
Machine Learning: An Overview and Applications in Pharmacogenetics

 , ,
, , 
Abstract
:1. Introduction
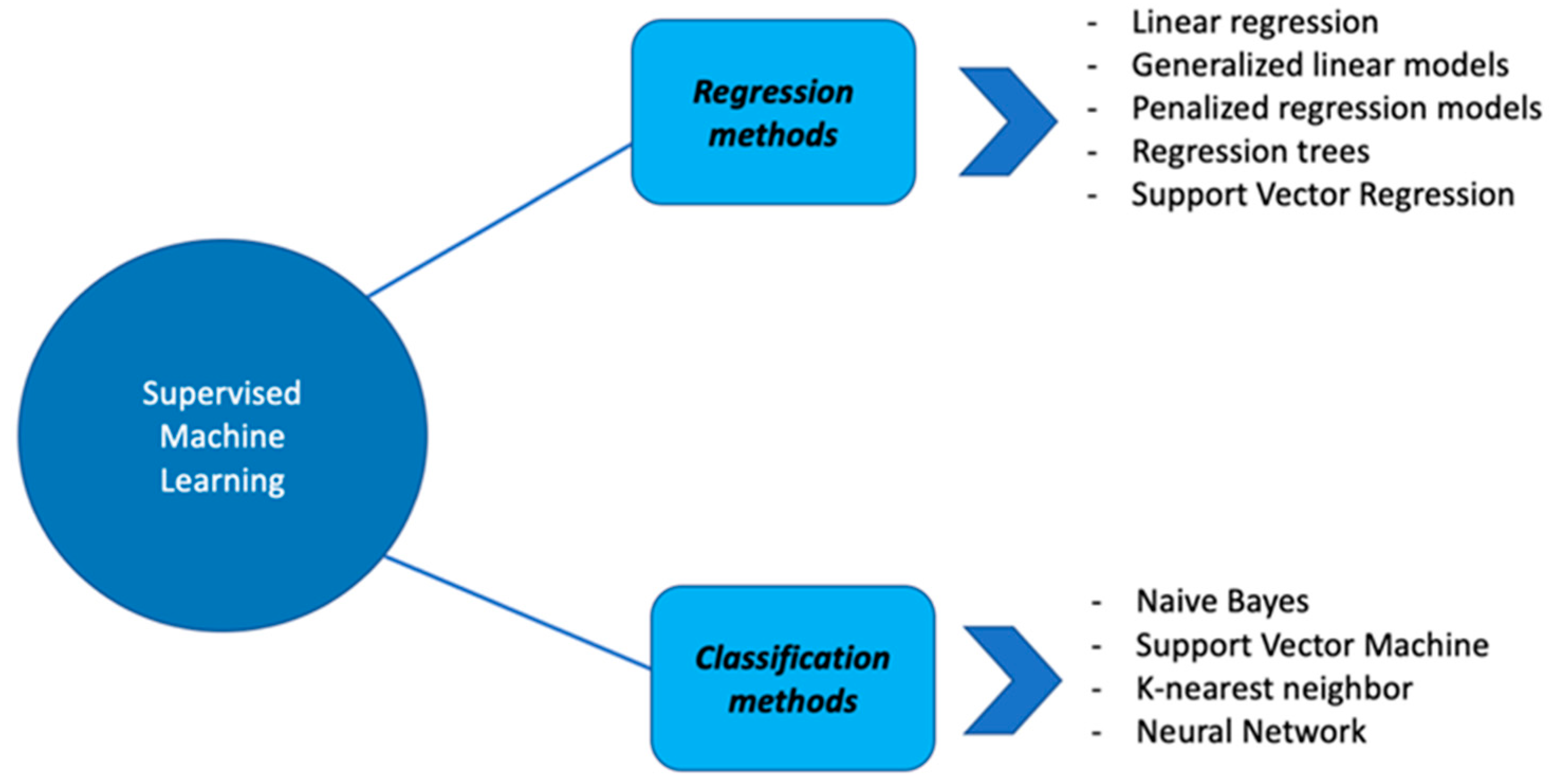
2. Supervised Machine Learning Approaches
2.1. Regression Methods
- Start with a single node containing all the observations. Calculate and RSS;
- If all the observations in the node have the same value for all the input variables, stop. Otherwise, search over all binary splits of all variables for the one which will reduce RSS as much as possible;
- Restart from step 1 for each new node.
