1. Introduction
Semantic segmentation of remote sensing images plays a significant role in remote sensing image processing. It aims to classify various ground object categories in the image pixel by pixel (e.g., roads, buildings, trees, vehicles and fields) and give the corresponding semantic information. It has been widely applied in urban planning [
1], environmental monitoring [
2] and land resource utilization [
3].
The main methods of remote sensing image segmentation are based on full convolution neural networks and involve design of an appropriate model structure to extract as much ground feature information as possible. To better integrate high-level and low-level features, UNet [
4] employs skip connection and SegNet [
5] retains the maximum pool layer index in the encoder. RefineNet [
6] integrates the characteristics of ResNet [
7] and UNet [
4], and introduces chain pooling to extract background semantic information. In addition, to solve the multi-scale problem in remote sensing imagery, PSPNet [
8] includes a pyramid pooling module (PPM), which combines the global pooling and convolution cores of different sizes. Deeplab [
9,
10,
11] introduces the dilated convolution and atrous spatial pyramid pooling module (ASPP), which reduces the number of down-sampling operations and enlarges the reception field range. HRNet [
12,
13] maintains high-resolution representation by connecting the high-resolution and low-resolution feature maps concurrently, and enhances the high-resolution feature representation of the image by repeating parallel convolutions and performing multi-scale fusion. In addition, a series of models (e.g., LinkNet [
14], BiSeNet [
15], DFANet [
16]) are also designed for faster speed of inference and to include fewer parameters in the model. However, for complex background and diverse types of ground objects, there are still some tricky problems.
The first issue is that remote sensing image quality can be easily affected by external factors, which creates challenges for the practical segmentation process. For instance, due to different camera angles and ground heights, there are always shadows and occluded objects in the real images, which could be segmented wrongly. To resolve this problem, many scholars utilize auxiliary data to supervise network training. The most common method is to take digital surface model (DSM) data corresponding to the remote sensing image as supplementary information of the color channel, or to combine the open-source map data. Moreover, considering that not all remote sensing images have DSM or open-source map data, some scholars have introduced boundary information. In addition to outputting image segmentation results, they also obtain image boundary results and calculate the boundary loss. Nevertheless, as the image boundary belongs to low-level feature information, direct combination of low-level information with the high-level feature map may impose noise impacts on the final segmentation results. The image and its boundary share the same output branch, which will also weaken the learning capacity of the network for the original image. It is still challenging to integrate the boundary information into the model effectively.
Another issue is that some ground objects are easily confused. In general, remote sensing images have the characteristics of high intraclass variance and low interclass variance. For example, grass and trees, sparse grass and roads are intertwined and close in color in some scenes—many models may make a discrimination error among them. To solve the problem, some scholars have designed corresponding modules combined with the attention mechanism, which mainly includes channel attention and spatial attention. However, whether calculating the relationship of channels or pixels, it is essential that the process assigns different weights, which will produce dense attention maps simultaneously. It is hard to accurately capture the semantic information corresponding to different ground objects in remote sensing images. If the related module is not devised properly, it will not only increase the network complexity and the memory space, but also produce some redundant features. To enable the model to better distinguish confused features, combining category feature information with the attention mechanism can be considered. While calculating the contextual correlation between each pixel and other pixels in the surrounding area, the same category will be enhanced, and any different category will be weakened.
Inspired by the two issues above, we propose a high-resolution boundary-constrained and context-enhanced network (HBCNet) for remote sensing image segmentation. Different from the traditional encode-decoder structure, we choose the pretrained HRNet as our network baseline. HRNet connects the feature map from high-resolution to low resolution in parallel and adopts repeated multi-scale fusion, which is more conducive to extraction of the corresponding boundary information. We then devise the boundary-constrained module (BCM) and the context-enhanced module (CEM). The boundary-constrained module combines the high-resolution feature map from the network baseline to obtain boundary information and multiple BCMs are cascaded to form a boundary extraction branch, which is parallel with the main segmentation branch. The context-enhanced module consists of three parts: contextual feature expression (CFE), semantic attention extraction (SAE) and contextual enhancement representation (CER). We also adopt multi-loss which consists of boundary and image loss to better train our network.
Together, the main contributions of this paper are the following:
We present a boundary-constrained module (BCM) and form a parallel boundary extraction branch in the main segmentation network. Meanwhile, the boundary loss and the image loss are successfully combined to supervise the network training.
