NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment


Abstract
:1. Introduction
1.1. Related Work
2. Materials and Methods
2.1. Food and Drink Image Datasets
2.2. NutriNet and Other Deep Convolutional Neural Networks
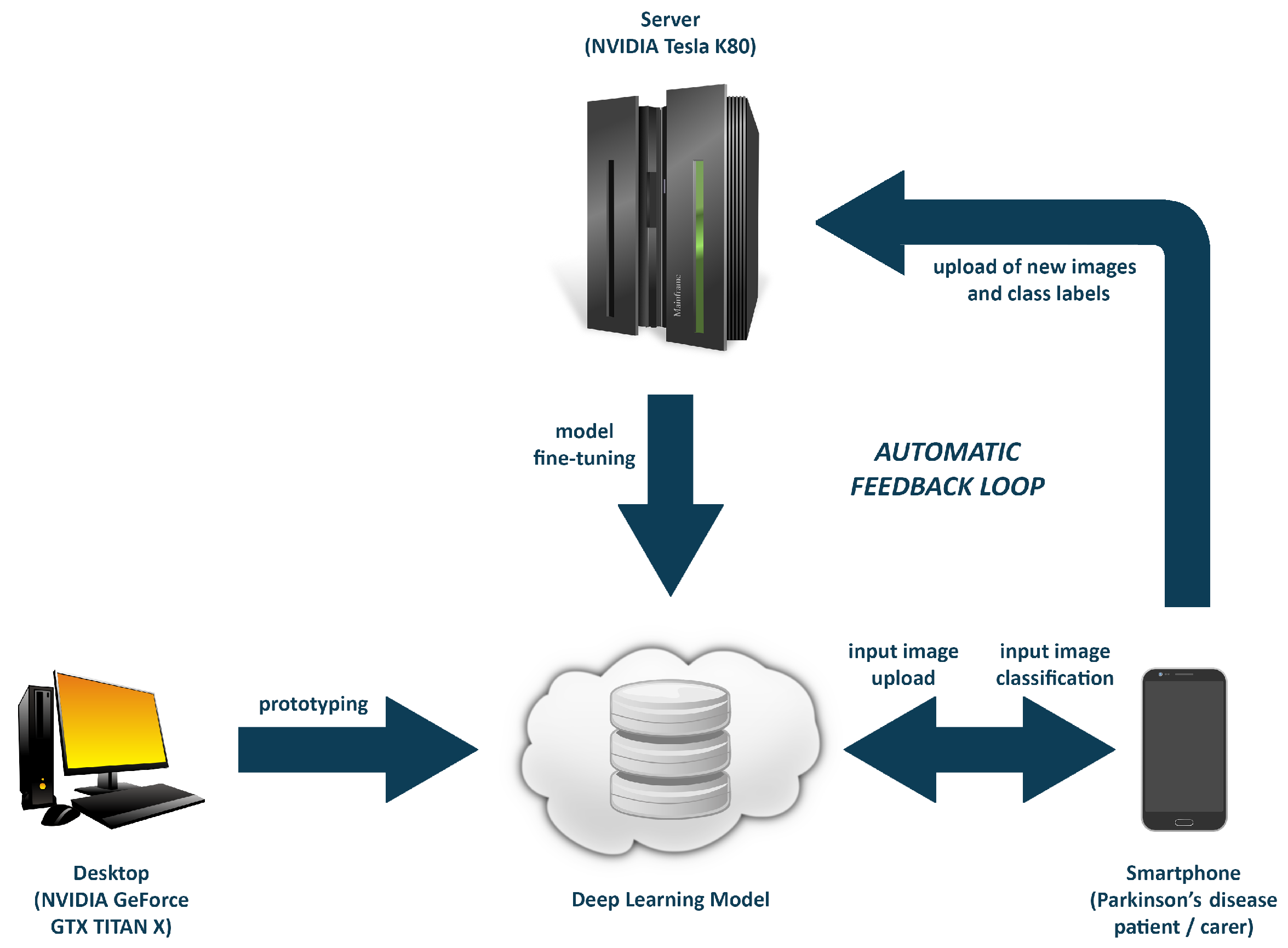
2.3. Implementing an Online Training Component
3. Results
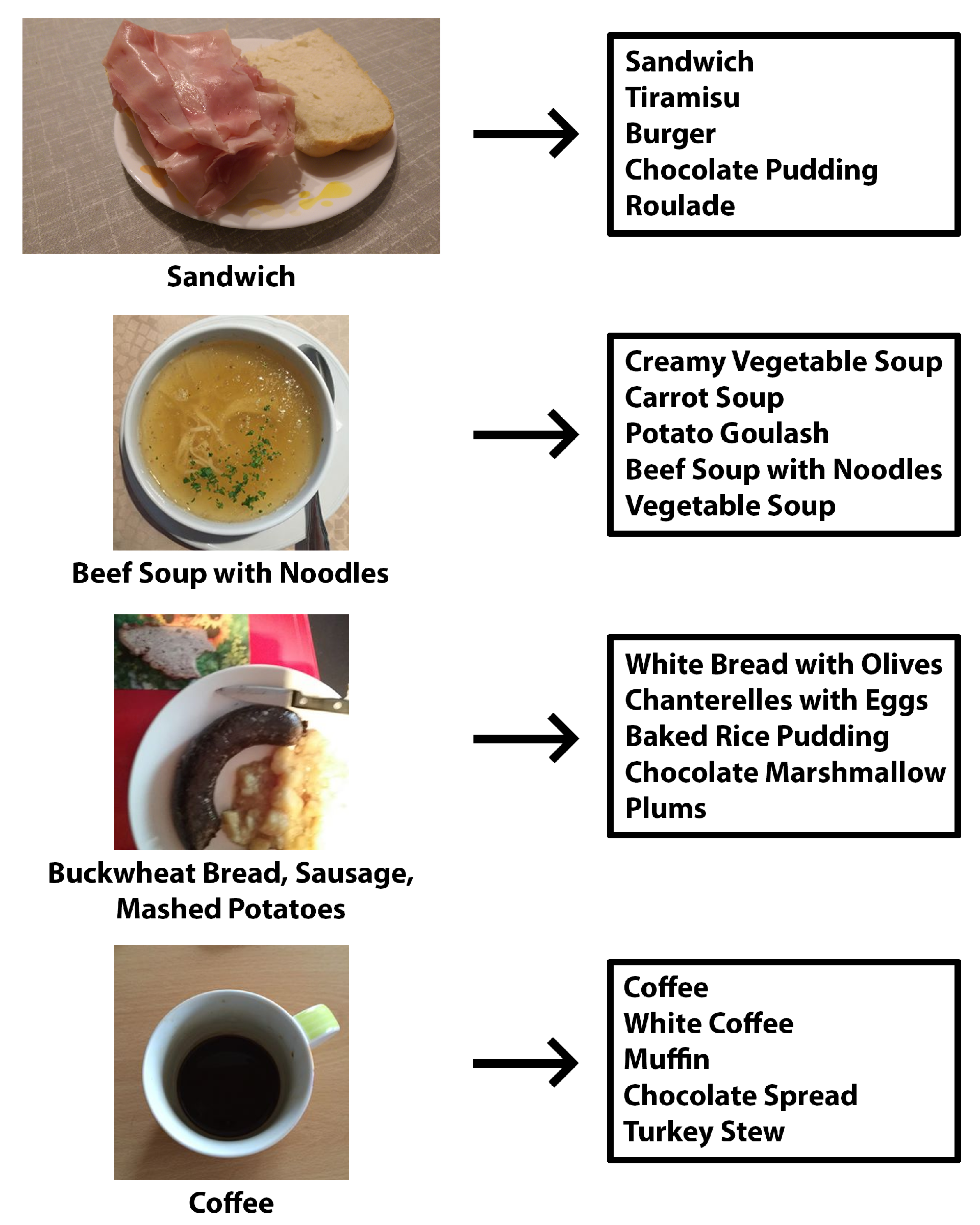
3.1. Testing NutriNet on Other Datasets
4. Discussion
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive Fields, Binocular Interaction and Functional Architecture in the Cat’s Visual Cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS’12, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Chen, M.; Dhingra, K.; Wu, W.; Yang, L.; Sukthankar, R.; Yang, J. PFID: Pittsburgh Fast-Food Image Dataset. In Proceedings of the ICIP 2009, Cairo, Egypt, 7–10 November 2009; pp. 289–292. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the ICCV’99, Corfu, Greece, 20–21 September 1999; pp. 1150–1157. [Google Scholar]
- Joutou, T.; Yanai, K. A Food Image Recognition System with Multiple Kernel Learning. In Proceedings of the ICIP 2009, Cairo, Egypt, 7–10 November 2009; pp. 285–288. [Google Scholar]
- Yang, S.; Chen, M.; Pomerlau, D.; Sukthankar, R. Food Recognition using Statistics of Pairwise Local Features. In Proceedings of the CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 2249–2256. [Google Scholar]
- Anthimopoulos, M.M.; Gianola, L.; Scarnato, L.; Diem, P.; Mougiakakou, S.G. A Food Recognition System for Diabetic Patients Based on an Optimized Bag-of-Features Model. JBHI 2014, 18, 1261–1271. [Google Scholar] [CrossRef] [PubMed]
- GoCARB—Type 1 Diabetes Self-Management and Carbohydrate Counting: A Computer Vision Based Approach. Available online: http://www.gocarb.eu (accessed on 30 December 2016).
