1. Introduction
With the development of computer vision, pattern recognition, and deep learning, plant and animal species recognition technologies [
1,
2,
3,
4,
5,
6] based on aerial images also have been constantly improving, and are being applied in various fields. In the tasks of understanding the geographical distribution of plant and animal species and protecting species diversity, it is of positive significance to identify species and their surrounding environmental characteristics through aerial images.
In contrast to traditional image classification [
7,
8,
9,
10,
11,
12], the discrepancies between aerial images of different plant and animal species categories are small, which is a typical Fine-Grained Visual Categorization (FGVC) task; also, the proportion of plant and animal pixels is relatively small in the global image due to the sparsity of aerial images. Therefore, in the plant and animal species recognition task based on aerial images, even though the aerial images have both RGB and near-infrared (NIR) modal data, it is almost difficult to distinguish species classes if we rely on image information alone. Currently, the optimization of species recognition by introducing additional information has become a hot research topic. Currently, common additional information includes the geographic and temporal information of the image capturing [
13,
14,
15,
16,
17], and studies have shown that geographic and temporal information can improve the accuracy of FGVC in BirdSnap [
18], PlantCLEF [
19], FungiCLEF [
20], YFCC100M [
21], iNaturalist [
22,
23,
24], and GeoLifeCLEF [
25] datasets.
However, most of the current research approaches extract potential embedding of images by Convolutional Neural Networks (CNN) and finally classify the concatenation of location, date, and image embedding for species identification [
15,
26,
27,
28]. Alternatively, feature summation [
13], multiplication [
14,
29], and dynamic projecting [
17] are used to fuse image embedding and location–date features. Although these methods have achieved excellent results, most of these methods only consider the fusion of image and location–date features in a single dimension. While dynamically projecting approaches construct high-dimensional interactions between multimodal representations, mapping similar image features to different locations in the feature space suggests accurate classification accuracy. However, this is also a fusion method after feature extraction from different modal data; also, these methods only consider the enhancement of image features by location–date multimodal embedding of images without considering the influence of the surrounding environment features, which is, of course, related to the common fine-grained image classification dataset.
To further exploit the potential impact of additional information, we propose to incorporate it into the process of extracting image latent embedding while introducing additional information into the fusion of the extracted multimodal features. Due to the similarity in image appearance, the distinguishability of the images’ latent features extracted by the network model is insufficient if the image classes are the same. Especially, when the locations of the aerial images are close to each other, it is still difficult for the existing multimodal fusion methods to distinguish species classes. However, when extracting image embedding by the CNN model, it is again difficult for us to interact with the additional information during the image feature-extraction process. With the widespread use of Visual Transformer (ViT) [
30] in the image field [
31,
32,
33,
34,
35,
36,
37,
38,
39], its unique learning approach makes it possible to introduce additional information into the extraction process of image potential embedding. In this paper, we propose a Dynamic Vision Transformer (DViT) architecture to dynamically enhance the latent representation of image embedding by additional environmental information of the location.
Specifically, in the potential embedding extraction of aerial images, the multimodal aerial images of the RGB and NIR are input into the transformer encoder model with the Learnable Mask Token (LMT), respectively. The mask token has learned the attention weight. Then, we mask the low-weight patches to extract the latent representations of the local regions with high attention weights. At the same time, the location environment embedding by multi-layer perceptron (MLP) is added to the process of extracting the latent representation and fused with the token with high attention weights to improve the distinguishability of the aerial images’ latent representation by the dynamic attention fusion (DAF) model. Finally, the enhanced latent representations by additional location environment embedding of RGB and NIR images are fused for multimodal species recognition. We evaluated DViT on the GeoLifeCLEF 2021 and 2022 datasets, achieving state-of-the-art performance.
In summary, this paper attempts to propose a DViT model combining multimodal aerial images and location environment information to reduce the effect of small image discrepancies for multimodal species recognition. The main contributions of this paper are summarized as follows:
This paper analyzed the impact of additional location environment information for fine-grained image classification on multimodal species recognition.
This paper is the first study that combines a visual transformer with the LMT and DAF and proposes a DViT architecture, which utilizes the multimodal aerial remote sensing image and location environment information to reduce the effect of small image discrepancies.
