
A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images

Abstract
:1. Introduction
- We add a residual structure in the backbone to alleviate the gradient disappearance problem and enhance the generalization performance of the backbone. To further improve the extraction capability of the backbone for fine-grained features, a simple attention module is used in the residual unit, without increasing the computational effort;
- We increase the number of down-sampling once (from the original 16-fold down-sampling process of UNet to 32-fold down-sampling) and use multi-head self-attention for the lowest level feature to rebuild the feature map and enhance the semantic representation of each feature point on the feature map. This improves the refinement of pixel segmentation between different categories;
- To solve the problem regarding multiple scales in different categories, we use a channel attention module and a spatial attention module in the feature fusion stage at different scales to better fuse the feature information of targets at different scales;
- To address the problem of unbalanced target categories among multiple categories, we use weighted cross-entropy loss (WCE loss) to ensure the model focuses more on categories with smaller sample sizes.
2. Methods
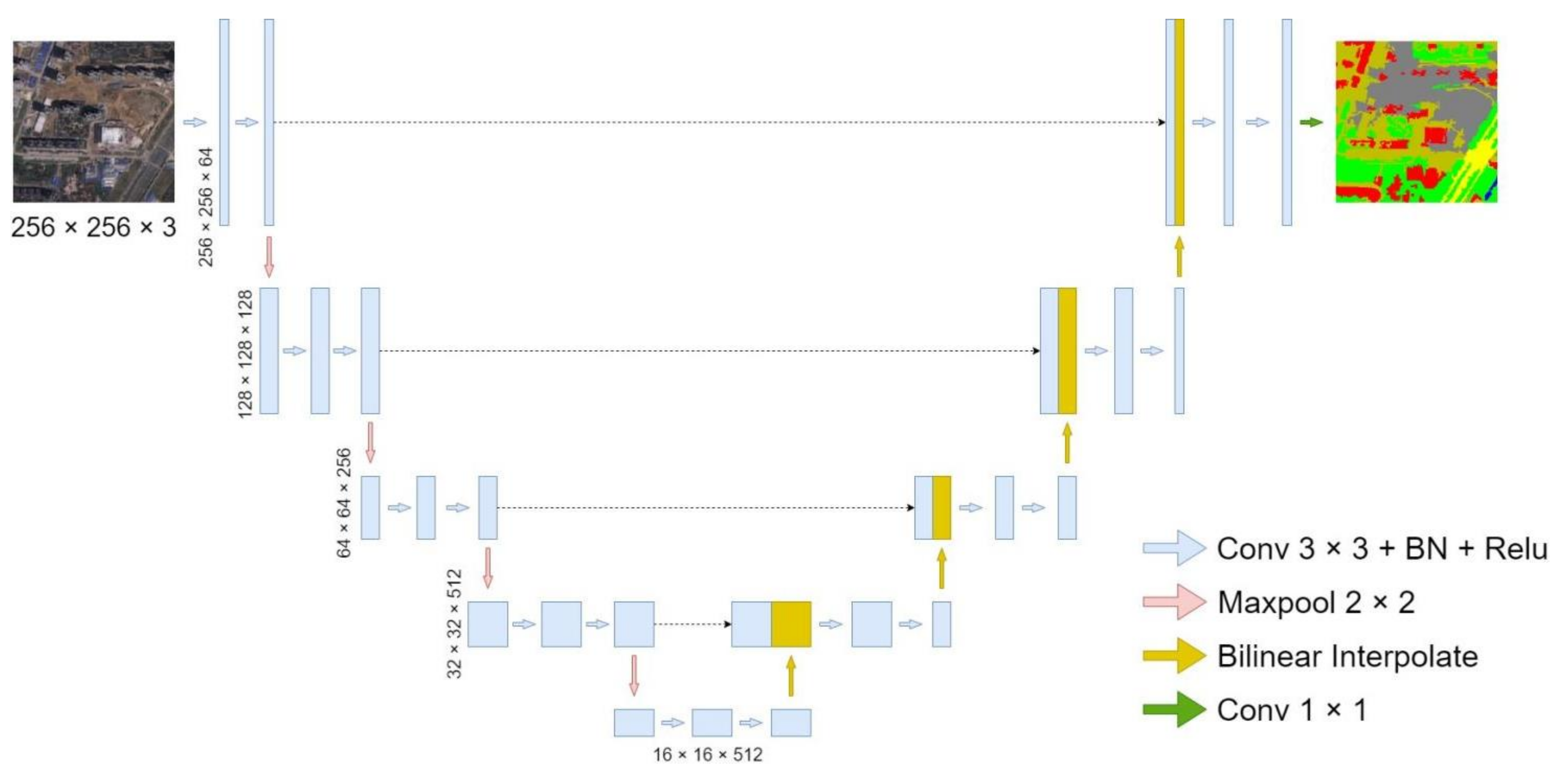
2.1. Structure of MA-UNet
2.2. Residual Encoder Based on Attention
- We obtain the feature space mean d based on the input feature map X, as shown in Equation (1);
- We find the variance of the feature map width and height in its channel direction based on the feature space mean d, as shown in Equation (2);
- We obtain the energy distribution of the feature map, as shown in Equation (3), where q is the energy factor;
- Finally, the enhanced feature map is obtained, as shown in Equation (4).
