In-Field Estimation of Orange Number and Size by 3D Laser Scanning



 ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
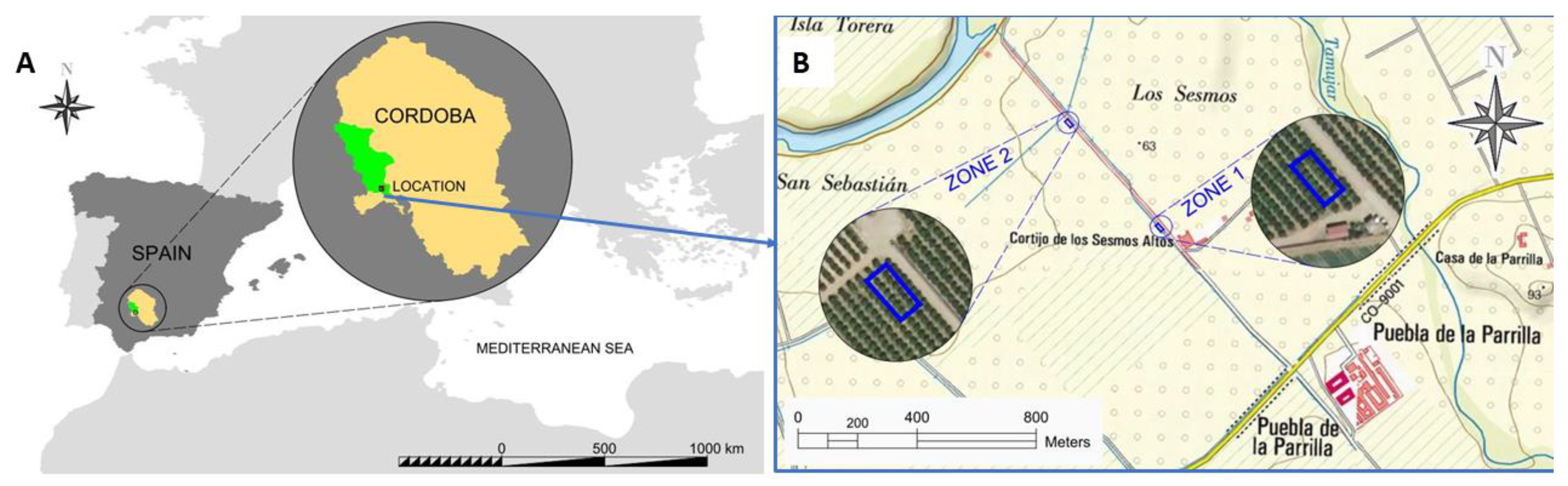
