Hyperspectral Image Super-Resolution via Nonlocal Low-Rank Tensor Approximation and Total Variation Regularization


Abstract
:1. Introduction
2. Notation and Preliminaries
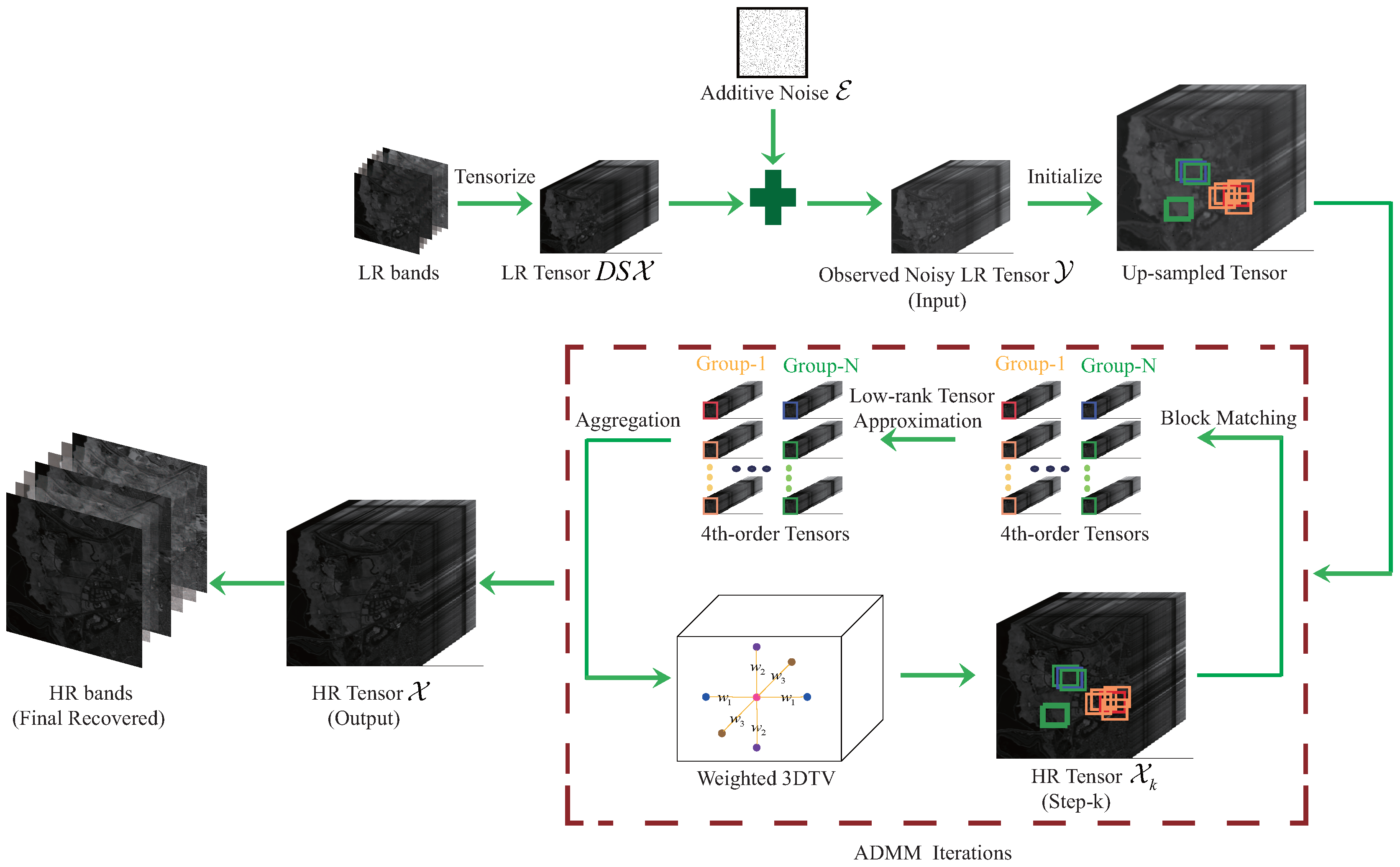
3. HSI Super-Resolution via Nonlocal Low-Rank Tensor Approximation and TV Regularization
3.1. Observation Model
3.2. 3D TV Regularization
3.3. Nonlocal Low-Rank Tensor Approximation
3.4. Proposed Model
4. Optimization Procedure
5. Experimental Study
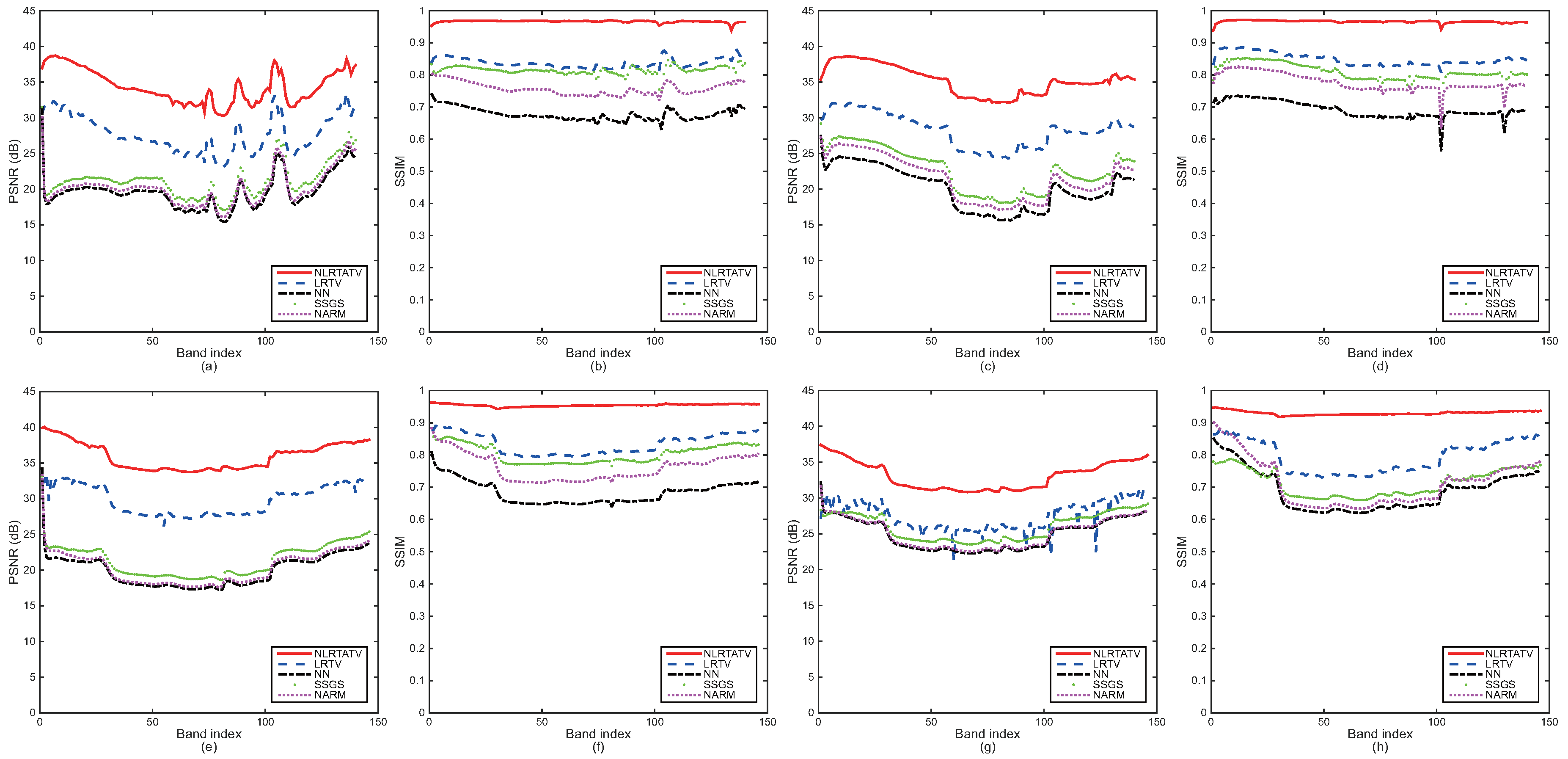
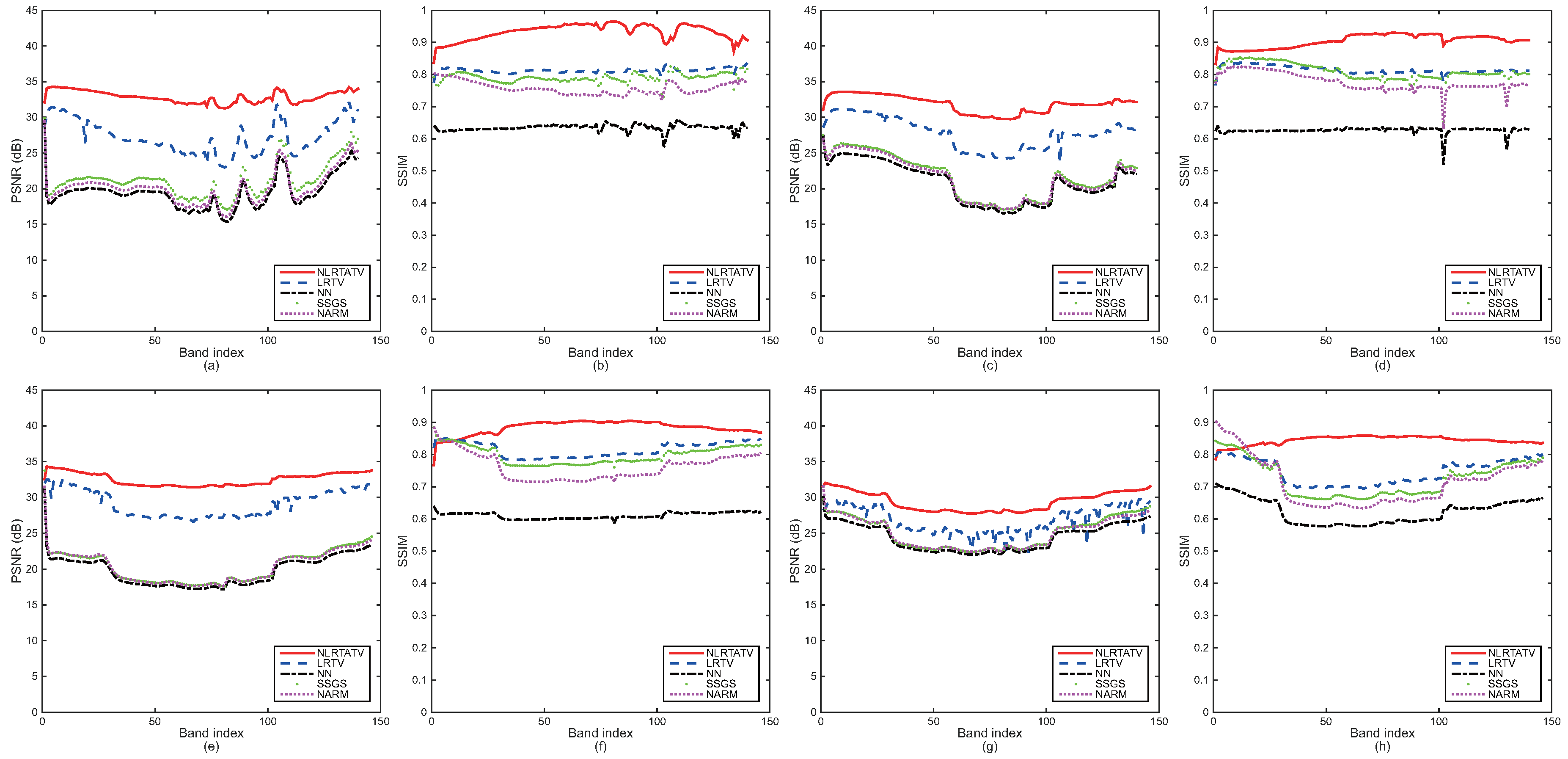
5.1. Quantitative Comparison
5.2. Visual Quality Comparison
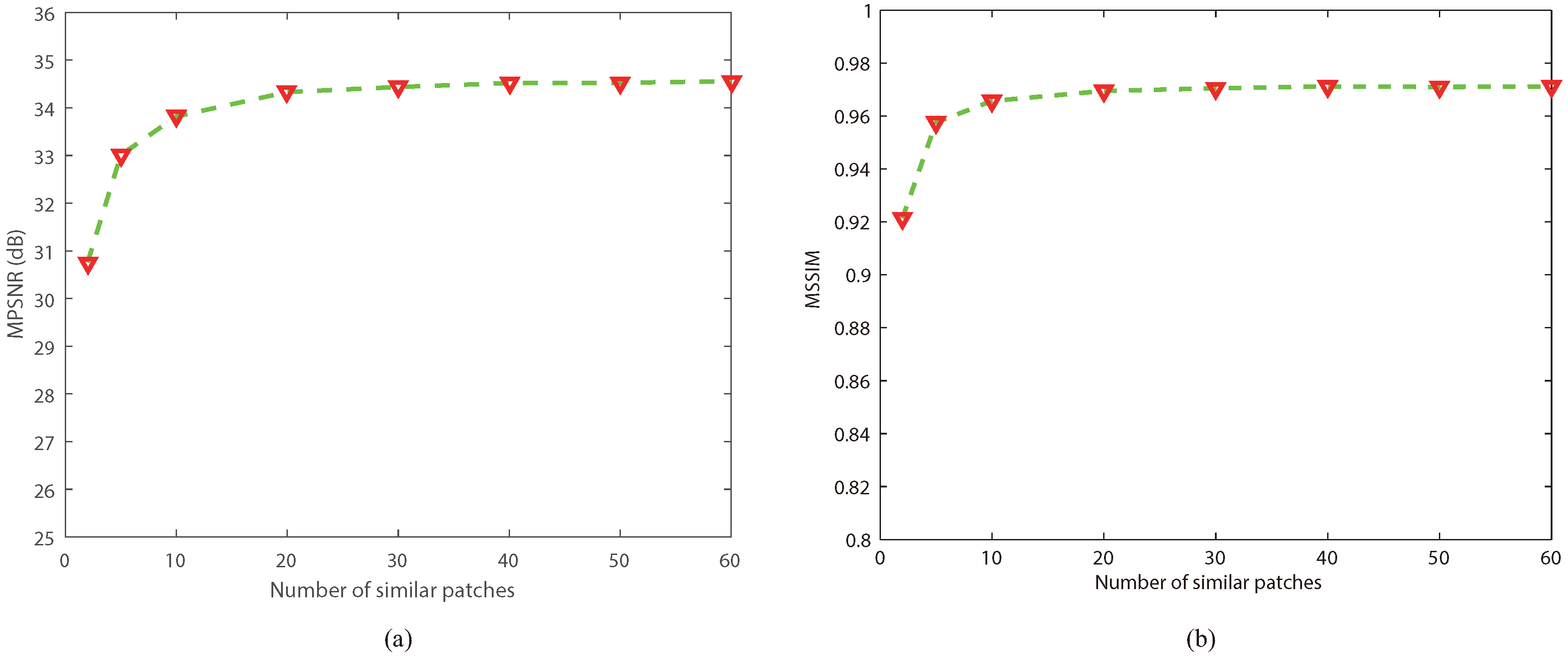
5.3. Analysis of the Parameters
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gu, Y.; Zheng, Y.; Zhang, J. Integration of spatial-spectral information for resolution enhancement in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1347–1357. [Google Scholar]
- Akgun, T.; Altunbasak, Y.; Mersereau, R.M. Super-resolution reconstruction of hyperspectral images. IEEE Trans. Image Process. 2005, 14, 1860–1875. [Google Scholar] [CrossRef] [PubMed]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 20–36. [Google Scholar]
- Farsiu, S.; Robinson, D.; Elad, M.; Milanfar, P. Advances and challenges in super-resolution. Int. J. Imaging Syst. Technol. 2006, 14, 47–57. [Google Scholar] [CrossRef]
