In the deep learning literature, GAN has recently performed well in describing the prior distribution of imaging targets. The network is capable of generating very clear and realistic images, and it is even difficult for the human eye to judge whether the images are real or fake. At the same time, VAE is also a very effective generative model, which can extract latent features of descriptive data through an effective inference network. This paper integrates these two models well, which makes the model proposed in this paper have its own advantages. The characteristics of the two are introduced separately below.
3.1. Feature Inference Network
As a form of deep generative models, a variable autoencoder is a generative network structure based on variable Bayesian inference, proposed by Kingma et al. in 2014. Unlike traditional autoencoders that describe the bit space numerically, it describes the observations of the bit space in a probabilistic way, showing great application value in data generation.
A variational autoencoder essentially learns the hidden relationship between the input variable x and the hidden variable z. Given x, the conditional probability distribution of the hidden variable is . After learning this distribution, different samples can be generated by sampling .
From a probabilistic point of view, we assume that any dataset is sampled from some distribution . Z is a hidden variable representing some internal feature. For example, pictures x and z of a handwriting dataset can represent some settings, such as bootstrap size, writing style, bold, italics, etc., which fit some prior distribution . Given a particular hidden variable z, we can sample a series of generated samples from the learned distribution that have a commonality denoted by z.
When the distribution
is known, we want to learn to generate a probabilistic model
; here, we can use maximum likelihood estimation: a good model should have a good chance of producing the observed samples
. If the generative model
is parameterized with
, for example, we learn
through a neural network that is a decoder, then
is the weights
w,
b, etc., of this decoder, so the optimization goal of the neural network is:
Since
z is a continuous variable, the above integral cannot be converted to a discrete form, making it difficult to directly optimize the above formula. Using the idea of variational inference, use the distribution
to approximate
, that is, the distance between the two needs to be optimized:
KL divergence
is a measure of the gap between distributions
q and
p, defined as:
Strictly speaking, the distance is generally symmetric, while the KL divergence is not, and the KL divergence is expanded as:
For the optimization objective function
, our goal is to maximize the likelihood probability max
or max
, so we can use max l(
) to achieve this. As shown in the following formula:
Therefore, the encoder network parameterizes the function, and the decoder network parameterizes the function, it can be obtained by computing the KL divergence between the decoder output distribution ) and the prior distribution and by the loss function of the likelihood probability between the decoder targets to optimize .
3.2. Deep Generative Adversarial Network
With the development of deep learning, people hope to find richer hierarchical models to better describe the probability distribution of various complex data encountered in real life. By far the most successful applications of deep learning are models that map high-dimensional informative sensor inputs to class labels. These remarkable successes are mainly based on backpropagation and dropout algorithms, which use piecewise linear functions and can generate particularly efficient gradients. Because deep generative models will suffer from some problems, such as many complex high-dimensional probability calculations, it is difficult to approximate in maximum likelihood estimation and similar learning strategies, and it is even more difficult to use piecewise linear functions in the generation process to generate efficient gradient.
In the proposed generative adversarial network framework, the generative model competes in the training phase with an adversary, which is a discriminative model, which determines whether a sample comes from the generative model’s distribution or the learned data distribution. The generative model can be viewed as a counterfeit-like team trying to produce counterfeit money and deceive the police by using it; the discriminative model is like the police, trying to detect counterfeit money. In the process of confrontation, both sides try to improve their methods by learning until they can not tell the difference between the real and the fake.
For the generator to learn to describe the distribution
of the data
x, define a prior distribution
of the input noise variable, and then denote a mapping from
z to the data space as
. Moreover, define another multilayer perceptron
capable of outputting a single scalar.
represents the probability that
x comes from the data rather than the generator
by training
to maximize the probability of assigning the correct label to the generated samples from
and samples from the real data. At the same time,
is trained to minimize
, that is, by simultaneously training
and
to play the following two-player max-min game
:
Essentially, under nonparametric conditions, the training criterion enables the generative distribution to accurately describe the data distribution when is sufficiently discriminative. In practical applications, iterative numerical methods are generally used to implement the game, and the optimization process usually takes l steps optimization and one step optimization. Alternating between the two results in that as long as changes slowly enough, can stay near its optimal solution.
3.3. PFDI-Net: Architecture and Training
For VAE, when it is simply used to generate images, the generated images are more regular but blurred; for GAN, its training process is not so stable, and it is prone to problems such as mode collapse or gradient disappearance. In order to solve the respective problems of VAE and GAN, this paper adopts the combined use of the two models to give full play to the advantages of the two models to compensate for their respective shortcomings.
From the perspective of VAE, the target generated by VAE is relatively vague, and a large part of the reason is that it does not know how to better define the loss between the generated target and the real target. The traditional VAE will define the loss by comparing the pixel difference between the generated target and the real target, and then take the mean value, which results in the generated target being blurred. To solve this problem, we can add a discriminator to the VAE. At this time, when the decoder of the VAE generates the target, not only should the loss between the generated target and the original target be small but also the generated target should be deceived by the discrimination. The addition of the discriminator forces the decoder of the VAE to generate clear targets.
From a GAN perspective, the generator of a traditional GAN receives guidance from the discriminator when generating targets, thereby gradually generating realistic targets as training progresses. In a simple GAN structure, however, since the capabilities of the generator and discriminator are difficult to balance, it is easy to cause instability in training. One of the important reasons is that the generator of GAN has never seen a real target and tries to generate a target directly from a large amount of data. At this time, the ability of the generator has difficultly competing with the discriminator to achieve confrontation. In this case, we usually need to adjust the parameters of the generator multiple times or train for a long time to make the model converge. The function of adding a VAE encoder to GAN is to add a loss to the generator, that is, the loss between the generated target and the real target, which is equivalent to telling the generator what the real target looks like, and the generator has an additional loss as a guide; it will be more stable when training.
