
A Heterogeneous Architecture for the Vision Processing Unit with a Hybrid Deep Neural Network Accelerator



Abstract
:1. Introduction
- A heterogeneous VPU architecture with a hybrid PE array and a 1-D Row Processor is designed to implement the ISP, the CNNs, and the hybrid DNNs tasks. The time-sharing schemes are applied to multiplex the hardware resources for different tasks.
- A new workflow for the DNNs is proposed with customized processing modules to process the subtasks of the DNNs concurrently.
- A pipeline strategy is applied to seamlessly carry out the vision tasks without any notable idle cycles on the processing modules.
2. Preliminary
3. The Architecture of the VPU
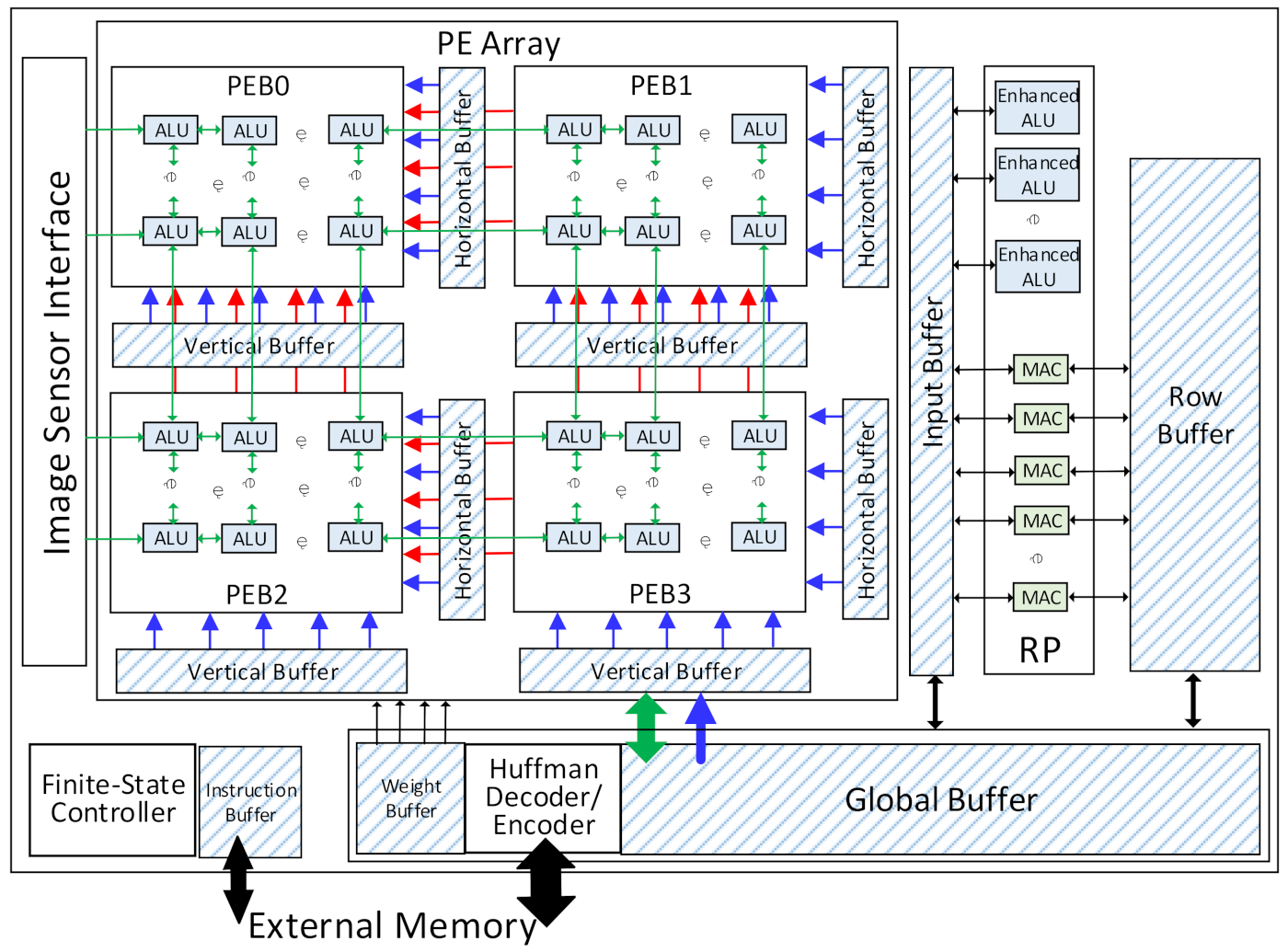
3.1. The Overall Architecture
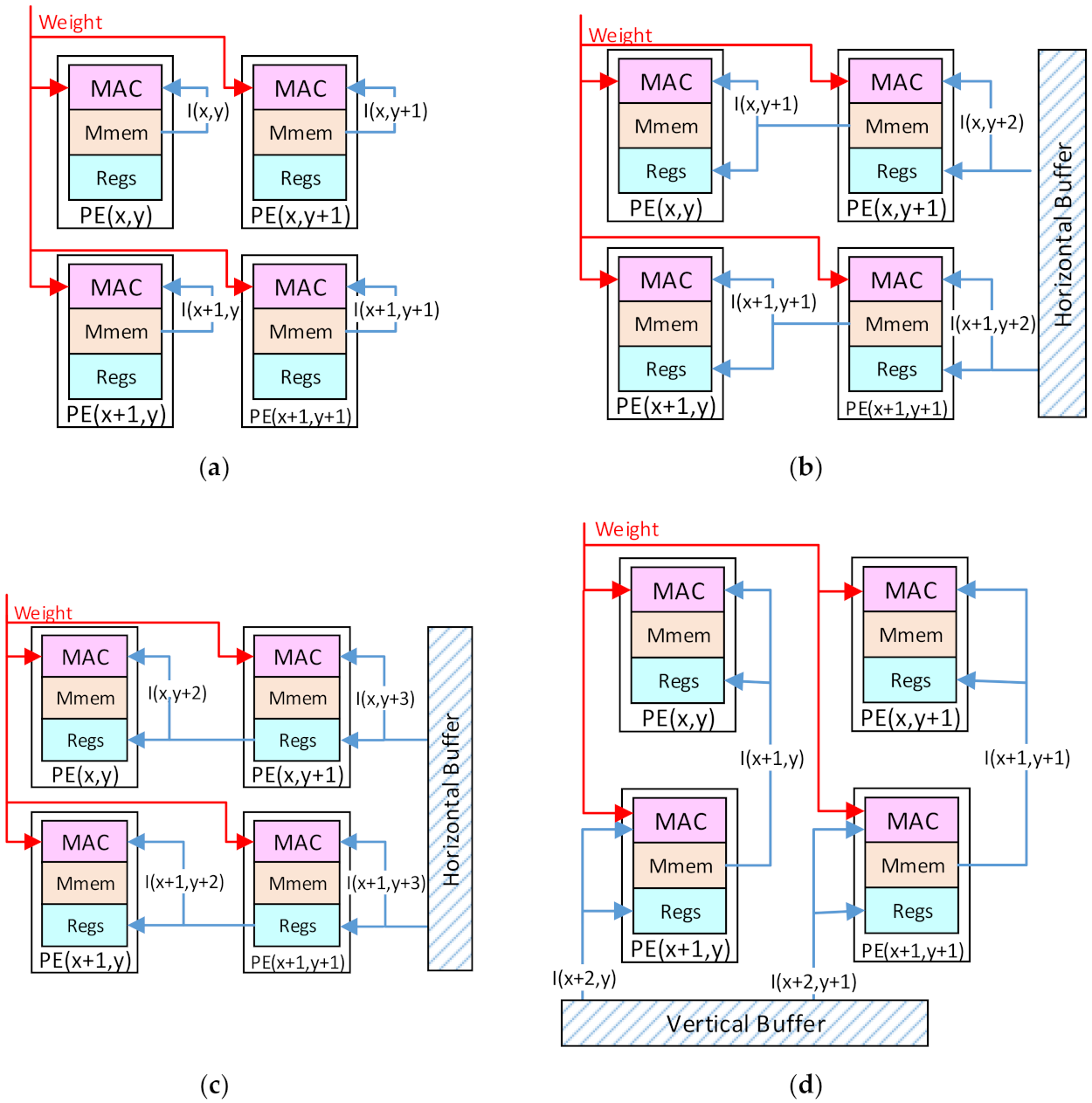
3.2. The PE Array
3.3. The Row Processor
3.4. The Memory Architecture
4. The Workflow of the Vision Tasks on the VPU
4.1. The Workflow for the ISP on the VPU
4.2. The Workflow for the CNN on the VPU
4.2.1. The Workflow for the Convolutional Layers
- (1)
- The Mapping Scheme

- (2)
- The Computing Flow

- (3)
- The Data Transmission Scheme in the Convolutional Layers
4.2.2. The Workflow of the FC Layers
4.2.3. The Non-Multiplication-and-Accumulation (Non-Mac) Operations
4.3. The Workflow of the RNN
4.4. The Pipeline Strategy in the Workflow of the Vision Task
5. The Experiment Results and the Discussion
5.1. The Implementation
- Each MAC in the PE array and the Row Processor was instantiated by one DSP and could work as one 16 × 16 MAC or two 8 × 8 MACs;
- The bit-widths of both the ALUs and the enhanced ALUs were 8, and the buses were also 8-bit wide;
- The bit-widths of the inter-PE transmission buses and the weight bus were 16 in the PE array, in which one 16-bit data or two 8-bit data could be transferred;
- Each horizontal/vertical buffer in the PEBs was composed of 7 2-KB banks, and each bank in the weight buffer was also 2-KB;
- The sharing buffer was comprised of 2 4-KB banks, while the row buffer consisted of 8 4-KB banks;
- The Global Buffer is comprised of 10 4-KB banks, and each Mmem is a 1-KB RAM.
5.2. The Experiment Method
5.2.1. The Modeling of the 224 × 224 Image Sensor
5.2.2. The Quantization
5.2.3. The Testbench
5.3. The Experiment Results and the Analysis
5.3.1. The Experiment Results for the ISP and the Analysis
5.3.2. The Experiment Results for the DNNs and the Analysis
- (1)
- The Test of the CNNs
- (2)
- The Experiment Results of the Hybrid DNNs and the Analysis
5.3.3. The Test of the Complete Vision Tasks
