1. Introduction
A hyperspectral sensor is a spectrometer that can simultaneously image a specific area on consecutive tens or hundreds of bands to obtain a hyperspectral image (HSI). Compared with multispectral images, HSIs have a wide range of bands and higher spectral resolution. Because hyperspectral imaging involves different bands, HSIs can obtain rich spectral information [
1], which is conducive to resource exploration [
2] and environmental monitoring [
3]. However, due to its high data dimensions, there is a problem of dimensional disaster in HSI processing. In fact, in the classification of hyperspectral data, many bands are redundant and have little positive effect on the classification result, so they seriously affect the processing results and efficiency. Therefore, feature selection and feature extraction came into being. For example, principal component analysis (PCA) [
4,
5] and independent component analysis (ICA) [
6,
7] are typical methods that transform high-dimensional data into low-dimensional data. In traditional HSI classification methods, support vector machine (SVM) [
8,
9], random forest [
10], and other methods have been considered as efficient algorithms. Moreover, a problem is that different spectra presented by HSIs may belong to the same category and similar spectra may belong to different categories, so it is difficult to obtain a high accuracy in classification by only considering spectral information. In recent years, the question of how to make full use of spatial features has become attractive in the field of HSI classification.
Kang et al. [
11] used the first principal component or the first three principal components of an HSI as a gray or color guide image to perform an edge-preserving filtering on the probability map obtained by the classifier, and then they selected the largest probability pixel to achieve classification. Additionally, adding texture features can be used to increase the classification accuracy of an HSI [
12]. In recent years, deep networks have gained widespread attention. A stacked autoencoder (SAE) [
13,
14], as one of the typical deep learning models, can extract and classify features by encoding and decoding the input vectors. Deep belief networks (DBNs) [
15] and convolutional neural networks (CNNs) [
16,
17,
18] have been proposed for spectral–spatial HSI classification. Furthermore, to obtain deep-level features, Zhao et al. [
19] used dimensionality reduction methods and 2DCNN models to extract spectral and spatial features. Using the neighborhood block as the input of the network, a 3DCNN [
20,
21] was used to direct extracted spectral and spatial features from an original HSI to make full use of its spectral–spatial features and improve the classification results. Mou et al. [
22] proposed the idea to use the time-series networks such as the RNN (recurrent neural network), LSTM (long short-term memory), and GRU (gated recurrent unit) for HSI classification, but the method only extracted hyperspectral spectral features, thus leading to limited classification accuracy. Xu et al. [
23] proposed a multi-scale CNN model. This model first performed PCA on HSIs to extract three principal components as the input of the network, which combined the characteristics of each pooling layer with the spectral characteristics to classify HSIs. In this method, only three principal components were extracted from hyperspectral data as input features, and most HSI information was lost, so it was not good enough to achieve excellent classification results. Zhong et al. [
24] designed a spectral spatial residual network (SSRN) for HSI classification, where the input data was a three-dimensional cube and the network used spectral and spatial residual blocks to learn discriminative features from the rich spectral and spatial features in the original HSI. However, this method only used residual alternating learning to obtain fusion features, and the feature fusion was not sufficient, so the extraction of spatial features was not good enough. Mu et al. [
25] proposed a multi-scale and multi-level spectral–spatial feature fusion network (MSSN), where neighborhood blocks of different scales were used as the input of the network. The spectral features extracted by the 3D convolutional neural network and the spatial features extracted by the 2D convolutional neural network were combined in the form of 3D–2D alternating residual blocks and a self-mapping method. Song et al. [
26] designed a deep feature fusion network (DFFN) for HSI classification by introducing residual learning and simultaneously adding the outputs of different levels of networks to further improve the classification results. The fusion method, however, was only an addition operation of the output features at different levels, the feature fusion of which was too simple and resulted in an insufficient fusion. Guo et al. [
27] proposed an efficient deep feature extraction and HSI classification method based on multi-scale spatial features and cross-domain convolutional neural network (MSCNN) that could make full use of the multi-scale spatial features obtained by the guided filter. The cross-domain convolutional neural network was used to reorder the multi-scale spatial features, which were then input into a simple convolutional neural network model for classification. This method only performed a kind of recombination operation on the edge features, and it did not introduce other features. The network model only extracted features simply and did not make full use of the features of the HSI.
To solve the above problems and to adaptively fuse the two different features in a deep network, we propose a spectral–spatial HSI classification method based on deep adaptive feature fusion (SSDF). In this paper, a U-shaped network structure was used to enhance the fusion of deep features. The edge features and the principal component features of the HSIs were fused adaptively to obtain new features. The new features were input into a multi-scale and multi-level feature extraction (MMFE) model, and the output features were then combined with the spectral features for classification.
The contributions of this work are as follows:
(1) The authors of this paper propose a U-shaped deep network that can adaptively fuse two different features consisting of convolutional layers, pooling layers, and deconvolution layers. The U-shaped network model was constructed to make sure that the two different features and the new feature after fusion have the same size. The labels of the U-shaped network are not the true labels of the image that are used in most literature; instead, they are the edge feature maps obtained by the guided filtering. The inputs of the U-shaped network are hyperspectral principal component feature maps. The U-shaped network is trained to learn the correlation and complementarity of two different features, adaptively fusing two different features and generating new feature maps. The new feature maps alleviate the problem of the low classification accuracy caused by using single kind of features.
(2) The authors of this paper designed an MMFE model that extracts the feature map of each pooling layer for convolution operation and finally inputs the convolved features to the global average pooling layer to extract the main information. The extraction of multi-level and multi-scale features can deeply extract the edge and abstract features of the image, which is beneficial to the final classification. The proposed deep adaptive feature fusion and spectral–spatial classification network uses advanced and different kinds of features as the input of the classification network, which can realize the multi-scale and multi-level fusion of multiple features, thus resulting in higher classification accuracy.
2. Materials and Methods
Here, we introduce SSDF.
Section 2.1,
Section 2.2 and
Section 2.3 introduce the methods for feature extraction and fusion, and
Section 2.4,
Section 2.5 and
Section 2.6 introduce the methods for the classification of the extracted features. Assume there is a hyperspectral dataset
, where
N is the number of labeled pixels and
b is the number of spectral bands.
represents the corresponding one-hot label vector set, where
L is the category of objects. We partition all data available into three sets—the training, validation, and test sets, which are denoted by
,
, and
, respectively. Their corresponding one-hot label vector sets are
,
, and
. First, the SSDF network uses
and
to update the network parameters. Then,
and
are used to monitor the temporary model generated by the network. Finally,
and
are used to evaluate the performance of the optimal training model.
