Decision Variants for the Automatic Determination of Optimal Feature Subset in RF-RFE


Abstract
:1. Introduction
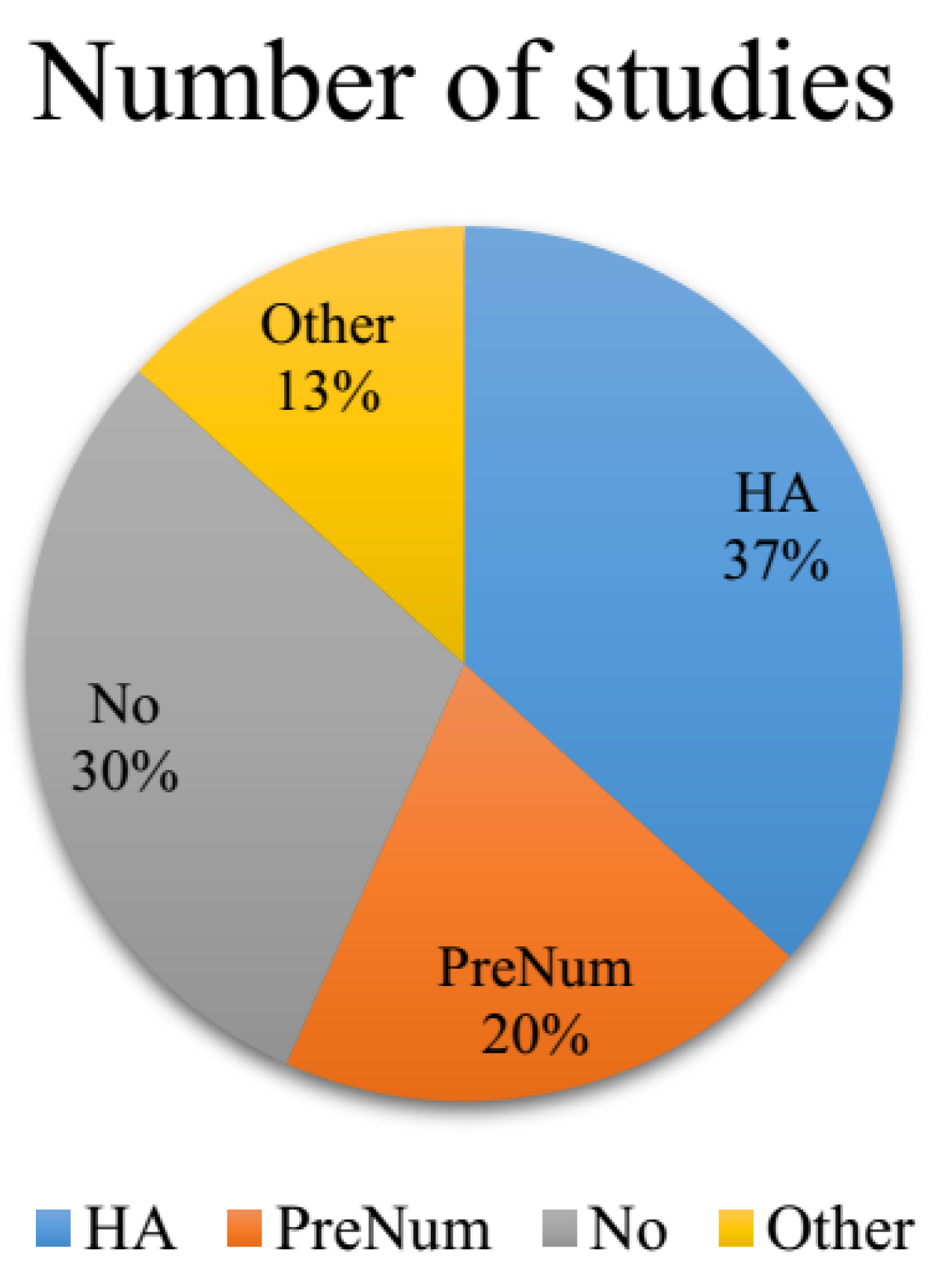
2. Related Works
3. Methods
3.1. Datasets and Preprocessing
3.2. Random Forest Classifier
3.3. Feature Selection Using Random Forest—Recursive Feature Elimination
3.4. Decision Variants for Recursive Feature Elimination
3.5. Voting Strategy for Subset Selection after Cross-Validation
3.6. Performance Measurements
4. Experimental Results
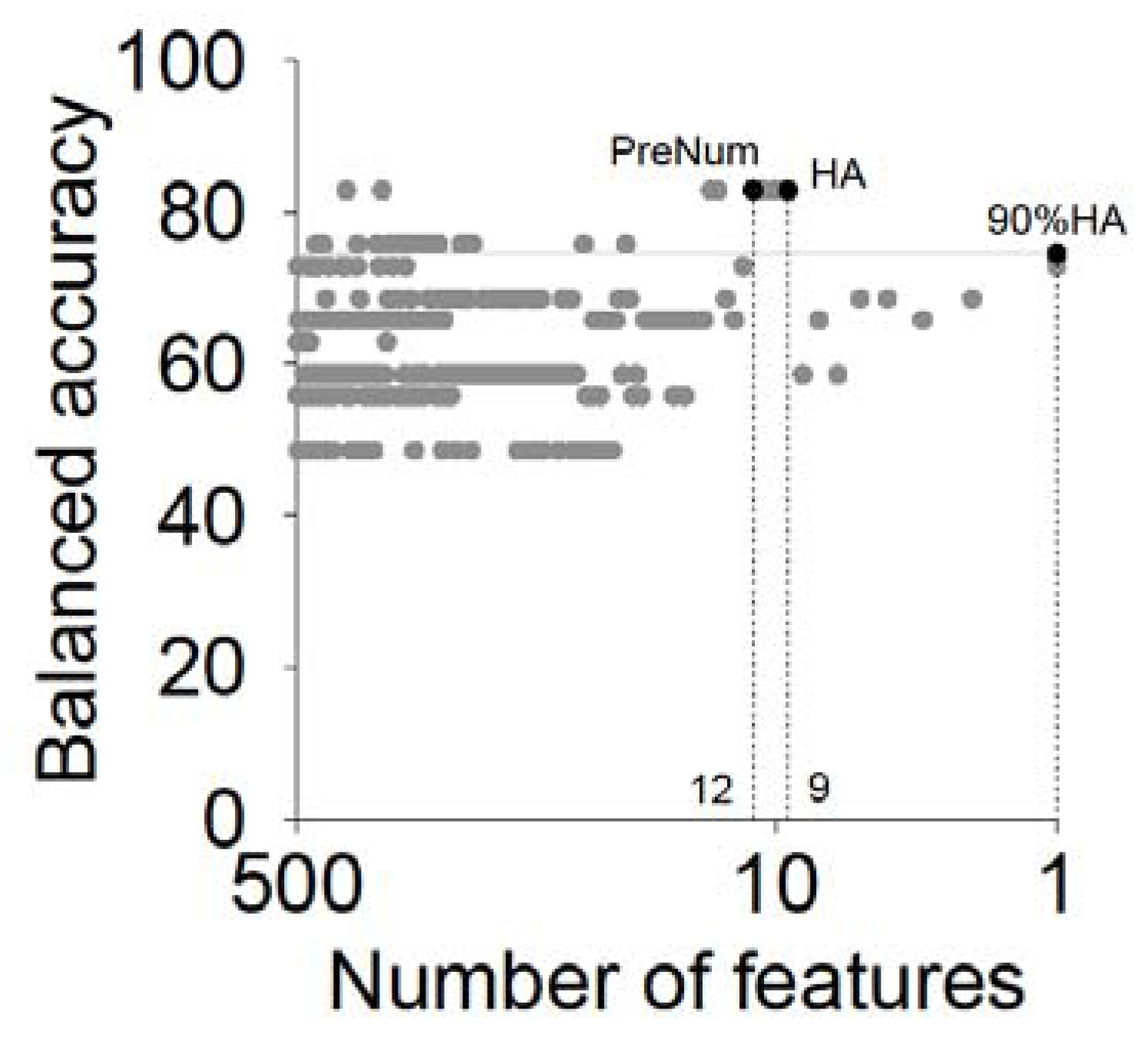
4.1. Performance Using the Voting Strategy
4.2. Performance Using Different Decision Variants
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Luukka, P. Feature selection using fuzzy entropy measures with similarity classifier. Expert Syst. Appl. 2011, 38, 4600–4607. [Google Scholar] [CrossRef]
- Zareapoor, M.; Seeja, K.R. Feature extraction or feature selection for text classification: A case study on phishing email detection. Int. J. Inf. Eng. Electron. Bus. 2015, 2, 60–65. [Google Scholar] [CrossRef]
- Su, R.; Xiong, S.; Zink, D.; Loo, L.H. High-throughput imaging-based nephrotoxicity prediction for xenobiotics with diverse chemical structures. Arch. Toxicol. 2016, 90, 2793–2808. [Google Scholar] [CrossRef] [PubMed]
- Saeys, Y.; Inza, I.; Larrañaga, P. WLD: Review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed]
- Igarashi, Y.; Nakatsu, N.; Yamashita, T.; Ono, A.; Ohno, Y.; Urushidani, T.; Yamada, H. Open TG-GATEs: A large-scale toxicogenomics database. Nucleic Acids Res. 2015, 43, 921–927. [Google Scholar] [CrossRef] [PubMed]
- Gautam, A.; Chaudhary, K.; Kumar, R.; Sharma, A.; Kapoor, P.; Tyagi, A.; Raghava, G.P.S. In silico approaches for designing highly effective cell penetrating peptides. J. Transl. Med. 2013, 11, 74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duan, K.B.; Rajapakse, J.C.; Wang, H.; Azuaje, F. Multiple SVM-RFE for gene selection in cancer classification with expression data. IEEE Trans. Nanobiosci. 2005, 4, 228–234. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artificial Intelligence. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar] [Green Version]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Bedo, J.; Sanderson, C.; Kowalczyk, A. An efficient alternative to SVM based recursive feature elimination with applications in natural language processing and bioinformatics. In Proceedings of the Australian Joint Conference on Artificial Intelligence: Advances in Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 170–180. [Google Scholar]
