Data from a multi-year experiment in soybean will be used to illustrate the use of the JMP Add-In program for the selection of superior plants and lines in soybean. This data is included in the JMP Add-In.
3.1. Cycle 1: Unreplicated Honeycomb Design—Construction, Data Analysis and Selection of Best Plants
Seeds were obtained from the Foundation seed source of the soybean cultivar “Haskell”. Seeds were planted in an Unreplicated honeycomb design that evaluated 420 plants in 30 rows and 14 plants per row, using a plant spacing of 0.9 m. After emergence, hill plots were thinned to contain a single plant. Plants were harvested when they reached maturity [
2].
To construct the aforementioned unreplicated honeycomb design, the user can employ the following steps. From the JMP Add-Ins menu, select the
Prognostic Breeding Application and go to the
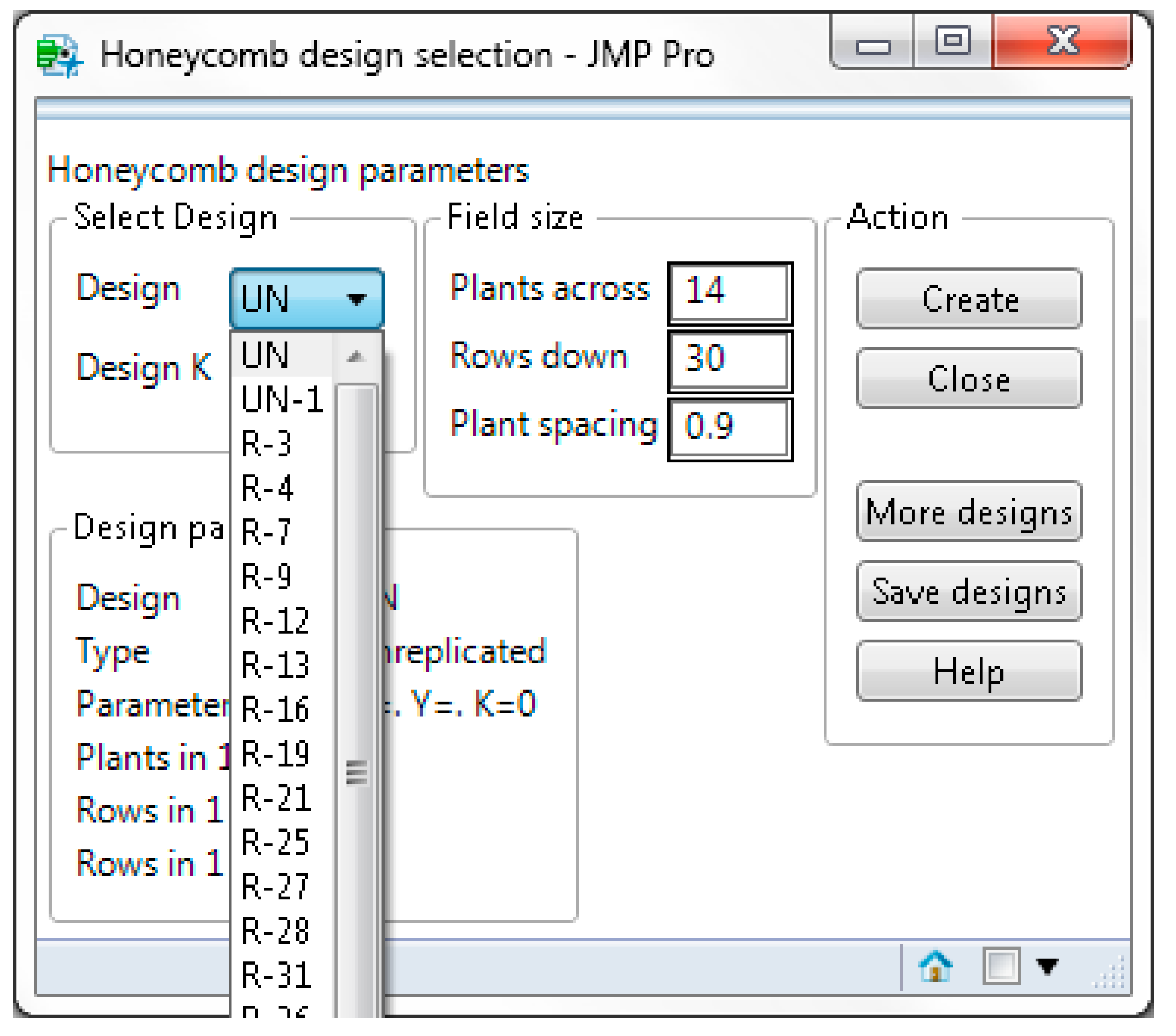
Honeycomb Design Selection item. In the
Honeycomb Design Selection window, select the
UN design from the Design drop-down box. The Field size control allows the user to specify the number of rows and plants per row in the field. Enter 14 in the Plants across box, 30 in the Rows down box and 0.9 in the Plant spacing box as shown in
Figure 3.