2.1. Guided Filter for Edge Feature Extraction
Guided filtering [
28] is an edge preservation filter with excellent performance that can make the output image retain the characteristics of the filtered image and better load the edge information of the guided image. In fact, the guided filtering method makes use of a local linear relationship between the output image of the guided filtering and the guided image. Assuming that the guided image is
I and the input image is
s, the filtered output image
c is obtained by a local linear model as follows:
where
is a square window with pixel
at the center and its length and width is
.
and
are the coefficients to be estimated of the linear model.
Then, to estimate the
and
parameters of the linear model, a cost function is established according to the difference between the input image
s and the output image
c:
where
is a regularization parameter that avoids making
too large. Finally, the ridge regression technique [
29] is used for parameter estimation. By minimizing the cost function (Equation (2)), the coefficients
and
can be solved as follows:
where
and
are the mean and the variance of the guided image
I in the window, respectively;
is the total number of pixels in the window; and
is the mean of the input image
s in the window. The guided filtered output image can be calculated after the
and
coefficients are obtained.
It can be seen from Equation (1) that the output image and the guided image have a linear relationship in the window, that is . Therefore, when the guided image I contains edge information, the output image c retains the edge information at the corresponding position. Therefore, the output image c is a feature map with the edge features of the HSI.
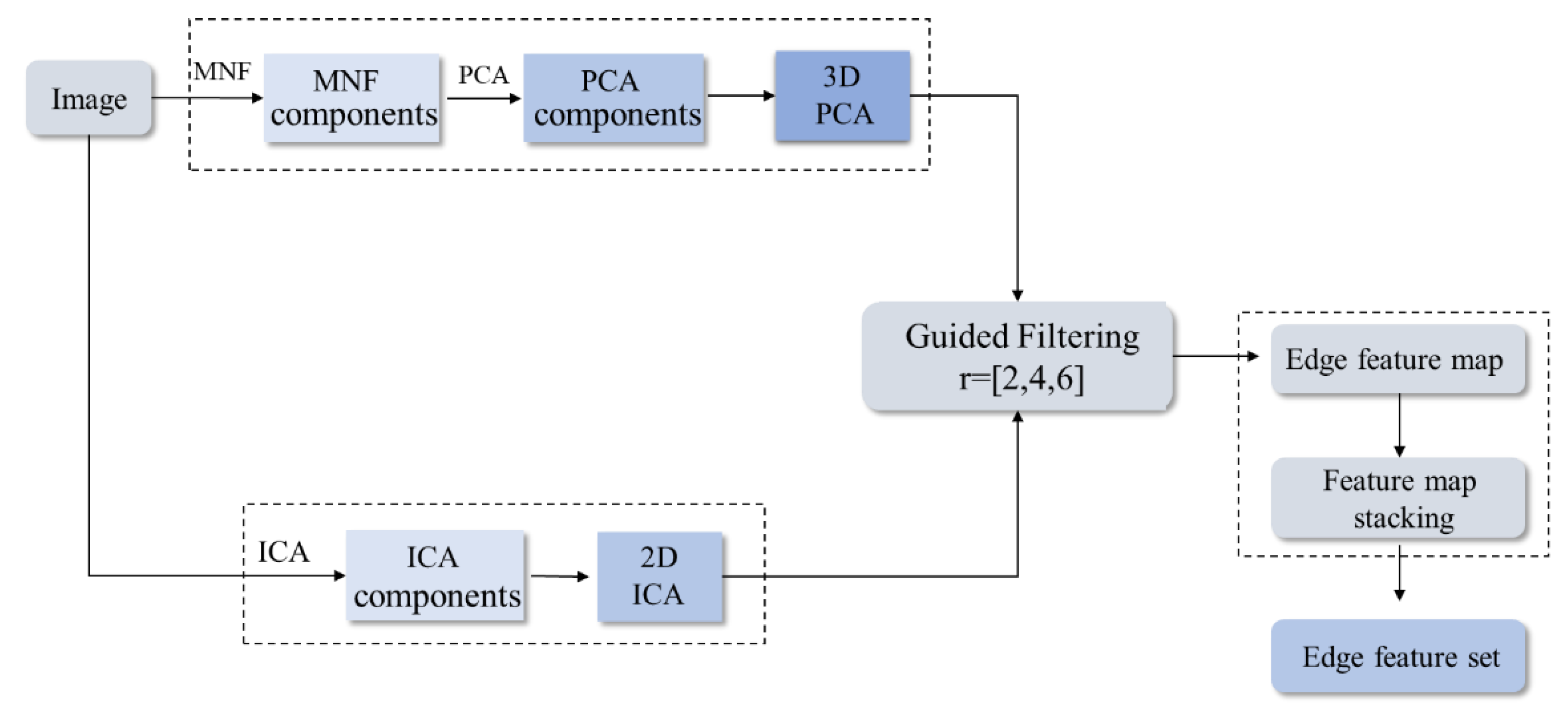
The authors of this paper used guided filtering technology to extract the edge features of the image, as shown in
Figure 1.
In
Figure 1, it can be seen that the minimum noise fraction rotation (MNF) [
30] is used to denoise the input image first, and then PCA is used to extract the first few principal components of the denoised image as the input image PC
1-PC
e for guided filtering. The guided image is the first independent component feature map IC
1 of the HSI extracted by ICA. Taking PC
1-PC
e as input images and using IC
1 and three different windows [
2,
4,
6] to perform guided filtering operations to obtain 3
e filtering feature vectors at various scales, we can stack all vectors to form a multi-scale guided filtering feature set, namely the edge feature image set.
2.2. Principal Component Feature Extraction
Because the high-dimensional characteristics of HSIs bring problems such as computational complexity and information redundancy, it was required to use PCA to reduce the dimensionality of the spectral information of HSIs and to extract the first
e principal component features. The spectral matrix
of the HSI is obtained according to the spectral information of the samples as follows:
where
n denotes the number of all pixels in the HSI,
p denotes the length of the spectral information of the samples,
represents the spectral matrix of the HSI with
n samples, and each row of
represents a spectrum sample with length
p. We calculate the average value
of the
i-th dimensional spectral information of the sample by the following formula:
Further calculations yield the covariance matrix
S of the spectral matrix
:
The component at the
i-th row and the
j-th column of the covariance matrix
S is:
where
represents the
j-th dimensional spectral value of the
k-th sample,
represents the average value of the
j-th dimensional spectral values of all the samples, and
.