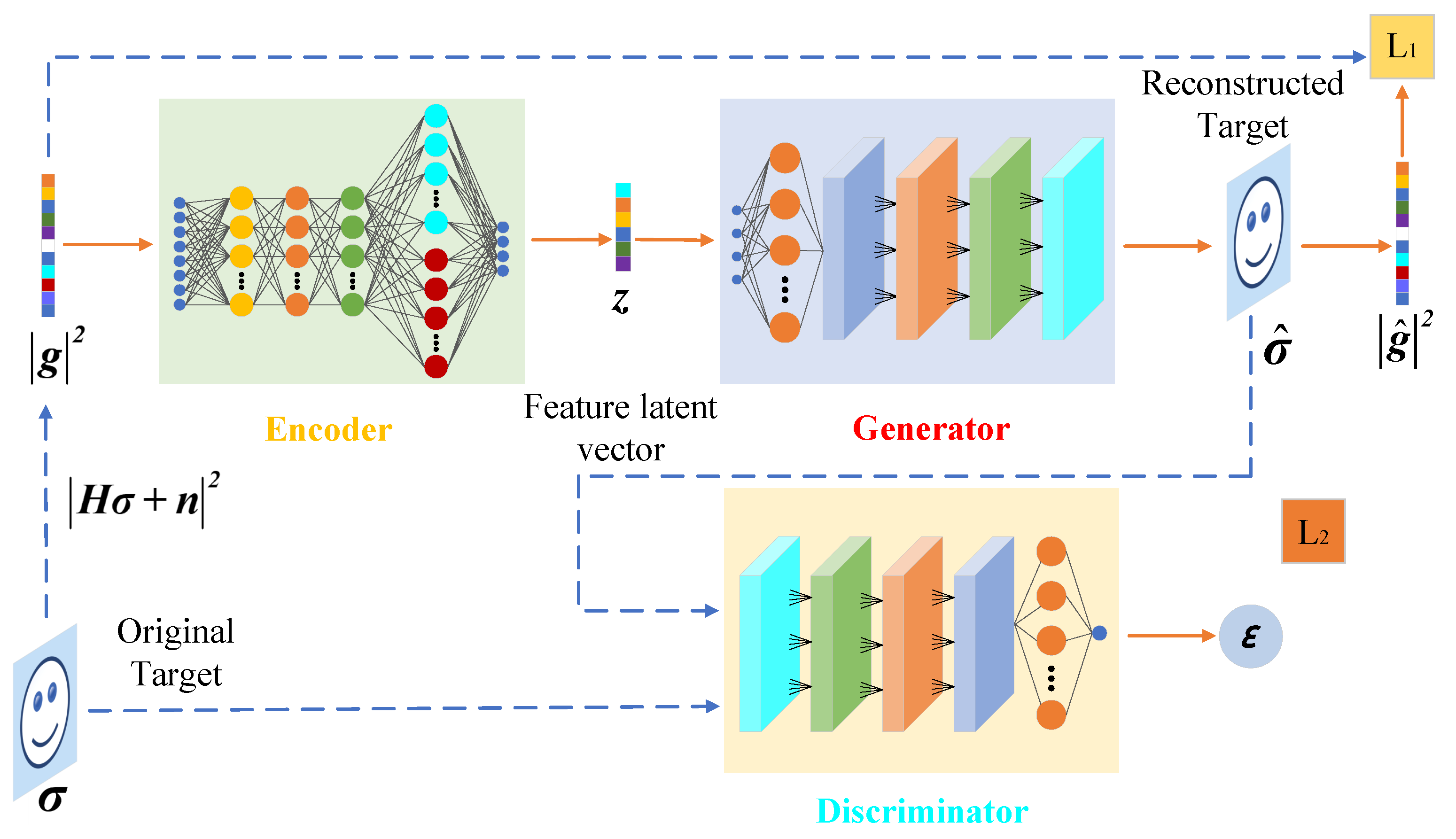
In the proposed PFDI-Net, as shown in
Figure 2, the imaging network mainly consists of three main components: encoder, generator, and discriminator. Specifically, the encoder consists of four fully connected layers with 500, 1000, 500, and 40 neurons, each layer activated by the Relu function. The generator has four convolutional layers with channels of 256, 128, 64, and 1, a corresponding convolution kernel of 3 × 3, 4 × 4, 4 × 4, 4 × 4, and a fully connected layer of 784 neurons sent to the convolutional layer after receiving the feature hidden vector extracted by the encoder for feature learning. Four convolutional layers and a fully connected layer form the discriminator. The structure of the generator and discriminator is symmetrical, with the four convolution layers having channels of 1, 64, 128, and 256, and the convolution kernel sizes are all 4 × 4. The only fully connected layer helps the discriminator’s output discrimination probability. It should be emphasized that Leaky Relu is used in all imaging network layers to activate the function. The Leaky Relu function is a variant of the traditional and well-known Relu activation function; solving the problem of Relu function in the negative interval improves the model training and test fitting ability because the derivative is always nonzero and reduces the development of silent neurons in order to produce a better generation effect. The above content was updated and added in the revised version of the manuscript.
The PFDI-Net proposed by us, and the overall structure of the imaging network model, is shown in
Figure 2, which is made up of three primary components—an encoder, a generator, and a discriminator. Where
represents the original scene target,
represents the reconstructed scene target,
represents the echo measurement,
represents the reconstructed echo measurement, and z represents the original scene compressed by the encoder. The hidden vector of the target feature,
, represents the discriminator output probability: output 1 is true; output 0 is false. Additionally, the associated loss varies for each component since the generative model is represented by the mapping
, where
K is the dimension of the feature latent vector and
N is the number of grid cells in the imaging space; moreover,
. We assume that the scene target in Equation (
3) is
and that the inferred model mapping relationship is
. To better describe the latent features of the scene target image data, we introduce a Gaussian random latent variable
, so that there will be a generative model:
. Among it,
is the prior distribution of
z, which is used to describe the cognition of the data.
is described by a generative network
, and
contains all the parameters for generating the network.
