
AAU-Net: Attention-Based Asymmetric U-Net for Subject-Sensitive Hashing of Remote Sensing Images


Abstract
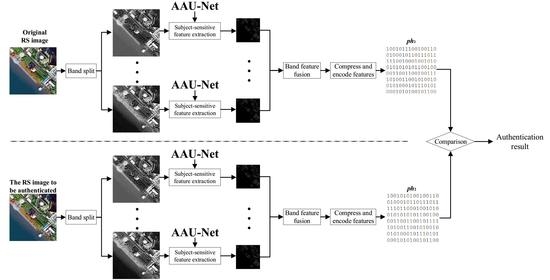
:
1. Introduction
- The differences in the various bands of RS images are not taken into account. Each band of the RS image reflects the spectral information within the band. As a result, there are certain differences among different bands. However, the current subject-sensitive hashing algorithms do not make the best use of these differences [16].
- The tampering sensitivity of the existing subject-sensitive hash still needs further improvement. Compared with perceptual hash, subject-sensitive hashing further distinguishes robustness into “subject-related tampering” and “subject-unrelated tampering”. However, the existing subject-sensitive hash cannot sufficiently distinguish the above two types of tampering sensitivities.
- While perceptual hashing methods (including subject-sensitive hashing) have better robustness than cryptographic methods, the robustness of existing subject-sensitive hashing algorithms still has room for improvement. For example, the robustness of the existing methods for the lossy data compression of RS images is still not ideal.
- In view of the shortcomings of existing subject-sensitive hashing algorithms, such as the inability to distinguish between subject-related tampering and subject-unrelated tampering, we introduce the attention mechanism into the research of subject-sensitive hashing to better realize the integrity authentication of RS images.
- Combining the characteristics of subject-sensitive hashing, a network named attention-based asymmetric U-Net (AAU-Net) is proposed to extract the subject-sensitive features of the bands of RS images, which has good tampering sensitivity and robustness.
- There are certain differences in the content of different bands of RS images, while the existing subject-sensitive hash algorithm does not take the differences into account. To overcome this problem, a subject-sensitive hashing algorithm that integrates the features of each band of RS images is proposed based on our AAU-Net.
2. Related Work
3. Proposed Method
3.1. AAU-Net: Attention-Based Asymmetric U-Net
3.1.1. Asymmetric Network Architecture of AAU-Net
- The encoder and decoder parts of the network structure are asymmetrical. In the original U-Net and variant networks based on U-Net (such as TernausNet [41], Res-UNet [42], MultiResUNet [43], and Attention U-Net [39]), the level of pooling in the encoder stage and the level of upsampling in the decoder stage are generally the same, while in AAU-Net, the level of pooling is greater than the level of upsampling: after upsampling in block 6, there is no upsampling in block 7, block 8, and block 9. If there are more upsampling operations, the pixel-level noise (false features composed of several pixels) will also increase.
- The asymmetry of input and output. The size of the input image of AAU-Net is 256 × 256, but the output is 64 × 64. This not only helps to reduce information redundancy, simplifying the downsampling operation of the algorithm in the feature processing stage, but also improves the robustness of the subject-sensitive hashing algorithm. In fact, even the traditional perceptual hash algorithm uses the method of reducing the image resolution in the image preprocessing stage to increase the robustness of the algorithm. After all, the lower the image resolution, the less useless information it contains.
- The continuous pooling operation and stride convolution in the original U-Net cause the loss of some spatial information [44], while the multi-scale input can greatly reduce the loss of spatial information [45], thereby improving the accuracy of the model. In AAU-Net, we perform downsampling processing on the original input image and build a multi-scale input (image pyramid) to reduce the loss of spatial information due to convolution and pooling operations, so that each layer of the encoding stage can learn more rich features, and then improve the model’s ability to extract subject-sensitive features.
- In the decoder stage of AAU-Net, an attention gate is added to suppress irrelevant areas, while the encoder does not introduce the attention mechanism, which is similar to Attention U-Net [39]. Although the multi-scale input of the encoder helps to extract rich information, it also increases the possibility of extracting useless features such as noise. The attention mechanism causes AAU-Net to suppress the useless features as much as possible.
3.1.2. Attention Gate
3.1.3. Loss Function
3.2. Subject-Sensitive Hashing Based on AAU-Net
3.2.1. The Process of Generating Subject-Sensitive Hash Sequences
| Algorithm 1: Subject-sensitive hash algorithm of an RS image. |
| Input: Storage path of the RS image Output: Subject-sensitive hash sequence 1 I = read(Storage path of the RS image) 2 Band1, Band2, …, BandN = split(I) 3 I1, I2, I3 …, IN = pre-process(Band1, Band2, …, BandN) 4 for Ik in (I1, I2, I3 …, IN) 5 Fk = AAU-Net (Ik) 6 end for 7 F = αk Fk 8 Subject-sensitive feature = PCA(F) 9 Subject-sensitive hash sequence = Normalization and Quantification (Subject-sensitive feature) |
3.2.2. Integrity Authentication Process
| Algorithm 2: Integrity authentication process. |
| Input: T, Hash1 and I’ Output: Authentication result 1 Hash2 = Subject-sensitive_hash (I’) 2 Dis = Normalized_hamming_distance (Hash1, Hash2) 3 If (Dis > T) 4 Integrity authentication failed 5 else 6 Passed integrity authentication 7 end if |
4. Experiment and Discussion
4.1. Performance Evaluation Metrics
- (1)
- Performance of robustness.
