
Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models


 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Methods
2.1. Study Area
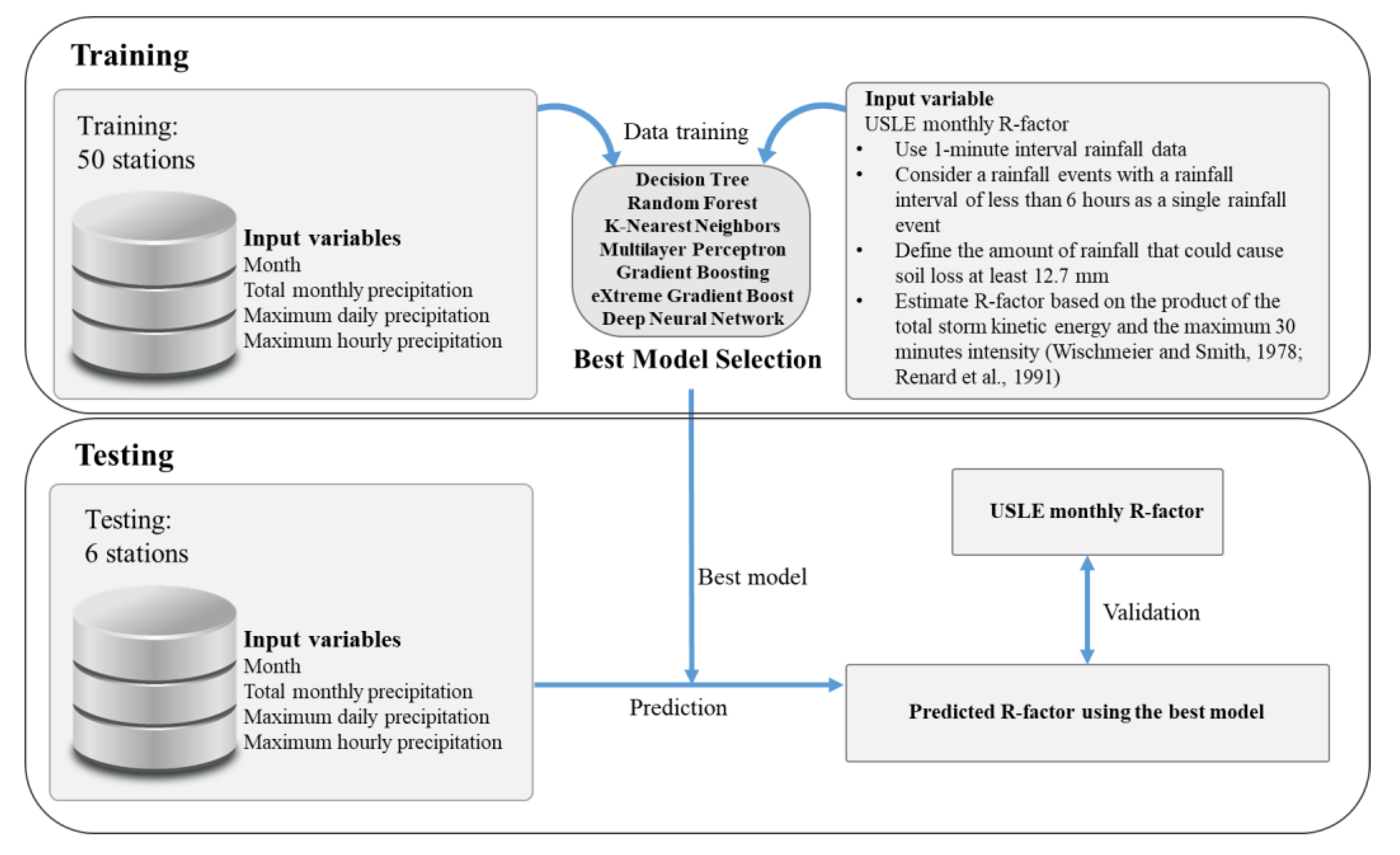
2.2. Monthly Rainfall Erosivity Calculation
2.3. Machine Learning Models
2.3.1. Decision Tree
2.3.2. Random Forest
2.3.3. K-Nearest Neighbors
2.3.4. Gradient Boosting and eXtreme Gradient Boost
2.3.5. Multilayer Perceptron
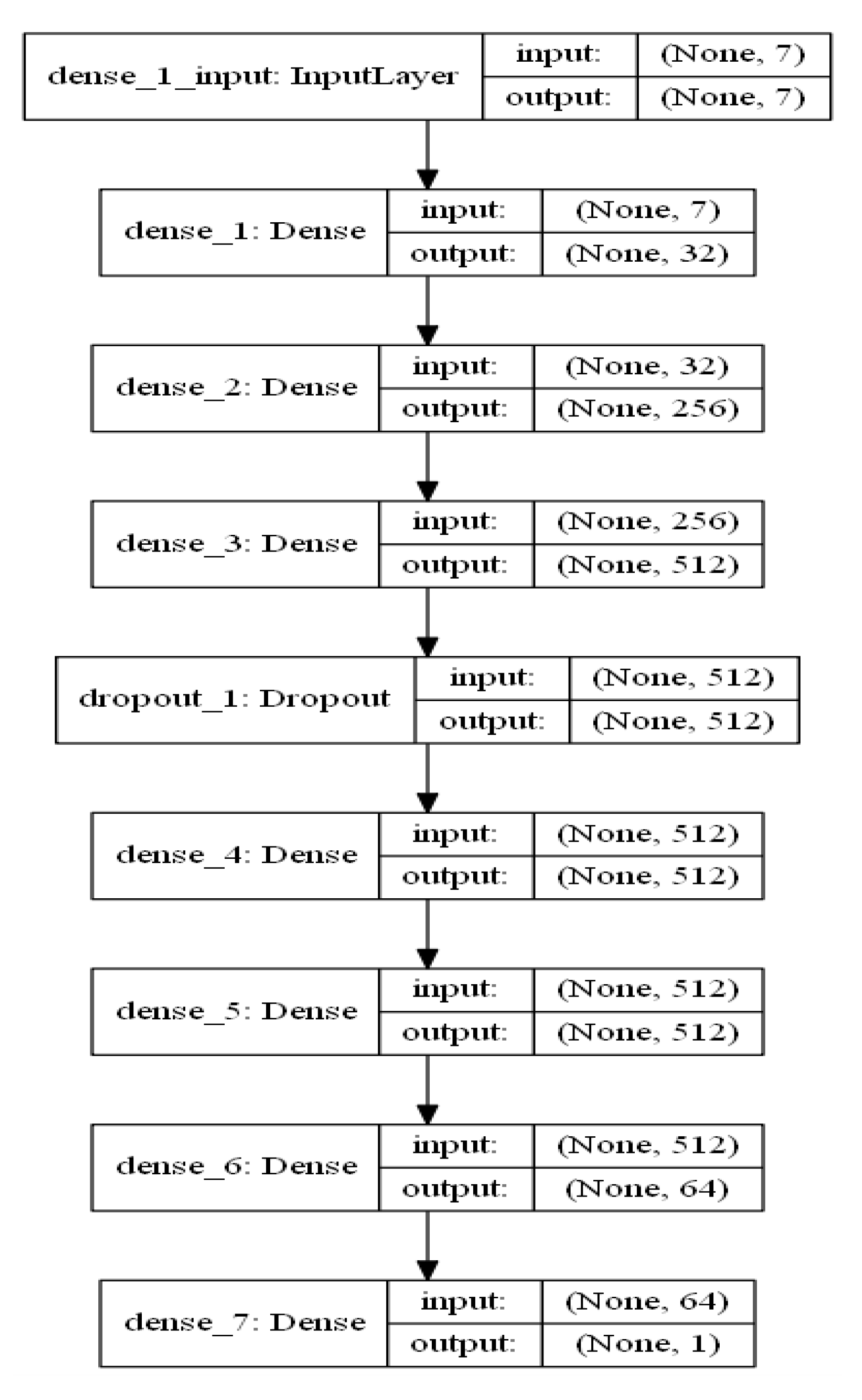
2.3.6. Deep Neural Network
2.4. Input Data and Validation Method
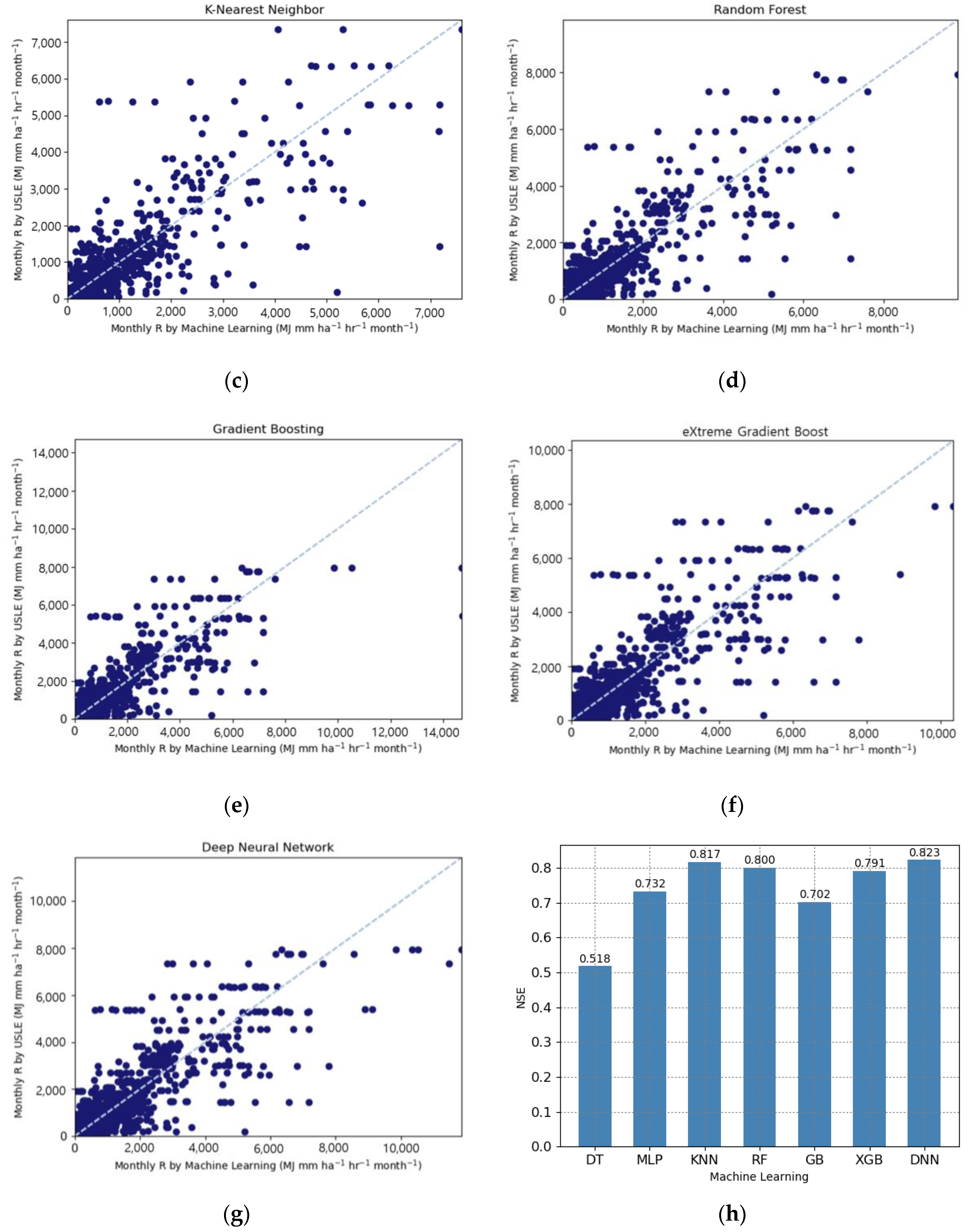
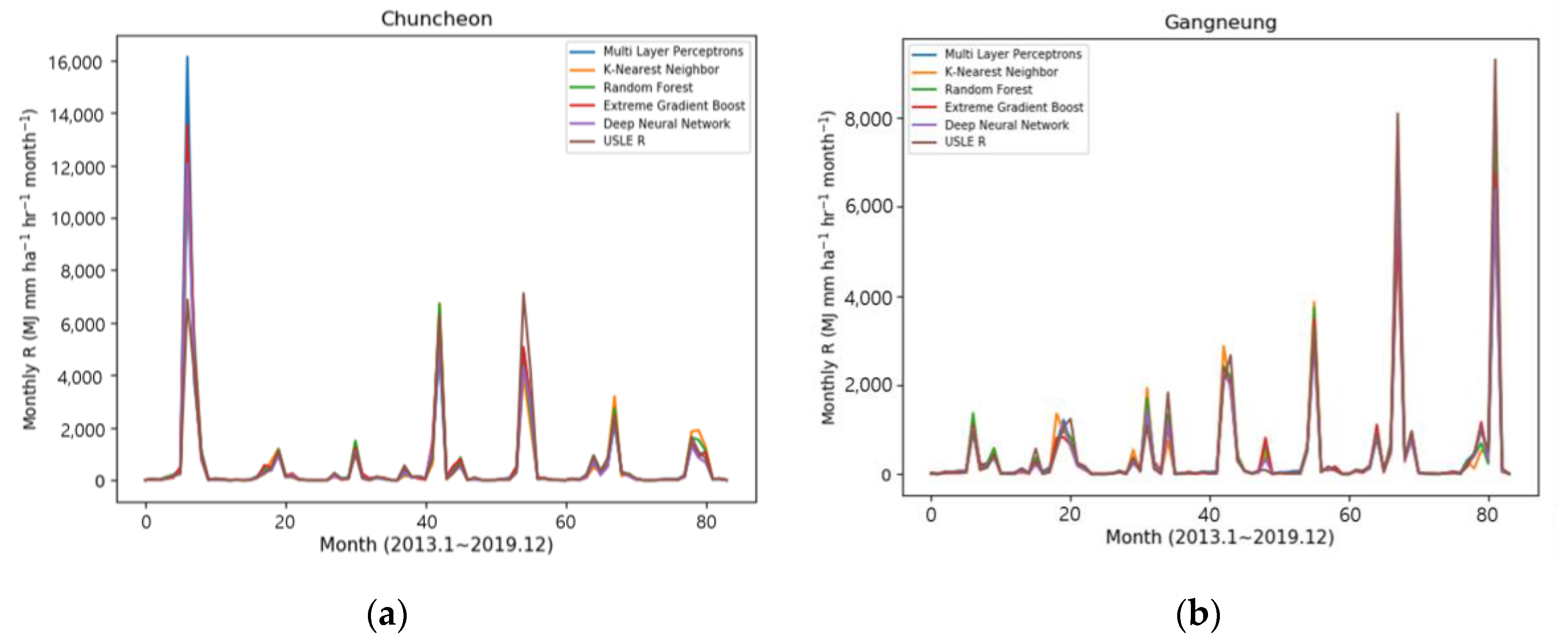
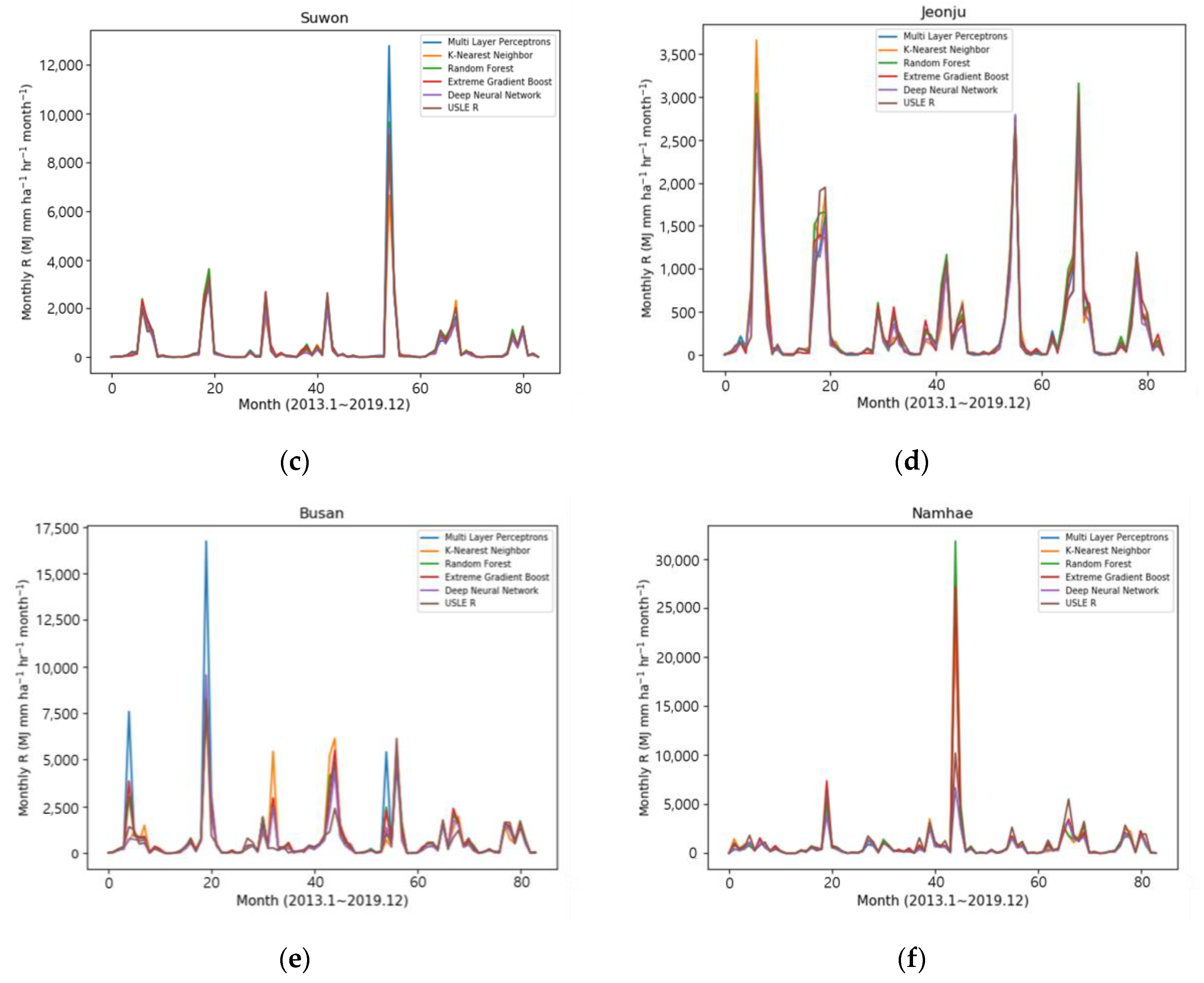
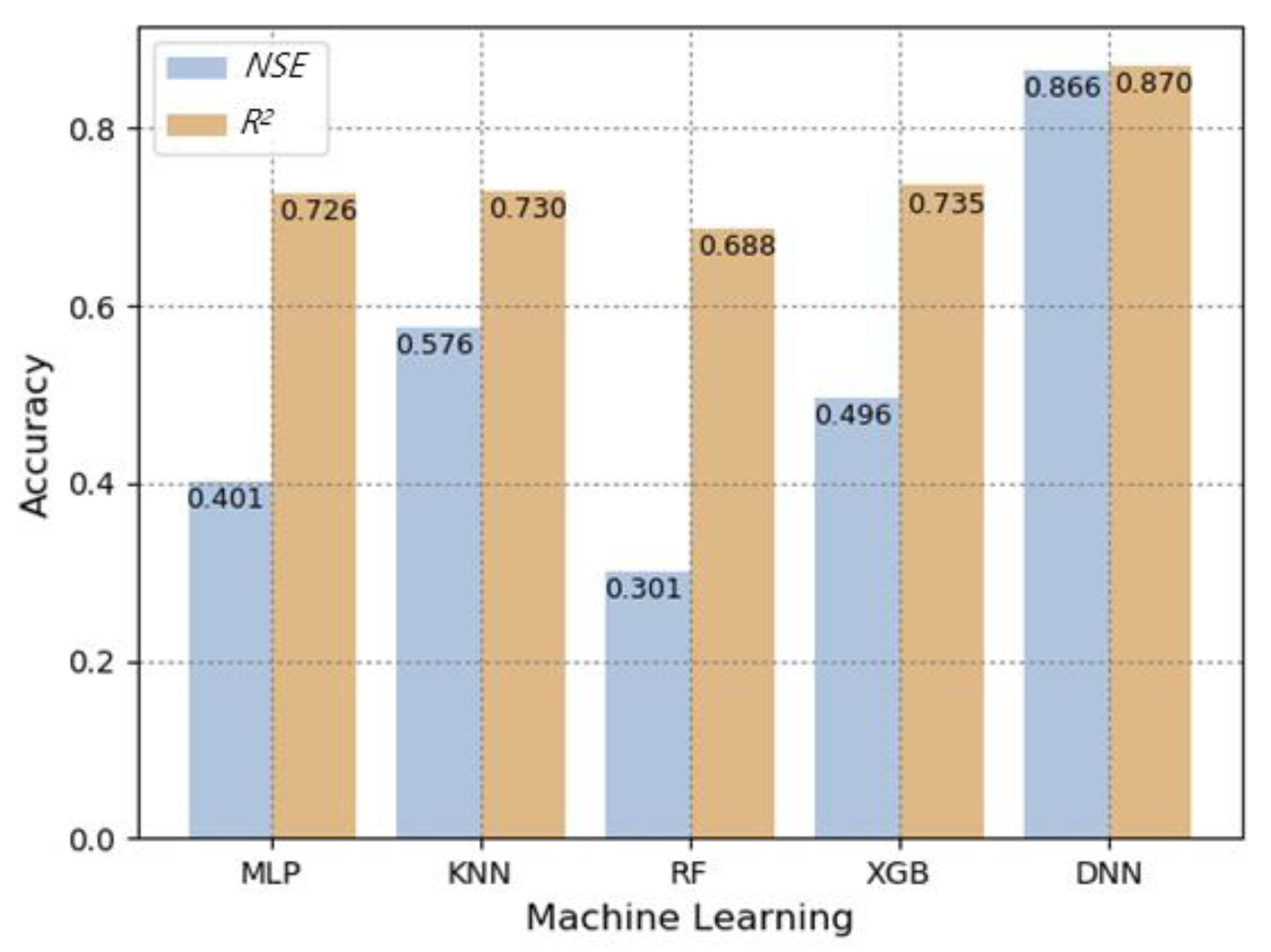
3. Results and Discussion
3.1. USLE R-Factor
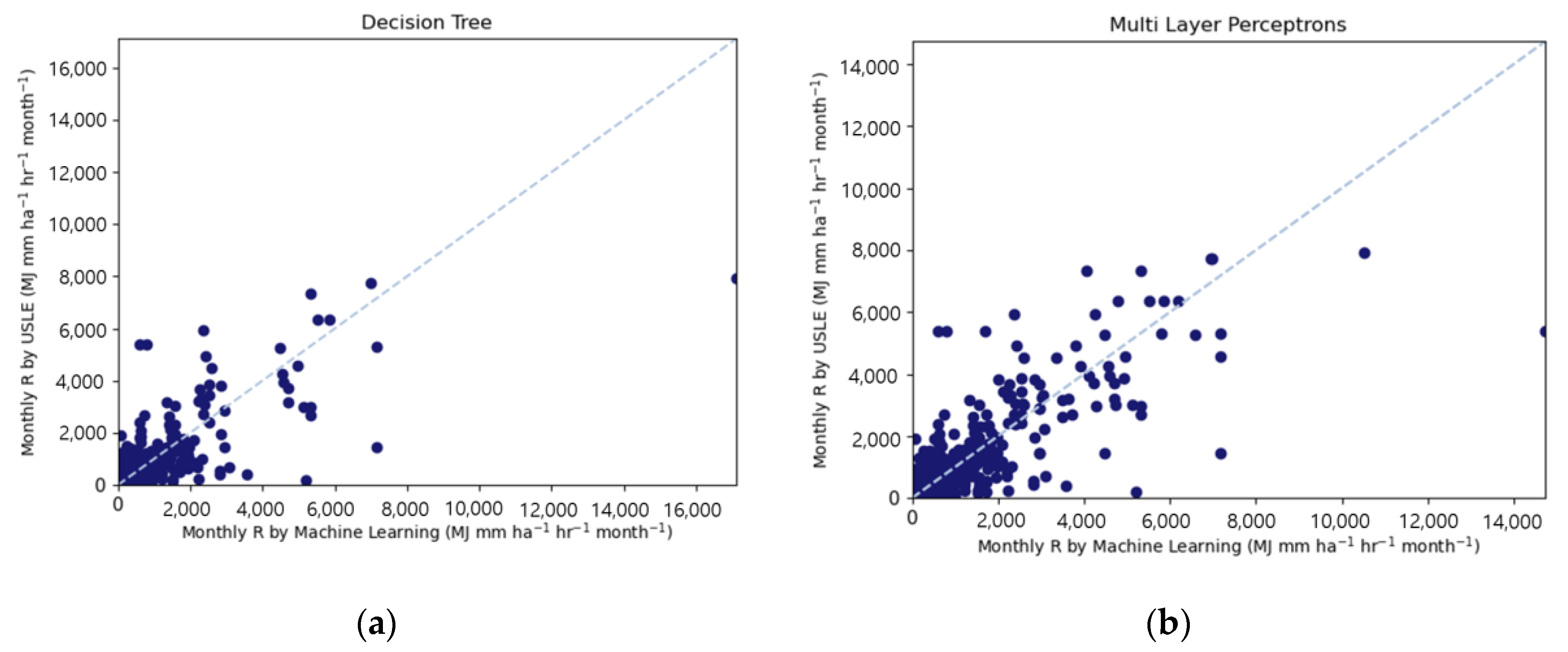
3.2. Validation of Machine Learning Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Diodato, N.; Bellocchi, G. Estimating monthly (R) USLE climate input in a Mediterranean region using limited data. J. Hydrol. 2007, 345, 224–236. [Google Scholar] [CrossRef]
- Fu, B.J.; Zhao, W.W.; Chen, L.D.; Liu, Z.F.; Lü, Y.H. Eco-hydrological effects of landscape pattern change. Landsc. Ecol. Eng. 2005, 1, 25–32. [Google Scholar] [CrossRef]
- Renschler, C.S.; Harbor, J. Soil erosion assessment tools from point to regional scales the role of geomorphologists in land management research and implementation. Geomorphology 2002, 47, 189–209. [Google Scholar] [CrossRef]
- Christensen, O.; Yang, S.; Boberg, F.; Maule, C.F.; Thejll, P.; Olesen, M.; Drews, M.; Sorup, H.J.D.; Christensen, J. Scalability of regional climate change in Europe for high-end scenarios. Clim. Res. 2015, 64, 25. [Google Scholar] [CrossRef] [Green Version]
- Stocker, T.; Gin, D.; Plattner, G.; Tignor, M.; Allen, S.; Boschung, J.; Nauels, A.; Xia, Y.; Bex, V.; Midgley, P.E. Climate Change 2013: The Physical Science Basis: Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2013; p. 1535. [Google Scholar]
- Achite, M.; Buttafuoco, G.; Toubal, K.A.; Lucà, F. Precipitation spatial variability and dry areas temporal stability for different elevation classes in the Macta basin (Algeria). Environ. Earth Sci. 2017, 76, 458. [Google Scholar] [CrossRef]
- Shi, Z.; Yan, F.; Li, L.; Li, Z.; Cai, C. Interrill erosion from disturbed and undisturbed samples in relation to topsoil aggregate stability in red soils from subtropical China. Catena 2010, 81, 240–248. [Google Scholar] [CrossRef]
- Kinnell, P.I.A.; Wang, J.; Zheng, F. Comparison of the abilities of WEPP and the USLE-M to predict event soil loss on steep loessal slopes in China. Catena 2018, 171, 99–106. [Google Scholar] [CrossRef]
- Lee, J.; Park, Y.S.; Kum, D.; Jung, Y.; Kim, B.; Hwang, S.J.; Kim, H.B.; Kim, C.; Lim, K.J. Assessing the effect of watershed slopes on recharge/baseflow and soil erosion. Paddy Water Environ. 2014, 12, 169–183. [Google Scholar] [CrossRef]
