
Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies †

 , and
, and 
Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Problem Statement and Research Questions
- To what extent do specific contextual parameters impact the effectiveness of TL, in the context of time series forecasting tasks and endeavors;
- How the TL performance evolves in view of variations of certain contextual parameters and dimensions related, amongst others, to machine learning (ML)/neural network (NN) model types, the configuration of the ML model, the difference in distribution or distance between the source and target domains, the size of the lag and horizons for TSF, etc.;
- How to formulate recommendations on ML/NN model architectures and their subsequent TL-aware configurations and dimensioning in view of practical requirements with respect to low model complexity for better implementability on hardware platforms, etc.
2. A Comprehension Transfer Learning Performance Analysis Framework (RQ1)
2.1. Critical State-of-the-Art Review of TL Performance Metrics
2.2. Negative Transfer and Catastrophic Forgetting in Transfer Learning
2.3. Definition and Justification of Normalized Performance Metrics and Performance Assessment Scenarios
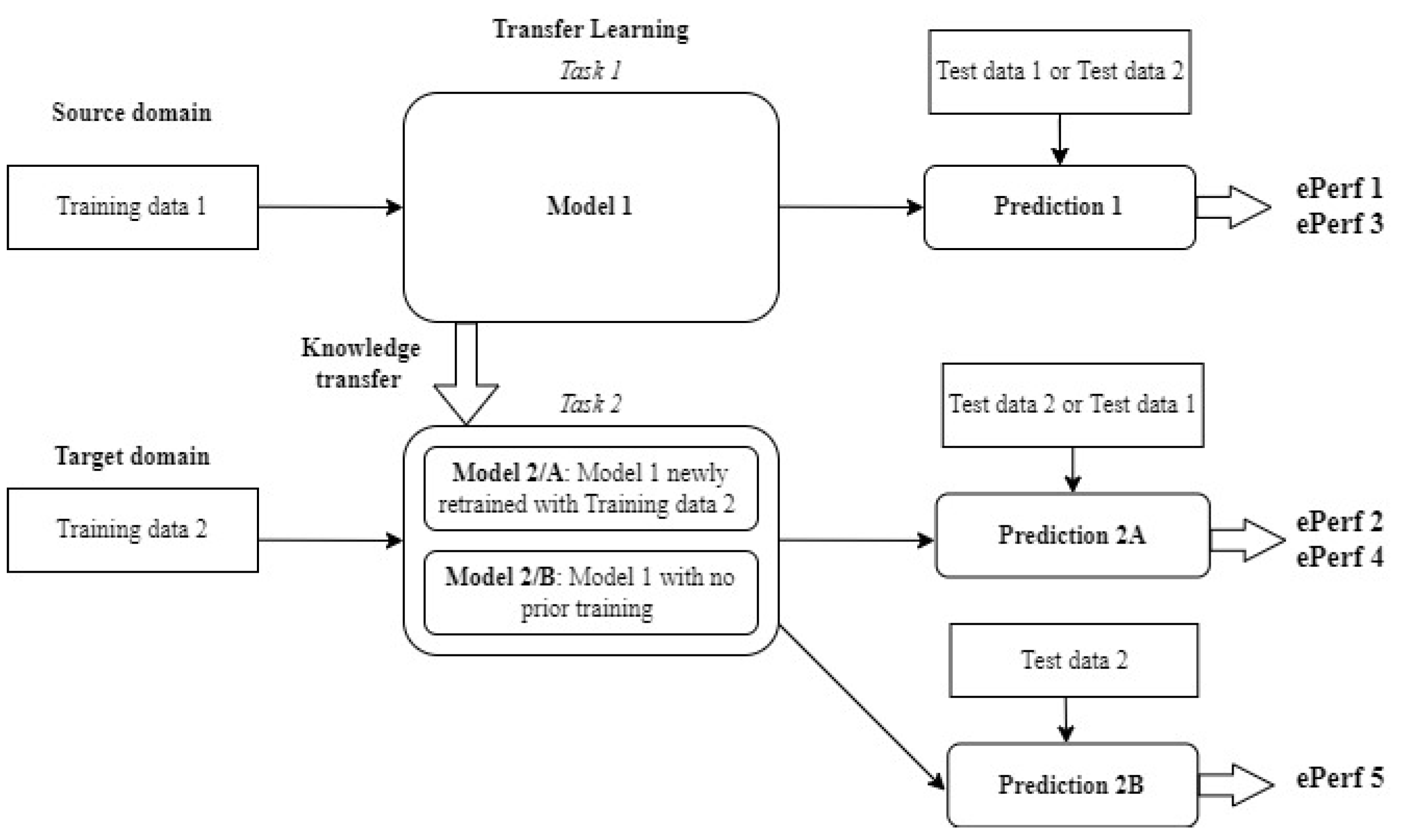
- Performance analysis scenario 1: In this scenario, Training Data 1 is used to train Model-1, and Test data 1 is used to make predictions with Model-1. The resulting performance of this scenario is termed .
