
C3Net: Cross-Modal Feature Recalibrated, Cross-Scale Semantic Aggregated and Compact Network for Semantic Segmentation of Multi-Modal High-Resolution Aerial Images

 ,
,
Abstract
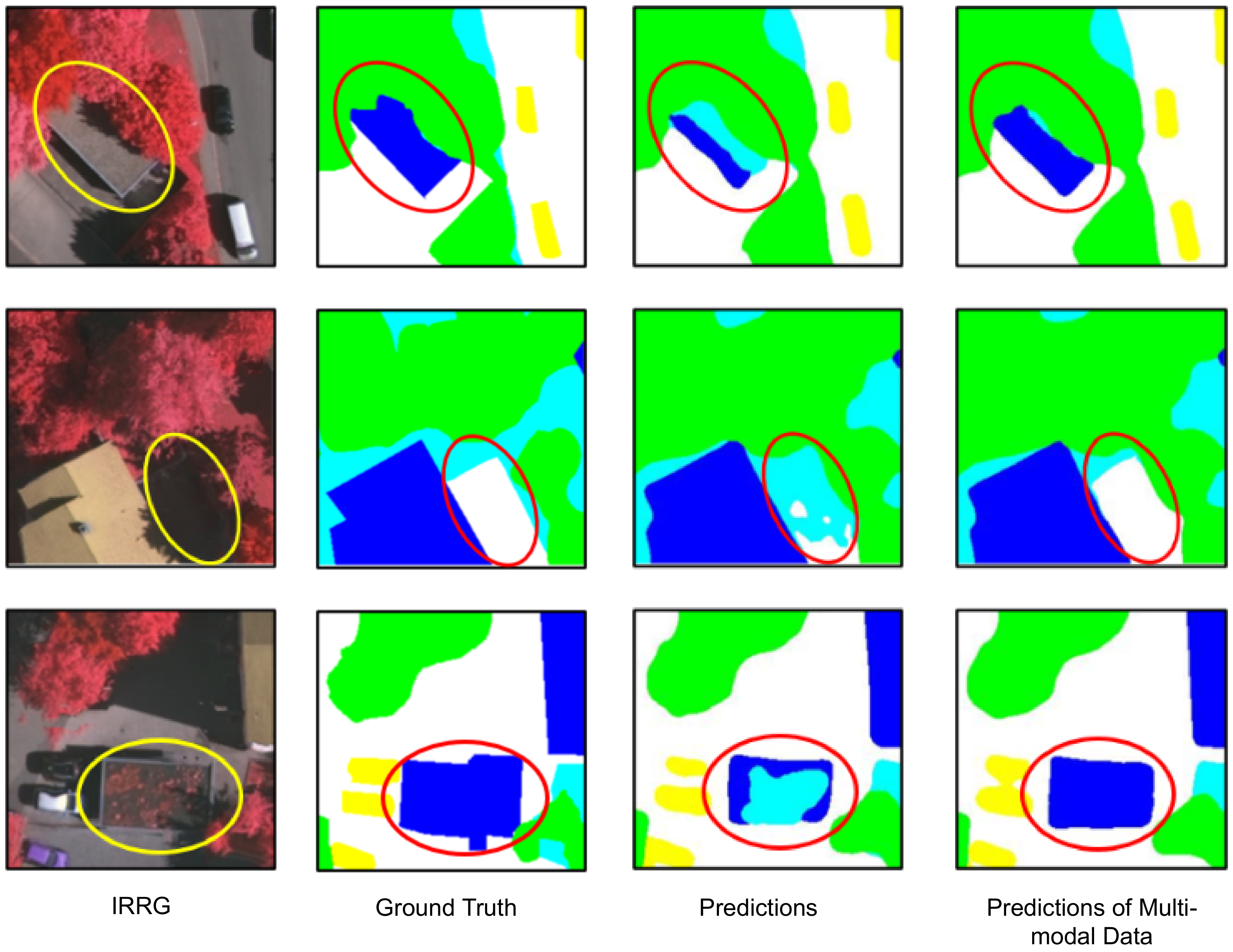
:1. Introduction
- We propose a multi-modal semantic segmentation network, C3Net, which takes into account both efficiency and accuracy. Compared with previous works, our network can be up to 15× fewer FLOPs with comparable accuracy.