With the target scene picture
as a starting point, the encoder condenses the inferred features to create a low-dimensional latent vector
, which is then supplied to the generator for imaging training to create a new sample
that closely resembles the target scene. Following the aforementioned training procedure, the model is stored for quick recall of test imaging. We suggest minimizing the following objective function in order to be able to extract information exclusively from the magnitude measurements in (
9) and to more accurately reconstruct the target image:
Finding the target
in (
10), which ideally only comprises samples taken from the image distribution, with
, and falling within the range of the generator, is our goal. In the low-dimensional latent representation space, the reduction technique in (
10) can be expressed equivalently as follows:
The idea behind this optimizer is to modify the latent representation vector z until the generator generates an image
that is consistent with (
10). Due to the modular operator and nonlinear deep generative model, the optimization process in (
10) is nonconvex and nonlinear. To locate the local minimum
, we use a gradient descent approach. It is important to note that when entering the method as a pretrained model, the generator’s weights are always fixed. Through the forward pass of the generator
, z is solved to provide the estimated image. The desired result is
, and the ideal
, denoted
, is the one that has the minimum reconstruction error.
For parametric inference, the true posterior distribution of the latent variable is very complicated. Therefore, it is difficult to obtain the desired explicit solution by expected maximum (EM), mean field variance Bayesian, Monte Carlo sampling (MCMC), and other methods. Furthermore, the number of samples to be processed in compressed sensing tasks is usually very large, which presents a test for the algorithm to handle large sample data. In view of this, the algorithm combines the characteristics of VAE, and effectively solves the parameters of the model by combining the prior inference network and the generative network .
Inference
through the prior feature network, i.e., the variational distribution of the output of the deep neural network has sufficient statistics to approximate the complex and true posterior distribution
of the hidden variable
:
where it represents a Gaussian distribution whose mean is
, the diagonal covariance matrix is
, and the vector
is its diagonal elements. Any nonlinear function can be implemented
and
, such as a deep neural network, and
contains all the parameters of the inference network.
The parameters of the prior inference network
and the generative network
are jointly optimized by the following cost function:
In Equation (
12) above, the first term describes the error between the generated measurements and the actual measurements, while the second term is the prior regularization constraint on the implicit vector
, and the KL divergence is used for regularization.
To better enable the generated network to map the hidden variable
z to the space of the original image, an adversarial learning method is adopted in this paper. The generator
and the discriminator
train the imaging network alternately with the following min–max cost function:
By alternately optimizing the cost functions
and
, the above imaging network model can be well trained by Algorithm 1.
| Algorithm 1 PFDI-Net training algorithm. |
Input: H: measurement matrix; T: maximum training epochs; : Echo signal testing dataset; : Scene target training dataset.
- 1:
Initialize , , ; - 2:
Iteration via a gradient descent scheme: - 3:
for T do - 4:
Sampling a batch of s training samples - 5:
For the i-th training sample, calculate - 6:
Regarding the cost function (12), the inference network and the generative network are updated by the ADAM optimization algorithm. - 7:
The discriminator network is updated by the ADAM optimization algorithm with respect to the cost function: . - 8:
The generator network is updated by the ADAM optimization algorithm with respect to the cost function: ; - 9:
end for - 10:
Output: The target reflection coefficient estimate .
|
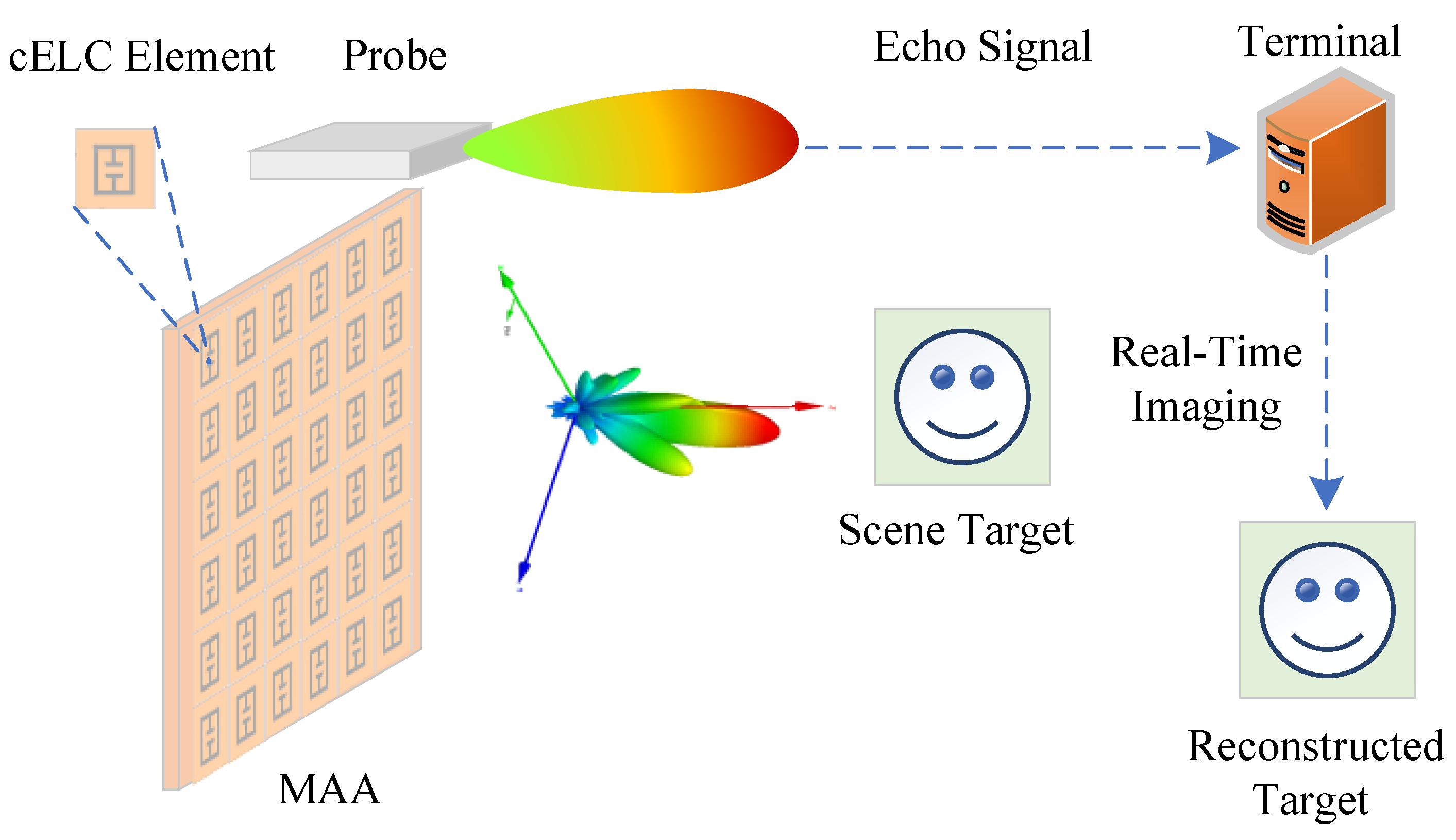
3.4. Measured Field Data
The measured radiation field data in this section serve to validate the proposed PFDI-Net approach. In this portion, a two-dimensional parallel-plate waveguide metasurface antenna with a waveguide slot feeding mechanism is designed and constructed to show the effectiveness of CI. By using the near-field scanning method, or measurement matrix, to measure the radiation field of various frequencies, a distance of 0.5 m must separate the scanning plane from the antenna platform. The image can then be recreated using the measured measurement matrix. Use an open-waveguide (OEWG) probe as the receiving antenna, including the panel-top probe configuration, to provide appropriate backscattered signal collection from all feasible directions and all frequencies. The antenna panel is 250 mm
2 in size, has a dielectric constant of 3.66, and a loss tangent of 0.003. The upper conductor of the waveguide uses 125 × 125 cELC metamaterial resonators, each of which has a Q value between 50 and 60. The substrate thickness between the copper ground layer and the conductive copper metamaterial hole is 0.5 mm.
Table 1 displays the system specifications of antennas.
The imaging experiment is based on the simulated metasurface antenna radiation field pattern data and imaging scene. The operation bandwidth of the antenna is 33∼37 GHz, the frequency sampling interval is 10 MHz, and the pattern of each frequency point is sampled along the two-dimensional spherical coordinate system of elevation and azimuth. The size of the field of view (FOV) is the elevation angle (∼), and the sampling interval is ; the azimuth angle sampling line of sight is (∼), and the sampling interval is , so the size of the original pattern T is .
The original target that contains the sparse target and extended target is employed to qualitatively evaluate the imaging ability of the measurement matrix for the scene. In order to qualitatively evaluate the ability of the measurement matrix to image the scene, the image containing the point-scattering target in the same dimension as the measurement matrix is used as the original image. It should be emphasized that the measurement matrix at this time is the pattern data, not the metamaterial in the actual imaging space. The measurement matrix is formed by the radiated field of the aperture antenna.
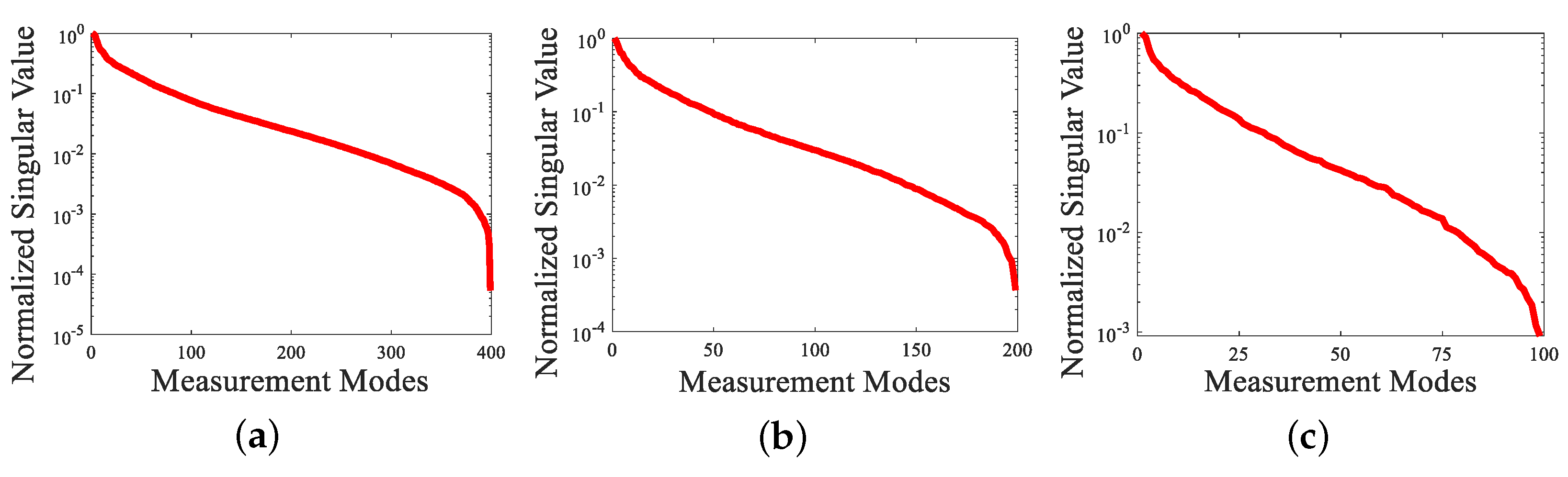
Figure 3 shows the singular value curves corresponding to the selected measurement matrix in different measurement modes, wherein the measurement modes are 400, 200, and 100 corresponding to M/N of 0.1, 0.05, and 0.025, respectively. In general, the number of nonzero singular values determines the accuracy of scene reconstruction using the pseudo-inverse operation, in the presence of measurement noise. The smaller singular value of the denominator term will diverge when the inversion operation is performed, which makes the reconstructed solution of the matrix inversion seriously deviate from the optimal solution.