Then, the covariance matrix S is diagonalized, and the feature vectors are orthogonally normalized. The normalized eigenvectors are arranged according to the size of the corresponding eigenvalues, from large to small, to obtain a feature matrix . Then the spectral feature matrix , where the first c columns of are the first c principal component features of the HSI.
Thus far, we used guided filtering to obtain the features that contain the main edge information of the HSI, and we adopted PCA to reduce the dimensions to obtain the features that contain the principal components of an HSI.
2.3. Adaptive Feature Fusion
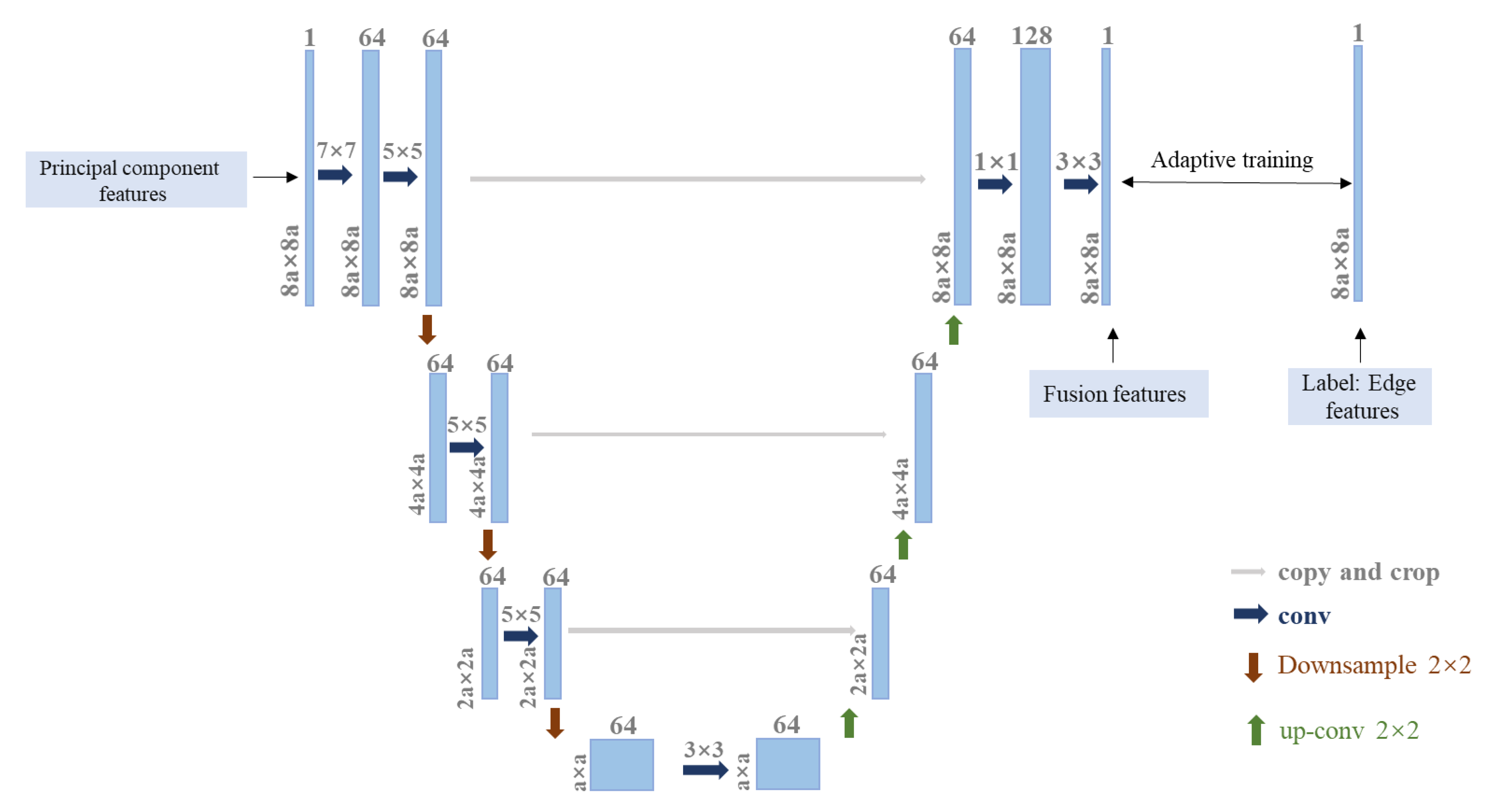
During the linear transformation of guided filtering, due to the difference in the radius of the sliding window, a part of the image information will be lost and the image information will not be fully utilized. In contrast, the principal component features of an HSI are the first few principal components of the image obtained by the PCA dimensionality reduction of the whole image, which can make up for the problem of information loss caused by the different sliding window radii in guided filtering. Therefore, to make more comprehensive use of HSI information, the authors of this paper adaptively fused these two different HSI features so that the HSI information could be fully utilized. As a deep autonomous learning model, deep learning can make a network adaptively learn the correlation and difference between model inputs and model labels by training on a network, thereby generating fusion features that contain both edge features and principal component features. Thus, the authors of this paper designed a U-shaped deep fusion network model with the principal component features as the model input and the edge features as the model label. The final output of the model comprises the fusion features that contain edge features and principal component features. The U-shaped network structure is shown in
Figure 2.
In
Figure 2, a, 2a, 4a, and 8a represent the size of the feature map; 1 × 1, 3 × 3, 5 × 5, and 7 × 7 represent the size of the convolution kernel; and 1, 64, and 128 represent the dimensions of the image. The fusion model consists of three parts: a convolution layer, a pooling layer (downsampling layer), and a deconvolution layer. This U-shaped structure, using the redefined input data and label data, enhances the fusion of the two features. As a feature extractor, the convolution layer can convert the input image into multi-scale features, which makes the features more abstract. However, the purpose of the designed network is to fuse features with the same size as the input features. Therefore, a deconvolution layer is designed after the convolutional layer, which can generate dense and enlarged feature maps.