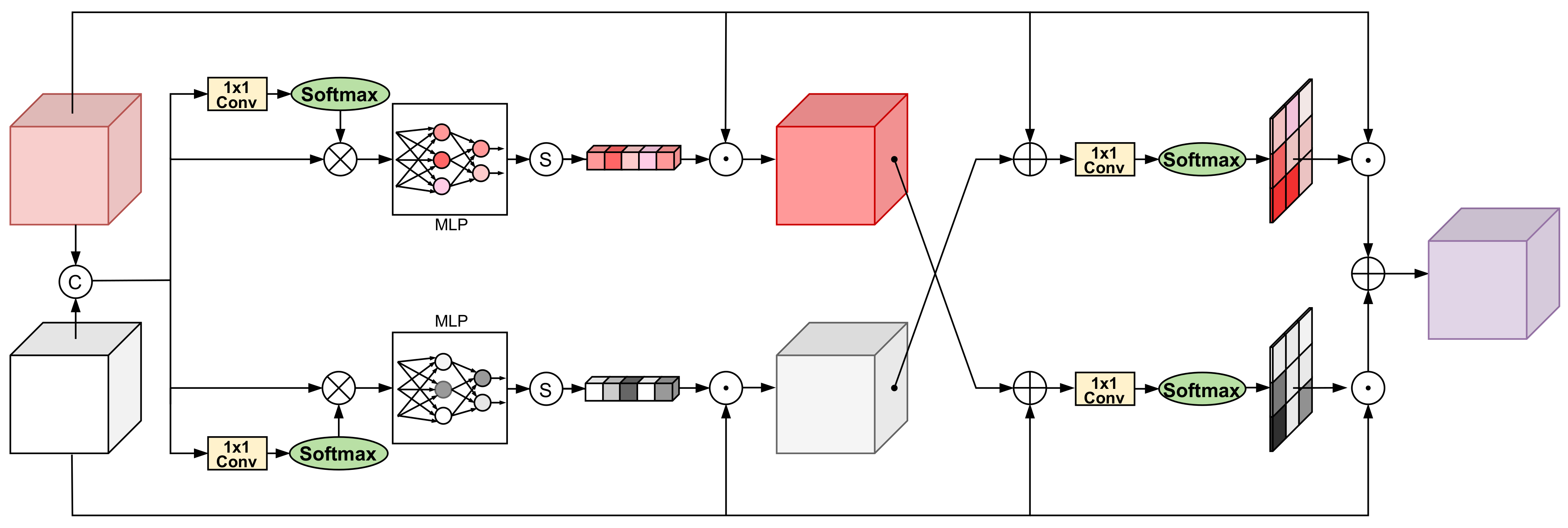
- In order to extract complementary features of different modalities, a cross-modal feature recalibration module (CFR) is designed to aggregate information of multi-modality and form discriminative representations for classification.
- A lightweight cross-scale semantic aggregation module (CSA) is introduced for adaptive multi-scale semantic context information propagation. Compared with the previous version, it can greatly reduce parameters and running time without loss of accuracy.
- A multi-level knowledge distillation strategy is utilized on a variety of compact backbones, which further reduces the model size and improves the segmentation performance of lightweight architectures.
