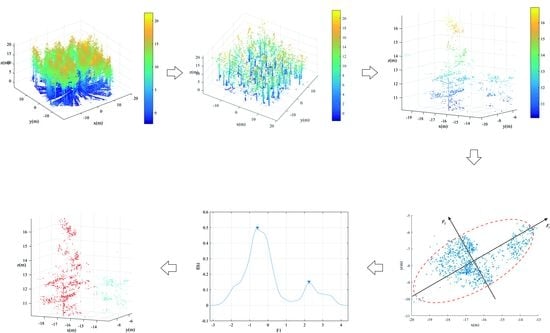
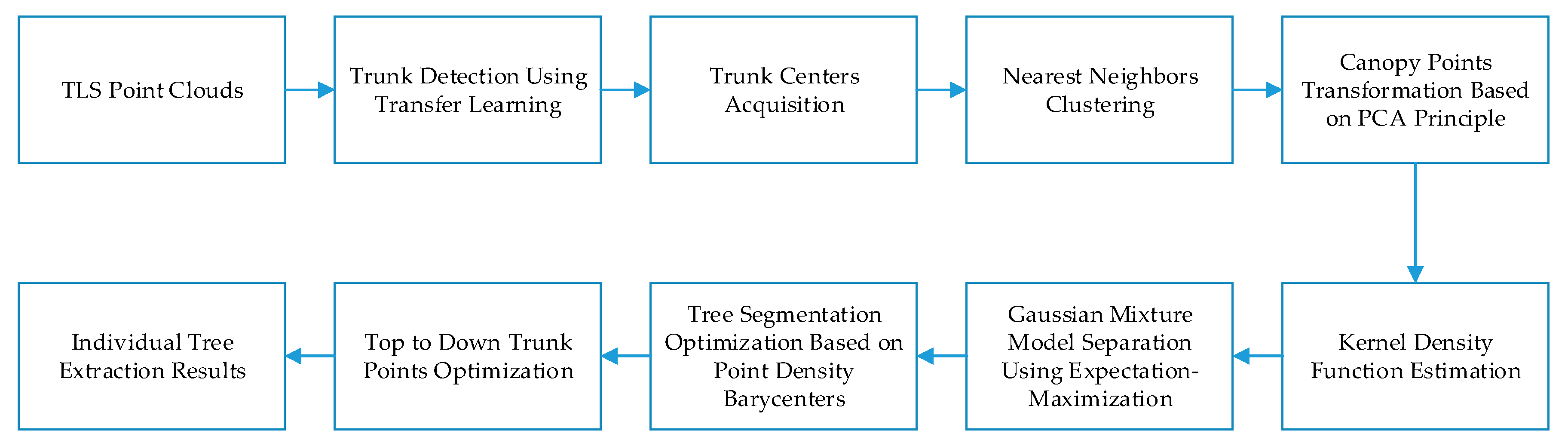
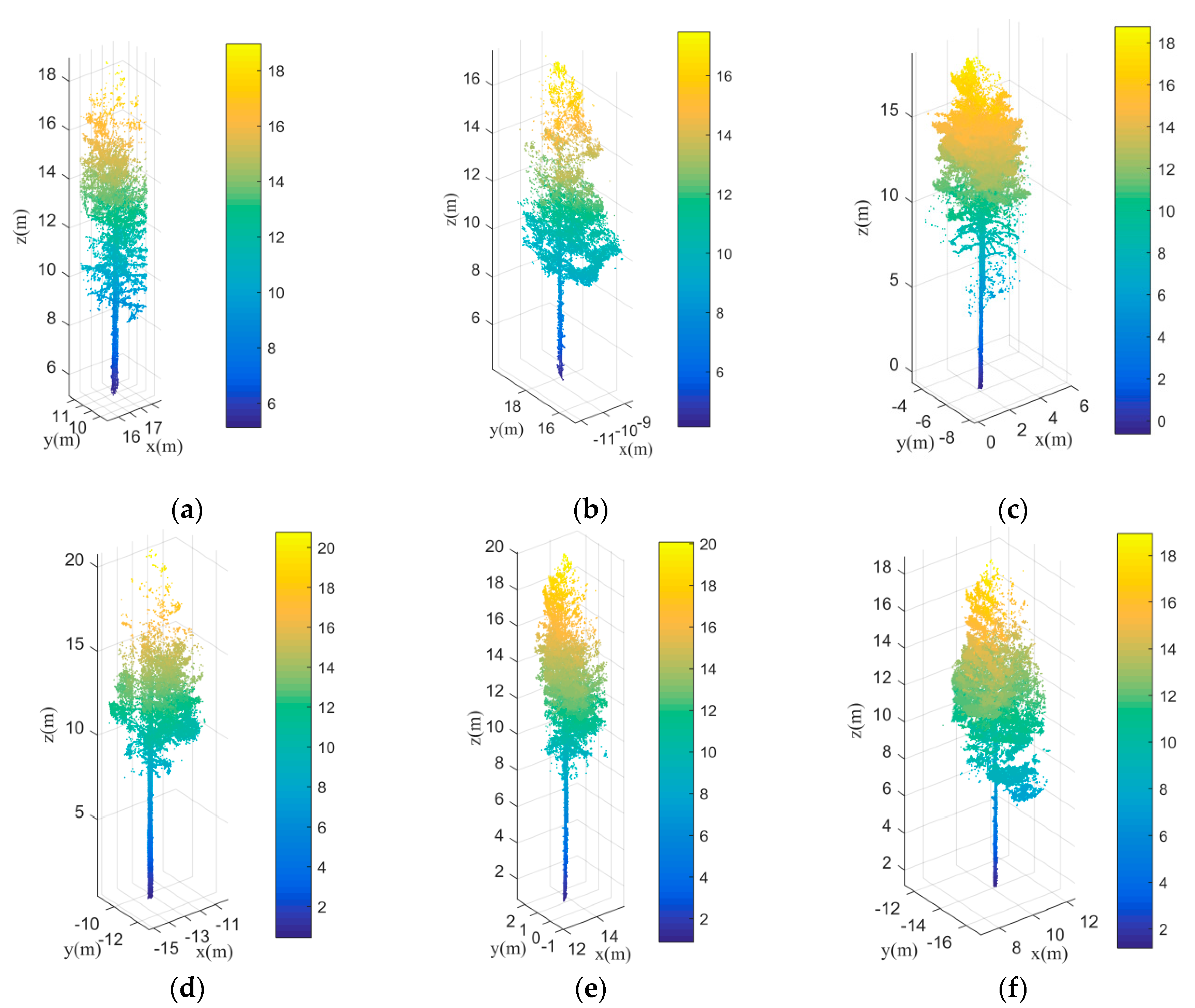
The flowchart of the proposed method is shown in
Figure 1. In this method, only coordinates information of LiDAR point clouds are required. Prior to trunk detection, the LiDAR points are filtered to remove the influence of ground points. This paper adopted an improved morphological filtering method proposed by Hui et al. [
43] to remove ground points. The filtering method is a hybrid filtering model which combines the strength of the morphological filtering and surface interpolation filtering methods. After removing the ground points, the trunk points were extracted using the transductive transfer learning, which was followed by trunk centers acquisition based on vertical continuity principle. According to the trunk centers, the initial point clouds segmentation results can be obtained using nearest neighbor clustering. Obviously, the initial segmentation is generally under-segmentation especially for canopy points. To separate the canopy points correctly, projection transformation was first conducted on the canopy points based on the PCA principle. The number of clustered components within each initial segmentation part was then determined by kernel density function estimation. Hereafter, Gaussian mixture model separation was applied to isolate canopies for each tree. To avoid over-segmentation of the canopies, point density barycenter was proposed and used to optimize the canopy extraction results. Meanwhile, the final trunk points for each tree were extracted in a top-down manner according to the extracted canopies. Detail explanation of the main steps of the proposed method is provided in the subsequent sections.
2.1. Trunk Points Detection Using Transductive Transfer Learning
Transfer learning is a machine learning method that has developed rapidly in recent years. Compared with traditional supervised learning methods, transfer learning can use established learning models to solve problems in different but related fields. There are many examples of transfer learning in nature. For example, if a person learns to ride a bicycle, it is relatively easy for him to learn to ride an electric bicycle. According to whether there are sample markers in the source and target domains, transfer learning can be divided into three categories, including inductive transfer learning, transductive transfer learning and unsupervised transfer learning. In this paper, transductive transfer learning is applied since we want to use the established training model to classify trunk points from new datasets without sample markers. The advantage of using transfer learning to classify trunk points is that it can make full use of the existing point clouds marking information, which can avoid training sample marking in the target domain. Obviously, sample marking is usually the most time-consuming and laborious.
Although the forest types in the datasets of the source and the target domains may be different, trunks and leaves will still present significantly different geometric features in their natural state. For instance, trunk points generally present linear geometric features, while leaf points are usually scattered distribution. Therefore, this paper mainly uses the geometric feature vectors to establish the training model to avoid the phenomenon of “negative transfer”. In this paper, five geometric vectors namely linearity, planarity, scatter, surface variation and eigen entropy were obtained by calculating the covariance tensor of the local points. Since the random forest (RF) is simple, easy to implement and low computational cost, this paper adopts RF to build a training model for transfer learning. The detailed way for calculating the mentioned five geometric vectors are as follows:
All the points are traversed one by one. For each point
all the points within its
distance are selected as the neighboring point sets
. The point set is used for calculating the covariance tensor
, which can be calculated using Equation (1):
According to Equation (1), three eigenvalues
and corresponding eigenvectors
,
,
were calculated. The three eigenvalues need to be normalized that is,
. According to these three eigenvalues the above-mentioned five geometric features were calculated, which are tabulated in
Table 1. Using these five geometric features the training model can be built using the datasets with marker information.