- (2)
- Performance of sensitivity to tampering.
- (3)
- Other evaluation metrics.
4.2. Datasets and Experimental Settings
4.2.1. Datasets
4.2.2. Implementation Details
4.3. Examples of Integrity Authentication
4.4. Performance Analysis
4.4.1. Performance of Robustness
4.4.2. Performance of Sensitivity to Tampering
4.4.3. Analysis of Security
4.5. Discussion
- (1)
- Robustness.
- (2)
- Tampering sensitivity.
- (3)
- Security.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qu, Y.H.; Zhu, Y.Q.; Han, W.C.; Wang, J.D.; Ma, M.G. Crop Leaf Area Index Observations with a Wireless Sensor Network and Its Potential for Validating Remote Sensing Products. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 431–444. [Google Scholar] [CrossRef]
- Mukesh, S.B.; Komal, C.H.; Rustam, P.; Alexander, K. Eco-environmental quality assessment based on pressure-state-response framework by remote sensing and GIS. Remote Sens. Appl. Soc. Environ. 2021, 23, 100530. [Google Scholar]
- Tu, W.; Zhang, Y.T.; Li, Q.Q.; Mai, K.; Cao, J.Z. Scale Effect on Fusing Remote Sensing and Human Sensing to Portray Urban Functions. IEEE Geosci. Remote Sens. Lett. 2021, 18, 38–42. [Google Scholar] [CrossRef]
- Huang, X.; Liu, H.; Zhang, L.P. Spatiotemporal Detection and Analysis of Urban Villages in Mega City Regions of China Using High-Resolution Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3639–3657. [Google Scholar] [CrossRef]
- Natalia, R.; Conrado, M.; Rudorff, M.K.; Gustavo, O. Remote sensing monitoring of the impact of a major mining wastewater disaster on the turbidity of the Doce River plume off the eastern Brazilian coast. ISPRS J. Photogramm. Remote Sens. 2018, 145, 349–361. [Google Scholar]
- Santos, L.B.L.; Carvalho, T.; Anderson, L.O.; Rudorff, C.M.; Marchezini, V.; Londe, L.R.; Saito, S.M. An RS-GIS-Based ComprehensiveImpact Assessment of Floods—A Case Study in Madeira River, Western Brazilian Amazon. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1614–1617. [Google Scholar] [CrossRef]
- Del’Arco, S.I.; Feitosa, R.Q.; Achanccaray, P.M.; Dias, M.B.L.; Alfredok, J.; Schultz, B.; Pinheiro, L.E. Campo Verde Database: Seeking to Improve Agricultural Remote Sensing of Tropical Areas. IEEE Geosci. Remote Sens. Lett. 2018, 15, 369–373. [Google Scholar] [CrossRef]
- Steele-Dunne, S.C.; McNairn, H.; Monsivais-Huertero, A.; Judge, J.; Liu, P.W.; Papathanassiou, K. Radar Remote Sensing of Agricultural Canopies: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2249–2273. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Zhai, G.J.; Lu, X.S. Integrated land-sea surveying and mapping of intertidal zone based on high-definition remote sensing images and GIS technology. Microprocess. Microsyst. 2021, 82, 103937. [Google Scholar] [CrossRef]
- Eylül, M.; Marius, R.; Christian, G.; Lars, T.W. Countrywide mapping of trees outside forests based on remote sensing data in Switzerland. Int. J. Appl. Earth Obs. Geoinf. 2021, 100, 102336. [Google Scholar]
- Niu, X.M.; Jiao, Y.H. An Overview of Perceptual Hashing. Acta Electron. Sin. 2008, 36, 1405–1411. [Google Scholar]
- Du, L.; Ho, A.T.S.; Cong, R. Perceptual hashing for image authentication: A survey. Sig. Process. Image Comm. 2020, 81, 115713. [Google Scholar] [CrossRef]
- Ding, K.M.; Zhu, Y.T.; Zhu, C.Q.; Su, S.B. A perceptual Hash Algorithm Based on Gabor Filter Bank and DWT for Remote Sensing Image Authentication. J. China Railw. Soc. 2016, 38, 70–76. [Google Scholar]
- Zhang, X.G.; Yan, H.W.; Zhang, L.M.; Wang, H. High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features. ISPRS Int. J. Geo-Inf. 2020, 9, 254. [Google Scholar] [CrossRef] [Green Version]
- Ding, K.; Chen, S.; Meng, F. A Novel Perceptual Hash Algorithm for Multispectral Image Authentication. Algorithms 2018, 11, 6. [Google Scholar] [CrossRef] [Green Version]
- Ding, K.; Liu, Y.; Xu, Q.; Lu, F. A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 485. [Google Scholar] [CrossRef]