2.2. Classification Methods
2.3. Supervised Machine Learning Approaches in Pharmacogenetics
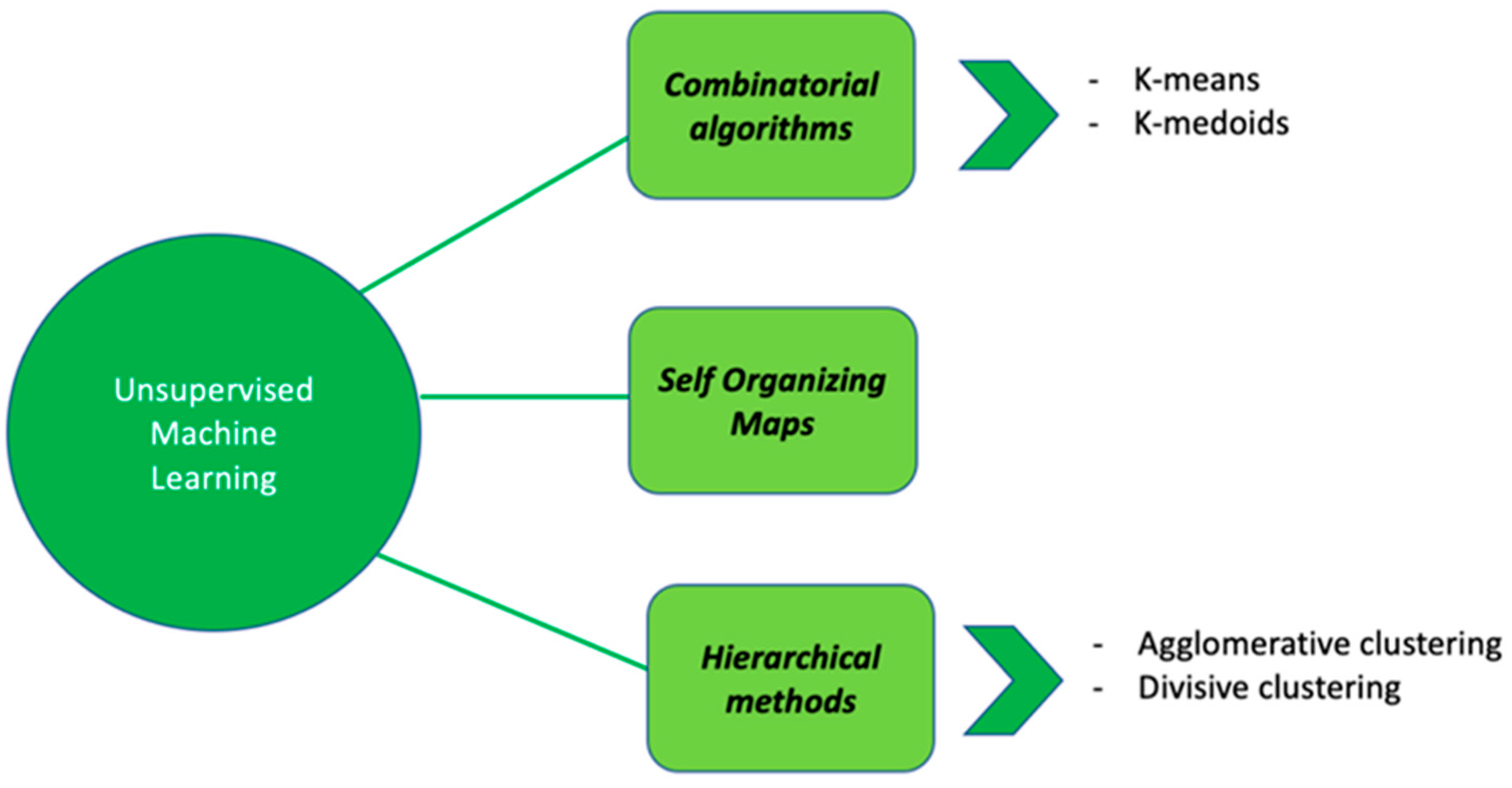
3. Unsupervised Machine Learning Approaches
3.1. Combinatorial Algorithms
3.2. Hierarchical Methods
- Compute the distance matrix D;
- The most similar observations are merged in a first cluster;
- Update D;
- Steps 2 and 3 are repeated until all observations belong to a single cluster.