- Yang, F.; Mao, K.Z. Robust feature selection for microarray data based on multicriterion fusion. IEEE/ACM Trans. Comput. Biol. Bioinform. 2011, 8, 1080–1092. [Google Scholar] [CrossRef] [PubMed]
- Kim, S. Margin-maximised redundancy-minimised SVM-RFE for diagnostic classification of mammograms. Int. J. Data Min. Bioinform. 2014, 10, 374–390. [Google Scholar] [CrossRef] [PubMed]
- Yoon, S.; Kim, S. AdaBoost-based multiple SVM-RFE for classification of mammograms in DDSM. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops, Philadephia, PA, USA, 3–5 November 2008; pp. 75–82. [Google Scholar]
- Yang, R.; Zhang, C.; Gao, R.; Zhang, L. A novel feature extraction method with feature selection to identify Golgi-resident protein types from imbalanced data. Int. J. Mol. Sci. 2016, 17, 218. [Google Scholar] [CrossRef] [PubMed]
- Granitto, P.M.; Furlanello, C.; Biasioli, F.; Gasperi, F. Recursive feature elimination with random forest for PTR-MS analysis of agroindustrial products. Chemom. Intell. Lab. Syst. 2006, 83, 83–90. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Voyle, N.; Keohane, A.; Newhouse, S.; Lunnon, K.; Johnston, C.; Soininen, H.; Kloszewska, I.; Mecocci, P.; Tsolaki, M.; Vellas, B.; et al. A pathway based classification method for analyzing gene expression for Alzheimer’s disease diagnosis. J. Alzheimer's Dis. 2016, 49, 659–669. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.W.; Jeong, J.C. Enhanced recursive feature elimination. In Proceedings of the Six International Conference on Machine Learning and Applications, Clincinnati, OH, USA, 13–15 December 2007; pp. 429–435. [Google Scholar]
- Sánchez, A.S.; Hernández, J.C.H.; Hernández, H.P.M.; Guzmán, D.I.; Juárez, A.C.; Flores, A.A; Flores, P.M.Q. Feature selection for improvement the performance of an electric arc furnace. Res. Comput. Sci. 2015, 102, 101–112. [Google Scholar]
- Christian, J.; Kröll, J.; Strutzenberger, G.; Alexander, N.; Ofner, M.; Schwameder, H. Computer aided analysis of gait patterns in patients with acute anterior cruciate ligament injury. Clin. Biomech. 2016, 33, 55–60. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Yang, Y.; Stein, E.A.; Ross, T.J. Multivariate classification of smokers and nonsmokers using SVM-RFE on structural MRI images. Hum. Brain Mapp. 2015, 36, 4869–4879. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, K.J.; Ser, W.; Lin, Z.; Foo, C.G. Acoustic detection of excessive lung water using sub-band features. In Proceedings of the Circuits and Systems Conference. Dallas, TX, USA, 12–13 October 2015; pp. 1–4. [Google Scholar]
