1. Introduction
O
3, NO
x, SO
2, CO, and PM
2.5 are major pollutants in the urban atmosphere that have been shown to directly or indirectly cause cardiovascular and respiratory disease, and even premature death. Among these air pollutants, fine particles (PM
2.5 or particulate matter with an aerodynamic diameter no larger than 2.5 microns) are of particular concern [
1]. They are complex and variable cocktails of toxic chemicals, including carcinogenic polycyclic aromatic hydrocarbons and dozens of heavy metals, which can suspend in the atmosphere and accumulate over time by penetrating deep into the lungs through human respiration [
2,
3]. Fuel combustion, such as motor vehicles, is the main source of PM
2.5 in the urban atmosphere, with significant spatial heterogeneity within cities. There is growing evidence that intra-urban gradients in PM
2.5 exposures are associated with different health outcomes [
4,
5]. The live monitoring of air contaminants and public disclosure of current air quality data have both been crucial strategies for reducing the impact [
6]. To track and forecast air pollution, numerous air quality monitoring stations have been constructed. However, the observed data provided by these observation stations cannot accurately depict the regional air pollution’s real-time geographical distribution, and have difficulty capturing the spatial variability of PM
2.5 at the urban street scale, which is of tremendous practical value for thorough spatial analysis and time-series prediction [
7,
8].
Historically, statistical and physical methods have been developed and used to predict air pollution at regional and even global scales [
9,
10,
11,
12,
13]. Chemical transport models (CTMs) are arguably the most reliable prediction tool in the air quality community. However, CTMs are still not ideal for simulating high-resolution intra-urban PM
2.5 distribution due to the high uncertainty of local emission inventories and complex urban street canyon effects. In addition, CTMs are usually highly specialized and expensive to run in terms of time and computational cost, making them difficult to be easily adopted by policy makers and epidemiologists. In the past few years, artificial intelligence (AI) and machine learning (ML) have been rapidly evolving to extract the nonlinear features of historical data effectively, thus leading to more competitive prediction performance than statistical and physical methods. They are now increasingly used in areas such as biology (e.g., protein structure prediction), chemistry (e.g., chemical reaction mechanisms), pharmacology (e.g., drug screening), computational graphics [
14], and speech recognition, since they do not need to consider the complex mechanisms within the system when predicting, and are therefore also applicable to the prediction of atmospheric pollutants.
Deep learning-based methods are at the forefront of artificial intelligence, and are well suited for big data mining and prediction [
15]. Among them, long short-term memory (LSTM) is particularly popular because of its significant advantages in understanding and processing time series data [
10,
16,
17,
18]. This method only considers time correlation, which is obviously insufficient to reflect the spatial and temporal coupling of air pollution. Recently, the convolutional neural network (CNN) has been shown to compensate for the shortcomings of LSTM in spatial analysis, leading to studies combining the two for air quality prediction [
19,
20,
21,
22]. Nevertheless, accurately mapping air quality requires a deeper understanding of the associations between air pollutants in time, space, and across-domain levels. For example, for PM
2.5 at a given monitoring station at a given time, its concentration level is correlated with historical PM
2.5 concentration levels at that station, PM
2.5 concentration levels at neighboring stations, and other meteorological parameters and gaseous precursors, all of which can hardly be addressed by simply merging LSTM and CNN.
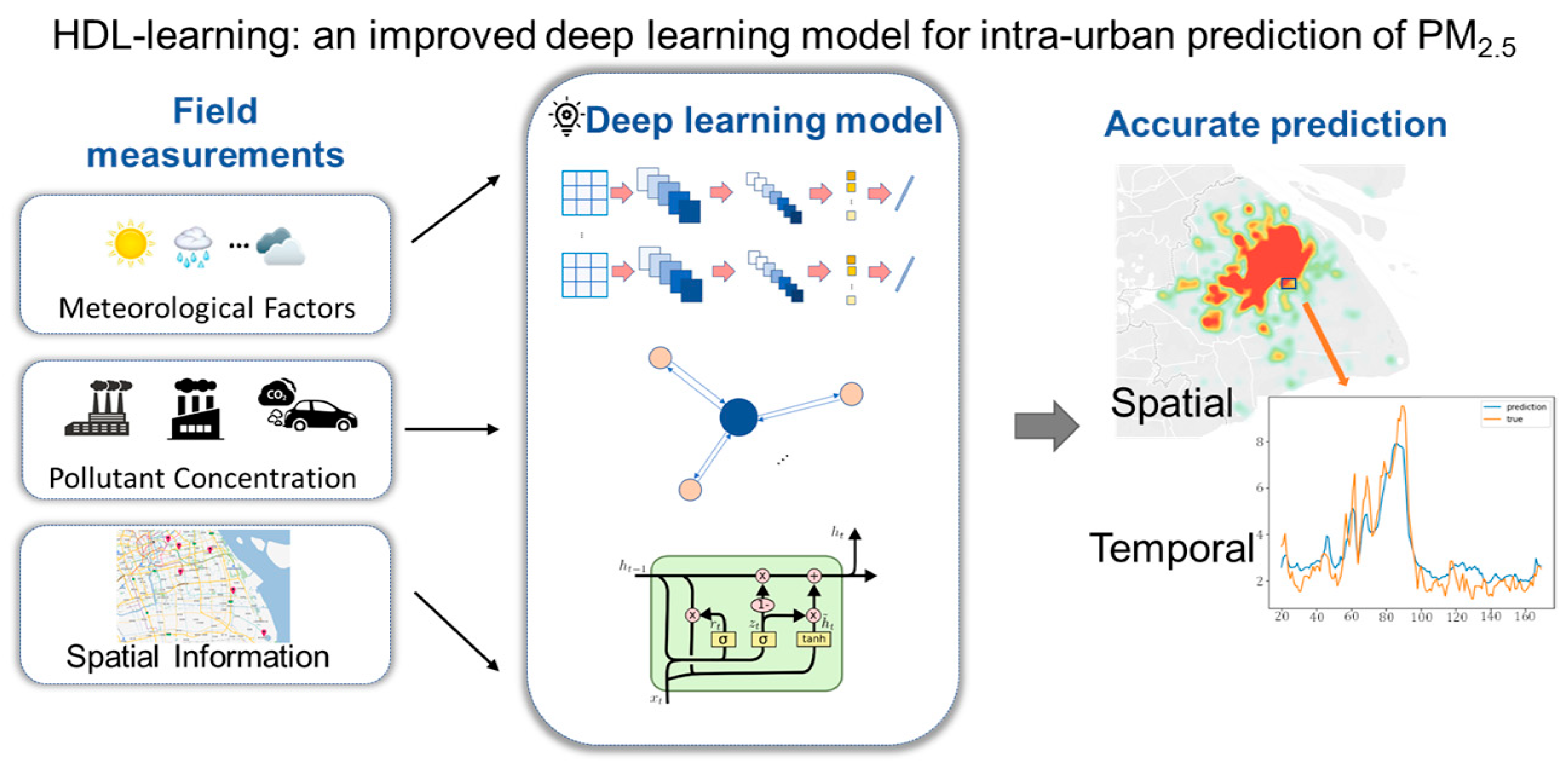
In this study, we propose a hybrid deep learning (HDL) framework (termed as HDL-learning) based on CNN-LSTM to improve the prediction of the intra-urban PM
2.5 concentration (
Figure 1). The framework differs from previous studies in that, firstly, a two-dimensional CNN (2D-CNN) was applied to matrices with dimensions of data types and time series for a given station to extract nonlinear correlations of the cross-domain information and timing patterns. Subsequently, a Gaussian function was incorporated to extract the distance-based correlation of air pollutant concentrations from the given station and other stations. Finally, LSTM was designed to fully analyze and extract the long-term historical features of the input time series data to yield time series prediction data. We tested the efficiency and validity of our proposed method in the megacity of Shanghai.