Our approach consistently achieved state-of-the-art (SOTA) results on multiple datasets compared to existing published works, especially with top-30 error rates of 0.7297 and 0.6567 for the GeoLifeCLEF 2021 and 2022 private test sets, respectively.
The remainder of this paper is organized as follows:
Section 2 provides a brief review of the related research on species recognition;
Section 3 provides a complete introduction to the proposed algorithm;
Section 4 shows the datasets, details, and results of the experiment; and, finally,
Section 5 presents the conclusions of this research method.
3. Methodology
In this section, we introduce a multimodal fusion framework for species recognition by aerial images and location environment information. The framework contains an RGB image path, an NIR image path, and a location environment path, taking as input the aerial images and the multimodal location environment information, respectively. First, the aerial image embedding is extracted by vision transformers with the LMT module, while the multimodal location environment embedding is derived by the MLP backbone network. Then the geo-location environment information is added to the process of extracting the latent representation. Finally, the DAF module adaptively performs projection location environmental embedding of the latent representations of aerial images to produce final species predictions.
3.1. Framework
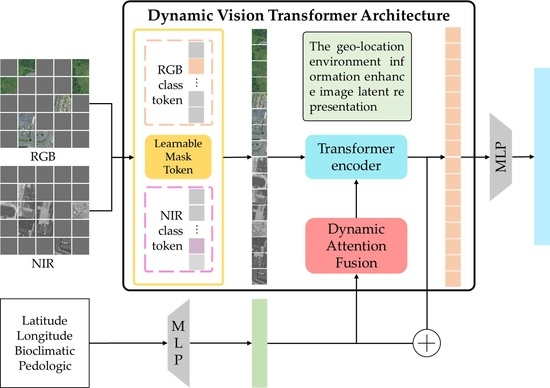
The complete network structure we designed is shown in
Figure 1. The aerial images used the Dynamic Transformer Encoder model to extract visual embedding, and the location environment embedding is extracted by the MLP block. Then, different from previous embedding fusion works, the DAF is used to enhance the ability of the image patch embedding. We dynamically project multimodal location environment embedding into the image tokens to enhance the image representation.
Following ViT, given the input aerial images, we first divide these aerial images into regular non-overlapping patches. However, the sparsity of the aerial image information creates small discrepancies between different categories of plant and animal species. If the patches are directly input to the transformer encoder, it will bring information redundancy. Therefore, the Masked Autoencoders (MAE) [
35] model uses random sampling with a high masking ratio to remove a high percentage of patches to eliminate redundancy. Although, random sampling can construct efficient feature representations with highly sparse inputs compared to block-wise sampling and grid-wise sampling. However, the uncertainty of random sampling may remove some patches with high representation power. Therefore, we use the LMT to sample a subset of patches for RGB and NIR aerial images, respectively. We remove patches with low impact on species recognition by the LMT. We simply refer to this as “learnable sampling”. A detailed introduction to the LMT model can be found in
Section 3.2.
Specifically, given the input aerial images, we can obtain this embedding without a mask token through the transformer encoder with the LMT model, following each modal image path. Simultaneously, the multimodal location environment path accepts latitude, longitude, bioclimatic, and pedologic data as input. This environment information is added to the process of extracting the latent embedding and fused with the token with high attention weights to improve the distinguishability of the latent embedding of aerial images. Then, the multimodal features are obtained through the MLP backbone network. After the multimodal images and location environment features are obtained, they are fused via the DAF model. In the DAF network, we fused the multimodal localization environment features with aerial image tokens through the multiplication method. The multimodal fusion latent representation is obtained via a map of the environment features in each image token to enhance the aerial image representations in the MLP backbone network. We also concatenated the class token of the multimodal aerial image to further enhance the multimodal fusion latent representation for species recognition.