- Zhang, X.; Nie, G.Z.; Huang, W.X.; Liu, W.X.; Ma, B.; Lin, C.W. Attention-guided image captioning with adaptive global and local feature fusion. J. Vis. Commun. Image Represent. 2021, 78, 103138. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-Attention in Reconstruction Bias U-Net for Semantic Segmentation of Building Rooftops in Optical Remote Sensing Images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Kim, J.; Chi, M. SAFFNet: Self-Attention-Based Feature Fusion Network for Remote Sensing Few-Shot Scene Classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Yu, J.K.; Yang, D.D.; Zhao, H.S. FFANet: Feature fusion attention network to medical image segmentation. Biomed. Signal Process. Control 2021, 69, 102912. [Google Scholar] [CrossRef]
- Zhu, Y.S.; Zhao, C.Y.; Guo, H.Y.; Wang, J.Q.; Zhao, X.; Lu, H.Q. Attention CoupleNet: Fully Convolutional Attention Coupling Network for Object Detection. IEEE Trans. Image Process. 2019, 28, 113–126. [Google Scholar] [CrossRef]
- Chen, X.; Weng, J.; Lu, W.; Xu, J.; Weng, J. Deep Manifold Learning Combined with Convolutional Neural Networks for Action Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3938–3952. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Gu, Y.; Wang, Y.; Yang, C.; Gui, W. A Deep Supervised Learning Framework for Data-Driven Soft Sensor Modeling of Industrial Processes. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4737–4746. [Google Scholar] [CrossRef]
- Du, P.J.; Bai, X.Y.; Tan, K.; Xue, Z.H.; Samat, A.; Xia, J.S.; Li, E.Z.; Su, H.J.; Liu, W. Advances of Four Machine Learning Methods for Spatial Data Handling: A Review. J. Geovis. Spat. Anal. 2020, 4, 13. [Google Scholar] [CrossRef]
- Wei, J.B.; Huang, Y.K.; Lu, K.; Wang, L.Z. Nonlocal Low-Rank-Based Compressed Sensing for Remote Sensing Image Reconstruction. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1557–1561. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, H.Q.; Shen, H.F.; Wu, P.H.; Zhang, L.P. A Spatial and Temporal Nonlocal Filter-Based Data Fusion Method. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4476–4488. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.Y.; Chen, Z.Z. An Adaptive Spectral Decorrelation Method for Lossless MODIS Image Compression. IEEE Trans. Geosci. Remote Sens. 2019, 57, 803–814. [Google Scholar] [CrossRef]
- Kulkarni, S.C.; Rege, P.P. Pixel level fusion techniques for SAR and optical images: A review. Inf. Fusion 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Peng, Y.D.; Li, W.S.; Luo, X.B.; Du, J.; Gan, Y.; Gao, X.B. Integrated fusion framework based on semicoupled sparse tensor factorization for spatio-temporal–spectral fusion of remote sensing images. Inf. Fusion 2021, 65, 21–36. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.S.; Chen, Z.C.; Chanussot, J.; Jia, X.P.; Zhang, B.; Li, B.P.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Zhao, Z.P.; Bao, Z.T.; Zhang, Z.X.; Deng, J.; Cummins, N.; Wang, H.; Tao, J.H.; Schuller, B. Automatic Assessment of Depression from Speech via a Hierarchical Attention Transfer Network and Attention Autoencoders. IEEE J. Sel. Top. Signal Process. 2020, 14, 423–434. [Google Scholar] [CrossRef]
- Ji, Z.; Li, S.J. Multimodal Alignment and Attention-Based Person Search via Natural Language Description. IEEE Internet Things J. 2020, 7, 11147–11156. [Google Scholar] [CrossRef]
- Zhang, B.; Xiong, D.Y.; Xie, J.; Su, J.S. Neural Machine Translation With GRU-Gated Attention Model. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4688–4698. [Google Scholar] [CrossRef]
- Lu, X.Q.; Wang, B.Q.; Zheng, X.T. Sound Active Attention Framework for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1985–2000. [Google Scholar] [CrossRef]
- Wang, B.; Wang, C.G.; Zhang, Q.; Su, Y.; Wang, Y.; Xu, Y.Y. Cross-Lingual Image Caption Generation Based on Visual Attention Model. IEEE Access 2020, 8, 104543–104554. [Google Scholar] [CrossRef]
- Zhu, M.H.; Jiao, L.C.; Liu, F.; Yang, S.Y.; Wang, J.N. Residual Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 449–462. [Google Scholar] [CrossRef]
- Xing, X.H.; Yuan, Y.X.; Meng, M.Q.H. Zoom in Lesions for Better Diagnosis: Attention Guided Deformation Network for WCE Image Classification. IEEE Trans. Med. Imaging 2020, 39, 4047–4059. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. Available online: https://arxiv.org/abs/1804.03999 (accessed on 20 May 2018).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Iglovikov, V.; Shvets, A. TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation. arXiv 2018, arXiv:1801.05746. Available online: https://arxiv.org/abs/1801.05746 (accessed on 17 January 2018).