- Tsai, R.Y.; Huang, T.S. Multi-frame image restoration and registration. Adv. Comput. Vis. Image Process. 1987, 1, 317–339. [Google Scholar]
- Kim, S.P.; Bose, N.K.; Valenzuela, H.M. Recursive reconstruction of high resolution image from noisy undersampled multiframes. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1013–1027. [Google Scholar] [CrossRef]
- Rhee, S.; Kang, M.G. Discrete cosine transform based regularized high-resolution image reconstruction algorithm. Opt. Eng. 1999, 38, 1348–1356. [Google Scholar] [CrossRef]
- Chan, R.H.; Chan, T.F.; Shen, L.; Shen, Z. Wavelet algorithms for high-resolution image reconstruction. SIAM J. Sci. Comput. 2003, 24, 1408–1432. [Google Scholar] [CrossRef]
- Ur, H.; Gross, D. Improved resolution from sub-pixel shifted pictures. CVGIP Graph. Models Image Process. 1992, 54, 181–186. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Models Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A. Sparse spatio-spectral representation for hyperspectral image super-resolution. In Proceedings of the ECCV 2014 European Conference on Computer Vision, Zürich, Switzerland, 6–12 September 2014; pp. 63–78. [Google Scholar]
- Loncan, L.; de Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simoes, M.; et al. Hyperspectral pansharpening: A review. IEEE Geosci. Remote Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Yang, J.; Li, Y.; Chan, J.C.W.; Shen, Q. Image Fusion for Spatial Enhancement of Hyperspectral Image via Pixel Group Based Non-Local Sparse Representation. Remote Sens. 2017, 9, 53. [Google Scholar] [CrossRef]
- Guo, Z.; Wittman, T.; Osher, S. L1 unmixing and its application to hyperspectral image enhancement. In Proceedings of the SPIE Conference on Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XV, Orlando, FL, USA, 13–17 April 2009. [Google Scholar]
- Zhao, Y.; Yang, J.; Zhang, Q.; Song, L.; Cheng, Y.; Pan, Q. Hyperspectral imagery super-resolution by sparse representation and spectral regularization. EURASIP J. Adv. Signal Process. 2011, 2011, 87. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, L.; Shen, H. A super-resolution reconstruction algorithm for hyperspectral images. Signal Process. 2012, 92, 2082–2096. [Google Scholar] [CrossRef]
- Huang, H.; Christodoulou, A.; Sun, W. Super-resolution hyperspectral imaging with unknown blurring by low-rank and group-sparse modeling. In Proceedings of the ICIP 2014 International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 2155–2159. [Google Scholar]