Assume that the input data of the U-shaped model is
x, and the output of the
i-th convolutional layer is represented as:
where
is the activation function of the
i-th layer and
and
represent the filters and bias vectors of the
i-th layer, respectively. According to the description of the proposed U-shaped architecture, the estimation of the network parameters
can be obtained by minimizing the loss between the fusion features and the label features, where
M is the number of layers of the model. The loss function is expressed by mean square error as follows:
where
represents the output of the network,
represents the label feature map, and
H represents the number of pixels on each feature map. The authors of this paper made use of multiple feature maps for feature fusion, so after each training gets a fused feature, the network parameters are initialized and the next feature map is retrained until all feature maps have been trained. All the obtained fusion feature maps are stacked in the spectral dimension to obtain the adaptive fusion features with the same dimensions and sizes as the original two features. These features include the edge and principal component features of the HSI, and the fusion features obtained by the adaptive method are more beneficial to the HSI classification.
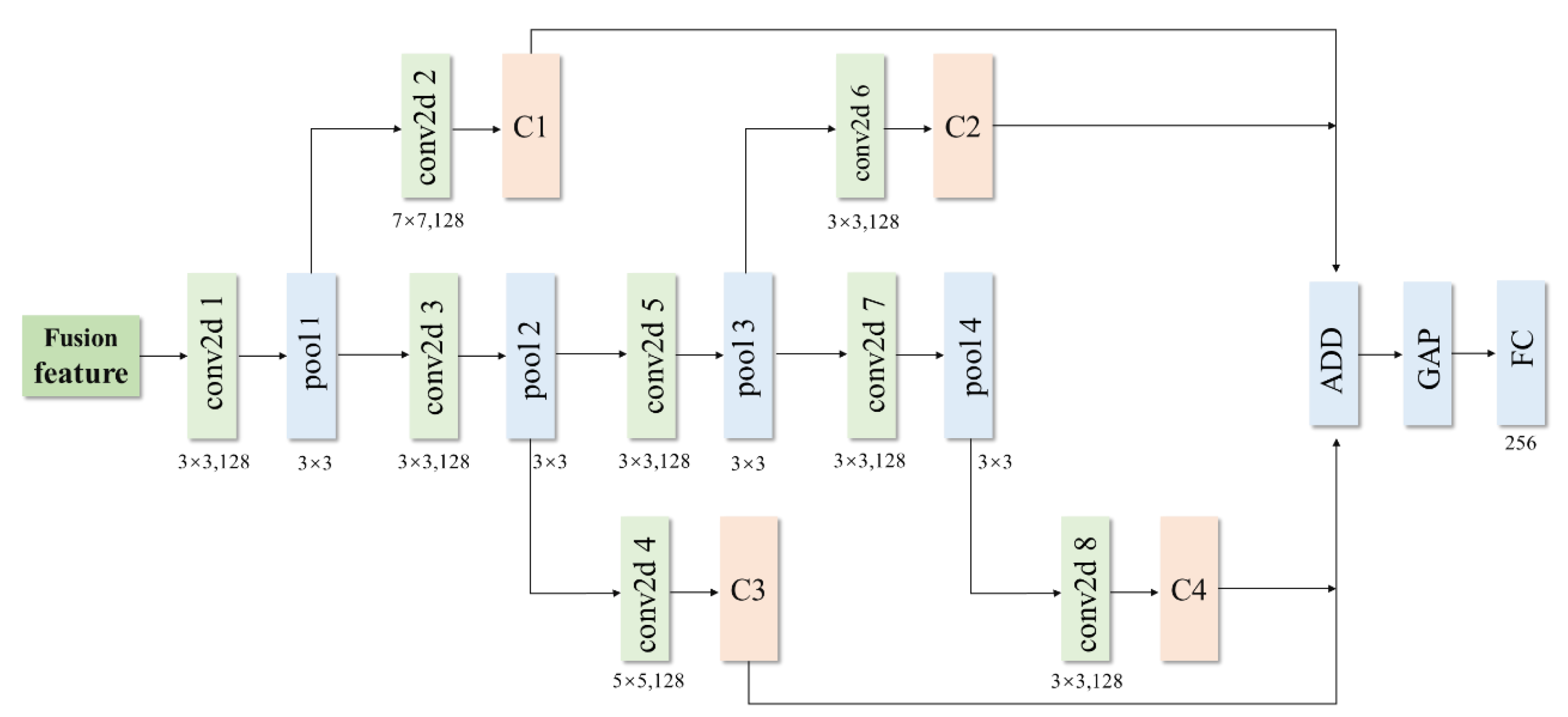
2.4. Multi-Scale and Multi-Level Feature Extraction
The method shown in
Figure 2 merely fuses the two kinds of features adaptively. To achieve better classification results, we needed to design a deep-level feature extraction and classification model. In this paper, an MMFE model was designed for classification. With the increasing of the number of convolutional layers, the spatial size of the feature map decreases sharply, leading to some information loss of the image. In a traditional CNN architecture, the fully connected layer is usually directly connected to the output of the last convolutional layer. In this case, the network pays more attention to the deep features and ignores the shallow features. The authors of this paper propose combining shallow convolution features with deep ones in classification. A diagram of the MMFE is given in
Figure 3.
To make full use of the features of different levels, the proposed network adds a 2D convolution layer (conv2d) after each pooling layer. The first purpose of this is to extract multi-level features by adding convolution layers at different levels. The second is that the size of the feature map can be changed by using a convolution layer so that the feature maps of different levels have the same size after passing through the convolution layer. Let denote the i-th feature map obtained by introducing the convolutional layer after the pooling layer, where is the activation function, is the feature map after the pooling layer, and and are the corresponding weight matrices and bias terms, respectively. The multi-level feature map output by the convolution is input to the ADD layer to perform addition , and the combined is then input to the global average pooling (GAP) to stretch it into a one-dimensional tensor, where the GAP can extract the main information of the feature map and can reduce parameters at the same time. The output of GAP finally passes through the fully connected layer (FC). This model extracts the deep features of the new features after fusion, and the obtained features also have multiple levels.
2.5. Spectral Feature Extraction
The authors of this paper used the LSTM model to extract the spectral features of the original HSI. The core module in the LSTM model is the storage unit, as shown in
Figure 4.