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted Res-UNet for High-Quality Retina Vessel Segmentation. In Proceedings of the 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Net. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Gu, Z.W.; Cheng, J.; Fu, H.Z.; Zhou, K.; Hao, H.Y.; Zhao, Y.T.; Zhang, T.Y.; Gao, S.H.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, H.; Cheng, J.; Xu, Y.; Wang, D.W.K.; Liu, J.; Cao, X. Joint Optic Disc and Cup Segmentation Based on Multi-Label Deep Network and Polar Transformation. IEEE Trans. Med. Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation. Diagnostics 2021, 11, 501. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Le, N.; Bui, T.; Vo-Ho, V.-K.; Yamazaki, K.; Luu, K. Narrow Band Active Contour Attention Model for Medical Segmentation. Diagnostics 2021, 11, 1393. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Lin, S.Z.; Han, Z.; Li, D.W.; Zeng, J.C.; Yang, X.L.; Liu, X.W.; Liu, F. Integrating model- and data-driven methods for synchronous adaptive multi-band image fusion. Inf. Fusion 2020, 54, 145–160. [Google Scholar] [CrossRef]
- Ding, K.M.; Zhu, C.Q.; Lu, Q. An adaptive grid partition based perceptual hash algorithm for remote sensing image authentication. Wuhan Daxue Xuebao 2015, 40, 716–720. [Google Scholar]
- Ji, S.P.; Wei, S.Y. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar]
- Adiga, V.; Sivaswamy, J. FPD-M-net: Fingerprint Image Denoising and Inpainting Using M-Net Based Convolutional Neural Networks. In Inpainting and Denoising Challenges; Springer: Cham, Switzerland, 2019; pp. 51–61. [Google Scholar]
- Zhao, S.; Liu, T.; Liu, B.W.; Ruan, K. Attention residual convolution neural network based on U-net (AttentionResU-Net) for retina vessel segmentation. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 032138. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef]
- Hu, J.J.; Song, Y.; Zhang, L.; Bai, S.; Yi, Z. Multi-scale attention U-net for segmenting clinical target volume in graves’ ophthalmopathy. Neurocomputing 2021, 427, 74–83. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Basak, H. Multi-scale Attention U-Net (MsAUNet): A Modified U-Net Architecture for Scene Segmentation. arXiv 2020, arXiv:2009.06911. Available online: https://arxiv.org/abs/2009.06911 (accessed on 15 September 2020).
- Ding, K.M.; Su, S.B.; Xu, N.; Jiang, T.T. Semi-U-Net: A Lightweight Deep Neural Network for Subject-Sensitive Hashing of HRRS Images. IEEE Access 2021, 9, 60280–60295. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Yuan, G.H.; Hao, Q. Digital watermarking secure scheme for remote sensing image protection. China Commun. 2020, 17, 88–98. [Google Scholar] [CrossRef]
- Zhang, J.; Sang, L.; Li, X.P.; Wang, H.; Li, Y.S. Design and Implementation of Raw Data Compression System for Subsurface Detection SAR Based on FPGA. J. Geovis. Spat. Anal. 2020, 4, 2. [Google Scholar] [CrossRef]
- Gao, X.; Mu, T.; Goulermas, J.Y.; Thiyagalingam, J.; Wang, M. An Interpretable Deep Architecture for Similarity Learning Built Upon Hierarchical Concepts. IEEE Trans. Image Process. 2020, 29, 3911–3926. [Google Scholar] [CrossRef]
- Wu, C.; Gales, M.J.F.; Ragni, A.; Karanasou, P.; Sim, K.C. Improving Interpretability and Regularization in Deep Learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 256–265. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tampering Test | Figure 8b | Figure 8c | Figure 8d | Figure 8e | Figure 8f | Figure 8g | Figure 8h | Figure 8h | Figure 8h |
|---|---|---|---|---|---|---|---|---|---|