- Li, J.; Yuan, Q.; Shen, H.; Meng, X.; Zhang, L. Hyperspectral image super-resolution by spectral mixture analysis and spatial–spectral group sparsity. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1250–1254. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2008, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhang, L.; Lukac, R.; Shi, G. Sparse Representation based Image Interpolation with nonlocal autoregressive modeling. IEEE Trans. Image Process. 2013, 22, 1382–1394. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Zhou, H.; Wang, Y.; Cao, W.; Han, Z. Super-resolution reconstruction of hyperspectral images via low rank tensor modeling and total variation regularization. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6962–6965. [Google Scholar]
- Shi, F.; Cheng, J.; Wang, L.; Yap, P.T.; Shen, D. LRTV: MR image super-resolution with low-rank and total variation regularizations. IEEE Trans. Med. Imaging 2015, 34, 2459–2466. [Google Scholar] [CrossRef] [PubMed]
- Kolda, T.G.; Bader, B.W. Tensor Decompositions and Applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Cao, W.; Wang, Y.; Yang, C.; Chang, X.; Han, Z.; Xu, Z. Folded-concave penalization approaches to tensor completion. Neurocomputing 2015, 152, 261–273. [Google Scholar] [CrossRef]
- Fan, J.; Xue, L.; Zou, H. Strong oracle optimality of folded concave penalized estimation. Ann. Stat. 2014, 41, 828–849. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Q.; Wu, Z.; Shen, Y. Total variation-regularized weighted nuclear norm minimization for hyperspectral image mixed denoising. J. Electron. Imaging 2016, 25, 013037. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 2272–2279. [Google Scholar]
- Dong, W.; Shi, G.; Li, X. Nonlocal image restoration with bilateral variance estimation: A low-rank approach. IEEE Trans. Image Process. 2013, 22, 700–711. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2949–2956. [Google Scholar]
- Cao, W.; Wang, Y.; Sun, J.; Meng, D.; Yang, C.; Cichocki, A.; Xu, Z. Total Variation Regularized Tensor RPCA for Background Subtraction From Compressive Measurements. IEEE Trans. Image Process. 2016, 25, 4075–4090. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Bunea, F.; She, Y.; Wegkamp, M. Optimal selection of reduced rank estimators of high-dimensional matrices. Ann. Stat. 2011, 52, 1282–1309. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) Moffett Field Data Set. Available online: https://aviris.jpl.nasa.gov/data/image_cube.html (accessed on 19 July 2017).
