
Retrieval of Fine-Grained PM2.5 Spatiotemporal Resolution Based on Multiple Machine Learning Models



Abstract
:
1. Introduction
- A PM2.5 retrieval model that integrates high-resolution satellite images with meteorological and socio-economic variables was proposed. The retrieval results had a high level of accuracy while realizing a fine-grained spatiotemporal resolution.
- Six typical machine learning algorithms were used to build a PM2.5 retrieval model. By comparing the results of these algorithms using quantitative validation indexes, the optimal algorithm recommendation for a specific application is given.
2. Materials and Methods
2.1. Study Area
2.2. Datasets and Data Preprocessing
2.2.1. Remote Sensing Image Data
2.2.2. Ground Monitoring Station Data
2.2.3. Socio-Economic Data
2.3. Methodology
- Preprocess the input data of the model. Because there were some data abnormalities, inconsistent data dimensions, and site-location mismatch problems in the input data, the data were first standardized, the outliers were removed, and Thiessen polygons were constructed to find the nearest-neighbor sites.
- Build the retrieval model based on different machine learning algorithms. The MLR, kNN, SVR, RT, RF, and BPNN algorithms were used separately in this step to build the model. Validation index: MAE, RMSE, and R2, combined with the cross-validation method, were then used to evaluate the retrieval results.
- Compare and analyze the indicators of different models. The pollution value and pollution categories of the retrieval results of different machine learning algorithms were compared, and the spatiotemporal resolution of the retrieval method in this study was compared with the resolutions presented in similar studies.
2.3.1. Data Integration
2.3.2. Machine Learning Algorithms
- (1)
- MLR
- (2)
- kNN
- (3)
- SVR
- (4)
- RT
- (5)
- RF
- (6)
- BPNN
2.3.3. Model Validation
- (1)
- Validation method
- (2)
- Validation Index
3. Results
3.1. Analysis of PM2.5 Retrieval Results
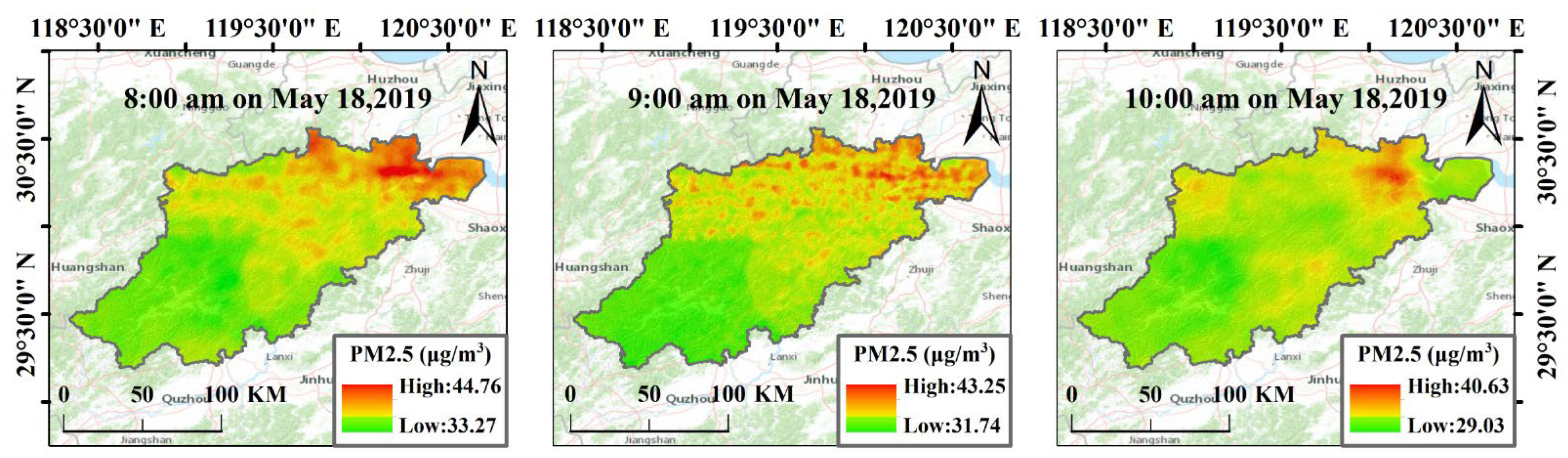
3.1.1. Prediction of the PM2.5 Concentration Distribution
3.1.2. Prediction of PM2.5-Based Air Quality Categories
3.1.3. Analysis of the Model Input Variables
3.2. Spatiotemporal Granularity Analysis of the Retrieval Result
4. Discussion
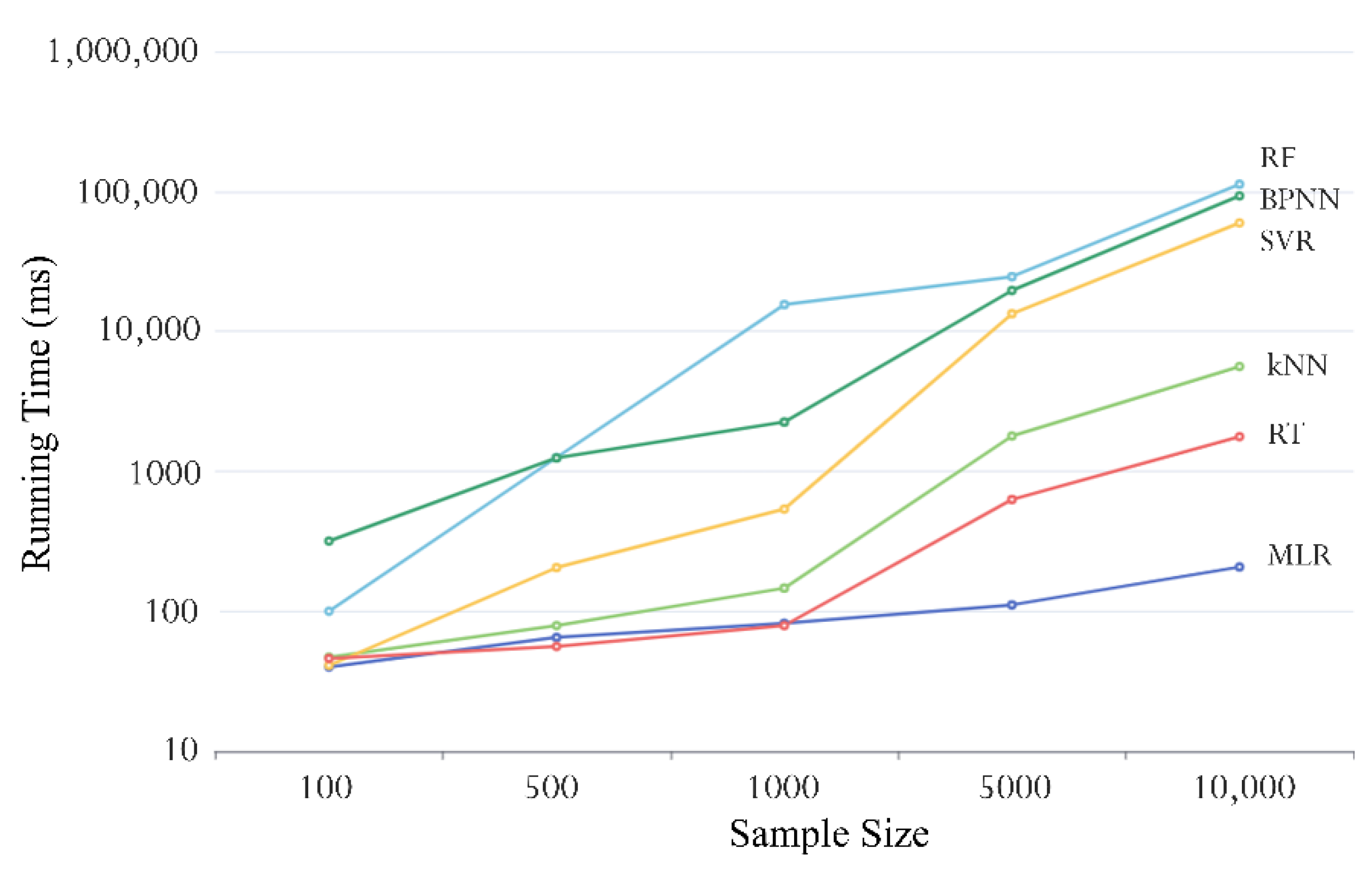
4.1. Time Efficiency of the Retrieval Model
4.2. Potential Room for Model Improvement
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MODIS | Moderate-resolution Imaging SpectroRadiometer |
| AOD | Aerosol Optical Depth |
| MLR | Multiple Linear Regression |
| SVR | Support Vector Regression |
| RF | Random Forest |
| ANN | Artificial Neural Network |
| kNN | k-nearest Neighbor |
| RT | Regression Tree |
| BPNN | Back Propagation Neural Network |