| U-Net-based algorithm | 0.0 | 0.046875 | 0.05859375 | 0.02734375 | 0.05859375 | 0.20703125 | 0.12109375 | 0.078125 | 0.03515625 |
| M-Net-based algorithm | 0.0 | 0.15234375 | 0.01171875 | 0.0234375 | 0.01953125 | 0.24609375 | 0.24609375 | 0.171875 | 0.1328125 |
| MultiResU-Net-based algorithm | 0.0 | 0.09375 | 0.015625 | 0.0390625 | 0.0625 | 0.2578125 | 0.23046875 | 0.06640625 | 0.13671875 |
| MUM-Net-based algorithm | 0.0 | 0.20703125 | 0.0234375 | 0.03515625 | 0.0625 | 0.11328125 | 0.20703125 | 0.2578125 | 0.01171875 |
| Attention ResU-Net-based algorithm | 0.0 | 0.02734375 | 0.0 | 0.015625 | 0.0 | 0.07421875 | 0.234375 | 0.015625 | 0.0 |
| Attention R2U-Net-based algorithm | 0.0 | 0.10546875 | 0.10546875 | 0.0234375 | 0.125 | 0.1796875 | 0.26953125 | 0.1640625 | 0.0703125 |
| Attention U-Net-based algorithm | 0.0 | 0.0625 | 0.0078125 | 0.02734375 | 0.01171875 | 0.125 | 0.23046875 | 0.1015625 | 0.01171875 |
| MA-U-Net-based algorithm | 0.0 | 0.078125 | 0.03125 | 0.09375 | 0.02734375 | 0.140625 | 0.1796875 | 0.21875 | 0.08203125 |
| AAU-Net-based algorithm | 0.0 | 0.0234375 | 0.0078125 | 0.00390625 | 0.0078125 | 0.11328125 | 0.2890625 | 0.06640625 | 0.0390625 |
| Tampering Test | Figure 8b | Figure 8c | Figure 8d | Figure 8e | Figure 8f | Figure 8g | Figure 8h | Figure 8h | Figure 8h |
|---|---|---|---|---|---|---|---|---|---|
| U-Net-based algorithm | Success | Fail | Fail | Success | Fail | Success | Success | Success | Success |
| M-Net-based algorithm | Success | Fail | Success | Success | Success | Success | Success | Success | Success |
| MultiResU-Net-based algorithm | Success | Fail | Success | Fail | Fail | Success | Success | Success | Success |
| MUM-Net-based algorithm | Success | Fail | Success | Fail | Fail | Success | Success | Success | Fail |
| Attention ResU-Net-based algorithm | Success | Success | Success | Success | Success | Success | Success | Fail | Fail |
| Attention R2U-Net-based algorithm | Success | Fail | Fail | Success | Fail | Success | Success | Success | Success |
| Attention U-Net-based algorithm | Success | Fail | Success | Success | Success | Success | Success | Success | Fail |
| MA-U-Net-based algorithm | Success | Fail | Fail | Fail | Success | Success | Success | Success | Success |
| AAU-Net-based algorithm | Success | Success | Success | Success | Success | Success | Success | Success | Success |
| Tampering Test | Figure 8b | Figure 8c | Figure 8d | Figure 8e | Figure 8f | Figure 8g | Figure 8h | Figure 8h | Figure 8h |
|---|---|---|---|---|---|---|---|---|---|
| U-Net-based algorithm | Success | Fail | Fail | Fail | Fail | Success | Success | Success | Success |
| M-Net-based algorithm | Success | Fail | Success | Fail | Success | Success | Success | Success | Success |
| MultiResU-Net-based algorithm | Success | Fail | Success | Fail | Fail | Success | Success | Success | Success |
| MUM-Net-based algorithm | Success | Fail | Fail | Fail | Fail | Success | Success | Success | Fail |
| Attention ResU-Net-based algorithm | Success | Fail | Success | Fail | Success | Success | Success | Fail | Fail |
| Attention R2U-Net-based algorithm | Success | Fail | Fail | Fail | Fail | Success | Success | Success | Success |
| Attention U-Net-based algorithm | Success | Fail | Success | Fail | Success | Success | Success | Success | Fail |
| MA-U-Net-based algorithm | Success | Fail | Fail | Fail | Fail | Success | Success | Success | Success |
| AAU-Net-based algorithm | Success | Fail | Success | Success | Success | Success | Success | Success | Success |