- Performance analysis scenario 2: In this scenario, Training Data 2 is used to fine-tune, or to continue the training of, Model-1, which then becomes Model-2A. Then, Test data 2 is used to make predictions with Model-2A. The resulting performance of this scenario is termed .
- Performance analysis scenario 3: The only action in this scenario is Test data 2, which is used to make predictions with Model-1, which was trained in scenario 1. The resulting performance of this scenario is called .
- Performance analysis scenario 4: The only action in this scenario is that Test data 1 is used to make predictions with Model-2A, which was trained in scenario 2. The resulting performance of this scenario is called .
- Performance analysis scenario 5: In this scenario, Training Data 2 is used to train Model-2B, and Test data 2 is used to make predictions with Model-2B. The resulting performance of this scenario is termed .
2.4. Definition and Justification of Comprehensive TL Performance Metrics
3. Essential Elements of a Comprehensive TL-Related Sensitivity Analysis in the Context of Time Series Forecasting (RQ2)
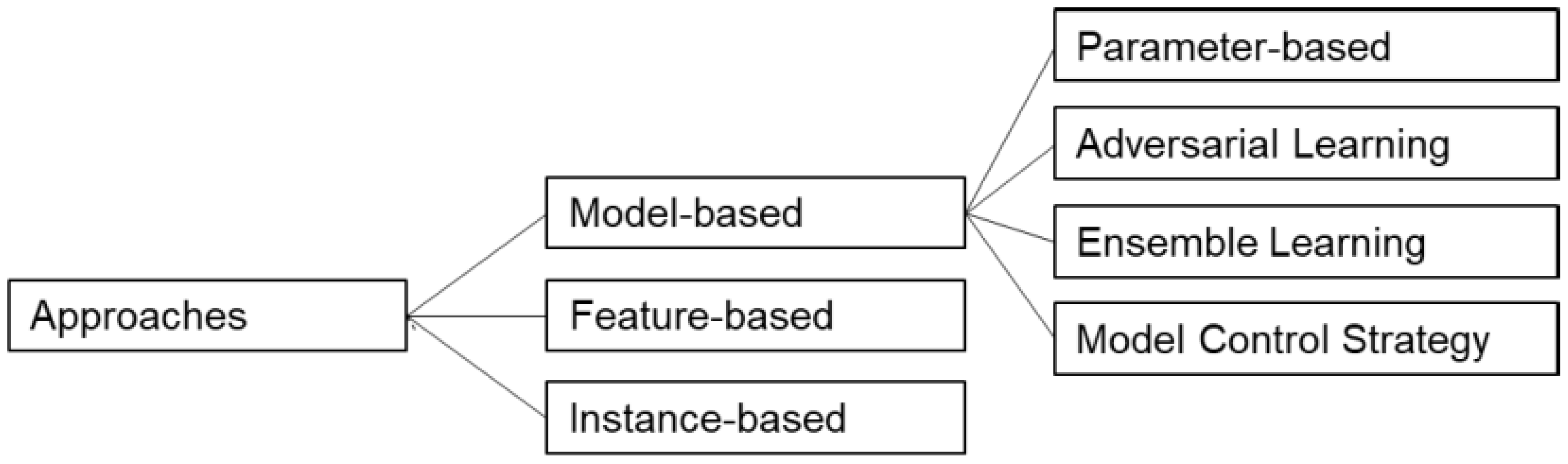
3.1. A Brief Survey of TL Techniques for TSF
3.1.1. Model-Based Transfer Learning
- Pre-training and fine-tuning approach: for the pre-training and fine-tuning approach, parameters from a model pre-trained on source data are either fully or partly employed to initialize a target model. This strategy aims to accelerate convergence during target training and enhance prediction accuracy and robustness. However, in many cases, all model parameters are reused for target training. A different but commonly used method involves transferring all weights to the target model except for the output layer, which is usually randomly initialized. Task adaptation is another aspect of fine-tuning [30]. Task adaptation, as a subcategory of transfer learning, involves adapting a pre-trained model to a new task that is related to the original task. The goal of task adaptation remains to improve the performance of the pre-trained model on the new task by leveraging the knowledge learned from the original task.
