1. Introduction
Fruit-picking robots are a class of agricultural machines that combine the advantages of the accuracy, efficiency, and characteristics of diverse sensors. They primarily perform automatic operations for crops in natural environments [
1,
2,
3,
4,
5,
6]. Among them, the deployment of machine vision systems and corresponding recognition algorithms allows them to efficiently complete many harvesting operations. In current research, stereo vision techniques especially have been used by numerous researchers, while the flourishing of artificial intelligence and deep learning methods have provided better solutions for fruit recognition, thus allowing robots to adapt to orchard environments with complex backgrounds, uneven lighting, and low color contrast [
7,
8,
9,
10,
11].
Further research on fruit picking has focused on how to build a compact, coordinated, and practical fruit-picking robot based on existing high-performance stereo vision systems and the algorithms suitable for that type of fruit object and its realistic environment [
12]. There have been some representative cases in this regard. Wang et al. proposed a litchi-picking robot based on a binocular stereo-vision-based system, which can separate and locate litchi in an unstructured realistic environment. The authors used an improved K-means clustering method to separate and a label template algorithm to locate fruit. Besides having good detection effects on nonoccluded and partially occluded litchi, their segmentation algorithm is robust to the influences of varying illumination [
13]. Cao et al. solved the problem of obstacles, thus avoiding changing and unstructured environments for their litchi-harvesting robots. Their improved method, rapidly exploring random tree, was tested in both virtual and realistic environments, where two CCD cameras assisted in capturing scene information. The target gravity method and a genetic algorithm enhanced the speed and accuracy of the computation, thus successfully driving the manipulator to the target location without collision [
14]. Wang et al. proposed a citrus fruit picking robot composed of a manipulator, binocular camera, personal computer, and tracked vehicle. They introduced a bite-mode end-effector with an improved harvesting postures prediction method and applied it to a fruit-picking robot. Through experimentations in both laboratory and natural environments, the harvesting results in the optimal posture had good performance [
15]. Kalampokas et al. developed an autonomous grape harvesting robot that can reduce harvesting time by detecting grape stems in images. For this purpose, a regression convolutional neural network was deployed for finishing a stem segmentation task, which provides higher correct identification rates in highly changing environments [
16]. Williams et al. introduced a new multi-arm kiwifruit harvesting robot working in pergola style orchards. The fruit picking robot consists of four picking robotic arms and corresponding end-effectors. With the assistance of deep neural networks as well as stereo matching methods, field implementation for detection and picking in commercial orchards was achieved [
17]. In recent studies, increasing attention and effort for visual picking robots were shifted to working performance, including better environmental adaptability and stability of the harvesting process. Xiong et al. introduced a robot incorporating a CCD industrial camera with an LED illuminating source and formed a nocturnal image acquisition system for achieving the recognition of litchi and picking points in the nighttime environment. The YIQ color model was used and the fruits and stems were removed by an improved fuzzy clustering algorithm through the study of images collected in both day and night environments, with the final picking point determined mathematically [
18]. Liang et al. also proposed a method for detecting litchi fruits and stems in the nighttime environment and achieved detection based on U-Net. In their work, after the processes to the bounding boxes of the YOLOv3, the regions of interest (ROI) of the stems were obtained. Through segmentation of the U-Net, the average precision in low-brightness can reach 89.30% [
19]. Ye et al. introduced robot-arranged two-step collision-free motion planning based on the binocular stereo vision information. The spatial environment information was used to solve the robot’s inverse kinematics problem using an improved adaptive weight particle swarm optimization algorithm to determine collision-free poses, while the improved Bi-RRT algorithm was used to achieve more accurate and faster path planning [
20].
The above studies have successfully applied stereo vision in fruit-picking robots and considered the impact of various aspects on harvesting. However, most of them have used huge, cumbersome industrial cameras, which can easily damage fruit during harvesting and are expensive to replace. In addition, these systems require a lot of computing power and calculation time for spatial localization and stereo matching, with the algorithm for fruit stem recognition also being complex, and migrate poorly between different types of fruit. These problems have also led to difficulties in commercializing fruit-picking robots; four directions, such as simplifying the tasks and enhancing robots, have been proposed to guide researchers to make more attempts [
21]. In summary, solving the above problems requires vision hardware that is more integrated, stable, and suitable to the unstructured environment of fruit picking. In addition, the development of more general algorithms based on this process is required [
22].