2.2. Components Number Estimation Based on Kernel Density Function
2.2.1. Trunk Centers Optimization and Nearest Neighbors Clustering
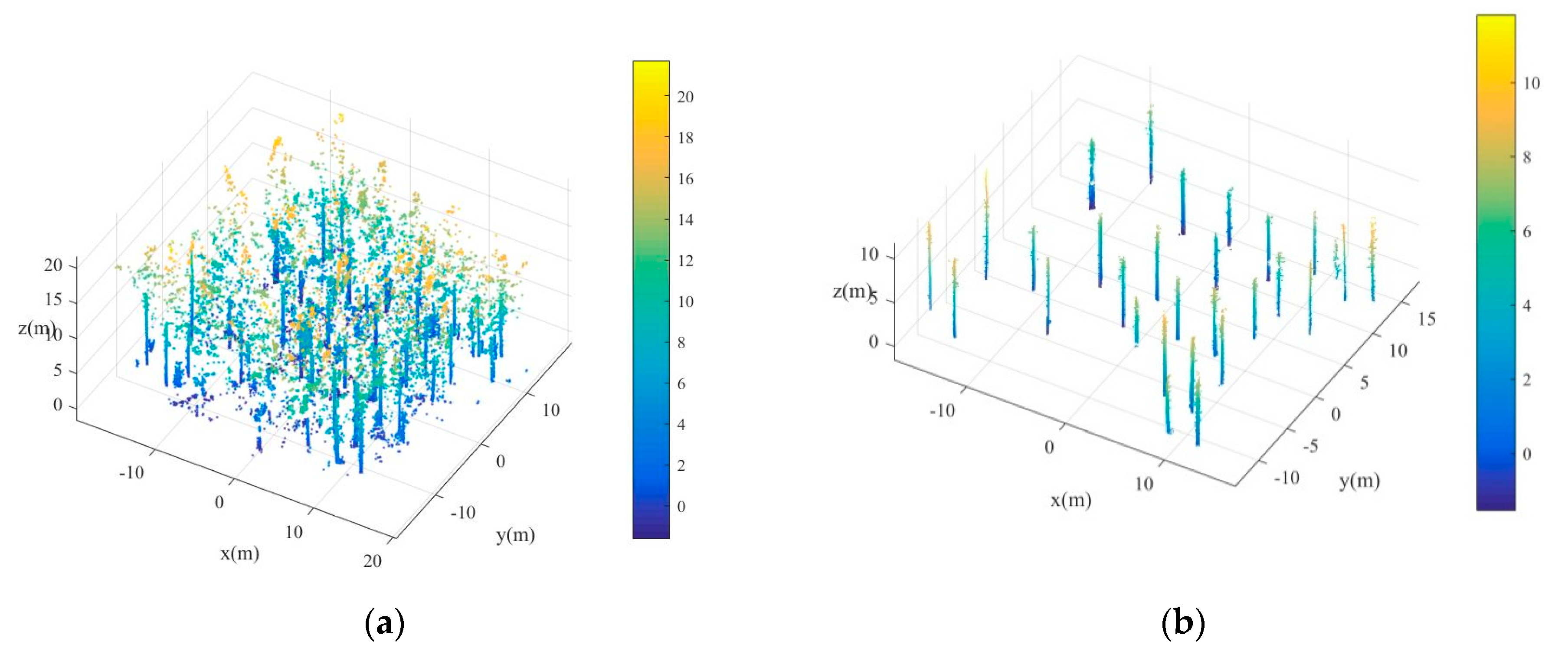
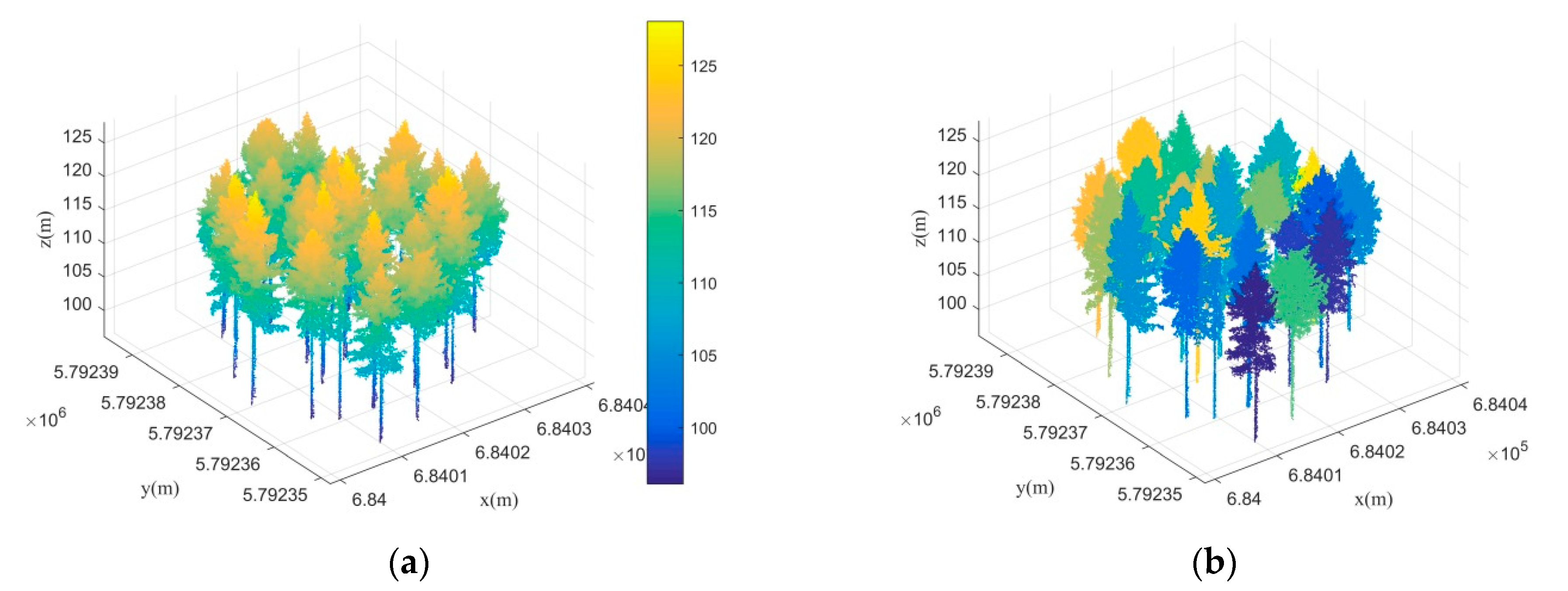
As shown in
Figure 2a, after trunk points extraction by transductive transfer learning, there are still some leaf points were misjudged as trunks. Compared with the trunk points, there is no continuity in the vertical direction for the misjudged leaf points. Moreover, the misjudged leaves tend to be scattered and isolated points. According to these two characteristics, this paper removed the misjudged points gradually. The detailed steps are described in
Appendix A.
Figure 2b is the optimized trunk points after eliminating misjudged points of
Figure 2a. As shown in
Figure 2b, although most of the misjudged points were effectively removed after the trunk points optimized processing, some burr points still existed on the trunk points. These burr points are mainly formed by branches around the trunk and need to be removed to achieve accurate calculated trunk centers. The detailed steps for trunk centers optimization are described in
Appendix B. After the trunk centers were calculated, the initial segmentation can be obtained using the trunk centers as the clustering centers. The points with the closest horizontal distance to the centers were clustered in the same class as that of the trunk center. The initial segmentation result by clustering is denoted by Equation (2),
where
is the initial segmentation for each cluster.
is the
-th turnk centers,
are the point clouds,
is the horizontal distance between two points and
is the number of the trunk centers.
2.2.2. Canopy Points Projection Transformation Based on PCA Principle
The initial tree segmentation results were obtained using the extracted trunk centers. However, the initial segments are prone to under segmentation since the extracted trunk centers generally contain some omission errors. That is, some points belonging to two different trees may be clustered as one segment. Therefore, the initial tree segmentation results need further optimization for achieving better single tree extraction performance.
In this study, the canopy and trunk were extracted separately. To avoid the influence of trunks or low brushes, this study first removes the points below the highest trunk points within each initial segment
for optimizing canopy points. This process can be written as Equation (3),
where
represents the canopy points,
is the point in the initial segment
,
is the number of points within
,
is the
coordinate of
and
represents the maximum elevation of the trunk points.
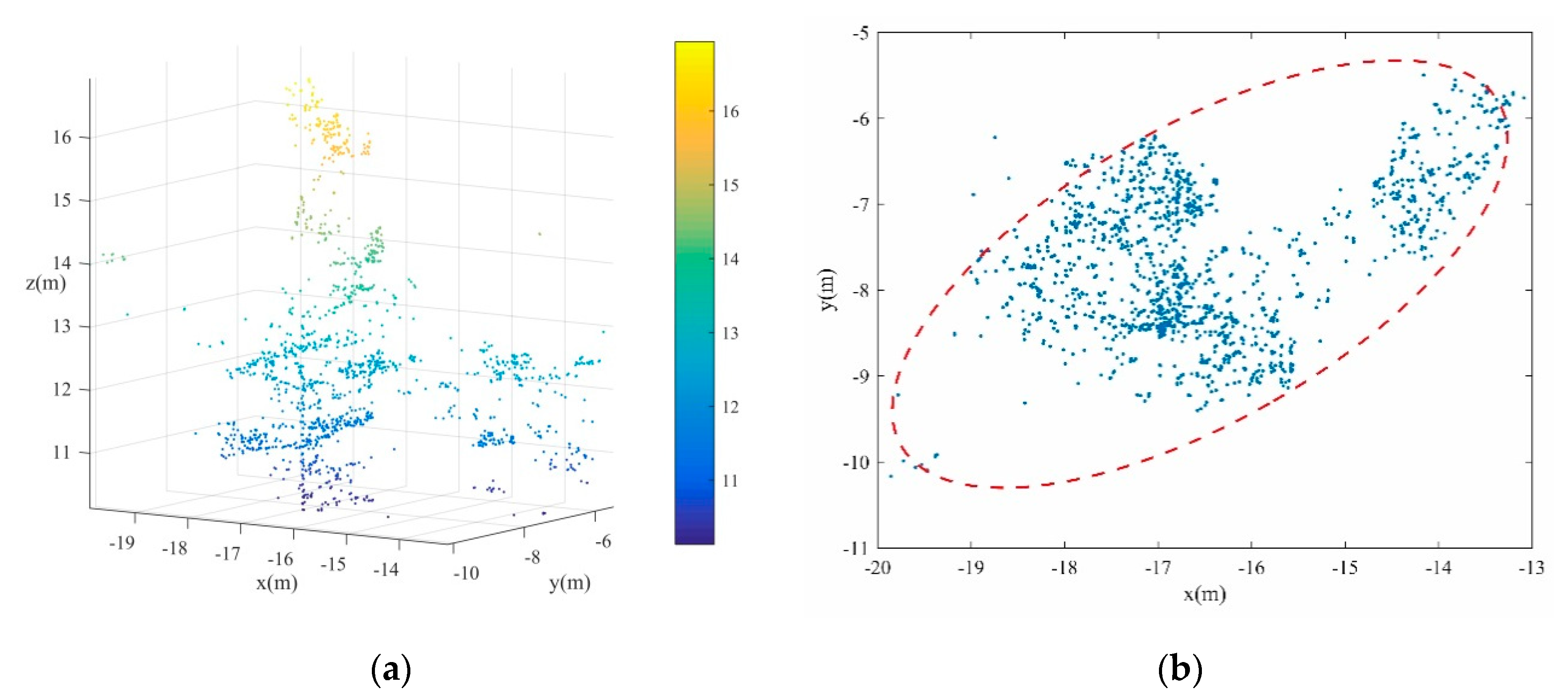
As shown in
Figure 3a, the canopy points of two adjacent trees are prone to be divided together. To achieve better individual tree extraction results, the undersegmented canopy points should be further separated. Generally speaking, the horizontal projection of canopy points of one single tree should be approximately circular. However, if more than one canopy is merged together, the corresponding canopy points’ horizontal projection tends to be elliptic as shown in
Figure 3b.
As can be seen from
Figure 4a, compared with the points distribution in the
x and
y directions, the points are more distinct in the direction of the long axis of the ellipse (
).
Figure 4b is the projection of the points in the direction of the long axis of the ellipse. It is easy to find that the points after projection in
direction are more distinct for separation.
The direction of the long axis of an ellipse can usually be defined as the direction of the first principal component of the PCA method. Therefore, this paper first applied PCA principle to transform the canopy points. To avoid the interference of some isolated points on the calculation of principal component analysis, this paper calculates the number of neighboring points of each point. The points with a smaller number of neighboring points were determined as isolated points and removed. Then, the covariance tensor of each initial segment is calculated according to Equation (1). The eigenvalues and eigenvectors of the covariance tensor were also calculated. The direction of the eigenvector corresponding to the maximum eigenvalue is defined as the direction of the long axis of the ellipse, and the points are projected in this direction. The transformation process can be described by Equation (4),
where
is the principal component after the transformation,
is the
matrix, and
,
,
is the coordinates of
in the
(Equation (3)),
is the total number of points that in the cluster.
is the eigenvector matrix of the cluster’s covariance matrix.
