
Land Cover Classification from Hyperspectral Images via Local Nearest Neighbor Collaborative Representation with Tikhonov Regularization


Abstract
:1. Introduction
- (1)
- A local nearest neighbor (LNN) method is proposed and introduced into the original CRC and CRT methods for land cover classification, denoted as LNNCRC and LNNCRT, respectively, which can effectively select the nearest neighbors and nearest classes of each test sample from all the training samples, so as to further exclude the interference of irrelevant samples and classes.
- (2)
- The proposed LNNCRC and LNNCRT methods utilize the same number of nearest neighbors from each nearest class of the test sample to construct dictionary, which can effectively eliminate the influence of imbalanced training samples on classification performance.
- (3)
- Due to the exclusion of the interference of irrelevant samples and classes in a further step, the proposed LNNCRC and LNNCRT methods can not only effectively improve the classification performance of CR models for land cover types, but also reduce the computational complexity of CR models.
2. Materials and Methods
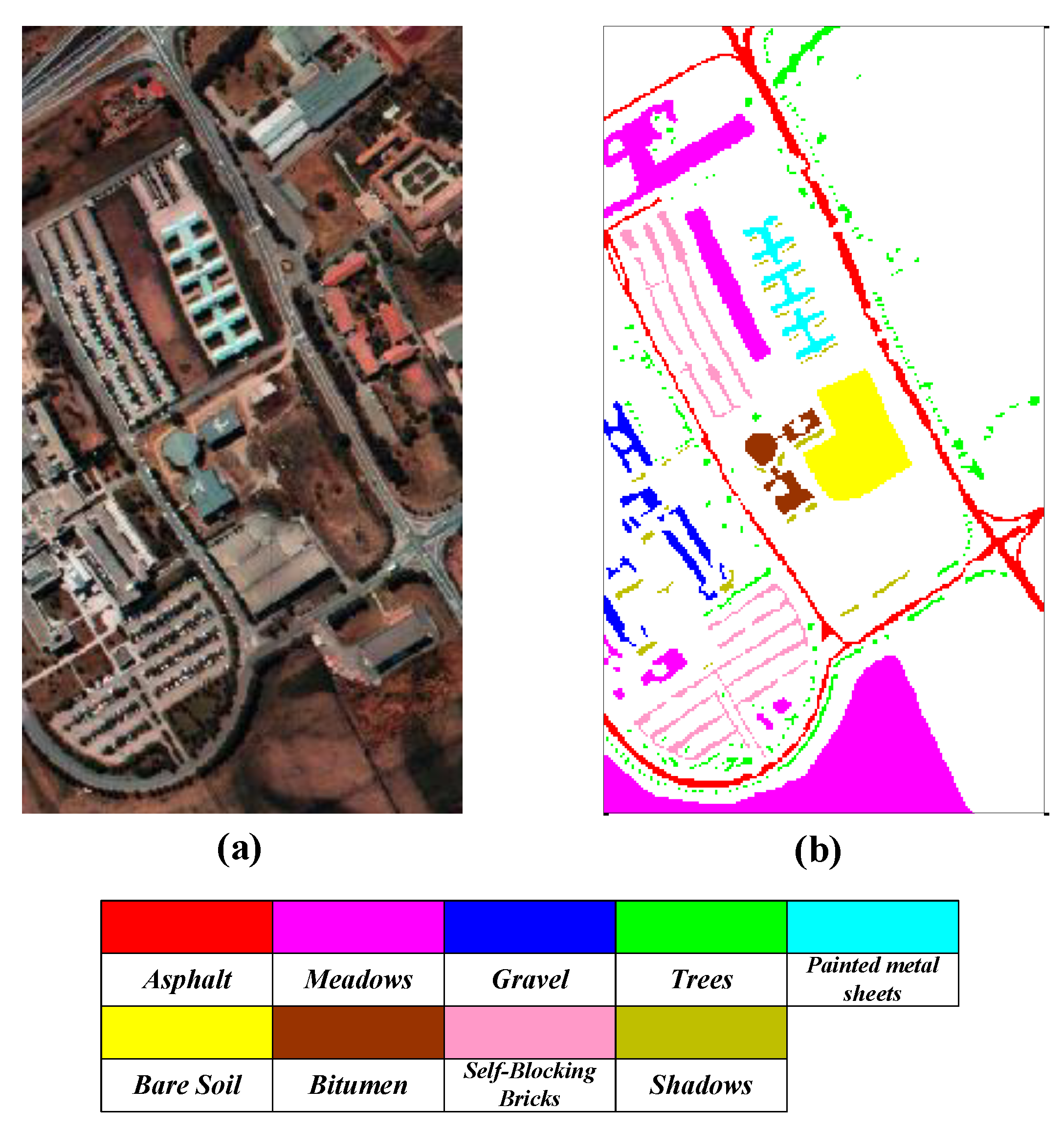
2.1. Data Collection
2.2. Classification Methods
2.2.1. Principle of KNCCRC
2.2.2. Principle of KNCCRT
2.2.3. Principle of the Proposed LNNCRC Method
2.2.4. Principle of The Proposed LNNCRT Method
3. Results and Discussion
3.1. Parameter Optimization
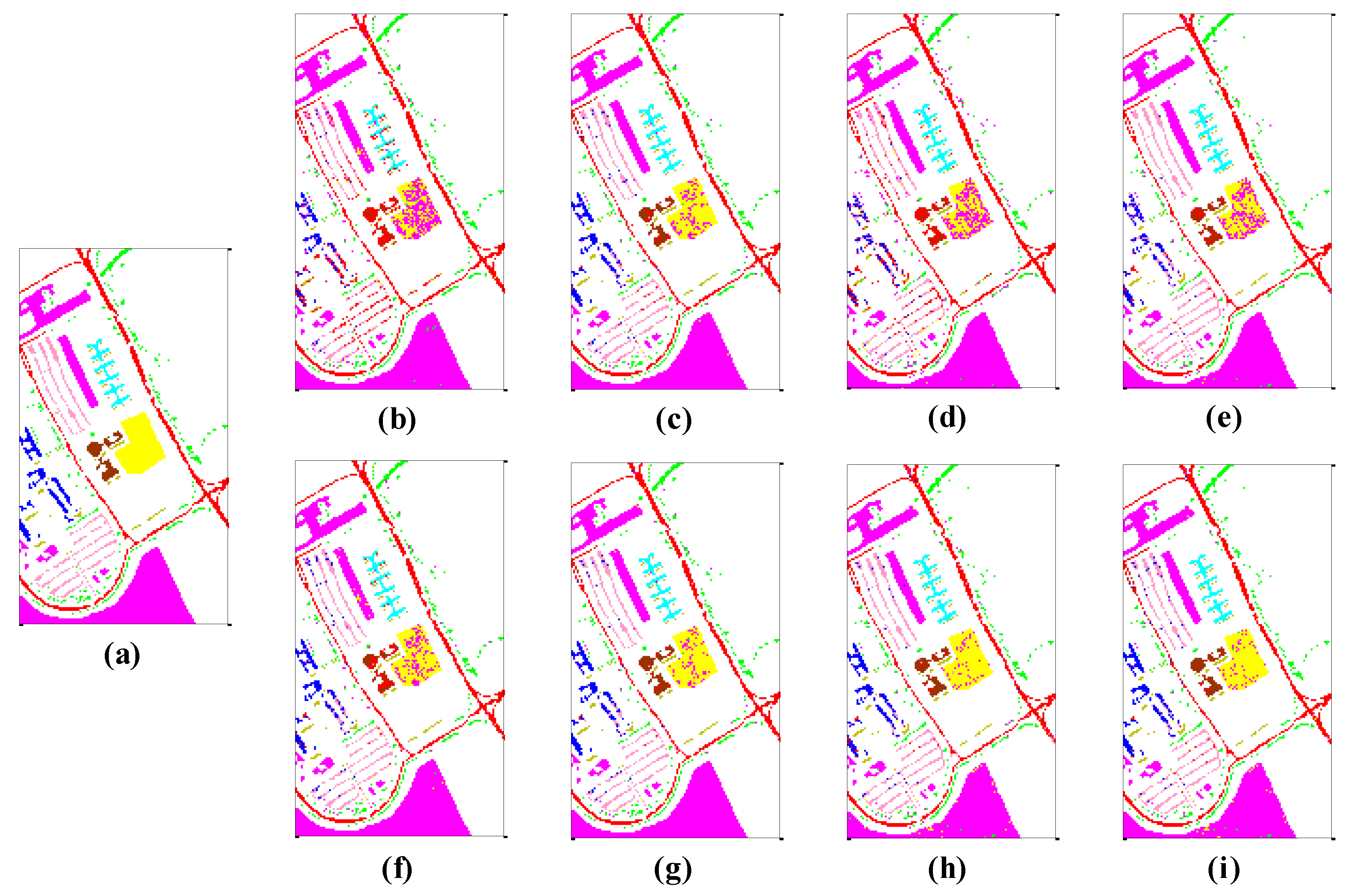
3.2. Land Cover Classification Performance for Different Methods
3.3. Comparison of Running Time
4. Conclusions
- (1)
- Compared with other methods, the proposed LNNCRT method achieves the best land cover classification performance, in which the OA, AA, and kappa reach 93.04%, 90.31%, and 0.9071, respectively.