| USGS | United States Geological Survey |
| FLAASH | Fast Line-of-sight Atmospheric Analysis of Hypercubes |
| CNEMC | China National Environmental Monitoring Center |
| CMA | China Meteorological Administration |
| R2 | Determination Coefficient |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Observed | MLR | kNN | SVR | RT | RF | BPNN |
|---|---|---|---|---|---|---|---|
| Excellent | 9791 | 6312 | 8007 | 7873 | 8308 | 8910 | 8500 |
| Favorable | 8179 | 6509 | 6585 | 6336 | 6426 | 6372 | 6510 |
| Light pollution | 1688 | 514 | 1007 | 794 | 1055 | 1147 | 1205 |
| Moderate pollution | 367 | 0 | 143 | 69 | 144 | 198 | 202 |
| Heavy pollution | 115 | 0 | 16 | 2 | 48 | 0 | 72 |
| Ultra-serious pollution | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Total | 20,140 | 13,335 | 15,758 | 15,074 | 15,981 | 16,627 | 16,489 |
| Accuracy | — | 66% | 78% | 75% | 79% | 83% | 82% |
| Algorithm | Time Complexity | Running Time (ms) | ||||
|---|---|---|---|---|---|---|
| 100 | 500 | 1000 | 5000 | 10,000 | ||
| MLR | O(n) | 40 | 65 | 82 | 111 | 207 |
| kNN | O(n) | 47 | 79 | 146 | 1787 | 5602 |
| SVR | O(n2) | 41 | 205 | 537 | 13,340 | 59,422 |
| RT | O(nlog(n)) | 46 | 56 | 79 | 628 | 1765 |
| RF | O(nlog(n)) | 100 | 1251 | 15,494 | 24,549 | 112,265 |
| BPNN | O(n2) | 317 | 1245 | 2245 | 19,564 | 92,817 |
References
- Lelieveld, J.; Evans, J.S.; Fnais, M.; Giannadaki, D.; Pozzer, A. The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 2015, 525, 367–371. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Liu, Y.; Gao, H.; Ma, J.; Mao, X.; Wang, Y.; Ma, X. Forecasting PM2.5 induced male lung cancer morbidity in China using satellite retrieved PM2.5 and spatial analysis. Sci. Total Environ. 2017, 607–608, 1009–1017. [Google Scholar] [CrossRef] [PubMed]
- Turner, M.C.; Krewski, D.; Pope, C.A.; Chen, Y.; Gapstur, S.M.; Thun, M.J. Long-term ambient fine particulate matter air pollution and lung cancer in a large cohort of never-smokers. Am. J. Respir. Crit. Care Med. 2011, 184, 1374–1381. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Yuan, Q.; Li, T.; Yue, L. Mapping PM2.5 concentration at high resolution using a cascade random forest based downscaling model: Evaluation and application. J. Clean. Prod. 2020, 277, 123887. [Google Scholar] [CrossRef]
- Meng, X.; Liu, C.; Zhang, L.; Wang, W.; Stowell, J.; Kan, H.; Liu, Y. Estimating PM2.5 concentrations in Northeastern China with full spatiotemporal coverage, 2005–2016. Remote Sens. Environ. 2021, 253, 112203. [Google Scholar] [CrossRef]