- Li, X.; Liu, T.; Tao, P.; Wang, C.; Chen, L. A highly accurate protein structural class prediction approach using auto cross covariance transformation and recursive feature elimination. Comput. Biol. Chem. 2015, 59, 95–100. [Google Scholar] [CrossRef] [PubMed]
- Pereira, T.; Paiva, J.S.; Correia, C.; Cardoso, J. An automatic method for arterial pulse waveform recognition using KNN and SVM classifiers. Med. Biol. Eng. Comput. 2016, 54, 1049–1059. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Zhuan, B.; Yan, Y.; Jiang, S.; Wang, T. Identification of gene markers in the development of smoking-induced lung cancer. Gene 2016, 576, 451–457. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Huang, X. Multiple SVM-RFE for multi-class gene selection on DNA-Microarray data. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–6. [Google Scholar]
- Zhang, L.; Wahle, A.; Chen, Z.; Lopez, J.; Kovarnik, T.; Sonka, M. Prospective Prediction of Thin-Cap Fibroatheromas from Baseline Virtual Histology Intravascular Ultrasound Data. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 603–610. [Google Scholar]
- Poona, N.K.; Niekerk, A.V.; Nadel, R.L.; Ismail, R. Random forest (RF) wrappers for waveband selection and classification of hyperspectral data. Appl. Spectrosc. 2016, 70, 322–333. [Google Scholar] [CrossRef] [PubMed]
- Tan, L.; Holland, S.K.; Deshpande, A.K.; Chen, Y.; Choo, D.I.; Lu, L.J. A semi-supervised Support Vector Machine model for predicting the language outcomes following cochlear implantation based on pre-implant brain fMRI imaging. Brain Behav. 2015, 5, e00391. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, A.K.; Srivastava, R.; Srivastava, S.; Tiwari, S. An efficient approach for the prediction of G-protein coupled receptors and their subfamilies. Smart Innov. Syst. Technol. 2016, 44, 577–584. [Google Scholar]
- Baur, B.; Bozdag, S. A feature selection algorithm to compute gene centric methylation from probe level methylation data. PLoS ONE 2016, 11, e0148977. [Google Scholar] [CrossRef] [PubMed]
- Liao, Y.; Li, S.E.; Wang, W.; Wang, Y. Detection of driver cognitive distraction: A comparison study of stop-controlled intersection and speed-limited highway. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1628–1637. [Google Scholar] [CrossRef]