- Partial freezing:partial freezing is a special case of fine-tuning, which is also frequently used in transfer learning for time series. Used particularly for neural network-based transfer, only selected parts of the model are retrained instead of retraining the whole model during a fine-tuning procedure. The parameters of the frozen layers are taken from the source model. The other layers to be fine-tuned are either initialized with source parameters or trained from scratch. As you survey the literature, one finds that it is mostly the output layer that is retrained, while the rest of the network is used as a fixed feature extractor based on the source data [31,32]. However, other studies have tried different numbers of frozen layers and different combinations of frozen and trainable layers [33,34].
- Architecture modification: for the transfer learning process, some studies [35,36] have endeavored the architecture modification of the model used during source pre-training for subsequently being fine-tuned in the target domain. For example, modifications might entail either removing or incorporating certain layers in a deep learning model architecture. However, an intuitive approach can involve adding adaptation layers on top of the network that can only be trained with target data [35]. Moreover, for adaptation to a certain problem at hand, layers may also be added inside the existing layers of the source model [36].
- Domain-adversarial learning: this is another approach to transfer learning that can be used to adapt a model from one domain (the source domain) to another domain (the target domain) where the data distributions are different. Influenced by the generative adversarial network (GAN) [37] concept and borrowing the notion of incorporating two adversarial components within a deep neural network that engage in a zero-sum game to optimize each other, this approach has been gaining interest [38,39,40]. As shown in Figure 3, a deep adversarial neural network (DANN) comprises three elements: a feature encoder, a predictor, and a domain discriminator. The feature encoder is made of several layers that transform the data into a new feature representation, whereas the predictor carries out the prediction task based on the obtained features. Moreover, the domain discriminator, which is a binary classifier, utilizes the same features to predict the domain from which an input sample is drawn.
- Dedicated model objective: the concept underlying dedicated model objective is that, like in domain adversarial learning and unlike in model retraining, model objective functions, especially those dedicated to TL, allow using source and target data within a single training phase. Some studies that have investigated and applied this concept include [41,42,43].
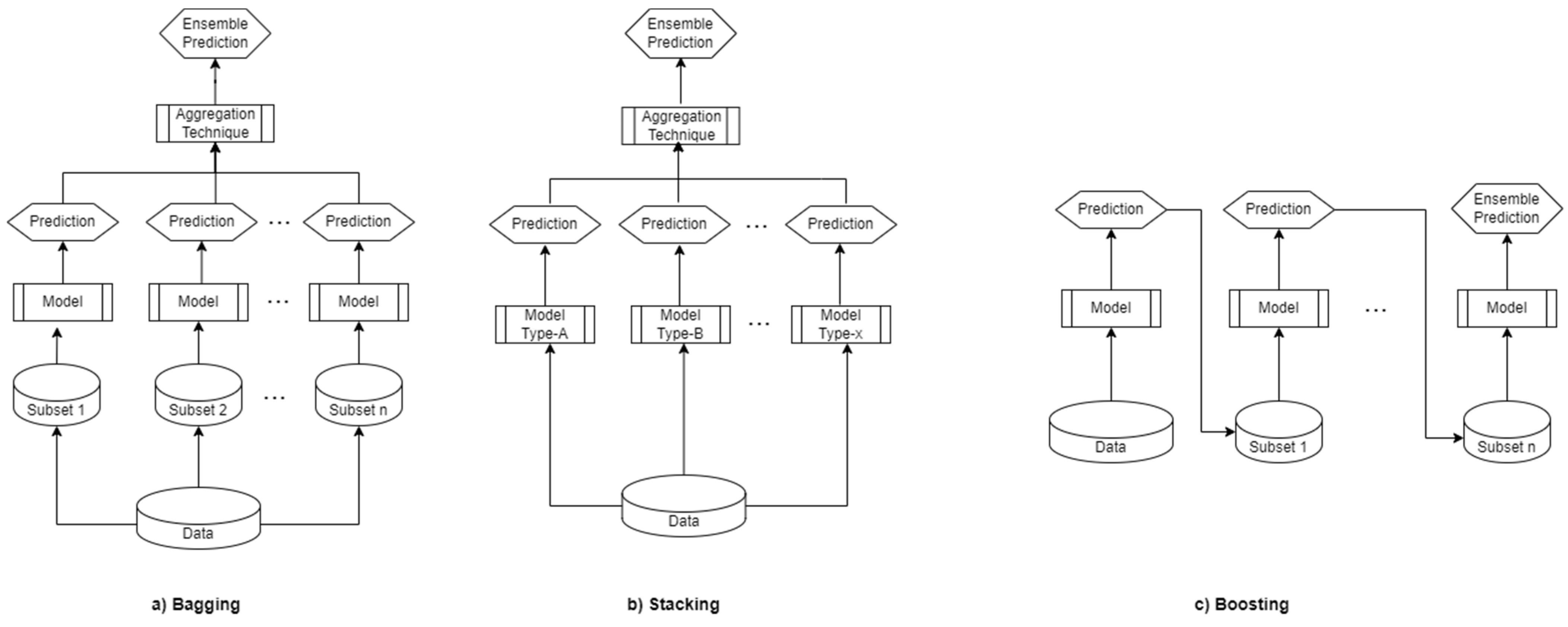
- Ensemble-based transfer learning: this is a TL approach that exploits the concept of ensemble learning. Ensemble learning involves the combination of multiple base learners, where each one is trained independently on a subset of the available data. Generally, the objective of ensemble learning is to lower generalization errors. There are various configurations of ensemble techniques, but the major ones are bagging, boosting, and stacking techniques. All these techniques are being used for transfer learning with time series. The reader may be interested in looking at [44,45,46]. By the way, the use case chosen for implementation in this study is an ensemble technique (see Section 5).