2.2.3. The Number of Components Determination Based on Kernel Density Estimation
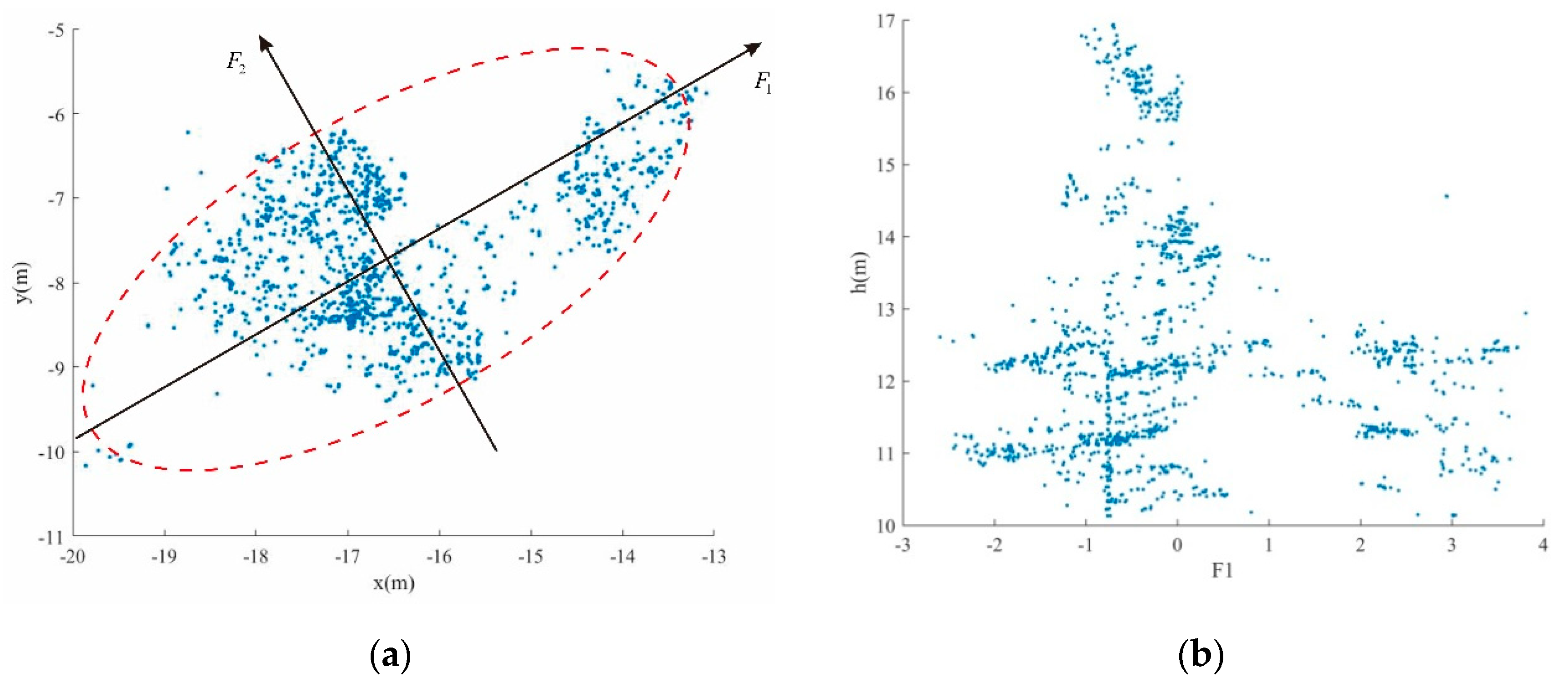
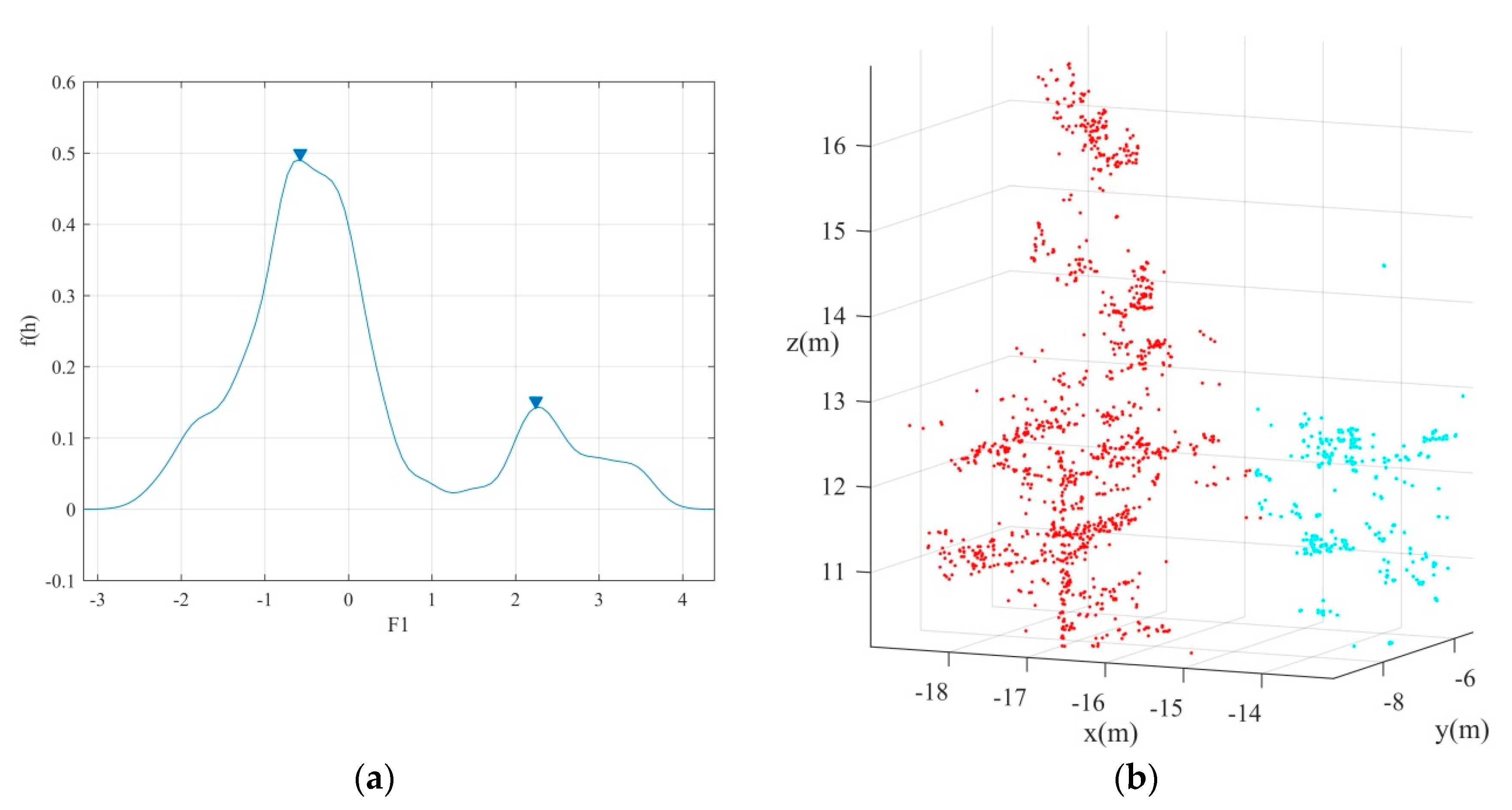
As mentioned above, the initial segmentation results based on the trunk centers are prone to be under segmentation. In other words, there may be more than one tree in one segment. As shown in
Figure 4b, there are two mixed trees that need to be separated. It can also be found that to achieve optimal segmentation of canopies, it is necessary to first determine the number of mixed components within each initial cluster.
From
Figure 4b, it can be found that the point density of the centers of each tree is usually large.
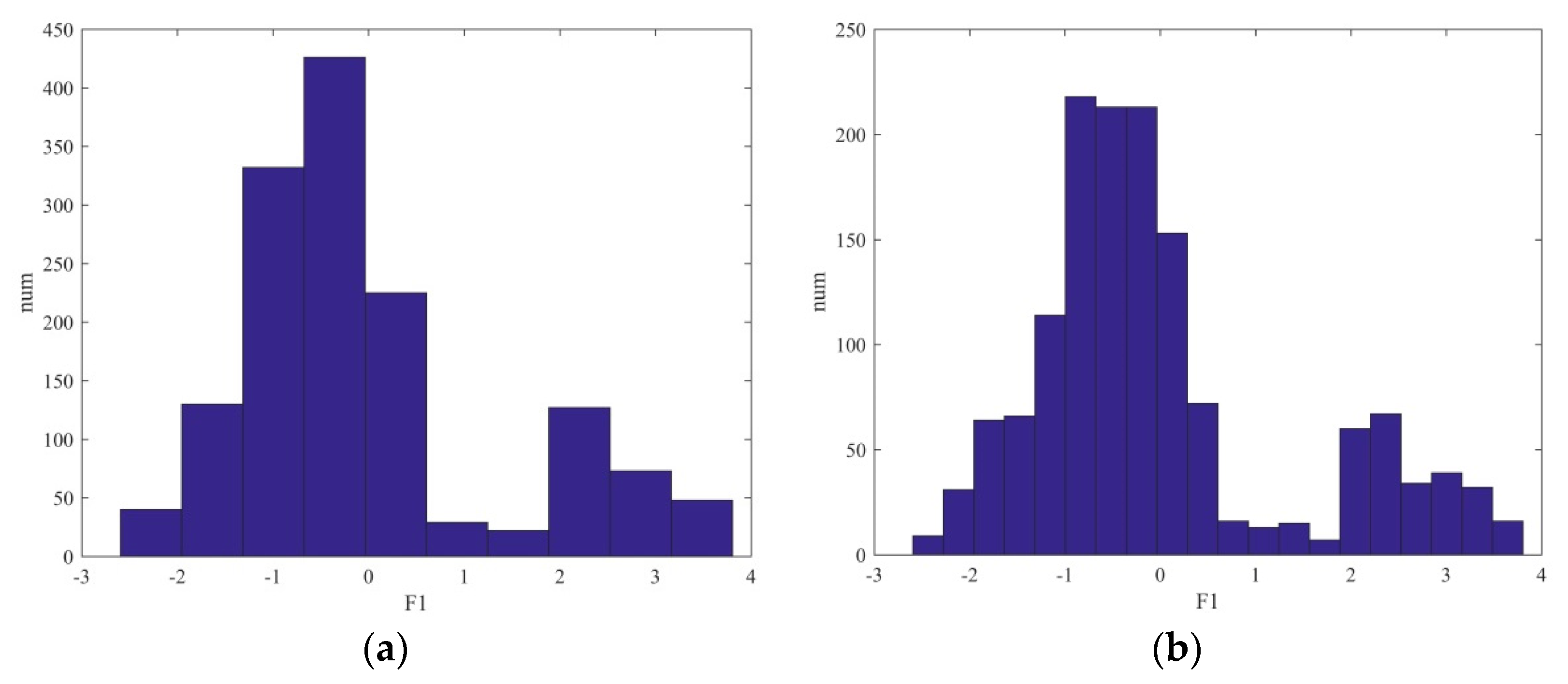
Figure 5a,b are histograms of point density distribution of tree points in
Figure 4b. The difference between
Figure 5a,b is the different statistical interval of point density statistics in the
direction, which is calculated based on PCA principle as described in
Section 2.2.2. It is easy to find from these two figures that the point density from the centers to the two sides shows a downward trend. Therefore, the number of components can be determined by detecting the number of local maxima of point density. To accurately detect the local maximum of point density, the kernel density estimation method was used to calculate the probability density function distribution of each initial segment. The kernel density estimation is defined as Equation (5),
where
is the number of points within each initial segmentation,
is the bandwidth and
is the kernel function. In this study, Gaussian kernel function was used for probability density estimation, which is defined in Equation (6) as:
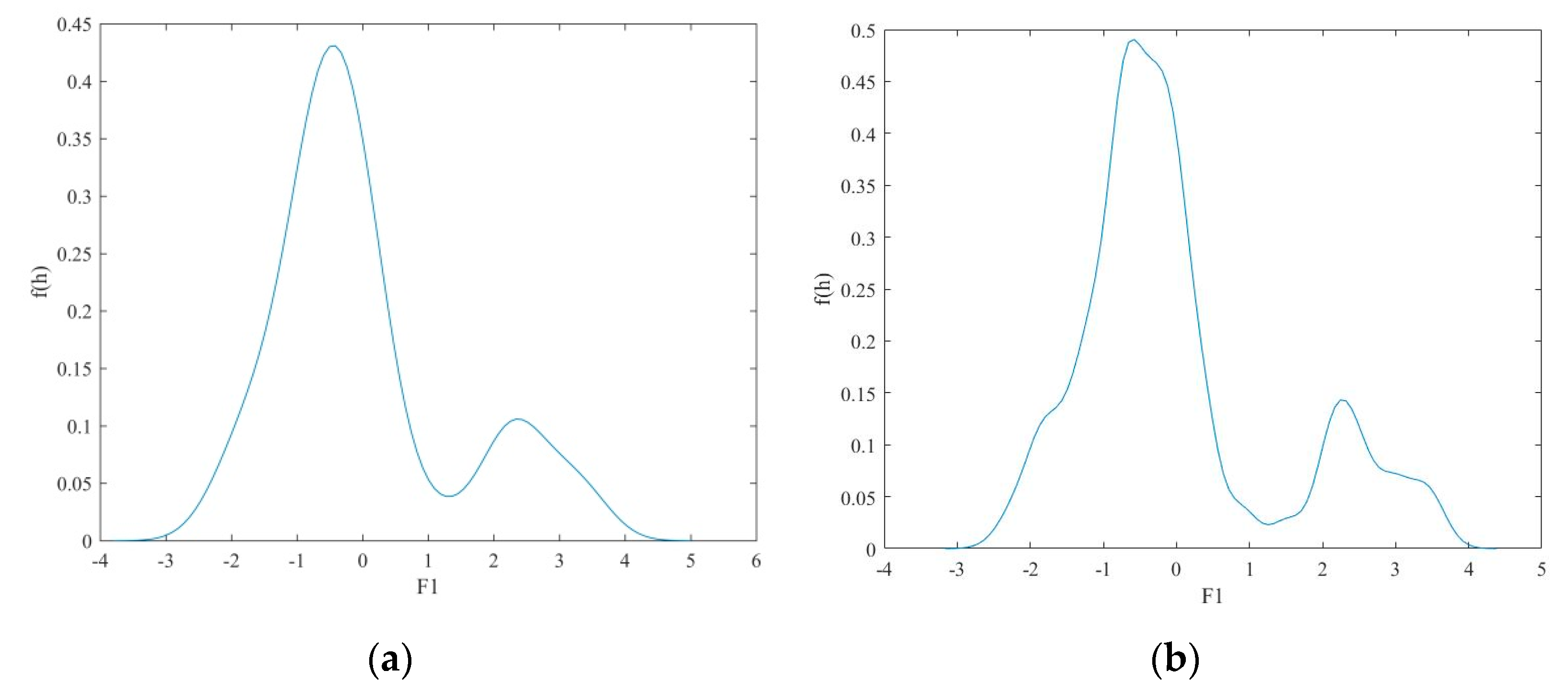
In Equation (5), bandwidth has a great influence on the result of Gaussian kernel density estimation.
Figure 6a,b shows the Gaussian kernel density estimation curves calculated by the points in
Figure 4b with different bandwidth parameters. To achieve accurate Gaussian probability density estimation, this paper applies Silverman’s rule of thumb to perform adaptive bandwidth calculation, which has been defined in Equations (7) and (8),
where
is the bandwidth of the
i-th dimension,
is the dimension, which is equal to 1 in this study and
is the total number of points.
is the estimated value of the standard deviation of the
i-th dimension variable, and
is the median of the absolute value of the residual difference between each variable and the mean value. The constant 0.6745 ensures that the estimation is unbiased under the normal distribution.
2.3. Canopy Points Extraction Through Gaussian Mixture Model Separation
From
Figure 6 it can be found that the kernel density distribution curves of different trees that clustered together can be regarded as a mixture of different Gaussian distributions. Therefore, the optimal segmentation of different trees can be achieved by separating the mixed Gaussian models with different parameters. By detecting the number of local maxima of the kernel density distribution curve, it can be determined that
Figure 4b has two components, as shown in
Figure 7a. Then, the Gaussian mixture model separation method can be applied to divide the mixed canopy points into two clusters.