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv, 2016; arXiv:1606.02147. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv, 2013; arXiv:1312.6229. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV’16, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Kawano, Y.; Yanai, K. Food Image Recognition with Deep Convolutional Features. In Proceedings of the UbiComp 2014, Seattle, WA, USA, 13–17 September 2014; pp. 589–593. [Google Scholar]
- Matsuda, Y.; Hoashi, H.; Yanai, K. Recognition of Multiple-Food Images by Detecting Candidate Regions. In Proceedings of the ICME 2012, Melbourne, Australia, 9–13 July 2012; pp. 25–30. [Google Scholar]
- Kawano, Y.; Yanai, K. Automatic Expansion of a Food Image Dataset Leveraging Existing Categories with Domain Adaptation. In Proceedings of the ECCV’14, Zürich, Switzerland, 6–12 September 2014; pp. 3–17. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101—Mining Discriminative Components with Random Forests. In Proceedings of the ECCV’14, Zürich, Switzerland, 6–12 September 2014; pp. 446–461. [Google Scholar]
- Kagaya, H.; Aizawa, K.; Ogawa, M. Food Detection and Recognition using Convolutional Neural Network. In Proceedings of the MM’14, Orlando, FL, USA, 3–7 November 2014; pp. 1055–1088. [Google Scholar]
- ImageNet. Available online: http://image-net.org (accessed on 30 December 2016).
- Yanai, K.; Kawano, Y. Food Image Recognition using Deep Convolutional Network with Pre-Training and Fine-Tuning. In Proceedings of the ICMEW 2015, Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Christodoulidis, S.; Anthimopoulos, M.M.; Mougiakakou, S.G. Food Recognition for Dietary Assessment using Deep Convolutional Neural Networks. In Proceedings of the ICIAP 2015, Genoa, Italy, 7–11 September 2015; pp. 458–465. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/Non-Food Image Classification and Food Categorization using Pre-Trained GoogLeNet Model. In Proceedings of the MADiMa’16, Amsterdam, The Netherlands, 15–19 October 2016; pp. 3–11. [Google Scholar]
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Ma, Y. DeepFood: Deep Learning-Based Food Image Recognition for Computer-Aided Dietary Assessment. In Proceedings of the ICOST 2016, Wuhan, China, 25–27 May 2016; pp. 37–48. [Google Scholar]
- Tanno, R.; Okamoto, K.; Yanai, K. DeepFoodCam: A DCNN-Based Real-Time Mobile Food Recognition System. In Proceedings of the MADiMa’16, Amsterdam, The Netherlands, 15–19 October 2016; p. 89. [Google Scholar]
- Ciocca, G.; Napoletano, P.; Schettini, R. Food Recognition: A New Dataset, Experiments, and Results. JBHI 2017, 21, 588–598. [Google Scholar] [CrossRef] [PubMed]
- Hassannejad, H.; Matrella, G.; Ciampolini, P.; De Munari, I.; Mordonini, M.; Cagnoni, S. Food Image Recognition using Very Deep Convolutional Networks. In Proceedings of the MADiMa’16, Amsterdam, The Netherlands, 15–19 October 2016; pp. 41–49. [Google Scholar]
- OPEN—Platform for Clinical Nutrition. Available online: http://opkp.si/enGB (accessed on 30 December 2016).
- PD_manager—mHealth Platform for Parkinson’s Disease Management. Available online: http://parkinson-manager.eu (accessed on 30 December 2016).
- Google Custom Search. Available online: http://developers.google.com/custom-search (accessed on 30 December 2016).
- Python Software Foundation. Available online: http://www.python.org/psf (accessed on 24 June 2017).
- Symas Lightning Memory-Mapped Database. Available online: http://symas.com/lightning-memory-mapped-database (accessed on 28 May 2017).