- (2)
- LNNCRC and LNNCRT outperform KNCCRC and KNCCRT, respectively, which indicates that the proposed methods not only further exclude the interference of irrelevant training samples and classes, but also effectively eliminate the influence of imbalanced training samples, so as to improve the land cover classification performance of CR models.
- (3)
- LNNCRT takes much less time than CRT, NRS, and KNCCRT, and LNNCRC takes much less time than NSC and KNCCRC, which indicates that the proposed methods can effectively reduce the computational complexity of CR models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land cover classification using Google Earth Engine and random forest classifier-the role of image composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Jenicka, S.; Suruliandi, A. Distributed texture-based land cover classification algorithm using hidden Markov model for multispectral data. Surv. Rev. 2016, 48, 430–437. [Google Scholar] [CrossRef]
- Herold, M. Assessment of the status of the development of the standards for the terrestrial essential climate variables. In Land. Land Cover; FAO: Rome, Italy, 2009. [Google Scholar]
- Akar, O.; Gormus, E.T. Land use/land cover mapping from airborne hyperspectral images with machine learning algorithms and contextual information. Geocarto Int. 2021. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, shrub, and grass classification using only RGB images. Remote Sens. 2020, 12, 1333. [Google Scholar] [CrossRef] [Green Version]
- Bi, F.K.; Hou, J.Y.; Wang, Y.T.; Chen, J.; Wang, Y.P. Land cover classification of multispectral remote sensing images based on time-spectrum association features and multikernel boosting incremental learning. J. Appl. Remote Sens. 2019, 13, 044510. [Google Scholar] [CrossRef]
- Mo, Y.; Zhong, R.F.; Cao, S.S. Orbita hyperspectral satellite image for land cover classification using random forest classifier. J. Appl. Remote Sens. 2021, 15, 014519. [Google Scholar] [CrossRef]
- Li, W.; Du, Q.; Zhang, F.; Hu, W. Hyperspectral image classification by fusing collaborative and sparse Representations. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 4178–4187. [Google Scholar] [CrossRef]
- Xie, M.L.; Ji, Z.X.; Zhang, G.Q.; Wang, T.; Sun, Q.S. Mutually exclusive-KSVD: Learning a discriminative dictionary for hyperspectral image classification. Neurocomputing 2018, 315, 177–189. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Li, S.T.; Plaza, A. Subpixel component analysis for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5564–5579. [Google Scholar] [CrossRef]
- Kuras, A.; Brell, M.; Rizzi, J.; Burud, I. Hyperspectral and Lidar data applied to the urban land cover machine learning and neural-network-based classification: A review. Remote Sens. 2021, 13, 3393. [Google Scholar] [CrossRef]
- Sivabalan, K.R.; Ramaraj, E. Phenology based classification index method for land cover mapping from hyperspectral imagery. Multimed. Tools Appl. 2021, 80, 14321–14342. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.M.; Gao, C.Z.; Tao, R. Spectral shift mitigation for cross-scene hyperspectral imagery classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 6624–6638. [Google Scholar] [CrossRef]
- Xia, J.S.; Yokoya, N.; Iwasaki, A. Ensemble of transfer component analysis for domain adaptation in hyperspectral remote sensing image classification. In 2017 IEEE International Geoscience and Remote Sensing Symposium; IEEE: Fort Worth, TX, USA, 2017; pp. 4762–4765. [Google Scholar]