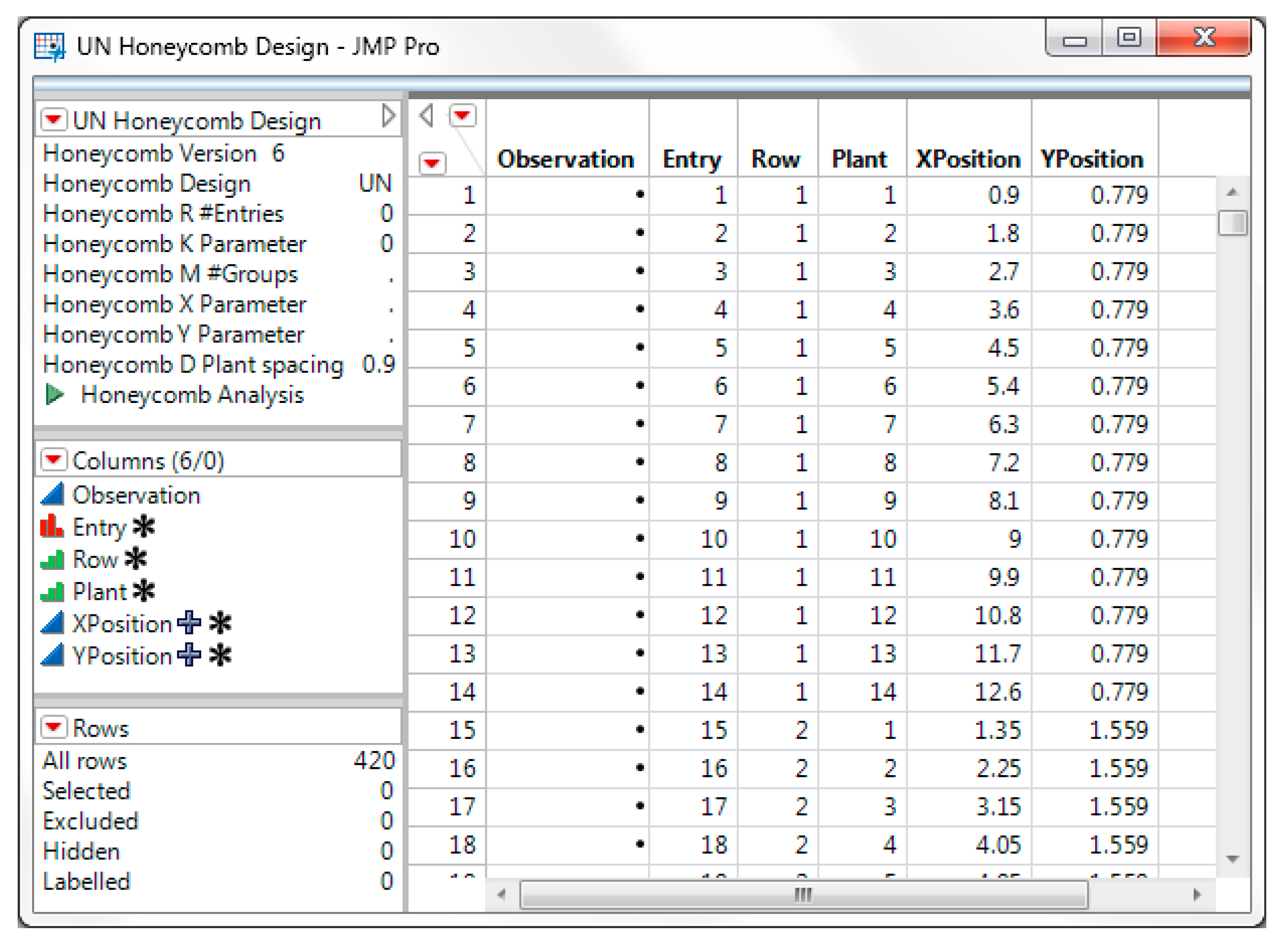
Press the
Create button when finished. This will create a JMP data table for the unreplicated honeycomb design with 30 rows and 14 plants per row. The XPosition and YPosition columns denote the placement of each plant in the field (
Figure 4).
Record the traits of interest in the JMP data table. In this experiment we recorded seed yield (i.e., the seed yield of each plant). Columns may be renamed (i.e., Observation to YLD, Entry to PlantID) and additional columns may be created as desired. The data values in the Entry column may be modified but the columns Row, Plant, XPosition, YPosition should not be modified.
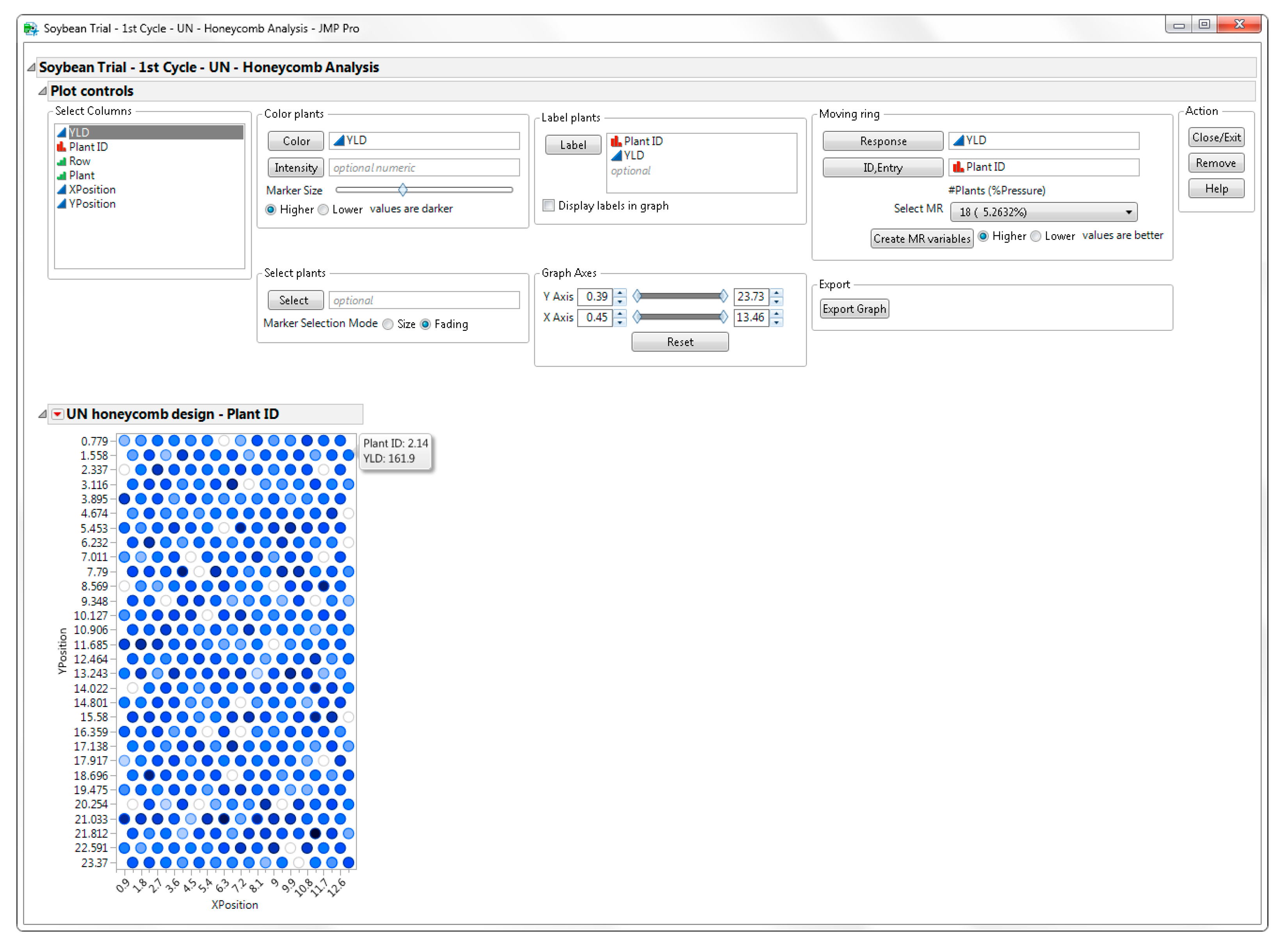
For the analysis, run the Honeycomb Analysis table script embedded within the JMP table. The program generates the graphic view of the design and Plot Controls that allow the user to visualize data points, analyze the data, and select plants as shown in
Figure 5.