5.4. The Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yang, J.; Yang, Y.; Chen, Z.; Liu, L.; Liu, J.; Wu, N. A Heterogeneous Parallel Processor for High-Speed Vision Chip. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 746–758. [Google Scholar] [CrossRef]
- Schmitz, J.A.; Gharzai, M.K.; Balkir, S.; Hoffman, M.W.; Nathan, S. A 1000 frames/s Vision Chip Using Scalable Pixel-Neighborhood-Level Parallel Processing. IEEE J. Solid-State Circuits 2017, 52, 556–568. [Google Scholar] [CrossRef]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Temam, O. ShiDianNao: Shifting vision processing closer to the sensor. In Proceedings of the 42nd Annual International Symposium on Computer Architecture, Portland, OR, USA, 13–17 June 2015. [Google Scholar]
- Shi, C.; Yang, J.; Han, Y.; Cao, Z.; Qin, Q.; Liu, L.; Wu, N.; Wang, Z. A 1000 Fps Vision Chip Based on a Dynamically Reconfigurable Hybrid Architecture Comprising a Pe Array Processor and Self-Organizing Map Neural Network. IEEE J. Solid-State Circuits 2014, 28, 256–269. [Google Scholar] [CrossRef]
- Zhang, W.; Fu, Q.; Wu, N.-J. A Programmable Vision Chip Based on Multiple Levels of Parallel Processors. IEEE J. Solid-State Circuits 2011, 46, 2132–2147. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Shin, D.; Yoo, H.-J. The Heterogeneous Deep Neural Network Processor with a Non-von Neumann Architecture. Proc. IEEE 2019, 108, 1245–1260. [Google Scholar] [CrossRef]
- Shouyi, Y.; Peng, O.; Shibin, T.; Fengbin, T.; Xiudong, L. A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications. IEEE J. Solid-State Circuits 2017, 53, 968–982. [Google Scholar]
- Xiaofan, Z.; Xinheng, L.; Anand, R.; Chuanhao, Z.; Shibin, T.; Peng, O.; Zuofu, C.; Kyle, R.; Deming, C. High-performance video content recognition with long-term recurrent convolutional network for FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Jiang, W.; Yi, Y.; Junhua, M.; Zhizheng, H.; Chang, H.; Wei, X. CNN-RNN: A Unified Framework for Multi-label Image Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Honglong, L.; Jie, Y.; Zhongxing, Z.; Nanjian, W. A high speed programmable vision chip for real-time object detection. Infrared Laser Eng. 2020, 49, 55–60. [Google Scholar] [CrossRef]
- Jiaqing, W.; Liyuan, L.; Nanjian, W. High-speed tracking system based on Multi-parallel-core processor and CNN algorithm. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019. [Google Scholar]
- Peng, L.; Yan, S. A Hybrid Vision Processing Unit with a Pipelined Workflow for Convolutional Neural Network Accelerating and Image Signal Processing. Electronics 2021, 10, 2989. [Google Scholar]
