4.1. Experimental Data and Environment
We selected input facial images from the PAL database as shown in
Figure 4 [
33,
34]. This database classifies the ages of 576 persons who are between 18 and 93 years old. In ethnicity, the database consists of 76% Caucasian, 16% African-American, and the remaining 8% as Asian, South Asian, and Hispanic backgrounds.
For the 580 PAL database images of 576 persons, the following data augmentation was used [
27,
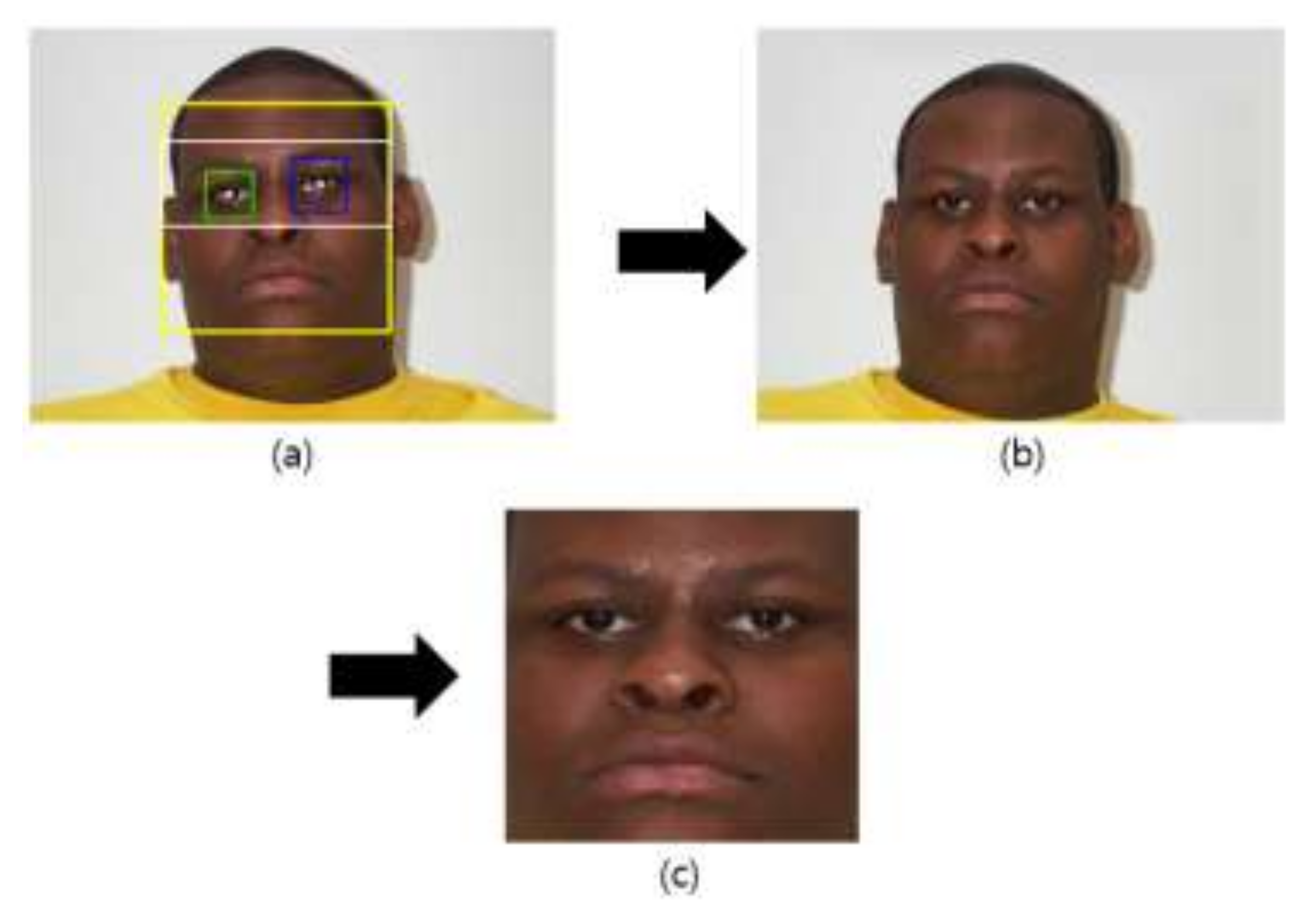
35]: 17 cases underwent vertical and horizontal image translation and cropping with the previously detected face region (
Figure 2c), and horizontal mirroring was applied to the images to get the augmented data of 19,720 (= 580 × 17 × 2) images. Sample images by this data augmentation can be seen in [
35].