- Ye, M.C.; Qian, Y.T.; Zhou, J.; Tang, Y.Y. Dictionary learning-based feature-level domain adaptation for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1544–1562. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Du, Q.; Zhang, F.; Hu, W. Collaborative-representation-based nearest neighbor classifier for hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 389–393. [Google Scholar] [CrossRef]
- Su, H.J.; Zhao, B.; Du, Q.; Du, P.J. Kernel collaborative representation with local correlation features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1230–1241. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yang, M.; Feng, X.C. Sparse Representation or Collaborative Representation: Which Helps Face Recognition? In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Tramel, E.W.; Prasad, S.; Fowler, J.E. Nearest regularized subspace for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 477–489. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Du, Q.; Xiong, M.M. Kernel collaborative representation with Tikhonov Regularization for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 48–52. [Google Scholar]
- Ma, Y.; Li, C.; Li, H.; Mei, X.G.; Ma, J.Y. Hyperspectral image classification with discriminative kernel collaborative representation and Tikhonov regularization. IEEE Geosci. Remote Sens. Lett. 2018, 15, 587–591. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Y.X.; Liu, N.; Du, Q.; Tao, R. Structure-aware collaborative representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7246–7261. [Google Scholar] [CrossRef]
- Su, H.J.; Yu, Y.; Wu, Z.Y.; Du, Q. Random subspace-based k-nearest class collaborative representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6840–6853. [Google Scholar] [CrossRef]
- Wei, J.S.; Qi, X.J.; Wang, M.T. Collaborative representation classifier based on k nearest neighbors for classification. J. Softw. Eng. 2015, 9, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.H.; Qian, J.X. Hyperspectral image classification via multiscale joint collaborative representation with locally adaptive dictionary. IEEE Geosci. Remote Sens. Lett. 2018, 15, 112–116. [Google Scholar] [CrossRef]
- Chakraborty, S.; Phukan, J.; Roy, M.; Chaudhuri, B.B. Handling the class imbalance in land-cover classification using bagging-based semisupervised neural approach. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1493–1497. [Google Scholar] [CrossRef]
- Fang, J.; Cao, X.Q. Multidimensional relation learning for hyperspectral image classification. Neurocomputing 2020, 410, 211–219. [Google Scholar] [CrossRef]
- Feng, W.; Huang, W.J.; Bao, W.X. Imbalanced hyperspectral image classification with an adaptive ensemble method based on SMOTE and rotation forest with differentiated sampling rates. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1879–1883. [Google Scholar] [CrossRef]
- Feng, W.; Quan, Y.H.; Dauphin, G.; Li, Q.; Gao, L.R.; Huang, W.J.; Xia, J.S.; Zhu, W.T.; Xing, M.D. Semi-supervised rotation forest based on ensemble margin theory for the classification of hyperspectral image with limited training data. Inf. Sci. 2021, 575, 611–638. [Google Scholar] [CrossRef]
- Lv, Q.Z.; Feng, W.; Quan, Y.H.; Dauphin, G.; Gao, L.R.; Xing, M.D. Enhanced-random-feature-subspace-based ensemble CNN for the imbalanced hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 3988–3999. [Google Scholar] [CrossRef]