The advent of depth cameras offers an economical solution for building three-dimensional (3D) optical coordinate measurement systems. Compact dimensions, low cost, and ease of secondary development yield such cameras, an increasingly popular hardware option for fruit-picking robots [
23]. Liu et al. proposed a strategy for recognizing and locating citrus fruits in a close shot-based strategy on a Realsense F200 Camera (Intel Corp., Santa Clara, CA, USA). Using an intersection curve cut by the depth-sphere, six different fruit varieties were identified and the background removed, which might contribute to high real-time harvesting robots [
24]. For harvesting in an irregular environment, Li et al. developed a reliable algorithm for detecting litchi fruit-bearing branches in large complex environments. Therein, Deeplabv3 was employed to distinguish the content of RGB images acquired by a Kinect V2 camera into three categories. The fruit-bearing branches belonging to the same cluster are identified by skeleton extraction, pruning operations, and spatial clustering. Finally, the positions of the branches are obtained using a 3D linear fitting [
25]. Zhong et al. have used a YOLACT real-time instance segmentation network to locate fruit picking points based on the detection of litchi main fruit bearing branches (MFBB) and defined the robot picking posture by MFBB masking using skeleton extraction and least square fitting. The data obtained for the performance of test sets from different image sensors show that Kinect DK depth cameras can meet the needs of network training [
26]. Yu et al. proposed a ripe litchi-recognition method using a Kinect V2 Red-Green-Blue Depth camera to capture multiple types of data. A random-forest binary classification model employing color and texture features was trained to recognize litchi fruit, whose dataset combined depth data and color data [
27]. Fu et al. used a low-cost Kinect V2 camera to build an apple-picking background-separation vision system in a modern orchard to guide the robot in precise, collision-free harvesting. Using a deep learning network based on depth features to filter background objects, the authors demonstrated that the algorithm can improve fruit detection accuracy and is expected to be applicable for robotic harvesting on fruiting-wall apple orchards [
28].
In fact, while consumer-grade depth cameras have made it easier to build vision systems for fruit-picking robots, there are still many hardware and depth-measurement technical limitations [
29,
30]. For example, point clouds obtained by depth cameras based on structured-light methods frequently include hole regions caused by missing depth information, which, along with lighting variations, have a large impact on image quality [
31]. These drawbacks all lead to difficulties in acquiring high-quality, dense-point cloud data of fruit stems, making it difficult to research fruit-picking robots targeting fruit stems. Therefore, a fruit-picking system that takes the hardware and software conditions of the depth camera into account is urgently needed. Compared with traditional stereo vision, the depth camera’s advantages in terms of shape and access to information can be exploited, while the picking point can be located within the allowed error range according to fruit characteristics.
The coordinated control of long-close distance has been proposed in other studies of picking strategies. Problems, such as complicated image information and insufficient representation of detailed features, have been solved. However, some solutions regard fruit bunches as a unit and cannot obtain information of the fruit number as well as their shape and some have low accuracy in acquiring the close-distance recognition position. Inspired by the work of other researchers, a litchi-picking robot was designed here based on the Intel Realsense D435i depth camera (Intel Corp., Santa Clara, CA, USA) and a long-close distance coordination control strategy proposed for bunches of fruit. The main contribution of this study included:
An eye-in-hand vision system was built for a consumer-grade depth camera and a long-close distance recognition strategy designed to meet actual positioning habits.
A density-based spatial point cloud clustering method was used to classify irregularly shaped fruit bunches, while a YOLOv5 convolutional neural network identified individual litchi.
A MaskRCNN instance segmentation network was used to segment bunches and bifurcate stems in a scene and extract the fruit-bearing branch positions based on mask relationships.
Depth reference points and fruit stalk positioning lines were introduced to reduce the impact of depth camera accuracy, thus enabling the position determination of the fruiting-bearing branches at a close distance.
The remainder of this study is organized as follows: In
Section 2, the hand–eye coordination strategy and methods of recognition at different distances are briefly described. In
Section 3, the experimental materials and methods are presented, followed by the results and corresponding subsequent analyses. Finally, the conclusions and future work are summarized in
Section 4.
2. Materials and Methods
2.1. Overall Framework
An eye-in-hand vision system based on a D435i camera and 6-degree-of-freedom robotic arm (RUOBO Corp., Foshan, Guangdong, China) was constructed. The litchi picking robot system was comprised of two modules, namely an eye-in-hand system and hand–eye coordination control strategy. The strategy was divided into two processes, including fruit-cluster location and picking-point location (
Figure 1).
The eye-in-hand system module was implemented based on the binocular visual stereo calibration method. The configuration of the image sensors and ease of using the official application programming interface (API) were taken into account, enabling determination of the correlation between the camera and robotic arm.
The hand–eye coordination control strategy module was divided into two steps. The first was to perform long-distance fruit cluster recognition, thus separating the clusters and obtaining close-distance recognition points. Second, taking into account the accuracy of the Realsense camera (Intel Corp., Santa Clara, CA, USA), the robot arm, being close to the bunch, obtained a close shot. The algorithm was then called to segment the litchi string and stem bifurcations, then predict the final picking point.
The position information obtained by locating the fruit bunch twice in the long- and close-distance enabled coordinated hand-eye control, and the method could be adapted to other types of bunch-fruit picking.
2.2. Eye-in-Hand System
Before sampling with the D435i depth camera, camera and hand–eye calibrations were required. Considering the sensor configuration of the depth camera (
Figure 2), infrared radiation (IR) stereo cameras (Intel Corp., Santa Clara, CA, USA) were chosen for binocular calibration, implemented through the classic Zhang’s method [
32]. The hand–eye calibration was based on Chen’s method, which obtained the coordinate transformation relationship of the left IR camera to the base of the robotic arm [
12]. Due to the lack of color features in IR camera images and the API, the depth stream needed to be aligned to the color stream. From this, the coordinate transformation relationship was obtained between the two cameras to obtain a better-quality image for the construction of the deep-learning network dataset. Therefore, it was necessary to consider the coordinate transformation relationship between the RGB camera coordinate system and the left IR camera coordinate system during hand–eye calibration.