| Tampering Test | Figure 8b | Figure 8c | Figure 8d | Figure 8e | Figure 8f | Figure 8g | Figure 8h | Figure 8h | Figure 8h |
|---|---|---|---|---|---|---|---|---|---|
| U-Net-based algorithm | Success | Success | Fail | Success | Fail | Success | Success | Success | Fail |
| M-Net-based algorithm | Success | Fail | Success | Success | Success | Success | Success | Success | Success |
| MultiResU-Net-based algorithm | Success | Fail | Success | Success | Fail | Success | Success | Success | Success |
| MUM-Net-based algorithm | Success | Fail | Success | Success | Fail | Success | Success | Success | Fail |
| Attention ResU-Net-based algorithm | Success | Success | Success | Success | Success | Success | Success | Fail | Fail |
| Attention R2U-Net-based algorithm | Success | Fail | Fail | Success | Fail | Success | Success | Success | Success |
| Attention U-Net-based algorithm | Success | Fail | Success | Success | Success | Success | Success | Success | Fail |
| MA-U-Net-based algorithm | Success | Fail | Success | Fail | Success | Success | Success | Success | Success |
| AAU-Net-based algorithm | Success | Success | Success | Success | Success | Success | Success | Success | Fail |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 64.2% | 75.0% | 85.2% | 96.6% | 99.3% | 99.9% |
| M-Net-based algorithm | 71.6% | 81.0% | 91.9% | 98.0% | 99.6% | 100% |
| MultiResU-Net-based algorithm | 87.8% | 93.0% | 97.5% | 99.2% | 99.9% | 100% |
| MUM-Net-based algorithm | 63.0% | 74.8% | 88.5% | 97.2% | 100% | 100% |
| Attention ResU-Net-based algorithm | 94.1% | 96.4% | 98.3% | 99.9% | 100% | 100% |
| Attention R2U-Net-based algorithm | 53.0% | 64.8% | 78.9% | 92.0% | 97.8% | 100% |
| Attention U-Net-based algorithm | 91.6% | 94.5% | 97.8% | 99.4% | 99.9% | 100% |
| MA-U-Net-based algorithm | 90.7% | 92.2% | 98.5% | 99.8% | 100% | 100% |
| AAU-Net-based algorithm | 96.1% | 97.8% | 98.8% | 99.8% | 100% | 100% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 63.3% | 75.1% | 88.9% | 96.7% | 99.8% | 100% |
| M-Net-based algorithm | 70.2% | 80.1% | 92.2% | 97.6% | 99.7% | 100% |
| MultiResU-Net-based algorithm | 76.3% | 86.0% | 94.7% | 98.1% | 99.6% | 100% |
| MUM-Net-based algorithm | 79.6% | 90.9% | 97.6% | 99.9% | 100% | 100% |
| Attention ResU-Net-based algorithm | 86.0% | 91.1% | 96.1% | 99.3% | 99.9% | 100% |
| Attention R2U-Net-based algorithm | 58.5% | 69.2% | 83.0% | 95.5% | 99.3% | 100% |
| Attention U-Net-based algorithm | 85.9% | 92.6% | 97.1% | 98.9% | 100% | 100% |
| MA-U-Net-based algorithm | 87.6% | 93.0% | 97.4% | 99.6% | 100% | 100% |
| AAU-Net-based algorithm | 73.6% | 81.0% | 93.3% | 98.8% | 99.8% | 100% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 99.6% | 99.8% | 99.8% | 100% | 100% | 100% |
| M-Net-based algorithm | 100% | 100% | 100% | 100% | 100% | 100% |
| MultiResU-Net-based algorithm | 100% | 100% | 100% | 100% | 100% | 100% |
| MUM-Net-based algorithm | 100% | 100% | 100% | 100% | 100% | 100% |
| Attention ResU-Net-based algorithm | 100% | 100% | 100% | 100% | 100% | 100% |
| Attention R2U-Net-based algorithm | 99.7% | 99.9% | 100% | 100% | 100% | 100% |
| Attention U-Net-based algorithm | 99.8% | 99.8% | 99.8% | 99.9% | 100% | 100% |
| MA-U-Net-based algorithm | 99.8% | 99.9% | 99.9% | 100% | 100% | 100% |
| AAU-Net-based algorithm | 99.8% | 100% | 100% | 100% | 100% | 100% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 61.7% | 81.8% | 85.6% | 95.8% | 99.3% | 100% |
| M-Net-based algorithm | 68.7% | 88.5% | 90.03% | 97.5% | 99.5% | 100% |
| MultiResU-Net-based algorithm | 87.5% | 92.1% | 96.8% | 99.1% | 99.9% | 100% |
