Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images



 ,
,
Abstract
:1. Introduction
- (1)
- A deep learning network used to segment microscopic images. Attributable to data enhancement and network training, it achieves the highest accuracy (93.09% in pixel accuracy) compared to some traditional methods. Additionally, it only consumes 17.553 s per slice which could be beneficial to practical applications.
- (2)
- A symmetric overlap-tile strategy for deep learning-based image segmentation. The strategy could eliminate under-segmentation errors along the boundary of dendrites which is currently inevitable when using the base DeepLab network in simple local processing. Additionally, this strategy makes it possible to segment high resolution images with limited GPU resources.
- (3)
- A symmetric rectification method which analyzes 3D information to yield more precise results. Given the complexity of serial sections, it cannot apply the image fusion method often applied to video sequences. However, we have designed a symmetric image fusion method which is suitable to 3D material slices. It rectifies the segmentation mask by analyzing the masks of neighboring slices. Experimental results indicate that it could eliminate contaminations which form during the sample preparation process.
2. Proposed Method
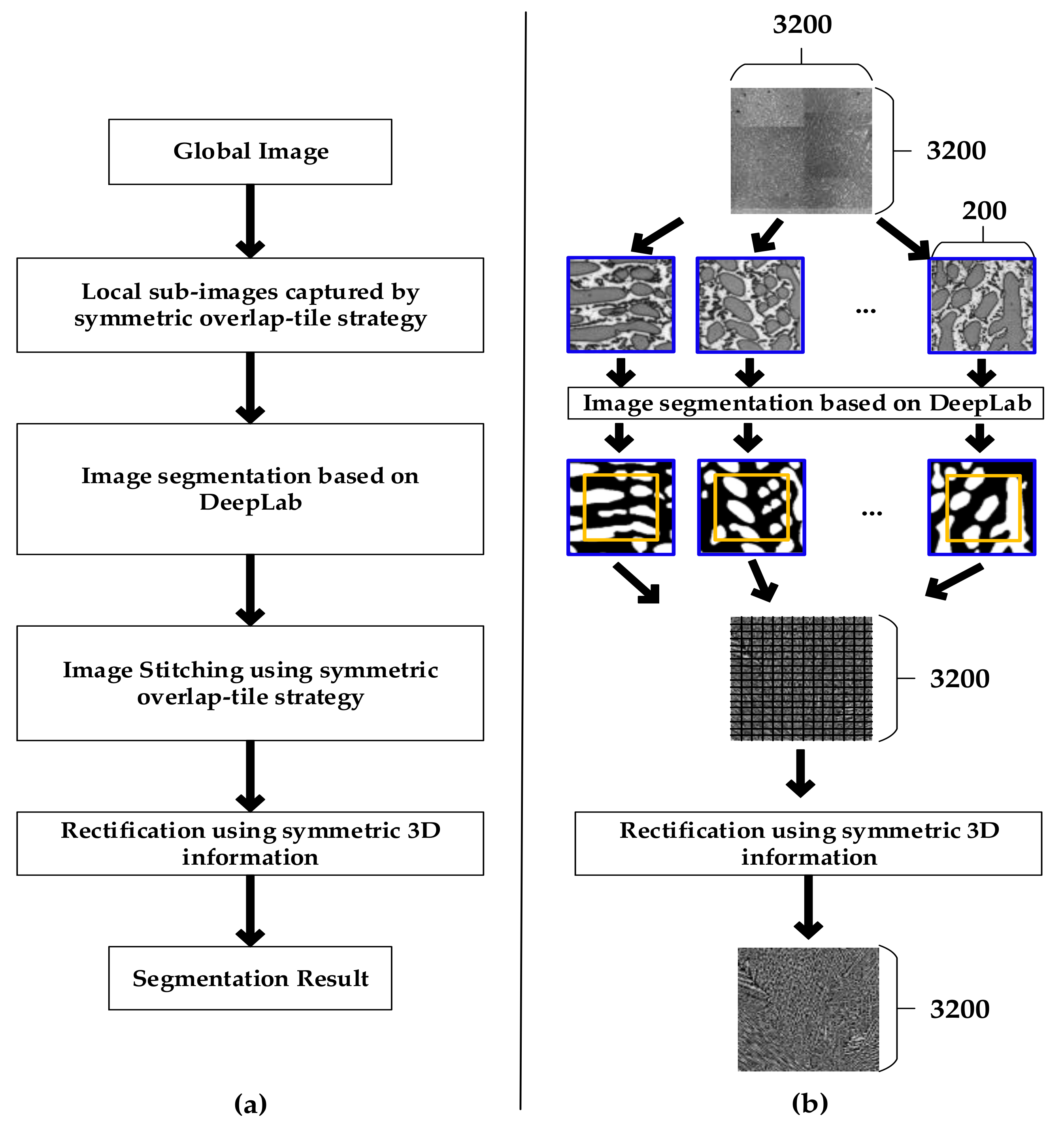
2.1. Overview of the Proposed Method
2.2. Image Segmentation Based on DeepLab
- Atrous Convolution
- Atrous Spatial Pyramid Pooling (ASPP)
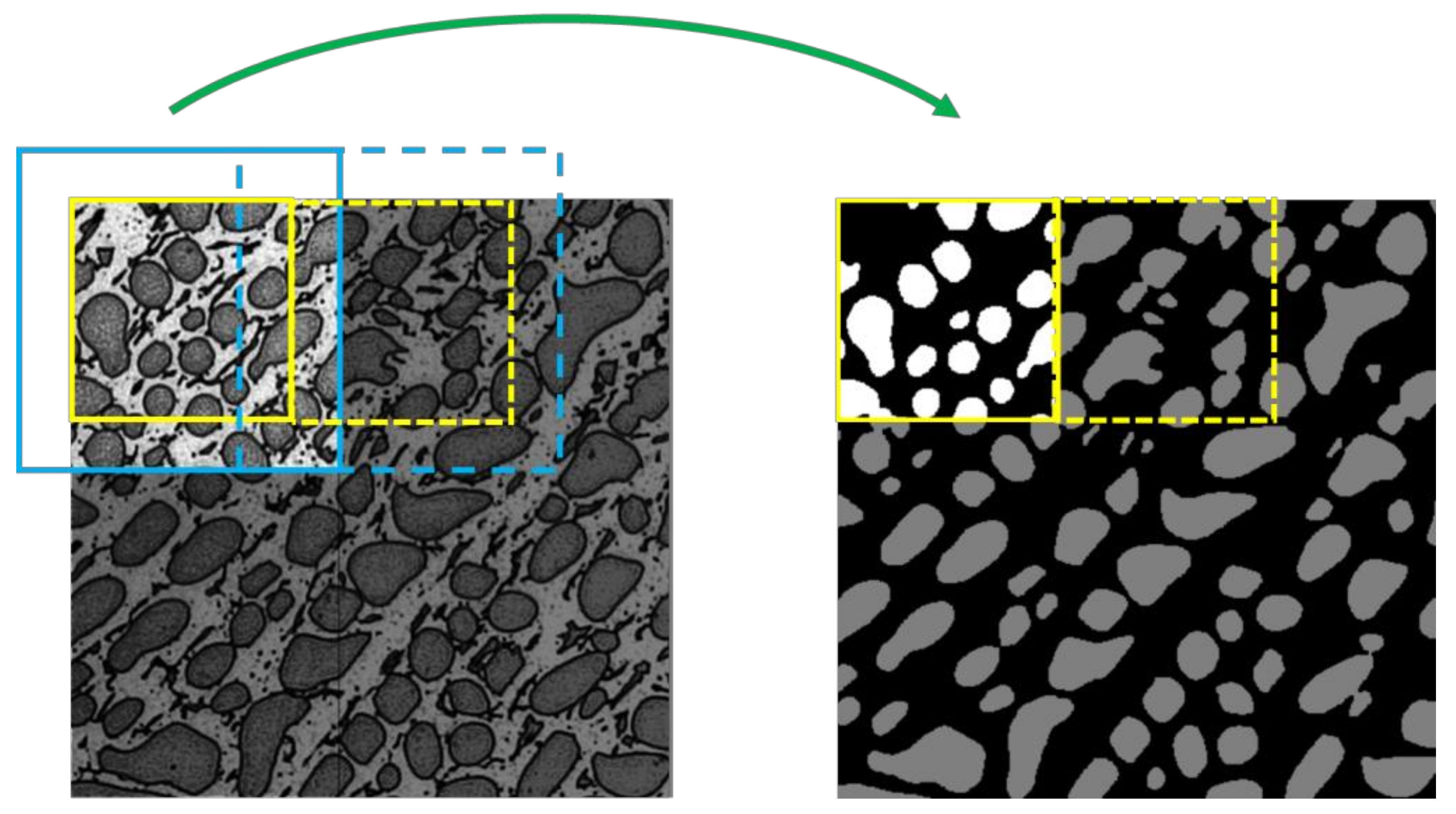
2.3. Symmetic Overlap-Tile Strategy for Seamless Segmentation
2.4. Symmetric Rectification Considering 3D Information
3. Implementation and Results
3.1. Experimental Data and Environment
3.2. Netowork Training
3.3. Testing of the Proposed DeepLab-Based Segementation
3.3.1. Image Segmentation by the Proposed Method
3.3.2. Comparison of the Proposed Method with Previous Methods
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

References