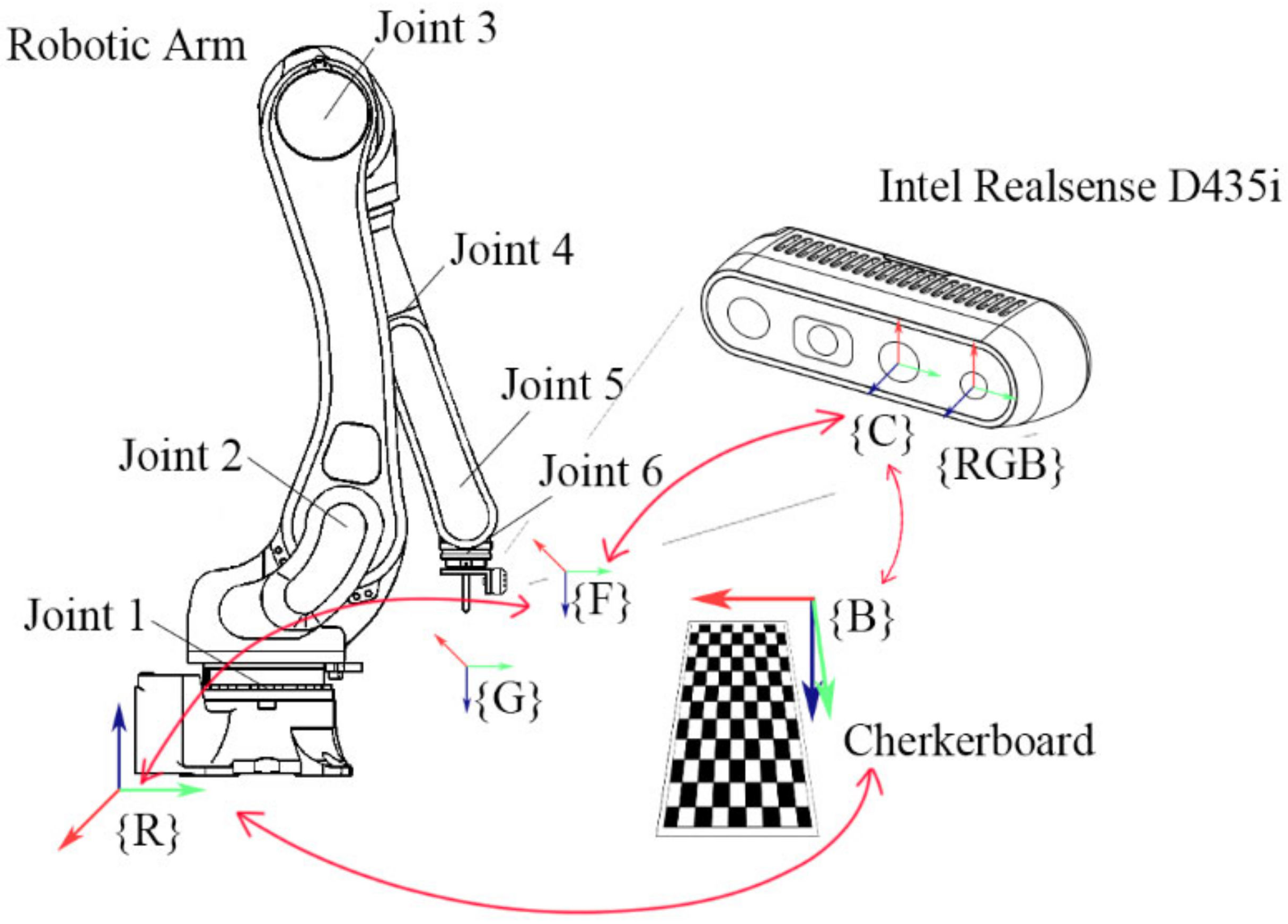
A checkerboard was placed in front of the robotic arm as a reference for the calibration process. The relationship of each coordinate system is shown in
Figure 3, with the two coordinate systems arranged on the depth camera. The coordinate system for each marker, described in turn, was {R} is the robotic arm coordinate system, {F} the flange coordinate system, {C} the left IR camera coordinate system, {RGB} the RGB camera coordinate system, {B} the checkerboard coordinate system, and {G} the end-effector coordinate system. The hand–eye calibration required constant adjustment of the arm’s posture to allow the camera to sample from different positions, and it was seen that two of the coordinate system relationships were fixed for each movement. These were the relationships of {R} to {B} and {C} to {F}.
According to the basic principles of the coordinate transformation, the coordinate transformation chain was described as
where
is the unit matrix. To obtain the coordinate transformation relationship between the tool (hand) and camera (eye), some transformations yielded
where
is the transformation matrix of {B} relative to {C}. As mentioned above, the robotic arm was adjusted to different
th postures from which a matrix was obtained by the least square method [
33]. Then,
is the transformation matrix of {R} relative to {B}, which was calibrated by the origin of {G} to approach the origin, and the
x and
y-axes of {B}. Finally, the
was recorded to obtain the transformation matrix of {F} relative to {R}, in every
th posture that could be calculated by forward kinematics.
Using the following calculations, the
coordinate transformation relationship was obtained, expressed as
where
is the number of different poses. In the present method,
was 15.
