


Accurate Detection Algorithm of Citrus Psyllid Using the YOLOv5s-BC Model


Abstract
:1. Introduction
2. Analysis and Design of YOLOv5s-BC Algorithm
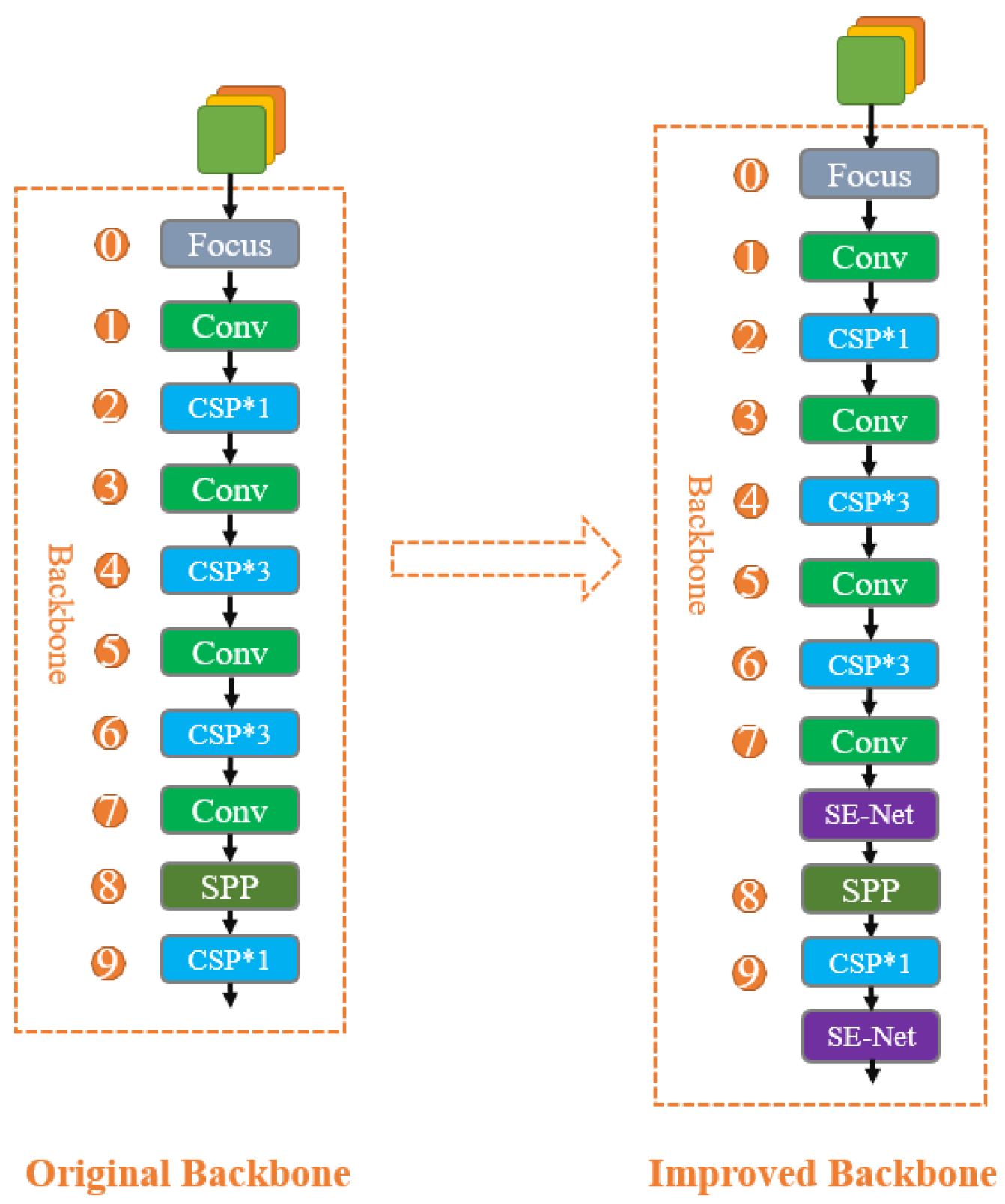
2.1. YOLOv5s Algorithm
2.2. SE-Net Attention Module
2.3. BottleneckCSP_C Module
2.4. Mosaic Data Enhancement
3. Experimental Design and Analysis
3.1. Experimental Data Collection and Data Set Construction
3.2. Experimental Parameters and Indicators
3.3. Ablation Contrast Experiment
3.4. Analysis of Different Attention Modules
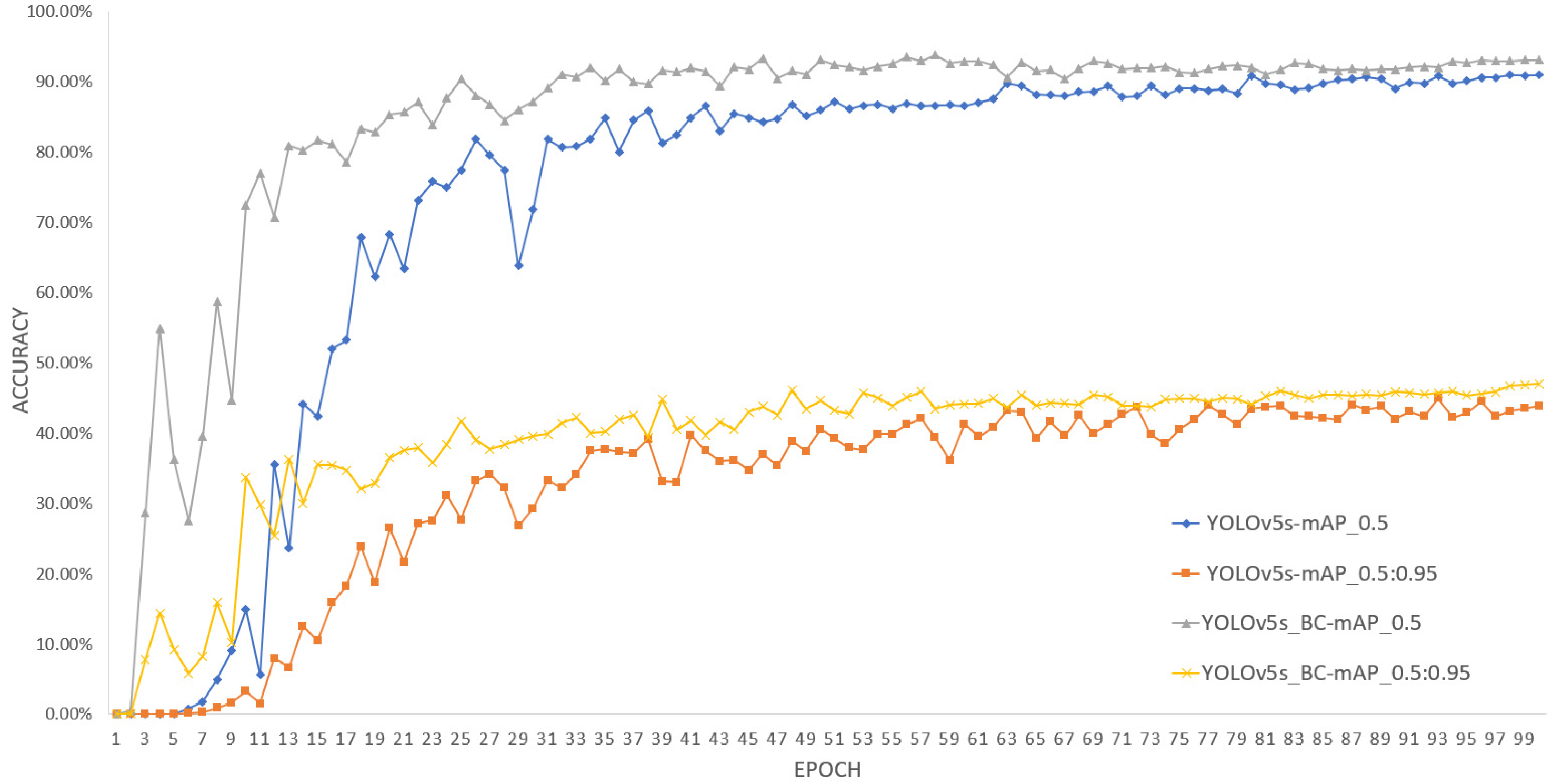
3.5. Training Results
3.6. Comparison of Test Results
3.7. Comparison with Existing Target Detection Algorithms
3.8. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lan, Y.; Zhu, Z.; Deng, X.; Lian, B.; Huang, J.; Huang, Z.; Hu, J. Monitoring and classification of citrus uanglongbing based on UAV hyperspectral remote sensing. Trans. Chin. Soc. Agric. Eng. 2019, 35, 92–100. (In Chinese) [Google Scholar]
- Zou, M.; Song, Z.; Tang, K.; Dong, P.; Zou, C. Comparing of micro extraction methods of DNA from citrus huanglongbing pathogen. Plant Quar. 2005, 271–274. (In Chinese) [Google Scholar]
- Luo, Z.; Ye, Z.; Xu, J.; Hu, G. Field diagnostic methods of Citrus Yellow Dragon disease. Guangdong Agric. Sci. 2009, 91–93. (In Chinese) [Google Scholar] [CrossRef]
- Planet, P.; Jagoueix, S.; Bové, J. Detection and characterization of the African citrus greening Liberobacter by amplification, cloning, and sequencing of the rpl KAJL-rpo BC operon. Curr. Microbiol. 1995, 30, 137–141. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C. The status of citrus Huanglongbing in China. Trop. Plant Pathol. 2020, 45, 279–284. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, L.; Shen, Y.; Zhang, J.; Wu, B. Real-time Pedestrian Detection in Orchard Based on Improved SSD. Trans. Chin. Soc. Agric. Mach. 2019, 29–35+101. (In Chinese) [Google Scholar]