The storage unit consists of four elements, i.e., the input gate (), the forget gate (), the output gate (), and the cell state (). The input gate determines how much new information is added to the cell state (). The output of the output gate is based on the cell state, but it is also a filtered version. The forget gate determines what information is discarded from the cell sate. The output of LSTM is . In the above formulas, is the weight matrix and is the bias vector; is the hyperbolic tangent; is the sigmoid function; and is the dot product. is each band of the HSI input into the LSTM model, and is the corresponding one-dimensional resultant vector. All the bands of pixels on the HSI are sequentially input into the LSTM model, and then a one-dimensional vector is output. Thus, the one-dimensional vector is a feature vector with the spectral characteristics of the HSI.
2.6. SSDF Model
Section 2.1,
Section 2.2,
Section 2.3 and
Section 2.4 introduced the adaptive feature fusion of edge features and principal component features, as well as the MMFE model for classification. These methods focus on processing the spatial context of pixels without considering the correlation between the pixels and different bands. Though deep feature extraction and fusion are performed on HSIs, most of the band information is ignored during feature preprocessing, and spectral features are not fully utilized. Therefore, we further introduced the LSTM model (
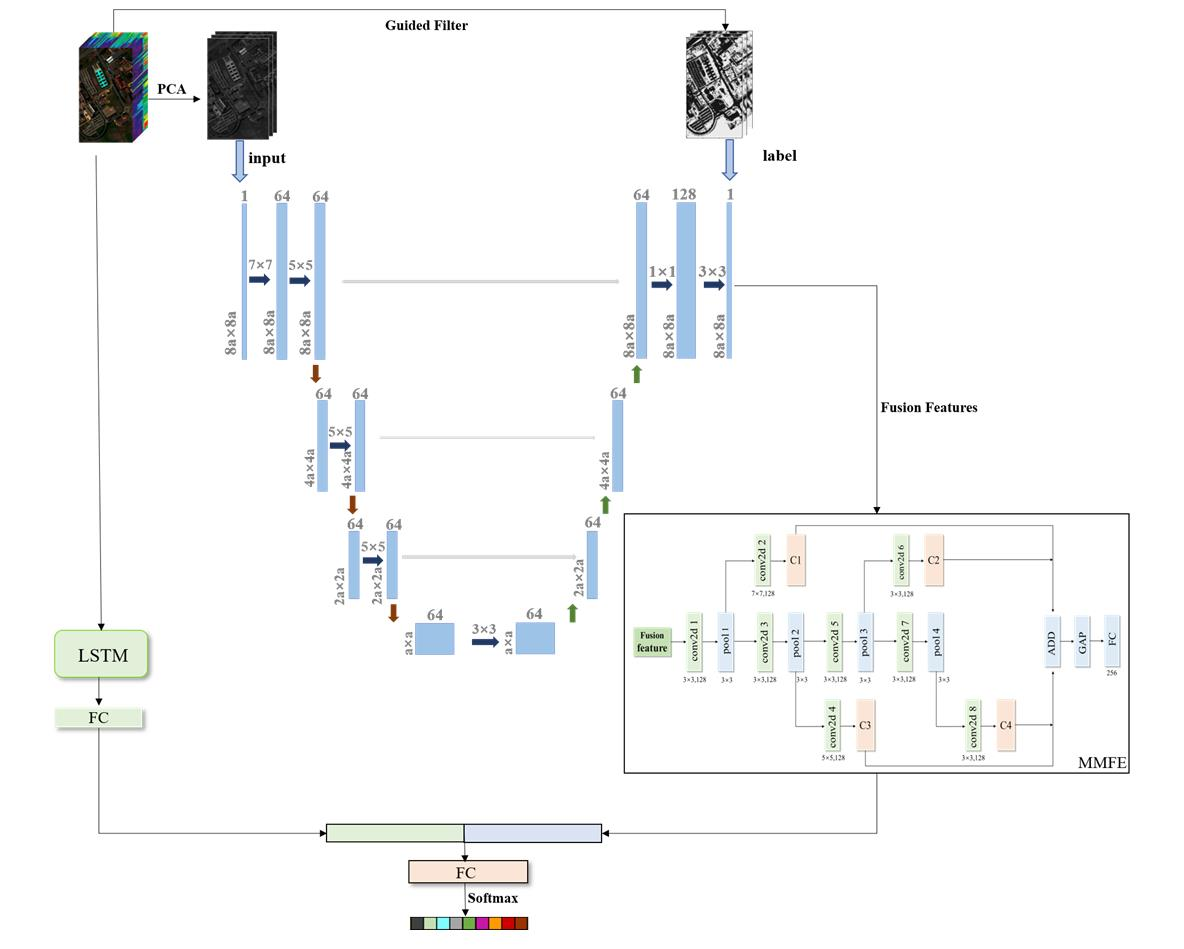
Section 2.5) to extract the spectral band information of the HSI, which is combined with the spatial features obtained by the MMFE model to perform spectral–spatial classification and form a complete SSDF method. As shown in
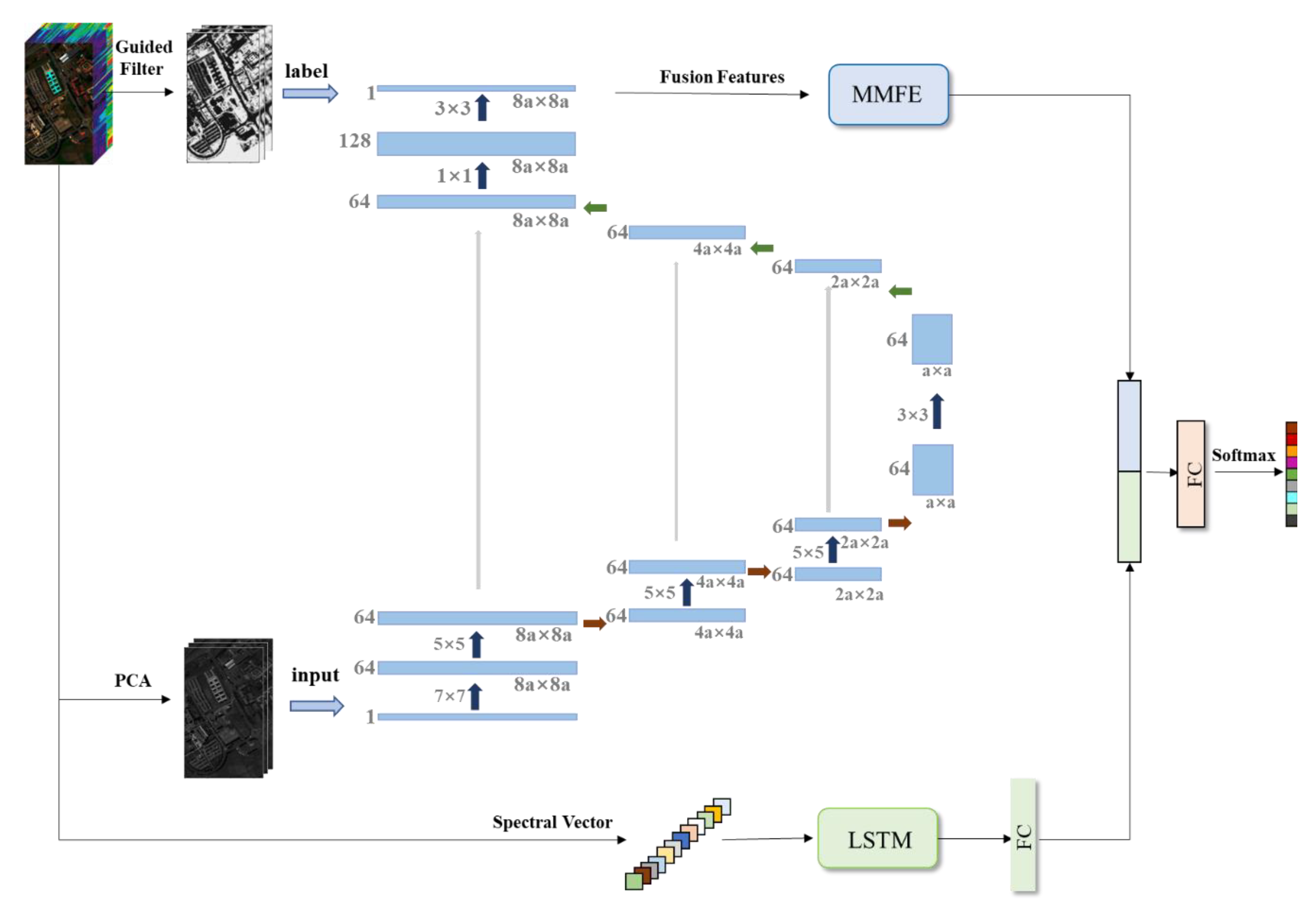
Figure 5, SSDF designs a deep adaptive fusion model to fully fuse the principal component features extracted by PCA and the edge features extracted by guided filtering, and the fused features are further extracted by MMFE and then combined with the spectral features extracted by LSTM for the final classification, which improves the classification accuracy. The Pavia University hyperspectral dataset [
31] was input into the network of the proposed SSDF as an example, which is shown in
Figure 5.
The network in the upper half of