- Chen, Y.H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In Proceedings of the International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016. [Google Scholar]
- Park, S.; Hong, I.; Park, J.; Yoo, H.J. An Energy-Efficient Embedded Deep Neural Network Processor for High Speed Visual Attention in Mobile Vision Recognition SoC. IEEE J. Solid-State Circuits 2016, 51, 2380–2388. [Google Scholar] [CrossRef]
- Li, Z.; Chen, Y.; Gong, L.; Liu, L.; Kim, H.S. An 879GOPS 243mW 80fps VGA Fully Visual CNN-SLAM Processor for Wide-Range Autonomous Exploration. In Proceedings of the 2019 IEEE International Solid- State Circuits Conference-(ISSCC), San Francisco, NV, USA, 17–19 February 2019. [Google Scholar]
- Bong, K.; Choi, S.; Kim, C.; Han, D.; Yoo, H.-J. A Low-Power Convolutional Neural Network Face Recognition Processor and a CIS Integrated with Always-on Face Detector. IEEE J. Solid-State Circuits 2017, 53, 115–123. [Google Scholar] [CrossRef]
- Cavigelli, L.; Benini, L. Origami: A 803-GOp/s/W Convolutional Network Accelerator. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2461–2475. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Z.; Yang, Y.; Yue, J.; Liu, R.; Feng, X.; Lin, Z.; Wu, X.; Li, X.; Yang, H.; Liu, Y. A 65nm 24.7µj/Frame 12.3mw Activation-Similarity-Aware Convolutional Neural Network Video Processor Using Hybrid Precision, Inter-Frame Data Reuse and Mixed-Bit-Width Difference-Frame Data Codec. In Proceedings of the 2020 IEEE International Solid- State Circuits Conference (ISSCC), San Francisco, NV, USA, 2–6 February 2020. [Google Scholar]
- Keumsun, P.; Minah, C.; Jae, H.C. Image Pre-Processing Method of Machine Learning for Edge Detection with Image Signal Processor Enhancement. Micromachines 2021, 12, 73. [Google Scholar]
- Kawamoto, R.; Taichi, M.; Kabuto, M.; Watanabe, D.; Izumi, S.; Yoshimoto, M.; Kawaguchi, H.; Matsukawa, G.; Goto, T.; Kojima, M. A 1.15-TOPS 6.57-TOPS/W Neural Network Processor for Multi-Scale Object Detection with Reduced Convolutional Operations. IEEE J. Sel. Top. Signal Process. 2020, 14, 634–645. [Google Scholar] [CrossRef]
- Chixiao, C.; Hongwei, D.; Huwan, P.; Haozhe, Z.; Yu, W.; Richard, S. OCEAN-An On-Chip Incremental-Learning Enhanced Artificial Neural Network Processor with Multiple Gated-Recurrent-Unit Accelerator. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 519–530. [Google Scholar]