In general, if the point clouds contain
different clusters of points, the density function of the Gaussian mixture distribution can be written as Equation (9),
where
represents vectors, which are the results of PCA transformation, that is
.
is the mixed components and
is the coefficient of proportion, which represents the prior probability of each mixed components.
are the parameters of the Gaussian distribution, and represent mean value, and variance, respectively. While,
represents the Gaussian density function, which is defined in Equation (10) as:
The expected-maximum (EM) algorithm is used to estimate the parameters of the Gaussian mixture model, which mainly includes the ‘E’ step and ‘M’ step. The ‘E’ step tries to calculate the probability of each component, while the ‘M’ step updates the Gaussian mixture model parameters, including , and , where . is the number of mixed components.
The EM algorithm needs to be implemented repeatedly. The convergence condition of the iteration is that the variation of mixed distribution parameters calculated in the last iteration and calculated in the next iteration must be less than the threshold value, or the number of iterations reaches the maximum. When the EM algorithm stops iterating, the points are divided into categories according to the maximum probability that the points belongs to. The points in
Figure 3a can be optimized as two separated tree canopies as shown in
Figure 7b.
2.4. Over-Segmentation Canopies Optimization Based on Point Density Barycenter
The canopy points extracted by Gaussian mixture model separation may be over-segmentation. In other words, the canopy points of one tree may be segmented as two or more clusters. Moreover, in
Section 2.1, the initial segmentation results were obtained based on the initial trunk centers. Since the initial trunk centers are not correct enough, one individual tree may also be divided into several trees mistakenly. This over-segmentation will not only make the extracted individual trees incomplete, but also lead to larger commission errors.
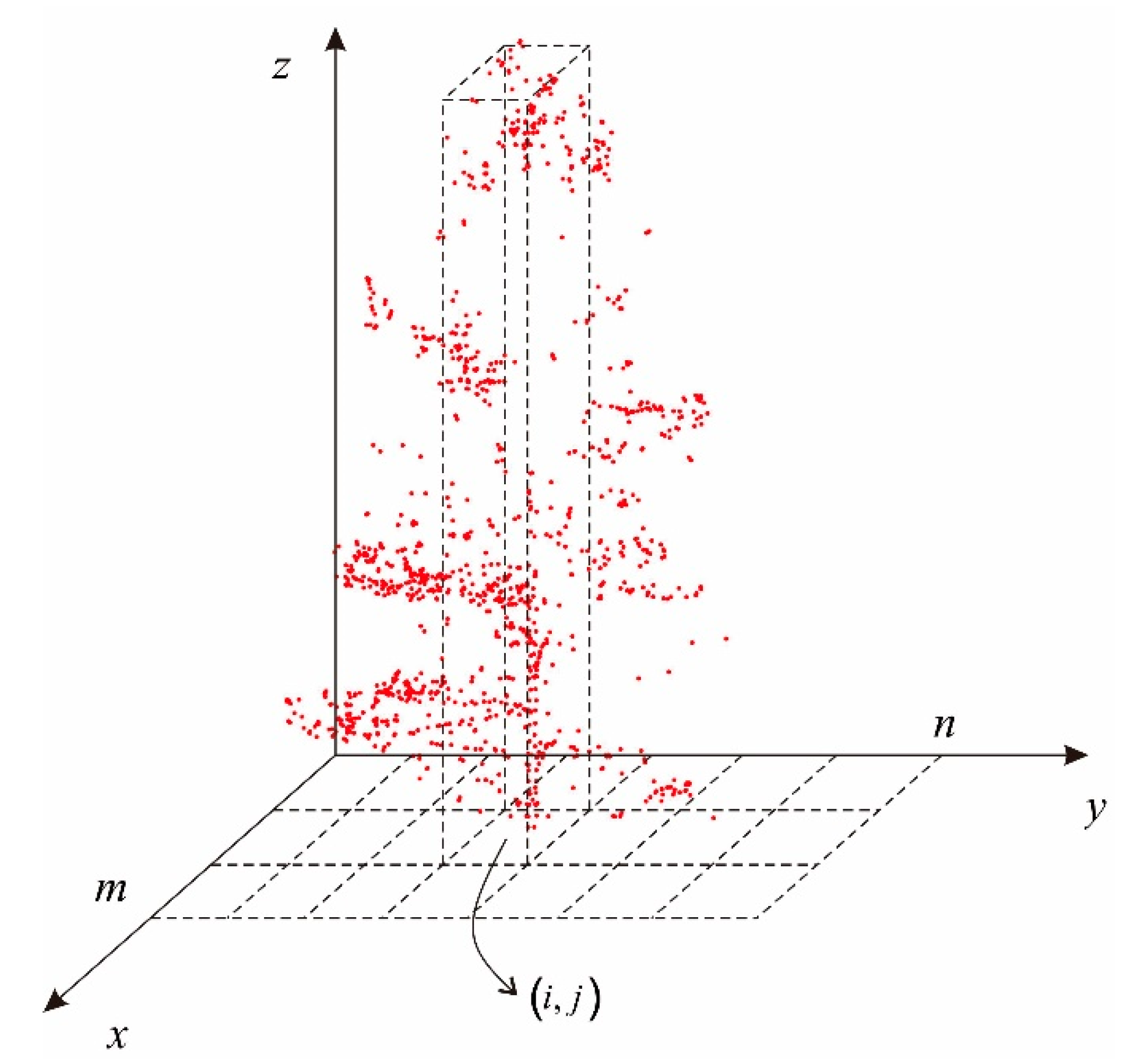
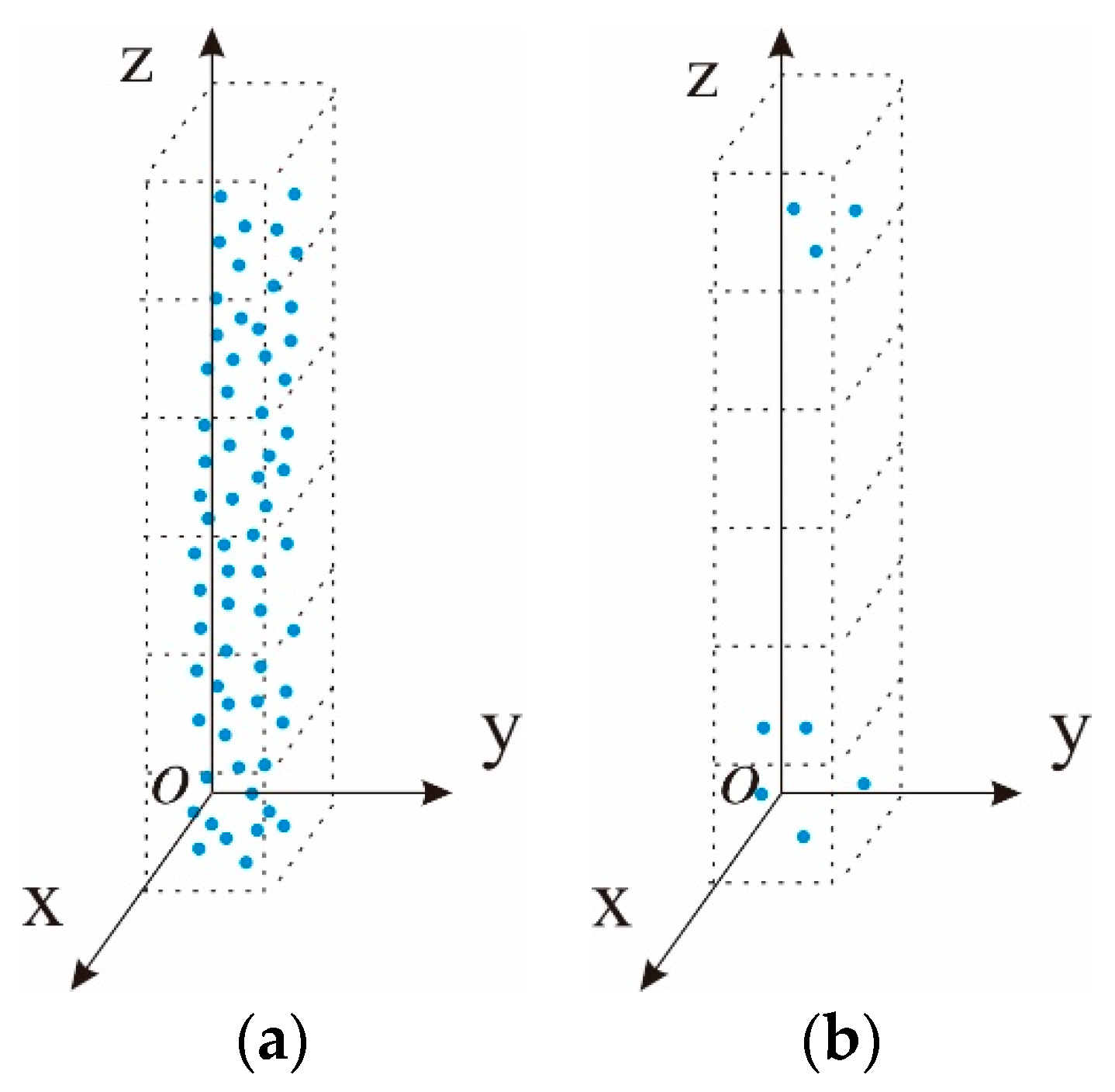
It is important to note that the horizontal positions of over-segmented trees are usually closer. Many researchers merge the over-segmented trees by calculating the horizontal distance of the highest points within each cluster, while some other researchers calculate the mean value of horizontal coordinates of each cluster to determine whether to combine the clusters. The above-mentioned two methods can obtain effective merging results under ideal conditions, such as the highest point of the tree is the vertex position of the tree, and the tree grows uniformly and symmetrically. However, in nature, due to the influence of light and water environments, the distribution of vegetation may be diverse. The highest point’s position or the mean coordinate of all points cannot represent the center of each cluster well. To make the forest optimization and combination method more robust, the barycenter of each cluster was proposed to combine the extracted trees close to each other.
As shown in
Figure 8, the points’ distribution along the vertical direction of the center position of one individual tree is generally dense. Therefore, the planar position with the highest point density is more representative of the central location of the individual tree when comparing with the location of the vertex or mean coordinates of the tree points. In this study, this location is defined as the weighted average of point density distribution after horizontal projection of point clouds, which are represented in Equations (11)–(13),
where
and
are the number of grids after point clouds horizontal projection, as shown in
Figure 8.
is the horizontal coordinate of grid
,
is the coordinate of one point in grid
.
represents calculating the mean value.
is the weight of grid
.
is the number of points with grid
.
2.5. Trunk Points Optimization in a Top-Down Manner
Although trunk points have been extracted by transductive transfer learning in
Section 2.1, the number of extracted trunks is generally less than the reference number of trunks, which always lead to large omission error. To obtain better trunk extraction results, this paper tries to acquire trunk points based on the optimized canopy points for each individual tree that have been extracted in
Section 2.4. Thus, the trunk points extraction method in this paper can also be called a top-down method.