- Pandey, A.; Himanshu, S.; Mishra, S.K.; Singh, V. hysically based soil erosion and sediment yield models revisited. Catena 2016, 147, 595–620. [Google Scholar] [CrossRef]
- Sigler, W.A.; Ewing, S.A.; Jones, C.A.; Payn, R.A.; Miller, P.; Maneta, M. Water and nitrate loss from dryland agricultural soils is controlled by management, soils, and weather. Agric. Ecosyst. Environ. 2020, 304, 107158. [Google Scholar] [CrossRef]
- Lucà, F.; Buttafuoco, G.; Terranova, O. GIS and Soil. In Comprehensive Geographic Information Systems; Huang, B., Ed.; Elsevier: Oxford, UK, 2018; Volume 2, pp. 37–50. [Google Scholar]
- Arnold, J.G.; Srinivasan, R.; Muttiah, R.S.; Williams, J.R. Large area hydrologic modeling and assessment part I: Model development1. J. Am. Water Resour. Assoc. 1998, 34, 73–89. [Google Scholar] [CrossRef]
- Morgan, R.P.C.; Quinton, J.N.; Smith, R.E.; Govers, G.; Poesen, J.W.A.; Auerswald, K.; Chisci, G.; Torri, D.; Styczen, M.E. The European soil erosion model (EUROSEM): A dynamic approach for predicting sediment transport from fields and small catchments. Earth Surf. Process. Landf. 1998, 23, 527–544. [Google Scholar] [CrossRef]
- Flanagan, D.; Nearing, M. USDA-water erosion prediction project: Hillslope profile and watershed model documentation. NSERL Rep. 1995, 10, 1–12. [Google Scholar]
- Lim, K.J.; Sagong, M.; Engel, B.A.; Tang, Z.; Choi, J.; Kim, K.S. GIS-based sediment assessment tool. Catena 2005, 64, 61–80. [Google Scholar] [CrossRef]
- Young, R.A.; Onstad, C.; Bosch, D.; Anderson, W. AGNPS: A nonpoint-source pollution model for evaluating agricultural watersheds. J. Soil Water Conserv. 1989, 44, 168–173. [Google Scholar]
- Wischmeier, W.H.; Smith, D.D. Predicting Rainfall Erosion Losses: A Guide to Conservation Planning; Department of Agriculture, Science, and Education Administration: Wahsington, DC, USA, 1978; pp. 1–67.
- Renard, K.G.; Foster, G.R.; Weesies, G.A.; McCool, D.K.; Yorder, D.C. Predicting Soil Erosion by Water: A Guide to Conservation Planning with the Revised Universal Soil Loss Equation (RUSLE). In Agriculture Handbook; U.S. Department of Agriculture: Washington, DC, USA, 1997; Volume 703. [Google Scholar]
- Kinnell, P.I.A. Comparison between the USLE, the USLE-M and replicate plots to model rainfall erosion on bare fallow areas. Catena 2016, 145, 39–46. [Google Scholar] [CrossRef]
- Bagarello, V.; Stefano, C.D.; Ferro, V.; Pampalone, V. Predicting maximum annual values of event soil loss by USLE-type models. Catena 2017, 155, 10–19. [Google Scholar] [CrossRef]
- Park, Y.S.; Kim, J.; Kim, N.W.; Kim, S.J.; Jeong, J.; Engel, B.A.; Jang, W.; Lim, K.J. Development of new R C and SDR modules for the SATEEC GIS system. Comput. Geosci. 2010, 36, 726–734. [Google Scholar] [CrossRef]