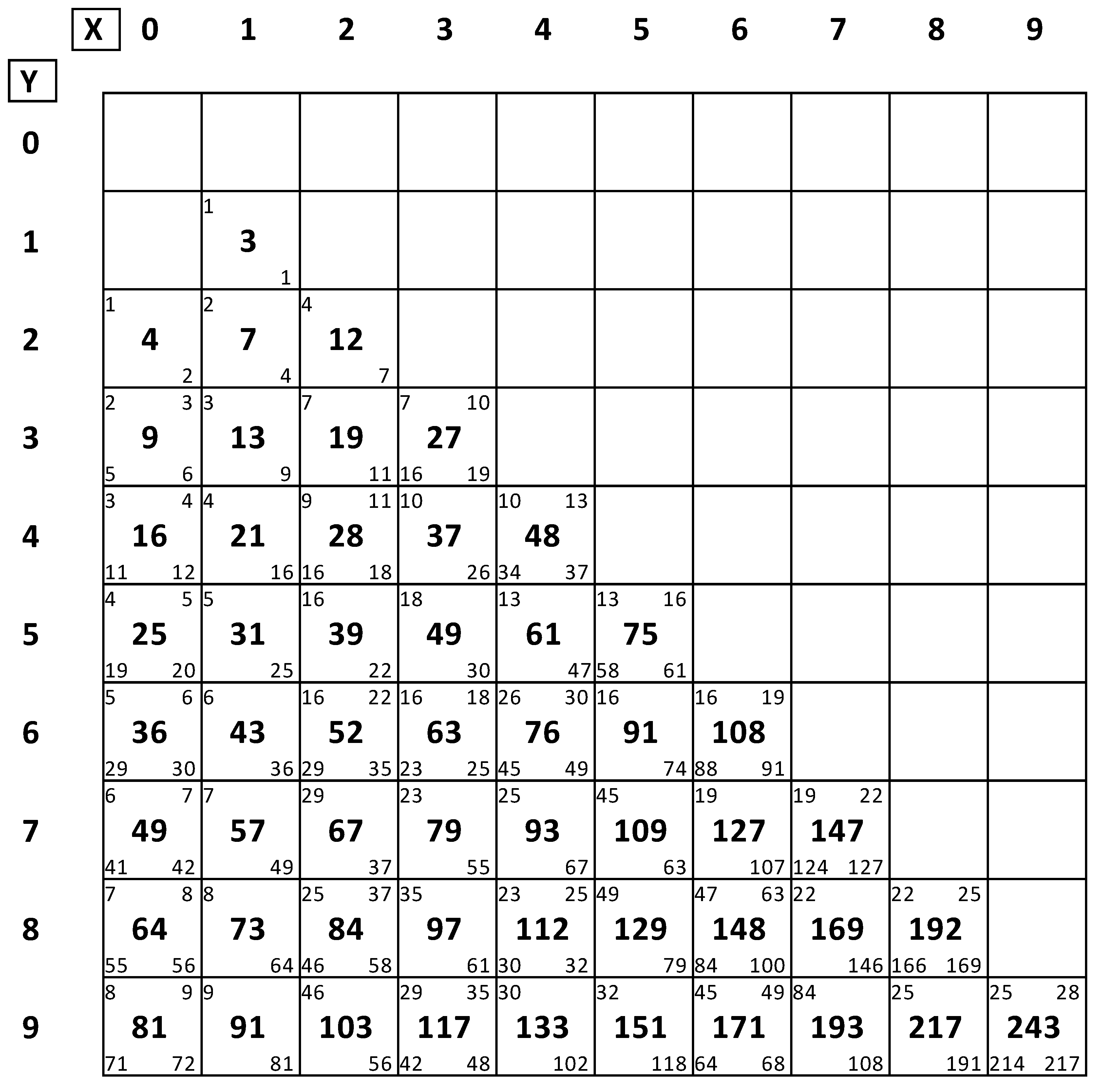
You can assign the column YLD to the Color role to color the graph according to the value of the yield to get an idea of the highest-yielding plants in this field. You can label plants by PlantID and YLD columns. In this case, hovering the mouse over a point in the graph displays the values of PlantID and YLD for these points, as shown for the last plant of row 2 in the honeycomb graph (
Figure 5). Missing plants are displayed as white circles. Assign the column YLD to the
Moving Ring Response role. Select the Moving Ring size. In this example, we selected a moving ring of 18 plants (MR = 18) (
Figure 5). Press the
Create MR variables button.
The necessary moving ring variables are added to the JMP table, so that the breeder can carry out the selection of plants. In the unreplicated honeycomb designs, selection of the best plants is performed based on the PI(YLD) column. The compares and adjusts the yield of each plant to the mean plant yield of its 18 surrounding moving-ring plants. We decided to select the best 20 plants.