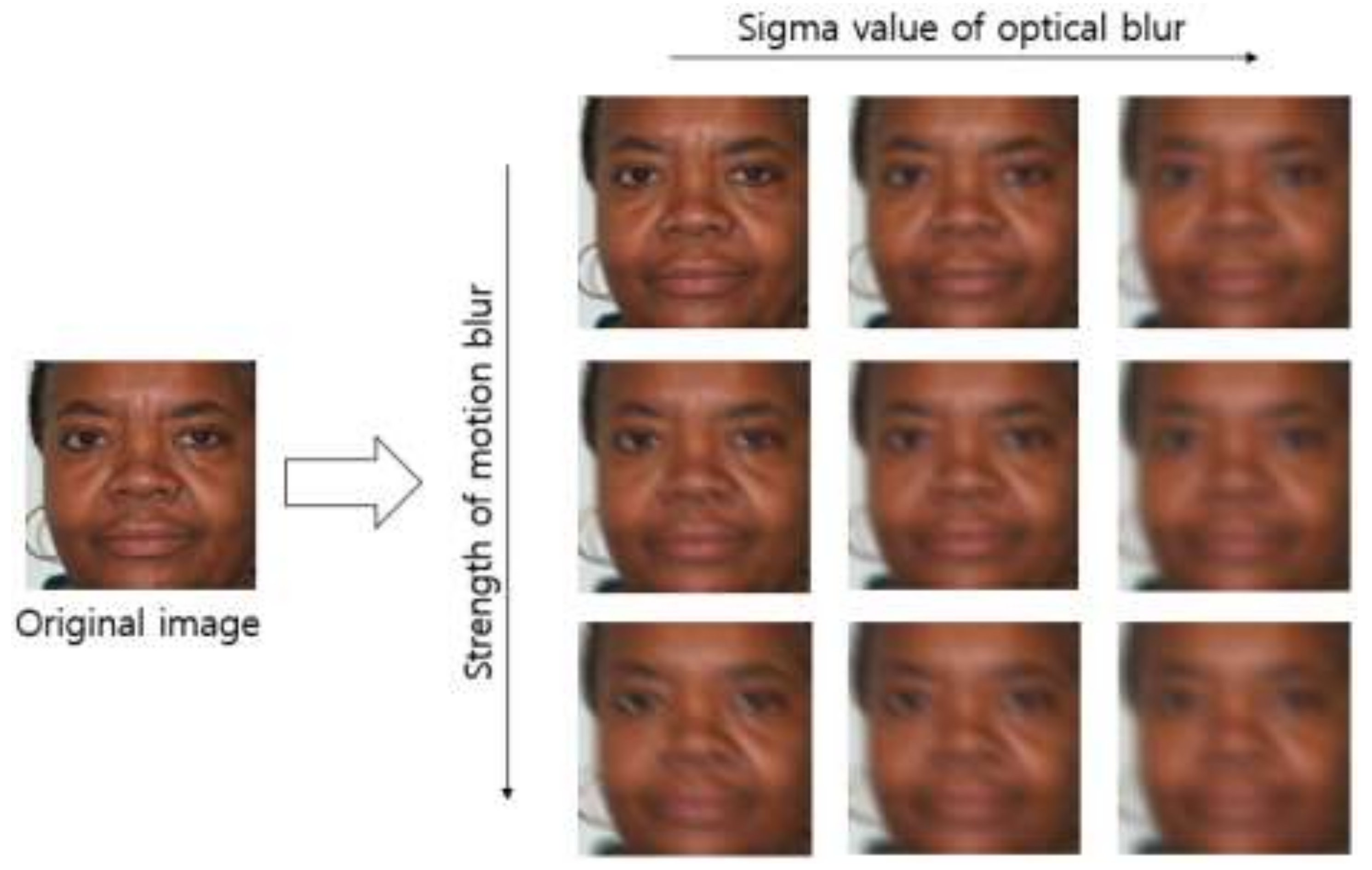
There is no open database of images obtained in a blurring environment. For this reason, we created artificially blurred images by applying five sigma values of Gaussian filtering to optical blurring, four directions of motion blur on the basis of the point spread function of motion blurring, which was introduced in study [
36], and seven types of strength of motion blur. In other words, 81,200 (= 580 × 5 (sigma value) × 4 (motion direction) × 7 (strength of motion blur)) optical and motion blurred images were added. Consequently, 100,920 (= 19,720 + 81,200) pieces of data were obtained.
Figure 5 shows some examples of the generated optical and motion blurred images.
For the experiment, we used a desktop computer equipped with a 3.50 GHz CPU (Intel (R) Core (TM) i7-3770K) [
37] and 24 GB RAM. Windows Caffe [
38] was utilized for training and testing. We used an Nvidia graphic card with 1920 compute unified device architecture (CUDA) cores and 8 GB memory (Nvidia GeForce GTX 1070) [
39]. To extract the face ROI, we used the C/C++ program and OpenCV library [
40] with Microsoft Visual Studio 2015 [
41].