- Qian, S.; Sun, Y.; Xiong, Z. Intelligent chatter detection based on wavelet packet node energy and LSSVM-RFE. In Proceedings of the IEEE International Conference on Advanced Intelligent Mechatronics, Pusan, Korea, 7–11 July 2015; pp. 1514–1519. [Google Scholar]
- Spetale, F.E.; Bulacio, P.; Guillaume, S.; Murillo, J.; Tapia, E. A spectral envelope approach towards effective SVM-RFE on infrared data. Pattern Recognit. Lett. 2016, 71, 59–65. [Google Scholar] [CrossRef] [Green Version]
- Taneja, M.; Garg, K.; Purwar, A.; Sharma, S. Prediction of click frauds in mobile advertising. In Proceedings of the Eighth International Conference on Contemporary Computing, Noida, India, 20–22 August 2015; pp. 162–166. [Google Scholar]
- Bevilacqua, V.; Salatino, A.A.; Leo, C.D.; Tattoli, G. Advanced classification of Alzheimer’s disease and healthy subjects based on EEG markers. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–5. [Google Scholar]
- Devi, C.; Devaraj, D.; Venkatesulu, M.; Krishnaveni, S. An empirical analysis of gene selection using machine learning algorithms for cancer classification. Int. J. Appl. Eng. Res. 2015, 10, 7909–7922. [Google Scholar]
- Fernandez-Lozano, C.; Cuiñas, R.F.; Seoane, J.A.; Fernández-Blanco, E.; Dorado, J.; Munteanu, C.R. Classification of signaling proteins based on molecular star graph descriptors using Machine Learning models. J. Theor. Biol. 2015, 384, 50. [Google Scholar] [CrossRef] [PubMed]
- Kenichi, O.; Naoya, O.; Kengo, I.; Hidenao, F. Effects of imaging modalities, brain atlases and feature selection on prediction of Alzheimer’s disease. J. Neurosci. Methods 2015, 256, 168–183. [Google Scholar]
- Mishra, S.; Mishra, D. SVM-BT-RFE: An improved gene selection framework using Bayesian t-test embedded in support vector machine (recursive feature elimination) algorithm. Karbala Int. J. Mod. Sci. 2015, 1, 86–96. [Google Scholar] [CrossRef]
- Song, N.; Wang, K.; Xu, M.; Xie, X.; Chen, G.; Wang, Y. Design and analysis of ensemble classifier for gene expression data of cancer. Adv. Genet. Eng. 2015, 5. [Google Scholar] [CrossRef]
- Son, H.; Lee, S.; Kim, C. An empirical investigation of key pre-project planning practices affecting the cost performance of green building projects. Procedia Eng. 2015, 118, 37–41. [Google Scholar] [CrossRef]
- Chanel, G.; Pichon, S.; Conty, L.; Berthoz, S.; Chevallier, C.; Grèzes, J. Classification of autistic individuals and controls using cross-task characterization of fMRI activity. Neuroimage Clin. 2016, 10, 78–88. [Google Scholar] [CrossRef] [PubMed]