2. Materials and Methods
2.1. HDL-Learning
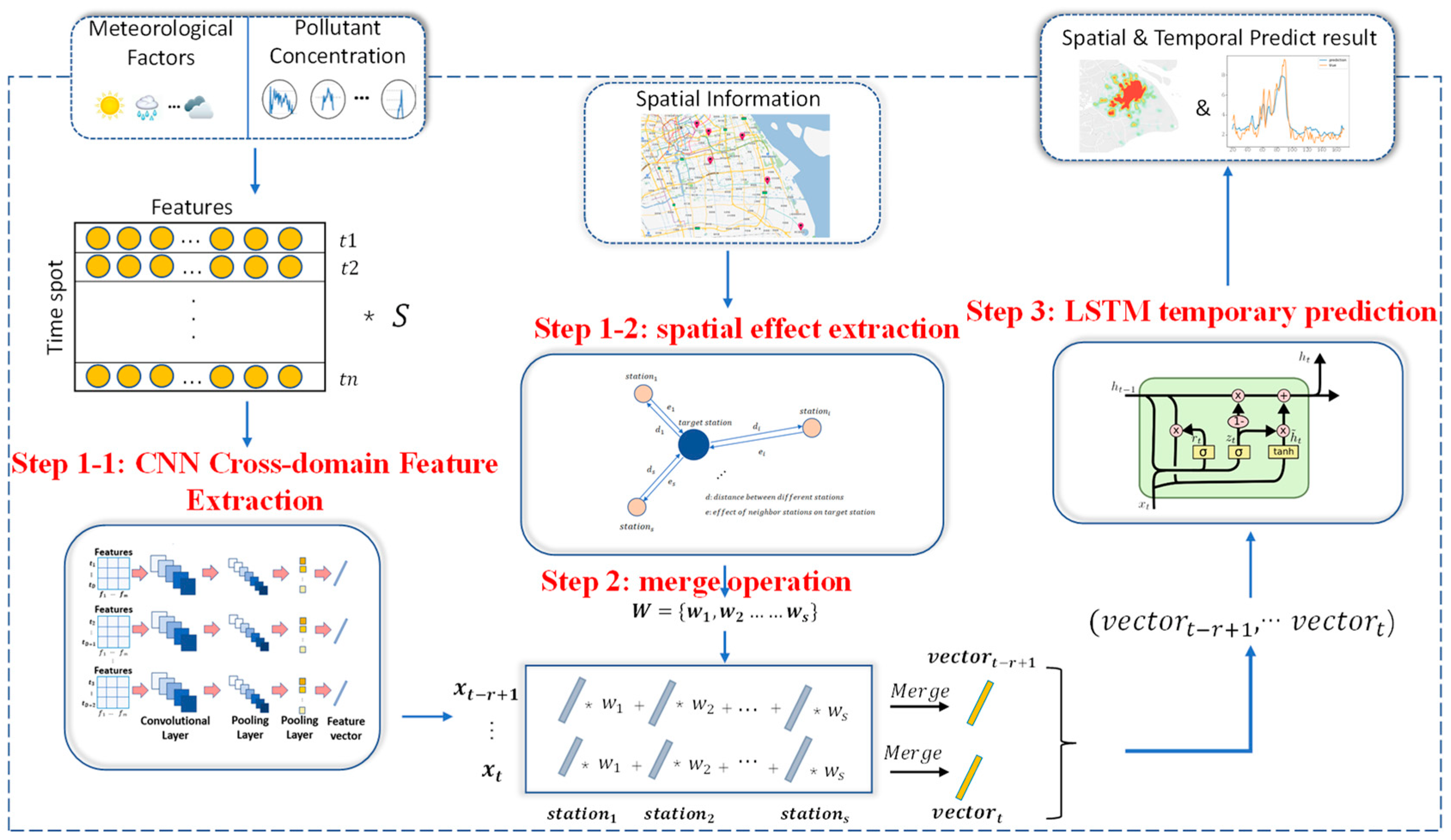
A hybrid deep learning framework called HDL-learning was developed here to predict the intra-urban variability of PM
2.5 concentrations. The overall structure of the proposed framework is illustrated in
Figure 2. In the model we consider that the local PM
2.5 concentration at a given moment is influenced by three main factors: the cross-domain characteristics represented by various other environmental and weather parameters at the area, the spatial characteristics of environmental and weather parameters in the surrounding area, and the time-series characteristics generated by historical environmental parameters. For this reason, the model proposed in this study contains three components that effectively represent and integrate these three interactions. Firstly, our model uses a two-dimensional CNN network to compress and extract the cross-domain features and short-term time-dependent features of the input data (see description below) to obtain the feature vector. Meanwhile, in order to fully extract the spatial features, we calculate the weights based on the distances between other stations and the target station using a Gaussian function as a representation of the extent of environmental pollution conditions in the surrounding area on the target station. Finally, after the vector weighting calculation, the set of vectors was imported into the LSTM prediction model for time series prediction to obtain the results. The model consists of three main components: the CNN feature extraction layer, the Gaussian weight calculation layer, and the LSTM series prediction model.
2.2. CNN Feature Extraction Layer
The CNN model is one of the most researched and widely used models in the field of deep learning in recent years [
23,
24]. It uses local connectivity and shared weights to obtain effective representations directly from the original data by alternating between convolutional and pooling layers, automatically extracting local features of the data and building dense, complete eigenvectors.
In a CNN network, the convolution layer extracts local features of the sample data by controlling the size of the convolution kernel. The pooling layer is generally in the layer below the convolution layer and is mainly used for feature selection, reducing the feature dimension of the original data and preventing overfitting. The fully-connected layer is responsible for integrating the local features extracted earlier, and then outputting the final result. The formula for calculating each element in the feature map is:
In the formula, is the output value and is the input vector; is for the activation function; is the weight value at position ; and is the bias in every calculation process.
