
MD3: Model-Driven Deep Remotely Sensed Image Denoising

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
- We propose a novel sparse coding denoising strategy, namely model-driven deep denoising (MD), for the pursuit of pleasing denoising performance efficiently.
- A learnable iterative soft thresholding algorithm (LISTA) is proposed for pursing the solution of sparse coding coefficient, while a lightweight residual network for learning a dictionary.
- The quantitative and qualitative results of experiments on both synthetic and real-life remote sensing images validate that the proposed MD approach is effective and even outperforms the state-of-the-art methods.
2. Related Works
2.1. Sparse-Model-Based Handle-Crafted Image Priors
2.2. Deep Neural Network
2.3. Deep Unfolding
3. Model-Driven Deep Denoising
3.1. MD Model Generation
3.2. MD Model Optimization
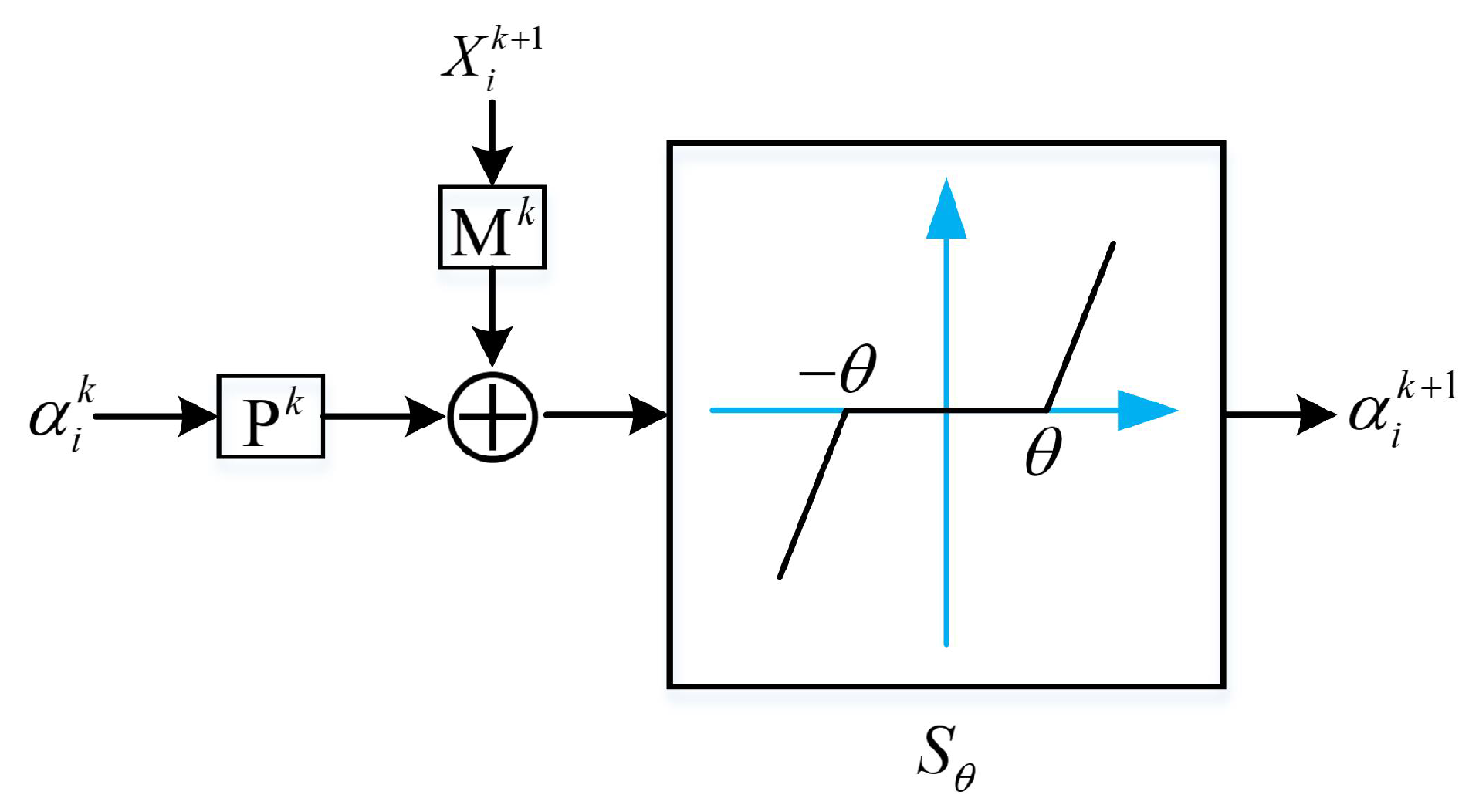
3.2.1. Solving x
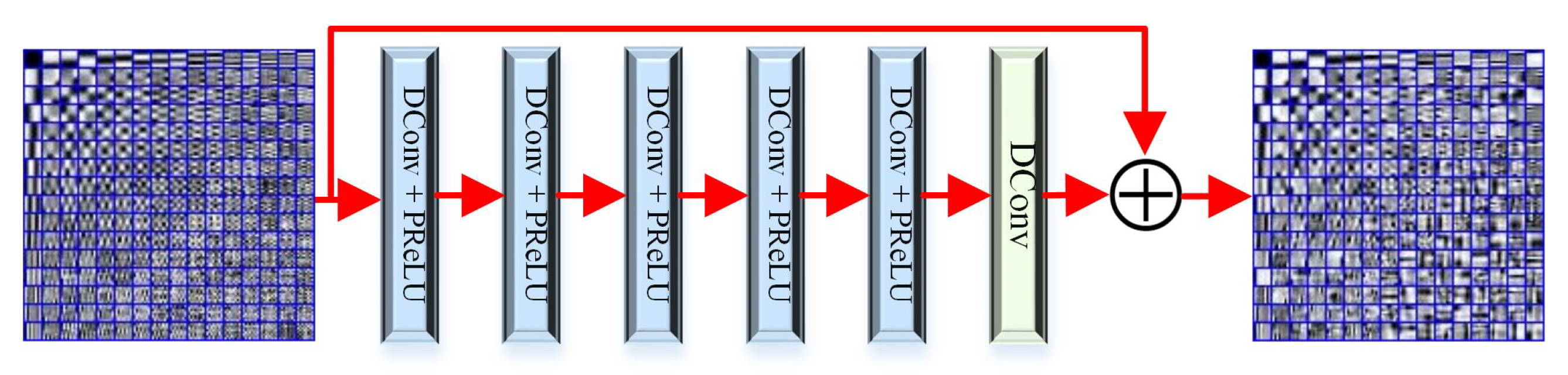
3.2.2. Solving and D
- For sparse coding : Equation (9a) is a restoration task for from , which can be rewritten as
- For dictionary D: with the aid of the half-quadratic splitting (HQS) algorithm due to its simplicity and fast convergence in many applications. Equation (9b) can be solved by inducing an auxiliary variable to convert the constrained problem (9b) into an unconstrained one:
4. Experimental Results and Analysis
4.1. Experimental Preparation
4.2. Analysis of Convergence and Intermediate Results
4.3. Experiments on the Synthetic RSI Images
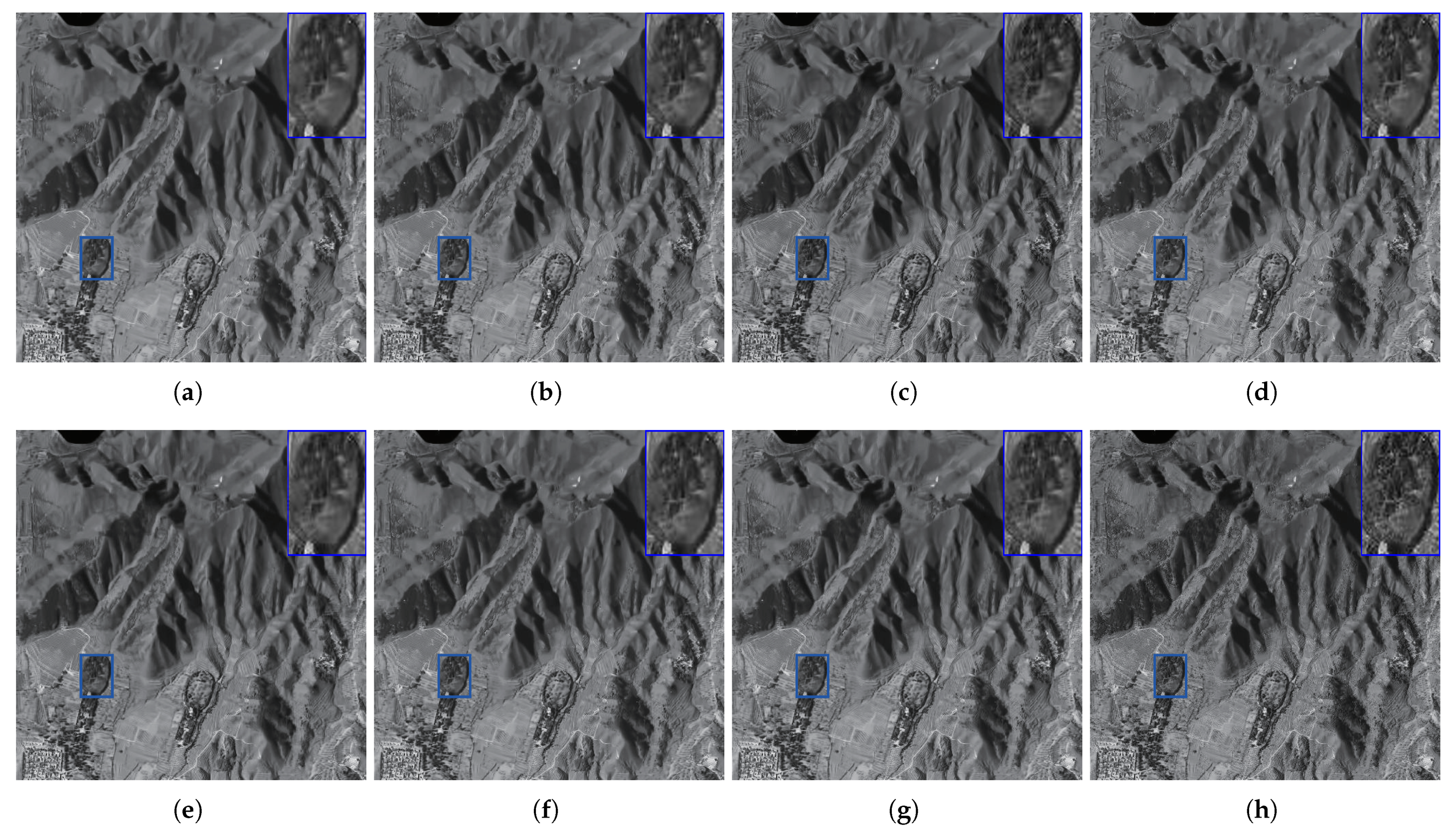
4.4. Experiments on Real-World RSI Images
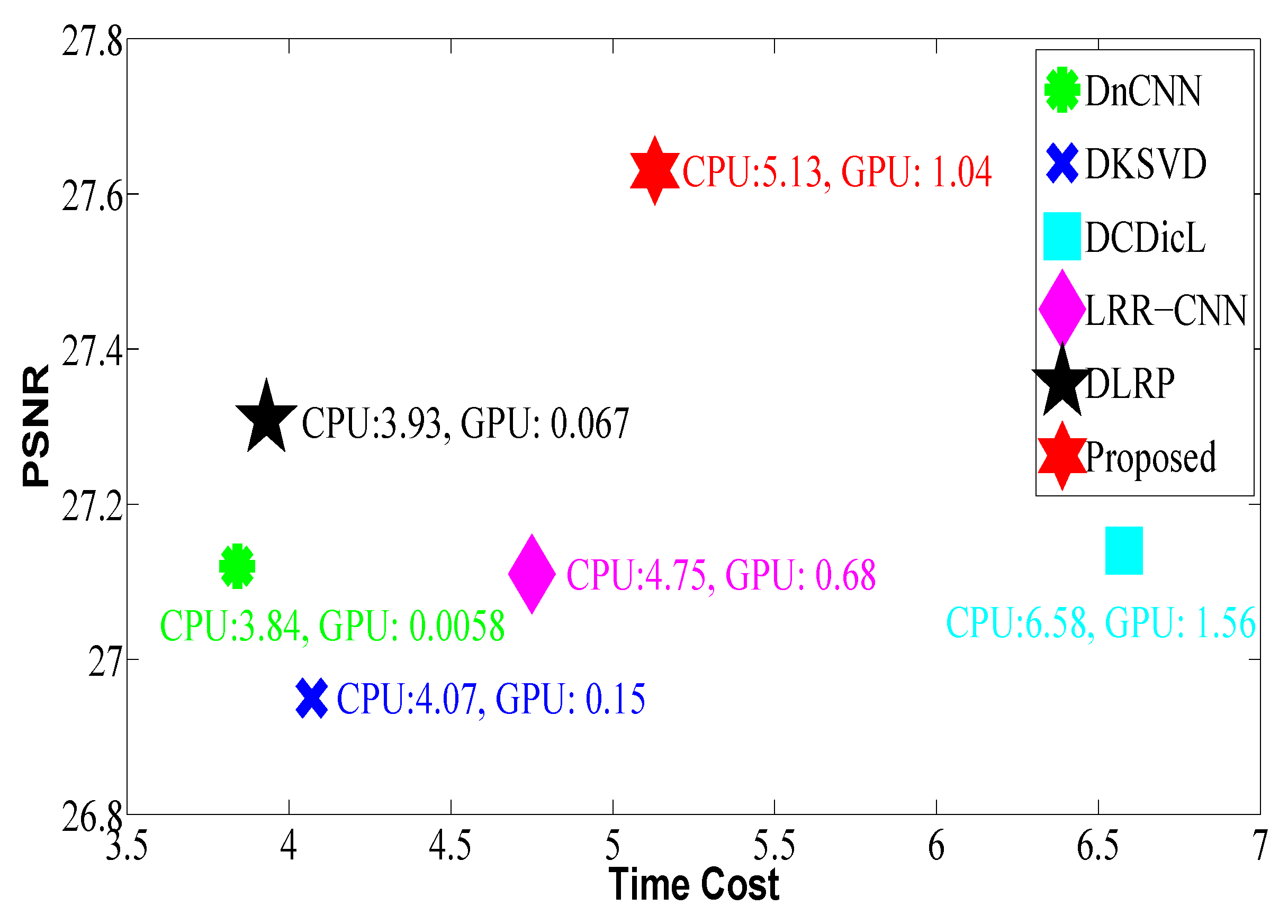
4.5. Computational Complexity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Zhang, Y.; Zhu, Z. Error-tolerant deep learning for remote sensing image scene classification. IEEE Trans. Cybern. 2021, 51, 1756–1768. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, Y. A new paradigm of remote sensing image interpretation by coupling knowledge graph and deep learning. Geomatics Inf. Sci. Wuhan Univ. 2022, 47, 1176–1190. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, Y.; Li, Q.; Zhang, T.; Sang, N.; Hong, H. Progressive dual-domain filter for enhancing and denoising optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 759–763. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, M.; Yan, L.; Zhao, X.; Li, Y.; Zhong, S. Toward universal stripe removal via wavelet-based deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2880–2897. [Google Scholar] [CrossRef]
- Rasti, B.; Chang, Y.; Dalsasso, E.; Denis, L.; Ghamisi, P. Image restoration for remote sensing: Overview and toolbox. arXiv 2021, arXiv:2107.00557. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, Y.; Li, Q.; Li, X.; Zhang, T.; Sang, N.; Hong, H. Joint analysis and weighted synthesis sparsity priors for simultaneous denoising and destriping optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6958–6982. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Rudin, L.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Physica D 2007, 60, 259–268. [Google Scholar] [CrossRef]