2. Related Work
2.1. Semantic Segmentation
2.2. Lightweight Networks
2.3. Knowledge Distillation
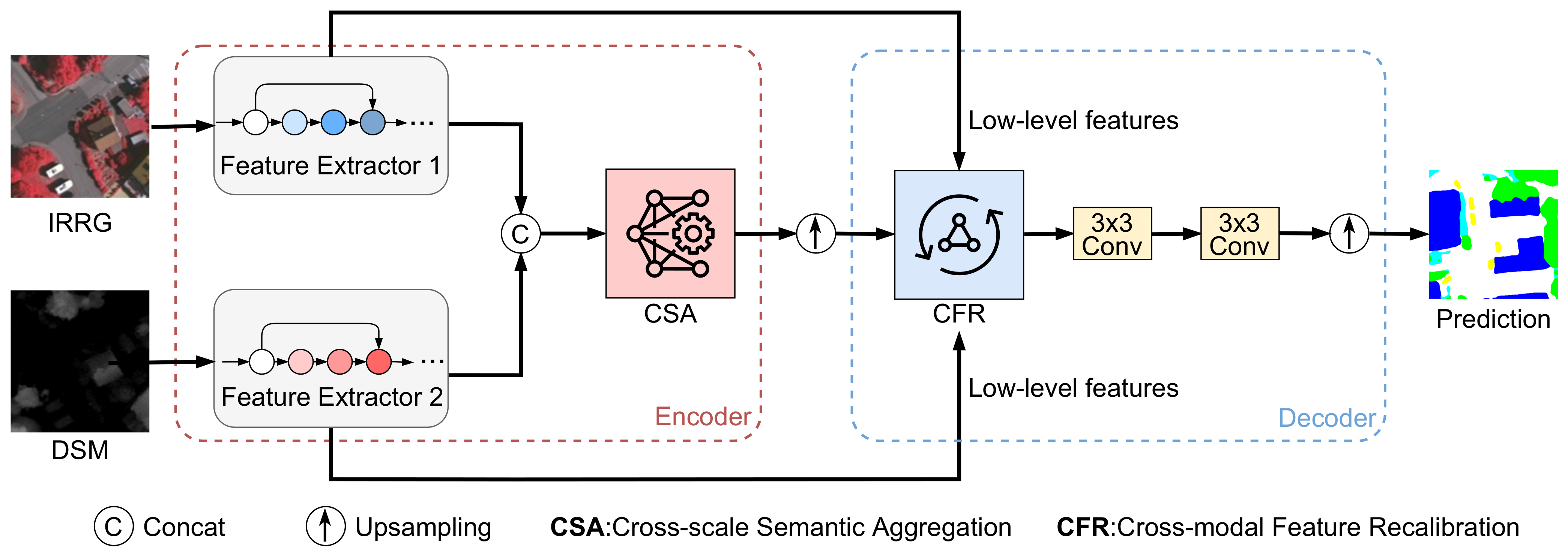
3. Method
3.1. Cross-Modal Feature Recalibration Module (CFR)
3.2. Cross-Scale Semantic Aggregation Module (CSA)
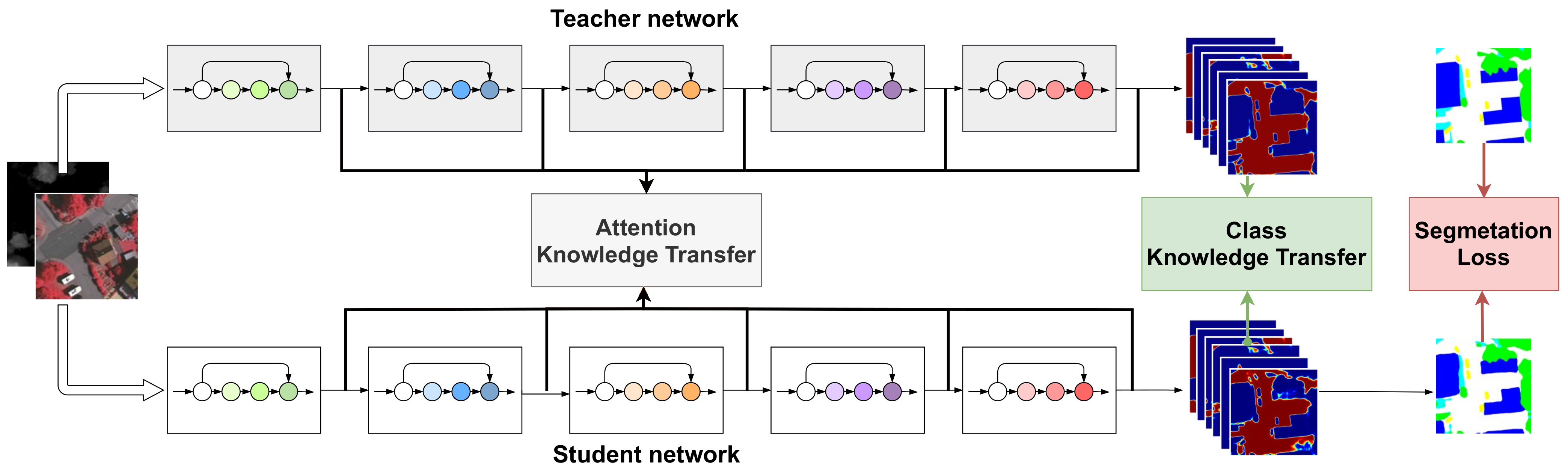
3.3. Multi-Level Knowledge Distillation Strategy
3.3.1. Class Knowledge Transfer
3.3.2. Attention Knowledge Transfer
| Algorithm 1 Training Process of Proposed Method. |
| Stage 1: Training teacher network |
| Input: Images ,Ground truths |
| Stage 2: Training student network |
| Input: Images ,Ground truths , Class-Knowledge , Attetion-knowledge |
4. Experiments
4.1. Dataset
4.1.1. ISPRS Vaihingen
4.1.2. ISPRS Potsdam
4.1.3. Dataset Augmentation
4.1.4. Evaluation
4.2. Implementation DETAILS
4.3. Results and Discussion
4.3.1. Effects of CFR
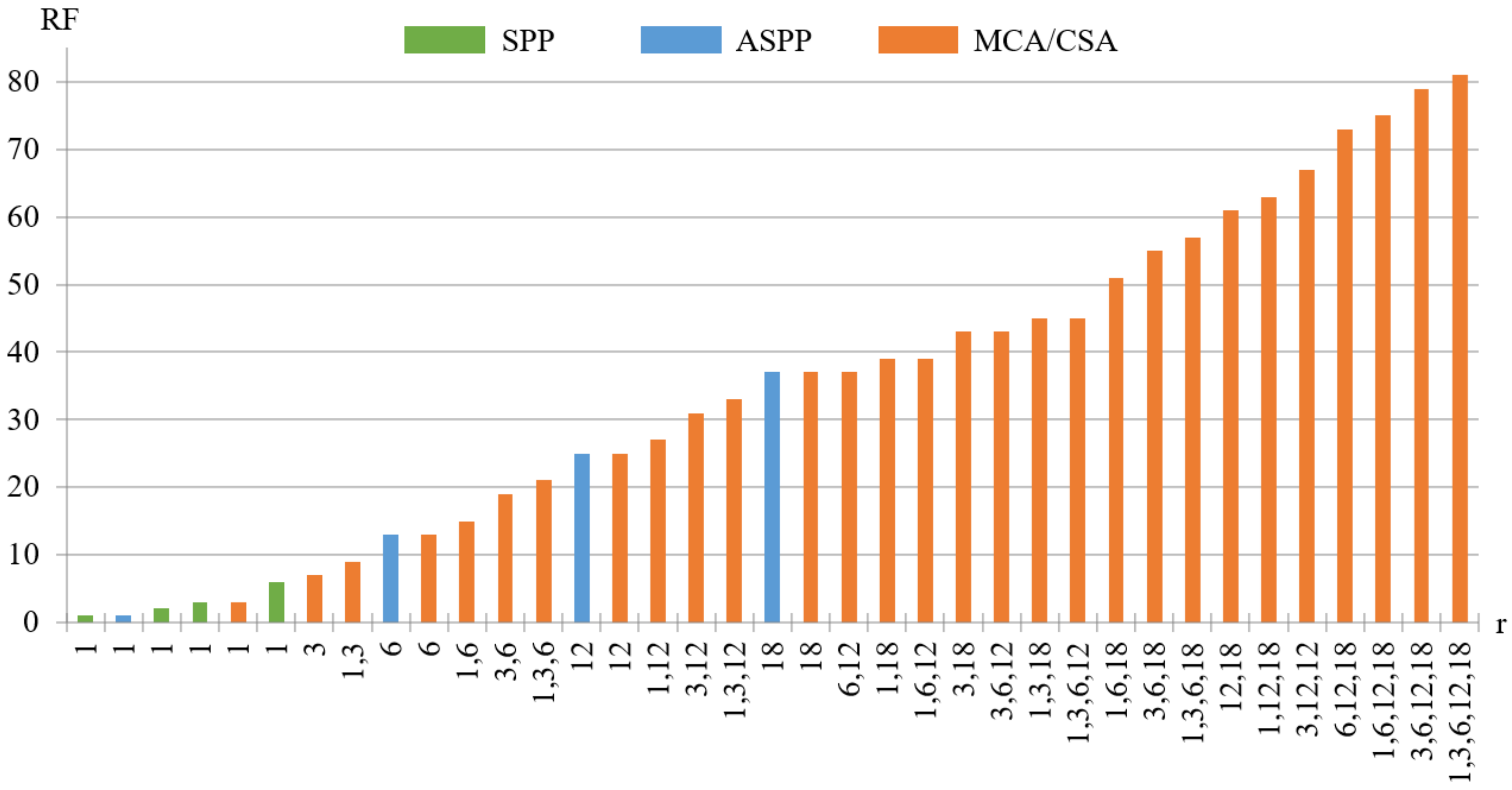
4.3.2. Effects of CSA
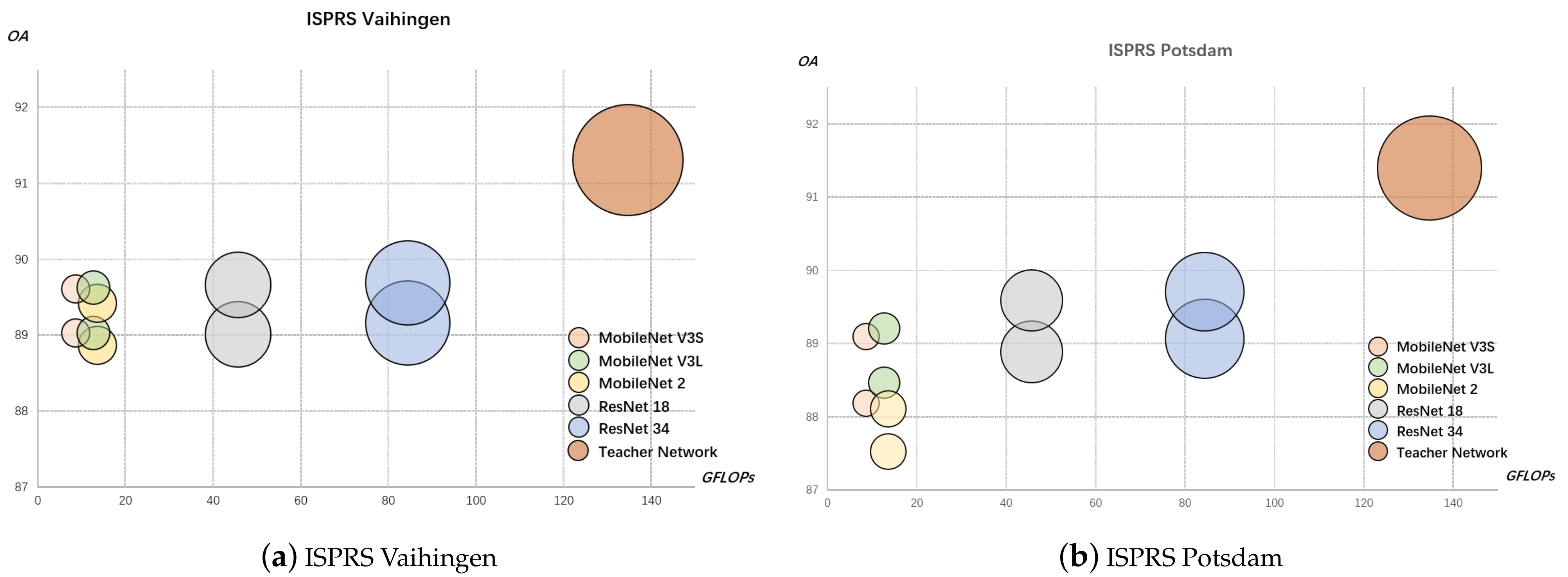
4.3.3. Effects of Multi-Level Knowledge Distillation Strategy
4.3.4. Comparing with State-of-the-Arts
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ISPRS | International Society for Photogrammetry and Remote Sensing |
| CNNs | Convolutional Neural Networks |
| SAR | Synthetic Aperture Radar |
| LiDAR | Light Detection and Ranging |
| CFR | Cross-modal feature recalibration module |
| KD | Knowledge distillation |
| OA | Overall accuracy |
| CSA | Cross-scale semantic aggregation module |
| FCN | Fully convolutional network |
| IRRG | Near Infrared-Red-Green |
| IRRGB | Near Infrared-Red-Green-Blue |
| LCG | lightweight convolution group |
| MSP | Multi-shape pooling |
| TOP | True orthophoto |
| DSM | Digital Surface models |
| nDSM | Normalized Digital Surface models |
| FLOPs | Float-point operations |
| GFLOPs | Giga Float-point operations |
References
