1. Introduction
The diverse types and sizes of objects bring a challenge to object recognition in remote sensing images (RSIs). Recently, mainly owing to its powerful feature abstraction ability, various deep learning technologies have achieved impressive success in different object recognition tasks, such as Fast R-CNN [
1], Faster R-CNN [
2], local attention based CNN [
3],
CNN [
4], SSD [
5] and YOLO [
6]. In addition to object recognition, deep learning-based methods are widely used for a wide variety of classification tasks based on remote sensing data acquired by different sensors, such as graph convolution neural networks [
7] based hyperspectral image classification [
8], and multimodal deep learning-based multisource image classification [
9]. Despite the recent advances, deep learning-based methods rely heavily on massive available labeled samples. In comparison, the machine learning-based object recognition method can obtain effective results using a small number of samples.
For the object recognition in RSIs, the general procedure consists of two steps, i.e., extracting an object slice using object detection method and recognizing the type of object contained in the slice using a trained classifier. By virtue of the object detection methods, e.g., region proposal-based methods [
10,
11,
12] and saliency-based methods [
13,
14,
15,
16], the positions of objects in RSIs can be obtained. Then, the slice of the object can be extracted for subsequent classification. It is worth noting that most existing classifiers, including deep learning methods [
1,
2,
3,
4,
5] and machine learning methods [
17,
18,
19,
20], can only deal with the input of the fixed size. Thereby, two image resizing operations are always used to extract slices containing objects with the fixed size, as shown in
Figure 1, one of which extracts the slices by the appropriate size to ensure that the object can be exactly covered, and then resizes the slice to the same size using the image interpolation method [
10,
11,
12]. Another way is to extract slices according to the maximum size of objects to cover each size of object [
13,
14,
15,
16]. After obtaining the slices with the fixed size, a proper classifier should be designed to predict the corresponding class label. Among the various machine learning based classifiers, the support vector machine (SVM) as well as its tensor extension, i.e., support tensor machine (STM), are the most worth considering due to a sound theoretical foundation and excellent generality capability. Besides the standard SVM (i.e.,
) [
17], various variants of SVM were established to improve the performance of SVM from different perspectives, including
[
18], least-square SVM [
19], etc. Since the standard SVM can be considered as a bi-category classifier and thus cannot be used to address multiclass classifications directly, the One-Versus-One (OVO) [
20], Error Correcting Output Codes (ECOC) [
21], and One-Versus-Rest (OVR) [
22] strategies were employed in order to use various binary SVMs to achieve multiclass classifications indirectly. Different from the classic SVM that relies on auxiliary strategies to achieve multiclass classification, the multiclass SVM was developed to classify multiclass objects by solving parameters of multiple classification hyperplanes simultaneously [
22]. Besides, based on the multiclass classification mechanism of [
22], some other multiclass-oriented SVM variants were developed, e.g., the graph embedded multiclass SVM [
23] and the least-squares twin multiclass SVM [
24].
Since the object slice can be represented naturally as a tensor in RSI, the tensor-based classifier, i.e., STM, was developed to exploit the structural information embedded in RSI better. According to the supervised tensor learning framework [
25] established in 2005, the
and
were extended to
and
by applying multilinear operator of tensor space, respectively. Besides, a large number of variants of STMs were established to deal with different classification tasks, such as linear support higher-order tensor machine (SHTM) [
26], multi-kernel STM [
27], higher rank support tensor machine [
28], and support tucker machine [
29]. Moreover, the support multimode tensor machine (SMTM) [
30] was built to exploit the multimode product of tensor to obtain the results of the multiclass classification for different perspectives, while its multiclass classification strategy is similar to conventional ECOC strategy.