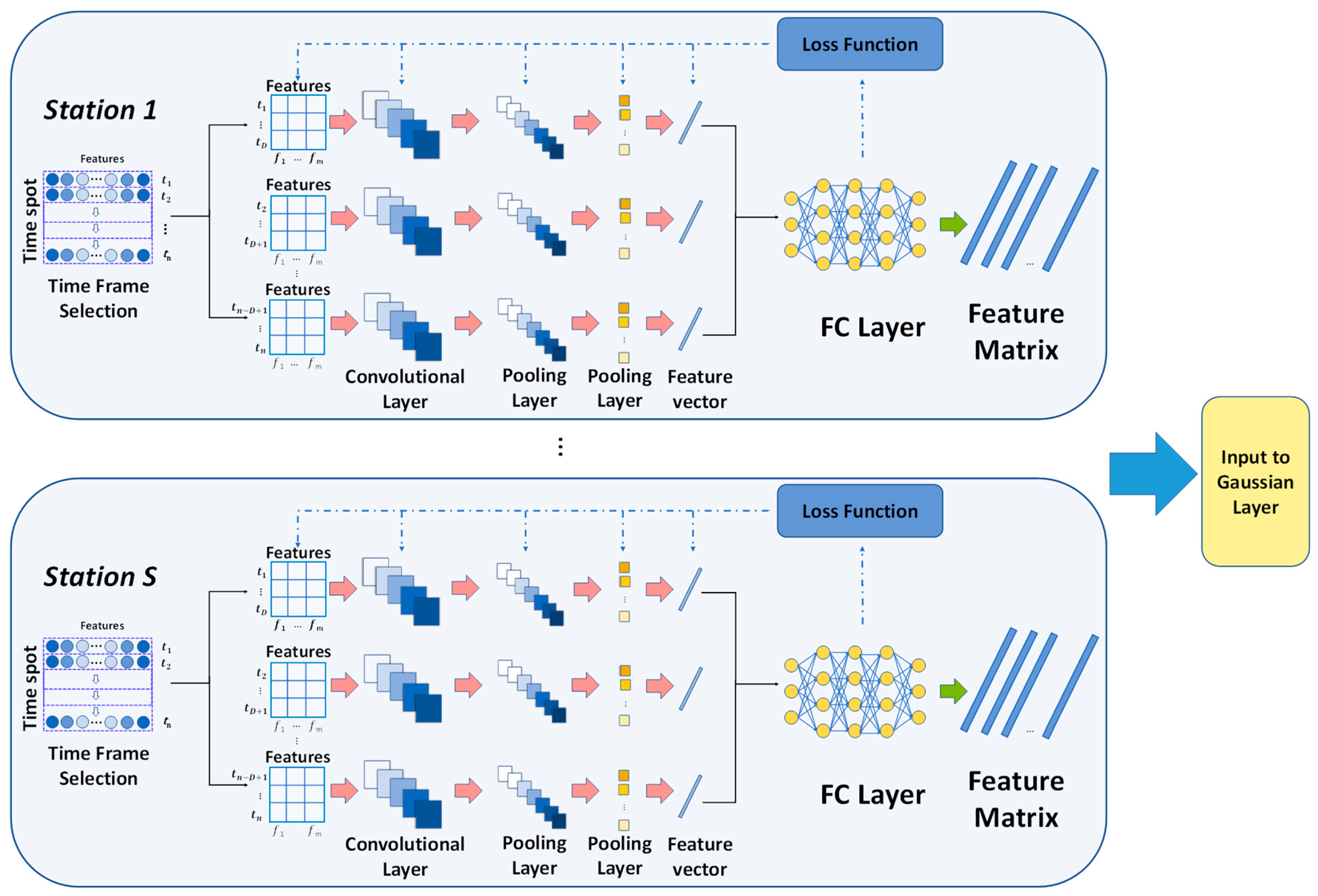
For the ability to extract data features, we use it to extract temporal features and cross-domain features for each station. We pre-set a time window of length
. For each moment in a time span of length
, m-dimensional data containing air quality and meteorological information in a time period of length
centered at moment
are extracted. In other words, at each moment in time
in a single station, we obtain a matrix of
representing the temporal and cross-domain features. Those matrixes are input into CNN for feature extraction. After convolution and pooling layers the extracted features were flattened into a 1-D array. Finally, the feature map containing the meteorological and air pollutant information of each station in every time spot was generated through the fully connected output layers, and the above steps were then applied to all stations. The structure diagram of this part is shown in
Figure 3.
2.3. Gaussian Weight Calculation Layer