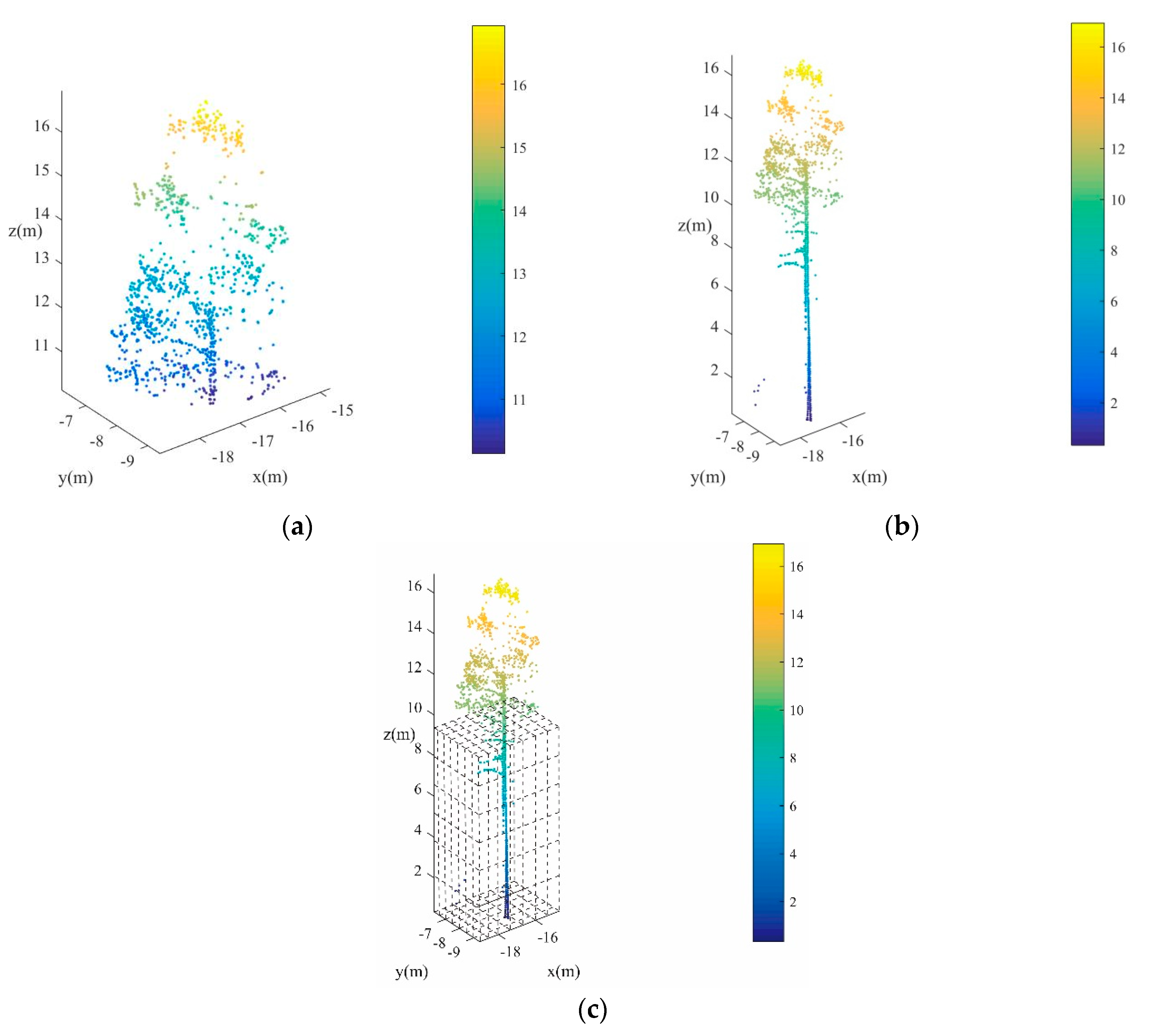
According to the method mentioned in
Section 2.3 and
Section 2.4, the optimized canopy points can be extracted by separating Gaussian mixture model and merging strategy, as shown in
Figure 9a. In this paper, the optimized trunk points are obtained in a top to down manner. Firstly, the horizontal projection range of the canopy points are obtained as
and
. Then, the points under the canopy can be acquired by subtracting the canopy points calculated in Equation (3), which is written as the point set
. Finally, the points within the horizontal projection can be obtained according to Equation (14),
where
represents the canopy points of
-th individual tree as shown in
Figure 9a.
is the points under the canopy of each individual tree.
Figure 9b is the combination of
and
. Obviously, the individual tree has been extracted successfully. However, there are still some low points in the extraction points, which are generally bushes. There points can be removed by voxelizing the point sets
as shown in
Figure 9c. The cubes with points falling in are labeled as 1. The number of cubes in each vertical direction is calculated. The points with poor continuity are filtered.