- Li, L.; Zhang, S.; Wang, B. Plant disease detection and classification by deep learning—A review. IEEE Access 2021, 9, 56683–56698. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jing, L.; Wang, R.; Liu, H.; Shen, Y. Orchard Pedestrian Detection and Location Based on Binocular Camera and Improved YOLOv3 Algorithm. Trans. Chin. Soc. Agric. Mach. 2020, 51, 34–39+25. (In Chinese) [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single shot multiBox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- You, J.; Lee, J. Offline mobile diagnosis system for citrus pests and diseases using deep compression neural network. IET Comput. Vis. 2020, 14, 370–377. [Google Scholar] [CrossRef]
- Xing, S.; Lee, M.; Lee, K.-K. Citrus pests and diseases recognition model using weakly dense connected convolution network. Sensors 2019, 19, 3195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xing, S.; Lee, M. Classification accuracy improvement for small-size citrus pests and diseases using bridge connections in deep neural networks. Sensors 2020, 20, 4992. [Google Scholar] [CrossRef]
- Kuzuhara, H.; Takimoto, H.; Sato, Y. Insect pest detection and identification method based on deep learning for realizing a pest control system. In Proceedings of the 2020 59th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Chiang Mai, Thailand, 23–26 September 2020. [Google Scholar]
- Wang, L.; Lan, Y.; Liu, Z. Development and experiment of the portable real-time detection system for citrus pests. Trans. Chin. Soc. Agric. Mach. 2021, 37, 282–288. (In Chinese) [Google Scholar]
- Li, H.; Long, C.; Zeng Meng Shen, J. A detecting method for the rape pests based on deep convolutional neural network. J. Hunan Agric. Univ. (Nat. Sci.) 2019, 560–564. (In Chinese) [Google Scholar] [CrossRef]
- Yang, Q.; Li, W.; Yang, X.; Yue, L.; Li, H. Improved YOLOv5 Method for Detecting Growth Status of Apple Flowers. Comput. Eng. Appl. 2022, 237–246. (In Chinese) [Google Scholar]