Figure 5 consists of two parts: one is the feature fusion network and the other is the MMFE model. The two networks are independently trained without affecting each other. In the feature fusion network, the first
c principal components of the HSI are used as the input of the fusion network, and the hyperspectral edge feature map obtained by the guided filtering is used as the labels of the fusion network. During network training, only one principal component feature map is input at a time, corresponding to the label that is also an edge feature map. The feature map output by the last layer of the network after training is a fusion feature map that combines two hyperspectral features. A total of
c feature maps need to be fused, so each time a feature map is re-input, the network parameters are initialized to ensure training consistency. After all the
c feature maps are trained, the obtained
c feature maps are stacked to get the final fusion feature. Then, the obtained fused features are input into the MMFE network to further extract multi-scale and multi-level features. The MMFE network outputs a one-dimensional spatial feature vector
by using convolution layers and pooling operations alternately, followed by a fully connected layer.
The input of the lower half of
Figure 5 is the original HSI. For this example, all the bands of each pixel of the HSI were input into the LSTM model to obtain the one-dimensional feature vector of the pixel. This feature vector was then input into a fully connected layer to further extract integrated features to obtain a spectral feature vector
.
In the SSDF model, the spatial feature vector
, spectral feature vector
, and the classifier training are integrated into a unified network. To complete the unified spectral–spatial classification using the feature stacking method, the feature vector
obtained in the MMFE is connected to the feature vector
obtained in the LSTM to form a new feature vector
, which then passes through a fully connected layer and a SoftMax layer. The loss function of SSDF is defined as Equation (12).
where
represents the label feature map,
represents the corresponding predicted label of the
i-th training sample, and
represents the size of the training set. As the classification network is trained, all parameters are simultaneously optimized by a small batch random gradient descent algorithm. Finally, the SoftMax layer generates the prediction vector set
.