We devise a context-enhanced module (CEM) with the self-attention mechanism to introduce the contextual representation into the object region feature expression. This promotes the semantic correlation among pixels of the same ground object type.
Based on HRNet and the two modules above, we propose the HBCNet for remote sensing image segmentation and adopt test-time augmentation (TTA) to improve the final segmentation accuracy effectively.
The remainder of this paper is arranged as follows. Related work is introduced in
Section 2. The overview of HBCNet and its components are detailed in
Section 3. The experimental results on the ISPRS Vahingen and Potsdam benchmarks are presented in
Section 4. Discussion, including of an ablation study, is provided in
Section 5. The final conclusions are drawn in
Section 6.
3. Methods
In this section, we first provide an overall introduction to the HBCNet, and then demonstrate the basic principles and internal structure of the boundary-constrained module and the context-enhanced module. Finally, we illustrate the related multi-loss function in the process of network training.
3.1. Overview
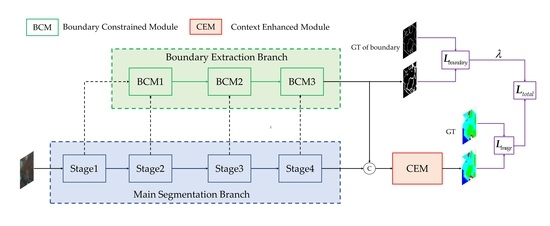
The overall structure of the high-resolution boundary-constrained and context-enhanced network (HBCNet) is shown in
Figure 1.
The network consists of three parts: the image branch, the boundary branch and the context-enhanced module. The image branch takes HRNet, which includes four stages, as the baseline for feature extraction. Each stage connects the multi-resolution feature maps in parallel and repeatedly exchanges information on the sub-network for multi-scale fusion. The boundary branch is cascaded by three boundary-constrained modules. The first BCM inputs are the highest resolution feature maps of stage 1 and stage 2 in the baseline, and the next two BCM inputs come from the previous BCM and the corresponding baseline stage output. The last BCM not only outputs the results of boundary extraction, but also transfers them to the context-enhanced module (CEM). The CEM also consists of three portions: contextual feature expression (CFE), semantic attention extraction (SAE) and contextual enhancement representation (CER). First, the deep network features and the boundary representation are concatenated as input and the feature vectors of the different categories are obtained. Then, the previous outcome is handled with a self-attention mechanism and the feature expression combined with semantic information is extracted. Finally, the contextual enhancement representation is generated by integrating the semantic feature expression and the deep network features.
3.2. Boundary-Constrained Module
The boundary-constrained module is the critical part of the whole boundary branch. As shown in
Figure 2, there are two inputs to this module: the first is a highest resolution feature map inside the stage of the baseline, the other is the previous BCM output.
Given a high-resolution input feature map
, we extract the dependencies of the internal channels of the feature maps through the global average pooling and obtain the result
. The channel
c in
could be formalized as
Next, two full-connection layers are used for adaptive calibration so that the network can learn the interaction between each channel. The first connection layer is composed of a linear layer and a ReLU function, and the second is composed of a linear layer and a sigmoid function. The related process can be written as
Here, denotes sigmoid function, denotes ReLU function, means linear layer , means linear layer , and r is the compression factor, which is used to reduce the amount of calculation with a default setting of 4.
After passing through the full-connection layers, we obtain the corresponding global feature expression
and then utilize it to perform pointwise multiplication with the previous BCM output
and obtain high-resolution representations. Finally, we concatenate the initial input feature map with the high-resolution representations and gain the BCM output
. The whole process can be defined as
where
denotes matrix pointwise operation,
denotes concatenation of channels.
The BCM makes full use of the high-resolution feature representation of HRNet. The high-resolution feature maps have richer boundary and texture information, and the receptive field gradually increases with the continuous convolution operations. If we want to supervise the network training with boundary information, it is practical to do the extraction in high-resolution feature maps.
3.3. Context-Enhanced Module
The context-enhanced module (CEM) is designed with a self-attention mechanism and comprises many mathematical operations. As shown in
Figure 3, the CEM is composed of three portions as follows: contextual feature representation (CFR), semantic attention extraction (SAE) and contextual enhancement representation (CER).