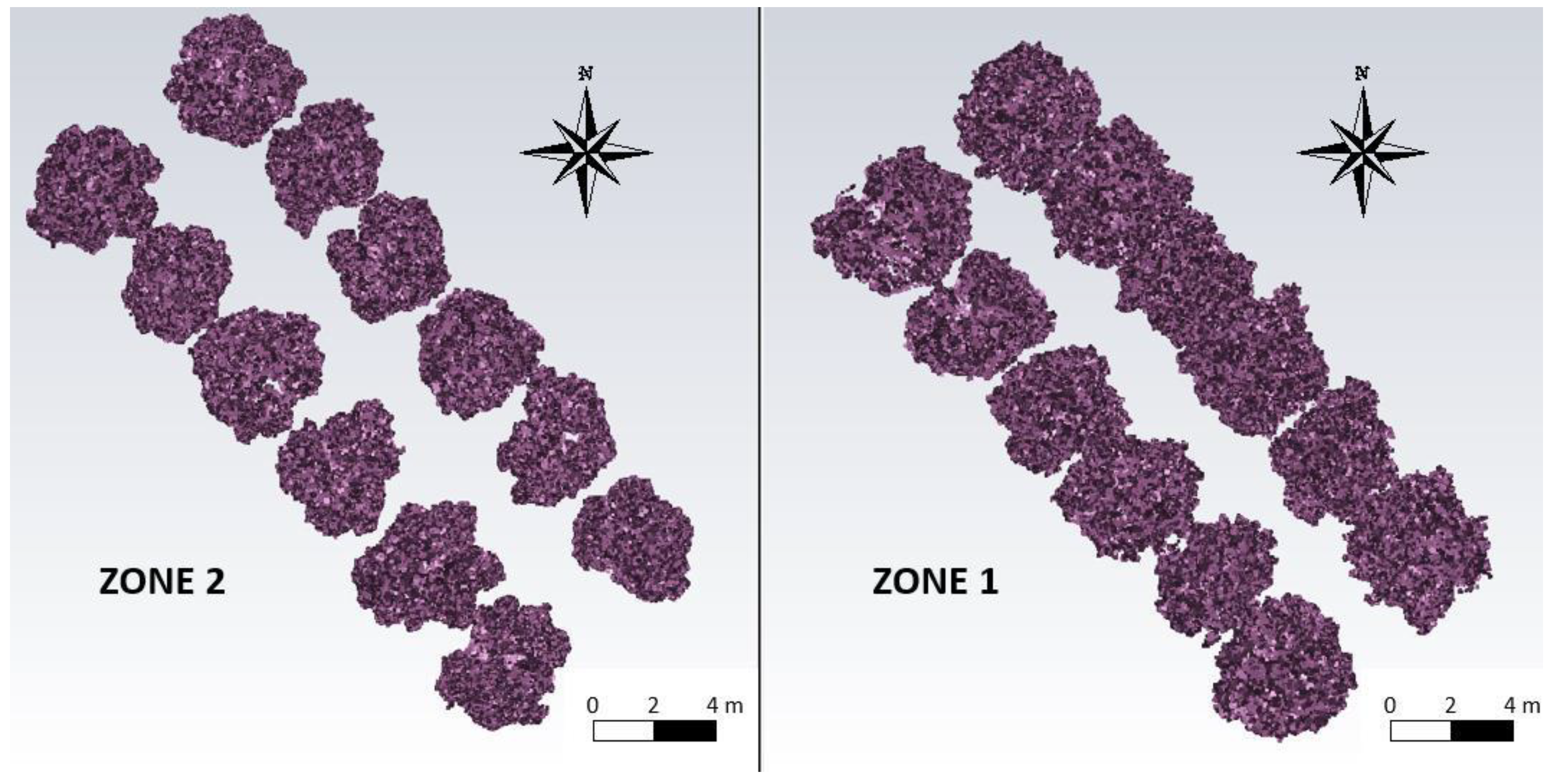
2.1. Orange Trees Plots
2.2. Data
2.2.1. Yield and Orange Sampling
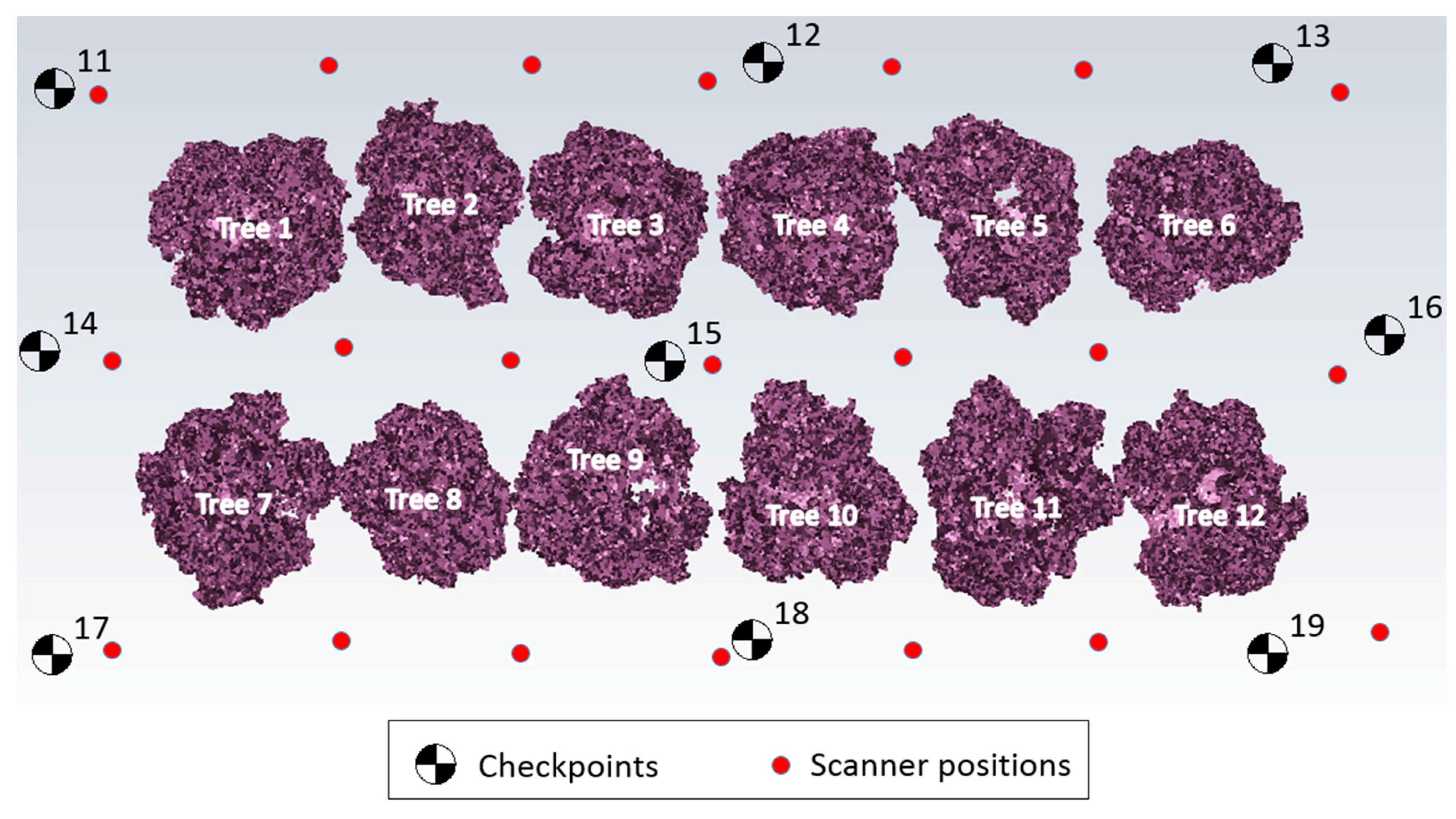