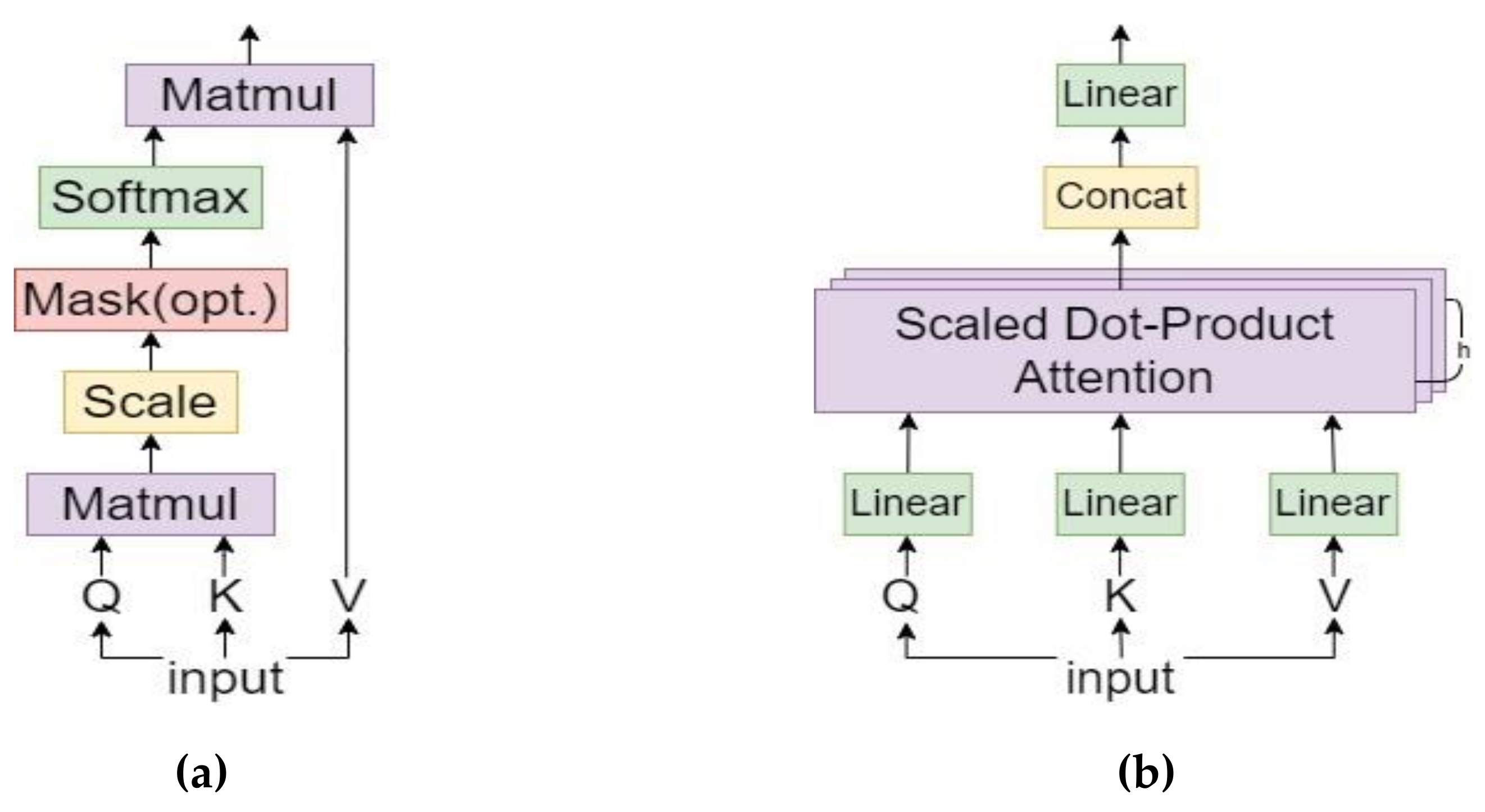
2.3. Feature Map Reconstruction Based on Multi-Head Self-Attention
2.4. Feature Fusion Based on Attention Enhancement
2.5. Improved Loss Function
3. Experiments and Results
3.1. Datasets
3.2. Evaluation Metrics
3.3. Experimental Design
3.4. Results and Analysis
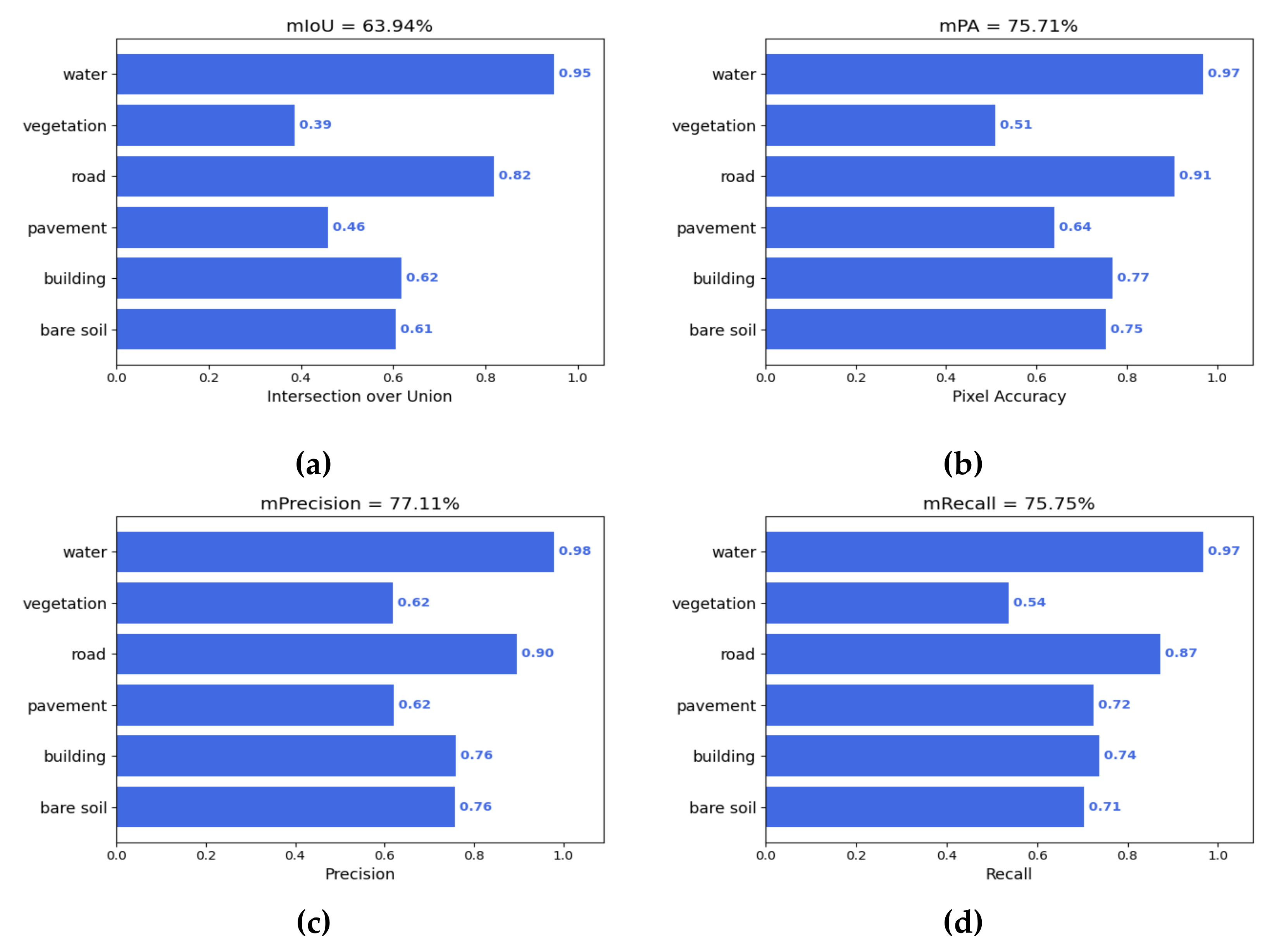
3.4.1. Experimental Results of MA-UNet
3.4.2. Results of the Comparison Experiment
3.4.3. Ablation Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhan, J.; Hu, Y.; Cai, W.; Zhou, G.; Li, L. PDAM–STPNNet: A Small Target Detection Approach for Wildland Fire Smoke through Remote Sensing Images. Symmetry 2021, 13, 2260. [Google Scholar] [CrossRef]
- Wang, S.; Sun, X.; Liu, P.; Xu, K.; Wu, C.; Wu, C. Research on Remote Sensing Image Matching with Special Texture Background. Symmetry 2021, 13, 1380. [Google Scholar] [CrossRef]
- Kai, Y.K.; Rajendran, P. A Descriptor-Based Advanced Feature Detector for Improved Visual Tracking. Symmetry 2021, 13, 1337. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A Dual-Attention Capsule U-Net for Road Extraction from Remote Sensing Imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Lei, S.; Zou, Z.; Liu, D. Sea-Land Segmentation for Infrared Remote Sensing Images based on Superpixels and Multi-scale Features. Infrared Phys. Technol. 2018, 91, 12–17. [Google Scholar] [CrossRef]
- Xi, C.; Yulong, G.; He, R. The Use of Remote Sensing to Quantitatively Assess the Visual Effect of Urban Landscape-A Case Study of Zhengzhou. China Remote Sens. 2022, 14, 203. [Google Scholar] [CrossRef]
- Shen, Y.; Ai, T.; Chen, H. Multilevel Mapping from Remote Sensing Images: A Case Study of Urban Buildings. IEEE Trans. Geosci. Remote Sens. 2021, 99, 1–16. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef] [Green Version]