- NutriNet Food and Drink Image Recognition Dataset Tools. Available online: http://cs.ijs.si/korousic/imagerecognition/nutrinetdatasettools.zip (accessed on 5 June 2017).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. JMLR 2014, 15, 1929–1958. [Google Scholar]
- Howard, A.G. Some Improvements on Deep Convolutional Neural Network Based Image Classification. arXiv, 2013; arXiv:1312.5402. [Google Scholar]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Nesterov, Y. A Method of Solving a Convex Programming Problem with Convergence Rate O(). Sov. Math. Dokl. 1983, 27, 372–376. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. JMLR 2011, 12, 2121–2159. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv, 2016; arXiv:1609.04747. [Google Scholar]
- Krizhevsky, A. One Weird Trick for Parallelizing Convolutional Neural Networks. arXiv, 2014; arXiv:1404.5997. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the MM’14, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- NVIDIA DIGITS—Interactive Deep Learning GPU Training System. Available online: http://developer.nvidia.com/digits (accessed on 30 December 2016).
- Torch—A Scientific Computing Framework for LuaJIT. Available online: http://torch.ch (accessed on 8 April 2017).
- Torch Implementation of ResNet and Training Scripts GitHub. Available online: http://github.com/facebook/fb.resnet.torch (accessed on 7 April 2017).