4. Discussion
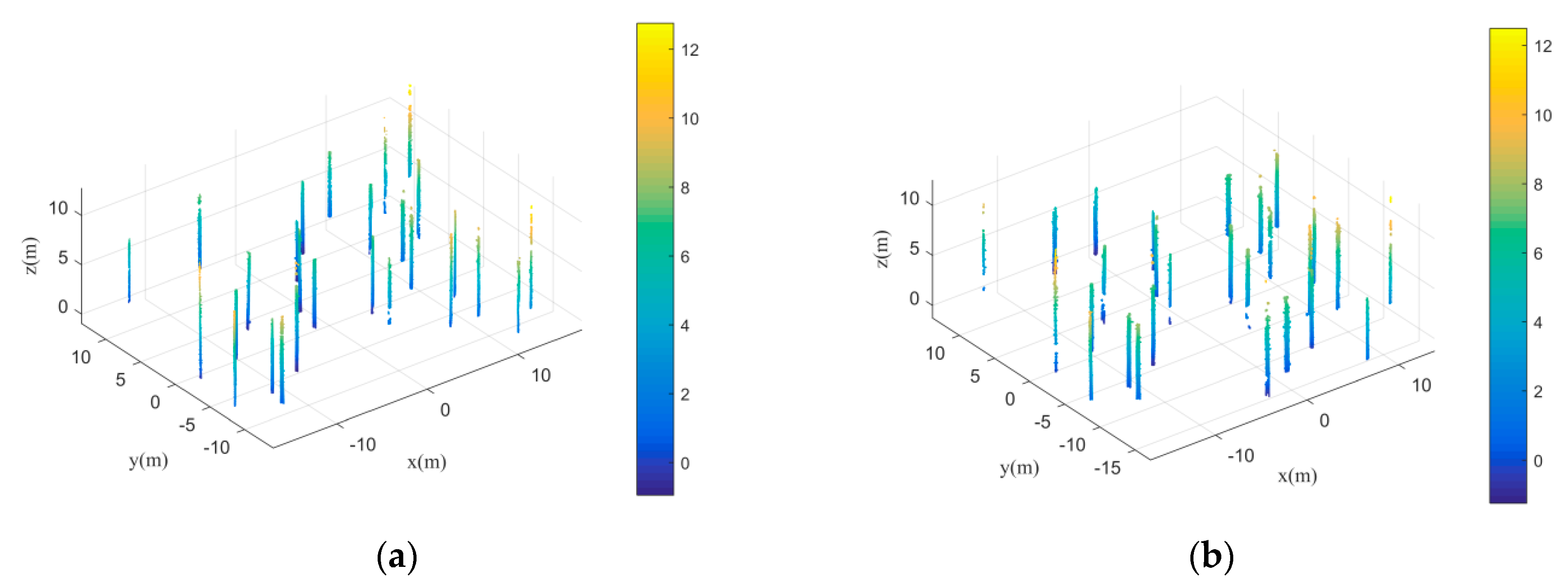
In this paper, trunk stems are first detected by the transductive transfer learning, which are the key to the initial segmentation. It is because the initial segmentation is obtained by nearest neighbor clustering based on the acquired trunk stem centers.
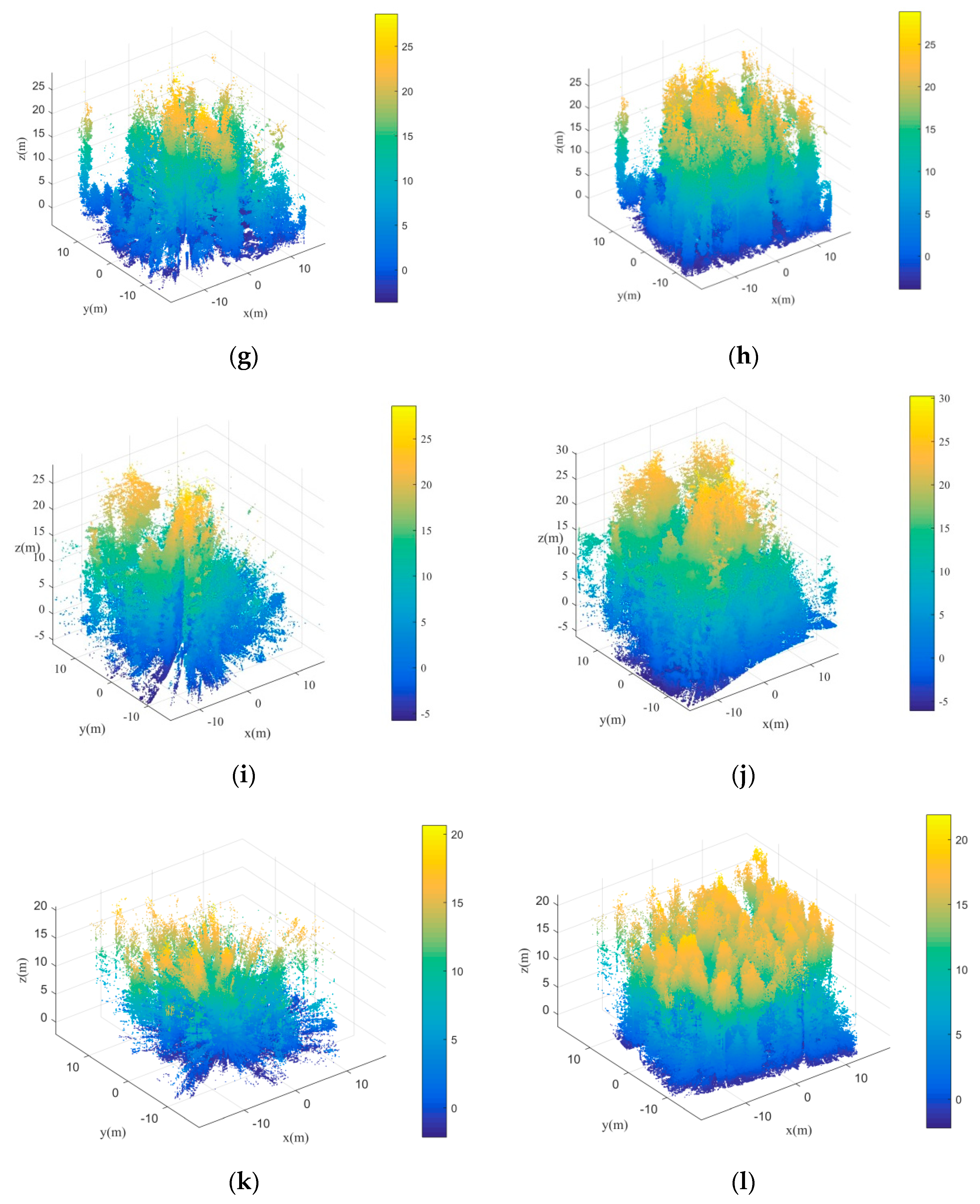
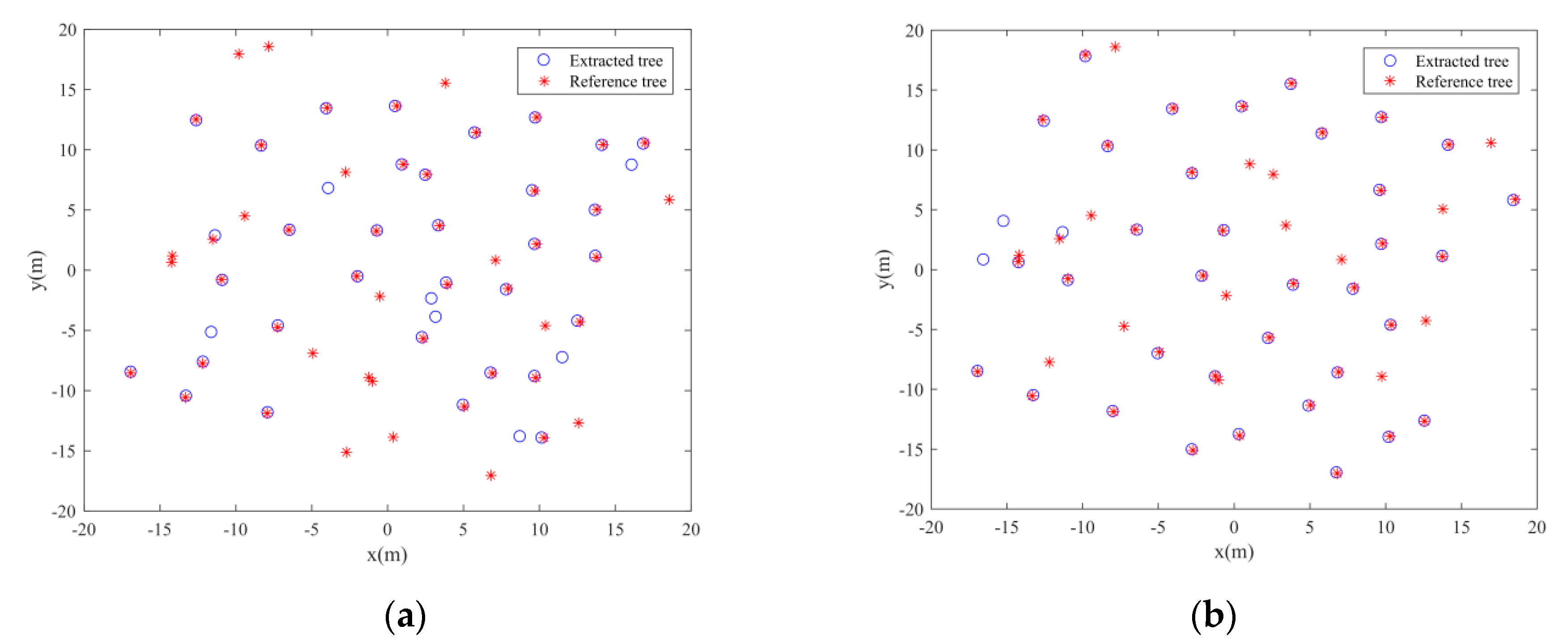
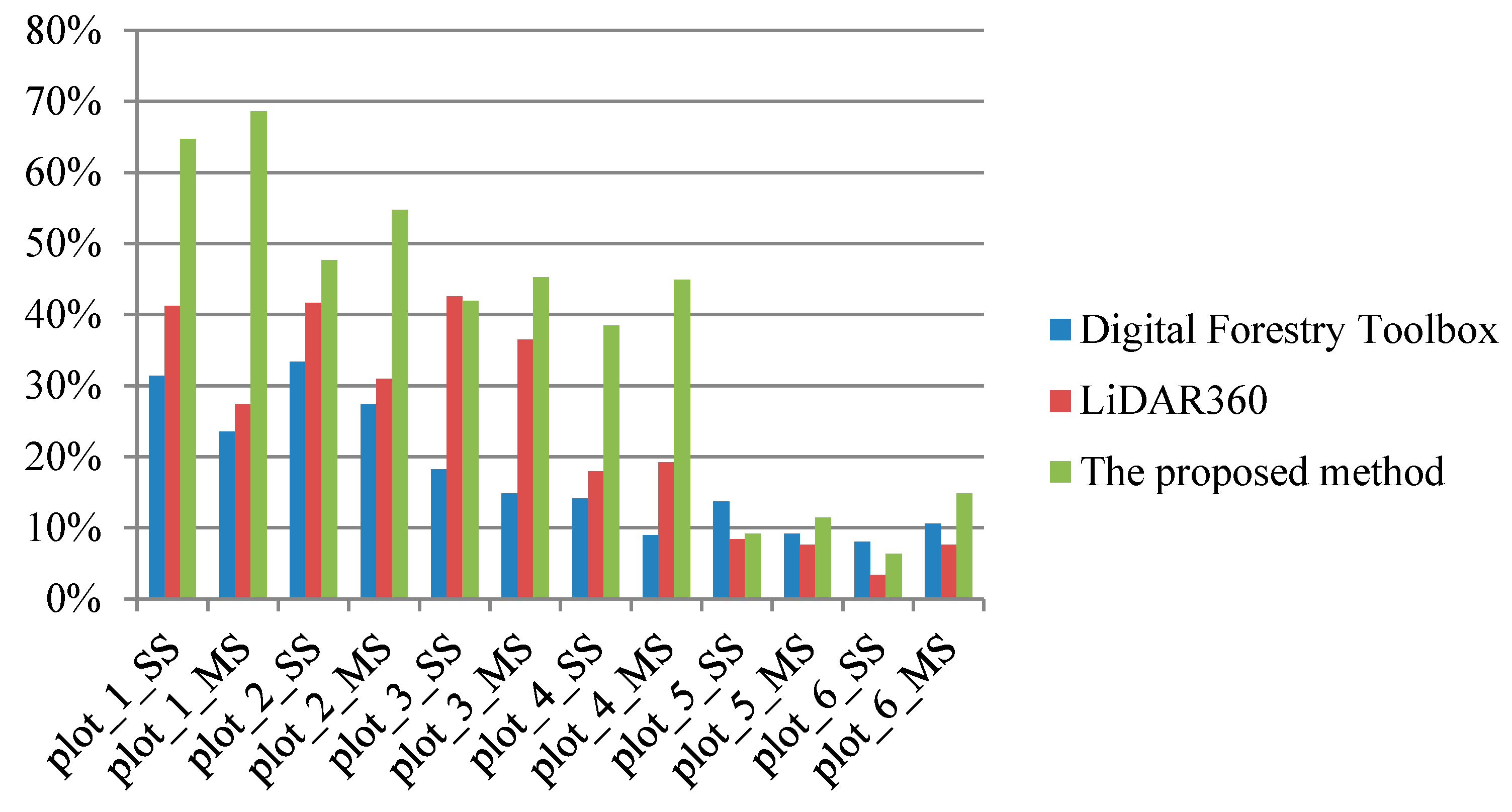
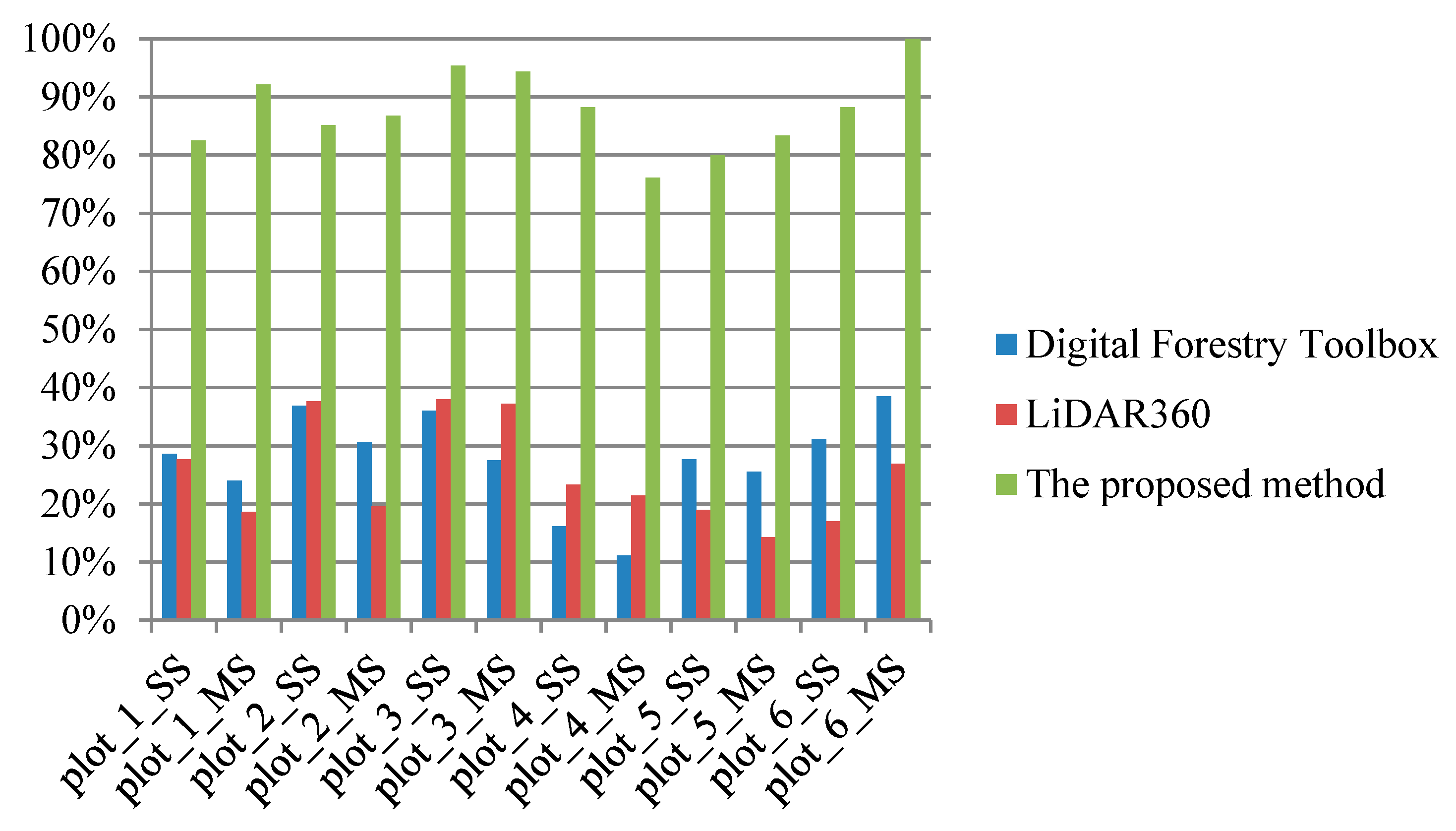
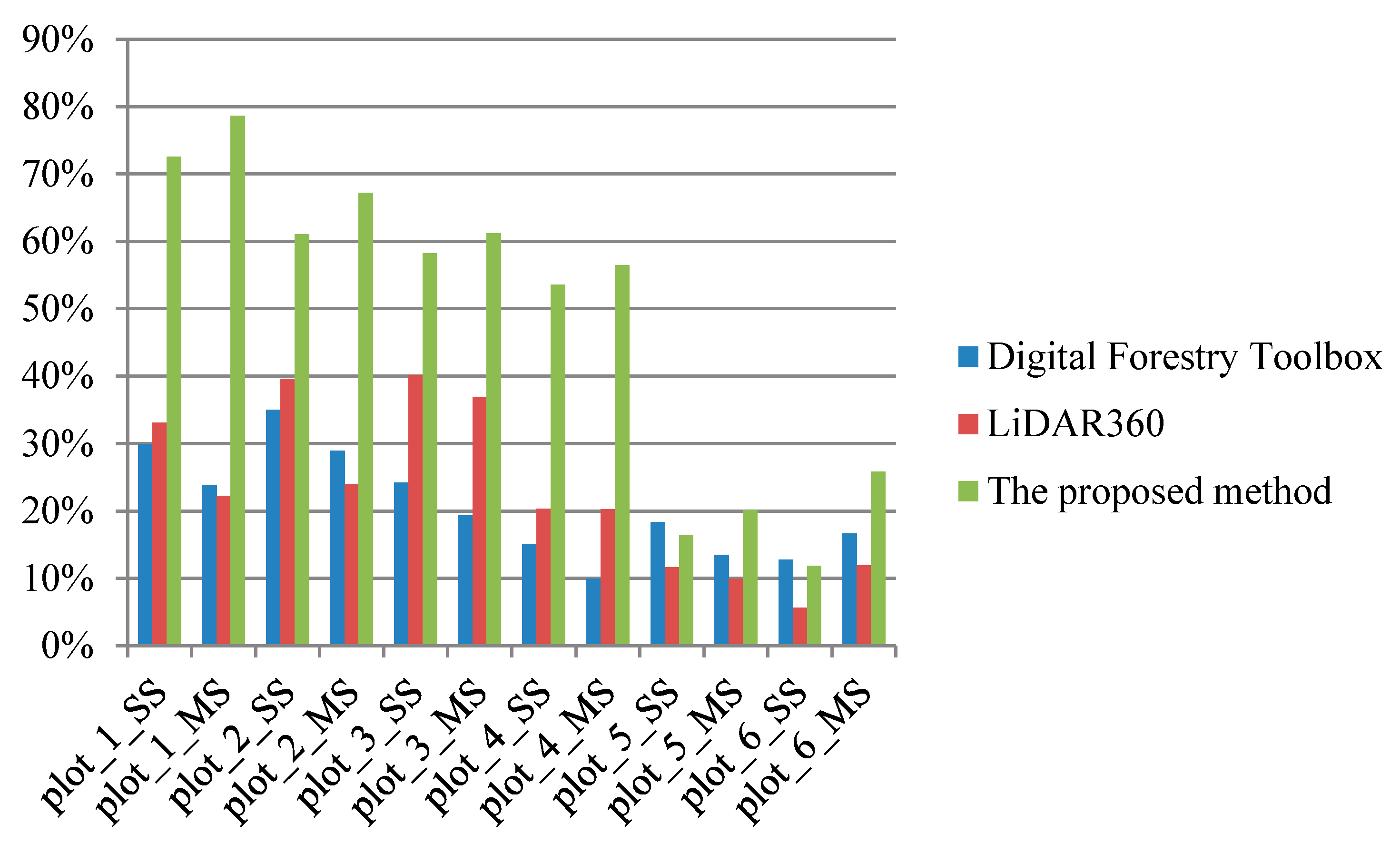
Table 5 shows the trunk stems detection rate by the transductive transfer learning for different plots. It is easy to find that the trunk stem detection rate turns worse as the forest environments become complicated, which is similar to the regularity of individual tree extraction results. Thus, it can be concluded that the trunk stems detection results have an influence of the final individual tree extraction results. Although the initial segmentation results can be optimized by the following Gaussian mixture model separation, the individual tree extraction results cannot be good if the initial segmentation results are too poor.