- Shin, D.; Lee, J.; Lee, J.; Lee, J.; Yoo, H.J. DNPU: An Energy-Efficient Deep-Learning Processor with Heterogeneous Multi-Core Architecture. IEEE Micro 2018, 38, 85–93. [Google Scholar] [CrossRef]
- Hsiao, S.F.; Chen, K.C.; Lin, C.C.; Chang, H.J.; Tsai, B.C. Design of a Sparsity-Aware Reconfigurable Deep Learning Accelerator Supporting Various Types of Operations. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 376–387. [Google Scholar] [CrossRef]
- Liangkai, Z.; Ning, W.; Fen, G.; Fang, Z.; Jiahui, Z.; Tong, L. Small Area Configurable Deep Neural Network Accelerator for IoT System. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020. [Google Scholar]
- Zeng, S.; Guo, K.; Fang, S.; Kang, J.; Xie, D.; Shan, Y.; Wang, Y.; Yang, H. An Efficient Reconfigurable Framework for General Purpose CNN-RNN Models on FPGAs. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2017, 37, 35–47. [Google Scholar] [CrossRef]
- Sim, J.; Lee, S.; Kim, L.-S. An Energy-Efficient Deep Convolutional Neural Network Inference Processor with Enhanced Output Stationary Dataflow in 65-nm CMOS. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 87–100. [Google Scholar] [CrossRef]
- Moons, B.; Uytterhoeven, R.; Dehaene, W.; Verhelst, M. 14.5 Envision: A 0.26-to-10TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-scalable Convolutional Neural Network processor in 28nm FDSOI. In Proceedings of the International Solid-state Circuits Conference, San Francisco, NV, USA, 5–9 February 2017. [Google Scholar]
- Kartik, D.; Praveen, K.; Minesh, M. Improving CNN-RNN Hybrid Networks for Handwriting Recognition. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Buffalo, NY, USA, 5–8 August 2018. [Google Scholar]
- Yujin, S.; Yongjin, X. End-to-End Captcha Recognition Using Deep CNN-RNN Network. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019. [Google Scholar]
- Yongxing, Y.; Jie, Y.; Liyuan, L.; Nanjian, W. High-Speed Target Tracking System Based on a Hierarchical Parallel Vision Processor and Gray-Level LBP Algorithm. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 950–964. [Google Scholar]
- Bruno, A.S.; Arthur, M.L.; Jones, Y. A Manycore Vision Processor Architecture for Embedded Applications. In Proceedings of the 2020 Brazilian Symposium on Computing Systems Engineering (SBESC), Florianopolis, Brazil, 24–27 November 2020. [Google Scholar]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar]
- Min, L.; Qiang, C.; Shuicheng, Y. Network in Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Alessandro, A.; Hesham, M.; Enrico, C.; Antonio, R.N.; Ricardo, T.M.; Iulia-Alexandra, L.; Milde, M.B.; Federico, C.; Alejandro, L.B.; Liu, S.C. NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 644–656. [Google Scholar]