3.5. Data Preparation
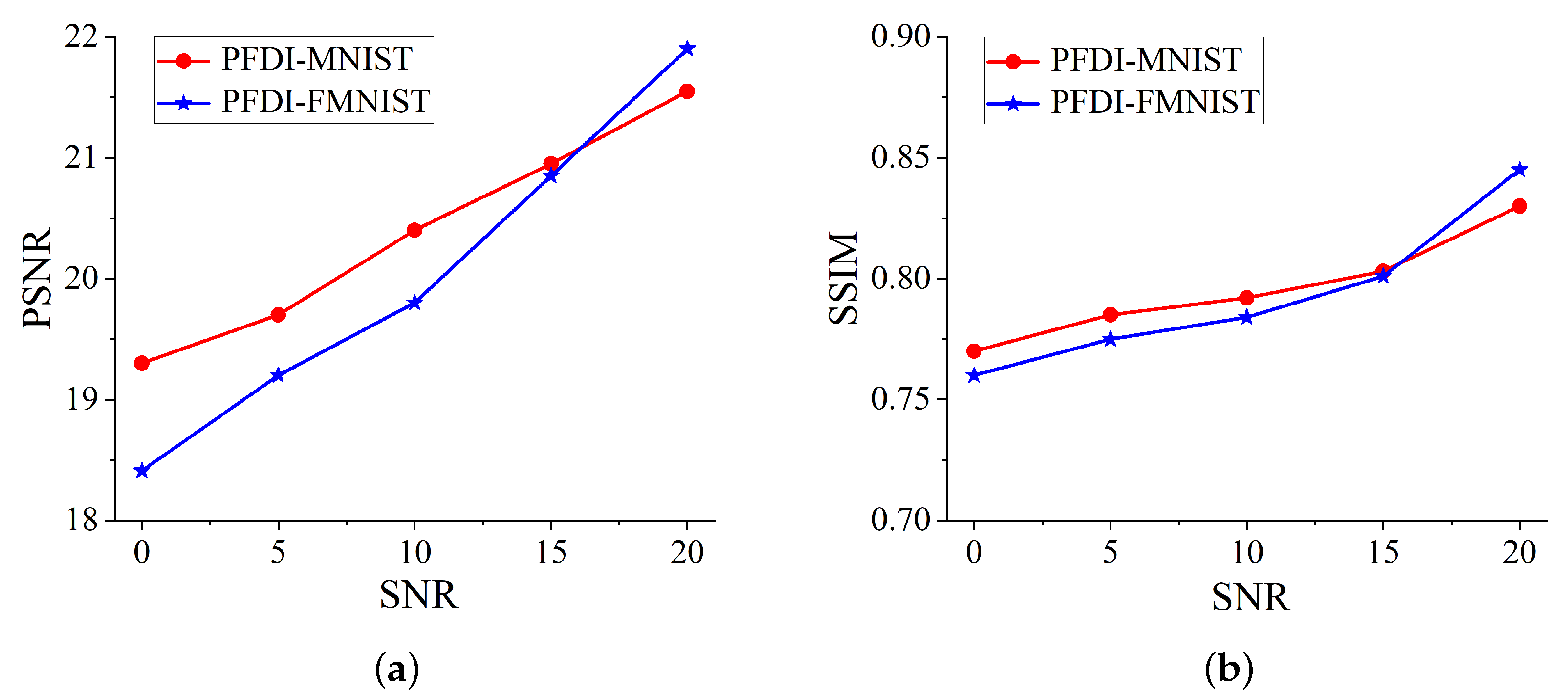
This paper uses the MNIST and Fashion-MNIST datasets to construct the target datasets required for our simulation tests. The original target scattering coefficients and associated echo measurement magnitudes should be included in the target datasets. Both datasets consist of 60,000 training images and 10,000 testing images, each of size 28 × 28. The initial images of the two datasets built above were modified to 61 × 61 in accordance with the experimental demands and the actual imaging specifications of the metasurface antenna used in the preceding section. Consider this adjustment to be an image made up of a number of scatter points with random scatter coefficient values between 0 and 1, and think of it as such. In order to create the datasets needed for our imaging, referred to as PFDI-MNIST and PFDI-FMNIST, respectively, 20,000 target images from each of the two datasets mentioned above were chosen. Each dataset contains the amplitude value of the echo measurement and the original target picture. The PFDI-MNIST dataset and the PFDI-FMNIST dataset under imaging settings were generated by the imaging algorithm and were separated into 70% training set, 20% validation set, and 10% test set.
Additionally, the Adam optimization algorithm is employed with a learning rate of 0.0001 and a batch size of 256 to optimize the complete imaging network model utilizing mean square error (MSE) and KL divergence as loss functions, and we employ the imaging quality metrics Peak Signal-to-Noise Ratio (PSNR) and Structure Similarity Index Measure (SSIM), which are noted alongside imaging outcomes. The imaging model is configured to train for 1000 epochs, and the latent vector dimension is set at 40. It takes a lot of time to validate findings and generate them after each training period, but it is necessary to track network performance. Following the completion of the network training, the network model is saved, the measured scene echo measurement value’s amplitude value is fed into the network, and the network model is called to produce the target image in real time.
The batch processing of the above data sets is carried out on the MATLAB platform. The network model is implemented on python 3.7 using tensorflow version 2.5 and is trained on a desktop computer with Nvidia 3070 Ti GPU and CUDA version 11.1. The desktop computer is ×64 compatible, with a Windows 10 64 bit operating system, Intel (R) core (TM) i7-10700 cpu@ 2.90 GHz, and 32 GB memory.