3.2. Learnable Mask Token
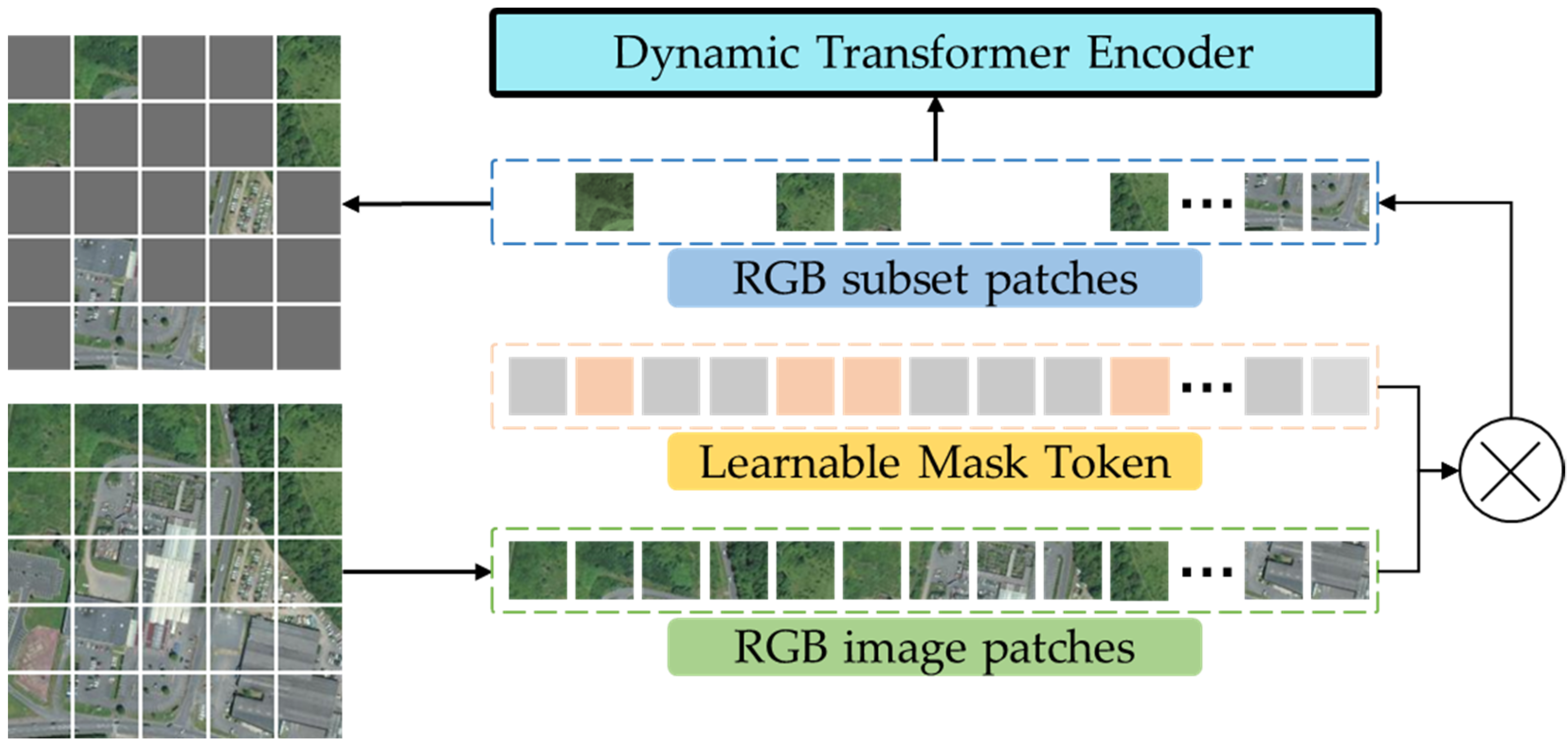
The sparsity of aerial image information creates small discrepancies between different categories of species; thus, how to efficiently extract the distinguishing local area embedding for species recognition is the focus of research. Therefore, this paper proposes the LMT (LMT) to sample a subset of patches on aerial images in a learnable way and extract a latent representation of local regions with distinguishability. The patch tokens of the RGB and NIR multimodal image are learned by LMT in the visual transformer model. Then the patch tokens with high weights on RGB and NIR modalities are input into the transformer encoder to extract the latent representation of the multimodal images.
In this section, we first describe the elementary implementation of the transformer encoder model with the LMT. Specifically, given the input aerial images, we divided them into regular non-overlapping patches,
. Then, these patches were input into LMT to sample a subset of patches to remove patches with low representability. The model architecture of LMP is shown in
Figure 2.