In each time spot, the output of the CNN layer is high dimension vectors, in which s is the number of air quality monitoring stations. Each output of vectors is calculated individually by CNN; therefore, it can precisely represent the information of low-dimension inputs.
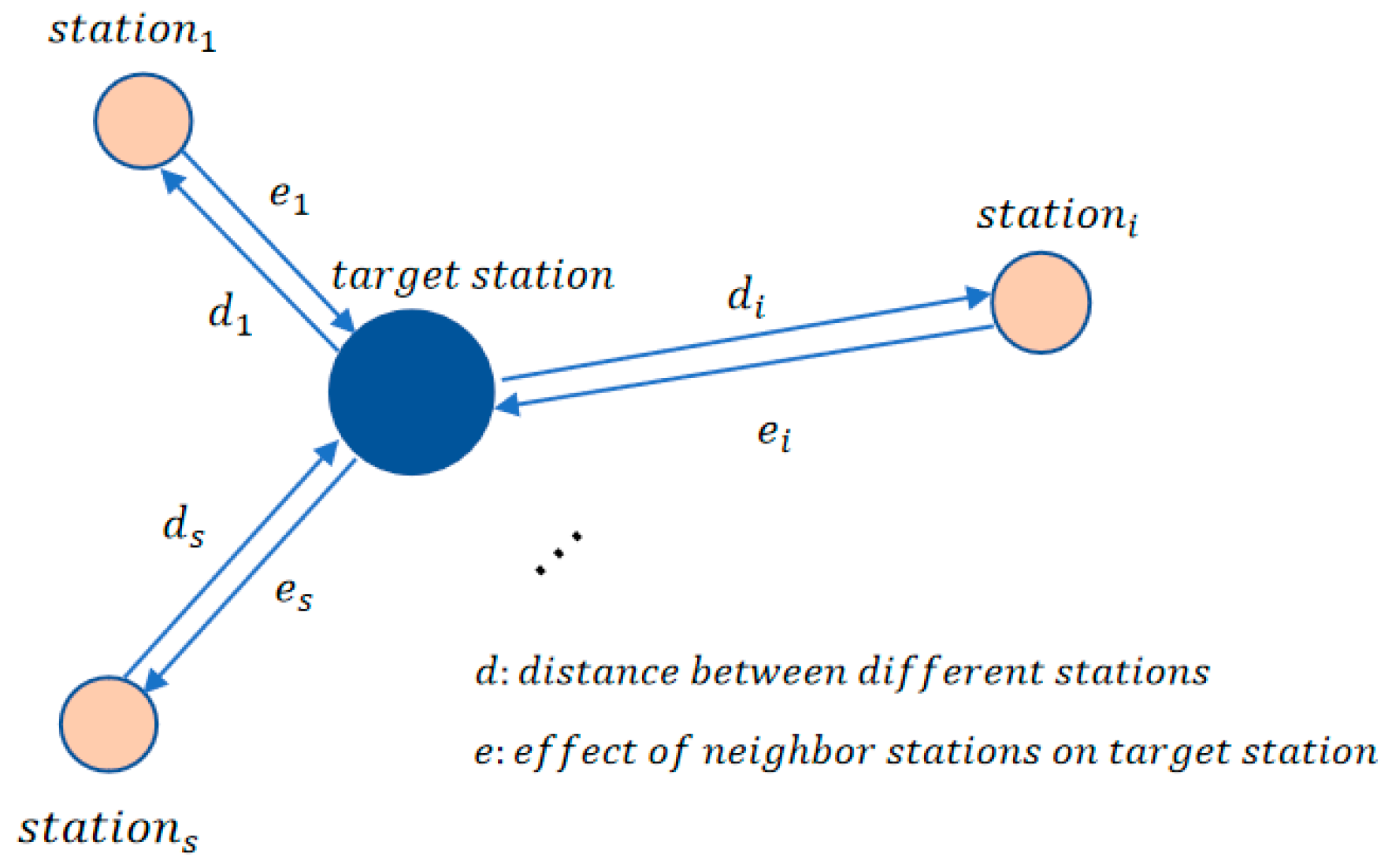
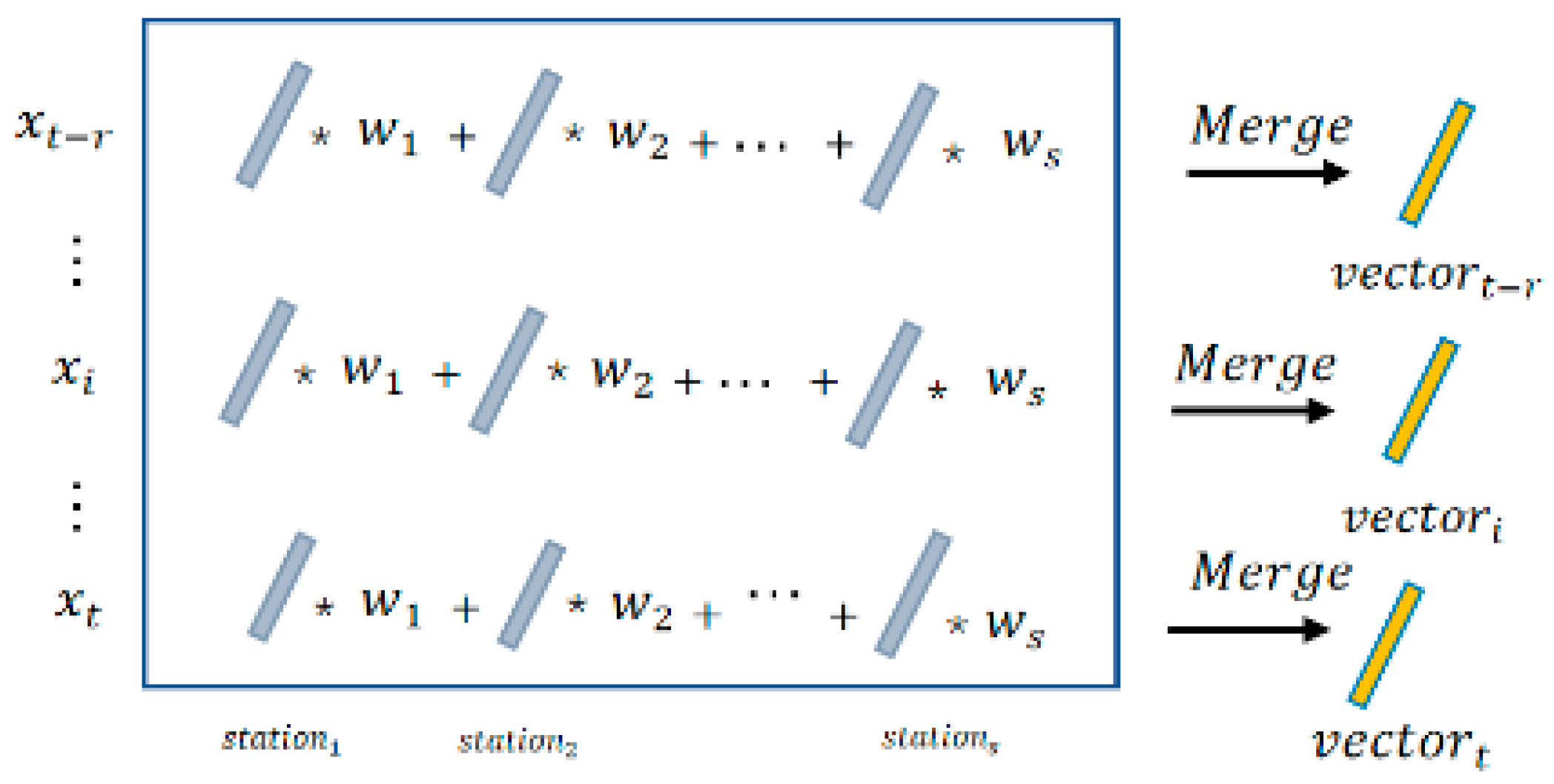
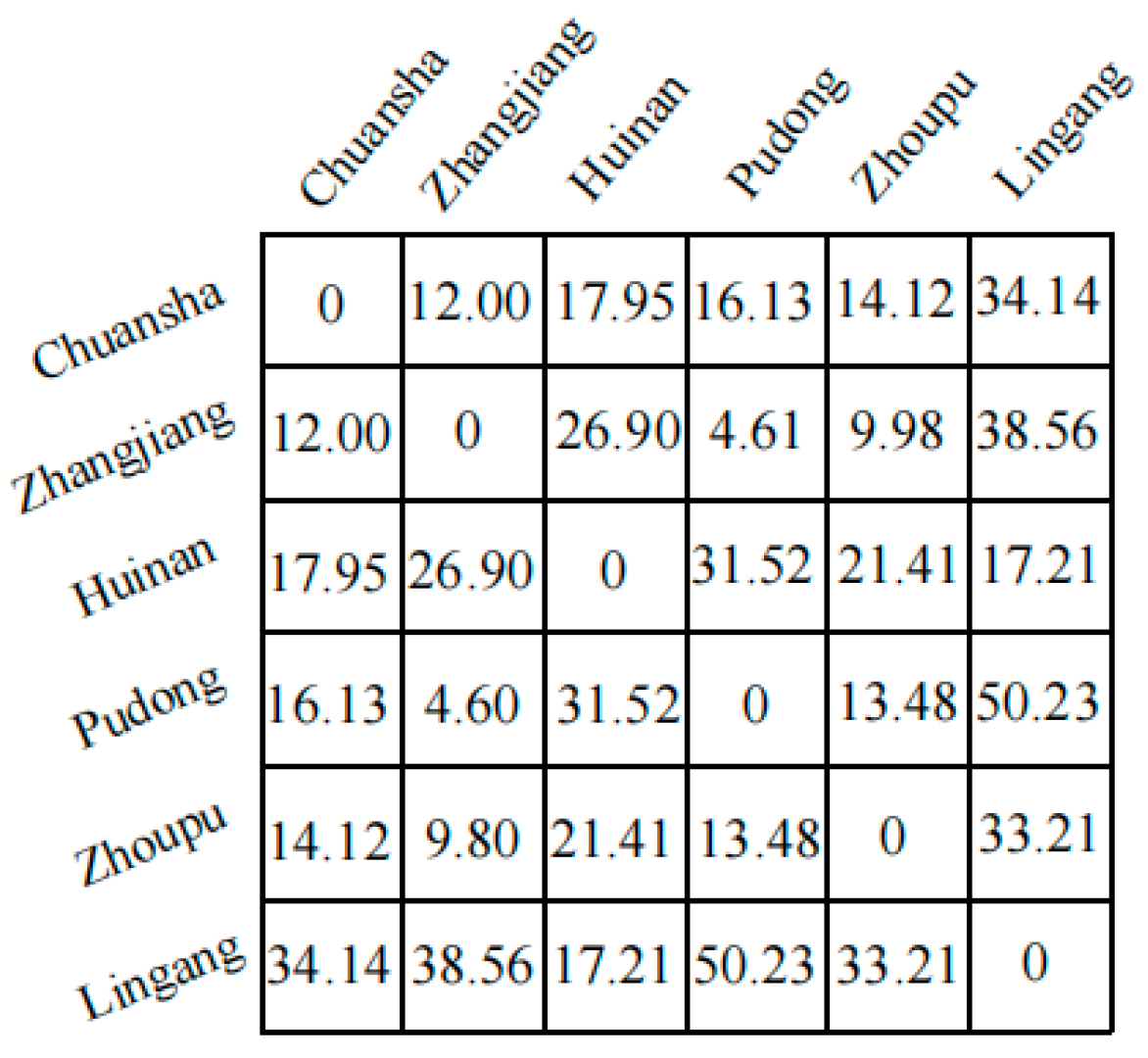
Since pollutant concentrations are affected by the spatial relationship, and the impact of pollutant concentrations in different areas on the target area follows the principle that the closer the distance, the greater the influence, we used the Gaussian model to calculate the effective degree of each neighbor station based on distance (
Figure 4). In the Gaussian weight calculation layer, the station expected to be predicted is considered as target station, and distances between the other station and the target station are fed into a Gaussian function with pre-set parameters to calculate the corresponding weights which represent the spatial influence from other regions on the PM
2.5 concentration at the target station. The output of CNN for the s stations at one moment was merged into one-dimensional vectors in a time series before being inputted to LSTM.