- Yu, N.Y.; Lee, D.J.; Han, J.H.; Lim, K.J.; Kim, J.; Kim, H.; Kim, S.; Kim, E.S.; Pakr, Y.S. Development of ArcGIS-based model to estimate monthly potential soil loss. J. Korean Soc. Agric. Eng. 2017, 59, 21–30. [Google Scholar]
- Park, C.W.; Sonn, Y.K.; Hyun, B.K.; Song, K.C.; Chun, H.C.; Moon, Y.H.; Yun, S.G. The redetermination of USLE rainfall erosion factor for estimation of soil loss at Korea. korean J. Soil Sci. Fert. 2011, 44, 977–982. [Google Scholar] [CrossRef] [Green Version]
- Panagos, P.; Ballabio, C.; Borrelli, P.; Meusburger, K. Spatio-temporal analysis of rainfall erosivity and erosivity density in Greece. Catena 2016, 137, 161–172. [Google Scholar] [CrossRef]
- Sholagberu, A.T.; Mustafa, M.R.U.; Yusof, K.W.; Ahmad, M.H. Evaluation of rainfall-runoff erosivity factor for Cameron highlands, Pahang, Malaysia. J. Ecol. Eng. 2016, 17. [Google Scholar] [CrossRef] [Green Version]
- Risal, A.; Bhattarai, R.; Kum, D.; Park, Y.S.; Yang, J.E.; Lim, K.J. Application of Web Erosivity Module (WERM) for estimation of annual and monthly R factor in Korea. Catena 2016, 147, 225–237. [Google Scholar] [CrossRef]
- Risal, A.; Lim, K.J.; Bhattarai, R.; Yang, J.E.; Noh, H.; Pathak, R.; Kim, J. Development of web-based WERM-S module for estimating spatially distributed rainfall erosivity index (EI30) using RADAR rainfall data. Catena 2018, 161, 37–49. [Google Scholar] [CrossRef]
- Lucà, F.; Robustelli, G. Comparison of logistic regression and neural network models in assessing geomorphic control on alluvial fan depositional processes (Calabria, southern Italy). Environ. Earth Sci. 2020, 79, 39. [Google Scholar] [CrossRef]
- Noymanee, J.; Theeramunkong, T. Flood forecasting with machine learning technique on hydrological modeling. Preced. Comput. Sci. 2019, 156, 377–386. [Google Scholar] [CrossRef]
- Vantas, K.; Sidiropoulos, E.; Evangelides, C. Rainfall erosivity and Its Estimation: Conventional and Machine Learning Methods. In Soil Erosion—Rainfall Erosivity and Risk Assessment; Intechopen: London, UK, 2019. [Google Scholar]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Liang, X. Assessment of urban flood susceptibility using semi supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef] [PubMed]
- Vu, D.T.; Tran, X.L.; Cao, M.T.; Tran, T.C.; Hoang, N.D. Machine learning based soil erosion susceptibility prediction using social spider algorithm optimized multivariate adaptive regression spline. Measurement 2020, 164, 108066. [Google Scholar] [CrossRef]
- Xiang, Z.; Demir, I. Distributed long-term hourly streamflow predictions using deep learning—A case study for state of Iowa. Environ. Modeling Softw. 2020, 131, 104761. [Google Scholar] [CrossRef]
- Renard, K.G.; Foster, G.R.; Weesies, G.A.; Porter, J.P. RUSLE: Revised universal soil loss equation. J. Soil Water Conserv. 1991, 46, 30–33. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 4th ed.; MIT Press: Cambridge, MA, USA, 2014; pp. 1–683. [Google Scholar]