- Goncalves, H.; Corte-Real, L.; Goncalves, J.A. Automatic Image Registration Through Image Segmentation and SIFT. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2589–2600. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Chen, D.R.; Shen, M.L. Watershed segmentation based on morphological gradient reconstruction. J. Optoelectron. Laser 2008. [Google Scholar]
- Blake, A.; Criminisi, A.; Cross, G. Image Segmentation of Foreground from Background Layers. US Patent US20100119147 A1, 2010. [Google Scholar]
- Radman, A.; Zainal, N.; Suandi, S.A. Automated segmentation of iris images acquired in an unconstrained environment using HOG-SVM and GrowCut. Digit. Signal Processing 2017, 64, 60–70. [Google Scholar] [CrossRef]
- Dong, C.; Liu, J.; Xu, F. Ship detection from optical remote sensing images using multi-scale analysis and Fourier HOG descriptor. Remote Sens. 2019, 11, 1529. [Google Scholar] [CrossRef] [Green Version]
- Qi, S.; Ma, J.; Lin, J. Unsupervised ship detection based on saliency and S-HOG descriptor from optical satellite images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. Comput. Sci. 2013. preprint. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Berlin, Germany, 2015. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Ye, H.; Jin, K. CT-UNet: Context-Transfer-UNet for Building Segmentation in Remote Sensing Images. Neural Processing Lett. 2021, 53, 4257–4277. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N. Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data. Remote Sens. 2021, 13, 3710. [Google Scholar] [CrossRef]
- Wang, S.; Chen, W.; Xie, S.M. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2017, 99, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Lin, S.; Ding, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Rahman; Siddiquee, M.M.; Tajbakhsh, N. Unet++: A Nested U-Net Architecture for Medical Image Segmentation. Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Chen, L.Y.; Yu, Q. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y. A Simple and Light-Weight Attention Module for Convolutional Neural Networks. Int. J. Comput. Vis. 2020, 128, 783–798. [Google Scholar] [CrossRef]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel “squeeze & excitation” in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2018; Springer: Cham, Switzerland, 2018; pp. 421–429. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel Remote Sensing Image Retrieval Based on Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Shao, Z.; Yang, K.; Zhou, W. Performance Evaluation of Single-Label and Multi-Label Remote Sensing Image Retrieval Using a Dense Labeling Dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Li, Y.; Shan, J.; Zhang, J.; Zhang, Y. Road Centerline Extraction in Complex Urban Scenes from LiDAR Data Based on Multiple Features. Geosci. Remote Sens. 2014, 52, 7448–7456. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhou, L.; Zhang, C.; Ming, W. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chi, M. SAFFNet: Self-Attention-Based Feature Fusion Network for Remote Sensing Few-Shot Scene Classification. Remote Sens. 2021, 13, 2532. [Google Scholar]
- Jiao, L. Attention-Guided Siamese Fusion Network for Change Detection of Remote Sensing Images. Remote Sens. 2021, 13, 4597. [Google Scholar]
- Bai, T.; Li, D.; Sun, K.; Chen, Y.; Li, W. Cloud Detection for High-Resolution Satellite Imagery Using Machine Learning and Multi-Feature Fusion. Remote Sensing 2016, 8, 715. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIOU (%) | mPA (%) | P (%) | R (%) |
|---|---|---|---|---|
| UNet | 59.67 | 72.52 | 74.00 | 71.92 |
| UNet++ | 62.07 | 75.16 | 76.32 | 74.83 |
| AttUNet | 61.54 | 74.35 | 75.18 | 73.39 |
| SegNet | 55.68 | 67.92 | 69.71 | 67.26 |