4.2. Training
This study applied fourfold cross-validation [
42] to 100,920 augmented pieces of data to conduct learning in each fold. In other words, 75,690 (= 100,920 × (3/4)) pieces of data were used for learning. The testing, which is explained in
Section 4.3, used the original images that were not augmented. The stochastic gradient descent (SGD) method [
43], as shown in Equation (7), was used to train the CNN:
where
is the weight to be trained,
is the learning rate, and
is the loss function. This method obtains the optimal
by iterating the learning until the loss function is converged. The SGD method finds an optimal weight, which minimizes the difference between the desired and calculated outputs, as the derivative base. Unlike the existing gradient descent (GD) method, the SGD method defines the size of the training set divided by the mini-batch size as iteration. One epoch is the time in which training is completed as many times as the number of iterations. The training is conducted for the predetermined epochs. This study used the following parameters for the SGD method: mini-batch size = 5, learning rate = 0.001, learning rate drop factor = 0.1, learning rate drop period = 10, L2 regularization = 0.0001, momentum = 0.9. For the meaning of each parameter, please refer to [
44]. During the training, data were shuffled and the learning rate was multiplied by the learning rate drop factor for each 10-epoch period. The weights used in the FC layer were initialized randomly using a Gaussian distribution with mean = 0 and standard deviation = 0.001, and the biases were initialized as default 0.
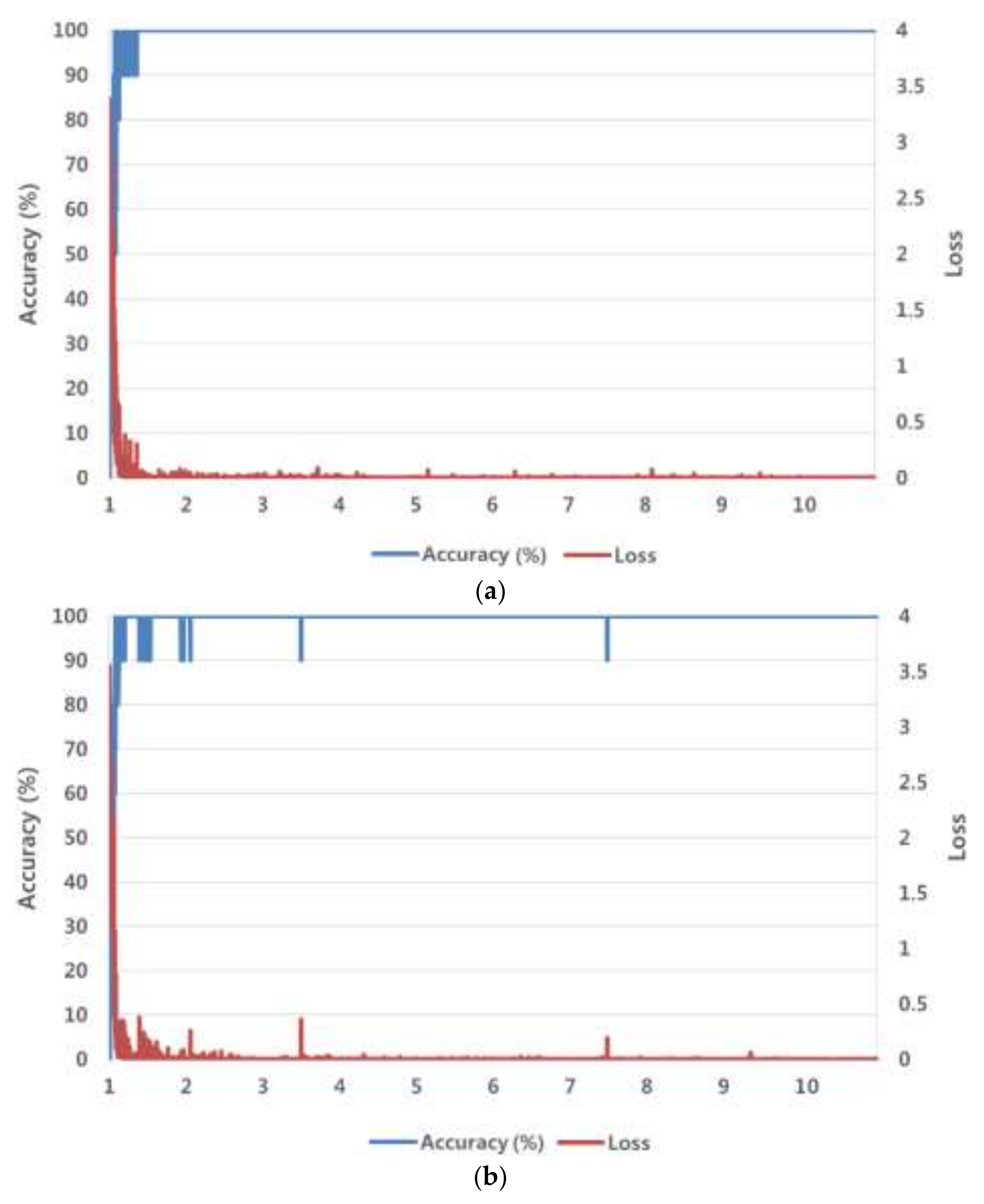
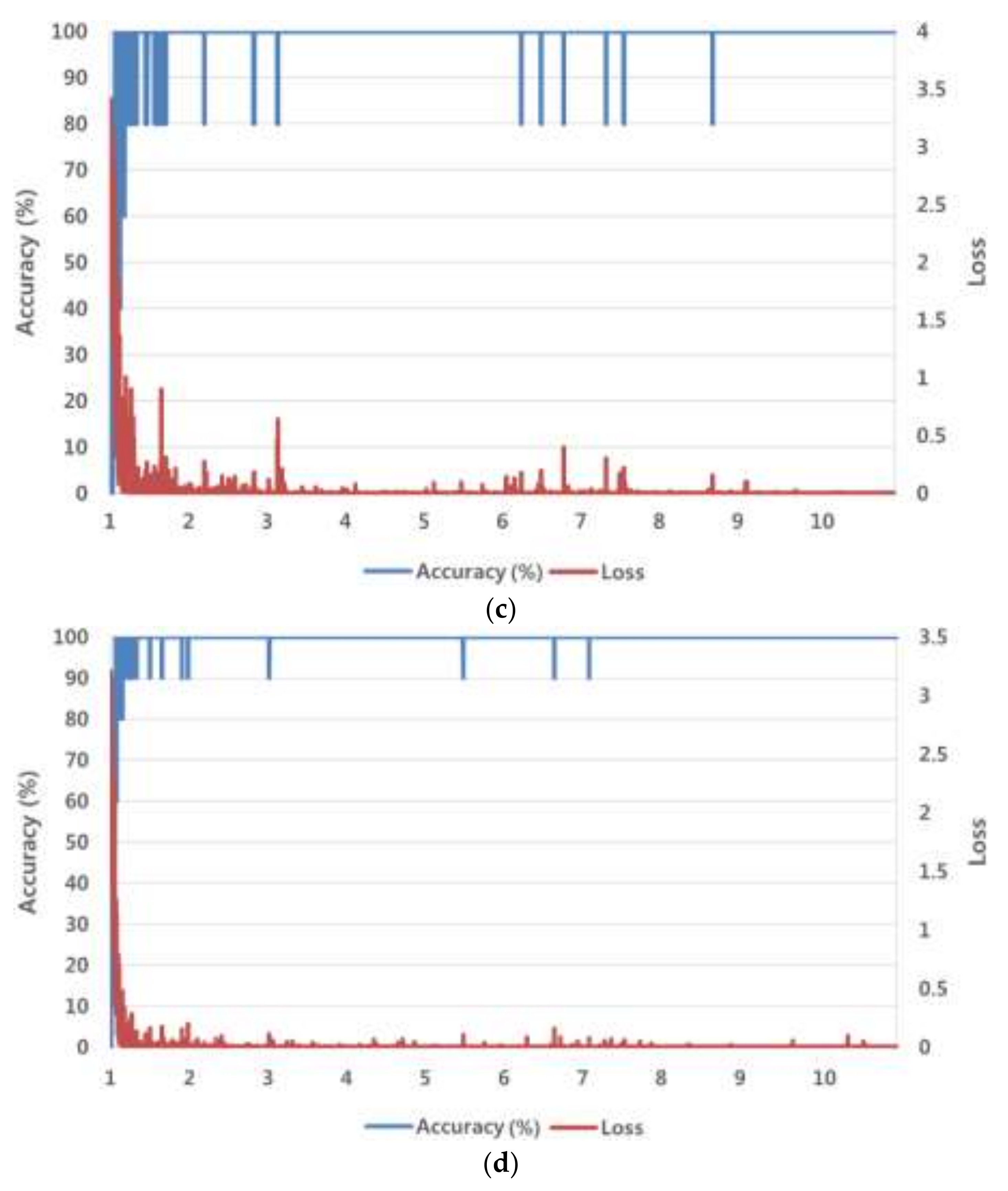
Figure 6 shows graphs of the training loss value and training accuracy value (%), which were obtained by training the ResNet-152 with the SGD method for the number of epochs. We experimentally determined the optimal parameters for the SGD method so as to obtain the lowest loss value and the highest accuracy of training data, shown in
Figure 6. As shown in the figure, the training made the loss and accuracy approach 0% and 100%, respectively, which indicates a good result.