- Fu, K.; Li, Y.; Sun, H.; Yang, X.; Xu, G.; Li, Y.; Sun, X. A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning. Remote Sens. 2018, 10, 1922. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Kun, F.; Hao, S.; Xian, S. An Aircraft Detection Framework Based on Reinforcement Learning and Convolutional Neural Networks in Remote Sensing Images. Remote Sens. 2018, 10, 243. [Google Scholar]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X. Semantic Segmentation of Aerial Images With Shuffling Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Cao, Z.; Fu, K.; Lu, X.; Diao, W.; Sun, H.; Yan, M.; Yu, H.; Sun, X. End-to-End DSM Fusion Networks for Semantic Segmentation in High-Resolution Aerial Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1766–1770. [Google Scholar] [CrossRef]
- Sun, X.; Liu, Y.; Yan, Z.; Wang, P.; Diao, W.; Fu, K. SRAF-Net: Shape Robust Anchor-Free Network for Garbage Dumps in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 1–15. [Google Scholar] [CrossRef]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-Aware Semi-Supervised Semantic Segmentation Network for Very High Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Sun, X. Point-Based Estimator for Arbitrary-Oriented Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 1–18. [Google Scholar] [CrossRef]
- Liu, J.; Chen, K.; Xu, G.; Li, H.; Yan, M.; Diao, W.; Sun, X. Semi-Supervised Change Detection Based on Graphs with Generative Adversarial Networks. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 74–77. [Google Scholar]
- Ma, H.; Liu, Y.; Ren, Y.; Yu, J. Detection of Collapsed Buildings in Post-Earthquake Remote Sensing Images Based on the Improved YOLOv3. Remote Sens. 2019, 12, 44. [Google Scholar] [CrossRef] [Green Version]