First, the module input is processed with 1 × 1 Conv of quantity K and reshaped as
. Simultaneously the module input is also managed with 1 × 1 Conv of quantity C (equal to the total number of categories) and the distribution map
is obtained by matrix reshape and transpose operation. Then the above outputs are handled with matrix multiplication, and we denote the result as contextual feature representation
. The
mth category feature vector
can be formalized as
where the
means the feature vector of the
ith pixel in
,
is the relation between the
ith pixel and the
mth category,
F denotes the transfer function, and
H and
W are the length and width of the feature map.
- 2.
Semantic Attention Extraction
Similar to [
41,
42], we adopt self-attention to perform semantic attention extraction. The Query matrix is calculated from the deep feature maps of the network and reshaped as
, in which the corresponding feature expression vector size of each pixel is also K. The Key matrix
and the Value matrix
are further generated by 1 × 1 Conv-BN-ReLU with contextual feature representation that is derived from the previous step. While calculating the attention weight of a single pixel between different categories, we also use the softmax function to do the normalization. The related process can be written as
Here,
denotes the Query vector of the
ith pixel
,
denotes the Key vector of the
jth category
, and
means the semantic attention weight matrix. Then we utilize
to do matrix multiplication with the Value matrix, which aims to add weights on the Value vector of different categories and obtain the semantic attention extraction
. The corresponding formula is
where
denotes the Value vector of the
jth category
.
- 3.
Contextual Enhancement Representation
After gaining the semantic attention extraction, we concatenate it with the deep network feature, which comes from the initial module input to better train our network. The process can be defined as
Here, both and denote BN-ReLU operation, denotes 1 × 1 Conv, and denotes concatenation of channels.
3.4. Multi-Loss Function
As mentioned above, the boundary segmentation result originates from the boundary branch and calculates the corresponding boundary loss with the boundary ground truth. Meanwhile, the boundary ground truth is extracted from the image ground truth by Sobel operator. The specific process is as follows: First, the original image ground truth is processed by Sobel operators, and the gradient images corresponding X direction and Y direction are obtained, respectively. Then these two gradient images are weighted and merged into the overall gradient image. The final boundary ground truth is gained after the binarization of the overall gradient image.
We adopt a binary cross-entropy function to compute the boundary loss. The related formula can be written as
where
is the one-hot vector and
,
means that the pixel
is the boundary pixel.
denotes the probability distribution of pixels classified as boundary in the image, and
represents the probability that pixel
is a boundary pixel.
The original image segmentation loss is calculated by the multi-classification cross-entropy function and can be defined as
Here, is the one-hot vector and . means that the pixel belongs to the cth category. denotes the probability distribution of the pixel and represents the probability that pixel belongs to the cth category. C denotes the number of categories.
The total loss is obtained by adding the image loss
and the boundary loss
which is weighted by the factor
. The related formula is as follows
The default setting of is 0.2.
4. Experiment
In this section, the datasets are first introduced and then the experiment settings and the evaluation metrics are elaborated. Finally, the experimental results for the ISPRS Vahingen and Potsdam benchmarks are analyzed.
4.1. Datasets
We performed experiments on the ISPRS 2D semantic benchmark datasets, including the Vahingen dataset and the Potsdam dataset [
43]. Both datasets are typical and are always used as the benchmark datasets in remote sensing image segmentation. They consist of six ground categories with different labeled color, including impervious surfaces (white), building (blue), low vegetation (cyan), tree (green), car (yellow), and cluster (red).
Figure 4 shows the overall view of the two datasets.
Potsdam: There are 38 high-resolution images of dimensions with 5 cm ground sampling distance (GSD). Each image has three data formats, including IRRG, RGB, RGBIR—we only employ the IRRG images. Each image also has the corresponding ground truth and digital surface model (DSM)—we only use the ground truth. The same as the ISPRS 2-D semantic labeling contest, we use 24 images for training and validation—the remaining 14 images are only used for testing. Considering the limitation in GPU memory, we crop the image to slices with a size of pixels, each slice overlapped with pixels. The ratio of the training set to the validating set is . Finally, we obtain 10,156 slices for training, 2540 slices for validation, and 7406 slices for testing.
Vahingen: There are 33 high-resolution images with 9 cm ground sampling distance of sizes ranging from to . All the images are in IRRG data format with the corresponding ground truth and DSM. The same as the ISPRS 2D semantic labeling contest, we employ 16 images for training and validation—the remaining 17 images are kept only for testing. We crop the image to slices of size , each slice overlapped with pixels. The ratio between the training set and the validation set is also . In the end, we obtain 3540 slices for training, 886 slices for validation and 5074 slices for testing.