- Nyström-Persson, J.; Igarashi, Y.; Ito, M.; Morita, M.; Nakatsu, N.; Yamada, H.; Mizuguchi, K. Toxygates: Interactive toxicity analysis on a hybrid microarray and linked data platform. Bioinformatics 2013, 29, 3080–3086. [Google Scholar] [CrossRef] [PubMed]
- Gautier, L.; Cope, B.; Bolstad, M.B.; Irizarry, R.A. Affy-Analysis of Affymetrix GeneChip data at the probe level. Bioinformatics 2004, 20, 307–315. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Zhang, A. Feature selection for classifying high-dimensional numerical data. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 252, pp. 251–258. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| υ | Number of Features | Balanced Accuracy (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|
| 7 | 1 | 52.93 | 42.22 | 63.64 |
| 6 | 1 | 52.93 | 42.22 | 63.64 |
| 5 | 2 | 57.47 | 42.22 | 72.73 |
| 4 | 4 | 61.21 | 46.67 | 75.76 |
| 3 | 6 | 66.41 | 55.56 | 77.27 |
| 2 | 12 | 72.78 | 62.22 | 83.33 |
| 1 | 42 | 66.16 | 44.44 | 87.88 |
| 0 | 151 | 55.40 | 24.44 | 86.36 |
| Without FS | 500 | 47.57 | 13.33 | 81.82 |
| Number of Features | Balanced Accuracy (%) | Sensitivity (%) | Specificity (%) | |
|---|---|---|---|---|
| HA | 12 | 72.78 | 62.22 | 83.33 |
| 90% HA | 17 | 77.27 | 66.67 | 87.87 |
| PreNum (12) | 26 | 75.40 | 64.44 | 86.36 |
| Without FS | 500 | 47.57 | 13.33 | 81.82 |
| Number of Features | Balanced Accuracy (%) | Sensitivity (%) | Specificity (%) | |
|---|---|---|---|---|
| HA | 17 | 70.05 | 66.84 | 73.26 |
| 90% HA | 17 | 68.18 | 64.17 | 72.19 |
| PreNum (17) | 24 | 70.05 | 67.91 | 72.19 |
| Without FS | 188 | 65.24 | 61.50 | 68.98 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Meng, Z.; Liu, X.; Jin, Q.; Su, R. Decision Variants for the Automatic Determination of Optimal Feature Subset in RF-RFE. Genes 2018, 9, 301. https://doi.org/10.3390/genes9060301
Chen Q, Meng Z, Liu X, Jin Q, Su R. Decision Variants for the Automatic Determination of Optimal Feature Subset in RF-RFE. Genes. 2018; 9(6):301. https://doi.org/10.3390/genes9060301
Chicago/Turabian StyleChen, Qi, Zhaopeng Meng, Xinyi Liu, Qianguo Jin, and Ran Su. 2018. "Decision Variants for the Automatic Determination of Optimal Feature Subset in RF-RFE" Genes 9, no. 6: 301. https://doi.org/10.3390/genes9060301
APA StyleChen, Q., Meng, Z., Liu, X., Jin, Q., & Su, R. (2018). Decision Variants for the Automatic Determination of Optimal Feature Subset in RF-RFE. Genes, 9(6), 301. https://doi.org/10.3390/genes9060301