- Dursun, T.; Soutis, C. Recent developments in advanced aircraft aluminium alloys. Mater. Des. 2014, 56, 862–871. [Google Scholar] [CrossRef]
- Hu, J.; Shi, Y.N.; Sauvage, X. Grain boundary stability governs hardening and softening in extremely fine nanograined metals. Science 2017, 355, 1292–1296. [Google Scholar] [CrossRef] [PubMed]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis, and Machine Vision, 4th ed.; Cengage Learning: Stamford, CT, USA, 2014; ISBN 1133593607. [Google Scholar]
- Lewis, A.C.; Howe, D. Future Directions in 3D Materials Science: Outlook from the First International Conference on 3D Materials Science. JOM 2014, 66, 670–673. [Google Scholar] [CrossRef]
- Almsick, M.V. Microscope Image Processing; Elsevier: New York, NY, USA, 2017; pp. 635–653. [Google Scholar]
- Hong, Z.Y.; Dong, W.Z. Formation mechanism of the discontinuous dendrite structure in Al-La alloys. J. Univ. Sci. Technol. Beijing 2009, 31, 1132–1137. [Google Scholar]
- D’Amore, A.; Stella, J.A.; Wagner, W.R. Characterization of the complete fiber network topology of planar fibrous tissues and scaffolds. Biomaterials 2010, 31, 5345–5354. [Google Scholar] [CrossRef] [PubMed]
- Vala, M.H.J.; Baxi, A. A review on Otsu image segmentation algorithm. Int. J. Adv. Res. Comput. Eng. Technol. 2013, 2, 387–389. [Google Scholar]
- Dewan, M.A.A.; Ahmad, M.O.; Swamy, M.N.S. Tracking biological cells in time-lapse microscopy: An adaptive technique combining motion and topological features. IEEE Trans. Biomed. Eng. 2011, 58, 1637–1647. [Google Scholar] [CrossRef] [PubMed]
- Meyer, F.; Beucher, S. Morphological segmentation. J. Vis. Commun. Image Represent. 1990, 1, 21–46. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using watershed transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef]
- Birkbeck, N.; Cobzas, D.; Jagersand, M. An Interactive Graph Cut Method for Brain Tumor Segmentation. In Proceedings of the Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009. [Google Scholar]