| MUM-Net-based algorithm | 62.1% | 74.3% | 88.2% | 97.3% | 99.7% | 100% |
| Attention ResU-Net-based algorithm | 93.6% | 96.1% | 98% | 99.8% | 100% | 100% |
| Attention R2U-Net-based algorithm | 48.7% | 60.2% | 77.5% | 92.0% | 98.5 | 100% |
| Attention U-Net-based algorithm | 90.1% | 94.2% | 97.3% | 99.0% | 99.9% | 100% |
| MA-U-Net-based algorithm | 90.6% | 96.0% | 98.2% | 98.9% | 99.9% | 100% |
| AAU-Net-based algorithm | 95.1% | 97.1% | 98.3% | 99.6% | 99.9% | 100% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 52.0% | 64.2% | 90.6% | 93.4% | 98.6% | 100% |
| M-Net-based algorithm | 53.5% | 63.4% | 78.5% | 92.8% | 98.6% | 100% |
| MultiResU-Net-based algorithm | 79.7% | 88.5% | 96.0% | 98.7% | 99.8% | 99.9% |
| MUM-Net-based algorithm | 42.1% | 52.3% | 71.1% | 90.4% | 98.3% | 99.9% |
| Attention ResU-Net-based algorithm | 81.5% | 86.6% | 92.1% | 96.4% | 98.9% | 100% |
| Attention R2U-Net-based algorithm | 19.5% | 27.0% | 41.3% | 64.2% | 86.1% | 99.9% |
| Attention U-Net-based algorithm | 52.0% | 64.2% | 80.6% | 93.4% | 98.6% | 100% |
| MA-U-Net-based algorithm | 87.4% | 93.2% | 97.1 | 99.3% | 99.7% | 100% |
| AAU-Net-based algorithm | 90.9% | 93.7% | 97.4% | 99.4% | 100% | 100% |
| Image 1 | Image 2 | Image 3 | Image 4 | |
|---|---|---|---|---|
| U-Net-based algorithm | 0.2500 | 0.2539 | 0.1210 | 0.1093 |
| M-Net-based algorithm | 0.1484 | 0.2148 | 0.2578 | 0.2500 |
| MultiResU-Net-based algorithm | 0.2421 | 0.2421 | 0.1054 | 0.2734 |
| MUM-Net-based algorithm | 0.1914 | 0.2773 | 0.0546 | 0.1367 |
| Attention ResU-Net-based algorithm | 0.1250 | 0.2421 | 0.0312 | 0.0234 |
| Attention R2U-Net-based algorithm | 0.1992 | 0.2695 | 0.0664 | 0.2187 |
| Attention U-Net-based algorithm | 0.1875 | 0.2656 | 0.2421 | 0.0312 |
| MA-U-Net-based algorithm | 0.1562 | 0.2382 | 0.0468 | 0.1484 |
| AAU-Net-based algorithm | 0.1523 | 0.1796 | 0.2109 | 0.0703 |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 98.9% | 98.0% | 96.2% | 86.4% | 59.2% | 0.9% |
| M-Net-based algorithm | 99.2% | 99.0% | 96.2% | 87.0% | 60.7% | 1.3% |
| MultiResU-Net-based algorithm | 99.1% | 97.7% | 92.4% | 79.3% | 54.3% | 1.5% |
| MUM-Net-based algorithm | 98.8% | 98.5% | 95.3% | 78.7% | 42.8% | 1.6% |
| Attention ResU-Net-based algorithm | 83.9% | 76.7% | 57.5% | 34.7% | 12.1% | 0.7% |
| Attention R2U-Net-based algorithm | 99.9% | 99.9% | 99.9% | 98.0% | 81.5% | 1.8% |
| Attention U-Net-based algorithm | 98.9% | 98.0% | 96.2% | 86.4% | 59.2% | 0.9% |
| MA-U-Net-based algorithm | 99.2% | 98.1% | 93.9 | 76.2% | 38.9% | 1.1% |
| AAU-Net-based algorithm | 99.5% | 99.2% | 96.4% | 87.0% | 64.2% | 1.6% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 97.0% | 94.9% | 85.6% | 61.4% | 31.1% | 0.8% |
| M-Net-based algorithm | 96.3% | 94.3% | 89.2% | 66.8% | 33.2% | 0.3% |
| MultiResU-Net-based algorithm | 84.0% | 78.3% | 62.5% | 35.0% | 11.8% | 0.3% |
| MUM-Net-based algorithm | 95.0% | 91.0% | 82.2% | 56.2% | 14.9% | 0.4% |
| Attention ResU-Net-based algorithm | 67.9% | 58.1% | 40.7% | 23.1% | 7.8% | 0.3% |
| Attention R2U-Net-based algorithm | 98.8% | 98.1% | 95,4% | 80.9% | 52.8% | 1.2% |
| Attention U-Net-based algorithm | 93.7% | 91.3% | 84.4% | 68.6% | 36.2% | 0.6% |
| MA-U-Net-based algorithm | 88.8% | 85.5% | 74.2% | 48.4% | 16.8% | 9% |
| AAU-Net-based algorithm | 92.8% | 90.9% | 83.0% | 65.6% | 29.5% | 1.1% |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 88.75% | 84.5% | 74.5% | 43.25% | 16.0% | 0.25% |
| M-Net-based algorithm | 69.5% | 60.0% | 36.5% | 14.75% | 4% | 0% |
| MultiResU-Net-based algorithm | 73.5% | 65.25% | 45.75% | 15.5% | 4.0% | 0% |