- Hong, J.; Lee, S.; Bae, J.H.; Lee, J.; Park, W.J.; Lee, D.; Kim, J.; Lim, K.J. Development and evaluation of the combined machine learning models for the prediction of dam inflow. Water 2020, 12, 2927. [Google Scholar] [CrossRef]
- Wang, L.; Guo, M.; Sawada, K.; Lin, J.; Zhang, J.A. Comparative Study of Landslide Susceptibility Maps using Logistic Regression, Frequency Ratio, Decision Tree, Weights of Evidence and Artificial Neural Network. Geosci. J. 2016, 20, 117–136. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Park, S.; Hwang, E. A multilayer perceptron-based electric load forecasting scheme via effective recovering missing data. Kips Trans. Softw. Data Eng. 2019, 8, 67–78. [Google Scholar]
- Bae, J.H.; Han, J.; Lee, D.; Yang, J.E.; Kim, J.; Lim, K.J.; Neff, J.C.; Jang, W.S. Evaluation of Sediment Trapping Efficiency of Vegetative Filter Strips Using Machine Learning Models. Sustainability 2019, 11, 7212. [Google Scholar] [CrossRef] [Green Version]
- Qu, W.; Li, J.; Yang, L.; Li, D.; Liu, S.; Zhao, Q.; Qi, Y. Short-term intersection Traffic flow forecasting. Sustainability 2020, 12, 8158. [Google Scholar] [CrossRef]
- Yao, Z.; Ruzzo, W.L. A regression-based K nearest neighbor algorithm for gene function prediction from heterogeneous data. BMC Bioinform. 2006, 7, S11. [Google Scholar] [CrossRef] [Green Version]
- Ooi, H.L.; Ng, S.C.; Lim, E. ANO detection with K-Nearest Neighbor using minkowski distance. Int. J. Process. Syst. 2013, 2, 208–211. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ngarambe, J.; Irakoze, A.; Yun, G.Y.; Kim, G. Comparative Performance of Machine Learning Algorithms in the Prediction of Indoor Daylight Illuminances. Sustainability 2020, 12, 4471. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M. Very high resolution object-based land use–land cover urban classification using extreme gradient boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef] [Green Version]
- Babajide Mustapha, I.; Saeed, F. Bioactive molecule prediction using extreme gradient boosting. Molecules 2016, 21, 983. [Google Scholar] [CrossRef] [Green Version]
- Lavecchia, A. Machine-learning approaches in drug discovery: Methods and applications. Drug Discov. Today. 2015, 20, 318–331. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, S. Machine learning-based water level prediction in Lake Erie. Water 2020, 12, 2654. [Google Scholar] [CrossRef]
- Siniscalchi, S.M.; Yu, D.; Deng, L.; Lee, C.H. Exploiting deep neural networks for detection-based speech recognition. Neurocomputing 2013, 106, 148–157. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Cancelliere, A.; Di Mauro, G.; Bonaccorso, B.; Rossi, G. Drought forecasting using the standardized precipitation index. Water Resour. Manag. 2007, 21, 801–819. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Moghimi, M.M.; Zarei, A.R. Evaluating the performance and applicability of several drought indices in arid regions. Asia-Pac. J. Atmos. Sci. 2019, 1–17. [Google Scholar] [CrossRef]