- Masd, S.; Codire, L.; Morier, G. Evaluating the Single-Shot Multi Box Detector and YOLO Deep Learning Models for the Detectionof Tomatoes in a Green house. Sensors 2021, 21, 3569. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Press: New York, NY, USA, 2018; pp. 7132–7141. [Google Scholar]
- Lin, X.; Liu, J.; Tian, S. Image description generation method based on multi-space mixed attention. J. Comput. Appl. 2020, 40, 985–989. (In Chinese) [Google Scholar]
- Cheng, M.; Gai, Y.; Da, F. A Stereo-Matching Neural Network Based on Attentio n Mechanism. Acta Opt. Sin. 2020, 40, 1415001. (In Chinese) [Google Scholar] [CrossRef]
- Hsu, W.; Lin, W. Adaptive Fusion of Multi-Scale YOLO for Pedestrian Detection. IEEE Access 2021, 110063–110073. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, H.; Peng, J. Research on the Use of YOLOv5 Object Detection Algorithm in Mask Wearing Recognition. World Sci. Res. J. 2020, 6, 230–238. [Google Scholar]
- Lei, G.; Qiulong, W.; Wei, X.; Ji, G. A Small Object Detection Algorithm Based on Improved YOLOv5. J. Univ. Electron. Sci. Technol. China 2022, 2022, 251–258. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | R/% | [email protected]/% |
|---|---|---|---|
| YOLOv5s | 88.20 | 83.31 | 91.02 |
| YOLOv5s + SE-Net (10th layers) | 98.51 | 86.02 | 91.49 |
| YOLOv5s + SE-Net (8th layers) | 90.21 | 85.53 | 92.40 |
| YOLOv5s + SE-Net (8th and 10th layers) | 89.81 | 88.01 | 93.12 |
| YOLOv5s + BottleneckCSP_C | 91.52 | 86.01 | 92.67 |
| YOLOv5s + SE-Net (8th layers) + BottleneckCSP_C | 91.63 | 87.04 | 93.25 |
| YOLOv5s + SE-Net (10th layers) + BottleneckCSP_C | 90.63 | 87.04 | 91.82 |
| YOLOv5s + SE-Net (8th and 10th layers) + BottleneckCSP_C | 89.51 | 87.53 | 93.43 |
| Serial Number | From | Params | Module | Arguments |
|---|---|---|---|---|