s one-dimensional vectors were outputted during the time period (
) to calculate the effective weights for each station based on its distance between target stations. The Gaussian function has the special feature that the weight is 1 when the distance between two points is the shortest among all neighbors, and tends to 0 as the distance increases. The effective weights are calculated as Equations (2) and (3).
where
is the geographical distance between station
and the target station. The merging operation process is shown in
Figure 5. In this operation, for each moment, the feature vectors of each station around the target station are multiplied and summed by the corresponding weights to obtain the merged vector. The fused vectors are then fed into the LSTM for temporal prediction.
2.4. LSTM Prediction Model
The output vector of the merge operation is then inputted to the LSTM layer. Value of for hours before time are the input of LSTM time series prediction model, and the prediction target is the hourly PM2.5 concentration value for time . is the input and represents the dynamic time series. is for the weight matrix. C is for the memory unit. h is the hidden layer information and is the bias. The training process for LSTM is as follows:
i. The LSTM first selectively forgets some past PM2.5 data information and other factors and we choose the σ (sigmoid) function as the activation function of the forget gate LSTM.
The value of the forget gate
is limited between 0 to 1. As shown in Equation (4), by multiplying
and in Equation (5), the memory unit of time
t − 1
, if the element value of
tends to 0, it means the corresponding feature information in
is forgotten, and if the element value of
tends to 1, it means that the corresponding feature information is saved.
ii. determine the new information to be stored in the storage unit.
The new information consists of two parts. The output gate
determines the updated information and the initial updated value
is the new candidate value vector. Equations (6) and (7) are their calculation process. By multiplying
and
, the important feature information updated value
is selected and stored in the memory unit.
iii. Update the state of memory unit:
iv. Finally determine the prediction output information:
is obtained from the output gate and the memory unit status , where the calculation method of is the same as that of and . After that, the entire model is fine-tuned via stochastic gradient descent to attain global optimization.
LSTM adds the temporal prediction function to the model. Its inputs are one-dimensional vectors representing the real data features. Therefore, complicated and redundant calculations are avoided and reliance of the data on the temporal dimension is considered.
2.5. Experiment Setting
2.5.1. Dataset Preparation and Model Setting
China took less than a decade to establish the world’s largest air pollution monitoring network after severe haze pollution events in 2013. As of 2020, there were ~1630 state-controlled monitoring sites that required data to be released publicly. In this study, historical air quality and meteorological data (past L-hour) were used to train the model to predict hourly PM
2.5 mass concentrations (future n-hour) at a given site. To this end, we focused on Shanghai and considered air quality (including PM
2.5, PM
10, SO
2, NO
2, CO, and O
3; in μg m
−3) and meteorological data (including temperature, relative humidity, wind direction, and wind speed) measured at six stations (i.e., Pudong, Zhoupu, Huinan, Chuansha, Zhangjiang, and Lingang). In total, 52,705 hourly data points were successfully obtained throughout the year 2020, in which 200-day and 166-day datasets were used for the training (adjusting relevant parameters in our models) and validation (to test the performance of our model) of our method, respectively. Details of the data we used in the study are shown in
Text S1, Table S1, and Figure S1 in the Supplementary Materials. For missing data, linear spline imputation was used to interpolate and thus reconstruct a continuous and reliable dataset (For details, refer to
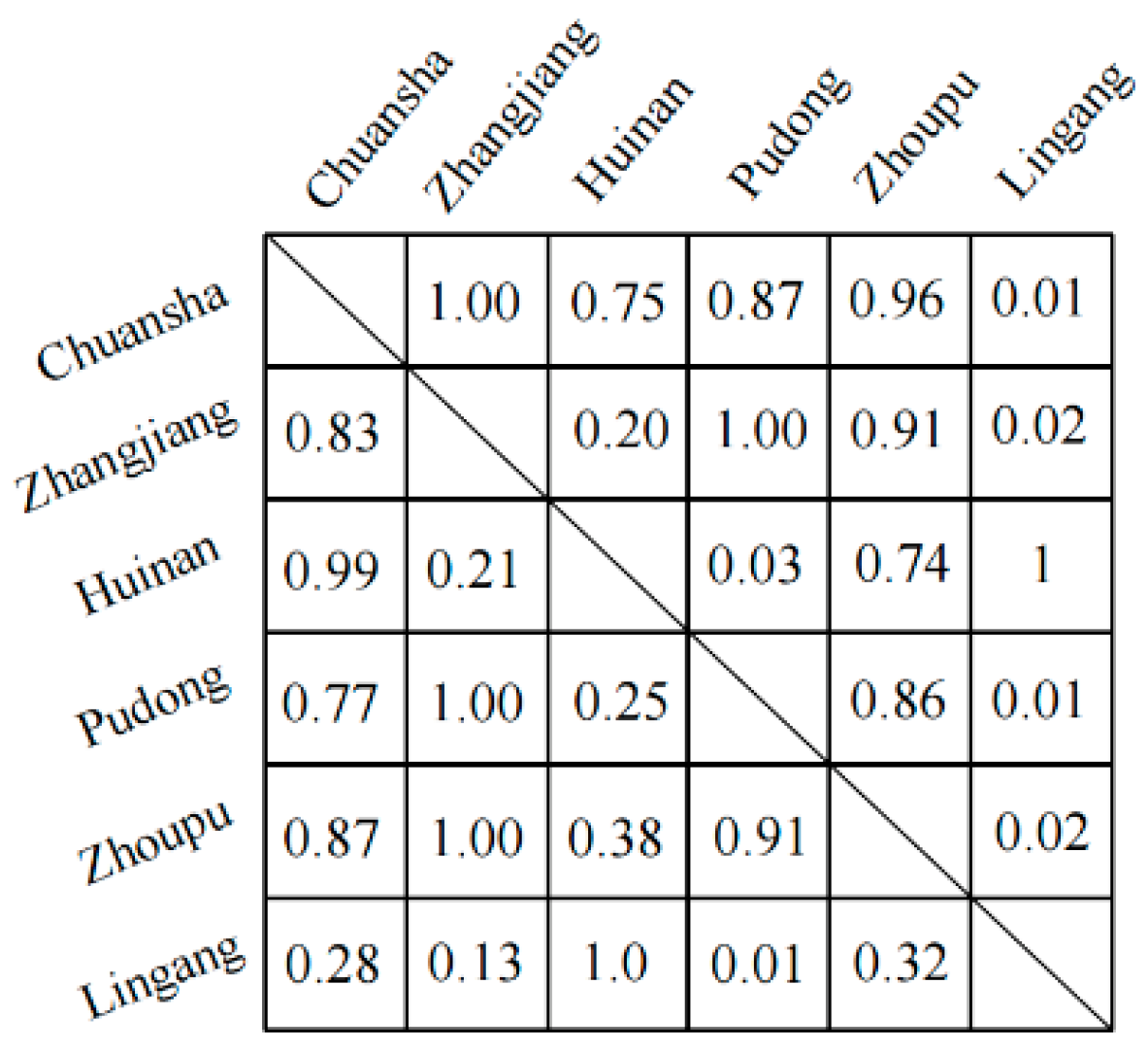
Text S2 of the Supplementary Materials). To elucidate the correlation between pollutants and each weather variable, we did a correlation analysis of each variable prior to the formal experiment, and as a result, we found various positive and negative correlations between and within the pollutant data and weather data, with details in
Text S2 and Figure S2 of the Supplementary Materials. After that, air quality and data were normalized in the range of [−1, 1] as an input to the CNN model, and wind speed/direction data were encoded and normalized as input to the subsequent network. The hyperparameters of the proposed model are contained in
Text S3 of the Supplementary Materials.