- Hyperspectral Digital Imagery Collection Experiment (HYDICE) Urban Data Set. Available online: http://www.tec.army.mil/hypercube (accessed on 19 July 2017).
- HYDICE Washington DC Mall Data Set. Available online: https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html (accessed on 19 July 2017).
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral—Spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- Keshava, N. Distance metrics and band selection in hyperspectral processing with applications to material identification and spectral libraries. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1552–1565. [Google Scholar] [CrossRef]
- Peak Signal-to-Noise Ratio. Available online: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio. (accessed on 19 November 2017).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Sprechmann, P.; Bronstein, A.M.; Sapiro, G. Learning efficient sparse and low rank models. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1821–1833. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
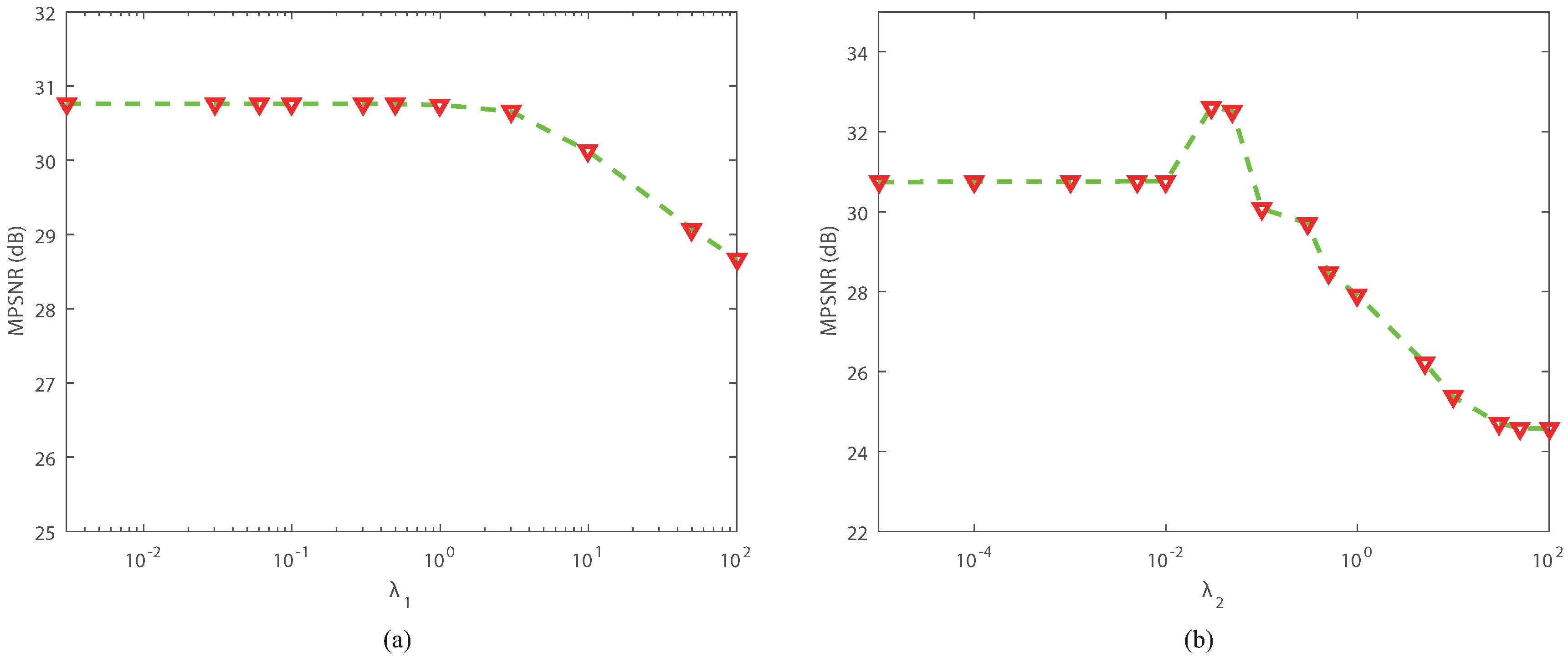{kind=link}
{kind=link}
| NN | NARM | SSGS | LRTV | NLRTATV | ||
|---|---|---|---|---|---|---|
| MPSNR (dB) | 19.6357 | 20.1774 | 21.2733 | 27.7744 | 34.3935 | |
| DC Mall (factor 2) | MSSIM | 0.6771 | 0.7575 | 0.8142 | 0.8380 | 0.9665 |
| SAM (rad) | 0.0998 | 0.0913 | 0.0875 | 0.0805 | 0.0487 | |
| MPSNR (dB) | 20.1281 | 21.5613 | 22.7087 | 28.2954 | 35.2754 | |
| Urban (factor 2) | MSSIM | 0.6924 | 0.7770 | 0.8092 | 0.8485 | 0.9663 |
| SAM (rad) | 0.0971 | 0.0837 | 0.0789 | 0.0710 | 0.0470 | |
| MPSNR (dB) | 19.9535 | 20.3799 | 21.4042 | 29.8499 | 35.9816 | |
| Moffett Field (factor 2) | MSSIM | 0.6836 | 0.7621 | 0.8042 | 0.8349 | 0.9545 |
| SAM (rad) | 0.0958 | 0.0820 | 0.0754 | 0.0630 | 0.0365 | |
| MPSNR (dB) | 24.9190 | 25.1116 | 26.0086 | 27.4270 | 33.1308 | |
| Moffett Field (factor 3) | MSSIM | 0.6888 | 0.7130 | 0.7139 | 0.7955 | 0.9301 |