The LMP model is a fully connected layer in which the input is a one-hot encoder vector of the same length as the image patches. The output of LMP is sorted to remove those corresponding images with low weights, which is specifically expressed as
where
is the patches without masks,
is the parameter of the LMT model, and
is the mask token projection of binarization corresponding to each image patch. These image patches with high weights were mapped to a high-dimensional embedding and fused to the positional embedding.
For multimodal embedding of RGB and NIR images, we added the LMT as a class token to generate a new embedding. At the same time, we fused the multimodal location environment embedding with multimodal image embedding to improve the distinguishing ability. The new embedding is as follows:
where
is the length of patches through the LMT,
is the top 25% sorted by the learned mask token,
is the multimodal image patches embedding by convolution mapped, and
is the positional embedding.
In a different MAE model, we do not randomly remove image patches but remove low-weight image patches through the LMT, and after each backpropagation, we arrange the learned mask tokens in the order of deletion token. Finally, the low-weight mask token is selected again for deletion. This reciprocates until the optimal high-weight region is selected for species identification.
Based on this, we use the LMT to sample a subset of patches for RGB and NIR images, respectively. We replaced random sampling with the LMT model; we simply refer to this as “learnable sampling”. The learnable way of the mask token largely eliminates redundancy by removing a high percentage of patches.
3.3. Dynamic Attention Fusion Model
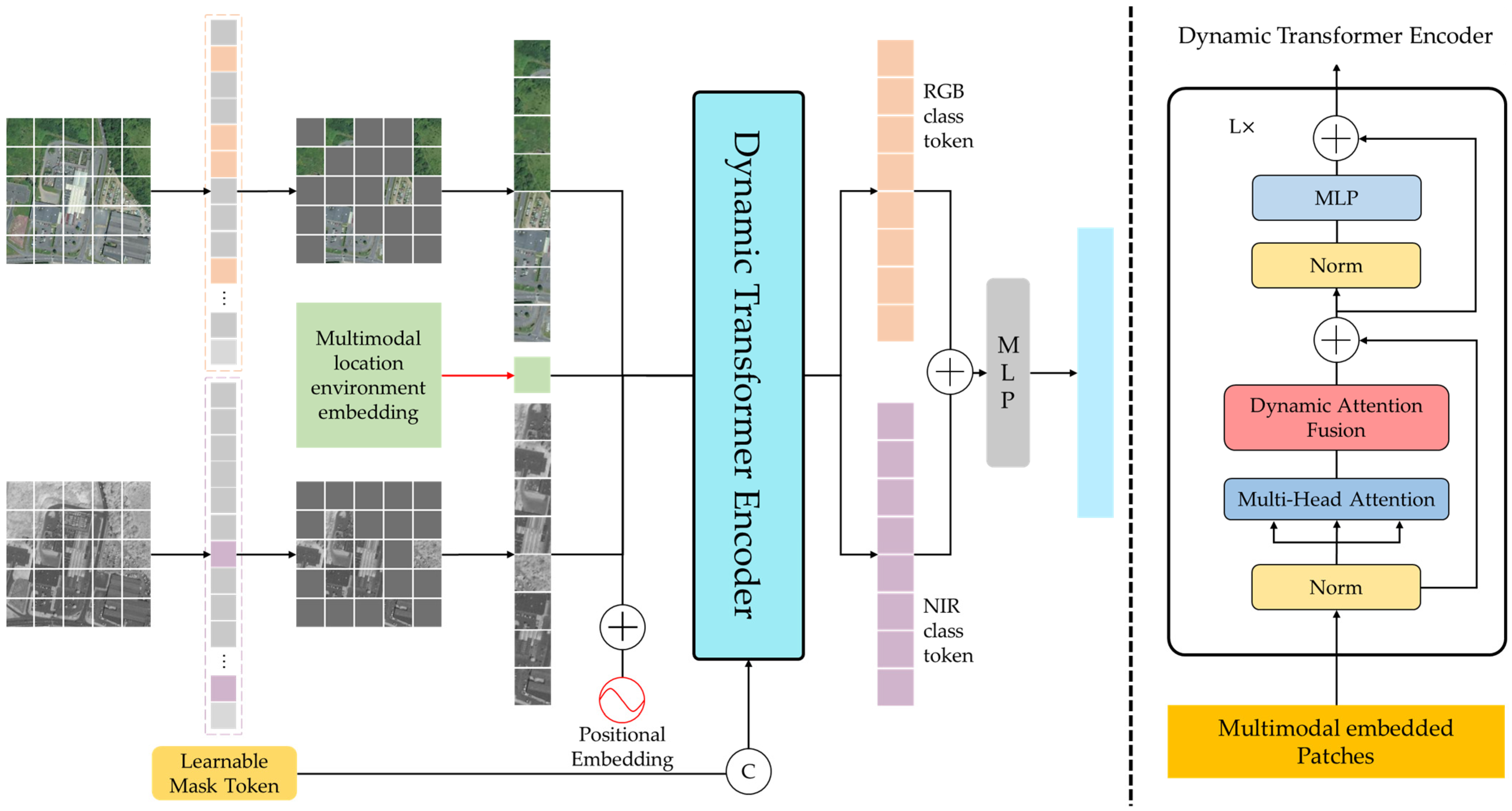
The added class token is used to learn the attention weight of each patch before inputting multimodal image paths into the transformer encoder model. The impact of the high-dimensional features of each patch on species recognition is attended to through the attention weights, in which we represent the positional relationship of each patch with the LMT. The transformer encoder module contains L layers of MSA, DAF, and MLP blocks.
In this section, we first describe the elementary implementation of our proposed dynamic attention fusion (DAF-A) model and its improved variant DAF-B. Inspired by dynamic filters [
17,
78,
79,
80], we propose a DAF model that introduces multimodal location environmental embedding,
, into the visual transformer encoder adaptively to enhance the distinguishability of aerial image representations. In
Figure 3 on the left, we show a single unit of DAF-A, the most concise implementation of DAF-A. The classification process is as follows:
where
,
, and
are the query, key, and value of the
model,