| 0 | −1 | 3530 | Focus | (3, 32, 3) |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | −1 −1 −1 −1 −1 −1 −1 −1 −1 −1 −1 −1 −1 (−1, 6) −1 −1 −1 (−1, 4) −1 −1 (−1, 16) −1 −1 (−1, 12) −1 (19, 22, 25) | 18,560 19,968 73,984 161,280 295,424 6,442,048 1,180,672 131,072 656,896 1,249,280 131,072 131,584 0 0 378,880 33,024 0 0 95,232 147,712 0 313,344 590,336 0 1,249,280 16,182 | Conv BottleneckCSP_C Conv BottleneckCSP_C Conv BottleneckCSP_C Conv SELayer SPP BottleneckCSP_C SELayer Conv Upsample Concat BottleneckCSP_C Conv Upsample Concat BottleneckCSP_C Conv Concat BottleneckCSP_C Conv Concat BottleneckCSP_C Detect | (32, 64, 3, 2) (64, 64, 1) (64, 128, 3, 2) (128, 128, 3) (128, 256, 3, 2) (256, 256, 3) (256, 512, 3, 2) (512, 4) (512, 512, (5, 9, 13)) (512, 512, 1, False) (512, 4) (512, 256, 1, 1) (None, 2, ‘nearest’) (1) (512, 256, 1, False) (256, 128, 1, 1) (None, 2, ‘nearest’) (1) (256, 128, 1, False) (128, 128, 3, 2) (1) (256, 256, 1, False) (256, 256, 3, 2) (1) (512, 512, 1, False) (1, ((10, 13, 16, 30, 33, 23), (30, 61, 62, 45, 59, 119), (116, 90, 156, 198, 373, 326)), (128, 256, 512)) |
| Model | P/% | R/% | [email protected]/% | [email protected]:.95/% | Parameters |
|---|---|---|---|---|---|
| YOLOv5s | 88.20 | 83.31 | 91.02 | 43.83 | 7,255,094 |
| YOLOv5s + SE-Net (10th layers) | 98.51 | 86.02 | 91.49 | 42.61 | 7,386,166 |
| YOLOv5s + SE-Net (8th layers) | 90.21 | 85.53 | 92.40 | 44.36 | 7,386,166 |
| YOLOv5s + SE-Net (8th and 10th layers) | 89.81 | 88.01 | 93.12 | 47.02 | 7,517,238 |
| YOLOv5s + CBAM (10th layers) | 89.99 | 86.54 | 91.31 | 43.04 | 7,288,505 |
| YOLOv5s + CBAM (8th layers) | 85.98 | 88.15 | 91.55 | 44.62 | 7,288,505 |
| YOLOv5s + CBAM (8th and 10th layers) | 89.89 | 87.26 | 91.73 | 46.46 | 7,321,916 |
| Model | Data | P/% | R/% | [email protected]/% | [email protected]:.95/% |
|---|---|---|---|---|---|
| YOLOv5s | Out-of-focus data | 88.91 | 84.22 | 91.84 | 47.15 |
| Close-range data | 95.55 | 95.61 | 97.12 | 52.47 | |
| Prospective data | 50.01 | 54.52 | 45.12 | 12.35 | |
| YOLOv5s-BC | Out-of-focus data | 96.84 | 81.67 | 94.39 | 47.51 |
| Close-range data | 95.74 | 97.83 | 97.44 | 56.26 | |
| Prospective data | 54.43 | 54.55 | 45.27 | 12.56 |
| Model | P/% | R/% | [email protected]/% | [email protected]:.95/% | Parameters |