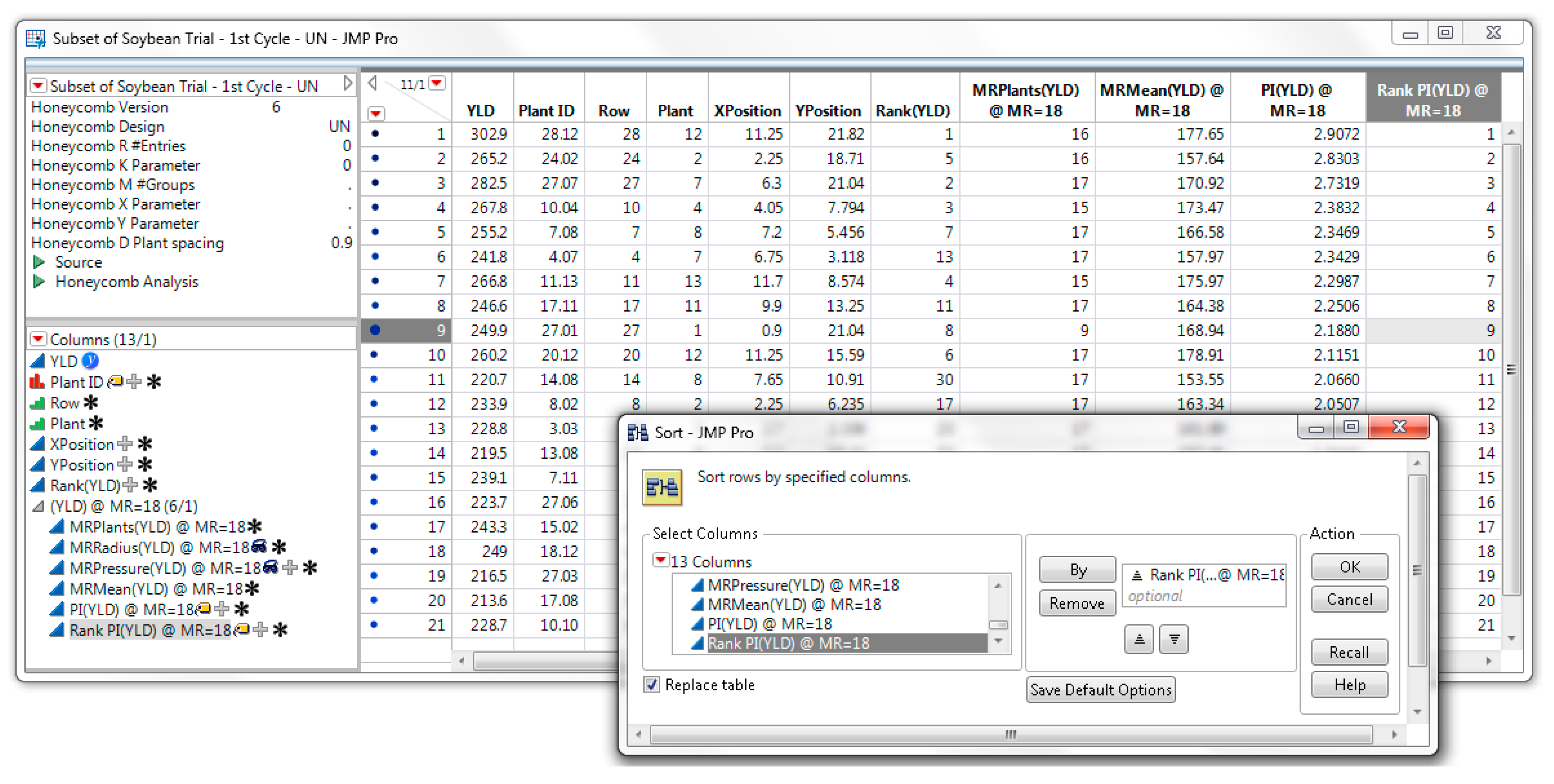
To select the best 20 plants, assign the Rank PI column to the
Select Plants role and adjust the selection limits to 1 and 20. Since one of the selected plants is on the border, you can decide to keep the border plant which has been evaluated with a smaller moving ring size, or you can increase the selection limit until 20 non-border plants are selected. We decided to drop the border plant, thus we assigned the selection limits to 1 and 21 in order to select 20 non-border plants (
Figure 6). From the JMP menu, select
Tables and go to
Subset to create a JMP table of the selected plants.
This creates a subset of the JMP table that contains only the 21 selected plants as shown in
Figure 7. You can sort the subset JMP table by Rank PI(YLD). Delete the border plant (Plant = 1, Row = 27) from the subset. Save this JMP table for future reference. As the data show, when a moving ring of 18 plants was used (MR = 18), the best 20 plants had a PI(YLD) > 1.77, while the two highest-ranking plants had a PI(YLD) value of 2.91 and 2.83, respectively.
The PI(YLD), and therefore the best plants, depends upon the moving ring size selected. The breeder may calculate the PI(YLD) for different moving ring sizes (i.e., MR = 18 plants and MR = 30 plants) by changing the moving ring size and pressing the
Create MR variables button. The size of the moving ring depends on the genetic structure and size of the population being sampled and on the degree of soil homogeneity [
4,
8]. Heterogeneous fields require smaller moving ring sizes than homogeneous fields. After comparing the PI(YLD) for different moving ring sizes, the breeder may decide to modify his/her choice of which plants are “best.”
3.2. Cycle 2: Replicated Honeycomb Design—Construction, Data Analysis and Selection of Best Lines and Best Plants
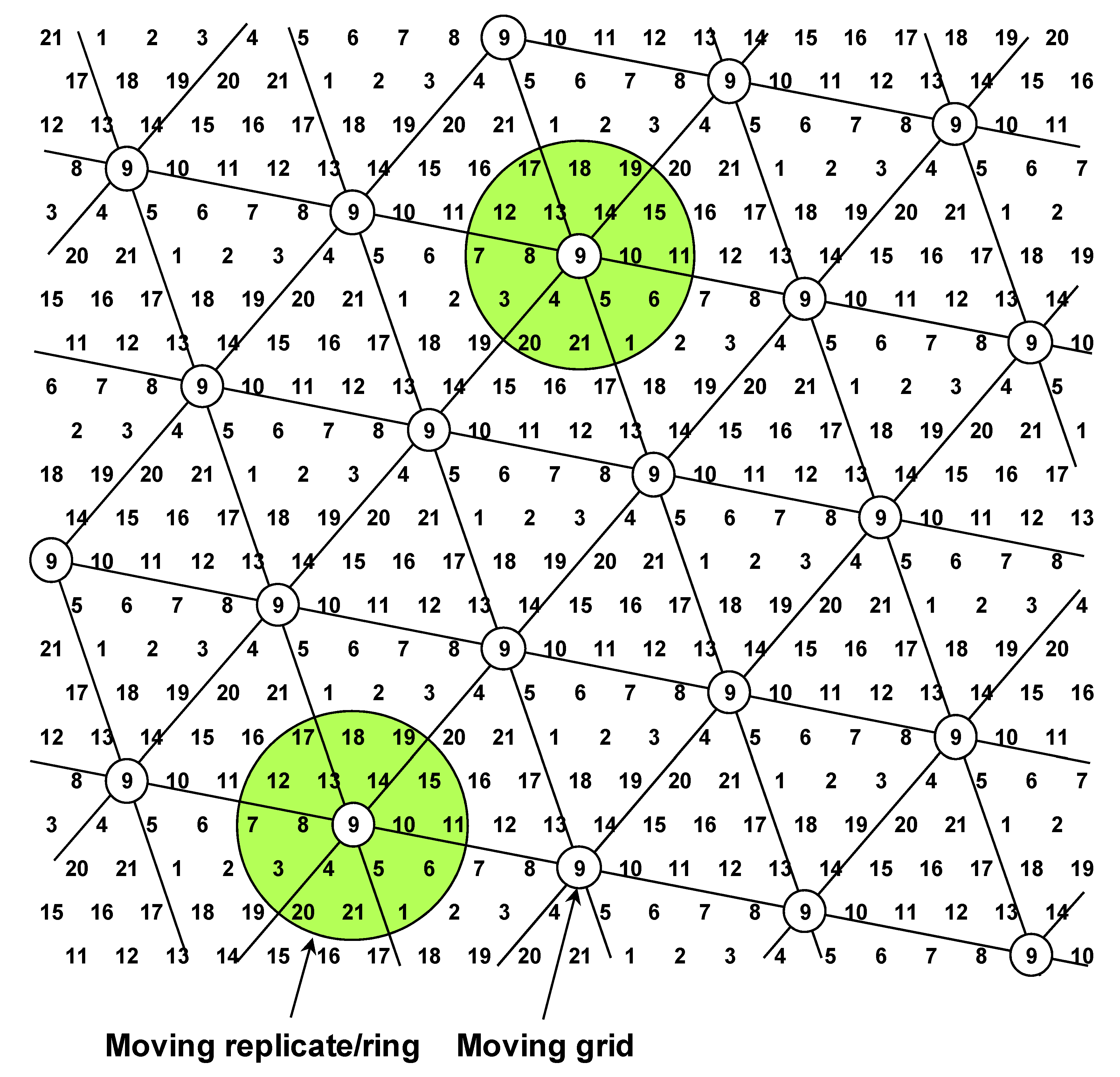
Seeds from the 20 best plants (from cycle 1) plus the check were planted in a Replicated-21 honeycomb design (
Figure 2). Each of these selected plants forms a candidate line. Foundation seed from “Haskell” was assigned to the 21st line (representing the check). The seeds were planted in a R-21 honeycomb design of 672 plants in 14 rows, 48 plants per row, using a plant spacing of 0.9 m [
2]. There were 32 plants for each line. After emergence, hill plots were thinned to contain a single plant. Plants were harvested when they reached maturity. A partial view of the soybean experiment is depicted in
Figure 8. While a square arrangement of plants produces field rows and alleys in two directions, a triangular arrangement of plants produces field rows and alleys in three directions (
Figure 8).