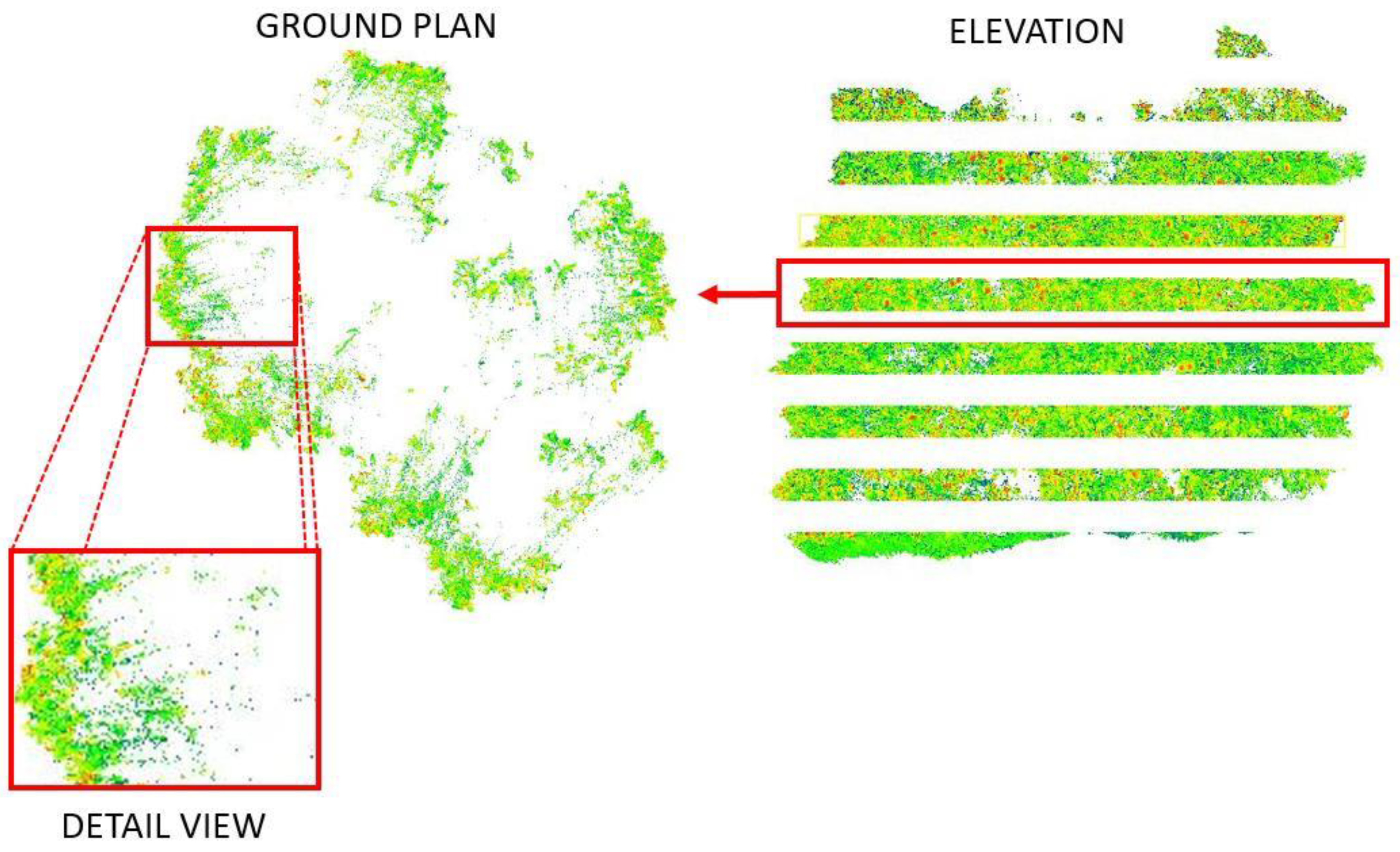
2.2.2. Three-Dimensional Modelling Using Laser Scanner
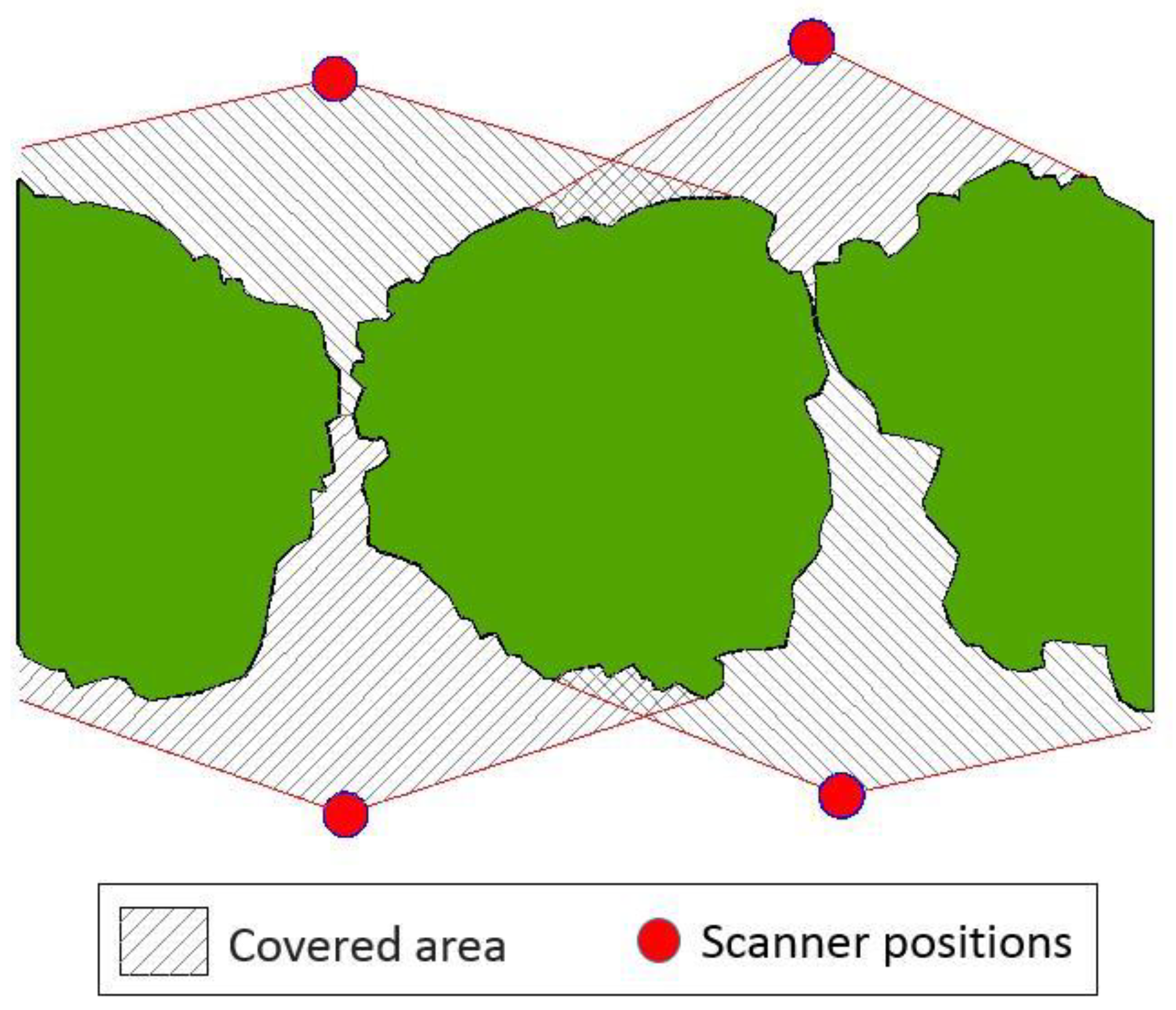
(a) Data Acquisition
(b) Data Processing