After calculating the hand–eye relationship, the coordinates of the target point in the left IR camera coordinate system ({C}) were obtained, and the position relative to the base coordinate system of the robotic arm ({R}) was calculated. The camera API provided a convenient function that allowed the selection of a point in the aligned image and the corresponding depth information obtained using the structured-light method, which meant that the aligned image was selected as the input for object detection.
However, the images acquired by the left IR camera were missing color information, and if the color stream was aligned to the depth stream, there would be many holes in the image. This would thus affect the training effect of the subsequent training of the convolutional neural network (CNN). Therefore, a transformation matrix from the color camera coordinate system ({RGB}) to the left IR camera coordinate system was introduced, expressed as
. By checking the sensor configuration of the depth camera, the origin of the left IR camera coordinate system was found to be on the y-axis of the color camera coordinate system. The distance between these two origins of coordinates was 15 mm, such that it was possible to define
as
Thus, the final hand–eye transformation relationship was
2.3. Hand-Eye Coordination Control Strategy
The D435i camera has a wider field of view than do D415 and D455 cameras and has a global shutter format that is more suitable for variable environments. This allows the D435i camera to capture more information at once about the environment and resist depth image blur. Comparing the parameters of these three cameras, the D435i camera has a smaller ”min z” (distance from the depth camera to the captured object), which meant that the D435i camera could be used at a closer distance to the stems and thus had better detection performance. Thus, the D435i camera was chosen for building a robotic arm vision system based on the above comparison.
Servi et al. proposed a method for testing the effects of sampling distance to the imaging accuracy using different Realsense cameras, with results that illustrated that the farther the working distance is, the worse the results in image sampling. The structured-light measurement method also predetermines the working distance and condition of the target surface, which are two important influencing factors [
34].
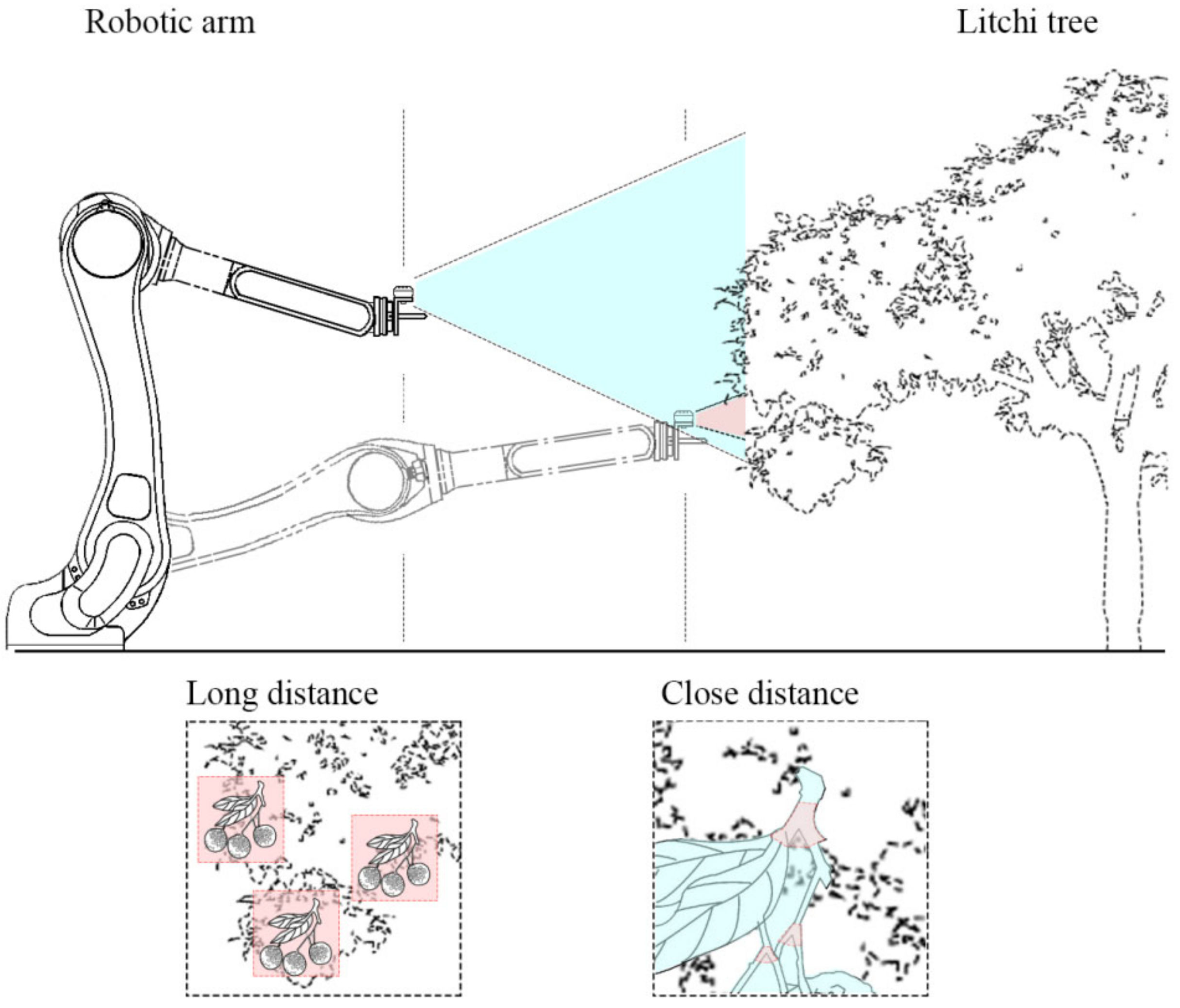
A two-stage hand–eye coordination control strategy was proposed based on such a situation (
Figure 4).