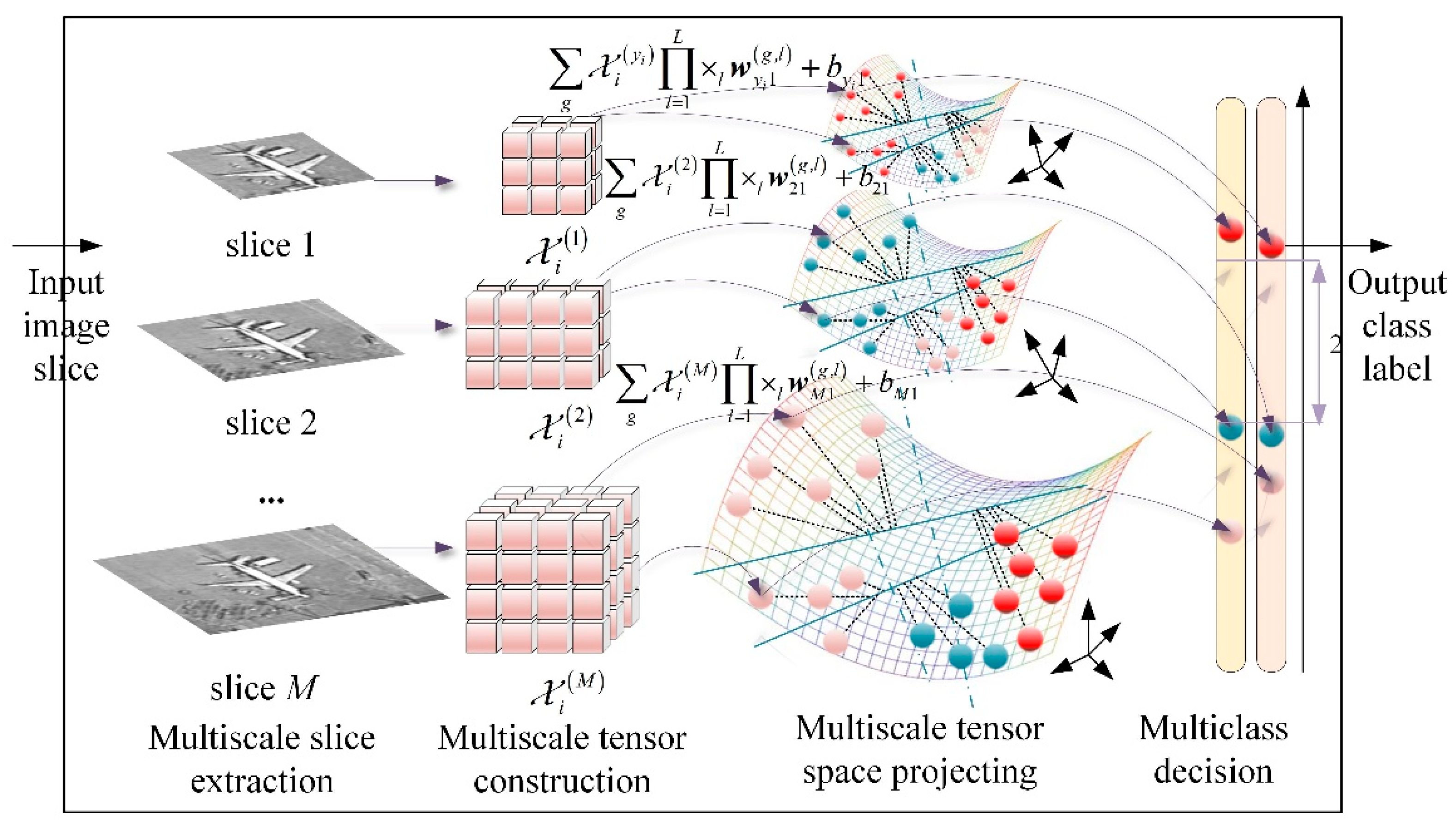
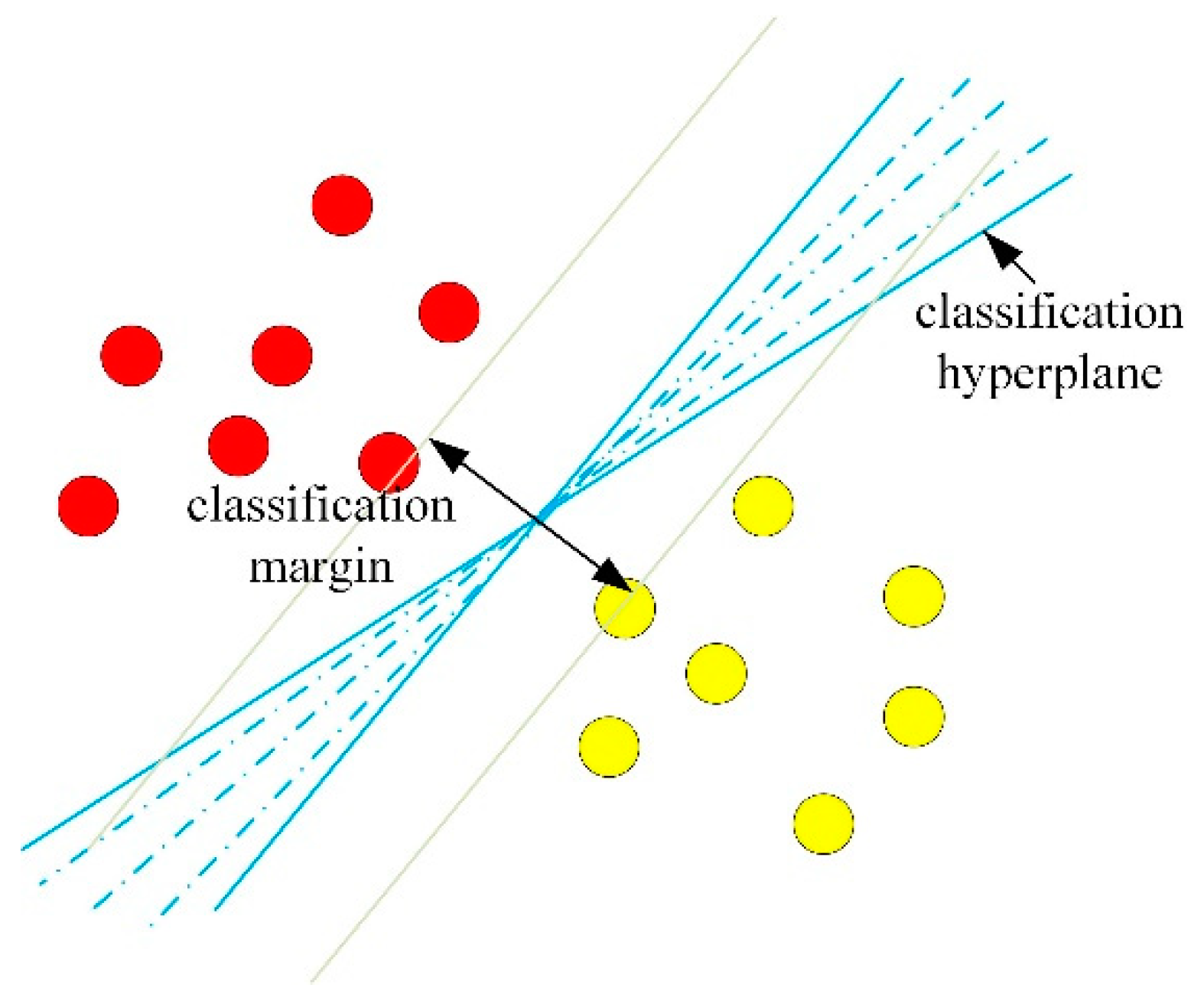
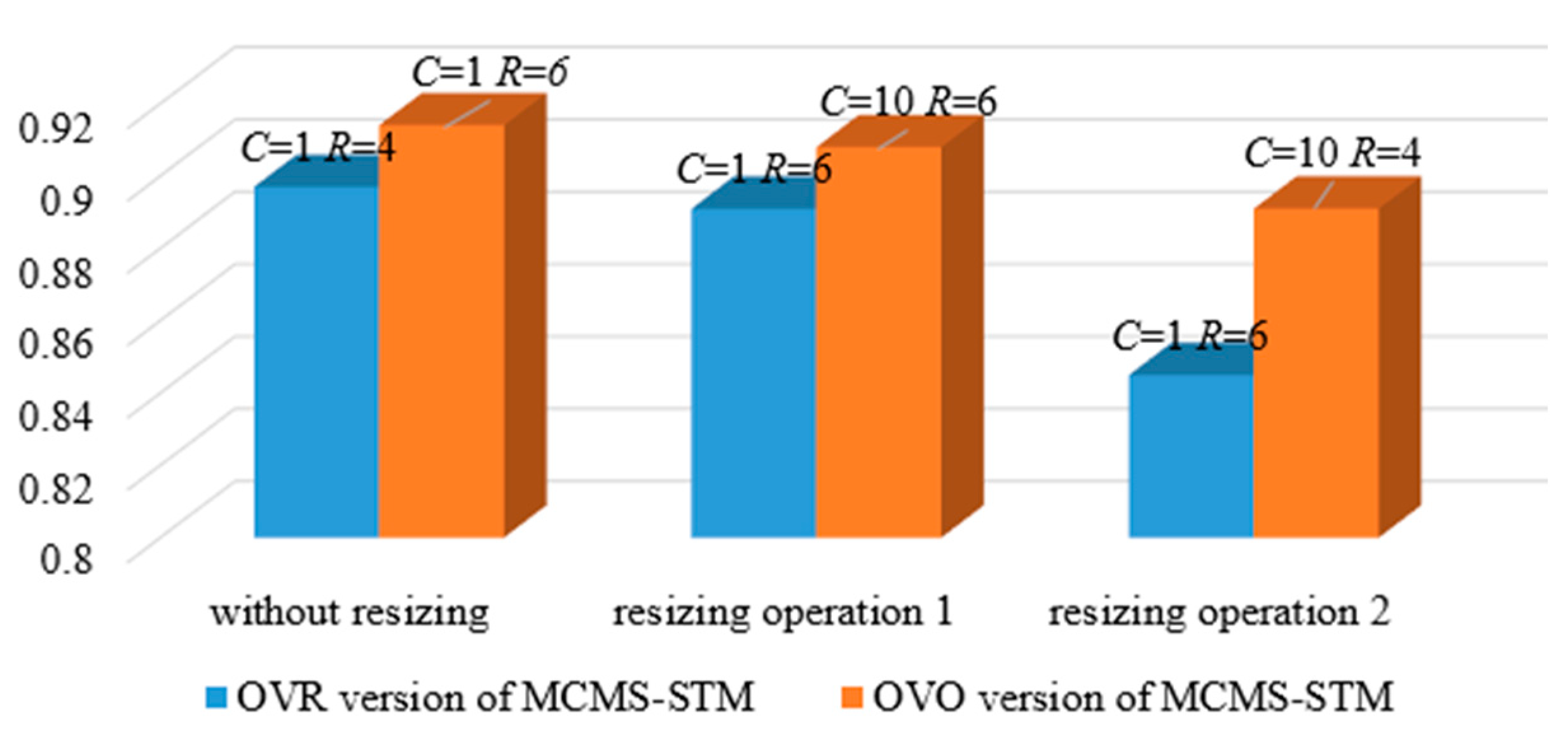
For classifying objects with multiple classes and different sizes, most existing STM methods need to exploit OVO or OVR strategies to train a series of binary classifiers to perform multiclass classification indirectly. The OVO and OVR strategies inherently assume that multiclass classifications can be solved by multiple independent bi-category classifications, ignoring the correlation between multiple classes [
23]. Although there exist a few SVM methods that can handle multiclass classification directly, e.g., multiclass SVM [
22] and its variants [
23,
24], their multiclass classification mechanism that is similar to OVR may generate excessive constraints to limit the classification hyperplane, leading to the increase of complexity for training classifier [
31]. On the other hand, since the existing STMs only accept tensors with a fixed size as input, it needs to resize the object slices of different classes in RSIs into a fixed size. Considering that objects with different classes usually present different sizes, the typical two resizing operations will bring adverse effect on object recognition, of which the first type of resizing operation will lead to the loss of objects’ scale information, and the second type of resizing operation is easy to cause the slice to contain more background interferences. The examples of two types of resizing operations are given in
Figure 1. It is seen that using the second type of resizing operation will lose the scale information of the ships and thus cannot identify ships according to their size feature, and using the first type of resizing operation will generate slices with a large size so that the slice containing ship with class 1 covers excessive background interferences. To deal with the slices to be classified present different sizes, the deep learning method, i.e., the scale free convolution neural network, is built to utilize the global average pooling to map feature maps to unify size [
32]. However, for representative machine learning methods, e.g., STM, there is no related work that can process the input slices with different sizes. In comparison to image resizing, the objects with different sizes should be contained by slices with proper sizes to reduce the impact of background interferences and maintain inherent scale information of the contained object, and these slices can be naturally represented as tensors with different dimensions, denoted as multiscale tensors in this paper, while the existing STMs can only process tensor with the same size and cannot process the slices with different sizes represented as multiscale tensors.