is the patch of multimodal location environment,
reformulates a 1-d feature into a 2-d matrix,
denotes the fully connected layer,
is the class token concatenation of the RGB and NIR image, and
is the prediction result of the model.
Finally,
are replaced by the corresponding positions in the LMT, and the patches with high weights are extracted again for the next iteration. Aerial image embedding and multimodal location environment embedding have the potential to complement each other. Therefore, we concatenated image embedding and multimodal location environment embedding in DAF-B, which is an extended version of DAF-A, and then dynamically mapped them to the image embedding.
In the DViT model training process, we used focal loss to reduce the impact of category imbalance. The loss function is defined as follows:
where
and
are hyperparameters,
is the balance factor, and γ is to adjust the rate at which the weight of simple samples is reduced. To verify the ability of multimodal location environment information to enhance the distinguishability of image features, we verified the robustness of the model using RGB, NIR, and RGB+NIR, and the experimental results are shown in table in
Section 4.3.
4. Experiments
This section, we will introduce the detailed analysis of the experiment, including datasets, performance metrics, experimental details results, and ablation experiment analysis. In addition, the ablation experimental analysis is conducted to better illustrate the effectiveness of the DViT architecture.
4.1. Dataset
We conducted experiments on a species dataset with additional location environment information (GeoLifeCLEF 2021, 2022). GeoLifeCLEF 2021 and 2022 are part of the LifeCLEF 2021 and 2022 evaluation campaigns, respectively, as well as part of the Eighth Workshop on Fine-Grained Visual Categorization (FGVC8) on CVPR 2021 and FGVC9 on CVPR 2022.
The observation data in GeoLifeCLEF 2021 and 2022 are given latitude and longitude coordinates, the remote sensing imagery in RGB and NIR, and the cover and altitude data of the surrounding environment within 256 m × 256 m, which is 1 m per pixel in these data. In addition, bioclimatic and pedologic data corresponding to each observational data sample is also given, as extracted, preprocessed environmental variable features. The observation data of the location [43.779, 3.812] in GeoLifeCLEF 2021 and [32.957, −96.470] in GeoLifeCLEF 2022 are shown in
Figure 4 and
Figure 5.
Due to the sparseness of the land cover and altitude data, only RGB and NIR images in the dataset were used in the training process of the DViT model. Additional information selected regarded species location and preprocessed environmental embedding. The sample statistics of species number, train, validation, and test of GeoLifeCLEF 2021 and 2022 are shown in
Table 2.