- Shi, J.; Jitendra, M. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Jonathan, L.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X. Pyramid scene parsing network. arXiv, 2016; arXiv:1612.01105. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv, 2015; arXiv:1506.04579. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv, 2015; arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Chen, X.; Mottaghi, R.; Liu, X.; Fidler, S.; Urtasun, R.; Yuille, A. Detect What you Can: Detecting and Representing Objects Using Holistic Models and Body Parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 27–29 June 2016. [Google Scholar]
- Alatan, A.; Aydin. Image sequence analysis for emerging interactive multimedia services-the European COST 211 framework. IEEE Trans. Circuits Syst. Video Technol. 1998, 8, 802–813. [Google Scholar] [CrossRef] [Green Version]
- Doulamis, A.; Doulamis, N.; Ntalianis, K.; Kollias, S. Efficient unsupervised content-based segmentation in stereoscopic video sequences. Int. J. Artif. Intell. Tools 2000, 9, 277–303. [Google Scholar] [CrossRef]
- Feng, M.; Wang, Y.; Wang, H. Reconstruction of three-dimensional grain structure in polycrystalline iron via an interactive segmentation method. Int. J. Miner. Metall. Mater. 2017, 24, 257–263. [Google Scholar] [CrossRef]
- Waggoner, J.; Zhou, Y.; Simmons, J. 3D Materials image segmentation by 2D propagation: A graph-cut approach considering homomorphism. IEEE Trans. Image Process. 2013, 22, 5282–5293. [Google Scholar] [CrossRef] [PubMed]
- Python Language Reference. Available online: http://www.python.org (accessed on 8 January 2018).
- Tensorflow. Available online: http://www.tensorfly.cn/ (accessed on 8 January 2018).
- Laganière, R. OpenCV 3 Computer Vision Application Programming Cookbook, 3rd ed.; Packt Publishing Ltd: Birmingham, UK, 2017; ISBN 178649715. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Geforce GTX 1080Ti. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1080-ti/ (accessed on 8 January 2018).