- Bougleux, S.; Peyré, G.; Cohen, L. Non-local regularization of inverse problems. Inverse Probl. Imaging 2011, 5, 511–530. [Google Scholar]
- Zuo, W.; Zhang, L.; Song, C.; Zhang, D. Texture enhanced image denoising via gradient histogram preservation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhu, H.; Cui, C.; Deng, L.; Cheung, R.; Yan, H. Elastic Net Constraint based Tensor Model for High-order Graph Matching. IEEE Trans. Cybern. 2020, 51, 4062–4074. [Google Scholar] [CrossRef]
- Li, Z.; Malgouyres, F.; Zeng, T. Regularized non-local total variation and application in image restoration. J. Math. Imaging Vis. 2017, 59, 296–317. [Google Scholar] [CrossRef]
- Zhang, H.; Tang, L.; Fang, Z.; Xiang, C.; Li, C. Nonconvex and nonsmooth total generalized variation model for image restoration. Signal Process. 2018, 143, 69–85. [Google Scholar] [CrossRef]
- Liu, J.; Ma, R.; Zeng, X.; Liu, W.; Wang, M.; Chen, H. An efficient non-convex total variation approach for image deblurring and denoising. Appl. Math. Comput. 2021, 397, 125977. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, Q.; Lou, S.; Hou, Y. Wavelet-based total variation and nonlocal similarity model for image denoising. IEEE Signal Process. Lett. 2017, 24, 877–881. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Qiao, Y.; Xu, G.; Deng, L.; Yu, F. DSPNet: A lightweight dilated convolution neural networks for spectral deconvolution with self-paced learning. IEEE Trans. Ind. Inform. 2019, 16, 7392–7401. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 950–965. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [Green Version]
- Dong, W.; Shi, G.; Li, X.; Ma, Y.; Huang, F. Compressive sensing via nonlocal low-rank regularization. IEEE Trans. Image Process. 2014, 23, 3618–3632. [Google Scholar] [CrossRef]
- Yang, H.; Lu, J.; Zhang, H.; Luo, Y.; Lu, J. Field of experts regularized nonlocal low rank matrix approximation for image denoising. J. Comput. Appl. Math. 2022, 412, 114244. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, C. Nonlocal low-rank regularized tensor decomposition for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5174–5189. [Google Scholar] [CrossRef]
- Liu, N.; Li, W.; Tao, R.; Du, Q.; Chanussot, J. Multi-graph-based low-rank tensor approximation for Hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5530314. [Google Scholar]