- Liu, D.; Jiang, W.; Wang, S. Streamflow prediction using deep learning neural network: A case study of Yangtze River. Inst. Electr. Electron. Eng. 2020, 8, 90069–90086. [Google Scholar] [CrossRef]
- Nhu, V.; Hoang, N.; Nguyen, H.; Ngo, P.T.T.; Bui, T.T.; Hoa, P.V.; Samui, P.; Bui, D.T. Effectiveness assessment of Keras based deep learning with different robust optimization algorithms for shallow landslide susceptibility mapping at tropical area. Catena 2020, 188, 104458. [Google Scholar] [CrossRef]
- Lee, K.; Choi, C.; Shin, D.H.; Kim, H.S. Prediction of heavy rain damage using deep learning. Water 2020, 12, 1942. [Google Scholar] [CrossRef]
- Sit, M.A.; Demir, I. Decentralized flood forecasting using deep neural networks. arXiv 2019, arXiv:1902.02308. [Google Scholar]
- Kim, M.; Kim, Y.; Kim, H.; Piao, W. Evaluation of the k-nearest neighbor method for forecasting the influent characteristics of wastewater treatment plant. Front. Environ. Sci. Eng. 2015, 10, 299–310. [Google Scholar] [CrossRef]
- Korea Ministry of Environment. Notice Regarding Survey of Topsoil Erosion; Ministry of Environment: Seoul, Korea, 2012; pp. 1–41.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Models | Module | Function | Notation |
|---|---|---|---|
| Decision Tree | Sklearn.tree | DecisionTreeRegressor | DT |
| Random Forest | Sklearn.ensemble | RandomForestRegressor | RF |
| K-Nearest Neighbors | Sklearn.neighbors | KNeighborsRegressor | KN |
| Gradient Boosting | Sklearn.ensemble | GradientBoostingRegressor | GB |
| eXtreme Gradient Boost | xgboost.xgb | XGBRegressor | XGB |
| Multilayer Perceptron | Sklearn, neural_network | MLPRegressor | MLP |
| Deep Neural Network | Keras.models.Sequential | Dense, Dropout | DNN |
| Machine Learning Models | Hyperparameter |
|---|---|
| Decision Tree | criterion = “entropy”, min_samples_split = 2 |
| Random Forest | n_estimators = 52, min_samples_leaf = 1 |
| K-Nearest Neighbors | n_neighbors = 3, weights = ‘uniform’, metric = ‘minkowski’ |
| Gradient Boosting | learning_rate = 0.01, min_samples_split = 4 |
| eXtreme Gradient Boost | Booster = ‘gbtree’, max_depth = 10 |
| Multilayer Perceptron | hidden_layer_sizes = (50,50,50), activation = “relu”, solver = ‘adam’ |
| Deep Neural Network | kernel_initializer = ‘normal’, activation = “relu” |
| Description | Count | Mean | std | Min | 25% | 50% | 75% | Max | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Input variable | month | month (1~12) | 4087 | 6.49 | 3.45 | 1 | 3 | 6 | 9 | 12 |
| m_sum_r | the total amount of monthly precipitation | 4087 | 96.45 | 97.01 | 0 | 30.90 | 66.20 | 126.15 | 1009.20 | |
| d_max_r | maximum daily precipitation | 4087 | 39.39 | 38.10 | 0 | 14.50 | 27.10 | 51.35 | 384.30 | |