- All data are in one cluster;
- The cluster is split using a flat clustering method (K-means, K-medoids);
- Choose the best cluster among all the clusters to split that cluster through the flat clustering algorithm;
- Steps 2 and 3 are repeated until each data is in its own singleton cluster.
3.3. Self Organizing Maps
- Choose random values for the initial weights ;
- Randomly choose an object i and find the winner neuron j whose weight is the closest to observation ;
- Update the position of moving it towards ;
- Update the positions of the neuron weights with h (winner neighborhood);
- Assign each object i to a cluster based on the distance between observations and neurons.
3.4. Unsupervised Machine Learning Approaches in Pharmacogenetics
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Committee for Proprietary Medicinal. Position Paper on Terminology in Pharmacogenetics; The European Agency for the Evaluation of Medicinal Products: London, UK, 2002. [Google Scholar]
- Sekhar, M.S.; Mary, C.A.; Anju, P.; Hamsa, N.A. Study on drug related hospital admissions in a tertiary care hospital in South India. Saudi Pharm. J. 2011, 19, 273–278. [Google Scholar] [CrossRef] [Green Version]
- Fabiana, R.V.; Marcos, F.; Galduróz, J.C.; Mastroianni, P.C. Adverse drug reaction as cause of hospital admission of elderly people: A pilot study. Lat. Am. J. Pharm. 2011, 30, 347–353. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-hill: New York, NY, USA, 1997. [Google Scholar]
- Chambers, J.; Hastie, T. Linear Models. In Statistical Models in S; Wadsworth & Brooks/Cole: Pacific Grove, CA, USA, 1992. [Google Scholar]
- Lindsey, J.; Data, C.; Lindsey, J. Generalized Linear Models; Springer: New York, NY, USA, 1996. [Google Scholar]
- Ziegel, E.R. An Introduction to Generalized Linear Models; Taylor & Francis: Abingdon, UK, 2002. [Google Scholar]
- Hilt, D.E.; Seegrist, D.W. Ridge: A Computer Program for Calculating Ridge Regression Estimates; Department of Agriculture, Forest Service, Northeastern Forest Experiment: Upper Darby, PA, USA, 1977. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Cilluffo, G.; Sottile, G.; La Grutta, S.; Muggeo, V.M. The Induced Smoothed lasso: A practical framework for hypothesis testing in high dimensional regression. Stat. Methods Med. Res. 2020, 29, 765–777. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H.; Popescu, B.E. Predictive learning via rule ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers [Internet]; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar] [CrossRef] [Green Version]
- Webb, G.I. Naïve Bayes. In Encyclopedia of Machine Learning [Internet]; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 713–714. [Google Scholar] [CrossRef]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin, Germany, 2016; pp. 207–235. [Google Scholar]
- Laaksonen, J.; Oja, E. Classification with learning k-nearest neighbors. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 1480–1483. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Fabbri, C.; Corponi, F.; Albani, D.; Raimondi, I.; Forloni, G.; Schruers, K.; Kautzky, A.; Zohar, J.; Souery, D.; Montgomery, S.; et al. Pleiotropic genes in psychiatry: Calcium channels and the stress-related FKBP5 gene in antidepressant resistance. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2018, 81, 203–210. [Google Scholar] [CrossRef] [PubMed]
- Maciukiewicz, M.; Marshe, V.S.; Hauschild, A.-C.; Foster, J.A.; Rotzinger, S.; Kennedy, J.L.; Kennedy, S.H.; Müller, D.J.; Geraci, J. GWAS-based machine learning approach to predict duloxetine response in major depressive disorder. J. Psychiatr. Res. 2018, 99, 62–68. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.R.; Kim, D.; Kim, S.Y. Prediction of acquired taxane resistance using a personalized pathway-based machine learning method. Cancer Res. Treat. Off. J. Korean Cancer Assoc. 2019, 51, 672. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cramer, D.; Mazur, J.; Espinosa, O.; Schlesner, M.; Hübschmann, D.; Eils, R.; Staub, E. Genetic interactions and tissue specificity modulate the association of mutations with drug response. Mol. Cancer Ther. 2020, 19, 927–936. [Google Scholar] [CrossRef]