- Donoho, D.; Gavish, M.; Montanari, A. The phase transition of matrix recovery from gaussian measurements matches the minimax mse of matrix denoising. Proc. Natl. Acad. Sci. USA 2013, 110, 8405–8410. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Xie, Y.; Gu, S.; Liu, Y.; Zuo, W.; Zhang, W.; Zhang, L. Weighted schatten p-norm minimization for image denoising and background subtraction. IEEE Trans. Image Process. 2016, 25, 4842–4857. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Li, Q.; Fang, H.; Zhang, T.; Sang, N. Iterative weighted nuclear norm for X-ray angiogram image denoising. Signal Image Video Process. 2017, 11, 1445–1452. [Google Scholar] [CrossRef]
- Huang, T.; Dong, W.; Xie, X.; Shi, G.; Bai, X. Mixed noise removal via laplacian scale mixture modeling and nonlocal low-rank approximation. IEEE Trans. Image Process. 2017, 26, 3171–3186. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, L.; He, W.; Zhang, L. Hyperspectral image denoising with total variation regularization and nonlocal low-rank tensor decomposition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3071–3084. [Google Scholar] [CrossRef]
- Zhu, H.; Ni, H.; Liu, S.; Xu, G.; Deng, L. Tnlrs: Target-aware non-local low-rank modeling with saliency filtering regularization for infrared small target detection. IEEE Trans. Image Process. 2020, 29, 9546–9558. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Huang, X.; Gao, Z.; Li, S.; He, T.; Zhang, Y. Mfvnet: Deep adaptive fusion network with multiple field-of-views for remote sensing image semantic segmentation. Sci. China Inf. Sci. 2022. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, J.; Xu, G.; Deng, L. Tensor field graph-cut for image segmentation: A non-convex perspective. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1103–1113. [Google Scholar] [CrossRef]
- Kong, X.; Zhao, Y.; Xue, J.; Chan, J.C.W.; Zang, J. Hyperspectral image denoising based on nonlocal low-rank and TV regularization. Remote Sens. 2020, 12, 1956. [Google Scholar] [CrossRef]
- Li, Y.; Kong, D.; Zhang, Y.; Tan, Y.; Chen, L. Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2021, 179, 145–158. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, S.; Deng, L.; Li, Y.; Xiao, F. Infrared Small Target Detection via Low Rank Tensor Completion with Top-Hat Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1004–1016. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain knowledge-guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification. ISPRS J. Photogramm. Remote Sens. 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representation over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Bristow, H.; Eriksson, A.; Lucey, S. Fast convolutional sparse coding. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 391–398. [Google Scholar]
- Cardona, C.G.; Wohlberg, B. Convolutional dictionary learning: A comparative review and new algorithms. IEEE Trans. Comput. Imaging 2018, 4, 366–381. [Google Scholar] [CrossRef] [Green Version]