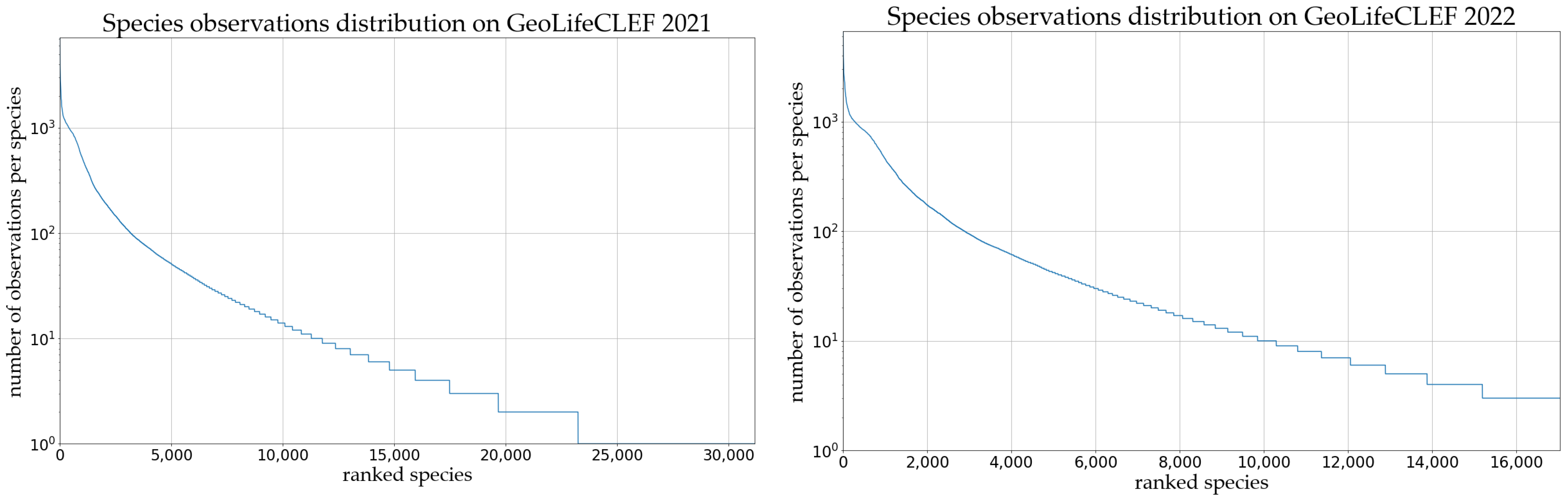
Due to the category imbalance of the species recognition dataset, the visualization of species observation distribution in the two datasets is shown in
Figure 6. It can be seen that the long-tailed distributions problem of the GeoLifeCLEF 2021 dataset is more obvious. This dataset includes 31,179 observed species and only species category labels are given. The 17,037 observed species in the GeoLifeCLEF 2022 removed species categories with a small sample from GeoLifeCLEF 2021; this includes 9080 plants and 7957 animals. The species, genus, family, and kingdom category labels are also given for each observed data sample.
4.2. Implementation Details and Performance Metrics
We iteratively update the parameters of the RGB and NIR paths of DViT on the MAE pre-training model, to accelerate the model convergence during the training process. During the training process, we applied random cropping, random rotation, random vertical and horizontal flips, and 5–10% brightness and contrast adjustment to perform data augmentation on the image dataset. We applied center cropping to the image as a data-augmentation operation during the inference. Meanwhile, we trained with the Stochastic Gradient Descent (SGD) algorithm with momentum for DViT model optimization with an effective batch size of 512 on the 800 epochs. The learning rate was set to 0.0024 and the learning rate decayed to 0.95. The proposed model was trained and predicted using PyTorch on the GeForce RTX A6000 platform.
In the experiment, we used the top-30 error rate in the two public multimodal species recognition datasets (GeoLifeCLEF 2021 and 2022) to validate the performance of the DViT model. The top-30 error rate is expressed as follows:
where
is the ground-truth label of observation
. For each observation
, it provides 30 candidate labels
to compute the top-30 error rate.
