
Analysis and Prediction for Confirmed COVID-19 Cases in Czech Republic with Uncertain Logistic Growth Model


Abstract
:1. Introduction
2. Uncertain Regression Analysis
2.1. Uncertain Logistic Growth Model
2.2. Parameter Estimation and Residual Analysis
2.3. Forecast
2.4. Uncertain Hypothesis Test
3. Uncertain Logistic Growth Model for COVID-19 Cases in Czech Republic
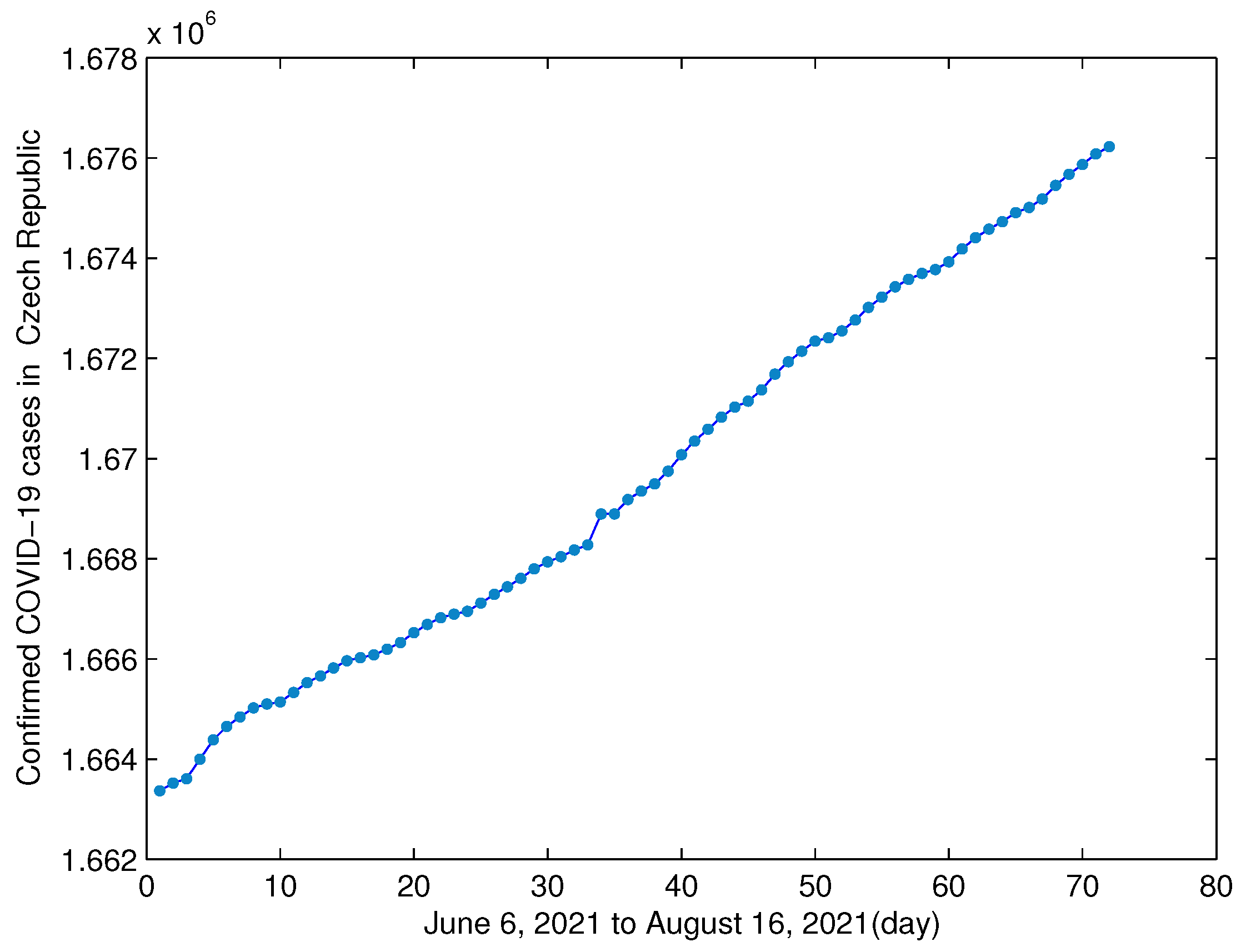
3.1. Data and Model
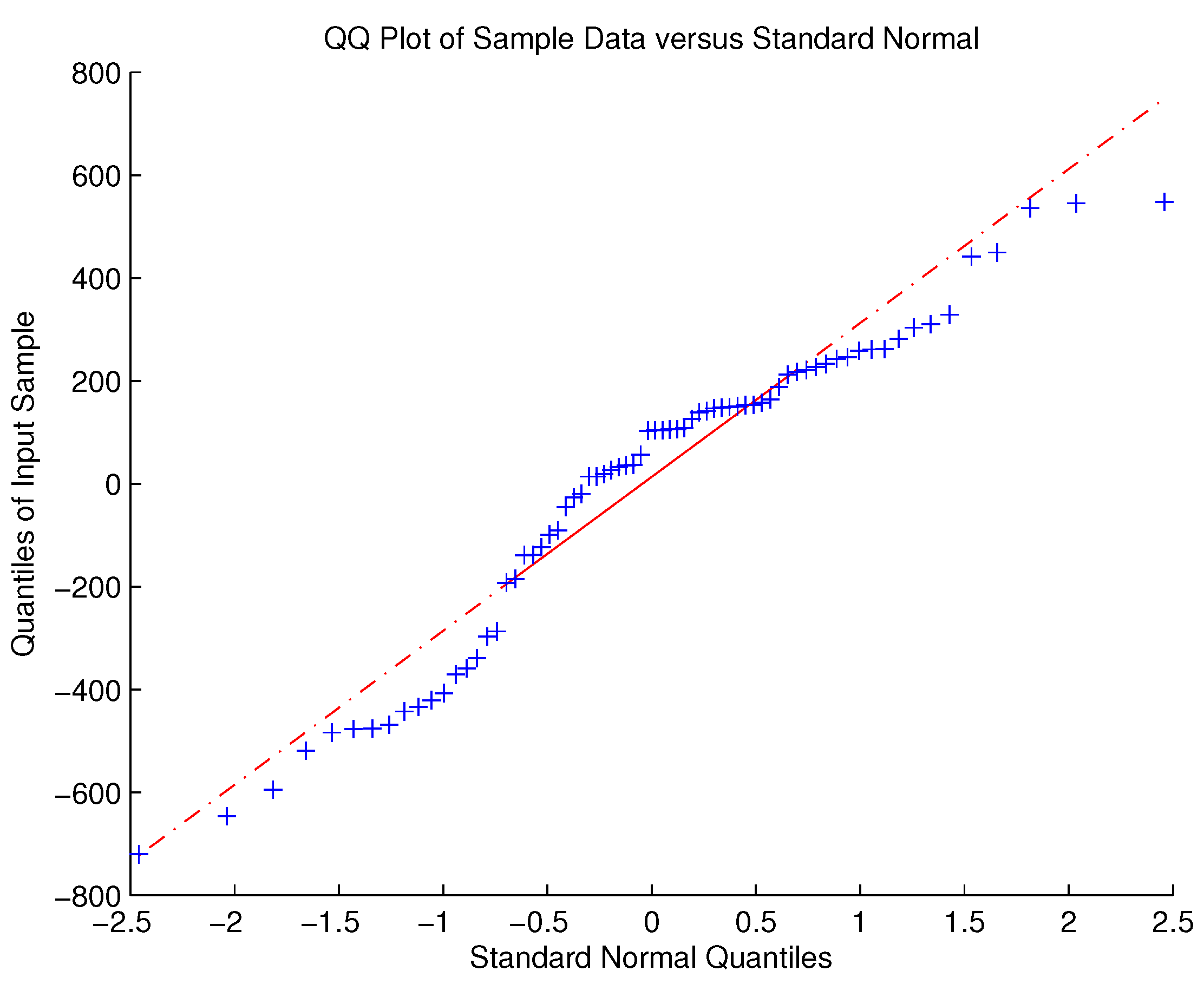
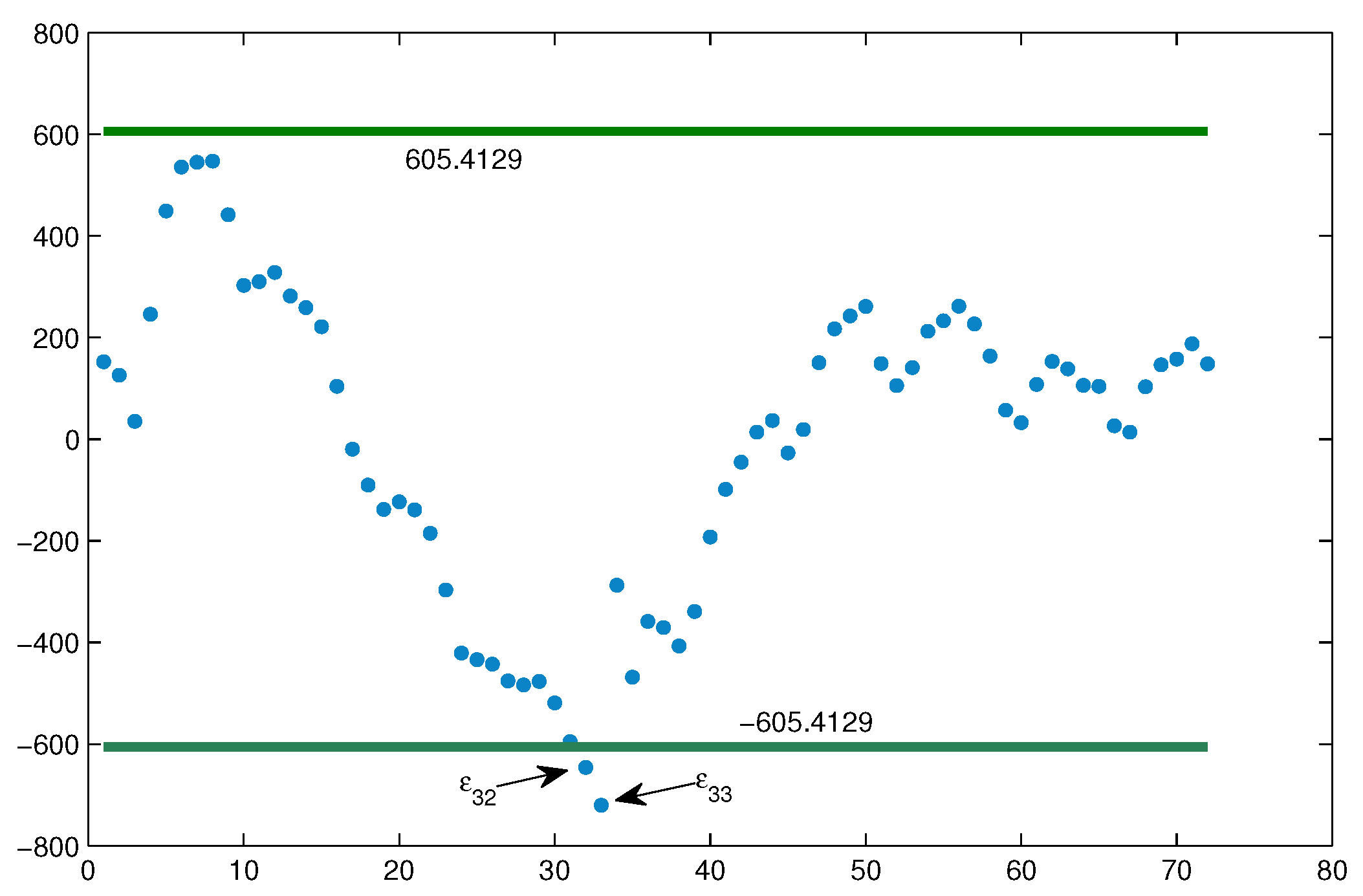
3.2. Parameter Estimation and Residual Analysis
3.3. Forecast
3.4. Uncertain Hypothesis Test
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yao, K.; Liu, B. Uncertain regression analysis: An approach for imprecise observations. Soft Comput. 2018, 22, 5579–5582. [Google Scholar] [CrossRef]
- Liu, B. (Ed.) Uncertain Statistics. In Uncertainty Theory, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 122–149. [Google Scholar]
- Liu, Z.; Yang, Y. Least absolute deviations estimation for uncertain regression with imprecise observations. Fuzzy Optim. Decis. Mak. 2020, 19, 33–52. [Google Scholar] [CrossRef]