- Rey-Otero, I.; Sulam, J.; Elad, M. Variations on the CSC model. IEEE Trans. Image Process. 2020, 68, 519–528. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Z.; Li, Q.; Zhang, T.; Sang, N.; Hong, H. Iterative weighted sparse representation for X-ray cardiovascular angiogram image denoising over learned dictionary. IET Image Process. 2018, 12, 254–261. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Zhu, H.; Peng, H.; Xu, G.; Deng, L.; Cheng, Y.; Song, A. Bilateral weighted regression ranking model with spatial-temporal correlation filter for visual tracking. IEEE Trans. Multimed. 2021, 24, 2098–2111. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, L.; Zhang, D. A trilateral weighted sparse coding scheme for real-world image denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 21–38. [Google Scholar]
- Peng, C.; Liu, Y.; Chen, Y.; Wu, X.; Cheng, A.; Kang, Z.; Chen, C.; Cheng, Q. Hyperspectral image denoising using non-convex local low-rank and sparse separation with spatial-spectral total variation regularization. arXiv 2022, arXiv:2201.02812. [Google Scholar]
- Shi, M.; Zhang, F.; Wang, S.; Zhang, C.; Li, X. Detail preserving image denoising with patch-based structure similarity via sparse representation and svd. Comput. Vis. Image Underst. 2021, 206, 103173. [Google Scholar]
- Ou, Y.; Swamy, M.N.S.; Luo, J.; Li, B. Single image denoising via multi-scale weighted group sparse coding. Signal Process. 2022, 200, 108650. [Google Scholar] [CrossRef]
- Sun, L.; Dong, W.; Li, X.; Wu, J.; Li, L.; Shi, G. Deep maximum a posterior estimator for video denoising. Int. J. Comput. Vis. 2021, 129, 2827–2845. [Google Scholar] [CrossRef]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Jia, X.; Liu, S.; Feng, X.; Zhang, L. FOCNet: A fractional optimal control network for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6054–6063. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W. Image denoising using deep cnn with batch renormalization. Neural Netw. 2017, 121, 461–473. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Chen, H.; Shen, C. Memory-efficient hierarchical neural architecture search for image denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3657–3666. [Google Scholar]
- Mou, C.; Zhang, J.; Fan, X.; Liu, H.; Wang, R. COLA-Net: Collaborative attention network for image restoration. IEEE Trans. Multimed. 2021, 24, 1366–1377. [Google Scholar] [CrossRef]
- Pan, E.; Ma, Y.; Mei, X.; Fan, F.; Huang, J.; Ma, J. SQAD: Spatial-spectral quasi-attention recurrent network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Ng, M.K.; Zhuang, L.; Gao, L.; Zhang, B. Nonlocal self-similarity-based hyperspectral remote sensing image denoising with 3-D convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Jia, X.; Peng, Y.; Ge, B.; Li, J.; Liu, S.; Wang, W. A multi-scale dilated residual convolution network for image denoising. Neural Process. Lett. 2022. [Google Scholar] [CrossRef]