The problem is formed as follows: given air pollutant data , meteorological data , where S is the set of air quality monitoring stations , and T is the current timestamp, we aim to predict the AQI over the next K hours for from former air pollutant and meteorological data.
2.5.2. Inter-Comparison Parameters of Model Performance
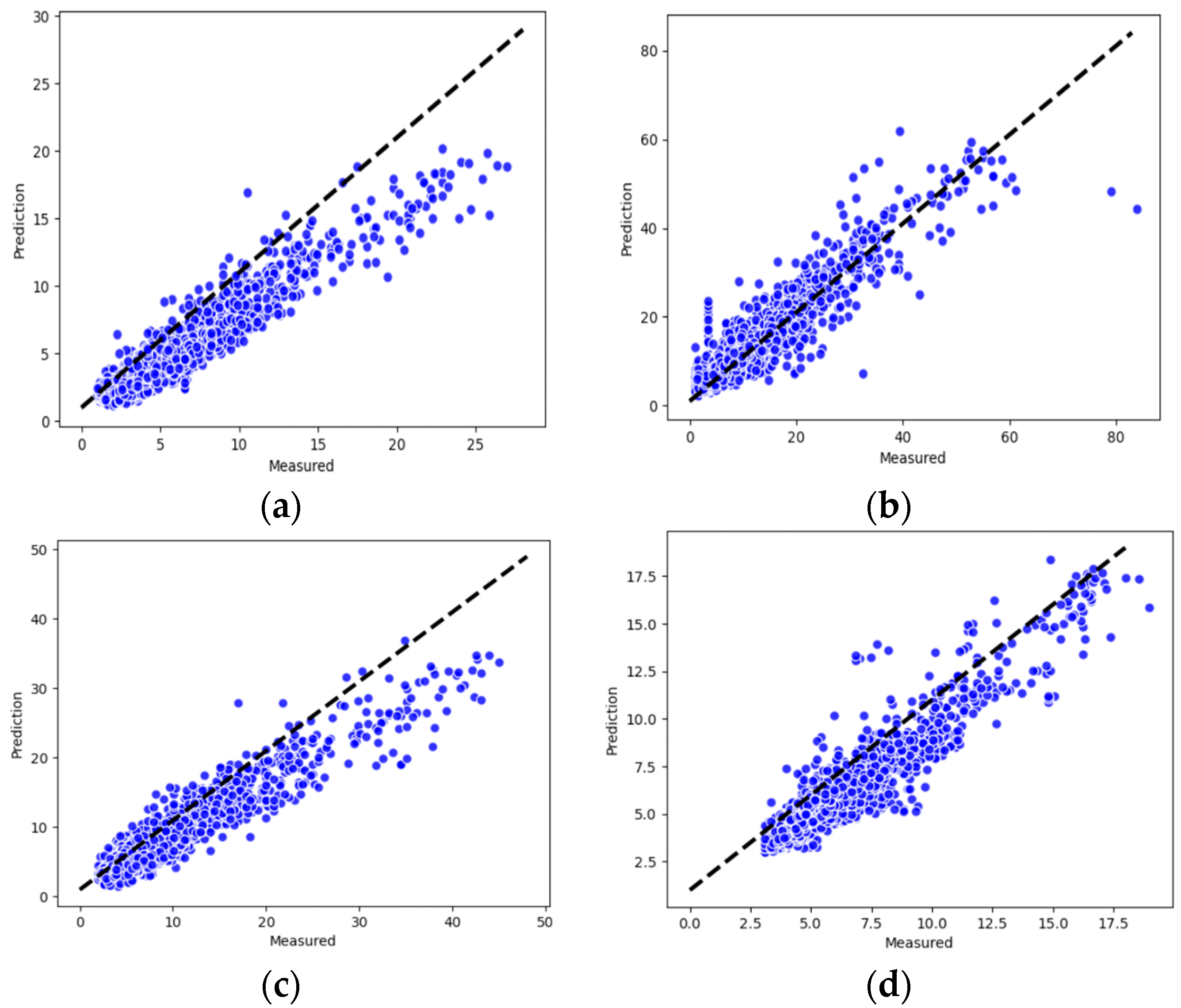
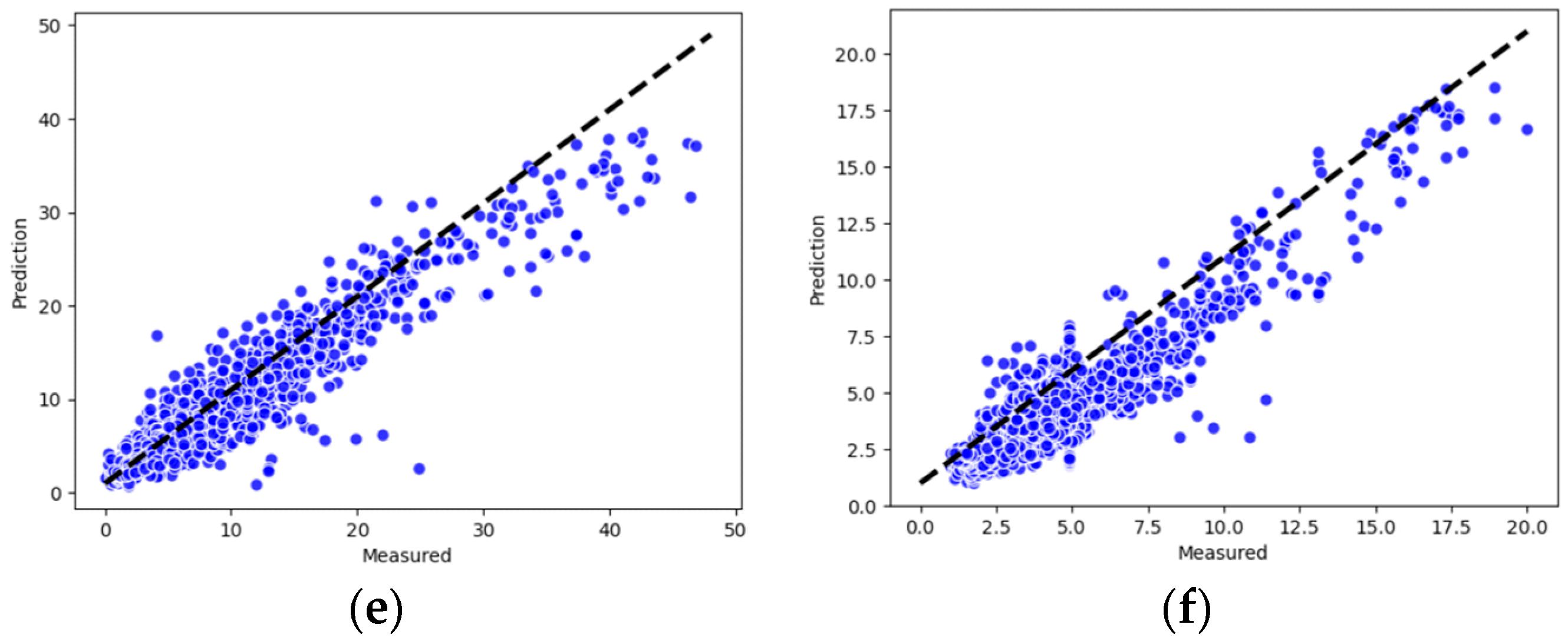
Using the same dataset as the model input, the performance of the new model proposed in this study was compared with benchmark methods used previously. Three inter-comparison parameters were used to quantitatively evaluate their performance in terms of PM2.5 prediction.