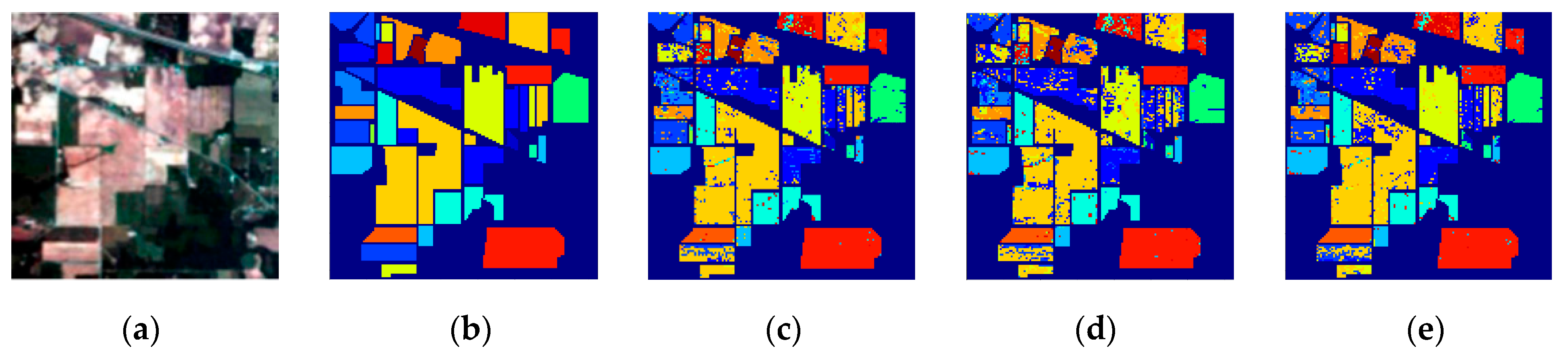
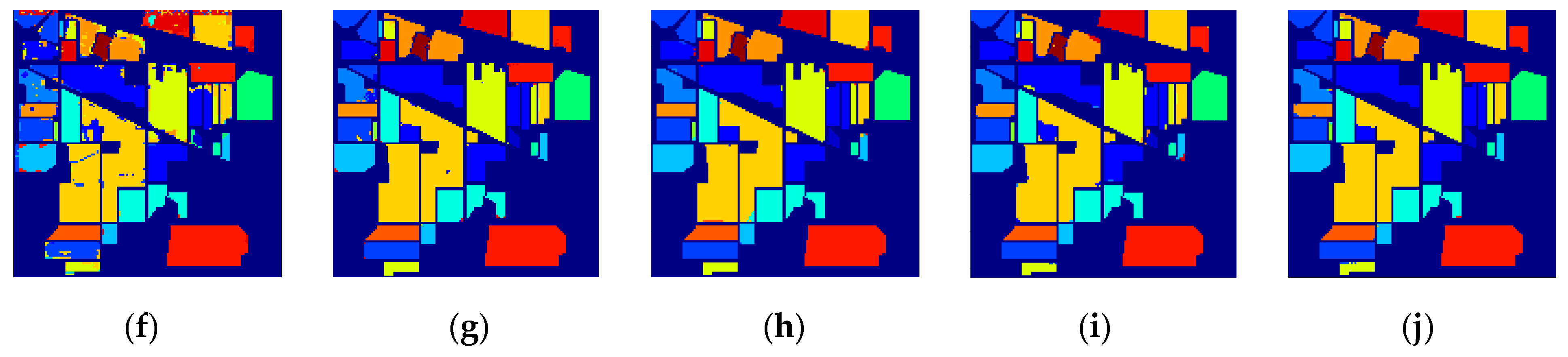
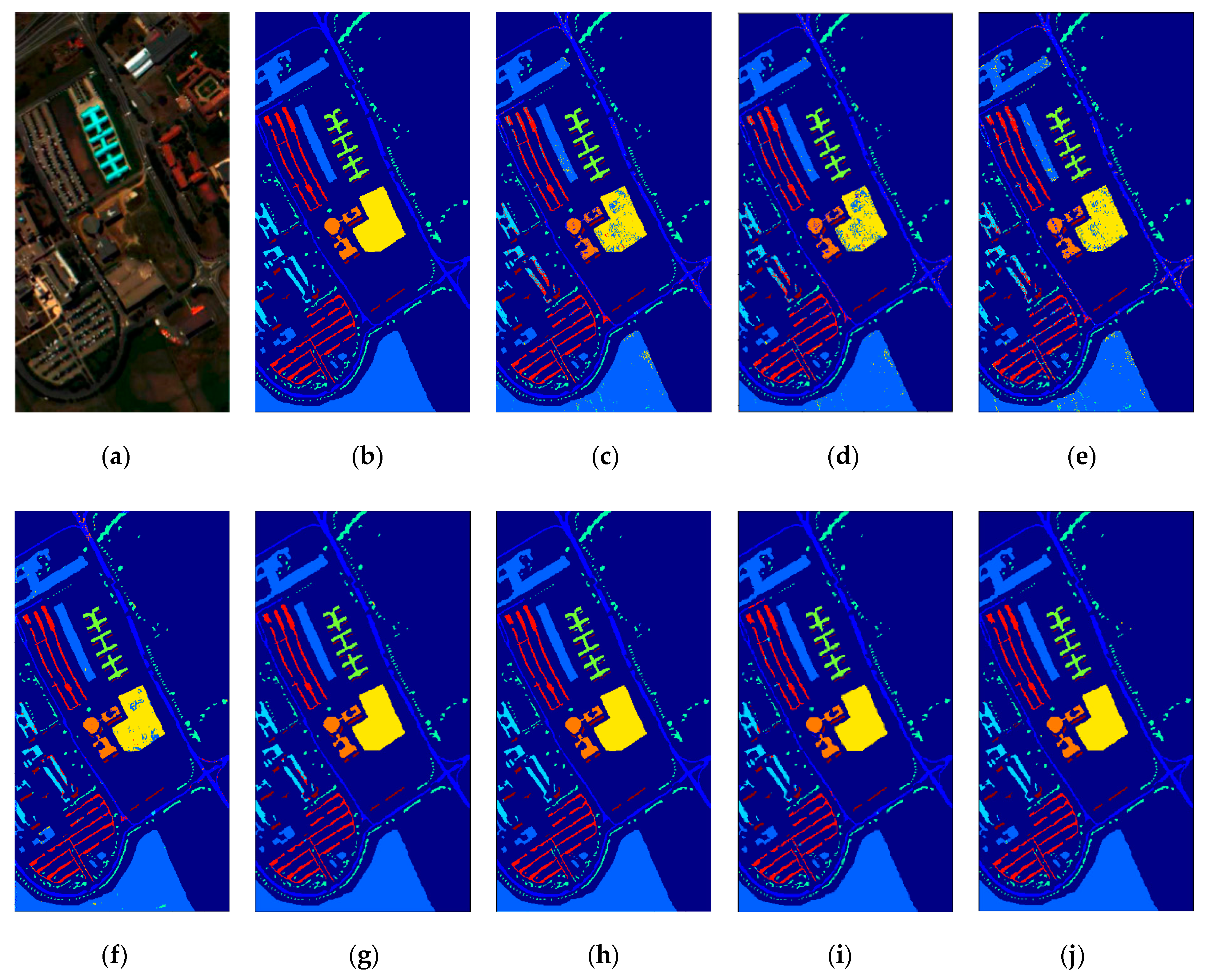
5. Discussion
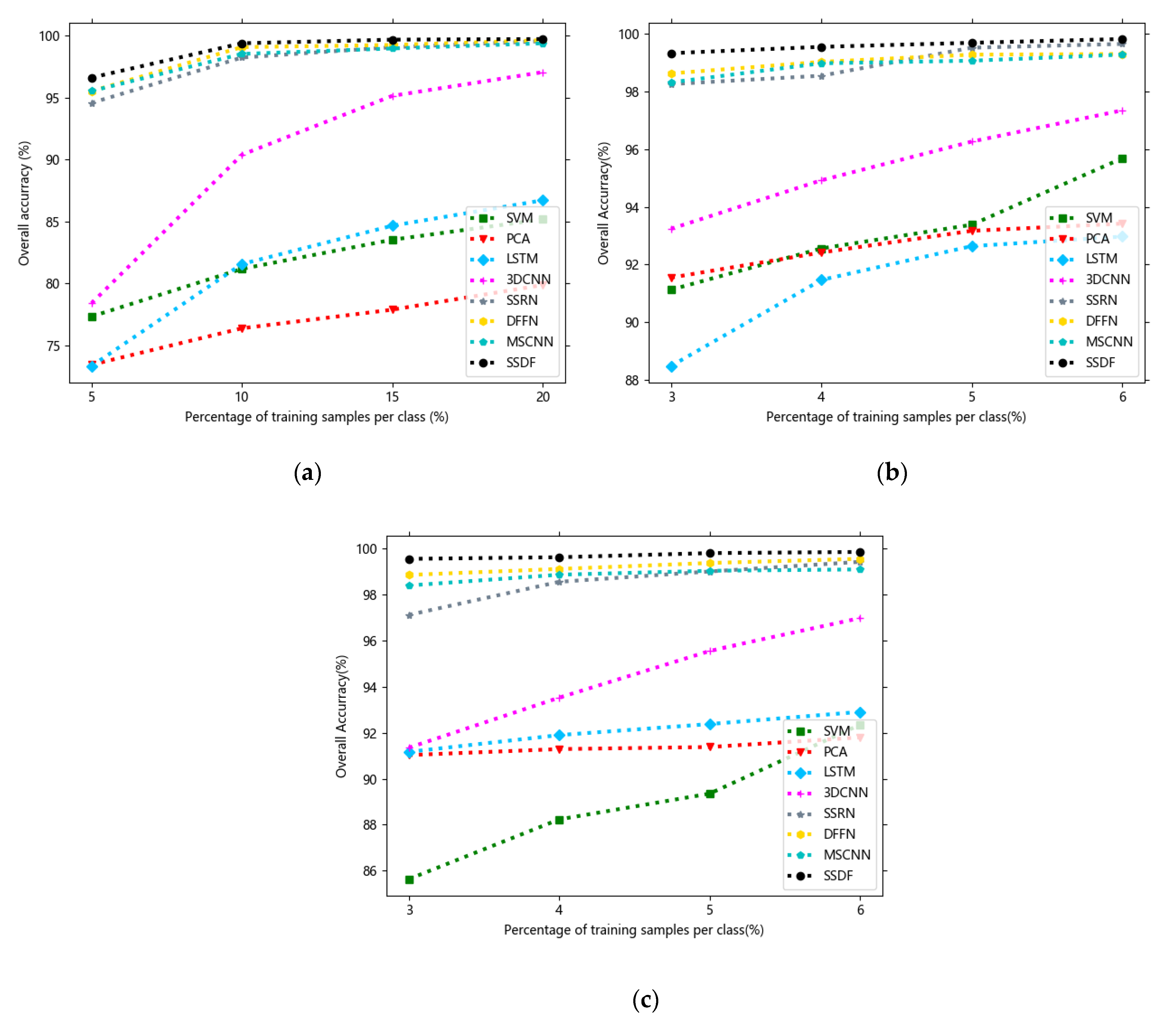
To test the generalization ability and robustness of the SSDF, we randomly selected 5%, 10%, 15%, and 20% labeled samples from the Indian Pines dataset and 3%, 4%, 5%, and 6% labeled samples from the Pavia University and Salinas scene datasets as the training data. The curves in
Figure 12 show the overall accuracies of the eight methods versus different percentages of training samples.
It can be seen from
Figure 12 that when there were fewer training data, SSDF could still achieve a much higher classification accuracy than SVM, PCA, LSTM, and 3DCNN, and it was also superior to other the state-of-the-art SSRN, DFFN and MSCNN methods.
As can be seen from all the above experimental results, the proposed SSDF achieved the best classification performance in most categories, and it also obtained the best classification results on the three evaluation indicators of OA, AA, and Kappa. The reasons for this performance improvement are as follows:
(1) The principal component features and edge features were used as the input and label of the U-shaped network, respectively, so that the network adaptively generated new fusion features that could adaptively learn the correlation and complementarity of two different features through network training and provide more sufficient information for classification.
(2) The MMFE model combined low-level features with high-level features, making the model perform better.
Compared with the simple spectral–spatial combination of SSRN, the proposed SSDF introduced the idea of merging multiple features, thus fully merging the rich feature correlation and feature dissimilarity between two different features. At the same time, compared with the MSCNN network, SSDF not only used the U-shaped network to adaptively generate advanced features but also introduced the idea of a multi-scale and multi-level classification network, and this structure could more deeply extract the original information of HSIs and further improve the classification effect.
6. Conclusions
The authors of this paper have proposed a hyperspectral image spectral–spatial classification based on deep adaptive feature fusion (SSDF). Compared with other existing network models, the U-shaped structure in SSDF is composed of special inputs and labels, i.e., the principal component features and edge features are used as the input and label of the U-shaped network, respectively. Corresponding training of inputs and labels through deep networks can effectively extract and fuse two elementary features to generate advanced features. Moreover, compared with a network model with single feature input, SSDF was found to greatly retain the complementarity and rich correlation among the features by making full use of various features. Additionally, the proposed SSDF model contains a multi-scale and multi-level network for extracting deep features that, to some extent, fuses elementary features with advanced features, thus making our method more generalizable. The experimental results showed that the performance of SSDF on the three datasets was better than other existing state-of-the-art methods, and SSDF was always able to obtain good classification results under different training conditions, which further validated that the proposed SSDF has excellent generalization ability and robustness.
Though the idea of multi-feature fusion brings higher classification accuracy, it also increases the computational complexity of a model. In the future, we will try to simplify the proposed model. Furthermore, although the fusion of edge features and principal component features has shown its effectiveness of improving classification accuracy, we will investigate the possibility of working with other types of features for fusion, which may result in better performance if better combination of features is found.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