- Chen, D. Tukeys biweight estimation for uncertain regression model with imprecise observations. Soft Comput. 2020, 24, 16803–16809. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Uncertain maximum likelihood estimation with application to uncertain regression analysis. Soft Comput. 2020, 24, 9351–9360. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Residual and confidence interval for uncertain regression model with imprecise observations. J. Intell. Fuzzy Syst. 2018, 35, 2573–2583. [Google Scholar] [CrossRef]
- Ye, T.; Liu, B. Uncertain hypothesis test with application to uncertain regression analysis. Fuzzy Optim. Decis. Mak. 2021. [Google Scholar] [CrossRef]
- Ye, T.; Liu, B. Uncertain significance test for regression coefficients with application to regional economic analysis. Tech. Rep. 2021. under review. [Google Scholar]
- Song, Y.; Fu, Z. Uncertain multivariable regression model. Soft Comput. 2018, 22, 5861–5866. [Google Scholar] [CrossRef]
- Ye, T.; Liu, Y. Multivariate uncertain regression model with imprecise observations. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4941–4950. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Z.; Liu, J. Least absolute deviations for uncertain multivariate regression model. Int. J. Gen. Syst. 2020, 49, 449–465. [Google Scholar] [CrossRef]
- Ding, J.; Zhang, Z. Statistical inference on uncertain nonparametric regression model. Fuzzy Optim. Decis. Mak. 2021. [Google Scholar] [CrossRef]
- Liu, Z.; Jia, L. Cross-validation for the uncertain Chapman-Richards growth model with imprecise observations. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2020, 28, 769–783. [Google Scholar] [CrossRef]
- Liu, S. Leave-p-Out Cross-Validation Test for Uncertain Verhulst-Pearl Model With Imprecise Observations. IEEE Access 2019, 7, 131705–131709. [Google Scholar] [CrossRef]
- Hu, Z.; Gao, J. Uncertain Gompertz regression model with imprecise observations. Soft Comput. 2020, 24, 2543–2549. [Google Scholar] [CrossRef]
- Fang, L.; Hong, Y. Uncertain revised regression analysis with responses of logarithmic, square root and reciprocal transformations. Soft Comput. 2020, 24, 2655–2670. [Google Scholar] [CrossRef]
- Chen, X.; Li, J.; Xiao, C.; Yang, P. Numerical solution and parameter estimation for uncertain SIR model with application to COVID-19. Fuzzy Optim. Decis. Mak. 2021, 20, 189–208. [Google Scholar] [CrossRef]
- Jia, L.; Chen, W. Uncertain SEIAR model for COVID-19 cases in China. Fuzzy Optim. Decis. Mak. 2021, 20, 243–259. [Google Scholar] [CrossRef]