- Schindelin, J.; Arganda-Carreras, I.; Frise, E.; Kaynig, V.; Longair, M.; Pietzsch, T. Fiji: An open-source platform for biological-image analysis. Nat. Methods 2012, 9, 676. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Name | Kernels | No. of Blocks | Feature Map Resolution(Height × Width) | No. of Stride | |
|---|---|---|---|---|---|
| Type | Dimension | ||||
| Image Input | 1 | 200 × 200 | None | ||
| Conv_1 | Conv | 7 × 7 × 64 | 1 | 100 × 100 | 2 × 2 |
| Conv_2 | Max Pool | 3 × 3 | 1 | 50 × 50 | 2 × 2 |
| Conv | 1 × 1 × 64 | 3 | 1 × 1 | ||
| Conv | 3 × 3 × 64 | 1 × 1 | |||
| Conv | 1 × 1 × 256 | 1 × 1 | |||
| Conv_3 | Conv | 1 × 1 × 128 | 4 | 25 × 25 | 1 × 1 (2 × 2 in first block) |
| Conv | 3 × 3 × 128 | 1 × 1 | |||
| Conv | 1 × 1 × 512 | 1 × 1 | |||
| Conv_4 | Atrous Conv, rate = 2 | 1 × 1 × 256 | 23 | 25 × 25 | 1 × 1 |
| Atrous Conv, rate = 2 | 3 × 3 × 256 | 25 × 25 | 1 × 1 | ||
| Atrous Conv, rate = 2 | 1 × 1 × 1024 | 25 × 25 | 1 × 1 | ||
| Conv_5 | Atrous Conv, rate = 4 | 1 × 1 × 512 | 3 | 25 × 25 | 1 × 1 |
| Atrous Conv, rate = 4 | 3 × 3 × 512 | 25 × 25 | 1 × 1 | ||
| Atrous Conv, rate = 4 | 1 × 1 × 2048 | 25 × 25 | 1 × 1 | ||
| Conv_6 (ASPP) | Atrous Conv, rate = 6 | 3 × 3 × 2 | 1 | 25 × 25 | 1 × 1 |
| Atrous Conv, rate = 12 | 3 × 3 × 2 | 1 | 25 × 25 | 1 × 1 | |
| Atrous Conv, rate = 18 | 3 × 3 × 2 | 1 | 25 × 25 | 1 × 1 | |
| Atrous Conv, rate = 24 | 3 × 3 × 2 | 1 | 25 × 25 | 1 × 1 | |
| Softmax | 1 | 25 × 25 | None | ||
| Output Layer | Billiner Interpolation by 8 | 1 | 200 × 200 | None | |
| Rank | Simple Local Processing | Symmetric Overlap-Tile Strategy | 3D Symmetric Rectification | Pixel Accuracy (%) | Inference Time per Slice (s) |
|---|---|---|---|---|---|
| 1 | √ | 91.96 ± 0.11% | 14.026 | ||
| 2 | √ | 92.45 ± 0.15% | 17.553 | ||
| 3 | √ | √ | 93.09 ± 0.06% | 17.553 |
| Rank | Method | Pixel Accuracy (%) | Inference Time (s) |
|---|---|---|---|
| 1 | Ground Truth | 100.00% | 100,800 |
| 2 | Our method | 93.09 ± 0.06% | 17.553 |
| 3 | Graph-Cut | 87.14 ± 1.03% | 360 |
| 4 | Watershed | 87.13 ± 0.55% | 12.260 |
| 5 | K-Means | 65.68 ± 6.14% | 13.315 |
| 6 | Otsu | 65.43 ± 7.47% | 0.072 |
| 7 | Adaptive Mean | 56.69 ± 1.09% | 0.081 |
| 8 | Adaptive Gaussian | 56.37 ± 1.04% | 0.109 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, B.; Ban, X.; Huang, H.; Chen, Y.; Liu, W.; Zhi, Y. Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry 2018, 10, 107. https://doi.org/10.3390/sym10040107
Ma B, Ban X, Huang H, Chen Y, Liu W, Zhi Y. Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry. 2018; 10(4):107. https://doi.org/10.3390/sym10040107
Chicago/Turabian StyleMa, Boyuan, Xiaojuan Ban, Haiyou Huang, Yulian Chen, Wanbo Liu, and Yonghong Zhi. 2018. "Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images" Symmetry 10, no. 4: 107. https://doi.org/10.3390/sym10040107
APA StyleMa, B., Ban, X., Huang, H., Chen, Y., Liu, W., & Zhi, Y. (2018). Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry, 10(4), 107. https://doi.org/10.3390/sym10040107