2.3. K-Means Algorithm Application
2.3.1. Data Segmentation
2.3.2. Algorithm
2.4. Statistical Analysis
3. Results
3.1. Orange Count with K-Means Algorithm
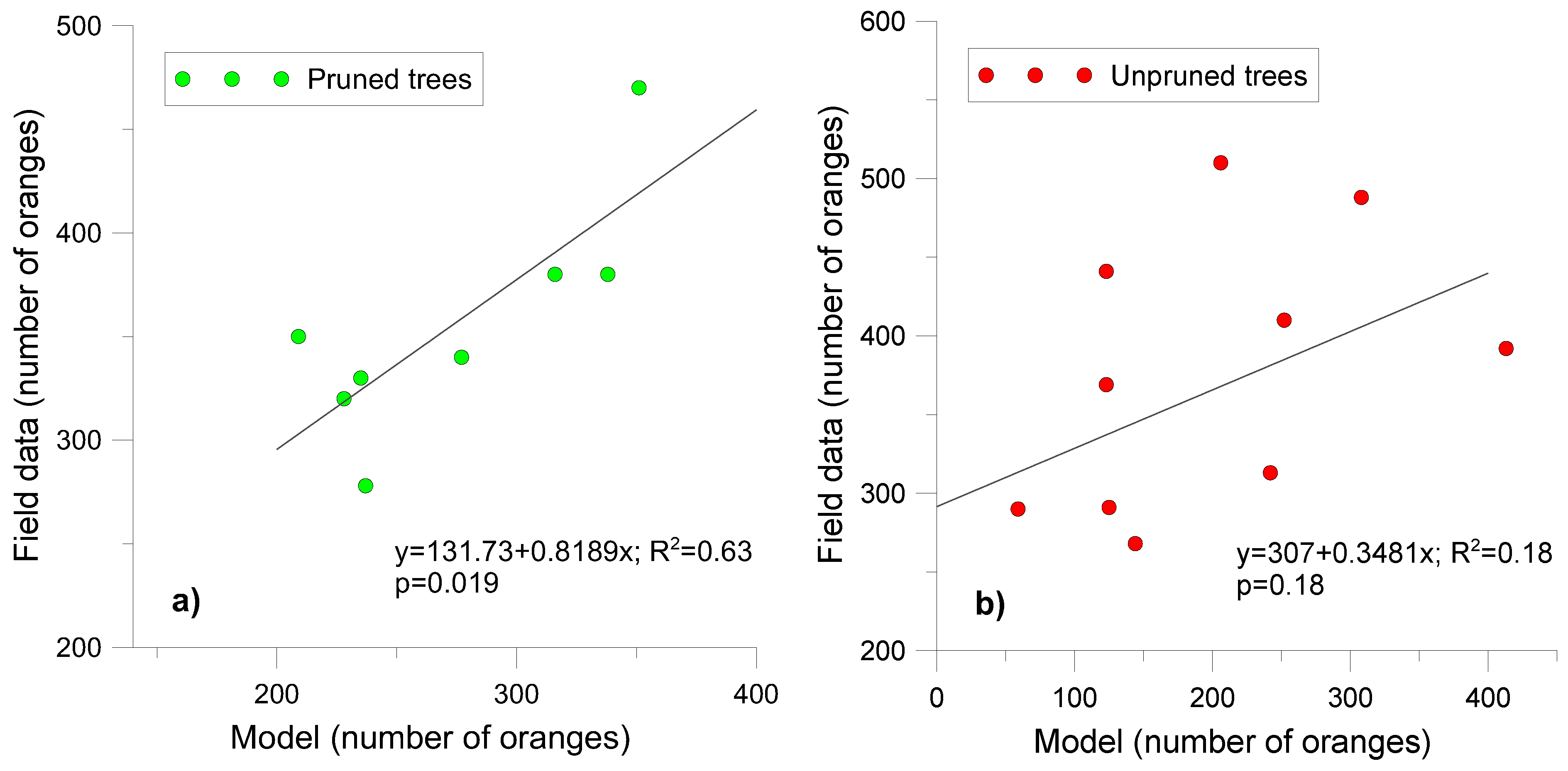
3.2. Yield Estimation
Fruit weighti = −212.8 + 5.344 × Diameteri + Ɛi c
a,b: perpendicular axis in the horizontal plane; c: Z axle.