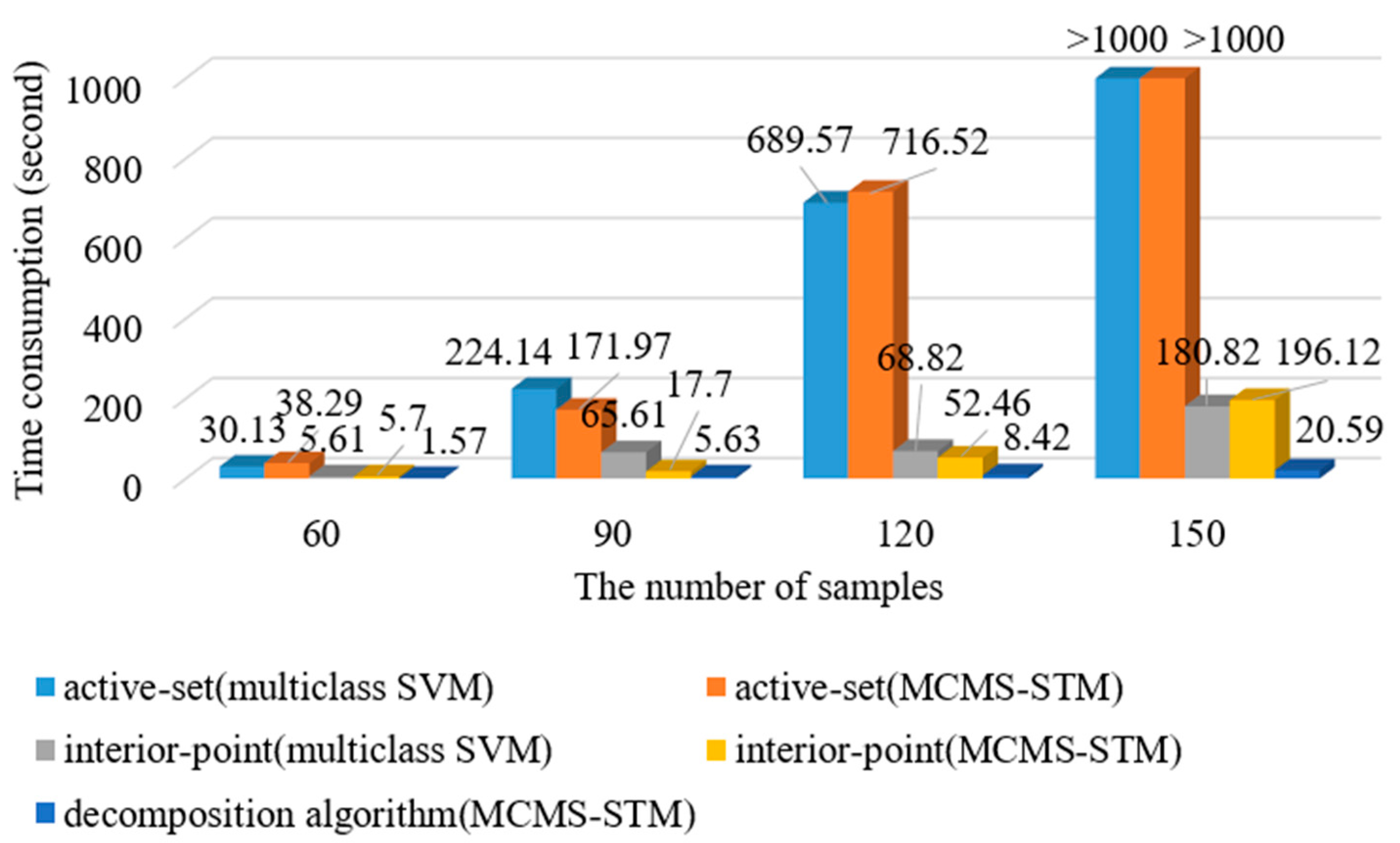
Motived by the abovementioned issues, the multiclass multiscale support tensor machine (MCMS-STM) is proposed in this paper. To deal with mutliclass classification, by integrating OVR and OVO strategies to optimization problems, a new multiclass classification mechanism is constructed to use multiple hyperplanes defined by rank-R tensors instead of a single hyperplane defined by rank-1 tensor of STM, where each hyperplane is needed to separate samples with specific classes. Furthermore, to classify objects with different sizes, according to positions of objects obtained from detection results, it is necessary to extract the objects slices with proper sizes rather than the fixed size to reduce the impact of background interferences and maintain inherent scale information of the contained object. These slices with different sizes can be naturally represented as tensors with different dimensions, denoted as multiscale tensors in this paper. Note that the existing STM methods can only process tensor with the same size and cannot process the slices with different sizes represented as multiscale tensors. To deal with input of multiscale tensors, instead of the fixed-dimensional hyperplane used in STM, the M-dimensional hyperplanes are built to separate input of multiscale tensors, and the resulting projecting value is used to predict the class label of input to achieve cross-scale object recognition. In addition, to train the OVO version of MCMS-STM efficiently, a decomposition algorithm is proposed to split the dual problem of the MCMS-STM into a series of sub-optimizations to accelerate the training.