- Su, R.; Liu, X.; Wei, L.; Zou, Q. Deep-Resp-Forest: A deep forest model to predict anti-cancer drug response. Methods 2019, 166, 91–102. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, P.; Gao, Z.; Wang, R.; Khalighi, K. Ensemble of machine learning algorithms using the stacked generalization approach to estimate the warfarin dose. PLoS ONE 2018, 13, e0205872. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.; Li, X.; Zhang, W.; Zhou, H.-H. Comparison of nine statistical model based warfarin pharmacogenetic dosing algorithms using the racially diverse international warfarin pharmacogenetic consortium cohort database. PLoS ONE 2015, 10, e0135784. [Google Scholar] [CrossRef]
- Sharabiani, A.; Bress, A.; Douzali, E.; Darabi, H. Revisiting warfarin dosing using machine learning techniques. Comput. Math. Methods Med. 2015, 2015, 560108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Truda, G.; Marais, P. Evaluating warfarin dosing models on multiple datasets with a novel software framework and evolutionary optimisation. J. Biomed. Inform. 2021, 113, 103634. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, R.; Luo, Z.-Y.; Yan, H.; Huang, W.-H.; Yin, J.-Y.; Mao, X.-Y.; Chen, X.-P.; Liu, Z.-Q.; Zhou, H.-H.; et al. Comparison of the predictive abilities of pharmacogenetics-based warfarin dosing algorithms using seven mathematical models in Chinese patients. Pharmacogenomics 2015, 16, 583–590. [Google Scholar] [CrossRef] [PubMed]
- Yılmaz Isıkhan, S.; Karabulut, E.; Alpar, C.R. Determining cutoff point of ensemble trees based on sample size in predicting clinical dose with DNA microarray data. Comput. Math. Methods Med. 2016, 2016, 6794916. [Google Scholar] [CrossRef] [PubMed]
- Chandak, P.; Tatonetti, N.P. Using machine learning to identify adverse drug effects posing increased risk to women. Patterns 2020, 1, 100108. [Google Scholar] [CrossRef] [PubMed]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Jin, X.; Han, J. K-Medoids Clustering. In Encyclopedia of Machine Learning [Internet]; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 564–565. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Mirkin, B. Hierarchical Clustering. Core Concepts in Data Analysis: Summarization, Correlation and Visualization; Springer: Berlin, Germany, 2011; pp. 283–313. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Tao, Y.; Zhang, Y.; Jiang, B. DBCSMOTE: A clustering-based oversampling technique for data-imbalanced warfarin dose prediction. BMC Med. Genom. 2020, 13, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Kautzky, A.; Baldinger, P.; Souery, D.; Montgomery, S.; Mendlewicz, J.; Zohar, J.; Serretti, A.; Lanzenberger, R.; Kasper, S. The combined effect of genetic polymorphisms and clinical parameters on treatment outcome in treatment-resistant depression. Eur. Neuropsychopharmacol. 2015, 25, 441–453. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Methods | Strengths | Limitations |
|---|---|---|
| GLM | The response variable can follow any distribution in the exponential family Easy to interpret | Affected by noisy data, missing values, multicollinearity and outliers |
| Ridge | Overcomes multicollinearity issues | Increased bias |
| LASSO | Avoids overfitting Effective in high dimensional settings | Selects only one feature from a group of correlated features |
| EN | Selects more than n predictors when n (sample size)<<p (# of variables) | Computationally expensive with respect to LASSO and Ridge |
| RT | Easy to implement Ability to work with incomplete information (missing values) | Computationally expensive |
| RF | High performance and accuracy | Less interpretability High prediction time |
| SVR | Easy to implement Robust to outliers | Unsuitable for large datasets Low performance in overlapping situations * |
| NB | Suitable for multi-class prediction problems | Independence assumption Assigns zero probability to category of a categorical variable in the test data set that was not available in the training dataset |
| SVM | Suitable for high dimensional settings | No probabilistic explanation for the classification Low performance in overlapping situations * Sensitive to outliers |
| KNN | Easy to implement | Affected by noisy data, missing values and outliers |
| NN | Robust to outliers Ability to work with incomplete information (missing values) | Computationally expensive |
| Reference | AIM | Included Population | Methodologies | Results |
|---|---|---|---|---|
| Fabbri 2018 [19] | To predict response to antidepressants | 671 patients | NN and RF | The best accuracy among the tested models was achieved by NN |