| h_max_r | maximum hourly precipitation | 4087 | 11.84 | 12.69 | 0 | 4.00 | 7.50 | 15.50 | 197.50 | |
| Output variable | R-factor | R-factor | 4087 | 419.10 | 1216.79 | 0 | 15.99 | 77.84 | 326.24 | 43,586.61 |
| Station Number | Station Name | R-Factor (MJ mm ha−1 h−1 month−1) | R-Factor (MJ mm ha−1 h−1 year−1) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| January | February | March | April | May | June | July | August | September | October | November | December | Annual | ||
| 90 | Sokcho | 21 | 29 | 32 | 95 | 47 | 159 | 1039 | 2860 | 368 | 494 | 507 | 44 | 5694 |
| 95 | Cheolwon | 2 | 37 | 30 | 119 | 257 | 235 | 5867 | 2769 | 403 | 239 | 65 | 24 | 10,046 |
| 98 | Dongducheon | 2 | 69 | 31 | 91 | 287 | 455 | 3031 | 1364 | 424 | 228 | 47 | 24 | 6053 |
| 100 | Daegwallyeong | 4 | 19 | 20 | 79 | 577 | 194 | 1472 | 1669 | 453 | 237 | 40 | 8 | 4772 |
| 106 | Donghae | 17 | 29 | 34 | 207 | 27 | 157 | 592 | 1317 | 469 | 1461 | 128 | 8 | 4447 |
| 108 | Seoul | 0 | 31 | 37 | 95 | 284 | 266 | 2813 | 988 | 191 | 90 | 50 | 16 | 4861 |
| 112 | Incheon | 3 | 50 | 69 | 83 | 224 | 192 | 2193 | 897 | 406 | 480 | 88 | 27 | 4712 |
| 114 | Wonju | 2 | 22 | 31 | 83 | 284 | 699 | 2654 | 999 | 303 | 65 | 40 | 8 | 5189 |
| 127 | Chungju | 4 | 36 | 22 | 79 | 171 | 270 | 2075 | 1240 | 909 | 117 | 38 | 17 | 4978 |
| 129 | Seosan | 7 | 72 | 50 | 135 | 147 | 562 | 747 | 635 | 330 | 146 | 127 | 42 | 3000 |
| 130 | Uljin | 86 | 16 | 47 | 292 | 24 | 227 | 590 | 470 | 360 | 2816 | 143 | 30 | 5100 |
| 133 | Daejeon | 8 | 47 | 50 | 182 | 72 | 602 | 1658 | 1293 | 494 | 181 | 96 | 24 | 4707 |
| 136 | Andong | 1 | 32 | 53 | 101 | 48 | 325 | 1142 | 808 | 368 | 176 | 33 | 14 | 3100 |
| 137 | Sangju | 6 | 18 | 67 | 105 | 45 | 361 | 1098 | 1143 | 420 | 273 | 51 | 19 | 3605 |
| 138 | Pohang | 7 | 46 | 106 | 139 | 40 | 233 | 417 | 1051 | 910 | 1478 | 51 | 23 | 4500 |
| 143 | Daegu | 1 | 8 | 57 | 80 | 67 | 313 | 548 | 1322 | 238 | 340 | 26 | 12 | 3013 |
| 152 | Ulsan | 15 | 36 | 122 | 141 | 154 | 287 | 751 | 1499 | 727 | 1709 | 77 | 74 | 5591 |
| 156 | Gwangju | 8 | 59 | 92 | 156 | 74 | 927 | 1249 | 2458 | 703 | 361 | 99 | 49 | 6236 |
| 165 | Mokpo | 15 | 112 | 117 | 227 | 177 | 630 | 1023 | 944 | 2094 | 493 | 85 | 127 | 6044 |
| 172 | Gochang | 12 | 24 | 137 | 151 | 77 | 399 | 1768 | 2235 | 614 | 273 | 77 | 21 | 5788 |
| 175 | Jindo | 18 | 43 | 231 | 559 | 511 | 598 | 738 | 1323 | 799 | 636 | 113 | 36 | 5606 |
| 201 | Ganghwa | 1 | 26 | 35 | 60 | 193 | 59 | 1922 | 1255 | 648 | 654 | 48 | 20 | 4921 |
| 203 | Icheon | 2 | 34 | 103 | 83 | 211 | 207 | 2284 | 1068 | 450 | 162 | 45 | 24 | 4673 |
| 212 | Hongcheon | 1 | 11 | 23 | 81 | 461 | 162 | 2220 | 934 | 223 | 51 | 29 | 8 | 4204 |
| 217 | Jeongseon | 1 | 20 | 18 | 75 | 117 | 126 | 2165 | 654 | 355 | 101 | 36 | 16 | 3686 |
| 221 | Jecheon | 3 | 26 | 21 | 90 | 158 | 265 | 1616 | 1162 | 405 | 80 | 43 | 12 | 3881 |