The remainder of this paper is organized as follows.
Section 2 consists of some preliminaries, such as the basic definitions and notions, the classical SVM and STM methods. In
Section 3, the OVR version and OVO version of MCMS-STM and the corresponding solving methods are presented. Then, the decomposition algorithm is constructed to accelerate the training of the OVO version of MCMS-STM, and the relationship between the multiclass classification mechanism used in MCMS-STM and the existing methods is discussed. In
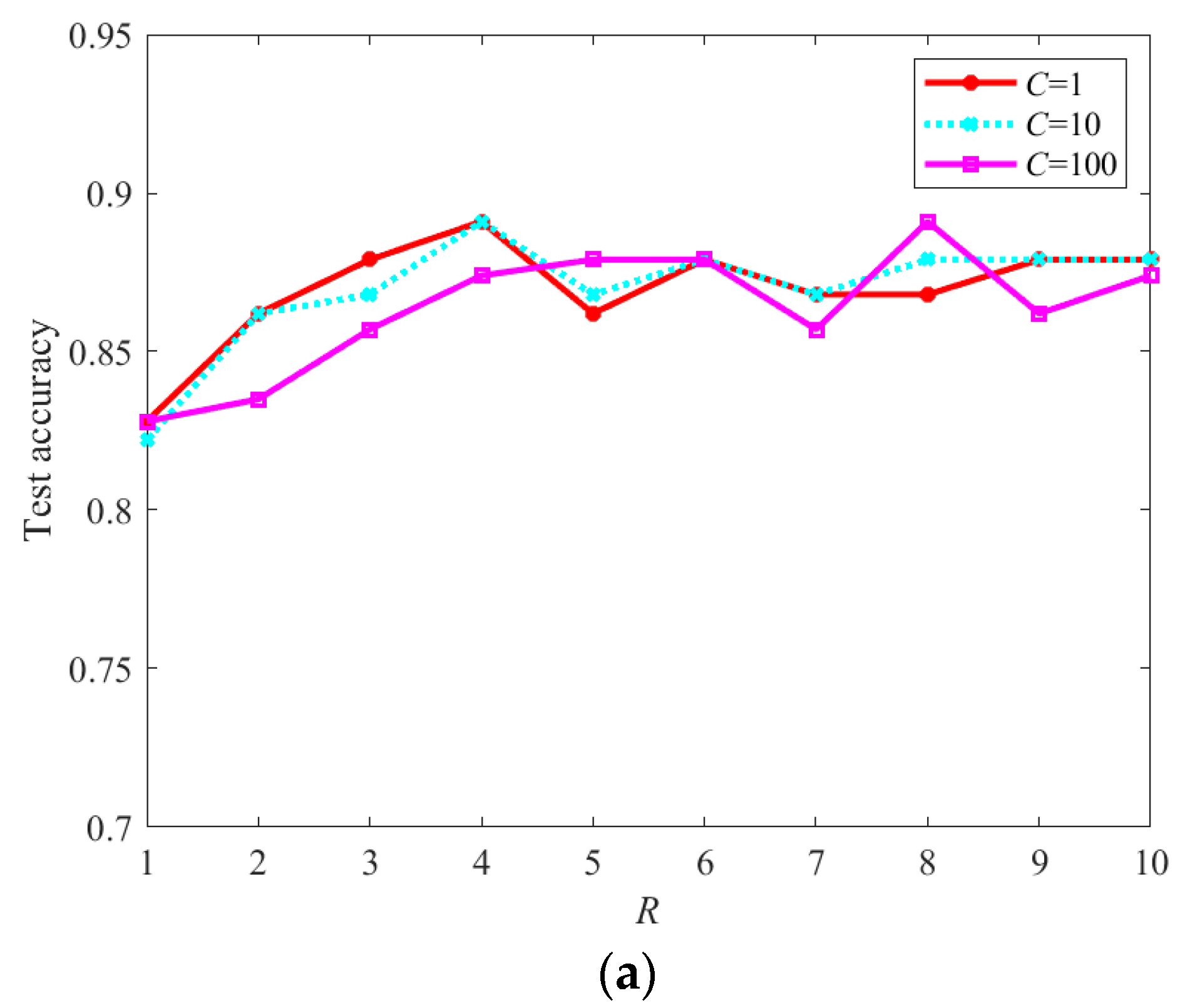
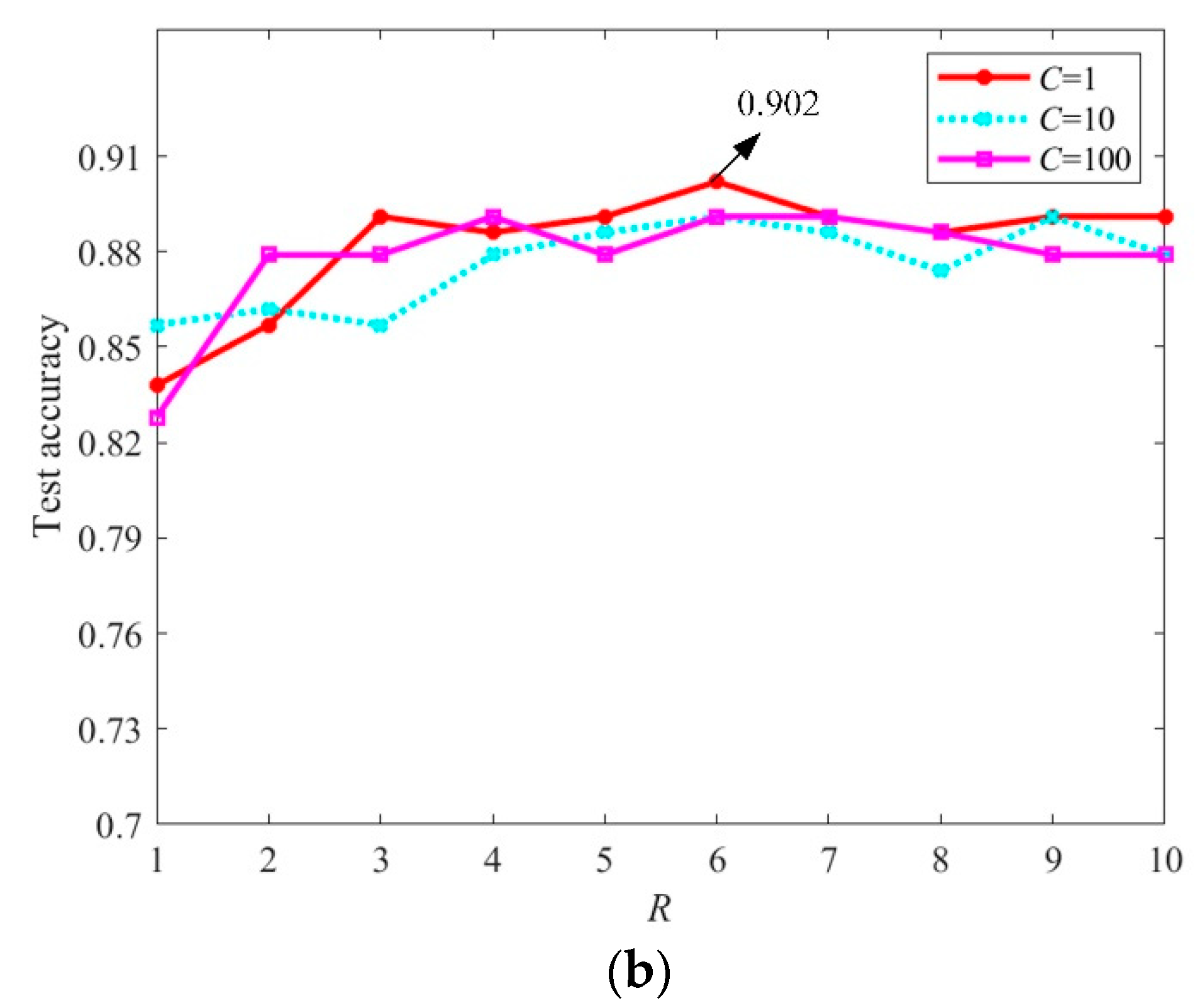
Section 4, the experiments are conducted on publicly RSIs to analyze the parameter setting and the impact of image resizing operation and evaluate the performance of the MCMS-STM. Our conclusion is given in
Section 5.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}