Root mean square error (RMSE). RMSE quantifies the deviation between the predicted data and the actual data. A low value of RMSE indicates precise prediction.
Mean absolute error (MAE). MAE is the average value of absolute error, which can better reflect the actual situation of prediction error.
Determination coefficient (R2). The R2 score measures how well a statistical model predicts an outcome by calculating the proportion of variance in the dependent variable that is predicted by the statistical model.
RMSE and MAE are negatively oriented, which means that lower scores imply the better performance of models, while the R2 scores are positively oriented.
4. Conclusions
Operating a reliable air quality forecasting model in an urban area is one of the most important tools for health protection. The accurate prediction of air quality requires accurate modelling of temporal patterns in air quality data as well as the precise analysis of interactions between pollutants and meteorological data from the cross-domain aspect. We proposed a deep learning method to accomplish this by putting together the newly designed CNN, Gaussian weight layer, and LSTM in a hierarchical architecture. The main contributions of our model are as follows:
To take spatial and temporal factors which influence the PM2.5 concentration at station level into consideration, we leveraged data from multiple sources, including air pollutants and meteorological data from six sites covering the main area of the Pudong district. A huge improvement over previous studies was the utilization of high-frequency meteorological data and pollutant data from an official source.
We calculated weights by Gaussian function and applied them to different site data, which fully considers the spatial and temporal influence of surrounding sites on the target site. Our method can be extended to predict PM2.5 concentration in any area.