- Chen, W.; Ran, H.; Cao, X.; Wang, J.; Teng, D.; Chen, J.; Zheng, X. Estimating PM2.5 with high-resolution 1-km AOD data and an improved machine learning model over Shenzhen, China. Sci. Total Environ. 2020, 746, 141093. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Li, L. A robust deep learning approach for spatiotemporal estimation of Satellite AOD and PM2.5. Remote Sens. 2020, 12, 264. [Google Scholar] [CrossRef] [Green Version]
- van Donkelaar, A.; Martin, R.V.; Brauer, M.; Kahn, R.; Levy, R.; Verduzco, C.; Villeneuve, P.J. Global estimates of ambient fine particulate matter concentrations from satellite-based aerosol optical depth: Development and application. Environ. Health Perspect. 2010, 118, 847–855. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Li, H.; Zhang, S.; Chen, Y.; Fan, Q. High Spatial Resolution PM2.5 Retrieval Using MODIS and Ground Observation Station Data Based on Ensemble Random Forest. IEEE Access 2019, 7, 44416–44430. [Google Scholar] [CrossRef]
- Yazdi, M.D.; Kuang, Z.; Dimakopoulou, K.; Barratt, B.; Suel, E.; Amini, H.; Lyapustin, A.; Katsouyanni, K.; Schwartz, J. Predicting fine particulate matter (PM2.5) in the greater london area: An ensemble approach using machine learning methods. Remote Sens. 2020, 12, 914. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Hu, X.; Huang, L.; Bi, J.; Liu, Y. Estimating ground-level PM2.5 in china using satellite remote sensing. Environ. Sci. Technol. 2014, 48, 7436–7444. [Google Scholar] [CrossRef] [PubMed]
- Zou, B.; Zheng, Z.; Wan, N.; Qiu, Y.; Wilson, J.G. An optimized spatial proximity model for fine particulate matter air pollution exposure assessment in areas of sparse monitoring. Int. J. Geogr. Inf. Sci. 2016, 30, 727–747. [Google Scholar] [CrossRef]
- de Hoogh, K.; Héritier, H.; Stafoggia, M.; Künzli, N.; Kloog, I. Modelling daily PM2.5 concentrations at high spatio-temporal resolution across Switzerland. Environ. Pollut. 2018, 233, 1147–1154. [Google Scholar] [CrossRef]
- Unnithan, S.L.K.; Gnanappazham, L. Spatiotemporal mixed effects modeling for the estimation of PM2.5 from MODIS AOD over the Indian subcontinent. GISci. Remote Sens. 2020, 57, 159–173. [Google Scholar] [CrossRef]
- Liu, Y.; Park, R.J.; Jacob, D.J.; Li, Q.; Kilaru, V.; Sarnat, J.A. Mapping annual mean ground-level PM2.5 concentrations using Multiangle Imaging Spectroradiometer aerosol optical thickness over the contiguous United States. J. Geophys. Res. D Atmos. 2004, 109, 3269–3278. [Google Scholar]
- Liu, Y.; Sarnat, J.A.; Kilaru, V.; Jacob, D.J.; Koutrakis, P. Estimating ground-level PM2.5 in the eastern United States using satellite remote sensing. Environ. Sci. Technol. 2005, 39, 3269–3278. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Q.; Tao, J.; Chen, L.; Zhu, H.; Zhu, S.Y.; Wang, Y. Estimating ground-level particulate matter in five regions of China using aerosol optical depth. Remote Sens. 2020, 12, 881. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.J.; Liu, Y.; Coull, B.A.; Schwartz, J.; Koutrakis, P. A novel calibration approach of MODIS AOD data to predict PM2.5 concentrations. Atmos. Chem. Phys. 2011, 11, 7991–8002. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhu, Z.; Gong, W.; Zhu, Z.; Sun, K.; Wang, L.; Huang, Y.; Mao, F.; Shen, H.; Li, Z.; et al. Estimation of ultrahigh resolution PM2.5 concentrations in urban areas using 160 m Gaofen-1 AOD retrievals. Remote Sens. Environ. 2018, 216, 91–104. [Google Scholar] [CrossRef]
- Sun, L.; Wei, J.; Bilal, M.; Tian, X.; Jia, C.; Guo, Y.; Mi, X. Aerosol optical depth retrieval over bright areas using Landsat 8 OLI images. Remote Sens. 2016, 8, 23. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Han, F.; Li, M.; Zhang, Z.; Xiaohui, D.; Wei, P. On the opposite seasonality of MODIS AOD and surface PM2.5 over the Northern China plain. Atmos. Environ. 2019, 215, 116909. [Google Scholar] [CrossRef]
- Yang, Q.; Yuan, Q.; Yue, L.; Li, T.; Shen, H.; Zhang, L. The relationships between PM2.5 and aerosol optical depth (AOD) in mainland China: About and behind the spatio-temporal variations. Environ. Pollut. 2019, 248, 526–535. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zhang, M.; Kang, J.; Hong, D.; Xu, J.; Zhu, X. Estimation of PMx Concentrations from Landsat 8 OLI Images Based on a Multilayer Perceptron Neural Network. Remote Sens. 2019, 11, 646. [Google Scholar] [CrossRef] [Green Version]
- Yun, G.; Zuo, S.; Dai, S.; Song, X.; Id, C.X.; Liao, Y.; Zhao, P.; Chang, W.; Id, Q.C.; Li, Y.; et al. Individual and Interactive Influences of Anthropogenic and Ecological Factors on Forest PM2.5 Concentrations at an Urban Scale. Remote Sens. 2018, 10, 521. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Weng, F.; Li, Z.; Cribb, M.C. Hourly PM2.5 estimates from a geostationary satellite based on an ensemble learning algorithm and their spatiotemporal patterns over central East China. Remote Sens. 2019, 11, 2120. [Google Scholar] [CrossRef] [Green Version]
- He, Q.; Huang, B. Satellite-based high-resolution PM2.5 estimation over the Beijing-Tianjin-Hebei region of China using an improved geographically and temporally weighted regression model. Environ. Pollut. 2018, 236, 1027–1037. [Google Scholar] [CrossRef]
- Kaimian, H.; Li, Q.; Wu, C.; Qi, Y.; Mo, Y.; Chen, G.; Zhang, X.; Sachdeva, S. Evaluation of different machine learning approaches to forecasting PM2.5 mass concentrations. Aerosol. Air Qual. Res. 2019, 19, 1400–1410. [Google Scholar] [CrossRef] [Green Version]
- Stadlober, E.; Hörmann, S.; Pfeiler, B. Quality and performance of a PM10 daily forecasting model. Atmos. Environ. 2008, 42, 1098–1109. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapoik, V.; Long, W.; Nj, B. Support Vector Regression Machines. Neural Inf. Process. 1996, 28, 779–784. [Google Scholar]