3.6. Numerical Tests
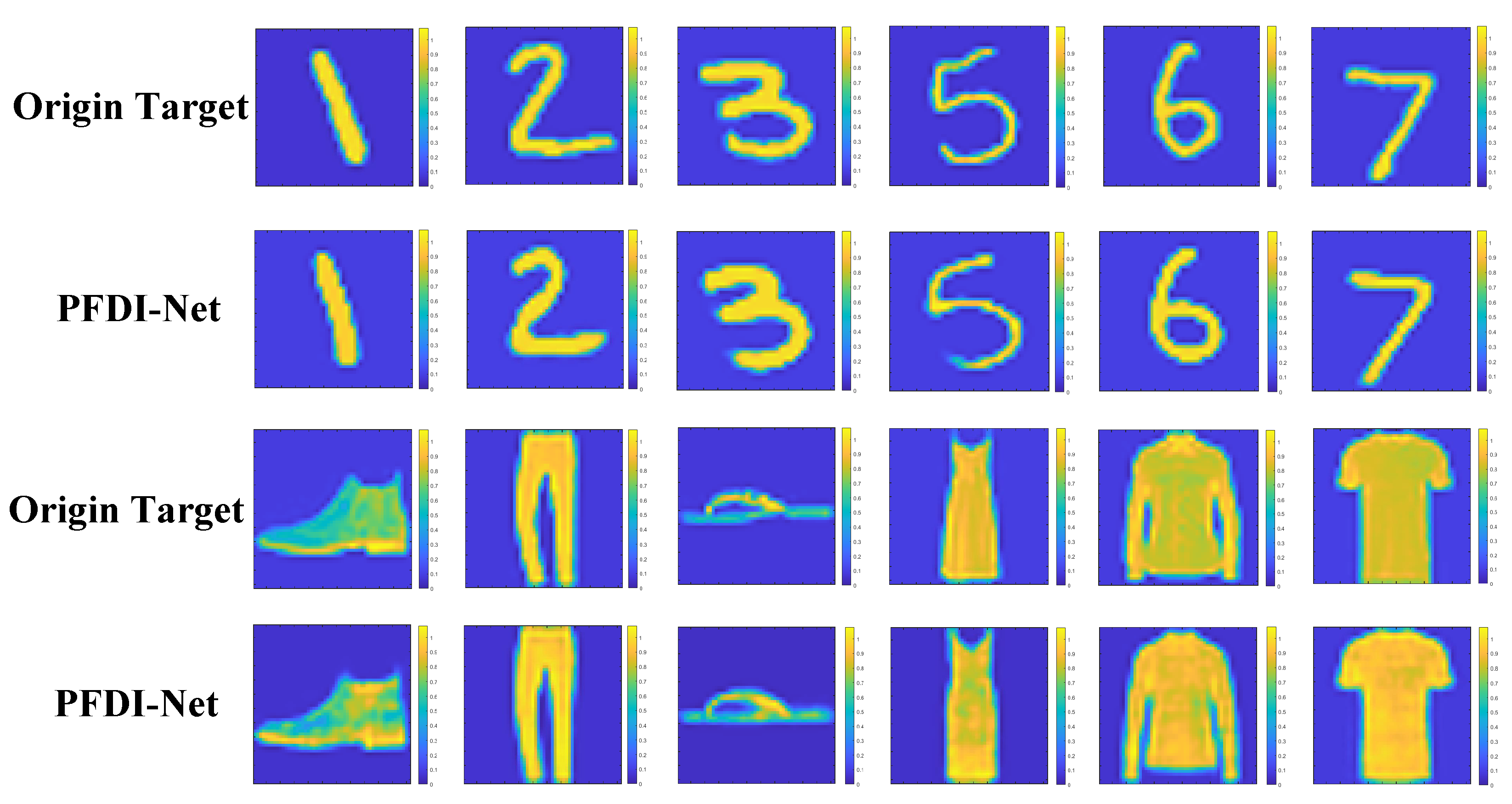
The PFDI-Net algorithm that we proposed can adopt a combination of an a priori inference model and generative adversarial model and performs imaging simulation training on the common sparse target image dataset PFDI-MNIST and the extended target dataset PFDI-FMNIST, respectively, to test the performance of our system’s target power generation capability. In order to conduct numerical experiments and performance evaluation more logically, we separately selected three targets for imaging comparisons in the above datasets. The measurement mode of the measurement matrix is selected as 400, which is equivalent to a scene information sampling rate M/N of 0.1, and the imaging result is shown in
Figure 4.