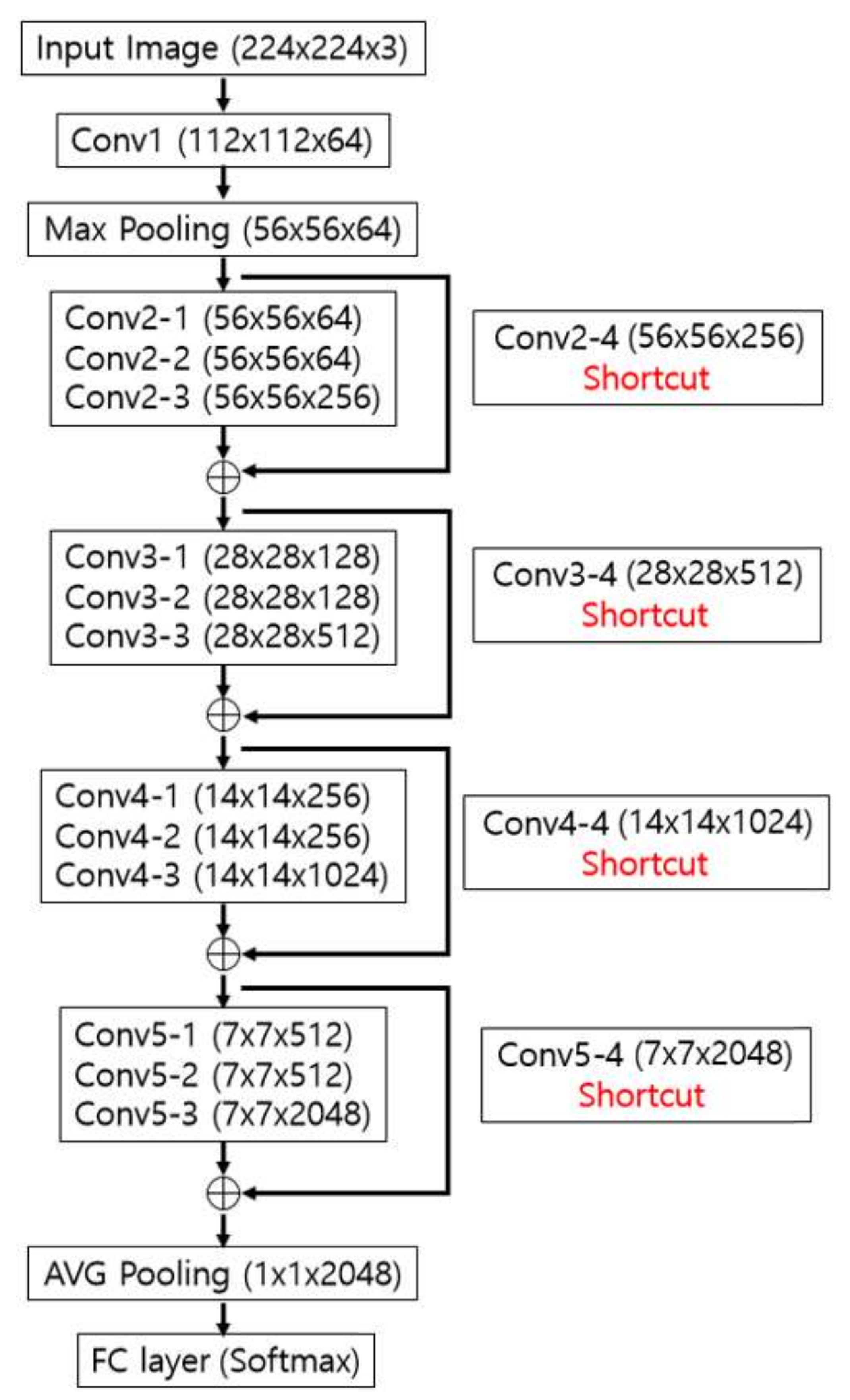
Figure 7 shows an example of the trained filter images. These filters are used in Conv1 in
Table 3, and 64 filters of 7 × 7 size are displayed, as in
Table 3. The figure is an enlargement of the 7 × 7 size for visibility. That is, we trained CNN that can extract the important low-, mid-, and high-frequency features (as shown in
Figure 7) for age estimation robust to the various qualities of input image, such as unblurred, optical blurred, or motion blurred images.