- Chai, Y.; Fu, K.; Sun, X.; Diao, W.; Wang, L. Compact Cloud Detection with Bidirectional Self-Attention Knowledge Distillation. Remote Sens. 2020, 12, 2770. [Google Scholar] [CrossRef]
- Yan, Z.; Yan, M.; Sun, H.; Fu, K.; Sun, X. Cloud and Cloud Shadow Detection Using Multilevel Feature Fused Segmentation Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1600–1604. [Google Scholar] [CrossRef]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel Segmentation of Polarimetric Synthetic Aperture Radar (SAR) Images Based on Generalized Mean Shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef] [Green Version]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. Int. J. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Braga, A.M.; Marques, R.C.P.; Rodrigues, F.A.A.; Medeiros, F.N.S. A Median Regularized Level Set for Hierarchical Segmentation of SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Yang, J. Level Set Segmentation Algorithm for High-Resolution Polarimetric SAR Images Based on a Heterogeneous Clutter Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Change Loy, C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Diao, W.; Zhang, Y.; Yan, M.; Yu, H.; Sun, X.; Fu, K. Semantic Labeling for High-Resolution Aerial Images Based on the DMFFNet. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1021–1024. [Google Scholar]
- Mou, L.; Zhu, X.X. RiFCN: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNNS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef] [Green Version]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Polytechnique, Paris, France, 2014. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, M.; Liu, B.; Foroosh, H. Factorized convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 545–553. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2820–2828. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. arXiv 2019, arXiv:1904.11492. [Google Scholar]