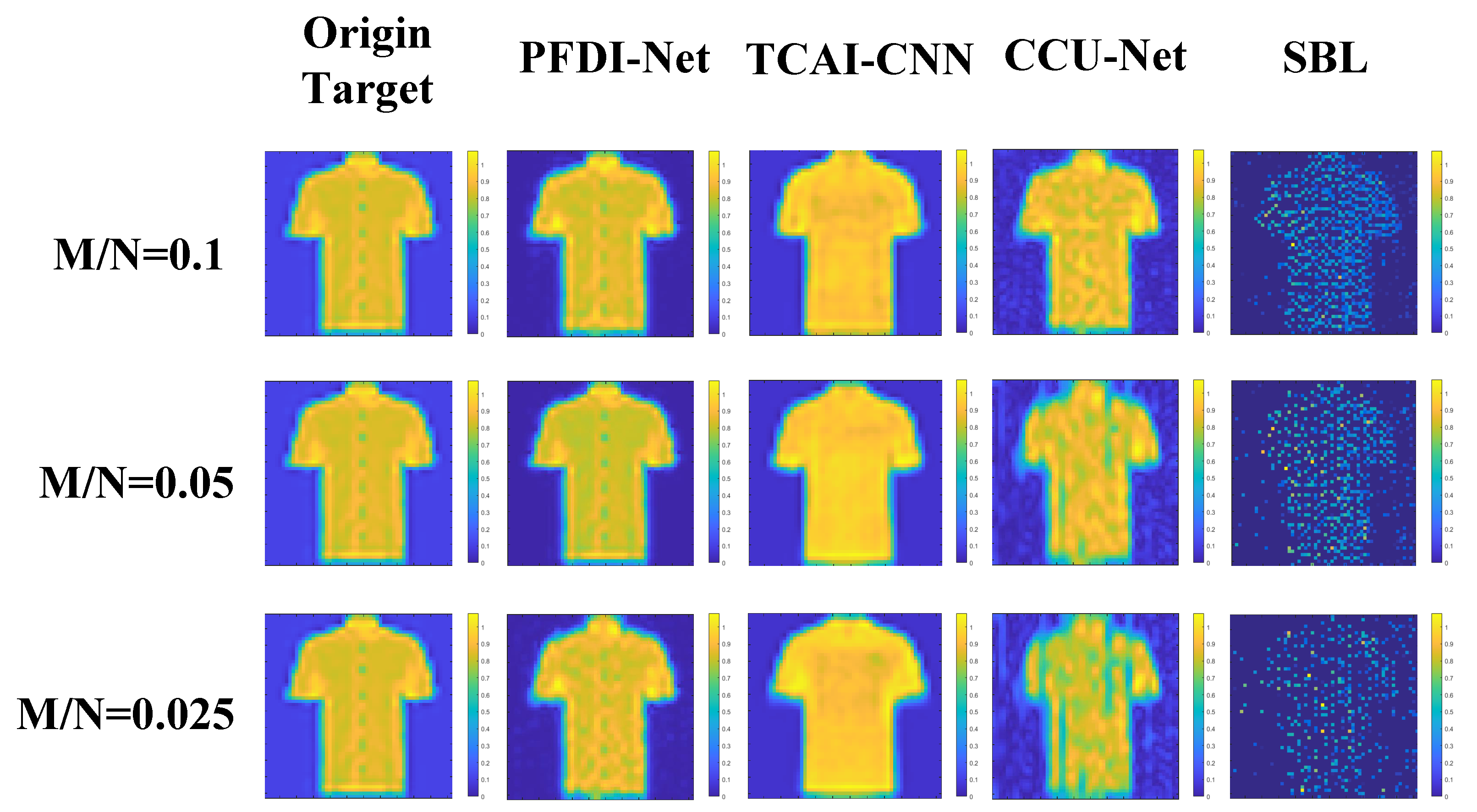
It should be emphasized that the imaging simulation process, with an emphasis on the application of our suggested approach, takes noise-free scenarios into account throughout. The experimental results demonstrate that the proposed algorithm can extract the prior information of the target contained only by inputting the amplitude value of the echo measurement value and cannot only reconstruct the regular sparse target but can also successfully restore the extension target under the condition of a fixed number of measurement modes and scene compression ratios. Additionally, the algorithm that we proposed can generate high-quality rebuilt images.
To further assess the efficiency of our suggested approach in reconstructing pictures using just amplitude information in the phaseless state, we ran a number of simulation experiments. First, the performance of our suggested approach is evaluated using the PFDI-Net in sparse and extended target datasets at various scene information compression ratios. The results are displayed in
Figure 5 and
Figure 6. It can be observed that our model can still provide a reconstruction target with a distinct target contour and good resolution when M/Ns are as low as 0.025, 0.05, and 0.1. Our approach passed the test even when the information compression ratio is lower, demonstrating strong resilience and efficiency.
Then, the imaging outcomes of our suggested approach for resolving the inverse problem are contrasted with those of a traditional sparse Bayesian learning (SBL) algorithm, a cascaded complex U-net (CCU-Net) model [
23], and a Terahertz Coded-Aperture Imaging network (TCAI-CNN) [
21]. In
Figure 5 and
Figure 6, although the TCAI-CNN reconstruction imaging results show the approximate shape, they cannot capture the detailed features specific to the target. Additionally, the original target contour features cannot be precisely reconstructed in the CCU-Net imaging results, the SBL algorithm is unable to operate in the case of extremely low compression ratios, and the imaging outcomes essentially show no details of the original target. In contrast, the target contour information could be perfectly retrieved with our method, and our approach comes closer to the actual scenario in the target building. In general, in comparison with the other three methods, while the other three approaches can recreate the target’s overall shape, the details are still missing and come with some strong artificial points. Our PFDI-Net approach yields higher resolution results with more accurate scattering intensity and a sharper target profile under all M/N situations. Moreover, the imaging quality steadily improves as M/N increases. The algorithm that is proposed by us offers higher resolution results with more realistic scattering intensities and sharper target contours than the other three algorithms under all M/N conditions.
Additionally, the proposed algorithm offers imaging more quickly than the classical SBL algorithm. According to an average of 10 experiments for each approach,
Table 2 displays the time needed for various techniques. Given how easily neural-network-based methods may be parallelized, we also monitor the reconstruction time while using GPUs to implement the suggested method. The end-to-end network, on the other hand, can directly translate the echo signal’s amplitude value into the target after compression, whereas classical imaging methods need numerous iterations to predict a viable solution. Therefore, it is not unexpected that generative model-based approaches are faster.