- Zhu, S.; Lian, X.; Wei, L.; Che, J.; Shen, X.; Yang, L.; Qiu, X.; Liu, X.; Gao, W.; Ren, X.; et al. PM2.5 forecasting using SVR with PSOGSA algorithm based on CEEMD, GRNN and GCA considering meteorological factors. Atmos. Environ. 2018, 183, 20–32. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Chen, B.; Zhang, Y.; Zhao, Y.; Xian, Y.; Xu, G.; Zhang, H.; Guo, L. Retrieval of daily PM2.5 concentrations using nonlinear methods: A case study of the Beijing-Tianjin-Hebei Region, China. Remote Sens. 2018, 10, 2006. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.; Wu, L.; Qin, K.; Zhang, Y.; Shen, Y.; Zhou, Y. A geographically and temporally weighted regression model for ground-level PM2.5 estimation from satellite-derived 500 m resolution AOD. Remote Sens. 2016, 8, 262. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Chen, W.; Liang, Z. Impact of land use on PM2.5 pollution in a representative city of middle China. Int. J. Environ. Res. Public Health 2017, 14, 462. [Google Scholar] [CrossRef]
- Askariyeh, M.H.; Zietsman, J.; Autenrieth, R. Traffic contribution to PM2.5 increment in the near-road environment. Atmos. Environ. 2020, 224, 117113. [Google Scholar] [CrossRef]
- Han, D.; Gao, S.; Fu, Q.; Cheng, J.; Chen, X.; Xu, H.; Liang, S.; Zhou, Y.; Ma, Y. Do volatile organic compounds (VOCs) emitted from petrochemical industries affect regional PM2.5? Atmos. Res. 2018, 209, 123–130. [Google Scholar] [CrossRef]
- Cooley, T.; Anderson, G.P.; Felde, G.W.; Hoke, M.L.; Ratkowski, A.J.; Chetwynd, J.H.; Gardner, J.A.; Adler-Golden, S.M.; Matthew, M.W.; Berk, A.; et al. FLAASH, a MODTRAN4-based atmospheric correction algorithm, its applications and validation. Int. Geosci. Remote Sens. Symp. 2002, 3, 1414–1418. [Google Scholar]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Pal, M.; Bharati, P. Introduction to correlation and linear regression analysis. In Applications of Regression Techniques; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–18. [Google Scholar]
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing machine learning classifiers for object-based land cover classification using very high resolution imagery. Remote Sens. 2015, 7, 153–168. [Google Scholar] [CrossRef]
- Tao, Y.; Yan, H.; Gao, H.; Sun, Y.; Li, G. Application of SVR optimized by modified simulated annealing (MSA-SVR) air conditioning load prediction model. J. Ind. Inf. Integr. 2019, 15, 247–251. [Google Scholar] [CrossRef]