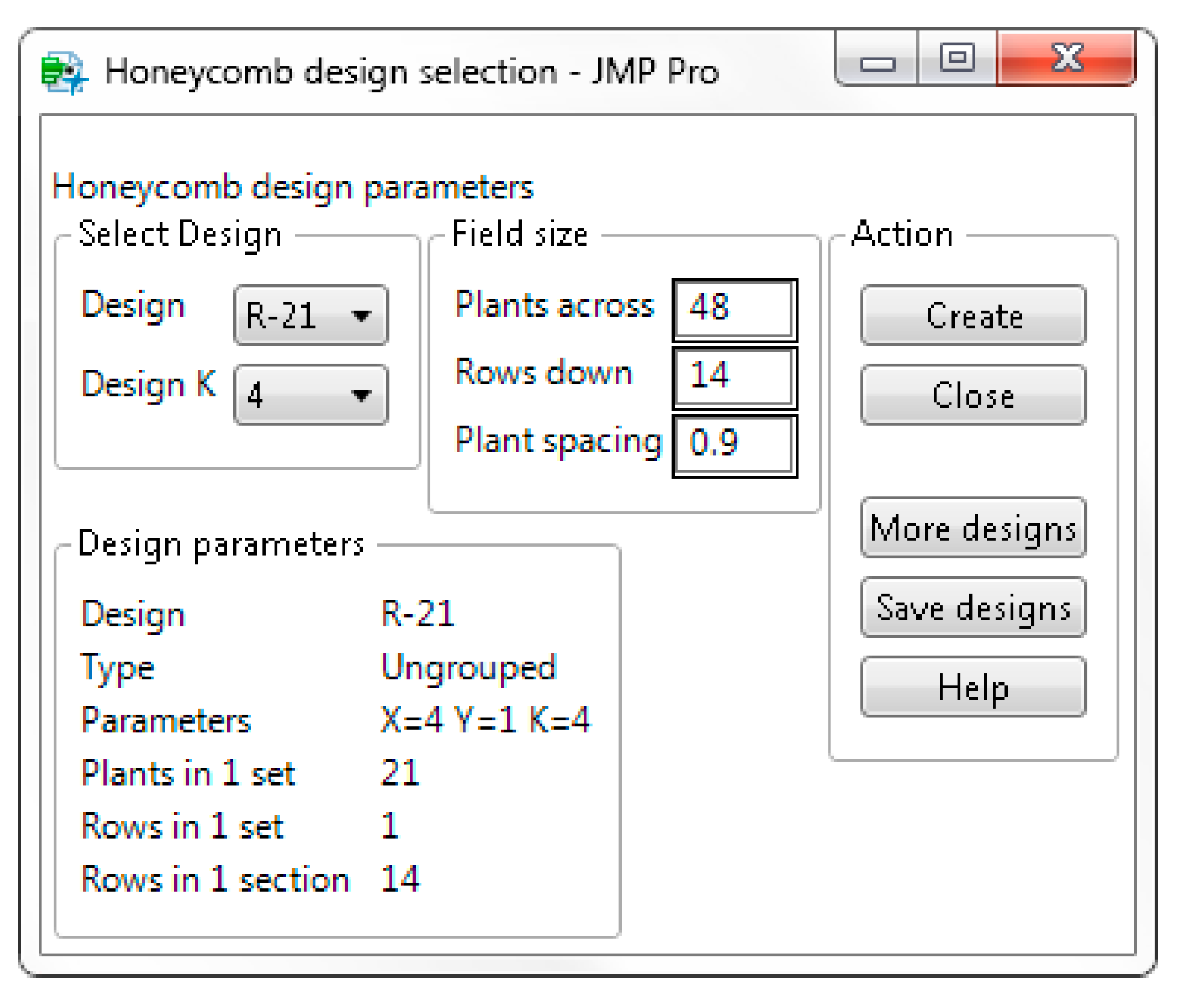
To construct the aforementioned replicated honeycomb design the user can employ the following steps. From the JMP Add-Ins menu, select the
Prognostic Breeding Application and go to
Honeycomb Design Selection item. Select R-21 in the Design box and 4 in the Design K box. If you select 16 in the Design K box, the R-21 will be constructed with an alternative arrangement of entries. Enter 48 in the Plants across box, 14 in the Rows down box and 0.9 in the Plant spacing box as shown in
Figure 9.