- Liu, Z. Uncertain growth model for the cumulative number of COVID-19 infections in China. Fuzzy Optim. Decis. Mak. 2021, 20, 229–242. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Initial value estimation of uncertain differential equations and zero-day of COVID-19 spread in China. Fuzzy Optim. Decis. Mak. 2021, 20, 177–188. [Google Scholar] [CrossRef]
- Ye, T.; Yang, X. Analysis and prediction of confirmed COVID-19 cases in China with uncertain time series. Fuzzy Optim. Decis. Mak. 2021, 20, 209–228. [Google Scholar] [CrossRef]





{kind=link}
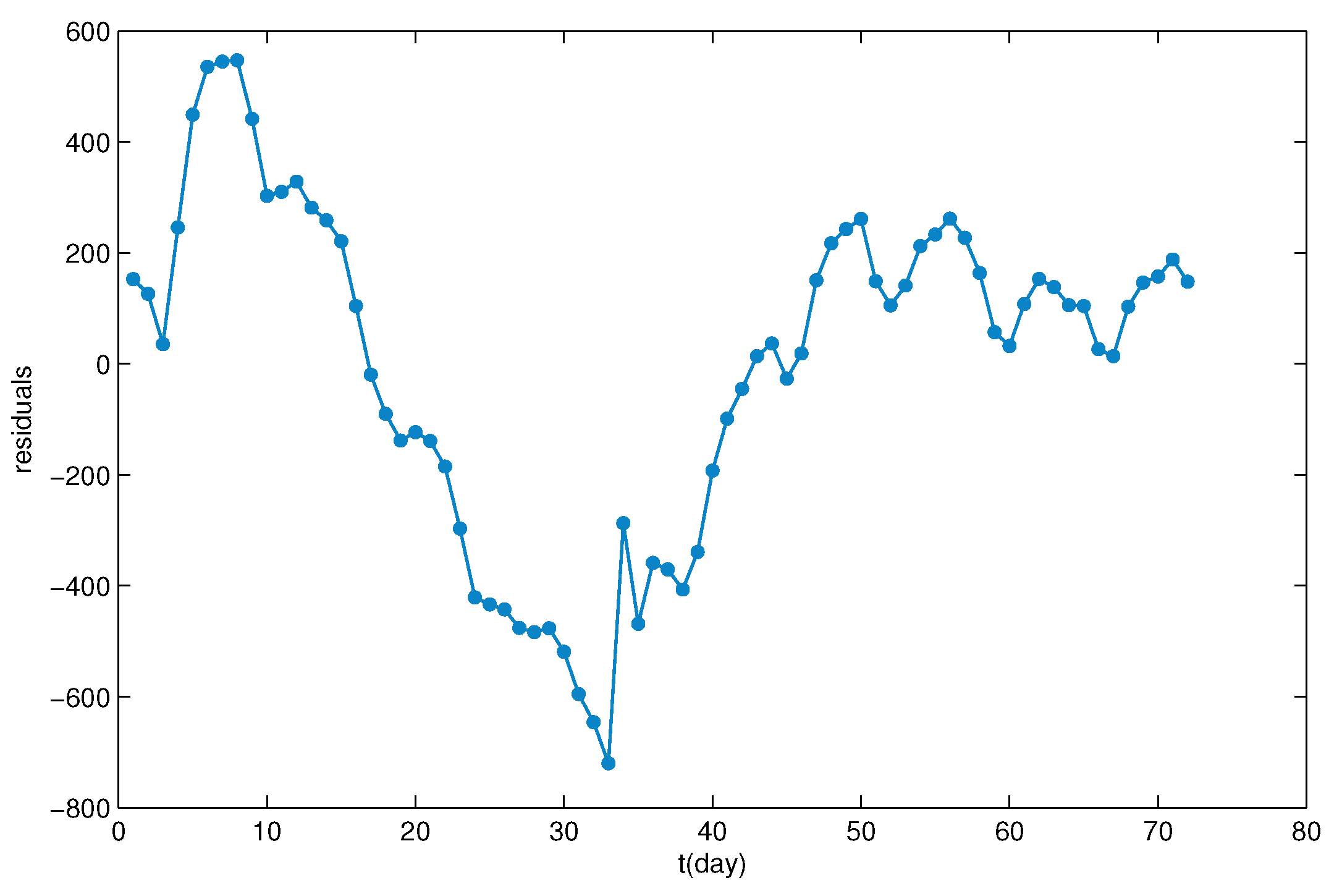{kind=link}
{kind=link}
{kind=link}
| 1,663,363 | 1,663,517 | 1,663,607 | 1,663,998 | 1,664,382 | 1,664,649 | 1,664,839 | 1,665,022 |
| 1,665,097 | 1,665,139 | 1,665,327 | 1,665,526 | 1,665,660 | 1,665,818 | 1,665,961 | 1,666,025 |
| 1,666,082 | 1,666,192 | 1,666,325 | 1,666,521 | 1,666,686 | 1,666,821 | 1,666,890 | 1,666,947 |
| 1,667,115 | 1,667,287 | 1,667,435 | 1,667,608 | 1,667,796 | 1,667,935 | 1,668,040 | 1,668,170 |
| 1,668,277 | 1,668,891 | 1,668,891 | 1,669,182 | 1,669,351 | 1,669,496 | 1,669,745 | 1,670,073 |