- Dong, X.; Lin, J.; Lu, S.; Wang, H.; Li, Y. Multiscale spatial attention network for seismic data denoising. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Xu, J.; Deng, X.; Xu, M. Revisiting convolutional sparse coding for image denoising: From a multi-scale perspective. IEEE Signal Process. Lett. 2022, 29, 1202–1206. [Google Scholar] [CrossRef]
- Zhang, K.; Gool, L.-V.; Timofte, R. Deep unfolding network for image super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3217–3226. [Google Scholar]
- Meinhardt, T.; Moeller, M.; Hazirbas, C.; Cremers, D. Learning proximal operators: Using denoising networks for regularizing inverse imaging problems. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1799–1808. [Google Scholar]
- Sreter, H.; Giryes, R. Learned convolutional sparse coding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2191–2195. [Google Scholar]
- Zhu, H.; Zhang, J.; Xu, G.; Deng, L. Balanced ring top-hat transformation for infrared small-target detection with guided filter kernel. IEEE Trans. Aerosp. Electron. Syst. 2021, 56, 3892–3903. [Google Scholar] [CrossRef]
- Scetbon, M.; Elad, M.; Milanfar, P. Deep K-SVD Denoising. IEEE Trans. Image Process. 2021, 30, 5944–5955. [Google Scholar] [CrossRef]
- Simon, D.; Elad, M. Rethinking the csc model for natural images. Adv. Neural Inf. Process. Syst. 2019, 32, 2274–2284. [Google Scholar]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising prior driven deep neural network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 40, 2305–2318. [Google Scholar] [CrossRef] [Green Version]
- Fu, X.; Zha, Z.J.; Wu, F.; Ding, X.; Paisley, J. Jpeg artifacts reduction via deep convolutional sparse coding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2501–2510. [Google Scholar]
- Bertocchi, C.; Chouzenoux, E.; Corbineau, M.C.; Pesquet, J.C.; Prato, M. Deep unfolding of a proximal interior point method for image restoration. Inverse Probl. 2020, 36, 034005. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Yong, H.; Zhang, L. Deep convolutional dictionary learning for image denoising. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Sun, H.; Liu, M.; Zheng, K.; Yang, D.; Li, J.; Gao, L. Hyperspectral image denoising via low-rank representation and CNN denoiser. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 716–728. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Z.; Zhu, Z.; Zhang, Y.; Fang, H.; Shi, Y.; Zhang, T. DLRP: Learning deep low-rank prior for remotely sensed image denoising. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, W.; Zhu, Q.; Qi, N.; Chen, D. Deep sparse representation based image restoration with denoising prior. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6530–6542. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 27–30. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- MODIS Data. Available online: https://modis.gsfc.nasa.gov/data/ (accessed on 30 January 2018).