- Yu, Y.; Wu, C.; Zhao, T.; Wang, K.; He, L. OPU: An FPGA-Based Overlay Processor for Convolutional Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 35–47. [Google Scholar] [CrossRef]
- Yu, Y.; Zhao, T.; Wang, K.; He, L. Light-OPU: An FPGA-based Overlay Processor for Lightweight Convolutional Neural Networks. In Proceedings of the FPGA2020: The 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 23–25 February 2020. [Google Scholar]
- Chen, W.; Jinming, Z.; Kun, W.; Lei, H. MP-OPU: A Mixed Precision FPGA-based Overlay Processor for Convolutional Neural Networks. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021. [Google Scholar]
- Bai, L.; Zhao, Y.; Huang, X. A CNN Accelerator on FPGA Using Depthwise Separable Convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef] [Green Version]
- Yunfei, S.; Brian, L.; Xiaochao, X. An OpenCL-Based Hybrid CNN-RNN Inference Accelerator On FPGA. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019. [Google Scholar]
- Ying, Y.; Fen, G.; Danfeng, Q.; Xin, Y.; Ziyu, L.; Fang, Z.; Ning, W. Implementation of Reconfigurable CNN-LSTM Accelerator Based on FPGA. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology, Tianjin, China, 13–16 October 2021. [Google Scholar]
- Lee, J.; Lee, J.; Han, D.; Lee, J.; Park, G.; Yoo, H.J. LNPU: A 25.3TFLOPS/W Sparse Deep-Neural-Network Learning Processor with Fine-Grained Mixed Precision of FP8-FP16. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 2–6 February 2019. [Google Scholar]
- Yue, J.; Liu, Y.; Yuan, Z.; Wang, Z.; Guo, Q.; Li, J.; Yang, C.; Yang, H. A 3.77TOPS/W Convolutional Neural Network Processor with Priority-Driven Kernel Optimization. IEEE Trans. Circuits Syst. II Express Briefs 2018, 66, 277–281. [Google Scholar] [CrossRef]
- Amir, G.; Sehoon, K.; Zhen, D.; Zhewei, Y.; Michael, M.; Kurt, K. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv 2021, arXiv:2103.13630. [Google Scholar]
- Zhang, B.; Zhao, C.; Mei, K.; Zhao, J.; Zheng, N. Hierarchical and Parallel Pipelined Heterogeneous SoC for Embedded Vision Processing. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1434–1444. [Google Scholar] [CrossRef]
- Abbad, U.R.; Zohaib, M.; Muhammad, A.Q. Fuzzy Logic Based Automatic Vehicle Collision Prevention System. In Proceedings of the 2015 IEEE Conference on Systems, Process and Control (ICSPC), Bandar Sunway, Malaysia, 18–20 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Device | LUT | FF | BRAM | DSP | DNN 1 |