4. Discussion
4.1. Orange Count with K-Means Algorithm
4.2. Yield Estimation
R2 = 0.88, p < 10−10
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sarig, Y. Robotics of Fruit Harvesting: A State-of-the-art Review. J. Agric. Eng. Res. 1993, 54, 265–280. [Google Scholar] [CrossRef]
- Underwood, J.P.; Hung, C.; Whelan, B.; Sukkarieh, S. Mapping almond orchard canopy volume, flowers, fruit and yield using LiDAR and vision sensors. Comput. Electron. Agric. 2016, 130, 83–96. [Google Scholar] [CrossRef]
- Grand d’Esnon, A. Robotic Harvesting of Apples. In Proceedings of Agri-Mation 1 Conference and Exposition; ASAE: St. Joseph, MI, USA, 1985; pp. 210–214. [Google Scholar]
- Kassay, L.; Slaughter, D.C.; Molnar, S. Hungarian Robotic Apple Harvester; ASAE: St. Joseph, MI, USA, 1992. [Google Scholar]
- Bulanon, D.M.; Burks, T.F.; Alchanatis, V. Study on Fruit Visibility for Robotic Harvesting; ASABE Paper No. 07-3124; ASABE: St. Joseph, MI, USA, 2007. [Google Scholar]
- Tabb, A.; Peterson, D.; Park, J. Segmentation of Apple Fruit from Video via Background Modeling; ASAE: St. Joseph, MI, USA, 2006. [Google Scholar]
- Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef] [Green Version]
- Tanigaki, K.; Fujiura, T.; Akase, A.; Imagawa, I. Cherry Harvesting Robot. In Proceedings of the 3rd IFAC International Workshop on Bio-robotics, Information Technology and Intelligent Control for Bioproduction Systems, Sapporo, Japan, 9–10 September 2006; pp. 254–260. [Google Scholar]
- Van Henten, E.J.; Hemming, J.; Van Tuijl, B.A.J.; Kornet, J.G.; Bontsema, J. Collision-free Motion Planning for a Cucumber Picking Robot. Biosyst. Eng. 2003, 86, 135–144. [Google Scholar] [CrossRef]
- Payne, A.B.; Walsh, K.B.; Subedi, P.P.; Jarvis, D. Estimation of mango crop yield using image analysis–segmentation method. Comput. Electron. Agric. 2013, 91, 57–64. [Google Scholar] [CrossRef]
- Qureshi, W.S.; Payne, A.; Walsh, K.B.; Linker, R.; Cohen, O.; Dailey, M.N. Machine vision for counting fruit on mango tree canopies. Precis. Agric. 2017, 18, 224–244. [Google Scholar] [CrossRef]
- Harrell, R.C.; Adsit, P.D.; Pool, T.A.; Hoffman, R. The Florida Robotic Grove Lab; ASAE Paper no. 88–1578; ASAE: St. Joseph, MI, USA, 1988. [Google Scholar]
- Hannan, M.W.; Burks, T.F. Current Developments in Automated Citrus Harvesting; ASAE Paper no., 043087; ASAE: St. Joseph, MI, USA, 2004. [Google Scholar]
- Chaivivatrakul, S.; Moonrinta, J.; Dailey, M.N. Towards Automated Crop Yield Estimation-Detection and 3D Reconstruction of Pineapples in Video Sequences. In Proceedings of the Fifth International Conference on Computer Vision Theory and Applications, Angers, France, 17–21 May 2010; pp. 180–183. [Google Scholar]
- Chaivivatrakul, S.; Dailey, M.N. Texture-based fruit detection. Precis. Agric. 2014, 15, 662–683. [Google Scholar] [CrossRef]
- Kondo, N.; Nishitsuji, Y.; Ling, P.P.; Ting, K.C. Visual Feedback Guided Robotic Cherry Tomato Harvesting. Trans. ASAE 1996, 39, 2331–2338. [Google Scholar] [CrossRef]
- Clement, J.; Novas, N.; Gazquez, J.A.; Manzano-Agugliaro, F. An active contour computer algorithm for the classification of cucumbers. Comput. Electron. Agric. 2013, 92, 75–81. [Google Scholar] [CrossRef]
- Novas, N.; Álvarez-Bermejo, J.A.; Valenzuela, J.L.; Gázquez, J.A.; Manzano-Agugliaro, F. Development of a smartphone application for assessment of chilling injuries in zucchini. Biosyst. Eng. 2019, 181, 114–127. [Google Scholar] [CrossRef]
- Whittaker, D.; Miles, G.E.; Mitchell, O.R.; Gaultney, L.D. Fruit location in a partially occluded image. Trans. ASAE 1987, 30, 591–596. [Google Scholar] [CrossRef]
- Pla, F. Recognition of partial circular shapes from segmented contours. Comput. Vis. Image Undst. 1996, 63, 334–343. [Google Scholar] [CrossRef] [Green Version]