Press the
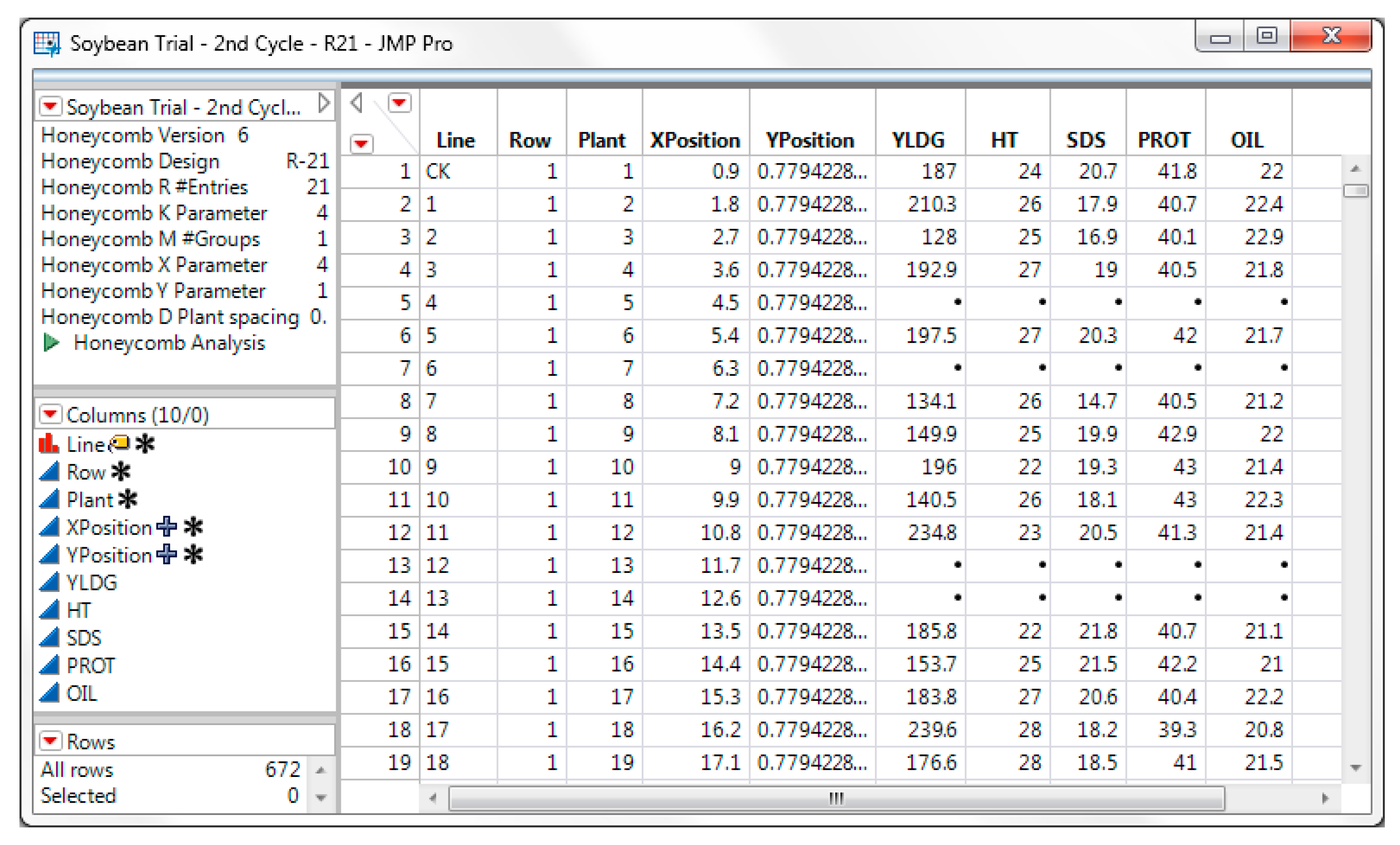
Create button to create the JMP table (
Figure 10). Record the traits of interest in the JMP data table. In this experiment we recorded Seed yield (YLDG), Height (HT), Seed size (SDS), Seed protein (PROT) and Seed oil (OIL) as shown in
Figure 10. The Entry column was renamed and JMP values labels were used to identify the check. The columns Row, Plant, XPosition, YPosition should not be modified.
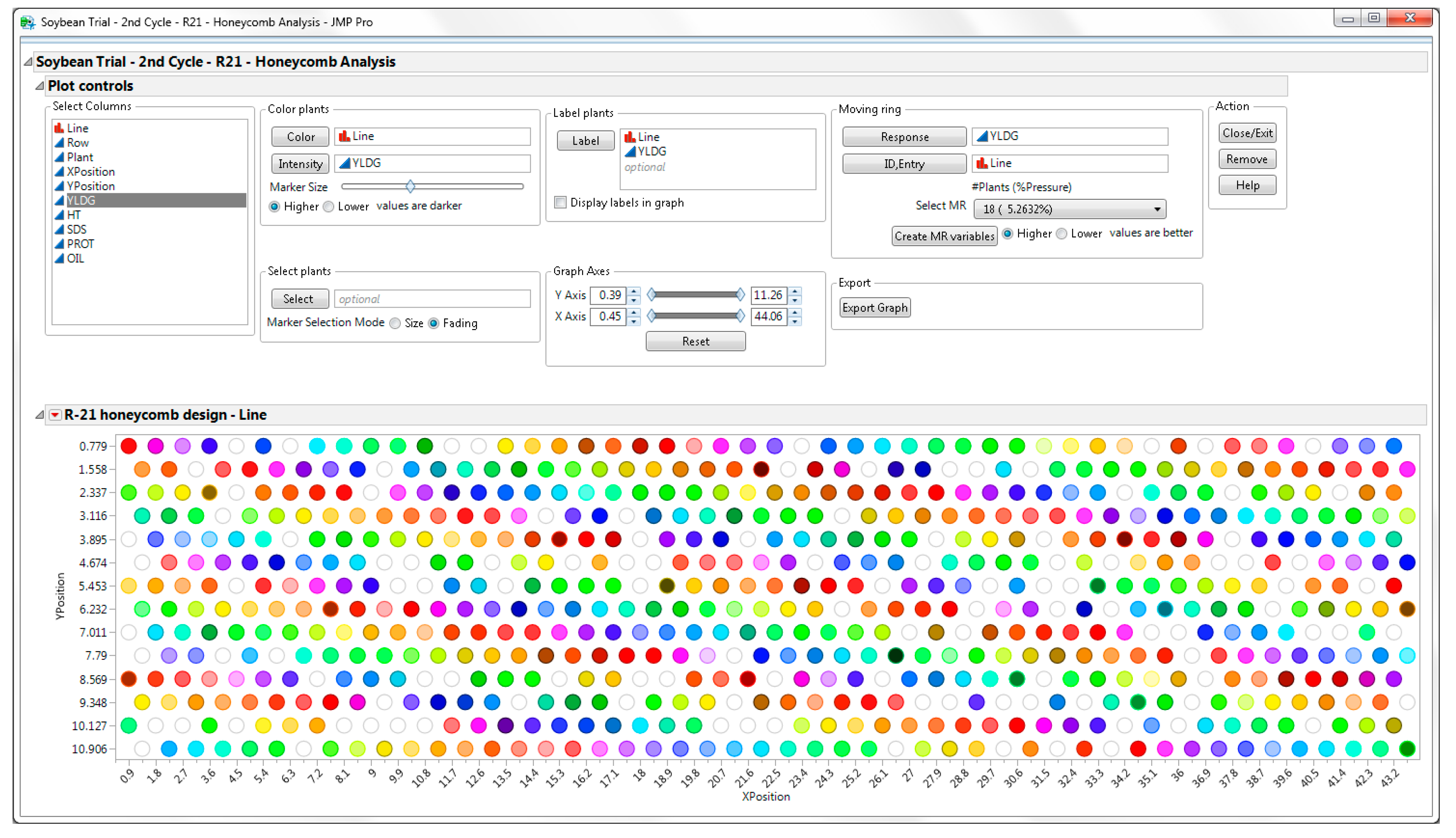
To analyze the data, run the
Honeycomb Analysis table script embedded within the JMP table (upper left side). The program generates the graphic view of the design with Plot Controls (
Figure 11) that allow the user to visualize data points, analyze the data, and select plants. The user can assign the Line and the trait of interest (YLDG) columns to the
Label role. The values of these columns are displayed in a pop-up window when the mouse hovers over the point in the graph.