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhao, S.; Jiao, L.; Taylor, M.; Zhang, B.; Xu, G.; Hou, H. Estimation of PM2.5 concentrations in China using a spatial back propagation neural network. Sci. Rep. 2019, 9, 13788. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cawley, G.C.; Talbot, N.L.C. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Zhang, H.; Kondragunta, S. Daily and Hourly Surface PM2.5 Estimation From Satellite AOD. Earth Space Sci. 2021, 8, e2020EA001599. [Google Scholar] [CrossRef]
- Xue, W.; Zhang, J.; Zhong, C.; Li, X.; Wei, J. Spatiotemporal PM2.5 variations and its response to the industrial structure from 2000 to 2018 in the Beijing-Tianjin-Hebei region. J. Clean. Prod. 2021, 279, 123742. [Google Scholar] [CrossRef]
- Chen, Z.; Hao, X.; Zhang, X.; Chen, F. Have traffic restrictions improved air quality? A shock from COVID-19. J. Clean. Prod. 2021, 279, 123622. [Google Scholar] [CrossRef]
- Yuan, M.; Huang, Y.; Shen, H.; Li, T. Effects of urban form on haze pollution in China: Spatial regression analysis based on PM2.5 remote sensing data. Appl. Geogr. 2018, 98, 215–223. [Google Scholar] [CrossRef]
- Li, X.; Wu, C.; Meadows, M.E.; Zhang, Z.; Lin, X.; Zhang, Z.; Chi, Y.; Feng, M.; Li, E.; Hu, Y. Factors underlying spatiotemporal variations in atmospheric pm2.5 concentrations in zhejiang province, china. Remote Sens. 2021, 13, 3011. [Google Scholar] [CrossRef]
- Gao, L.-N.; Tao, F.; Ma, P.-L.; Wang, C.-Y.; Kong, W.; Chen, W.-K.; Zhou, T. A short-distance healthy route planning approach. J. Transp. Health 2022, 24, 101314. [Google Scholar] [CrossRef]
- Reid, C.E.; Jerrett, M.; Petersen, M.L.; Pfister, G.G.; Morefield, P.E.; Tager, I.B.; Raffuse, S.M.; Balmes, J.R. Spatiotemporal prediction of fine particulate matter during the 2008 Northern California wildfires using machine learning. Environ. Sci. Technol. 2015, 49, 3887–3896. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, M.; Huang, B.; Li, S.; Lin, Y. Estimation and analysis of the nighttime PM2.5 concentration based on lj1-01 images: A case study in the pearl river delta urban agglomeration of china. Remote Sens. 2021, 13, 3405. [Google Scholar] [CrossRef]









| Category | Source | Accessed Date | Uniform Resource Location |
|---|---|---|---|
| Landsat images | USGS | 15 January 2020 | https://earthexplorer.usgs.gov/ |
| PM2.5 | CNEMC | 15 January 2020 | http://www.cnemc.cn/ |
| Meteorological | CMA | 15 January 2020 | http://www.cma.gov.cn/ |
| GDP | RESDC | 2 March 2020 | http://www.resdc.cn/ |
| POP | RESDC | 2 March 2020 | http://www.resdc.cn/ |
| Industry | BaiduMap | 5 March 2020 | https://lbsyun.baidu.com/ |
| Road Networks | OpenStreetMap | 5 March 2020 | https://www.openstreetmap.org/ |
| Model | Min (μg/m3) | Max (μg/m3) | Mean (μg/m3) | Median (μg/m3) |
|---|---|---|---|---|
| Observed | 1.0 | 198.08 | 42.30 | 35.77 |
| MLR | −57.73 (−58.73) | 121.56 (−76.52) | 42.30 (0) | 39.96 (+4.19) |