- A Freeware Multispectral Image Data Analysis System. Available online: https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html (accessed on 30 January 2018).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Huang, Z.; Wang, L.; An, Q.; Zhou, Q.; Hong, H. Learning a contrast enhancer for intensity correction of remotely sensed images. IEEE Signal Process. Lett. 2022, 29, 394–398. [Google Scholar] [CrossRef]
- Pyatykh, S.; Hesser, J.; Zheng, L. Image noise level estimation by principal component analysis. SIAM J. Imaging Sci. 2013, 22, 687–699. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, Z.; An, Q.; Wang, Z.; Zhou, T.; Alshomrani, A. Luminance learning for remotely sensed image enhancement guided by weighted least squares. IEEE Geosci. Remote Sens. Lett. 2021, 22, 1–5. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Noise Level | Noise Level | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MODIS- | Hyper-WDCM | Multi-WDC | Ave. | MODIS- | Hyper-WDCM | Multi-WDC | Ave. | |||||||||||
| A1 | A2 | A3 | T1 | T2 | T3 | A1 | A2 | A3 | T1 | T2 | T3 | |||||||
| NCSR | 28.9 | 28.81 | 29.69 | 30.37 | 35.83 | 34.67 | 28.53 | 31.03 | 30.98 | 27.5 | 27.53 | 28.07 | 29 | 34.61 | 33.41 | 27.15 | 30.34 | 29.7 |
| WSSR | 29.58 | 29.32 | 30.47 | 31.21 | 36.48 | 35.32 | 29.62 | 32.63 | 31.85 | 28.22 | 28.2 | 28.94 | 29.64 | 35.27 | 34 | 27.83 | 31.4 | 30.44 |
| DnCNN | 29.39 | 29.24 | 30.37 | 31.02 | 36.32 | 35.19 | 29.5 | 32.61 | 31.71 | 28.06 | 28.06 | 28.67 | 29.44 | 35.04 | 33.9 | 27.59 | 31.1 | 30.23 |
| DKSVD | 29.36 | 29.17 | 30.22 | 30.77 | 36.21 | 35.17 | 29.49 | 32.43 | 31.6 | 27.96 | 27.94 | 28.66 | 29.41 | 35.03 | 33.85 | 27.51 | 31.04 | 30.18 |
| DCDicL | 29.45 | 29.34 | 30.33 | 30.82 | 36.41 | 35.25 | 29.52 | 32.51 | 31.7 | 28.07 | 28.06 | 28.79 | 29.55 | 35.19 | 33.97 | 27.7 | 31.19 | 30.32 |
| LRR-CNN | 29.42 | 29.38 | 30.54 | 30.89 | 36.48 | 35.27 | 29.37 | 32.57 | 31.74 | 28.11 | 28.11 | 28.87 | 29.57 | 35.24 | 33.99 | 27.75 | 31.33 | 30.37 |
| DLRP | 29.58 | 29.5 | 30.56 | 31.09 | 36.61 | 35.38 | 29.65 | 32.65 | 31.88 | 28.3 | 28.25 | 29 | 29.69 | 35.29 | 34.15 | 28.17 | 31.44 | 30.54 |
| Proposed | 29.76 | 29.72 | 30.79 | 31.25 | 36.78 | 35.63 | 29.79 | 32.87 | 32.06 | 28.54 | 28.61 | 29.37 | 29.9 | 35.66 | 34.54 | 28.44 | 31.73 | 30.85 |
| Noise level | Noise level | |||||||||||||||||
| NCSR | 26.87 | 26.95 | 27.08 | 28.18 | 33.86 | 32.7 | 25.99 | 29.55 | 28.9 | 26.03 | 26.23 | 26.08 | 27.55 | 33.25 | 31.88 | 24.8 | 28.53 | 28.04 |
| WSSR | 27.2 | 27.28 | 27.68 | 28.69 | 34.41 | 33.07 | 26.77 | 30.33 | 29.43 | 26.44 | 26.66 | 26.82 | 28.07 | 33.75 | 32.35 | 25.65 | 29.48 | 28.65 |
| DnCNN | 27.12 | 27.2 | 27.56 | 28.51 | 34.23 | 33.02 | 26.6 | 30.06 | 29.29 | 26.14 | 26.51 | 26.57 | 27.96 | 33.45 | 32.22 | 25.53 | 29.16 | 28.44 |
| DKSVD | 26.95 | 27.04 | 27.52 | 28.47 | 34.21 | 33.01 | 26.72 | 29.92 | 29.32 | 26.15 | 26.4 | 26.57 | 27.78 | 33.42 | 32.2 | 25.36 | 29.06 | 28.37 |
| DCDicL | 27.14 | 27.24 | 27.61 | 28.64 | 34.38 | 33.04 | 26.77 | 30.09 | 29.36 | 26.2 | 26.63 | 26.65 | 28.1 | 33.6 | 32.29 | 25.55 | 29.25 | 28.66 |
| LRR-CNN | 27.11 | 27.25 | 27.67 | 28.67 | 34.39 | 33.07 | 26.74 | 30.11 | 29.38 | 26.35 | 26.65 | 26.82 | 28.03 | 33.74 | 32.3 | 25.64 | 29.39 | 28.62 |
| DLRP | 27.31 | 27.32 | 27.75 | 28.81 | 34.47 | 33.16 | 26.81 | 30.32 | 29.49 | 26.47 | 26.69 | 26.83 | 28.36 | 33.79 | 32.36 | 25.7 | 29.52 | 28.72 |
| Proposed | 27.63 | 27.69 | 28.17 | 29.14 | 35.01 | 33.69 | 27.03 | 30.68 | 29.88 | 26.75 | 26.95 | 27.11 | 28.37 | 34 | 32.86 | 26 | 29.7 | 28.97 |