Referring to the appropriate working-distance range of the D435i camera, the robotic arm first drove the camera at a long distance where it captured (identified) fruit bunches in a partial area of a tree in order to segment different fruit bunches and plan the picking route. After determining the close-distance recognition point, the robot arm was driven closer to the target bunch to identify the bifurcate stems and the whole litchi bunch. Compared with detecting a stem, bifurcate stems have more distinct features and thus are easier for study by neural networks.
Such a hand–eye coordination control strategy could be adapted to other bunch-fruit-picking operations, making full use to the high efficiency feature of the depth camera for achieving long-distance coarse positioning. The effects of the target scale can also be minimized, with the selection of segmentation bifurcate stems also improving the success rate, thus completing the operation within the error range of fruit picking.
2.4. Fruit Clusters Location
The first part of the hand–eye coordination control strategy was to perform long-distance location, in which the robotic arm was controlled far away from the bunches. The purpose at this stage was to locate and separate bunches in the field of view to determine the picking sequence as well as to guide the close-distance location.
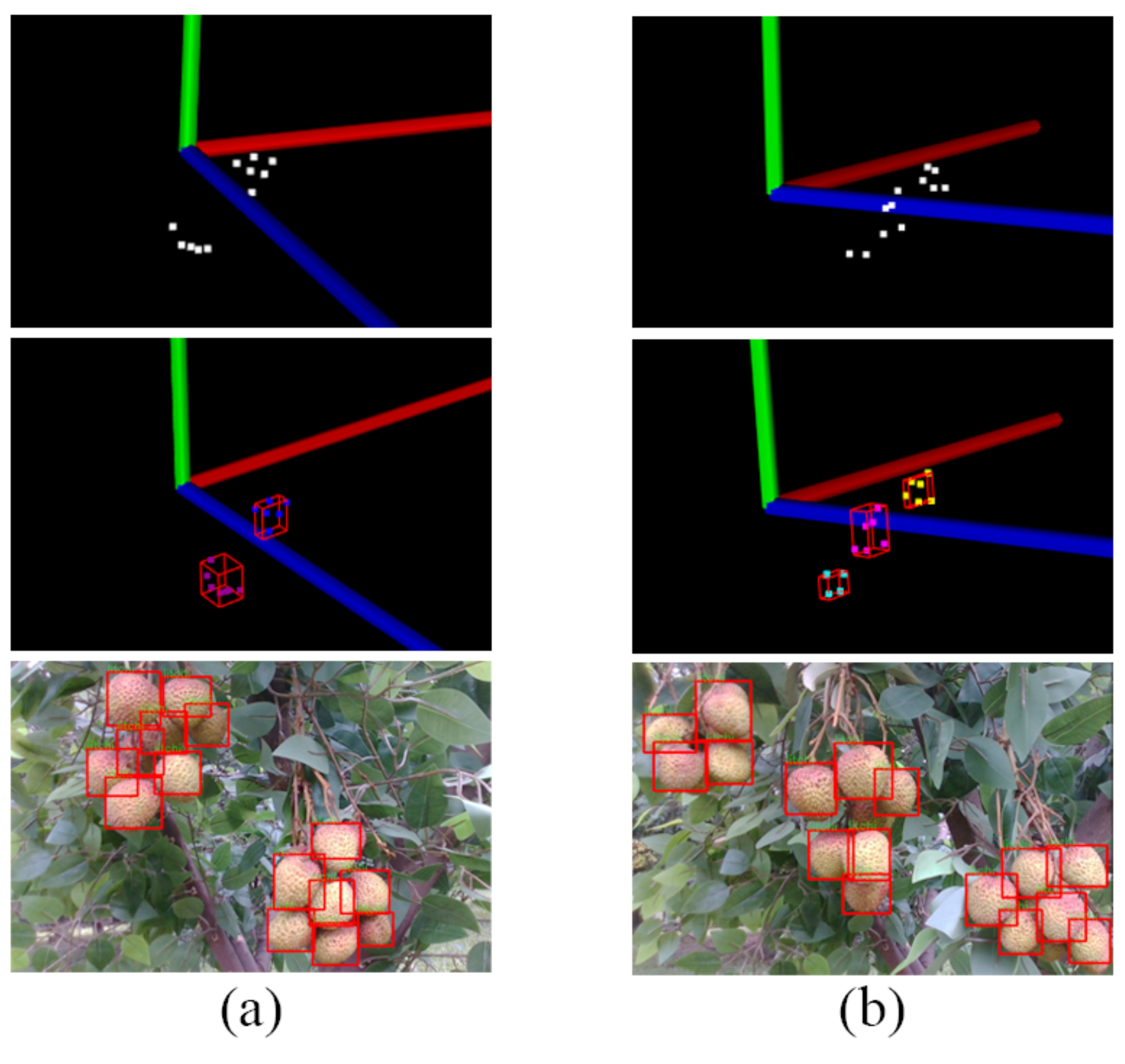
The specific operation was to use the YOLOv5 convolutional neural network to detect individual litchi and obtain its bounding box. Then, we used the Realsense camera to obtain the depth information of the center of bounding box and simulate each litchi in 3D space. Next, density-based spatial clustering of applications with noise (DBSCAN) was used to separate the clusters, and a 3D minimum enclosing box was finally created for each cluster to determine its approximate location in space. The overall schematic is shown in
Figure 5.