The user can also visualize the R-21 design by labeling plants by Line and displaying labels in the graph (
Figure 12).
Assign the trait of interest (YLDG) to the
Moving Ring Response role. Verify that the Line column is assigned to the
Moving Ring Entry role (
Figure 11). Select the Moving Ring size. In this case, we chose a ring size of 18 plants. Then press the
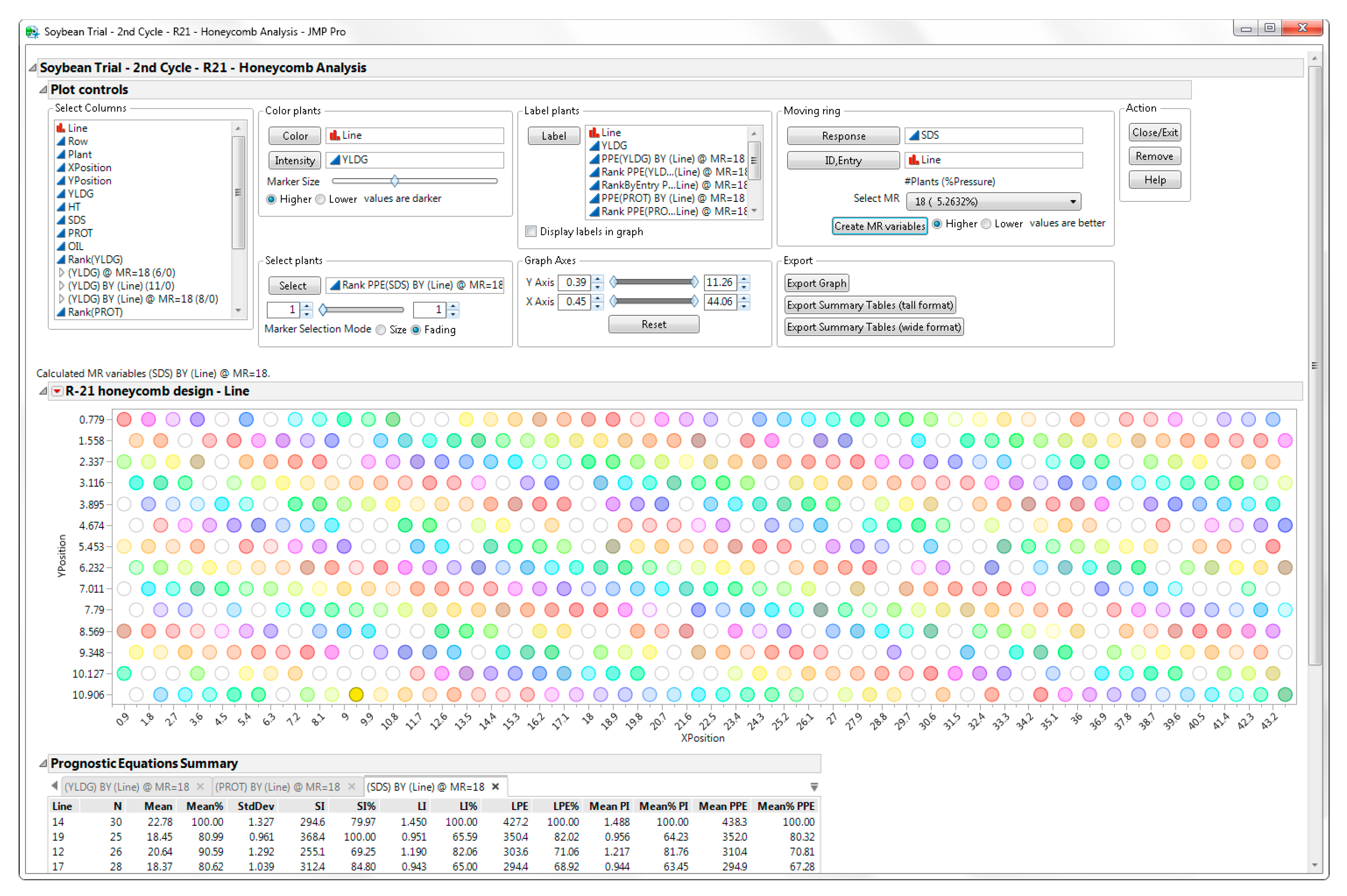
Create MR variables button. Various moving ring variables are added to the JMP table. For replicated designs, the JMP program generates a summary table that includes the Line Prognostic Equation (LPE) and the line average of the Plant Prognostic Equation (MeanPPE) used for selection of the best lines.
Summary Table calculates N (no. plants/line), Mean and Std Deviation of the trait, SI, LI, LPE, MeanPI, MeanPPE. To more easily compare lines and get the resolution range, selected variables are rescaled with respect to their maximum value (Mean%, SI%, LI%, LPE%, Mean%PI, Mean%PPE) (
Figure 13).
Selection of the best lines for YLDG is performed by ranking the lines by their LPE or MeanPPE [
2]. The two prognostic equations are similar since they both measure concurrently plant yield potential and stability of performance. Based on MeanPPE, the 4 best lines for YLDG are lines 12, 9, 10 and 18 with MeanPPE values of 63.75, 50.49, 46.75, and 46.70, respectively. Compared to lines 12, 10 and 18, line 9 has the highest plant yield index (MeanPI = 1.49) but it has low Stability Index (SI = 33.76). Since stability is the most important component for Crop Yield, line 9 is dropped from further consideration.