| KNN | 3.92 (+2.92) | 162.91 (−35.17) | 42.34 (+0.04) | 36.47 (+0.70) |
| SVR | 1.36 (+0.36) | 152.31 (−45.77) | 41.00 (−1.30) | 36.32 (+0.55) |
| RT | 1.0 (0) | 195.88 (−2.20) | 42.49 (+0.19) | 36.36 (+0.59) |
| RF | 5.74 (+4.74) | 154.19 (−43.89) | 42.42 (+0.12) | 37.00 (+1.23) |
| BPNN | 7.34 (+6.34) | 182.94 (15.14) | 41.51 (−0.79) | 34.45 (−1.32) |
| Model | MAE (μg/m3) | RMSE (μg/m3) | R2 |
|---|---|---|---|
| MLR | 13.29 | 18.78 | 0.51 |
| kNN | 8.28 | 11.80 | 0.80 |
| SVR | 10.11 | 15.05 | 0.68 |
| RT | 8.24 | 12.60 | 0.78 |
| RF | 6.72 | 10.11 | 0.86 |
| BPNN | 7.14 | 10.37 | 0.85 |
| Variable | Importance Ranking | Correlation Ranking | Ranking Change |
|---|---|---|---|
| 1DB | 1 | 1 | - |
| PREC | 2 | 10 | ↑ 8 |
| WS | 3 | 9 | ↑ 6 |
| TEMP | 4 | 3 | ↓ 1 |
| 2DB | 5 | 2 | ↓ 3 |
| RH | 6 | 18 | ↑ 12 |
| 6DB | 7 | 7 | - |
| 7DB | 8 | 5 | ↓ 3 |
| 4DB | 9 | 6 | ↓ 3 |
| 3DB | 10 | 4 | ↓ 6 |
| POP | 11 | 13 | ↑ 2 |
| Industry | 12 | 14 | ↑ 2 |
| Road | 13 | 12 | ↓ 1 |
| GDP | 14 | 16 | ↑ 2 |
| Band 5 | 15 | 11 | ↓ 4 |
| NDVI | 16 | 23 | ↑ 7 |
| Band 7 | 17 | 22 | ↑ 5 |
| Band 6 | 18 | 15 | ↓ 3 |
| Band 4 | 19 | 21 | ↑ 2 |
| Band 3 | 20 | 17 | ↓ 3 |
| Band 1 | 21 | 20 | ↓ 1 |
| Band 2 | 22 | 19 | ↓ 3 |
| Time | MAE (μg/m3) | RMSE (μg/m3) | R2 |
|---|---|---|---|
| January | 10.08 | 13.85 | 0.85 |
| February | 8.80 | 12.87 | 0.83 |
| March | 7.68 | 10.97 | 0.84 |
| April | 5.30 | 7.43 | 0.77 |
| May | 5.92 | 8.84 | 0.81 |
| June | 7.42 | 13.02 | 0.55 |
| July | 4.49 | 6.65 | 0.75 |
| August | 4.43 | 6.03 | 0.84 |
| September | 4.66 | 6.80 | 0.77 |
| October | 7.34 | 10.78 | 0.81 |
| November | 6.80 | 9.00 | 0.71 |
| December | 9.86 | 13.96 | 0.82 |
| Spring | 6.84 | 10.04 | 0.82 |
| Summer | 5.20 | 8.39 | 0.71 |
| Autumn | 6.16 | 9.09 | 0.78 |
| Winter | 10.09 | 14.54 | 0.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, P.; Tao, F.; Gao, L.; Leng, S.; Yang, K.; Zhou, T. Retrieval of Fine-Grained PM2.5 Spatiotemporal Resolution Based on Multiple Machine Learning Models. Remote Sens. 2022, 14, 599. https://doi.org/10.3390/rs14030599
Ma P, Tao F, Gao L, Leng S, Yang K, Zhou T. Retrieval of Fine-Grained PM2.5 Spatiotemporal Resolution Based on Multiple Machine Learning Models. Remote Sensing. 2022; 14(3):599. https://doi.org/10.3390/rs14030599
Chicago/Turabian StyleMa, Peilong, Fei Tao, Lina Gao, Shaijie Leng, Ke Yang, and Tong Zhou. 2022. "Retrieval of Fine-Grained PM2.5 Spatiotemporal Resolution Based on Multiple Machine Learning Models" Remote Sensing 14, no. 3: 599. https://doi.org/10.3390/rs14030599
APA StyleMa, P., Tao, F., Gao, L., Leng, S., Yang, K., & Zhou, T. (2022). Retrieval of Fine-Grained PM2.5 Spatiotemporal Resolution Based on Multiple Machine Learning Models. Remote Sensing, 14(3), 599. https://doi.org/10.3390/rs14030599