- Qian, C.; Li, H.; Zeng, G. Bi-directional Cross-Modality Feature Propagation with Separation-and-Aggregation Gate for RGB-D Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Duc, M.N.; Nikos, D.; Wenrui, D.; Adrian, M. Hourglass-ShapeNetwork Based Semantic Segmentation for High Resolution Aerial Imagery. Remote Sens. 2017, 9, 522. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Impervious Surface | Building | Low Vegetation | Tree | Car | OA |
|---|---|---|---|---|---|---|
| Baseline (IRRG) | 91.84 | 95.27 | 82.47 | 88.99 | 76.39 | 89.83 |
| Baseline (Directly Concatenate) | 91.15 | 95.02 | 84.12 | 89.60 | 70.13 | 89.85 |
| Baseline | 92.36 | 95.83 | 84.06 | 89.69 | 82.59 | 90.61 |
| Baseline + CFR | 92.79 | 96.01 | 84.99 | 90.06 | 83.29 | 91.08 |
| Module | Parameters | GFLOPs | Overall Accuracy |
|---|---|---|---|
| - | 0 | 0 | 90.36 |
| ASPP | 30,737,920 | 8.582 | 90.61 |
| SPP | 68,157,696 | 1.201 | 90.63 |
| MCA | 49,613,312 | 28.08 | 91.03 |
| CSA | 21,969,888 | 2.327 | 91.15 |
| Level 5 | Level 4 | Level 3 | Level 2 | Level 1 | Overall Accuracy |
|---|---|---|---|---|---|
| 89.01 | |||||
| ✓ | 89.42 | ||||
| ✓ | ✓ | 89.51 | |||
| ✓ | ✓ | ✓ | 89.56 | ||
| ✓ | ✓ | ✓ | ✓ | 89.57 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 89.66 |
| Methods | Impervious Surface | Building | Low Vegetation | Tree | Car | OA | |
|---|---|---|---|---|---|---|---|
| CH3 | FCN [55] | 89.4 | 93.8 | 76.5 | 86.6 | 71.3 | 86.8 |
| SegNet [22] | 90.2 | 94.1 | 77.4 | 87.4 | 77.3 | 87.6 | |
| DANet [56] | 94.1 | 90.8 | 81.4 | 87.4 | 75.9 | 88.6 | |
| DeepLab V3p [25] | 94.3 | 91.4 | 81.3 | 87.8 | 78.1 | 88.9 | |
| PSPNet [27] | 94.4 | 91.4 | 81.5 | 87.9 | 78.0 | 89.0 | |
| Baseline(ResNet101) | 91.8 | 95.3 | 82.5 | 89.0 | 76.4 | 89.8 | |
| HRNet+ASP+SR [57] | 94.7 | 92.9 | 83.2 | 88.9 | 84.3 | 90.1 | |