| Maciukiewicz 2018 [20] | To predict response to antidepressants | 186 patients | RT and SVM | SVM reported the best performance in predicting the antidepressants response. |
| Kim 2019 [21] | To study of the response to anti-cancer drugs | 1235 samples | EN, SVM and RF | Sophisticated machine learning algorithms allowed to develop and validate a highly accurate a multi-study–derived predictive model |
| Cramer 2019 [22] | To study of the response to anti-cancer drugs | 1001 cancer cell lines and 265 drugs | linear regression models | The interaction-based approach contributes to a holistic view on the determining factors of drug response. |
| Su 2019 [23] | To study of the response to anti-cancer drugs | 33,275 cancer cell lines and 24 drugs | Deep learning and RF | The proposed Deep-Resp-Forest has demonstrated the promising use of deep learning and deep forest approach on the drug response prediction tasks. |
| Ma 2018 [24] | To study the warfarin dosage prediction | 5743 patients | NN, Ridge, RF, SVR and LASSO | Novel regression models combining the advantages of distinct machine learning algorithms and significantly improving the prediction accuracy compared to linear regression have been obtained. |
| Liu 2015 [25] | To study the warfarin dosage prediction | 3838 patients | NN, RT, SVR, RF and LASSO | Machine learning-based algorithms tended to perform better in the low- and high- dose ranges than multiple linear regression. |
| Sharabiani 2015 [26] | To study the warfarin dosage prediction | 4237 patients | SVM | A novel methodology for predicting the initial dose was proposed, which only relies on patients’ clinical and demographic data. |
| Truda 2021 [27] | To study the warfarin dosage prediction | 5741 patients | Ridge, NN and SVR | SVR was the best performing traditional algorithm, whilst neural networks performed poorly. |
| Li 2015 [28] | To study the warfarin dosage prediction | 1295 patients | Linear regression model, NN, RT, SVR and RF | Multiple linear regression was the best performing algorithm. |
| Methods | Strengths | Limitations |
|---|---|---|
| K-means | Reallocation of entities is allowed No strict hierarchical structure | A priori choice of the number of clusters Dependent on the initial partition |
| K-medoids | Reallocation of entities is allowed No strict hierarchical structure | A priori choice of the number of clusters Dependent on the initial partition High computational burden |
| Agglomerative/ Divisive Hierarchical | Easy to implement Easy interpretation | Strict hierarchical structure Dependent on the updating rule |
| SOM | Reallocation of entities is allowed No strict hierarchical structure | A priori choice of the number of clusters Dependent on the number of iterations and initial weights |
| Reference | AIM | Included population | Methodologies | Results |
|---|---|---|---|---|
| Tao 2020 [36] | To balance the dataset of patients treated with warfarin and improve the predictive accuracy. | 592 patients | Cluster analysis | The algorithm detects the minority group, based on the association between the clinical features/genotypes and the warfarin dosage. |
| Kautzky 2015 [37] | To combine the effects of genetic polymorphisms and clinical parameters on treatment outcome in treatment-resistant depression. | 225 patients | Cluster analysis | Cluster analysis allowed identifying 5 clusters of patients significantly associated with treatment response. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cilluffo, G.; Fasola, S.; Ferrante, G.; Malizia, V.; Montalbano, L.; La Grutta, S. Machine Learning: An Overview and Applications in Pharmacogenetics. Genes 2021, 12, 1511. https://doi.org/10.3390/genes12101511
Cilluffo G, Fasola S, Ferrante G, Malizia V, Montalbano L, La Grutta S. Machine Learning: An Overview and Applications in Pharmacogenetics. Genes. 2021; 12(10):1511. https://doi.org/10.3390/genes12101511
Chicago/Turabian StyleCilluffo, Giovanna, Salvatore Fasola, Giuliana Ferrante, Velia Malizia, Laura Montalbano, and Stefania La Grutta. 2021. "Machine Learning: An Overview and Applications in Pharmacogenetics" Genes 12, no. 10: 1511. https://doi.org/10.3390/genes12101511
APA StyleCilluffo, G., Fasola, S., Ferrante, G., Malizia, V., Montalbano, L., & La Grutta, S. (2021). Machine Learning: An Overview and Applications in Pharmacogenetics. Genes, 12(10), 1511. https://doi.org/10.3390/genes12101511