YOLO is a regression method based on deep learning, which has been developed through four versions from YOLOv1 to YOLOv4 [
35,
36]. Through continuous innovation and improvement, it has attained top performance. Here, the recent YOLOv5 network was chosen for the detection of litchi individuals by considering the aspects discussed below; the network architecture is shown in
Figure 6.
Four features of YOLOv5 led to its selection as the target detection network. First, the input of YOLOv5 chose the same mosaic data enhancement method as YOLOv4. In long-distance location, the environment exists with different depth positions and different litchi sizes, which is quite advantageous for detecting litchi fruits with smaller scales using this method. Second, YOLOv5 introduces two cross-state partial network structures, which allows the model to efficiently identify a large number of litchi individuals in the field of view. Immediately afterward, YOLOv5 introduces the structure of the feature pyramid network (FPN) and path aggregation as its neck, which enhances the flow of feature information in the network and is a significant improvement, especially for the learning of low-level features. Finally, the head of the YOLOv5 network outputs multi-scale feature maps, which, combined with the data enhancement method at the input, allows the network to handle litchis of different volumes.
After completing object detection, the camera was used to obtain the depth value of the center of each bounding box and the coordinates of each litchi at the camera coordinate system calculated based on the calibration parameters. For the subsequent spatial-point cloud clustering operation, the obtained coordinate information was input to the point cloud library (PCL) in the form of point cloud objects, and the attributes were set according to the average size of the real litchi fruit.
DBSCAN is a density-based spatial clustering algorithm that divides regions into clusters that reach the set parameters and finds clusters of arbitrary shapes in a spatial database with noise [
37]. The algorithm has good results for dividing bunches of fruits with irregular shapes, as with litchi.
After determining the dataset to be clustered, two parameters were first initialized, namely and . Specifically, referred to the domain radius of the search, and the minimum number of points to determine a core point. It was also specified that all points of the dataset were classified into three types of points: core points, points that contain more than the number of within the range of ; boundary points, points that have less than in the radius but fall in the neighborhood of the core points; and noise points, points that are neither core points nor boundary points.
First, any point in the dataset or the point with the largest neighborhood density was selected as the starting point, and if the point was not classified as a certain cluster or not a boundary point, it was determined whether it was a core point.