4.3. Ablation Experiment Analysis
Mask Sampling Strategies: We first examined the impact of mask sampling strategies on DViT architecture performance. The experimental results are shown in
Table 3. Specifically, we compared the impact of four mask sampling strategies: learnable sampling (our default), random sampling, lock-wise sampling, and grid-wise sampling. Random sampling is a large-scale random removal of small image blocks, lock-wise sampling removes large random blocks, and grid-wise sampling keeps one of every four patches.
The experiments are conducted based on the ViT backbone of the GeoLifeCLEF 2022 dataset. The experimental results show that learnable sampling reduces the error rate of recognition compared to random sampling strategies. We believe that the strategies of learnable sampling can better extract the local region of interest representation with high differentiation. In the MAE model, the random sampling strategies have been shown to achieve better results than lock-wise sampling and grid-wise sampling. In this paper, we also show that random sampling strategies can achieve good results in multimodal species identification.
Comparison of Backbone: We trained different ViT backbones based on learnable mask strategies of the GeoLifeCLEF 2022 dataset, achieving a very competitive top-30 error rate of 0.6594. Furthermore, comparing ViT-Huge to ViT-Base and ViT Large, it was seen that the larger-scale backbone model achieves more competitive results. The experimental results are shown in
Table 4.
Comparison of Structures: We compared DAF-A and DAF-B (
Figure 3) based on the ViT backbone and learnable sampling strategies with GeoLifeCLEF 2022. The results are shown in
Table 5. The experimental results show that DAF-B can obtain better experimental results by fusing the embedding of aerial images and multimodal location environment embedding.
4.4. Comparisons with State-of-the-Arts
Our model was compared with five multimodal fusion schemes. We performed the implementation under a unified backbone for a fair comparison. In the ConcatNet [
15] model, the species class was predicted by concatenating the image latent feature representation extracted from the VIT model of the backbone network with the features of multimodal location information. In PriorsNet [
14], GeoNet [
13], EnsembleNet [
29], and Dynamic MLP [
17], we similarly combined the original method embedding in the original method with the same replacement to ensure the fairness of the experiments. The experimental results—the top-30 error rates for classification of DViT and other methods using the GeoLifeCLEF dataset for species identification—are shown in
Table 6.
For our proposed DViT model, the backbone structure adopts the ViT [
30] model and the LMT for aerial images to sample a subset of patches, and fused the patches’ subsets of RGB, NIR, and multimodal location environmental embedding into the transformer encode model to obtain the final classification results.
In the GeoLifeCLEF 2021 dataset, the top-30 recognition error rates of the proposed DViT on the private test set are lower than those of the baseline method using only aerial images (ResNet, DenseNet, and VIT), by 0.0371, 0.0241, and 0.0319, respectively. Compared with the Dynamic MLP, which is the optimal fusion model of aerial images and multimodal location environment embedding, it is lower by 0.0074, 0.0099, and 0.0057, respectively. The DViT proposed also achieves SOTA recognition performance in the GeoLifeCLEF 2022 dataset.
Because the test results of GeoLifeCLEF 2021 and 2022 were submitted to Kaggle to obtain the top-30 error rate, the accuracy, precision, and recall metrics could not be obtained. Therefore, we further evaluated the DViT model with the RGB and NIR fusion (ResNet 50, DenseNet 161, ViT-Huge) and multimodal fusion Dynamic MLP in the validation set. The results are shown in
Table 7 and
Table 8.
4.5. Limitation and Discussion
The proposed DViT model improves the discrimination of image features by dynamically fusing aerial image embedding and geo-location environment information, achieving state-of-the-art performance in plant and animal species recognition. However, this method still has three limitations. First, for each aerial image and set of environmental information of each observed species, there may be other plants and animals. In this situation, the local image region of observed species may be removed through LMT to reduce recognition performance. Second, the influence of the positional relationship between MSA and DAF in the DViT model was not considered, which is also one of the main issues to be considered in future studies. Finally, the training of DViT starts with the pre-trained model of MAE, which may affect feature extraction from aerial images. In future research, unsupervised learning can be introduced for feature extraction of aerial images to increase the robustness of image embedding to improve the performance of species recognition.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}