4.3. Testing with PAL Database
We conducted testing by using the original 81,780 (= 580 + 81,200) images, which were not augmented, as explained in
Section 4.1. Here, 580 pieces were the original PAL database images obtained from 576 persons, and 81,200 pieces were the optical and motion blurred images artificially created from the 580 pieces according to motion blur direction (four directions) and strength (seven degrees), as explained in
Section 4.1. As also mentioned above, since the fourfold cross-validation was applied to training and testing, testing was conducted with 20,445 (= 81,780/4) pieces for each fold.
Summarized explanations of training and testing images are as follows. From the original 580 PAL images, 19,720 (= 580 × 2 × 17) images were obtained by data augmentation, which included horizontal mirroring, and 17 cases of vertical and horizontal image translation with cropping. Then, 81,200 (= 580 × 5 (sigma value of Gaussian function) × 4 (motion direction) × 7 (strength of motion blur)) optical and motion blurred images were obtained from the original 580 PAL images. Consequently, 100,920 (= 19,720 + 81,200) images were finally obtained.
This study applied fourfold cross-validation [
42]. In other words, 75,690 (= 100,920 × (3/4)) images were used for learning, and testing was conducted with 20,445 (= 81,780 (580 (original) + 81,200 (optical and motion blurred))/4) images without the augmented images for each fold.
In our experiments, images from the same person were not included in both training and testing folds. The persons in the data of the training fold were different from those in the testing fold. For example, in the PAL database, the total number of classes (persons) was 576, and data of 432 (576 × 3/4) classes (persons) were used for training, whereas data of another 144 classes (576 × 1/4) (persons) were used for testing. Because the number of classes was so large, it took too much time to leave one person out of cross-validation, because the experiment would have to be performed 576 times. Therefore, in our experiments, we performed fourfold cross-validation.
The PAL database includes various types of images, such as neutral, happy, and profile. Among them, the number of neutral and frontal images is 580 [
33,
34]. In previous research [
11,
12,
16,
17,
18,
19,
21,
22], they used these 580 images for experiments, and we used the same 580 images for comparison with previous methods, as shown in
Table 4.
This study adopted MAE for age estimation accuracy, which has been widely used in existing studies [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. The equation of MAE is as follows [
45]:
where
is the number of input images,
is estimated age, and
is ground-truth age.
Table 4 presents the MAEs of age estimation produced by the existing methods using the original PAL database. As shown in the table, Belver et al.’s method showed the most accurate MAE of 3.79 years. However, this experimental result was based on the original unblurred images in the PAL database without optical and motion blurring. Optical and motion blurring make important facial age features, such as wrinkles and texture, vanish from the captured images, thereby increasing error in age estimation. For this reason, as mentioned above, we evaluated the age estimation performance for the original PAL database images and the optical and motion blurred images.
Comparative evaluation of performance was performed by varying the number of classes, which is the final output node of ResNet-152 in
Table 3. Since the PAL database, as explained in
Section 4.1, was established based on data of people in the age range 18 to 93, the total number of classes of age should be 76 (= 93 − 18 + 1). However, there is no image in the PAL database for two age classes, so the total number of classes becomes 74. Accordingly, to obtain the results of ResNet-152 for every age, we conducted training and testing by designating the number of classes, which is the final output node of ResNet-152, i.e., 74.
However, there were too many final output nodes of ResNet-152, which were reduced to decrease the complexity of the CNN structure and training. That is, if we tried to estimate age by one-year intervals, the number of output nodes in ResNet-152 should be 74. Using many output nodes increases the complexity of the CNN structure and makes its training difficult. Therefore, we reduced the number of output nodes in ResNet-152 by the following methods.
When the data were classified by age classes divided into three-year intervals, as shown in
Table 5, the number of final output nodes of ResNet-152 decreased from 74 to 25. Similarly, when the data were classified by age classes divided into five-year intervals, the number of final output nodes decreased from 74 to 15. In addition, when the data were classified by age classes divided into seven-year intervals, as shown in
Table 5, the number of final output nodes decreased from 74 to 11. In each case, the output age obtained by CNN was the middle age of each age range, as shown in
Table 5.
Besides using ResNet-152, we also compared the age estimation performance of the various existing CNN models, such as AlexNet and ResNet-50. As is clear from
Table 6, ResNet-152 with 25 classes (age classes divided into three-year intervals) had the lowest MAE, 6 years. That is, ResNet-152 including 152 layers showed higher accuracy than ResNet-50 including 50 layers and AlexNet including 8 layers. This result was lower than those in the existing research [
21,
22] by about 0.42–0.48 year, but unlike the current study, these studies considered either optical blur [
22] or motion blur [
21], not both types of blur at the same time. In addition, since the existing studies [
21,
22] conducted preclassification of direction or degree of blur, a long processing time was needed, a separate training of classifier for preclassification was necessary, and an age estimator needed to be separately trained according to the preclassification results. This increased system complexity. On the other hand, this research did not have a separate process of preclassification, but used a single ResNet-152 to design an age estimator that is robust to various conditions, including unblurred or optical and motion blurred. Among the existing studies, only [
21,
22] considered the blur of facial images, and thus we compared our study with those.