- Prabhakar, T.V.N.; Geetha, P. Two-dimensional empirical wavelet transform based supervised hyperspectral image classification. ISPRS-J. Photogramm. Remote Sens. 2017, 133, 37–45. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class | Total Samples | Training Samples | Validation Samples | Test Samples |
|---|---|---|---|---|---|
| 1 | Asphalt | 6631 | 663 | 1326 | 4642 |
| 2 | Meadows | 18,649 | 1865 | 3730 | 13,054 |
| 3 | Gravel | 2099 | 210 | 420 | 1469 |
| 4 | Trees | 3064 | 306 | 613 | 2145 |
| 5 | Painted metal sheets | 1345 | 135 | 269 | 942 |
| 6 | Bare soil | 5029 | 503 | 1006 | 3520 |
| 7 | Bitumen | 1330 | 133 | 266 | 931 |
| 8 | Self-blocking bricks | 3682 | 368 | 736 | 2577 |
| 9 | Shadows | 947 | 95 | 189 | 663 |
| All classes | 42,776 | 4278 | 8555 | 29,943 | |
| Parameters | Methods | |||||||
|---|---|---|---|---|---|---|---|---|
| CRC | CRT | NSC | NRS | KNCCRC | KNCCRT | LNNCRC | LNNCRT | |
| 5 × 10−3 | 5 × 10−2 | 7.5 | 7 | 3 × 10−3 | 1 × 10−1 | 3 × 10−2 | 3 × 10−1 | |
| K | No application | No application | No application | No application | 2 | 2 | 2 | 4 |
| k | No application | No application | No application | No application | No application | No application | 40 | 55 |
| Class | CRC | CRT | NSC | NRS | KNCCRC | KNCCRT | LNNCRC | LNNCRT |
|---|---|---|---|---|---|---|---|---|
| Asphalt | 95.99 | 92.99 | 96.32 | 95.51 | 94.12 | 92.73 | 89.83 | 92.85 |
| Meadows | 98.51 | 99.46 | 99.83 | 99.55 | 98.30 | 99.24 | 97.68 | 98.32 |
| Gravel | 23.95 | 65.15 | 32.29 | 44.49 | 62.30 | 73.31 | 65.51 | 75.17 |
| Trees | 82.53 | 90.28 | 53.10 | 82.86 | 84.61 | 90.90 | 92.63 | 92.38 |
| Painted metal sheets | 71.75 | 98.40 | 98.25 | 99.25 | 81.32 | 99.18 | 99.11 | 99.10 |
| Bare soil | 23.82 | 72.96 | 34.61 | 47.80 | 65.61 | 81.20 | 88.05 | 86.25 |
| Bitumen | 0.00 | 64.91 | 1.36 | 33.03 | 36.94 | 77.14 | 75.55 | 82.23 |
| Self-blocking bricks | 47.63 | 84.21 | 54.38 | 92.13 | 80.10 | 87.90 | 88.10 | 86.60 |
| Shadows | 4.11 | 99.77 | 36.36 | 99.41 | 99.71 | 99.98 | 99.91 | 99.89 |
| OA (%) | 74.17 | 90.59 | 76.53 | 86.22 | 87.08 | 92.59 | 91.97 | 93.04 |
| AA (%) | 49.81 | 85.35 | 56.28 | 77.12 | 78.11 | 89.06 | 88.49 | 90.31 |
| Kappa | 0.6358 | 0.8729 | 0.6666 | 0.8103 | 0.8247 | 0.9006 | 0.8931 | 0.9071 |
| Methods | CRC | CRT | NSC | NRS | KNCCRC | KNCCRT | LNNCRC | LNNCRT |
|---|---|---|---|---|---|---|---|---|
| Running time (seconds) | 5.2323 × 101 | 3.9765 × 104 | 5.8659 × 103 | 6.0098 × 103 | 1.2621 × 104 | 1.2867 × 104 | 7.3053 × 101 | 2.8159 × 102 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, R.; Zhou, Q.; Fan, B.; Wang, Y. Land Cover Classification from Hyperspectral Images via Local Nearest Neighbor Collaborative Representation with Tikhonov Regularization. Land 2022, 11, 702. https://doi.org/10.3390/land11050702
Yang R, Zhou Q, Fan B, Wang Y. Land Cover Classification from Hyperspectral Images via Local Nearest Neighbor Collaborative Representation with Tikhonov Regularization. Land. 2022; 11(5):702. https://doi.org/10.3390/land11050702
Chicago/Turabian StyleYang, Rongchao, Qingbo Zhou, Beilei Fan, and Yuting Wang. 2022. "Land Cover Classification from Hyperspectral Images via Local Nearest Neighbor Collaborative Representation with Tikhonov Regularization" Land 11, no. 5: 702. https://doi.org/10.3390/land11050702
APA StyleYang, R., Zhou, Q., Fan, B., & Wang, Y. (2022). Land Cover Classification from Hyperspectral Images via Local Nearest Neighbor Collaborative Representation with Tikhonov Regularization. Land, 11(5), 702. https://doi.org/10.3390/land11050702