- Grasso, G.M.; Recce, M. Scene analysis for an orange harvesting robot. AI Appl. 1997, 11, 9–15. [Google Scholar]
- Qureshi, W.S.; Satoh, S.I.; Dailey, M.N.; Ekpanyapong, M. Dense segmentation of textured fruits in video sequences. In Proceedings of the IEEE International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 2. [Google Scholar]
- Jiménez, A.R.; Ceres, R.; Pons, J.L. A survey of computer vision methods for locating fruit on trees. Trans. ASAE 2000, 43, 1911. [Google Scholar] [CrossRef] [Green Version]
- Sharifi, M.; Rafiee, S.; Keyhani, A.; Jafari, A.; Mobli, H.; Rajabipour, A.; Akram, A. Some physical properties of orange (var. Tompson). Int. Agrophys. 2007, 21, 391–397. [Google Scholar]
- Hannan, M.W.; Burks, T.F.; Bulanon, D.M.A. A machine vision algorithm combining adaptive segmentation and shape analysis for orange fruit detection. Agric. Eng. Int. CIGR J. 2010, 11, 1281. [Google Scholar]
- Zapata-Sierra, A.J.; Manzano-Agugliaro, F. Controlled deficit irrigation for orange trees in Mediterranean countries. J. Clean. Prod. 2017, 162, 130–140. [Google Scholar] [CrossRef]
- Plebe, A.; Grasso, G. Localization of spherical fruits for robotic harvesting. Mach. Vis. Appl. 2001, 13, 70–79. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Harding, D.; Cohen, W.B.; Parker, G.; Shugart, H.H. Surface lidar remote sensing of basal area and biomass in deciduous forests of eastern Maryland, USA. Remote Sens. Environ. 1999, 67, 83–98. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.; Gong, P.; Cheng, X.; Clinton, N.; Cao, C.; Wenjian, N.; Wang, L. Automated methods for measuring DBH and tree heights with a commercial scanning lidar. Photogramm. Eng. Remote Sens. 2011, 77, 219–227. [Google Scholar] [CrossRef]
- Sola-Guirado, R.R.; Bayano-Tejero, S.; Rodríguez-Lizana, A.; Gil-Ribes, J.A.; Miranda-Fuentes, A. Assessment of the Accuracy of a Multi-Beam LED Scanner Sensor for Measuring Olive Canopies. Sensors 2018, 18, 4406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miranda-Fuentes, A.; Rodríguez-Lizana, A.; Gil, E.; Agüera-Vega, J.; Gil-Ribes, J.A. Influence of liquid-volume and airflow rates on spray application quality and homogeneity in super-intensive olive tree canopies. Sci. Total Environ. 2015, 537, 250–259. [Google Scholar] [CrossRef] [PubMed]
- Miranda-Fuentes, A.; Llorens, J.; Rodríguez-Lizana, A.; Cuenca, A.; Gil, E.; Blanco- Roldán, G.L.; Gil-Ribes, J.A. Assessing the optimal liquid volume to be sprayed on isolated olive trees according to their canopy volume. Sci. Total Environ. 2016, 568, 296–305. [Google Scholar] [CrossRef]
- Miranda-Fuentes, A.; Rodríguez-Lizana, A.; Cuenca, A.; González-Sánchez, E.J.; Blanco-Roldán, G.L.; Gil-Ribes, J.A. Improving plant protection product applications in traditional and intensive olive orchards through the development of new prototype air-assisted sprayers. Crop Prot. 2017, 94, 44–58. [Google Scholar] [CrossRef]
- Verroust, A.; Lazarus, F. Extracting skeletal curves from 3D scattered data. Vis. Comput. 2000, 16, 15–25. [Google Scholar] [CrossRef]
- Mizoue, N.; Masutani, T. Image analysis measure of crown condition, foliage biomass and stem growth relationships of Chamaecyparis obtusa. For. Ecol. Manag. 2003, 172, 79–88. [Google Scholar] [CrossRef]
- Pfeifer, N.; Gorte, B.; Winterhalder, D. Automatic reconstruction of single trees from terrestrial laser scanner data. In Proceedings of the 20th ISPRS Congress: Geo-imagery Bridging Continents, Istanbul, Turkey, 12–23 July 2004; pp. 114–119. [Google Scholar]
- Phattaralerphong, J.; Sinoquet, H. Tree Analyser: Software to Compute Tree Structure Parameters from Photographs. User Manual. PIAF-INRA. 2007. Available online: http://www2.clermont.inra.fr/piaf/eng/download/download.php (accessed on 1 August 2019).