If the point was not a core point, it was classified as a boundary point or a noise point, and the starting point was reselected. If the point was a core point, it was classified into a new cluster, and all non-noise points in the neighborhood were grouped into this new cluster. After that, the points within this cluster that had not yet been classified were checked and classified in the same way until all points in the dataset were labeled.
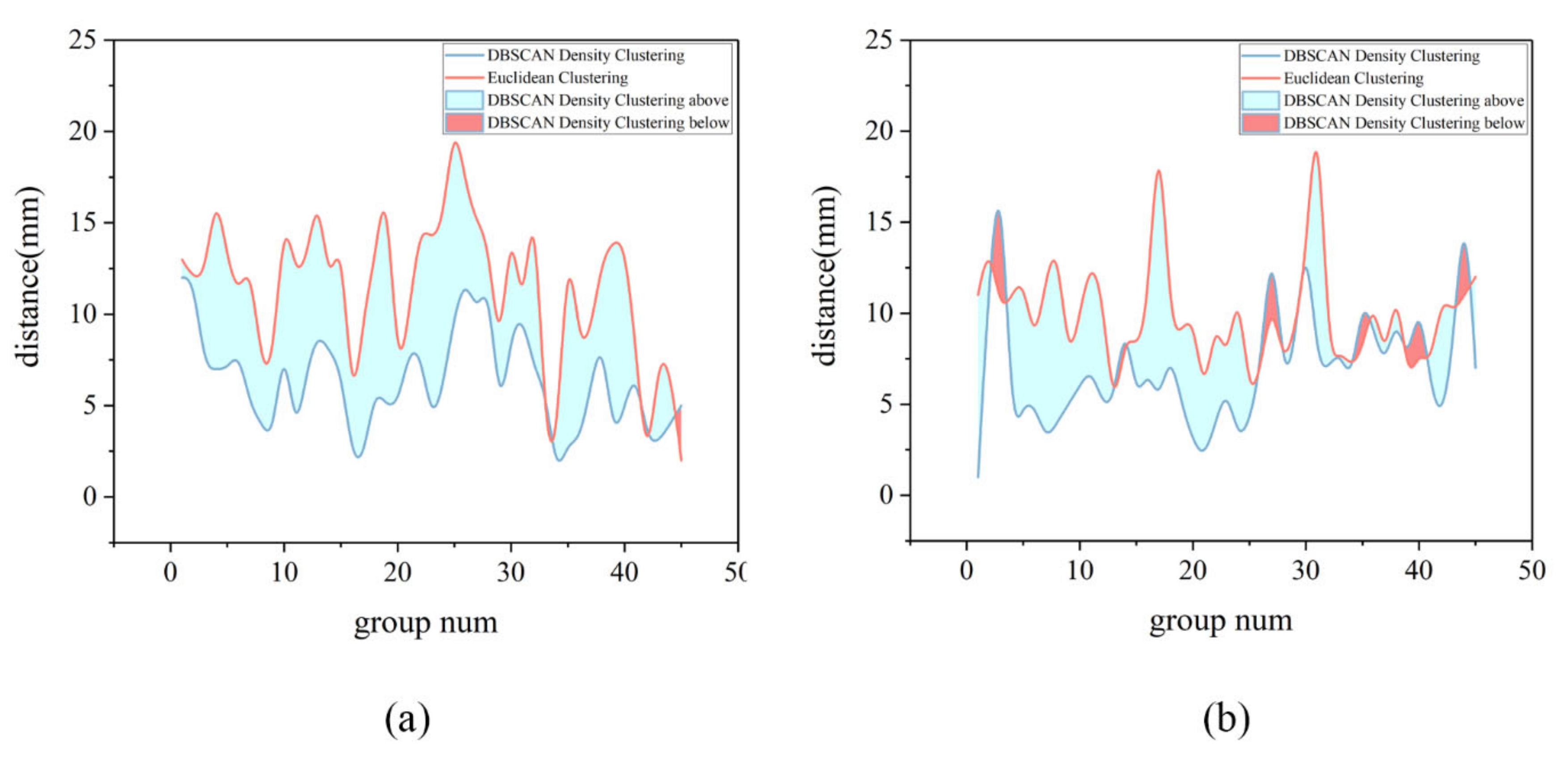
In the reality of the harvesting process, different litchi bunches usually have touching, shading, and other spatial location relationships, which are not conducive to segmentation. At the same time, the shape of the bunches is random, such that the traditional clustering method based on Euclidean distance is prone to mis-segmentation. The DBSCAN method can adapt to various shapes of bunches and take into account the growth characteristics; also, the clustering results in a single direction reflect the complete fruit distribution characteristics. Moreover, this method is not affected by the shape of individual fruit and has good performance with other kinds of bunches of fruits.
After clustering, the 3D minimum enclosing boxes of different clusters was obtained, and the corresponding close-distance recognition points were calculated.
2.5. Picking Point Location
After the robotic arm drove the camera close to the close-distance recognition point, the next step was to identify the fruiting-bearing branches of that litchi bunch. Due to the small scale and lack of features, it was difficult to make a direct identification. Meanwhile, the Realsense camera was prone to returning wrong results when acquiring depth information of fine objects due to the method of structured light. All these reasons indicated that it was not feasible to directly acquire the spatial information of fruiting-bearing branches.
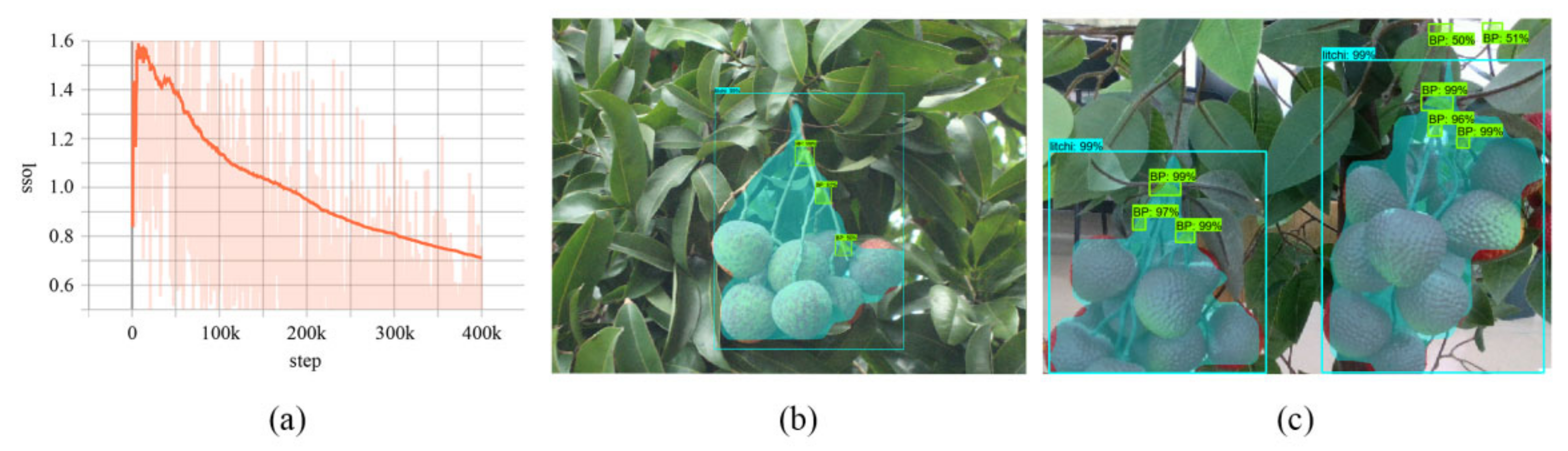
From the characteristics of the camera and the shape of litchi bunches, the instance segmentation network MaskRCNN was first used to segment the litchi bunches with picking stems in the field of view. Additionally, the bifurcate stems with obvious features and large scales were detected. After that, the bifurcate stems were filtered to determine the main bifurcate stems of the center cluster and to locate the fruit-bearing branch’s mask. Then, the mask was extracted using Zhang’s thinning algorithm and the points on the skeleton line obtained using the Realsense camera. Finally, a “Point + Line” spatial point cloud was formed with the center point of the main bifurcate stem and a spatial straight line was fitted to obtain the spatial position of the fruit-bearing branch. A schematic diagram of the above process is shown in
Figure 7 [
38].