| Noise level | Noise level | |||||||||||||||||
| NCSR | 25.36 | 25.48 | 25.32 | 27.06 | 32.36 | 31.37 | 24.23 | 28.05 | 27.4 | 24.95 | 25.07 | 25.04 | 26.53 | 32.02 | 30.67 | 23.62 | 27.54 | 26.93 |
| WSSR | 25.85 | 26.14 | 26.11 | 27.46 | 33.06 | 31.65 | 25.08 | 28.76 | 28.01 | 25.41 | 25.6 | 25.5 | 27 | 32.46 | 31.13 | 24.26 | 28.18 | 27.44 |
| DnCNN | 25.82 | 25.89 | 25.89 | 27.25 | 32.9 | 31.5 | 24.92 | 28.45 | 27.83 | 25.13 | 25.38 | 25.26 | 26.81 | 32.17 | 31.13 | 24.02 | 27.95 | 27.23 |
| DKSVD | 25.65 | 25.77 | 25.86 | 27.24 | 32.69 | 31.48 | 24.94 | 28.39 | 27.75 | 25.08 | 25.29 | 25.18 | 26.72 | 32.11 | 30.88 | 23.89 | 27.71 | 27.11 |
| DCDicL | 25.81 | 25.98 | 25.89 | 27.43 | 32.99 | 31.51 | 25.01 | 28.51 | 27.89 | 25.34 | 25.47 | 25.31 | 26.87 | 32.34 | 31.05 | 24.11 | 28.03 | 27.32 |
| LRR-CNN | 25.83 | 26.01 | 26.08 | 27.44 | 32.99 | 31.57 | 25.04 | 28.65 | 27.95 | 25.37 | 25.41 | 25.49 | 26.93 | 32.36 | 31.11 | 24.21 | 28.07 | 27.37 |
| DLRP | 25.95 | 26.19 | 26.15 | 27.5 | 33.16 | 31.66 | 25.12 | 28.87 | 28.08 | 25.41 | 25.72 | 25.54 | 27.05 | 32.68 | 31.16 | 24.27 | 28.12 | 27.49 |
| Proposed | 26.11 | 26.4 | 26.32 | 27.76 | 33.34 | 32.02 | 25.21 | 29.01 | 28.27 | 25.62 | 25.97 | 25.58 | 27.22 | 32.86 | 31.29 | 24.65 | 28.55 | 27.72 |
| Methods | Noise Level | Noise Level | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MODIS- | Hyper-WDCM | Multi-WDC | Ave. | MODIS- | Hyper-WDCM | Multi-WDC | Ave. | |||||||||||
| A1 | A2 | A3 | T1 | T2 | T3 | A1 | A2 | A3 | T1 | T2 | T3 | |||||||
| NCSR | 0.805 | 0.768 | 0.9108 | 0.8401 | 0.8853 | 0.8801 | 0.8912 | 0.861 | 0.8552 | 0.7549 | 0.6973 | 0.8851 | 0.7692 | 0.8788 | 0.869 | 0.8341 | 0.8287 | 0.8146 |
| WSSR | 0.8272 | 0.7983 | 0.9176 | 0.8482 | 0.908 | 0.8998 | 0.9014 | 0.8647 | 0.8708 | 0.7755 | 0.7192 | 0.8844 | 0.7931 | 0.8892 | 0.8751 | 0.8493 | 0.8385 | 0.828 |
| DnCNN | 0.8127 | 0.7763 | 0.9157 | 0.832 | 0.9084 | 0.8989 | 0.8937 | 0.8619 | 0.8625 | 0.7648 | 0.7178 | 0.8795 | 0.7805 | 0.8893 | 0.874 | 0.8474 | 0.8339 | 0.8234 |
| DKSVD | 0.8225 | 0.7778 | 0.9184 | 0.8428 | 0.9078 | 0.8966 | 0.9003 | 0.8694 | 0.8616 | 0.7508 | 0.6929 | 0.8864 | 0.7791 | 0.89 | 0.8735 | 0.8453 | 0.8234 | 0.8177 |
| DCDicL | 0.8156 | 0.7812 | 0.9153 | 0.8372 | 0.9077 | 0.8998 | 0.8578 | 0.8666 | 0.8655 | 0.7581 | 0.7099 | 0.8831 | 0.7887 | 0.8884 | 0.8755 | 0.8535 | 0.8322 | 0.8237 |
| LRR-CNN | 0.8206 | 0.7866 | 0.9144 | 0.8414 | 0.9094 | 0.8971 | 0.8934 | 0.8696 | 0.8666 | 0.7585 | 0.7122 | 0.8827 | 0.7875 | 0.8914 | 0.8743 | 0.8449 | 0.8361 | 0.8235 |
| DLRP | 0.8267 | 0.7971 | 0.9163 | 0.8475 | 0.9126 | 0.9016 | 0.9067 | 0.8716 | 0.8725 | 0.7717 | 0.7271 | 0.887 | 0.7981 | 0.8919 | 0.8804 | 0.8518 | 0.8381 | 0.8308 |
| Proposed | 0.8386 | 0.7992 | 0.9211 | 0.8517 | 0.9148 | 0.9069 | 0.9093 | 0.8743 | 0.8767 | 0.7952 | 0.7488 | 0.9008 | 0.8172 | 0.9025 | 0.8938 | 0.8723 | 0.8537 | 0.848 |
| Noise level | Noise level | |||||||||||||||||
| NCSR | 0.6482 | 0.6381 | 0.8381 | 0.7268 | 0.8695 | 0.8473 | 0.7952 | 0.7858 | 0.7686 | 0.6286 | 0.5862 | 0.8285 | 0.6825 | 0.8521 | 0.8241 | 0.7484 | 0.7497 | 0.7175 |
| WSSR | 0.7155 | 0.6691 | 0.8535 | 0.7472 | 0.8747 | 0.8578 | 0.8104 | 0.8065 | 0.7918 | 0.6637 | 0.6242 | 0.8248 | 0.7227 | 0.8672 | 0.842 | 0.7698 | 0.7791 | 0.7617 |
| DnCNN | 0.6995 | 0.6515 | 0.8481 | 0.7321 | 0.8744 | 0.8566 | 0.8085 | 0.8025 | 0.7842 | 0.6314 | 0.5962 | 0.8173 | 0.6958 | 0.8623 | 0.8395 | 0.769 | 0.7653 | 0.7471 |
| DKSVD | 0.6837 | 0.642 | 0.8453 | 0.7323 | 0.8732 | 0.8529 | 0.8023 | 0.7895 | 0.7777 | 0.6297 | 0.597 | 0.8155 | 0.6911 | 0.8606 | 0.8383 | 0.758 | 0.7579 | 0.7435 |