| 1,670,348 | 1,670,583 | 1,670,823 | 1,671,027 | 1,671,145 | 1,671,372 | 1,671,685 | 1,671,933 |
| 1,672,140 | 1,672,340 | 1,672,409 | 1,672,547 | 1,672,764 | 1,673,017 | 1,673,219 | 1,673,429 |
| 1,673,576 | 1,673,694 | 1,673,769 | 1,673,926 | 1,674,183 | 1,674,410 | 1,674,577 | 1,674,726 |
| 1,674,906 | 1,675,010 | 1,675,179 | 1,675,450 | 1,675,675 | 1,675,868 | 1,676,080 | 1,676,222 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Liu, W. Analysis and Prediction for Confirmed COVID-19 Cases in Czech Republic with Uncertain Logistic Growth Model. Symmetry 2021, 13, 2264. https://doi.org/10.3390/sym13122264
Ding C, Liu W. Analysis and Prediction for Confirmed COVID-19 Cases in Czech Republic with Uncertain Logistic Growth Model. Symmetry. 2021; 13(12):2264. https://doi.org/10.3390/sym13122264
Chicago/Turabian StyleDing, Chunxiao, and Wenjian Liu. 2021. "Analysis and Prediction for Confirmed COVID-19 Cases in Czech Republic with Uncertain Logistic Growth Model" Symmetry 13, no. 12: 2264. https://doi.org/10.3390/sym13122264
APA StyleDing, C., & Liu, W. (2021). Analysis and Prediction for Confirmed COVID-19 Cases in Czech Republic with Uncertain Logistic Growth Model. Symmetry, 13(12), 2264. https://doi.org/10.3390/sym13122264