| SAM (rad) | 0.0963 | 0.0915 | 0.0901 | 0.0810 | 0.0476 |
| NN | NARM | SSGS | LRTV | NLRTATV | ||
|---|---|---|---|---|---|---|
| MPSNR (dB) | 19.4578 | 20.1558 | 21.2191 | 27.2824 | 32.8701 | |
| DC Mall (factor 2) | MSSIM | 0.6346 | 0.7575 | 0.7901 | 0.8126 | 0.9329 |
| SAM (rad) | 0.1034 | 0.0913 | 0.0889 | 0.0845 | 0.0473 | |
| MPSNR (dB) | 20.8761 | 21.4544 | 21.6906 | 27.7523 | 31.8675 | |
| Urban (factor 2) | MSSIM | 0.6263 | 0.7770 | 0.8090 | 0.8148 | 0.9042 |
| SAM (rad) | 0.0928 | 0.0897 | 0.0835 | 0.0745 | 0.0628 | |
| MPSNR (dB) | 19.7640 | 20.3251 | 20.4034 | 29.1580 | 32.5487 | |
| Moffett Field (factor 2) | MSSIM | 0.6107 | 0.7621 | 0.7982 | 0.8158 | 0.8834 |
| SAM (rad) | 0.0905 | 0.0720 | 0.0695 | 0.0635 | 0.0470 | |
| MPSNR (dB) | 24.4130 | 25.0118 | 25.0782 | 26.8280 | 29.4416 | |
| Moffett Field (factor 3) | MSSIM | 0.6223 | 0.7130 | 0.7247 | 0.7458 | 0.8441 |
| SAM (rad) | 0.0929 | 0.0915 | 0.0864 | 0.0839 | 0.0660 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, X.; Han, Z.; He, S. Hyperspectral Image Super-Resolution via Nonlocal Low-Rank Tensor Approximation and Total Variation Regularization. Remote Sens. 2017, 9, 1286. https://doi.org/10.3390/rs9121286
Wang Y, Chen X, Han Z, He S. Hyperspectral Image Super-Resolution via Nonlocal Low-Rank Tensor Approximation and Total Variation Regularization. Remote Sensing. 2017; 9(12):1286. https://doi.org/10.3390/rs9121286
Chicago/Turabian StyleWang, Yao, Xi’ai Chen, Zhi Han, and Shiying He. 2017. "Hyperspectral Image Super-Resolution via Nonlocal Low-Rank Tensor Approximation and Total Variation Regularization" Remote Sensing 9, no. 12: 1286. https://doi.org/10.3390/rs9121286
APA StyleWang, Y., Chen, X., Han, Z., & He, S. (2017). Hyperspectral Image Super-Resolution via Nonlocal Low-Rank Tensor Approximation and Total Variation Regularization. Remote Sensing, 9(12), 1286. https://doi.org/10.3390/rs9121286