| DCDicL | 0.6569 | 0.6636 | 0.8563 | 0.7491 | 0.8755 | 0.854 | 0.8117 | 0.8002 | 0.7834 | 0.6571 | 0.6185 | 0.824 | 0.7161 | 0.8614 | 0.8374 | 0.7658 | 0.7739 | 0.7568 |
| LRR-CNN | 0.7036 | 0.6658 | 0.8563 | 0.7454 | 0.8768 | 0.8573 | 0.8094 | 0.8063 | 0.7901 | 0.6619 | 0.621 | 0.8237 | 0.7171 | 0.8644 | 0.8407 | 0.7692 | 0.7791 | 0.7596 |
| DLRP | 0.7297 | 0.6686 | 0.8533 | 0.759 | 0.8801 | 0.8602 | 0.8113 | 0.8076 | 0.7962 | 0.6645 | 0.626 | 0.8299 | 0.7165 | 0.8627 | 0.8392 | 0.7731 | 0.7803 | 0.7615 |
| Proposed | 0.7352 | 0.6884 | 0.8667 | 0.7708 | 0.8875 | 0.8709 | 0.8178 | 0.8103 | 0.806 | 0.6742 | 0.6319 | 0.8328 | 0.7375 | 0.8698 | 0.8531 | 0.79 | 0.7875 | 0.7721 |
| Noise level | Noise level | |||||||||||||||||
| NCSR | 0.5679 | 0.5436 | 0.7778 | 0.658 | 0.8392 | 0.8181 | 0.7115 | 0.7257 | 0.7052 | 0.5234 | 0.5137 | 0.7474 | 0.6333 | 0.832 | 0.7978 | 0.6597 | 0.6972 | 0.6756 |
| WSSR | 0.617 | 0.5903 | 0.8027 | 0.6945 | 0.8555 | 0.8218 | 0.7316 | 0.7536 | 0.7334 | 0.5764 | 0.5563 | 0.7715 | 0.664 | 0.8432 | 0.8132 | 0.6978 | 0.732 | 0.7068 |
| DnCNN | 0.5842 | 0.5656 | 0.79 | 0.6622 | 0.8483 | 0.8194 | 0.7193 | 0.7405 | 0.7162 | 0.5454 | 0.5249 | 0.7595 | 0.642 | 0.8373 | 0.8055 | 0.6757 | 0.712 | 0.6878 |
| DKSVD | 0.5799 | 0.5483 | 0.7834 | 0.662 | 0.8465 | 0.8222 | 0.7133 | 0.7351 | 0.7113 | 0.5333 | 0.5162 | 0.7593 | 0.6332 | 0.8344 | 0.8056 | 0.6765 | 0.7032 | 0.6827 |
| DCDicL | 0.6203 | 0.5886 | 0.7885 | 0.6888 | 0.8555 | 0.8268 | 0.7335 | 0.7493 | 0.7314 | 0.5847 | 0.5452 | 0.766 | 0.661 | 0.8362 | 0.8078 | 0.6961 | 0.7275 | 0.7031 |
| LRR-CNN | 0.6173 | 0.5899 | 0.7941 | 0.6801 | 0.8498 | 0.8242 | 0.7345 | 0.7535 | 0.7304 | 0.5818 | 0.5601 | 0.771 | 0.6554 | 0.8333 | 0.8057 | 0.6998 | 0.7284 | 0.7044 |
| DLRP | 0.6214 | 0.5896 | 0.7996 | 0.6862 | 0.8556 | 0.8255 | 0.7292 | 0.759 | 0.7333 | 0.585 | 0.5598 | 0.7788 | 0.6663 | 0.8463 | 0.8107 | 0.7022 | 0.7306 | 0.71 |
| Proposed | 0.641 | 0.6064 | 0.8055 | 0.703 | 0.8568 | 0.8345 | 0.7403 | 0.7667 | 0.7443 | 0.6036 | 0.5836 | 0.7832 | 0.6854 | 0.8511 | 0.816 | 0.726 | 0.7471 | 0.7245 |
| Methods | Mountain | City-Wall | Factory | |||
|---|---|---|---|---|---|---|
| QM | NIQE | QM | NIQE | QM | NIQE | |
| NCSR | 18.65 | 4.63 | 16.56 | 7.08 | 33.23 | 5.13 |
| WSSR | 22.72 | 3.61 | 21.05 | 3.57 | 39.35 | 4.09 |
| DnCNN | 21.62 | 3.93 | 20.05 | 5.43 | 37.76 | 4.61 |
| DKSVD | 20.75 | 4.43 | 19.32 | 5.07 | 36.53 | 4.64 |
| DCDicL | 23.5 | 3.77 | 21.48 | 3.61 | 40.36 | 4.31 |
| LRR-CNN | 22.07 | 3.56 | 19.78 | 3.69 | 38.12 | 4.14 |
| DLRP | 22.33 | 3.71 | 19.7 | 4.06 | 38.99 | 3.99 |
| Proposed | 25.34 | 3.5 | 24.46 | 3.42 | 44.19 | 3.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Zhu, Z.; Zhang, Y.; Wang, Z.; Xu, B.; Liu, J.; Li, S.; Fang, H. MD3: Model-Driven Deep Remotely Sensed Image Denoising. Remote Sens. 2023, 15, 445. https://doi.org/10.3390/rs15020445
Huang Z, Zhu Z, Zhang Y, Wang Z, Xu B, Liu J, Li S, Fang H. MD3: Model-Driven Deep Remotely Sensed Image Denoising. Remote Sensing. 2023; 15(2):445. https://doi.org/10.3390/rs15020445
Chicago/Turabian StyleHuang, Zhenghua, Zifan Zhu, Yaozong Zhang, Zhicheng Wang, Biyun Xu, Jun Liu, Shaoyi Li, and Hao Fang. 2023. "MD3: Model-Driven Deep Remotely Sensed Image Denoising" Remote Sensing 15, no. 2: 445. https://doi.org/10.3390/rs15020445
APA StyleHuang, Z., Zhu, Z., Zhang, Y., Wang, Z., Xu, B., Liu, J., Li, S., & Fang, H. (2023). MD3: Model-Driven Deep Remotely Sensed Image Denoising. Remote Sensing, 15(2), 445. https://doi.org/10.3390/rs15020445