|---|---|---|---|---|---|
| YOLOv5s | 88.20 | 83.31 | 91.02 | 43.83 | 7,255,094 |
| YOLOv5m | 91.31 | 84.02 | 89.03 | 46.57 | 21,485,814 |
| YOLOv5x | 92.31 | 84.02 | 91.93 | 47.15 | 88,433,654 |
| YOLOv5l | 96.54 | 83.02 | 92.21 | 46.67 | 47,393,334 |
| YOLOv3 | 85.33 | 81.01 | 85.21 | 42.65 | 61,523,734 |
| YOLOv3-tiny | 86.21 | 88.02 | 89.52 | 43.23 | 8,669,876 |
| Faster-RCNN | 87.11 | 88.38 | 89.94 | 44.63 | - |
| YOLOv5s-BC | 89.51 | 87.53 | 93.43 | 47.02 | 7,519,350 |
| Training Set img-Size | Test Set img-Size | [email protected]/% | [email protected]:.95/% | Pre-Process/ms | Inference/ms | NMS/ms | Speed/ms |
|---|---|---|---|---|---|---|---|
| 640 | 640 | 90.06 | 47.03 | 1.0 | 6.2 | 2.4 | 9.6 |
| 768 | 93.15 | 45.93 | 1.2 | 8.2 | 1.9 | 11.3 | |
| 896 | 84.31 | 87.26 | 1.8 | 7.4 | 1.9 | 12.1 | |
| 1024 | 84.66 | 41.68 | 2.4 | 8.7 | 1.7 | 12.8 | |
| 896 | 640 | 89.64 | 46.85 | 1.0 | 5.9 | 2.0 | 8.9 |
| 768 | 91.98 | 46.59 | 1.3 | 6.0 | 2.4 | 9.7 | |
| 896 | 93.43 | 47.02 | 1.8 | 8.7 | 1.4 | 11.9 | |
| 1024 | 91.40 | 47.51 | 2.4 | 9.1 | 2.5 | 14.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, S.; Ke, Z.; Li, Z.; Xie, J.; Zhou, X.; Liu, Y. Accurate Detection Algorithm of Citrus Psyllid Using the YOLOv5s-BC Model. Agronomy 2023, 13, 896. https://doi.org/10.3390/agronomy13030896
Lyu S, Ke Z, Li Z, Xie J, Zhou X, Liu Y. Accurate Detection Algorithm of Citrus Psyllid Using the YOLOv5s-BC Model. Agronomy. 2023; 13(3):896. https://doi.org/10.3390/agronomy13030896
Chicago/Turabian StyleLyu, Shilei, Zunbai Ke, Zhen Li, Jiaxing Xie, Xu Zhou, and Yuanyuan Liu. 2023. "Accurate Detection Algorithm of Citrus Psyllid Using the YOLOv5s-BC Model" Agronomy 13, no. 3: 896. https://doi.org/10.3390/agronomy13030896
APA StyleLyu, S., Ke, Z., Li, Z., Xie, J., Zhou, X., & Liu, Y. (2023). Accurate Detection Algorithm of Citrus Psyllid Using the YOLOv5s-BC Model. Agronomy, 13(3), 896. https://doi.org/10.3390/agronomy13030896