|---|---|---|---|---|---|---|---|
| [37] | 2019 | Zynq 7100 | 229,000 | 107K | 386 | 128 | CNN |
| [38] | 2020 | XC7K325T | 94,763 | 150,848 | 165 | 516 | CNN |
| [28] | 2018 | XC7Z020 | 29,867 | 35,489 | 85.5 | 190 | CNN |
| [39] | 2020 | XC7K325T | 173,522 | 241,175 | 193.5 | 704 | CNN |
| [40] | 2021 | XC7VX690T | 278,548 | 324,033 | 912 | 3072 | CNN |
| [41] | 2018 | Arria 10 | 163,506 | / | 24.5Mb | 1278 | CNN |
| [26] | 2020 | XC7Z020 | 9474 | 9379 | 72 | / | HDNN |
| [27] | 2018 | ZU5EG | 117,120 | 234,240 | 884 | 1248 | HDNN |
| [42] | 2019 | Arria 10 | / | / | / | / | HDNN |
| [9] | 2017 | XC7VX690T | 316,250 | 321,165 | 1508 | 3130 | HDNN |
| [43] | 2021 | Vertex7 | 53,078 | 29,869 | 465 | 388 | HDNN |
| This work | 2021 | XC7K325T | 152,264 | 88,742 | 104 | 212 | HDNN |
| Bit-Width | CNNs | |||
|---|---|---|---|---|
| VGG16 | MobilenetV3L | MobilenetV2 | Densenet121 | |
| Float 32 bit | 67.93% | 75.2% | 72.0% | 74.9% |
| Fixed 8 bit | 67.72% | 74.1% | 71.2% | 74.1% |
| Ref | [2] | [4] | [5] | [1] | [47] | This Work |
|---|---|---|---|---|---|---|
| Senor Resolution | 64 × 80 | 256 × 256 | 128 × 128 | 256 × 256 | 720P | 224 × 224 |
| Platform | ASIC | ASIC | ASIC | FPGA | Stratix IV | XC7K325T |
| PE Array | 8 × 10 | 64 × 64 | 32 × 128 PE, 32 RP | 64 × 64 PE, 8 × 8 PPU | Heterogeneous 1 | 7 × 14 |
| Bit-width for PE | 8 | 1 | 1 for PE, 8 for RP | 1for PE, 16 for PPU | 32 | 8 |
| Freq (MHz) | 20 | 50 | 100 | 50 | 133 | 200 |
| GOPS 2 | 1.6 | 12 | 44 | 31 | 37 3 | 19.6 4 |
| Runtime of | ||||||
| Demosaic | \ | \ | \ | \ | \ | 56us |
| 8 × 8 DCT | 380us | 98us | \ | \ | 812us | |
| Median Filter | 734us @ 3 × 3 | 55us @ 8 × 8 | \ | 6.94ms @ 5 × 5 | 1.96ms @ 3 × 3 | |
| Power(mW) | 36 | 630 | 533 | \ | 98.5 | 1410 |
| Ref | Freq (MHz) | Tested DNN | Bit-Width | GOPS | GOPS/ DSP/f | GOPS/W | Power (W) | Runtime (ms) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| [37] | 60 | VGG16 | 16 | 17.19 | 4.476 | 27.4 | 0.627 | 2269 | 0.44 |
| [38] | 200 | VGG16 | 8 | 354 | 3.43 | 21.45 | 16.5 | 82.1 | 12.18 |
| [28] | 214 | VGG16 | 8 | 84.3 | 2.073 | 24.1 | 3.497 | 364 | 2.747 |
| [39] | 200 | MobileNetV1 | 8 | 147.84 | 1.05 | 17.9 | 8.259 | 3.779 | 264.6 |
| MobileNetV2 | 98 | 0.696 | 11.5 | 8.522 | 3.07 | 325.7 | |||
| MobileNetV3L | 84.84 | 0.602 | 9.9 | 8.57 | 3 | 332.7 | |||
| DenseNet161 | 176 | 1.25 | 52.5 | 3.352 | 41.49 | 24.1 | |||
| [40] | 200 | VGG16 | Mixed | 2746 | 4.5 | \ | \ | 11.2 | 89.29 |
| MobileNetV1 | 1167.3 | 1.9 | 0.47 | 2127 | |||||