| 226 | Boeun | 8 | 19 | 42 | 106 | 62 | 482 | 2016 | 1102 | 583 | 163 | 77 | 15 | 4675 |
| 232 | Cheonan | 2 | 17 | 21 | 86 | 106 | 248 | 3408 | 1002 | 249 | 110 | 68 | 15 | 5333 |
| 235 | Boryeong | 5 | 73 | 47 | 142 | 127 | 322 | 878 | 849 | 1014 | 184 | 149 | 29 | 3820 |
| 238 | Guemsan | 5 | 17 | 52 | 154 | 48 | 483 | 1126 | 1059 | 447 | 148 | 37 | 17 | 3591 |
| 244 | Imsil | 3 | 9 | 83 | 106 | 67 | 369 | 2329 | 1416 | 632 | 224 | 44 | 16 | 5297 |
| 245 | Jeongeup | 11 | 18 | 106 | 160 | 265 | 318 | 1679 | 1930 | 521 | 207 | 46 | 27 | 5287 |
| 247 | Namwon | 8 | 19 | 78 | 159 | 52 | 704 | 2988 | 2304 | 479 | 586 | 88 | 49 | 7512 |
| 248 | Jangsu | 5 | 34 | 85 | 151 | 80 | 246 | 1997 | 1812 | 715 | 308 | 53 | 30 | 5516 |
| 251 | Gochanggoon | 7 | 14 | 127 | 191 | 69 | 352 | 1448 | 2066 | 521 | 175 | 37 | 23 | 5029 |
| 252 | Younggwang | 7 | 15 | 130 | 178 | 114 | 292 | 994 | 2008 | 596 | 491 | 63 | 39 | 4928 |
| 253 | Ginhae | 7 | 43 | 220 | 200 | 339 | 385 | 1036 | 1600 | 1216 | 734 | 44 | 48 | 5872 |
| 254 | Soonchang | 4 | 14 | 93 | 194 | 89 | 456 | 1724 | 1304 | 629 | 363 | 58 | 16 | 4945 |
| 259 | Gangjin | 10 | 34 | 204 | 344 | 425 | 666 | 1156 | 9781 | 903 | 444 | 187 | 18 | 14,170 |
| 261 | Haenam | 10 | 15 | 223 | 206 | 177 | 595 | 965 | 1142 | 650 | 1250 | 83 | 91 | 5406 |
| 263 | Uiryoong | 4 | 24 | 121 | 184 | 156 | 334 | 629 | 1961 | 805 | 643 | 39 | 36 | 4936 |
| 266 | Gwangyang | 8 | 76 | 120 | 218 | 591 | 686 | 827 | 2488 | 2195 | 555 | 86 | 73 | 7924 |
| 271 | Bonghwa | 0 | 9 | 36 | 86 | 95 | 415 | 1154 | 706 | 327 | 98 | 28 | 13 | 2968 |
| 273 | Mungyeong | 7 | 18 | 54 | 139 | 102 | 331 | 1724 | 742 | 529 | 180 | 61 | 21 | 3908 |
| 278 | Uiseong | 1 | 6 | 69 | 101 | 74 | 220 | 632 | 647 | 326 | 106 | 31 | 7 | 2220 |
| 279 | Gumi | 3 | 12 | 68 | 103 | 95 | 380 | 1296 | 1442 | 554 | 364 | 32 | 14 | 4363 |
| 281 | Yeongcheon | 2 | 11 | 81 | 162 | 52 | 316 | 1259 | 1082 | 409 | 230 | 28 | 12 | 3643 |
| 283 | Gyeongju | 3 | 11 | 53 | 101 | 55 | 125 | 573 | 759 | 681 | 686 | 21 | 13 | 3081 |
| 284 | Geochang | 3 | 17 | 54 | 105 | 60 | 434 | 1184 | 1491 | 619 | 2246 | 33 | 55 | 6299 |
| 285 | Hapcheon | 2 | 22 | 57 | 173 | 105 | 700 | 1114 | 1646 | 810 | 676 | 47 | 24 | 5378 |
| Machine Learning Models | NSE | RMSE (MJ mm ha-−1 h−1 month−1) | MAE (MJ mm ha-−1 h−1 month−1) | R2 |
|---|---|---|---|---|
| Decision Tree | 0.518 | 657.672 | 217.408 | 0.626 |
| Multilayer Perceptron | 0.732 | 490.055 | 158.847 | 0.783 |
| K-Nearest Neighbors | 0.817 | 405.327 | 149.923 | 0.794 |
| Random Forest | 0.800 | 423.345 | 148.147 | 0.799 |
| Gradient Boosting | 0.702 | 516.956 | 161.259 | 0.722 |
| eXtreme Gradient Boost | 0.791 | 433.230 | 159.275 | 0.788 |
| Deep Neural Network | 0.823 | 398.623 | 144.442 | 0.840 |
| Fold | Coefficient of Determination (R2) | ||||||
|---|---|---|---|---|---|---|---|