- Phattaralerphong, J.; Sinoquet, H. A method for 3D reconstruction of tree crown volume from photographs: Assessment with 3D-digitized plants. Tree Physiol. 2005, 25, 1229–1242. [Google Scholar] [CrossRef] [Green Version]
- Bailey, B.N.; Ochoa, M.H. Semi-direct tree reconstruction using terrestrial LiDAR point cloud data. Remote Sens. Environ. 2018, 208, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Lim, M.; Rosser, N.; Allison, R.; Petley, D. Erosional processes in the hard rock coastal cliffs at Staithes. Geomorphology 2010, 114, 12–21. [Google Scholar] [CrossRef]
- García-Gómez, I.; de Gorostiza, M.; Moraza, A. Láser escáner y nubes de puntos. Un horizonte aplicado al análisis arqueológico de edificios. Arqueol. Arquit. 2010, 30, 25–44. [Google Scholar] [CrossRef]
- Benedí, J.; Moreno, J.; Molina, C.; Arguedas, G.; Serrano, S.; Oliván, A. Utilización de técnicas de láser escáner terrestre en la monitorización de procesos geomorfológicos dinámicos: El manto de nieve y heleros en áreas de montaña. Cuadernos de investigación geográfica 2013, 39, 335–357. [Google Scholar]
- Ball, G.H.; Hall, D.J. ISODATA, A Novel Method of Data Analysis and Pattern Classification; Stanford Research Inst.: Menlo Park, CA, USA, 1965. [Google Scholar]
- Ridler, T.W.; Calvard, S. Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar]
- Unay, D.; Gosselin, B. Thresholding-based segmentation and apple grading by machine vision. In Proceedings of the 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005. [Google Scholar]
- Shruthi, G. Automatic Detection and Classification of Apple-A Survey. In Proceedings of the Third International Conference on Current Trends in Engineering Science and Technology (ICCTEST 2017), Bangalore, India, 5–7 January 2017; Don Bosco Institute of Technology: Dbit, Bangalore, India. [Google Scholar]
- Lloyd, S.P. Least squares quantization in PCM. IEEE Trans. Inform. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: London, UK, 2009; pp. 248–300. [Google Scholar]
- Goldberg, K.M.; Iglewicz, B. Bivariate extensions of the boxplot. Technometrics 1992, 34, 307–320. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Comput-Ing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Stein, M.; Bargoti, S.; Underwood, J. Image Based Mango Fruit Detection, Localisation andYield Estimation Using Multiple View Geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Yuan, Y.; Zhou, Y.; Naz Syed, T. Experiments and Analysis of Close-Shot Identification of On-Branch Citrus Fruit with RealSense. Sensors 2018, 18, 1510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tabatabaeefar, A.; Vefagh-Nematolahee, A.; Rajabipour, A. Modeling of orange mass based on dimensions. Agric. Sci. Technol. 2000, 2, 299–305. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Harvest (kg) | Tree | Total (kg) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| Real | 78.0 | 76.0 | 56.5 | 59.0 | 52.0 | 75.5 | 86.0 | 66.0 | 549 |
| Regression | 80.7 | 82.8 | 64.0 | 70.8 | 64.3 | 59.8 | 77.13 | 62.9 | 563 |
| Algorithm | 64.9 | 67.4 | 45.1 | 53.2 | 45.5 | 40.1 | 60.7 | 43.8 | 421 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Méndez, V.; Pérez-Romero, A.; Sola-Guirado, R.; Miranda-Fuentes, A.; Manzano-Agugliaro, F.; Zapata-Sierra, A.; Rodríguez-Lizana, A. In-Field Estimation of Orange Number and Size by 3D Laser Scanning. Agronomy 2019, 9, 885. https://doi.org/10.3390/agronomy9120885
Méndez V, Pérez-Romero A, Sola-Guirado R, Miranda-Fuentes A, Manzano-Agugliaro F, Zapata-Sierra A, Rodríguez-Lizana A. In-Field Estimation of Orange Number and Size by 3D Laser Scanning. Agronomy. 2019; 9(12):885. https://doi.org/10.3390/agronomy9120885
Chicago/Turabian StyleMéndez, Valeriano, Antonio Pérez-Romero, Rubén Sola-Guirado, Antonio Miranda-Fuentes, Francisco Manzano-Agugliaro, Antonio Zapata-Sierra, and Antonio Rodríguez-Lizana. 2019. "In-Field Estimation of Orange Number and Size by 3D Laser Scanning" Agronomy 9, no. 12: 885. https://doi.org/10.3390/agronomy9120885
APA StyleMéndez, V., Pérez-Romero, A., Sola-Guirado, R., Miranda-Fuentes, A., Manzano-Agugliaro, F., Zapata-Sierra, A., & Rodríguez-Lizana, A. (2019). In-Field Estimation of Orange Number and Size by 3D Laser Scanning. Agronomy, 9(12), 885. https://doi.org/10.3390/agronomy9120885