| Baseline+CSA | 92.3 | 95.6 | 83.6 | 89.3 | 80.7 | 90.4 | |
| CH4 | FPL [58] | 90.4 | 94.6 | 78.1 | 86.8 | 66.8 | 87.7 |
| HSN+OI+WBP [59] | 91.3 | 94.9 | 79.8 | 88.3 | 83.6 | 88.8 | |
| FCN [60] | 90.5 | 93.7 | 83.4 | 89.2 | 72.6 | 89.1 | |
| SegNet-RC [18] | 91.0 | 94.5 | 84.4 | 89.9 | 77.8 | 89.8 | |
| FCN+fusion+boundaries [20] | 92.3 | 95.2 | 84.1 | 90.0 | 79.3 | 90.3 | |
| FCN_MFS_DSMBackend [19] | 92.3 | 95.8 | 83.8 | 89.6 | 86.4 | 90.6 | |
| Baseline | 92.4 | 95.8 | 84.1 | 89.7 | 82.6 | 90.6 | |
| C2Net | 93.0 | 96.1 | 85.4 | 90.3 | 85.4 | 91.3 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Z.; Diao, W.; Sun, X.; Lyu, X.; Yan, M.; Fu, K. C3Net: Cross-Modal Feature Recalibrated, Cross-Scale Semantic Aggregated and Compact Network for Semantic Segmentation of Multi-Modal High-Resolution Aerial Images. Remote Sens. 2021, 13, 528. https://doi.org/10.3390/rs13030528
Cao Z, Diao W, Sun X, Lyu X, Yan M, Fu K. C3Net: Cross-Modal Feature Recalibrated, Cross-Scale Semantic Aggregated and Compact Network for Semantic Segmentation of Multi-Modal High-Resolution Aerial Images. Remote Sensing. 2021; 13(3):528. https://doi.org/10.3390/rs13030528
Chicago/Turabian StyleCao, Zhiying, Wenhui Diao, Xian Sun, Xiaode Lyu, Menglong Yan, and Kun Fu. 2021. "C3Net: Cross-Modal Feature Recalibrated, Cross-Scale Semantic Aggregated and Compact Network for Semantic Segmentation of Multi-Modal High-Resolution Aerial Images" Remote Sensing 13, no. 3: 528. https://doi.org/10.3390/rs13030528
APA StyleCao, Z., Diao, W., Sun, X., Lyu, X., Yan, M., & Fu, K. (2021). C3Net: Cross-Modal Feature Recalibrated, Cross-Scale Semantic Aggregated and Compact Network for Semantic Segmentation of Multi-Modal High-Resolution Aerial Images. Remote Sensing, 13(3), 528. https://doi.org/10.3390/rs13030528