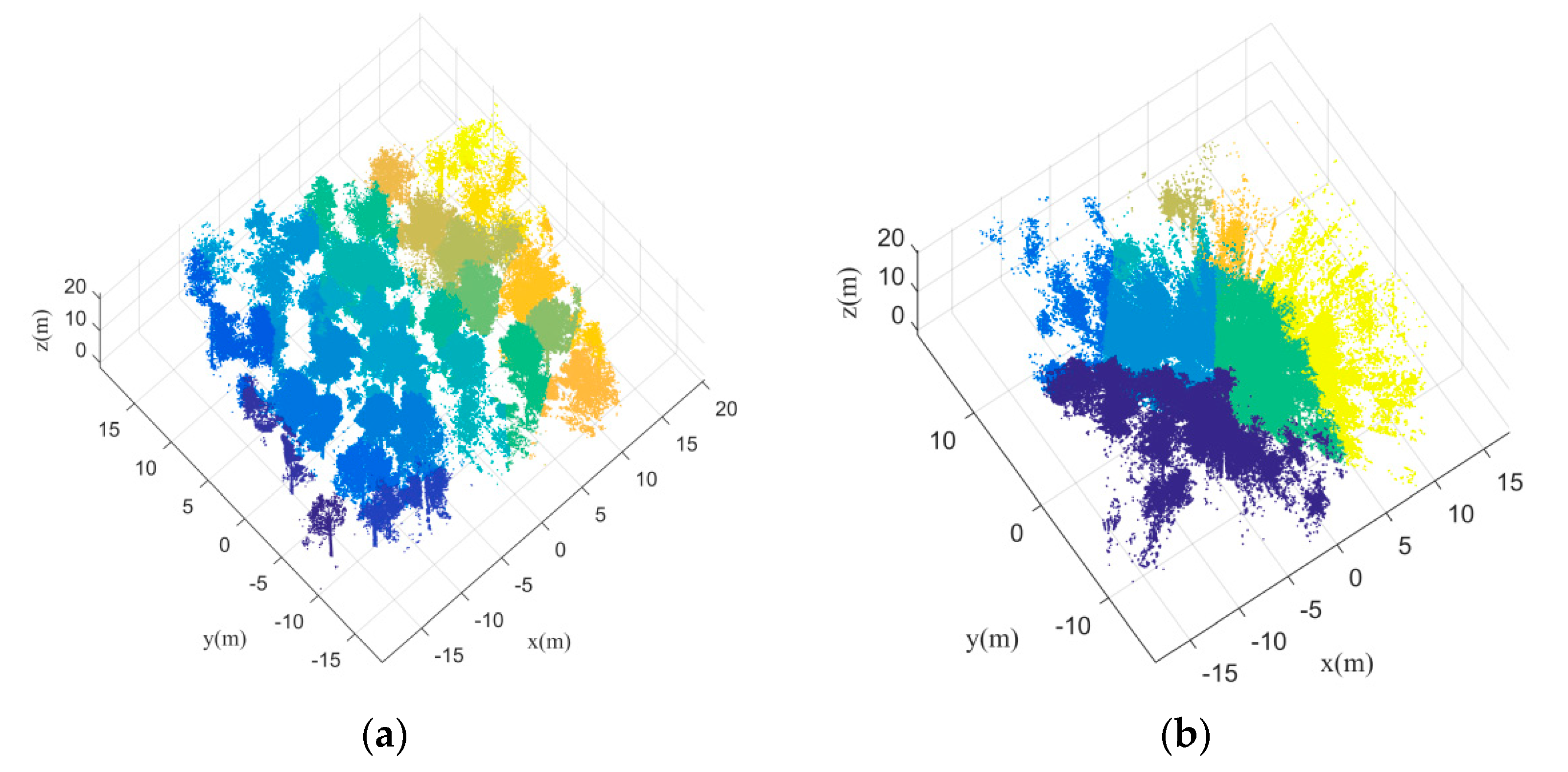
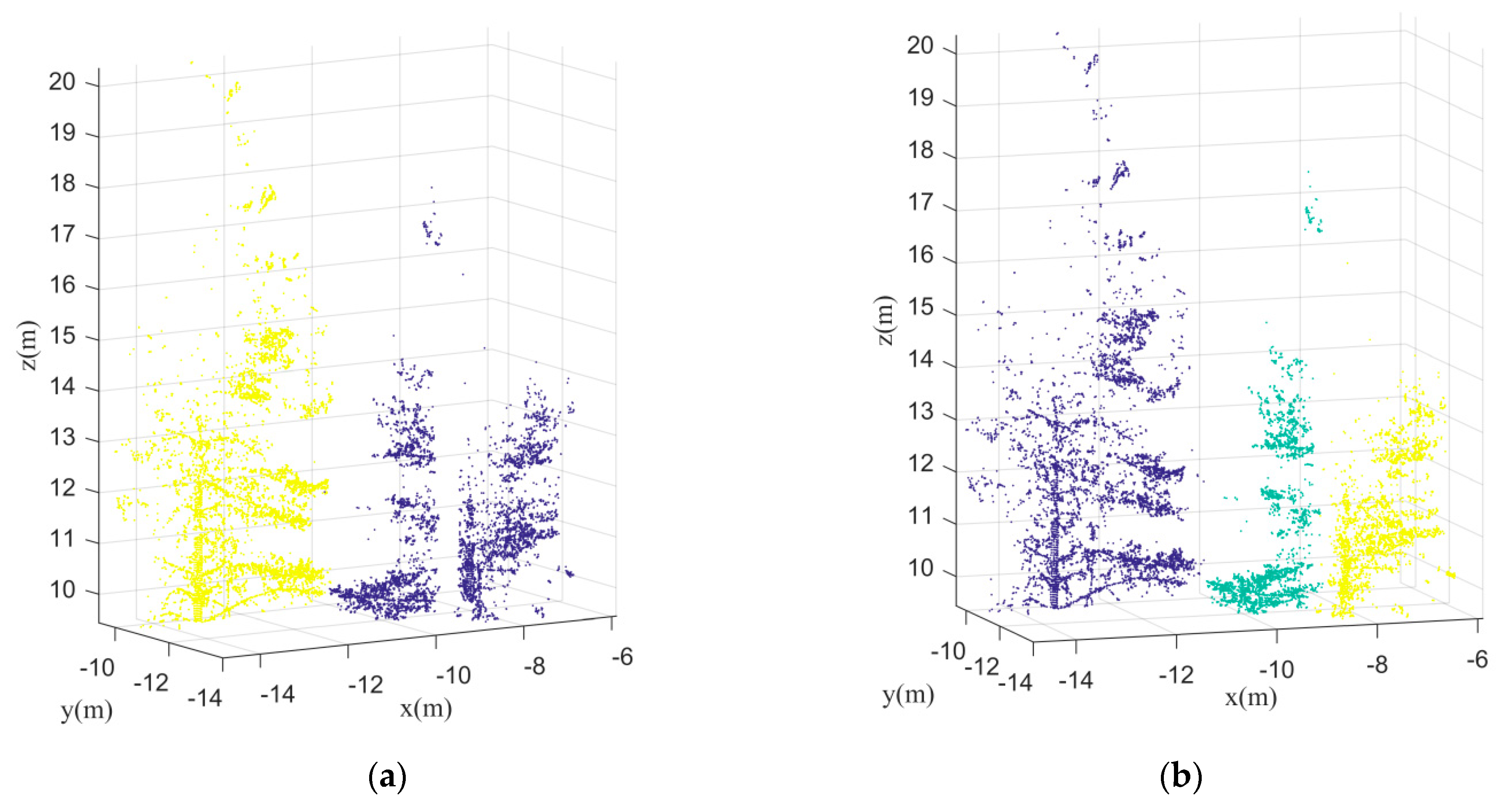
Figure 19a shows an initial segmentation for an easy plot (Plot 1). It is easy to find that although some adjacent trees are clustered together in the initial segmentation, the segmentation results still show clear difference among separated trees. The under-segmentation for some adjacent trees can be easy to be further separated by the following steps in this paper. As a contrast,
Figure 19a shows an initial segmentation for a difficult plot (Plot 6). From this figure, it is difficult to find separated trees. Although both
Figure 19a,b are under-segmentation,
Figure 19b cannot be further revised well since its initial segmentation is too poor.
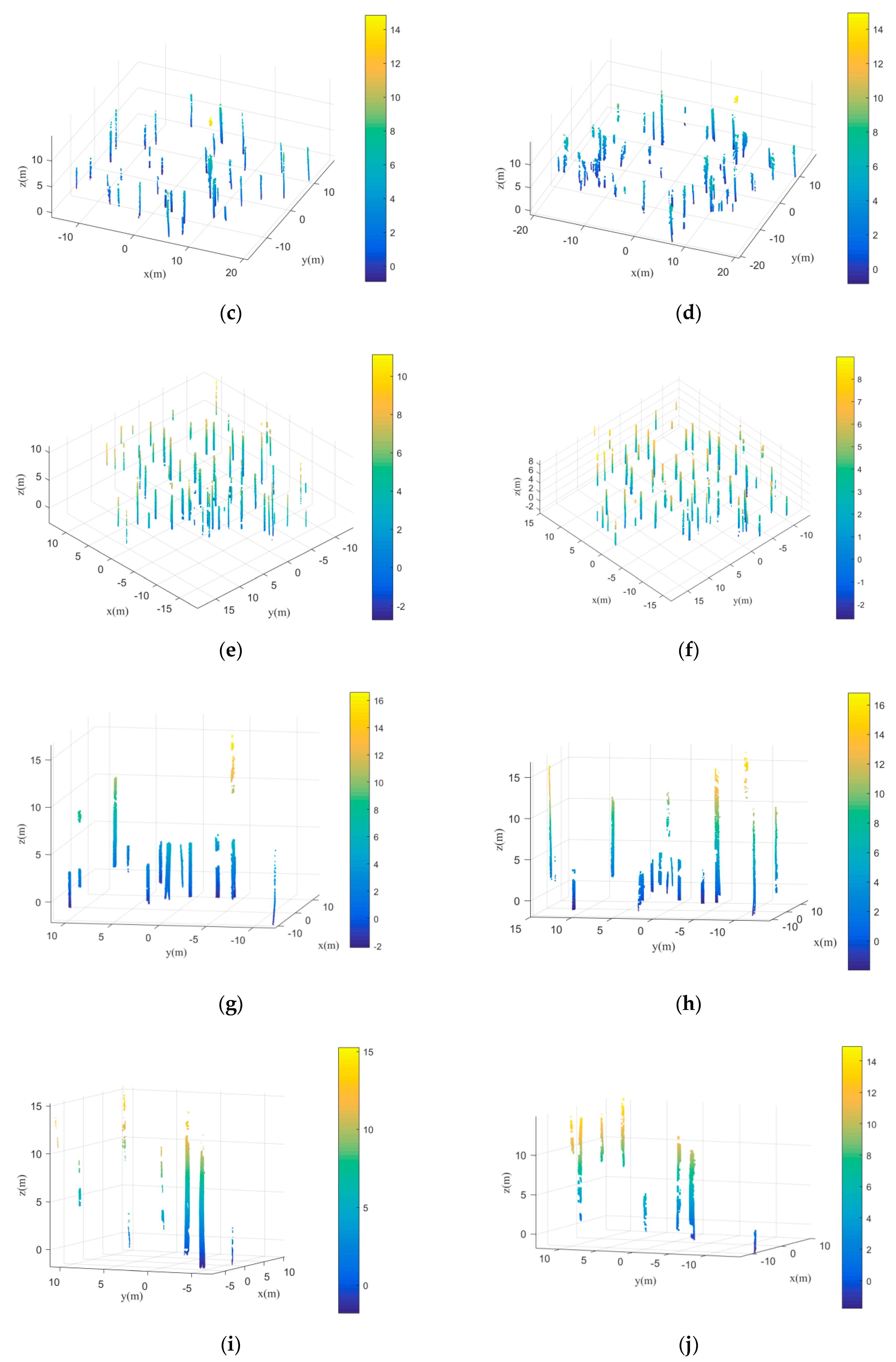
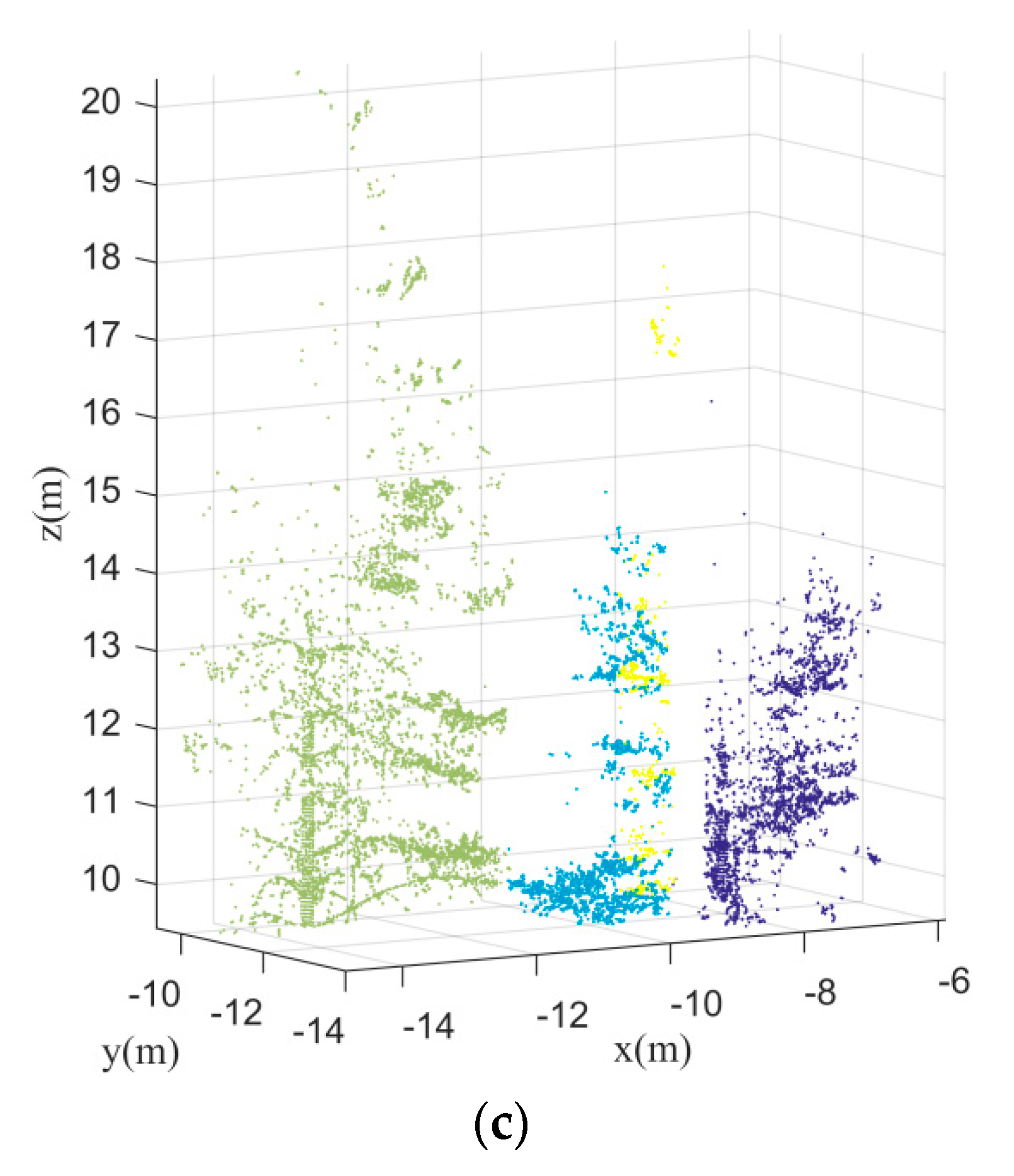
As mentioned above, some adjacent trees may be clustered together in the initial segmentation results. These under-segmented trees need to be further separated. Thus, the Gaussian mixture model separation plays an important role in the separation to under-segmented canopies. In the Gaussian mixture model separation, the separation number has a direct influence on the separation results.