| Decision Tree | Multi-Layer Perceptron | K-Nearest Neighbors | Random Forest | Gradient Boosting | eXtreme Gradient Boost | Deep Neural Network | |
| 1 | 0.631 | 0.781 | 0.818 | 0.817 | 0.730 | 0.801 | 0.821 |
| 2 | 0.598 | 0.806 | 0.705 | 0.686 | 0.648 | 0.737 | 0.733 |
| 3 | 0.544 | 0.759 | 0.705 | 0.682 | 0.635 | 0.717 | 0.759 |
| 4 | 0.592 | 0.714 | 0.780 | 0.774 | 0.653 | 0.644 | 0.762 |
| 5 | 0.626 | 0.783 | 0.794 | 0.799 | 0.722 | 0.788 | 0.840 |
| Average | 0.598 | 0.769 | 0.760 | 0.752 | 0.678 | 0.737 | 0.783 |
| Station Number | Station Name | Method | R-Factor (MJ mm ha−1 h−1 month−1) | R-Factor (MJ mm ha−1 h−1 year−1) | NSE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| January | February | March | April | May | June | July | August | September | October | November | December | Annual | ||||
| 101 | Chuncheon | C | 2 | 99 | 27 | 110 | 195 | 320 | 3466 | 1844 | 355 | 182 | 45 | 24 | 6670 | 0.814 |
| M | 5 | 59 | 26 | 84 | 166 | 356 | 3543 | 1608 | 323 | 154 | 31 | 16 | 6372 | |||
| 105 | Gangneung | C | 25 | 36 | 31 | 138 | 150 | 113 | 742 | 2476 | 390 | 1598 | 325 | 16 | 6040 | 0.874 |
| M | 57 | 24 | 38 | 84 | 154 | 100 | 774 | 2189 | 287 | 1129 | 207 | 14 | 5055 | |||
| 119 | Suwon | C | 3 | 29 | 80 | 115 | 278 | 165 | 2944 | 1463 | 388 | 107 | 84 | 27 | 5683 | 0.981 |
| M | 5 | 36 | 56 | 88 | 210 | 156 | 2708 | 1352 | 312 | 85 | 52 | 19 | 5076 | |||
| 146 | Jeonju | C | 7 | 17 | 104 | 105 | 108 | 526 | 1315 | 1511 | 311 | 240 | 67 | 21 | 4330 | 0.911 |
| M | 7 | 16 | 80 | 103 | 95 | 581 | 1086 | 1261 | 310 | 153 | 50 | 19 | 3760 | |||
| 159 | Busan | C | 32 | 79 | 199 | 408 | 472 | 781 | 1021 | 1729 | 1764 | 616 | 266 | 113 | 7479 | 0.883 |
| M | 22 | 56 | 148 | 243 | 317 | 639 | 860 | 2205 | 2514 | 458 | 184 | 91 | 7736 | |||
| 295 | Namhae | C | 19 | 407 | 366 | 946 | 892 | 1016 | 1608 | 1822 | 2169 | 1634 | 151 | 131 | 11,159 | 0.584 |
| M | 14 | 161 | 198 | 748 | 607 | 867 | 1201 | 1164 | 1633 | 1010 | 85 | 110 | 7798 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Lee, S.; Hong, J.; Lee, D.; Bae, J.H.; Yang, J.E.; Kim, J.; Lim, K.J. Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models. Water 2021, 13, 382. https://doi.org/10.3390/w13030382
Lee J, Lee S, Hong J, Lee D, Bae JH, Yang JE, Kim J, Lim KJ. Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models. Water. 2021; 13(3):382. https://doi.org/10.3390/w13030382
Chicago/Turabian StyleLee, Jimin, Seoro Lee, Jiyeong Hong, Dongjun Lee, Joo Hyun Bae, Jae E. Yang, Jonggun Kim, and Kyoung Jae Lim. 2021. "Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models" Water 13, no. 3: 382. https://doi.org/10.3390/w13030382
APA StyleLee, J., Lee, S., Hong, J., Lee, D., Bae, J. H., Yang, J. E., Kim, J., & Lim, K. J. (2021). Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models. Water, 13(3), 382. https://doi.org/10.3390/w13030382