We apply the ground truth with eroded boundaries to evaluate the model performance.
4.2. Experiment Settings and Evaluation Metrics
The HBCNet was constructed under the PyTorch deep-learning framework with a Pycharm compiler and used the pretrained HRNet_w48 as the network baseline. All the experiments were conducted on a single NVIDIA RTX 3090 GPU (24 GB RAM). The stochastic gradient descent with momentum (SGDM) optimizer was set to guide the optimization. The initial learning rate was 0.005 and the momentum was 0.9. A poly learning rate policy was adopted to adjust the learning rate during the network training. The batch size was 8 and the total number of training epochs was 200. In terms of data augmentation, we only employed random vertical and horizontal flip, and random rotation with specified angles
. In addition, we applied the test-time augmentation (TTA) method during the inference process, which included multi-scale input and transpose operations. All the settings are detailed in
Table 1.
The evaluation metrics to measure the performance on the two datasets were the same, including overall accuracy (OA), F1 score, m-F1 (mean F1 score), intersection over union (IoU), mean intersection over union (mIoU), precision (P), and recall (R). The corresponding calculation formulas are as follows
Here, TP, TN, FP, FN denote true positive, true negative, false positive and false negative number of pixels, respectively, in the confusion matrix.
Figure 5 shows the variation in the evaluation metrics (m-F1, OA, mIoU) and loss during the training phase with 200 epochs for the Potsdam validation dataset.
4.3. Experiment Results
4.3.1. Results for the Vahingen Dataset
Table 2 shows the experimental results for HBCNet and other models in the published paper for the Vahingen dataset. The results of some methods can be found on the official website of ISPRS 2D semantic labeling contest [
44], including UFMG_4 [
45], CVEO [
17], CASIA2 [
46] and HUSTW [
47]. Based on the original paper, we selected the dilated ResNet-101 [
48] as the baseline to train some networks, which consisted of FCN [
49], UNet [
4], EncNet [
33], PSPNet [
8], DANet [
35] and Deeplabv3+ [
11]. The corresponding super parameters and image size used in network training were the same as for HBCNet. In
Table 1, the values in bold are the best and the values underlined are the second best. It is obvious that the HBCNet far outperformed the other models, achieving the highest m-F1 of 91.32%, OA of 91.72% and mIoU of 84.21%. An improvement of 0.72% in mIoU and of 0.36% in m-F1 compared with the second-best methods was observed. The F1-score for building was also the highest among the ground categories.
Figure 6 demonstrates qualitatively the partial inference results of HBCNet and other models on the test dataset.
FCN had a good segmentation effect on large-scale objects, such as buildings, but it was not sensitive to details, and there were many noise points. UNet adopted the skip connection to integrate the shallow and the deep feature information, making up for the loss of details to some extent. Compared with the two models above, Deeplabv3+ and DANet achieved better effects. The former obtained a larger receptive field through atrous spatial pyramid pooling, and the latter employed channel and spatial attention mechanisms to capture more context feature information. However, it is clear from
Figure 6 that some buildings and trees had shadows and were intertwined with impervious surfaces, and that the above models often generated errors when dealing with such cases. HBCNet introduced boundary information for supervision in the training process and achieved the best result. While learning ground feature information, it also combined image boundary features for feedback and then enhanced the model anti-interference capability to shadows and other external factors.
4.3.2. Results for the Potsdam Dataset
Table 3 displays the results for HBCNet and the other networks for the Potsdam dataset. Related results for UFMG_4 [
45], CVEO [
17], CASIA2 [
46] and HUSTW [
47] can be found on the official website [
50]. It was evident that HBCNet produced positive results. The evaluation metrics for m-F1 and mIoU surpassed those of the other methods. There was a
improvement in mIoU and a
improvement in m-F1 compared with the second-best methods. Moreover, the F1-scores of HBCNet for impervious surfaces, tree and car were also the best.
Figure 7 presents a comparison of partial inference results for HBCNet and the other models. Compared to the original images, the trees and grassland are staggered and the ground color is close to that of the grassland. During the actual segmentation process, UNet and other models often produce errors and the boundary accuracy among different ground categories needs to be reinforced. HBCNet not only introduces boundary information, but also enhances the semantic correlation between pixels of the same category with the context-enhanced module. The contextual representation of the same category has been advanced and has alleviated the problem of high intra-class variance and low inter-class variance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}