Figure 20 shows the different separation results towards different separation number by applying the Gaussian mixture model separation. Clearly, if the separation number is larger than the number of reference trees, the separation results are over-segmentation. If the separation number is smaller than the number of reference trees, the separation results are under-segmentation. Therefore, the accurate separation number should be determined. In this paper, the separation number can be calculated based on kernel density estimation. By detecting the number of local maxima of the kernel density distribution curve, the number of mixed components can be acquired automatically.
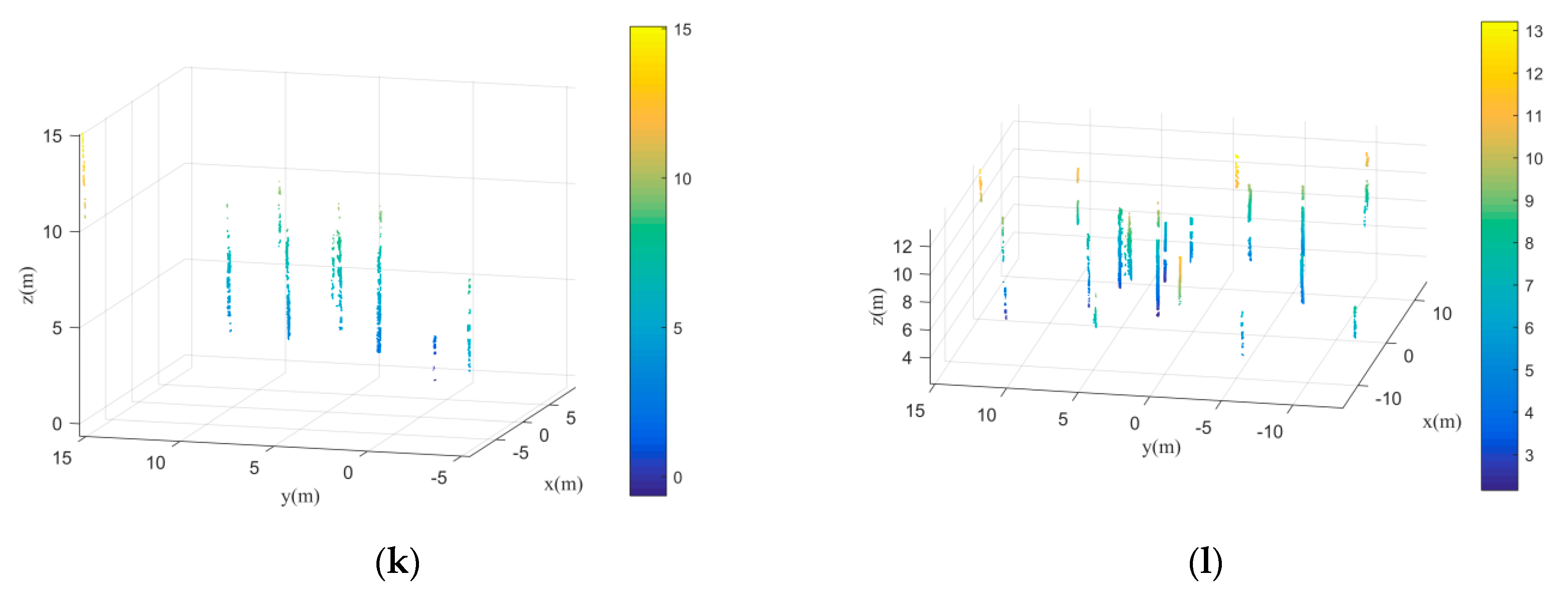
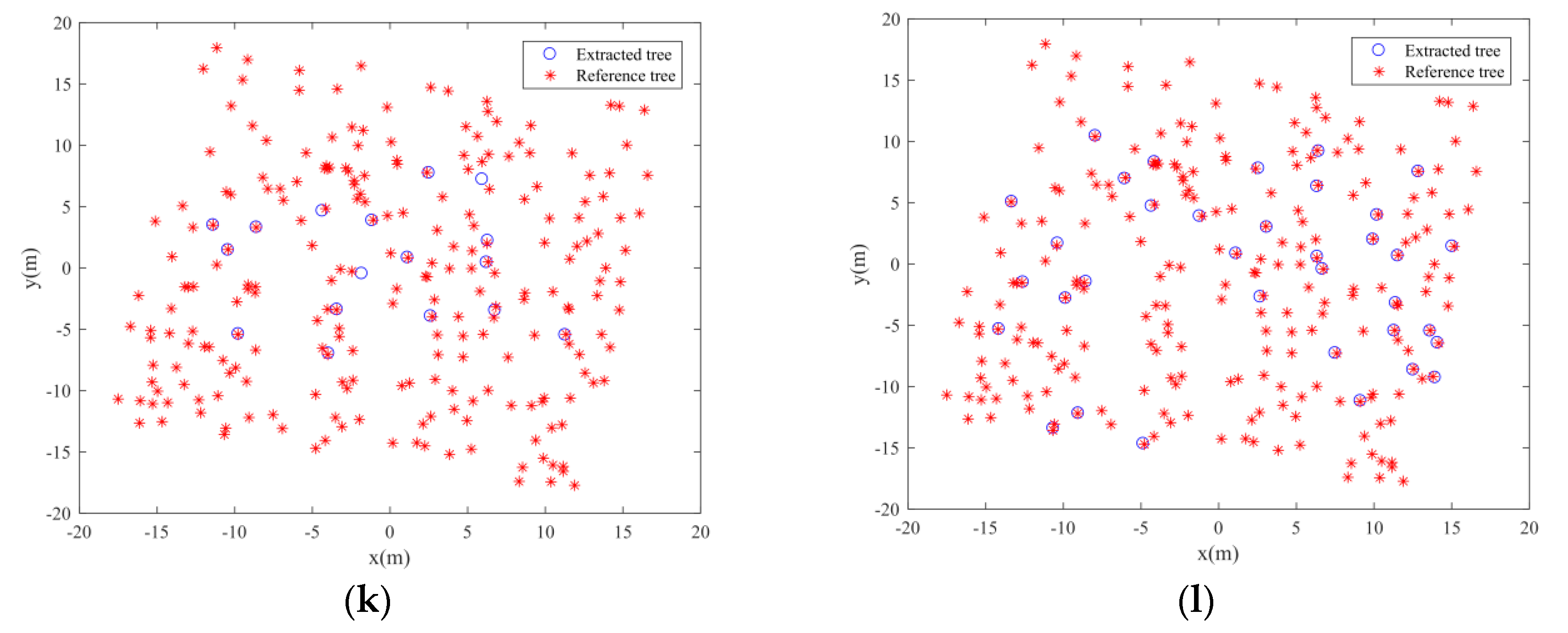
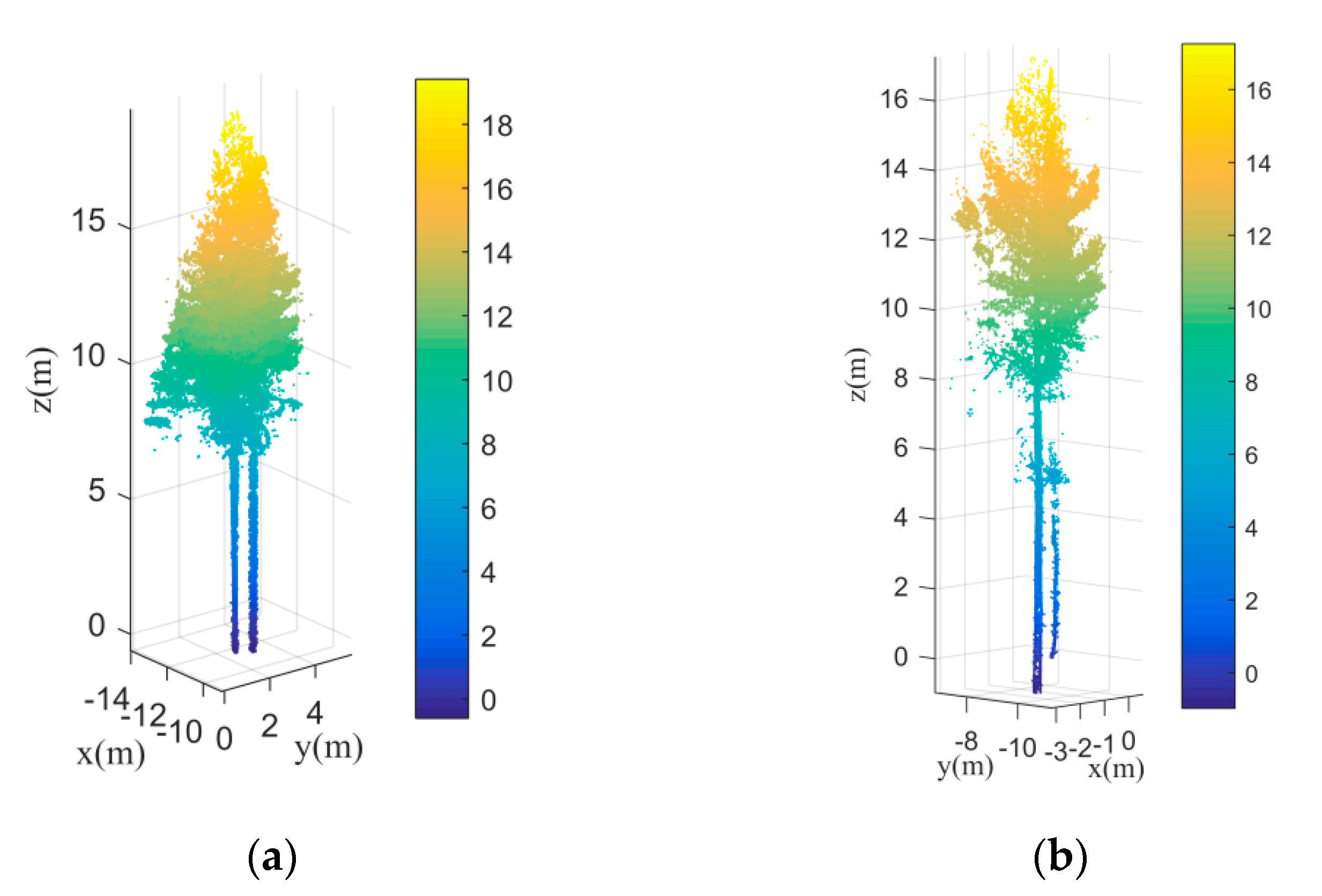
Although the under-segmented trees can be revised by the Gaussian mixture model separation, the trees that grow under another tree’s canopy are still difficult to be separated by the EM algorithm.
Figure 21a,b are two instances of the individual tree extraction results. Clearly, the extraction results contain omission errors. The smaller trees were not detected effectively. The reasons for this are twofold. On the one hand, the separation number cannot be calculated accurately based on kernel density estimation since the local maxima of the kernel density distribution curve formed by the smaller trees cannot be detected effectively. On the other hand, the Gaussian mixture model separation method is easy to misclassify trees that grow too much closer to be one tree. How to detect the trees that grow under canopies need to be focused in our future research. In terms of the trees with complex canopy architectures, such as the broadleaf forests, the proposed method will encounter difficulties. It is because the trees separation in this research mainly depends on the kernel density distribution of the canopy points. If the canopy architectures are complicated, the number of the local maxima of the kernel density distribution will not correspond to the number of trees that need to be segmented. Thus, the following individual trees segmentation using the EM algorithm will not be correct.



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}