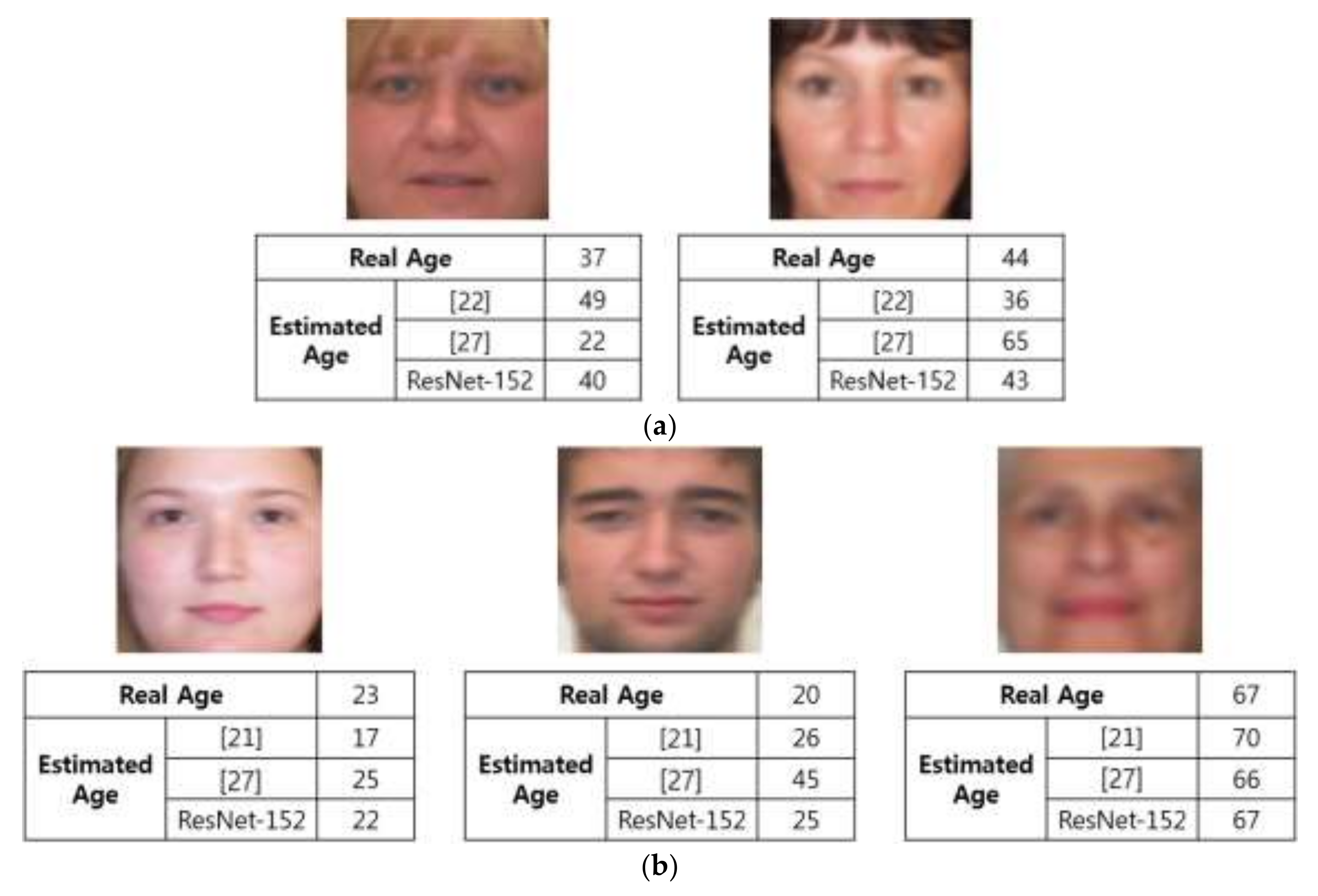
Figure 8 illustrates examples of age estimation by the proposed and existing methods. As seen in the figure, our method shows more accurate results of age estimation compared to previous methods.
4.4. Testing with MORPH Database
Our next experiment used the MORPH database, another open database. The MORPH database (album 2) contains 55,134 facial images of 13,617 individuals, with ages ranging from 16 to 77 years [
46]. From this database, we randomly selected 1574 images of individuals of different genders ranging in age from 16 to 65 years for our new experiments. In detail, 31 or 32 images were randomly selected from each age class, 16 to 65 (50 age classes), to guarantee a demographic distribution of the images from the whole database.