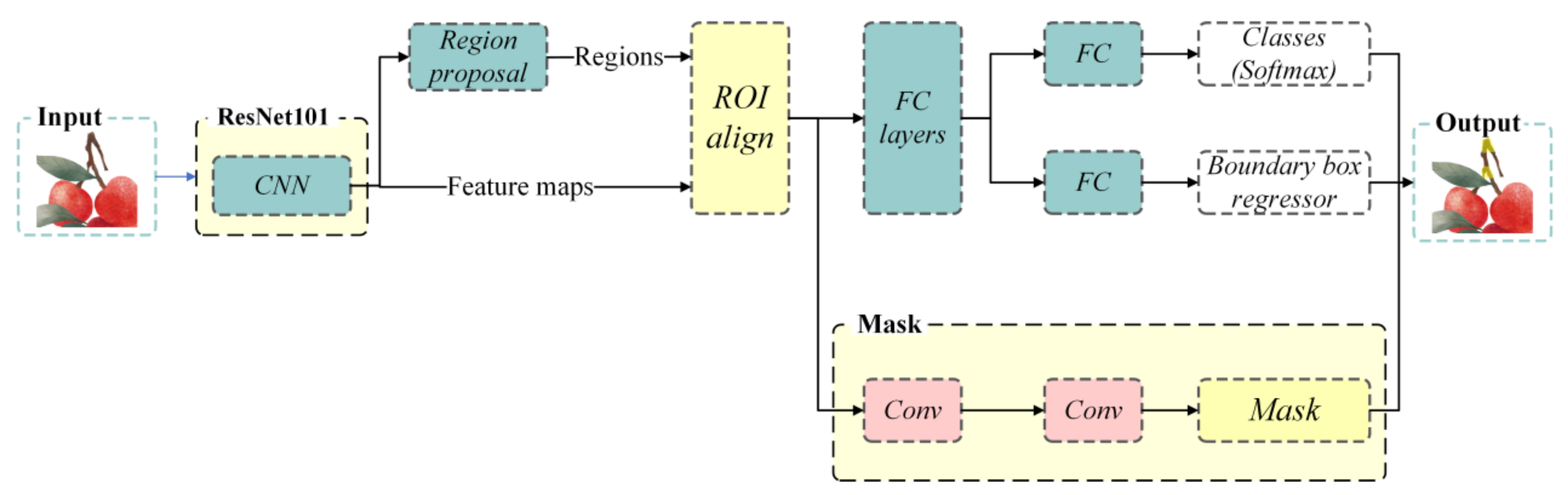
MaskRCNN is an instance segmentation network, which adds a branch of prediction segmentation mask to FasterRCNN, replacing the ROI pooling layer with an ROI align layer and adding a parallel FCN layer (mask layer). The structure of the network is shown in
Figure 8 [
39,
40].
MaskRCNN introduced the ROI align layer to obtain image values on the pixel points with floating point coordinates, thus improving the detection accuracy and facilitating segmentation of fine bifurcate stems. The backbone used a FPN network, which improved detection accuracy by inputting a single-scale image and finally obtaining a corresponding feature pyramid. These features make the MaskRCNN network work stably in the segmentation of litchi strings and bifurcate stems.
As long-distance location brought the camera close to a certain bunch of litchi, after segmenting the different litchi bunches and bifurcate stems in the scene, the bunch was selected whose center of mask was closest to the center of the image. All bifurcate stems whose center points were not within the bunch mask were then deleted, yielding the bifurcate stems belonging to that bunch. Then, the uppermost bifurcate stem was selected as the main bifurcate stem, and the part of the bunch mask above it was extracted as the fruit-bearing branch area.
After obtaining the fruit-bearing branch mask, the skeleton of the mask was extracted using Zhang’s thinning algorithm, which was used to refine the fruit-bearing stem’s mask and obtain a reference line. As the main bifurcate stem had a large scale, the depth value obtained using Realsense was more reliable such that the center point of the main bifurcation branch was used as a depth reference point. The resulting positioning line finally obtained the poses of the fruit-bearing branches to guide the final picking work. This method reduced the impact of outliers on the results, which was very helpful for reducing the impact caused by camera error sampling. The schematic is show as
Figure 9.
This method took into account the importance of the bifurcate stem of the fruit pedicel for position location of the fruit pedicel and the accuracy of the depth camera for obtaining depth. This used more reliable “points” to help fit more accurate spatial straight lines. Overall, such a method was feasible for most bunches of fruit.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}