| PSPNet | 58.31 | 72.32 | 73.12 | 70.67 |
| DeepLabv3+ | 61.36 | 74.49 | 74.87 | 73.04 |
| MA-UNet(ours) | 63.94 | 75.71 | 77.11 | 75.75 |
| Method | mIOU (%) | mPA (%) | P (%) | R (%) |
|---|---|---|---|---|
| UNet | 56.17 | 71.11 | 68.46 | 72.52 |
| UNet++ | 60.29 | 75.80 | 73.27 | 72.93 |
| AttUNet | 59.62 | 76.13 | 74.84 | 72.29 |
| SegNet | 53.73 | 70.71 | 66.32 | 68.90 |
| PSPNet | 55.81 | 71.28 | 69.54 | 68.49 |
| DeepLabv3+ | 59.36 | 74.96 | 72.35 | 72.14 |
| MA-UNet(ours) | 61.90 | 76.72 | 75.47 | 74.96 |
| Exp1 | Exp2 | Exp3 | Exp4 | Exp5 | |
|---|---|---|---|---|---|
| Residual + simAM | √ | √ | √ | √ | |
| MSA | √ | √ | √ | ||
| SAM | √ | √ | |||
| CAM | √ | ||||
| mIOU (%) | 59.67 | 61.14 | 61.82 | 63.58 | 63.94 |
| Param (M) | 13.32 | 13.49 | 14.536 | 14.537 | 14.57 |
| Classes | Exp1 | Exp2 | Exp3 |
|---|---|---|---|
| Bare soil | 60.64 | 59.84 | 57.31 |
| Building | 61.82 | 62.37 | 60.87 |
| Pavement | 46.35 | 50.08 | 48.62 |
| Road | 81.61 | 80.44 | 80.22 |
| Vegetation | 38.55 | 43.02 | 40.36 |
| Water | 94.67 | 93.49 | 94.04 |
| mIOU (%) | 63.94 | 64.87 | 63.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Bi, F.; Gao, Y.; Chen, L.; Feng, S. A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images. Symmetry 2022, 14, 906. https://doi.org/10.3390/sym14050906
Sun Y, Bi F, Gao Y, Chen L, Feng S. A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images. Symmetry. 2022; 14(5):906. https://doi.org/10.3390/sym14050906
Chicago/Turabian StyleSun, Yu, Fukun Bi, Yangte Gao, Liang Chen, and Suting Feng. 2022. "A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images" Symmetry 14, no. 5: 906. https://doi.org/10.3390/sym14050906
APA StyleSun, Y., Bi, F., Gao, Y., Chen, L., & Feng, S. (2022). A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images. Symmetry, 14(5), 906. https://doi.org/10.3390/sym14050906