The same methods as those described in
Section 4.2 and
Section 4.3 were applied to conduct data augmentation and create optical and motion blurred images, and fourfold cross-validation was used to obtain MAE, as with the PAL database. For the 1574 MORPH database images, the following data augmentation was used [
27,
35]: 17 cases underwent vertical and horizontal image translation and cropping with the previously detected face region (
Figure 2c), and horizontal mirroring was applied to the images to get augmented data of 53,516 (= 1574 × 17 × 2) images. Sample images by this data augmentation can be seen in [
35].
As with the PAL database, we created artificially blurred images by applying five sigma values of Gaussian filtering to optical blurring, four directions of motion blurring on the basis of the point spread function, which was introduced in [
36], and seven types of strength of motion blur. In other words, 220,360 (= 1574 × 5 (sigma value) × 4 (motion direction) × 7 (strength of motion blur)) optical and motion blurred images were added. Consequently, 273,876 (= 53,516 + 220,360) pieces of data were obtained.
This study applied fourfold cross-validation [
42] to 273,876 augmented pieces of data to conduct learning in each fold. In other words, 205,407 (= 273,876 × (3/4)) images were used for training. The testing used the original 221,934 (= 1574 + 220,360) images that were not augmented.
As shown in
Table 7, Han et al. produced an age estimation MAE of 3.6 years, which was the most accurate result. However, this result is attributed to the experiment that dealt with the original unblurred MORPH database images, including no optical and motion blurred images. As mentioned above, this study evaluated age estimation performance by dealing with both the original MORPH database and optical and motion blurred images.
Table 8 presents the results, comparing the proposed method and previous methods.
As with testing with the PAL database, as described in
Section 4.3, comparative evaluation of performance was performed by varying the number of classes, which is the final output node of ResNet-152 in
Table 8. Since the MORPH database used in our experiments included data of people in the age range 16 to 65, the total number of age classes should be 50 (= 65 − 16 + 1). Besides using ResNet-152, we also compared the age estimation performance of various existing CNN models, such as AlexNet and ResNet-50.
As is clear from
Table 8, ResNet-152 with 17 classes (age classes divided into three-year intervals) had the lowest MAE, 5.78 years. That is, ResNet-152 including 152 layers shows higher accuracy than ResNet-50 including 50 layers and AlexNet including 8 layers. This result was lower than the results of the existing studies [
21,
22] by about 0.27–0.83 years.
The MAE with the MORPH database by our method was a little lower than that with the PAL database, as shown in
Table 6 and
Table 8. That is because the amount of training data in the MORPH database was larger than that of the PAL database.
Figure 9 shows some age estimation results by the proposed method and the previous ones. As shown in this figure, our method shows more accurate results of age estimation compared to previous methods.
4.7. Comparing Accuracy with Self-Collected Database
The real application of age estimation from blurry images is for people on the move in surveillance environments. In this field, even modern cameras that include the functionality of auto-focusing cannot provide sharp images due to people being in motion, as shown in
Figure 13d.
In this environment, face recognition can be considered. However, face recognition requires enrollment of the user’s face, and it performs matching with features from enrolled and input face images. However, in many applications, the user does not want to enroll his or her face due to anxiety over private face information being divulged. In addition, in applications such as analysis of the ages of visitors at shopping centers for marketing, it is difficult to enroll the faces of all visitors in advance. However, our research on age estimation does not require enrollment, and the user’s age is estimated directly from the input image without any matching. Therefore, our method can be used in various fields without causing resistance by users to enrolling their face information.
Most of the images from the PAL and MORPH databases used in our experiments show frontal faces. Because these open databases have been widely used for evaluating the accuracy of age estimation [
11,
12,
14,
16,
17,
18,
19,
20,
21,
22], we used them for comparisons with previous methods. There is no open database (providing ground-truth age information) in which faces are captured at different angles and distances, some part of the face is obscured, and real blurred images are included. Therefore, in order to conduct experiments, we gathered a self-collected database of images of 20 participants including the factors of different angles and distances, obstruction, and real blurring, which were obtained by an auto-focusing camera set 2.4 m from the ground in an indoor surveillance environment.
Figure 13 shows examples of images in this database. For fair comparison, we have made our database available to other researchers. As shown in
Figure 13d, real blurred images were captured due to people moving, in spite of the auto-focusing functionality of the camera.
As shown in
Table 10, the MAE of age estimation for different distances was as large as 8.03. That is because important features, such as wrinkles, disappear in low-resolution images captured at a far distance. Real blurred images and images from different angles did not have much effect on the accuracy of age estimation. However, in case of obstruction, MAE was a little increased. That is because the important features for age estimation around the nose and mouth could not be used for estimation.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}