| MobileNetV2 | 890.88 | 1.45 | 0.34 | 2941 | |||||
| [41] | 133 | MobileNetV2 | 16 | 170.6 | 2.007 | \ | \ | 3.75 | 266.6 |
| This work | 200 | VGG16 | 8 | 161.73 | 3.814 | 23.7 | 6.824 | 197.5 | 5.06 |
| MobileNetV2 | 155.37 | 3.664 | 21.6 | 7.192 | 3.251 | 307.59 | |||
| MobileNetV3L | 149.33 | 3.521 | 20.1 | 7.429 | 3.002 | 333.06 | |||
| DenseNet161 | 158.14 | 3.73 | 23.6 | 6.7 | 104.8 | 9.54 |
| Ref | Freq (MHz) | Tested DNN 1 | Bit-Width | GOPS | GOPS/ DSP/f | GOPS/W | Power (W) | Runtime (ms) |
|---|---|---|---|---|---|---|---|---|
| [26] | 50 | LeNet + 2 LSTM128 1 | 8 for CNN 16 for RNN | / | / | / | / | 6 |
| [27] | 200 | AlexNet + 2 LSTM1024 | 8 for CNN 16 for RNN | 690.76 | 2.767 | 86.34 | 8 | 9 |
| [42] | 268 | CRNN | 8 for CNN 16 for RNN | 646 | ||||
| [9] | 100 | AlexNet + 1 LSTM 256 | 16 for input 12 for weight | 36.25 | 0.1158 | 1.53 | 23.69 | 40 |
| [43] | 200 | 1D CNN + LSTM64 | 8 for CNN 16 for RNN | 49.4 | 0.637 | 26.7 | 1.85 | 8.295 |
| This work | 200 | VGG16 + 2 LSTM1000 | 8 for CNN 16 for RNN | 162.7 | 3.84 | 23.7 | 6.864 | 197.51 |
| DenseNet161 + 2 LSTM1000 | 159.23 | 3.753 | 23.58 | 6.751 | 104.84 |
| No. | ISP Algorithms | Tested DNN 1 | Sum of Runtimes (ms) | Runtime (ms) | FPS | Power (W) |
|---|---|---|---|---|---|---|
| 1 | Demosiac, DCT, Median filter | MobileNetV3L | 5.62 | 3.14 | 308 | 8.11 |
| 2 | Demosiac, DCT, Median filter | VGG16 | 200.1 | 197.48 | 5.1 | 6.83 |
| 3 | Demosiac, DCT, Median filter | VGG16 + 2 LSTM1000 | 198.37 | 197.51 | 5.1 | 6.94 |
| 4 | Demosiac, DCT, Median filter | DenseNet161 + 2 LSTM1000 | 104.83 | 104.87 | 9.46 | 7.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Yang, Z.; Kang, L.; Wang, J. A Heterogeneous Architecture for the Vision Processing Unit with a Hybrid Deep Neural Network Accelerator. Micromachines 2022, 13, 268. https://doi.org/10.3390/mi13020268
Liu P, Yang Z, Kang L, Wang J. A Heterogeneous Architecture for the Vision Processing Unit with a Hybrid Deep Neural Network Accelerator. Micromachines. 2022; 13(2):268. https://doi.org/10.3390/mi13020268
Chicago/Turabian StyleLiu, Peng, Zikai Yang, Lin Kang, and Jian Wang. 2022. "A Heterogeneous Architecture for the Vision Processing Unit with a Hybrid Deep Neural Network Accelerator" Micromachines 13, no. 2: 268. https://doi.org/10.3390/mi13020268
APA StyleLiu, P., Yang, Z., Kang, L., & Wang, J. (2022). A Heterogeneous Architecture for the Vision Processing Unit with a Hybrid Deep Neural Network Accelerator. Micromachines, 13(2), 268. https://doi.org/10.3390/mi13020268