Line 12 has the highest MeanPPE = 63.75 and the best SI = 70.5, meaning that line 12 has high stability of performance. An important point to make is that line 12 has a relatively low yield potential (MeanPI = 0.9) and it would not have been selected if it did not have a very high SI, demonstrating the significance of selecting concurrently for yield potential and stability by using the PPE. The check line (Haskell) is on the bottom of the table with low MeanPPE = 18.56 and a low SI (
Figure 13).
Selection based on PPE or LPE magnifies the differences among lines [
2]. The resolving power of the MeanPPE, expressed by the resolution range of the Mean%PPE(YLDG) (25–100%), is much larger than the resolving power of Mean%(YLDG) (71–100%) (
Figure 13). This suggests that PPE has a better predictive and resolving power, thus selection is much more efficient when using the PPE. The user can visualize these differences by creating a chart using standard JMP tools (
Figure 14).
In conclusion, the best 3 lines selected for high crop yield potential (based on PPE) are lines 12, 10 and 18, with line 12 being the most important one. The superiority of line 12 was confirmed when grown in Randomized Complete Block (RCB) trials across 4 years and 17 different environments at commercial plant densities. Across all environments, line 12 exhibited a 5% statistically significant seed yield superiority compared to the check cultivar (CK), demonstrating the importance of selecting concurrently for plant yield and stability [
2].
Selection of the best plants within the selected lines is performed by ranking the plants within the selected lines by PPE. You can use a data filter to select lines 12, 10 and 18. Create a subset JMP table of these lines. By sorting the subset table by RankByEntryPPE, you can select the best 6 plants from each of these lines. These 18 plants, along with foundation seed as a check, can be promoted to the next cycle using a Replicated-19 honeycomb design.
Selection of the best lines for multiple traits, (i.e., YLDG, PROT, SDS) can be performed by creating moving ring variables and summary tables for each of the traits. The user assigns each of the additional traits,
PROT and
SDS, to the
Moving Ring Response role and presses the
Create MR variables button for each trait (
Figure 15). Summary tables for each trait are generated.
One important thing to note is that line 9 has consistently low Stability Index (low SI) across all different traits, YLDG, PROT and SDS, thus, it is excluded from further consideration. SI is a powerful parameter for selecting lines that have good trait stability and low SI values denote unstable lines.
There are different ways to select for multiple traits and every breeder may have different priorities. One way is to rank the lines based upon the prognostic equation (LPE or MeanPPE) for YLDG. Eliminate any lines with a low SI. Further reduce the number of lines in consideration to select only the best ones based upon the values of prognostic equations (LPE or MeanPPE) for the remaining traits: PROT and SDS.
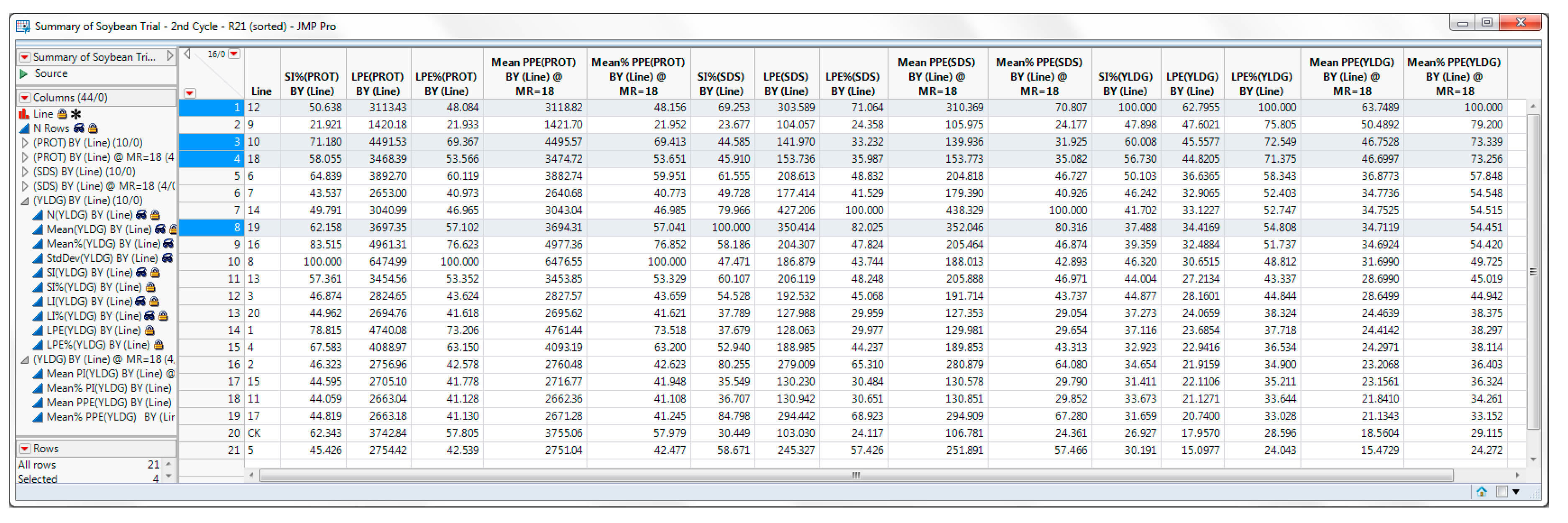
It may be easier to select for multiple traits using a combined summary table. Press the
Export Summary Table (wide format) button (shown in
Figure 15) to create a combined summary data table (
Figure 16). Use standard JMP tools to subset and sort this table to aid in the selection. Since yield is the most important trait, sort the table by LPE%(YLDG) or Mean%PPE(YLDG), descending. The best lines should lie towards the top of the table. To check for stability, reorder the columns, placing the SI% columns at the front of the table. Line 9, although it has the second highest LPE%(YLDG), has a low SI among YLDG, PROT and SDS, thus it is removed from further consideration.
To select the best lines, reorder the columns, placing the LPE% columns for the desired traits at the front of the table. Line 12 appears to be the best line for the trait YLDG. The breeder can use standard JMP tools to calculate a weighted average of the LPE% with weights 3,1,1 for YLDG, PROT, SDS, respectively. This lists the best 5 lines as 12, 10, 14, 18, 19. A weighted average of the LPE% with weights 3,2,1 for YLDG, PROT, SDS, respectively, lists the best 5 lines as 12, 8, 10, 19, 18. It seems reasonable that the best 4 lines for YLDG, PROT, SDS are lines 12, 10, 18, 19. The breeder can then select the best plants within these lines based upon the highest PPE of the most important trait.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