| MUM-Net-based algorithm | 87.25% | 82.25% | 68.5% | 38.25% | 7.5% | 0% |
| Attention ResU-Net-based algorithm | 30.75% | 25.5% | 14.5% | 6.5% | 1.5% | 0% |
| Attention R2U-Net-based algorithm | 89.5% | 84.5% | 73% | 47.25% | 21.25% | 0.25% |
| Attention U-Net-based algorithm | 82.0% | 76.5% | 60.25% | 28.75% | 12.25% | 0% |
| MA-U-Net-based algorithm | 87.8% | 80.9% | 65.1% | 36.9% | 12.5% | 0.1% |
| AAU-Net-based algorithm | 82.75% | 80.25% | 65.5% | 29.5% | 10.5% | 0% |
| Image 1 | Image 2 | Image 3 | Image 4 | |
|---|---|---|---|---|
| U-Net-based algorithm | 0.0273 | 0.0234 | 0.0742 | 0.1054 |
| M-Net-based algorithm | 0.0117 | 0.0 | 0.0078 | 0.0 |
| MultiResU-Net-based algorithm | 0.0429 | 0.0 | 0.0 | 0.0156 |
| MUM-Net-based algorithm | 0.0468 | 0.0 | 0.0 | 0.0195 |
| Attention ResU-Net-based algorithm | 0.0117 | 0.0 | 0.0 | 0.0 |
| Attention R2U-Net-based algorithm | 0.0429 | 0.0429 | 0.0156 | 0.0390 |
| Attention U-Net-based algorithm | 0.0156 | 0.0 | 0.0390 | 0.0429 |
| MA-U-Net-based algorithm | 0.0234 | 0.0078 | 0.0469 | 0.0664 |
| AAU-Net-based algorithm | 0.0078 | 0.0039 | 0.0195 | 0.0234 |
| Image 1 | Image 2 | Image 3 | Image 4 | |
|---|---|---|---|---|
| U-Net-based algorithm | 0.1171 | 0.2265 | 0.0820 | 0.1484 |
| M-Net-based algorithm | 0.2421 | 0.1796 | 0.2539 | 0.1484 |
| MultiResU-Net-based algorithm | 0.1367 | 0.1757 | 0.1718 | 0.1015 |
| MUM-Net-based algorithm | 0.2226 | 0.1914 | 0.1132 | 0.2265 |
| Attention ResU-Net-based algorithm | 0.0273 | 0.0625 | 0.0546 | 0.0351 |
| Attention R2U-Net-based algorithm | 0.1054 | 0.1875 | 0.0898 | 0.2070 |
| Attention U-Net-based algorithm | 0.1835 | 0.2656 | 0.2656 | 0.1445 |
| MA-U-Net-based algorithm | 0.2148 | 0.2265 | 0.2304 | 0.2109 |
| AAU-Net-based algorithm | 0.1875 | 0.2929 | 0.1601 | 0.1796 |
| T = 0.02 | T = 0.03 | T = 0.05 | T = 0.10 | T = 0.20 | T = 0.30 | |
|---|---|---|---|---|---|---|
| U-Net-based algorithm | 96.0% | 94.0% | 85.5% | 63.5% | 30.0% | 1.0% |
| M-Net-based algorithm | 98.0% | 97.0% | 93.5% | 76.5% | 37.5% | 0.5% |
| MultiResU-Net-based algorithm | 90.5% | 86.5% | 72.0% | 39.5% | 12.5% | 0.0% |
| MUM-Net-based algorithm | 99.0% | 98.5% | 94.0% | 70.0% | 31.0% | 0.0% |
| Attention ResU-Net-based algorithm | 57.0% | 47.5% | 32.5% | 16.5% | 5.0% | 0.5% |
| Attention R2U-Net-based algorithm | 99.5% | 98.5% | 95.0% | 82.5% | 52.5% | 1.0% |
| Attention U-Net-based algorithm | 96.0% | 94.0% | 85.0% | 63.5% | 30.0% | 0.0% |
| MA-U-Net-based algorithm | 96.9% | 94.8% | 91.1% | 68.2% | 28.2% | 0.5% |
| AAU-Net-based algorithm | 96.5% | 94.0% | 87.0% | 67.0% | 30.0% | 1.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, K.; Chen, S.; Wang, Y.; Liu, Y.; Zeng, Y.; Tian, J. AAU-Net: Attention-Based Asymmetric U-Net for Subject-Sensitive Hashing of Remote Sensing Images. Remote Sens. 2021, 13, 5109. https://doi.org/10.3390/rs13245109
Ding K, Chen S, Wang Y, Liu Y, Zeng Y, Tian J. AAU-Net: Attention-Based Asymmetric U-Net for Subject-Sensitive Hashing of Remote Sensing Images. Remote Sensing. 2021; 13(24):5109. https://doi.org/10.3390/rs13245109
Chicago/Turabian StyleDing, Kaimeng, Shiping Chen, Yu Wang, Yueming Liu, Yue Zeng, and Jin Tian. 2021. "AAU-Net: Attention-Based Asymmetric U-Net for Subject-Sensitive Hashing of Remote Sensing Images" Remote Sensing 13, no. 24: 5109. https://doi.org/10.3390/rs13245109
APA StyleDing, K., Chen, S., Wang, Y., Liu, Y., Zeng, Y., & Tian, J. (2021). AAU-Net: Attention-Based Asymmetric U-Net for Subject-Sensitive Hashing of Remote Sensing Images. Remote Sensing, 13(24), 5109. https://doi.org/10.3390/rs13245109