Our innovative use of CNNs to extract cross-domain features and time-dependent features for different dimensional inputs in a single site has been shown to be accurate and efficient in experiments, with the memory function of the LSTM network explaining the dependence of the data on the time dimension. This improves the accuracy of the model’s time series prediction results.
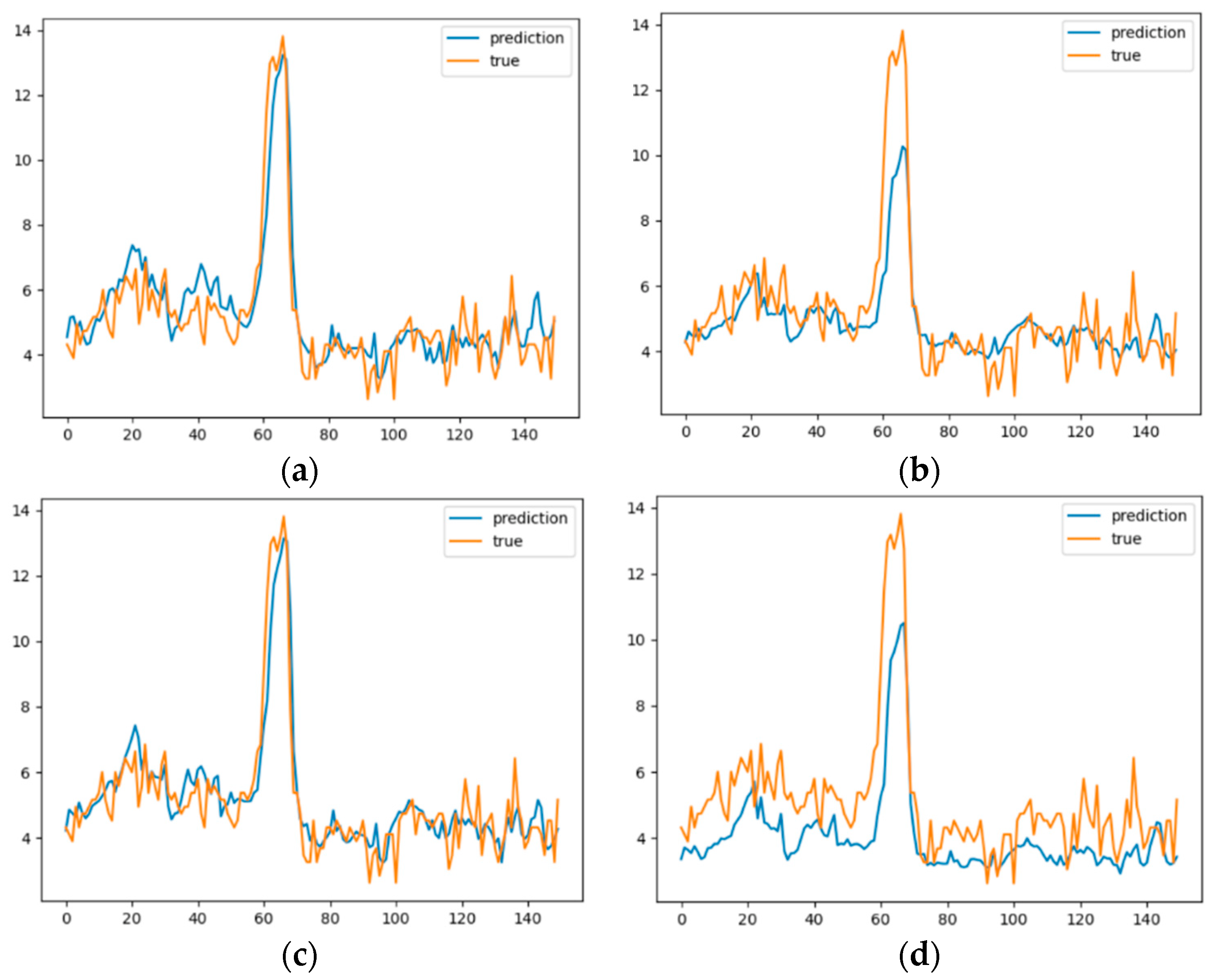
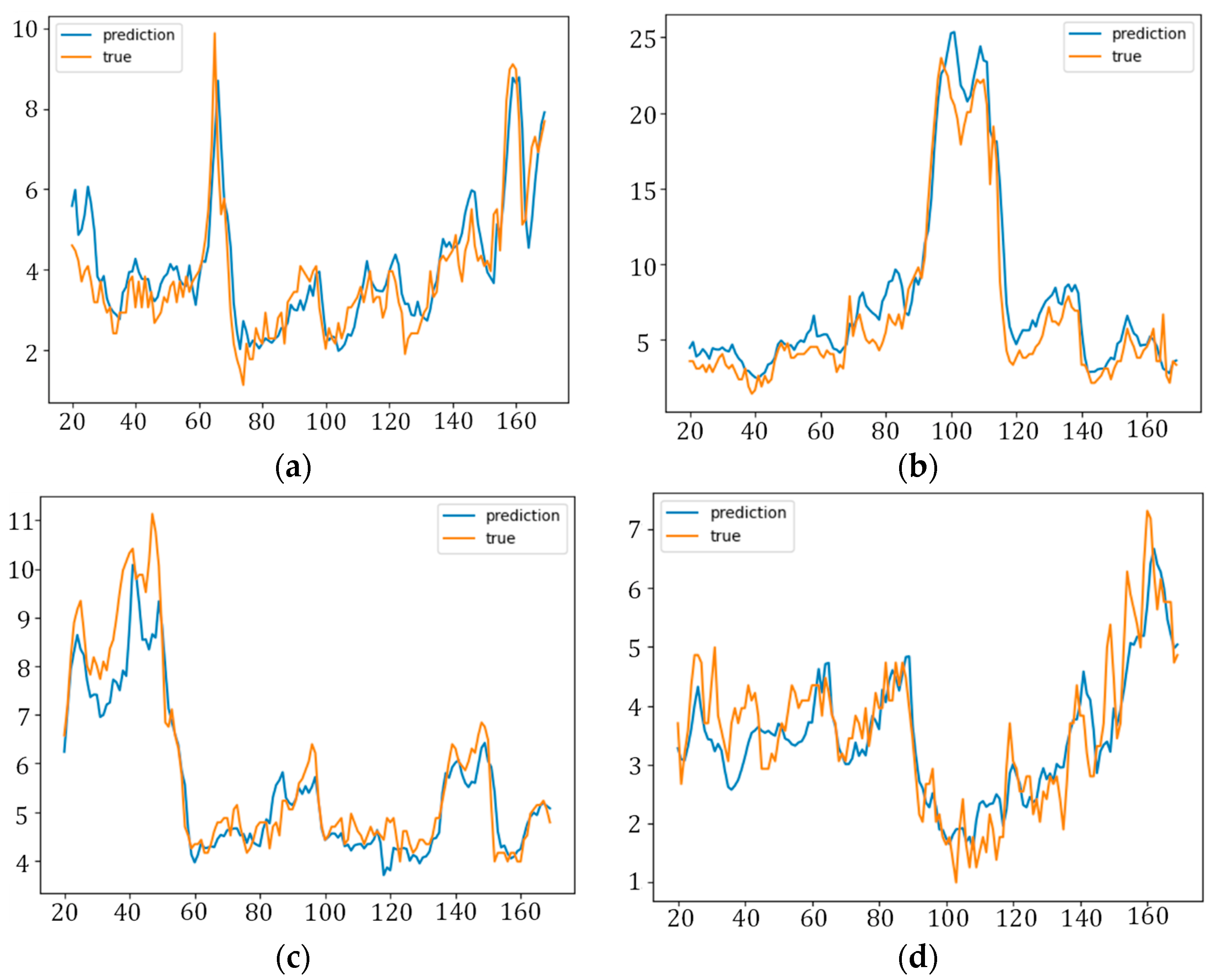
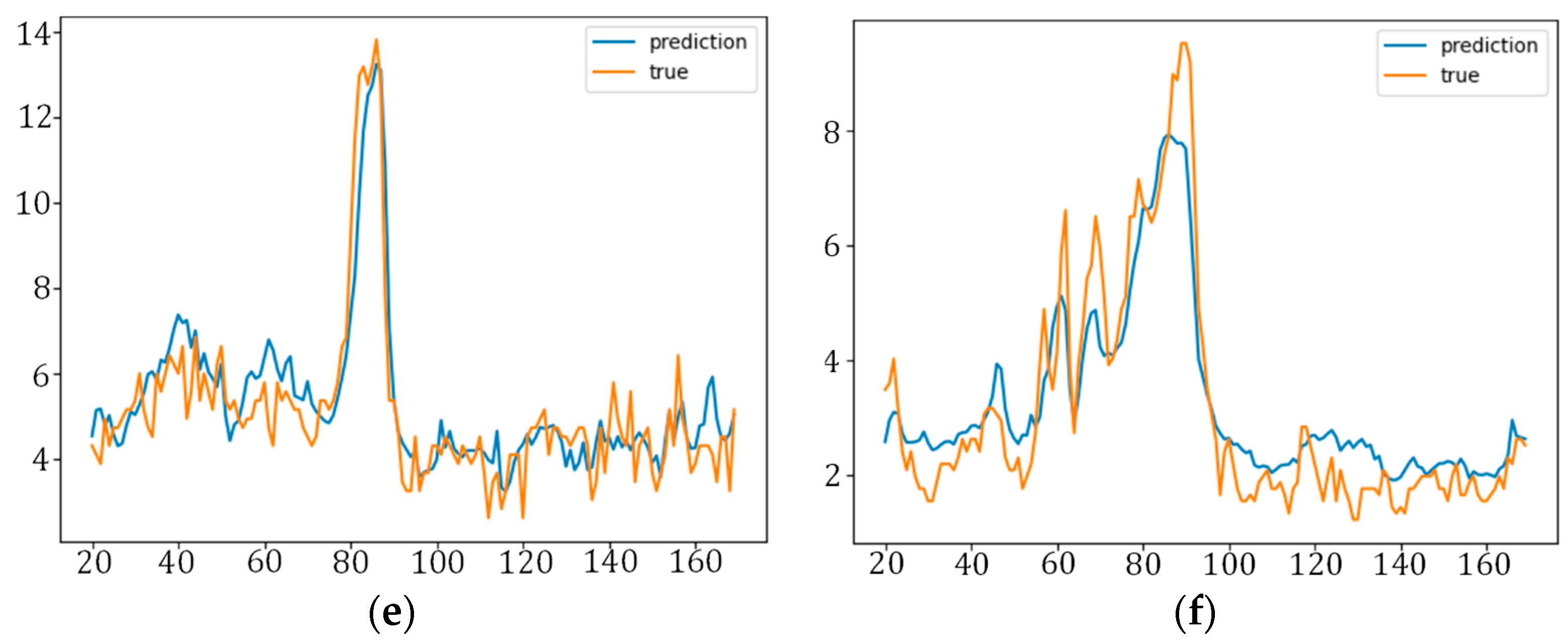
The application of the dataset in Shanghai demonstrates the improved performance of the proposed method over classic models for next-hour air quality prediction.
The HDL-learning model was trained and validated for forecasting the air quality of six counties in Pudong, Shanghai. When compared with the baseline geographically unweighted approaches, our method showed huge improved accuracy, and it reduced the error by at least 15%. Furthermore, our model showed consistent performance in predicting instances among all counties. Therefore, the proposed method can be utilized to provide valuable support to the city administration and to trigger early warnings for adverse air quality events. Our model also has some limitations, including that the CNN network is still limited in extracting deeper variable associations and the Gaussian function is still crude in modelling the influence of the geographical location between sites. In the future, ensemble-based approaches will be explored and incorporated along with the proposed model for further improvement in the prediction performance of the proposed framework.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}