- Deep Residual Learning for Image Recognition GitHub. Available online: http://github.com/KaimingHe/deep-residual-networks (accessed on 16 April 2017).
- GPU Technology Conference 2015—Deep Learning onGPUs. Available online: http://on-demand.gputechconf.com/gtc/2015/webinar/deep-learning-course/intro-to-deep-learning.pdf (accessed on 30 December 2016).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
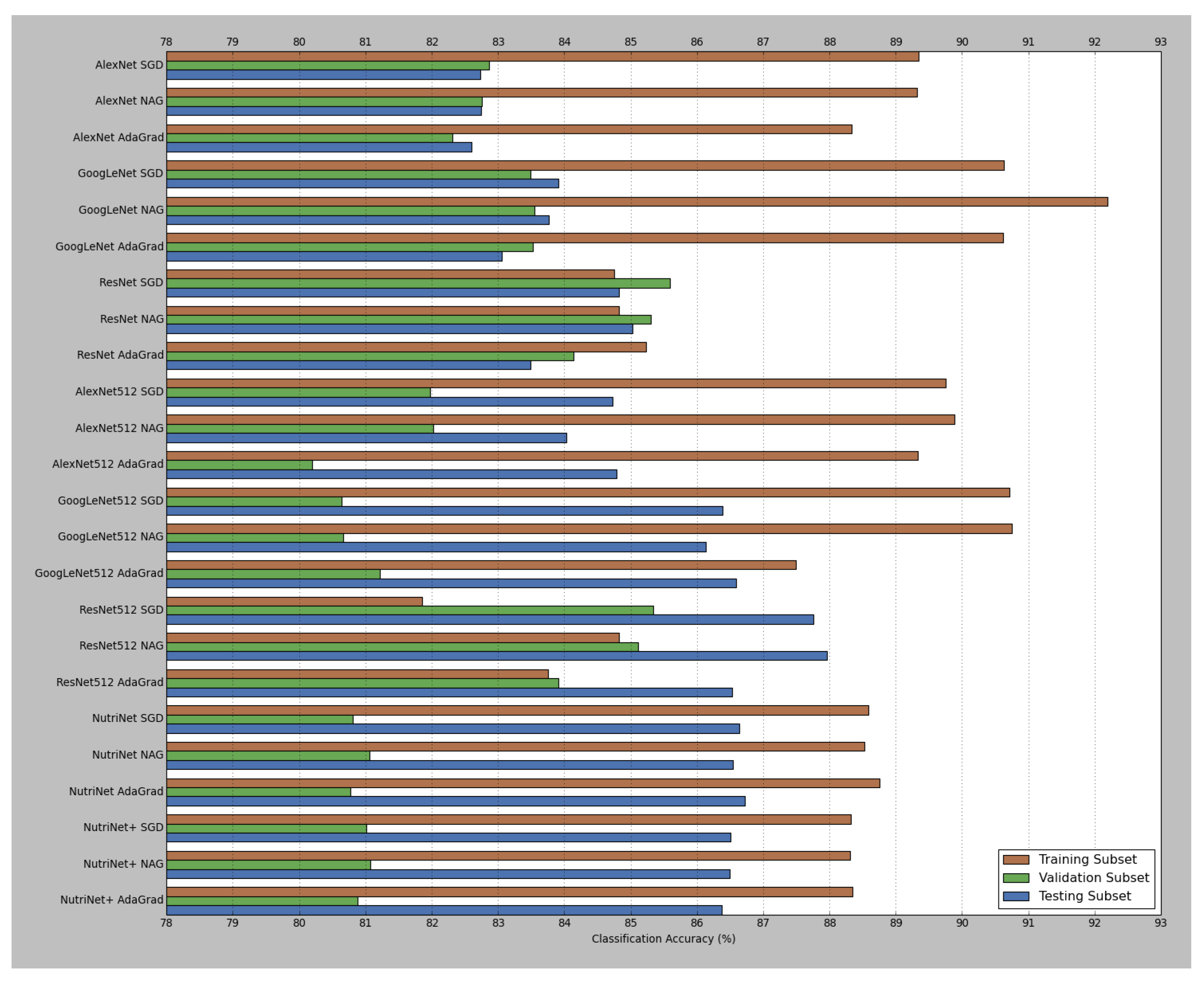
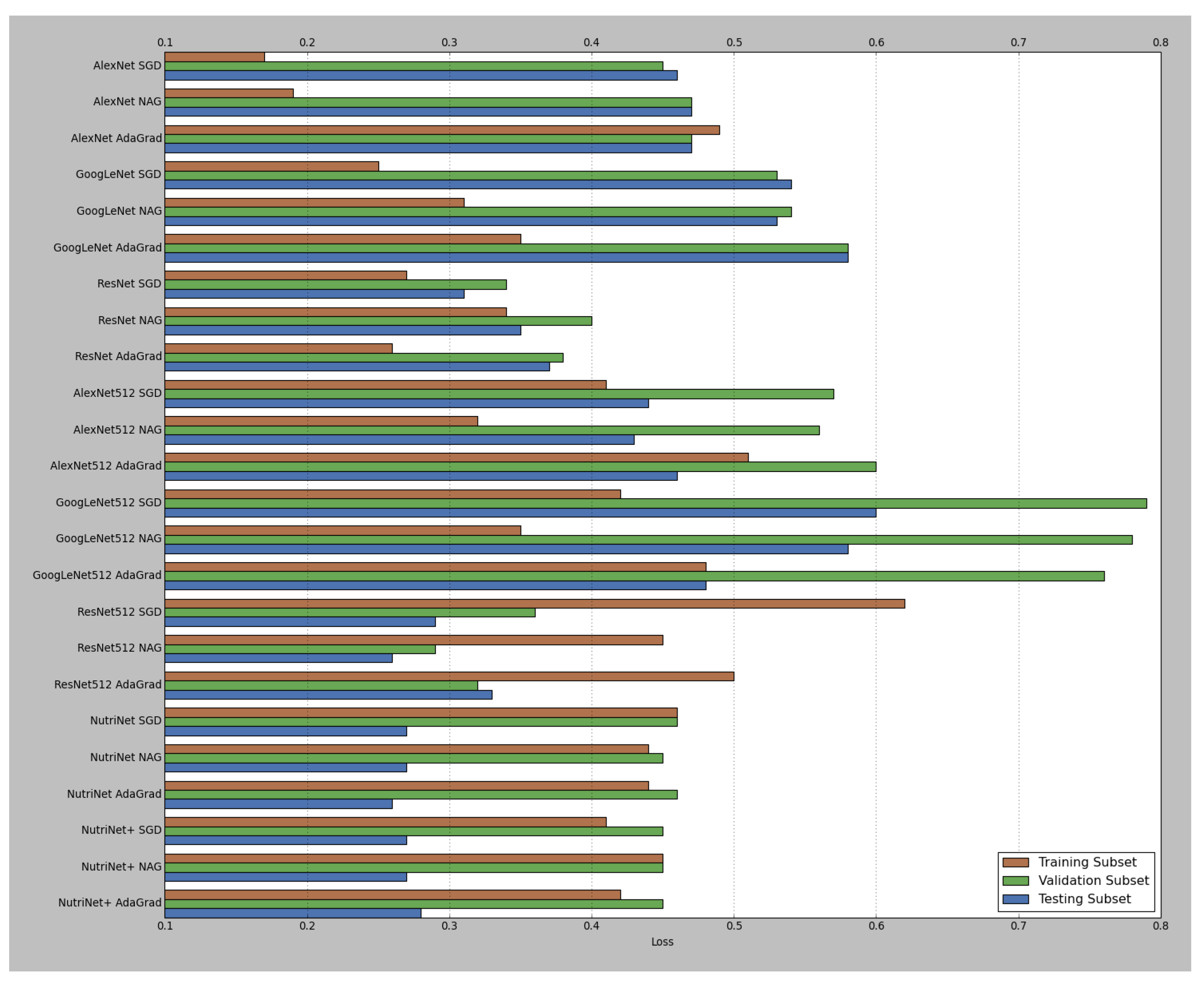
| Model Type | Model | Training Subset | Validation Subset | Testing Subset | |||
|---|---|---|---|---|---|---|---|
| Loss | Accuracy | Loss | Accuracy | Loss | Accuracy | ||
| Pre-Trained Models | AlexNet SGD | 0.17 | 89.35% | 0.45 | 82.87% | 0.46 | 82.73% |
| AlexNet NAG | 0.19 | 89.32% | 0.47 | 82.76% | 0.47 | 82.75% | |
| AlexNet AdaGrad | 0.49 | 88.33% | 0.47 | 82.31% | 0.47 | 82.60% | |
| GoogLeNet SGD | 0.25 | 90.63% | 0.53 | 83.49% | 0.54 | 83.91% | |
| GoogLeNet NAG | 0.31 | 92.19% | 0.54 | 83.55% | 0.53 | 83.77% | |
| GoogLeNet AdaGrad | 0.35 | 90.62% | 0.58 | 83.53% | 0.58 | 83.06% | |
| ResNet SGD | 0.27 | 84.75% | 0.34 | 85.60% | 0.31 | 84.82% | |
| ResNet NAG | 0.34 | 84.82% | 0.40 | 85.31% | 0.35 | 85.03% | |
| ResNet AdaGrad | 0.26 | 85.23% | 0.38 | 84.14% | 0.37 | 83.49% | |
| 512 × 512 Models | AlexNet SGD | 0.41 | 89.76% | 0.57 | 81.98% | 0.44 | 84.73% |
| AlexNet NAG | 0.32 | 89.89% | 0.56 | 82.03% | 0.43 | 84.03% | |
| AlexNet AdaGrad | 0.51 | 89.33% | 0.60 | 80.20% | 0.46 | 84.79% | |
| GoogLeNet SGD | 0.42 | 90.72% | 0.79 | 80.64% | 0.60 | 86.39% | |