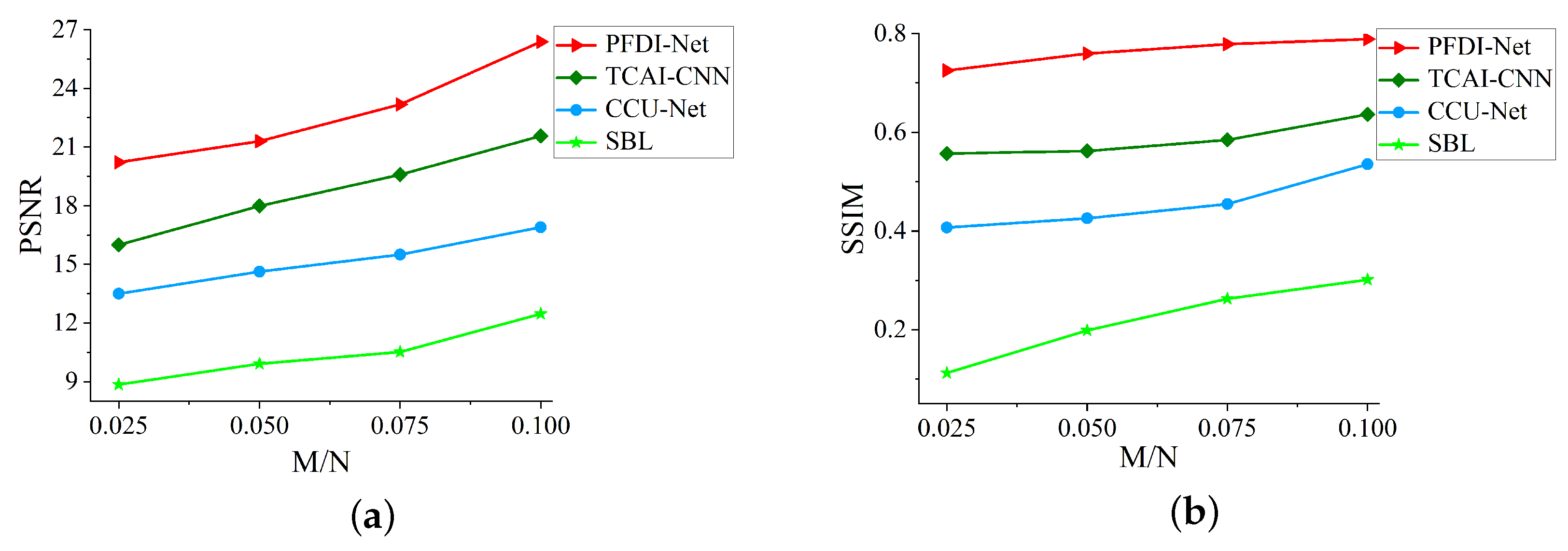
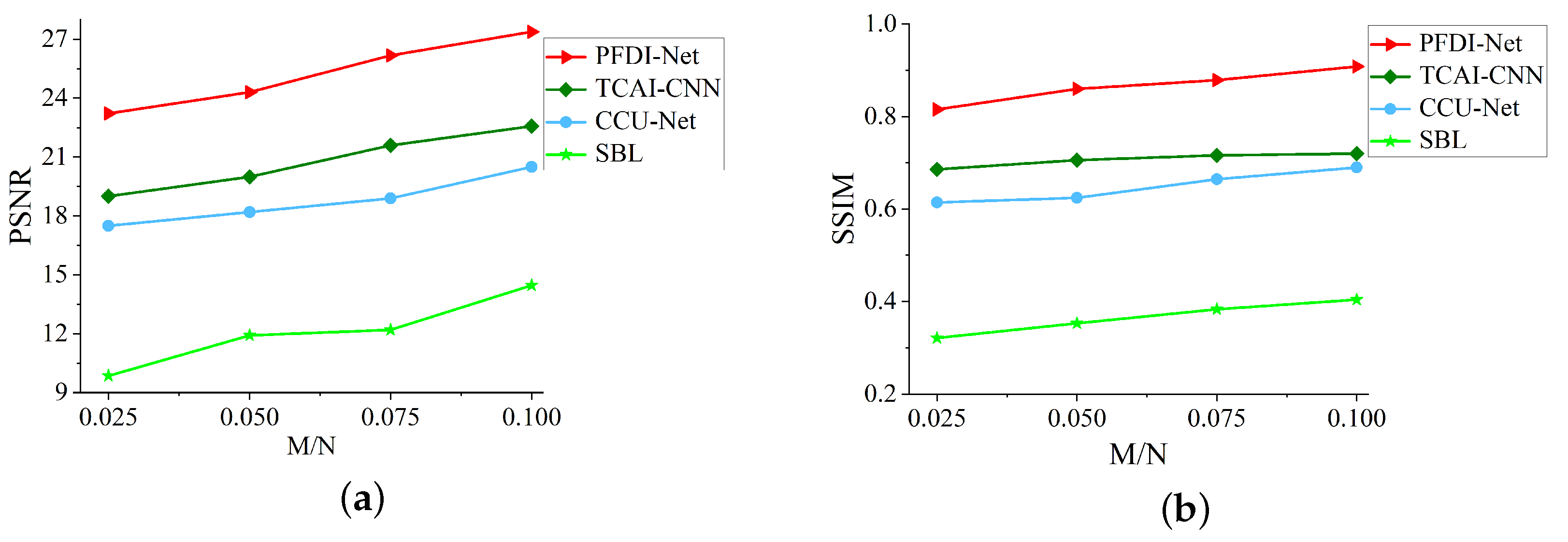
In order to reflect the imaging performance of the respective algorithms, we further use image Peak Signal-to-Noise Ratio (PSNR) and the Structure Similarity Index Measure (SSIM) value with the reference target image as two criteria to quantitatively evaluate the quality of the recovered targets, as illustrated in
Figure 7 and
Figure 8; as the M/N varies for PSNR in
Figure 7a and
Figure 8a, our approach produces greater reconstruction quality and is numerically superior to the other three methods. In terms of SSIM in
Figure 7b and
Figure 8b, our method is likewise significantly superior, thus attesting to the success of the PFDI-Net approach in reconstructing the intricate scene targets. Compared with previous imaging methods, our PFDI-Net is added to the feature prior inference network model. Due to the learning ability of the prior inference network, it can better learn the real distribution of the targe, and gradually generate realistic targets with training. No matter the M/N, the proposed approach performs better than the SBL, TCAI-CNN, and CCU-Net algorithms. The results demonstrate how effective the PFDI-Net approach is at reconstructing complicated scene items.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}