| GoogLeNet NAG | 0.35 | 90.75% | 0.78 | 80.66% | 0.58 | 86.14% | |
| GoogLeNet AdaGrad | 0.48 | 87.50% | 0.76 | 81.22% | 0.48 | 86.59% | |
| ResNet SGD | 0.62 | 81.86% | 0.36 | 85.34% | 0.29 | 87.76% | |
| ResNet NAG | 0.45 | 84.82% | 0.29 | 85.11% | 0.26 | 87.96% | |
| ResNet AdaGrad | 0.50 | 83.76% | 0.32 | 83.91% | 0.33 | 86.53% | |
| NutriNet SGD | 0.46 | 88.59% | 0.46 | 80.81% | 0.27 | 86.64% | |
| NutriNet NAG | 0.44 | 88.53% | 0.45 | 81.06% | 0.27 | 86.54% | |
| NutriNet AdaGrad | 0.44 | 88.76% | 0.46 | 80.77% | 0.26 | 86.72% | |
| NutriNet+ SGD | 0.41 | 88.32% | 0.45 | 81.01% | 0.27 | 86.51% | |
| NutriNet+ NAG | 0.45 | 88.31% | 0.45 | 81.08% | 0.27 | 86.50% | |
| NutriNet+ AdaGrad | 0.42 | 88.35% | 0.45 | 80.88% | 0.28 | 86.38% | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mezgec, S.; Koroušić Seljak, B. NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment. Nutrients 2017, 9, 657. https://doi.org/10.3390/nu9070657
Mezgec S, Koroušić Seljak B. NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment. Nutrients. 2017; 9(7):657. https://doi.org/10.3390/nu9070657
Chicago/Turabian StyleMezgec, Simon, and Barbara Koroušić Seljak. 2017. "NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment" Nutrients 9, no. 7: 657. https://doi.org/10.3390/nu9070657
APA StyleMezgec, S., & Koroušić Seljak, B. (2017). NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment. Nutrients, 9(7), 657. https://doi.org/10.3390/nu9070657