3.1.2. Feature-Based Transfer Learning
3.1.3. Instance-Based Transfer Learning
3.1.4. Hybrid Approaches
3.2. How Far Is the Developed TL Performance Analysis Framework Applicable to All the TSF TL Techniques
3.3. Background and Motivation for a Comprehensive TL Sensitivity Analysis
3.3.1. What Is Sensitivity Analysis?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transfer Learning Techniques Used in TSF | Some Sources | Applicability of the Developed TL Metrics |
|---|---|---|
| Model-based | ||
| Retraining | ||
| Pre-Training and Fine-Tuning | [30] | Yes |
| Partial Freezing | [31,34] | Yes |
| Architecture Modification | [35,36] | Yes |
| Joint training | ||
| Domain-Adversarial Learning | [38,39] | Yes |
| Dedicated Model Objective | [41,42] | Yes |
| Ensemble-based Transfer | [44,45] | Yes |
| Feature-based | ||
| Non-Neural Network-based | ||
| Feature Transformation | [3,10] | No |
| Neural Network Feature Learning | ||
| Auto-encoder-based feature learning | [50] | Maybe |
| Non-reconstruction-based feature learning | [51] | Maybe |
| Instance-based | ||
| Instance Selection | [53,54] | Yes |
| Hybrid | ||
| Temporary Freezing before Full Fine-Tuning | [8] | Yes |
| Ensemble Learning, and Feature Transformation | [60] | Maybe |
| Ensemble of Fine-Tuned Models | [57] | Yes |
| Ensemble of Fine-Tuned Autoencoders | [58] | Maybe |
| Autoencoders and Adversarial Learning | [38] | Maybe |
| Transformation of Encoded Data | [61] | Maybe |
| Instance Selection and Feature Transformation | [55] | Maybe |
| Instance Selection, Pre-Training, and Fine-Tuning | [54] | Yes |
3.3.2. Motivation for a Comprehensive TL Sensitivity Analysis: In General
3.3.3. Motivation for a Comprehensive TL Sensitivity Analysis: Specifically for TSF
3.3.4. Specification Book for a Comprehensive TSF TL Sensitivity Analysis
3.4. Critical Literature Review of Sensitivity Analysis Related to Transfer Learning
3.5. Comprehensive Identification, Justification, and Explanation of All the Relevant TSF Related TL SA Contextual Dimensions
3.5.1. Contextual Dimensions Related to the ML/NN Model
- Source model architecture: the architecture of the pre-trained model can greatly influence transfer learning. The choice needs to be ideally aligned with the complexity and nature of the new task.
- The depth of the network architecture. This is the number of hidden layers considered for the model.
- The width of the network architecture. This is the number of neurons in the various hidden layers of the model.
- The model’s transferred layers: based on the first three parameters mentioned above, the number of layers, also referred to as backbone parameters, can influence the performance of the transfer learning. The choice is to transfer all layers or only a subset of layers from the source model. In many cases, the higher-level features of deep networks are more task-specific, meaning that when adapting to a new task, only the first layers (which capture general features) may be transferable.
- Hyperparameters: the setting of adjustable hyperparameters is pivotal to the performance of transfer learning. Key hyperparameters to watch during transfer learning include learning rate, batch size, and number of epochs.
3.5.2. Contextual Dimensions Related to the TSF Input/Output Modeling
- The lag of the time series forecasting task (number of historical points in the past).
- The horizon of the time series forecasting task (the number of points in the future to forecast).
- Eventually, the formulation of the time series forecasting task, as a univariate or a multivariate, can also impact the performance of transfer learning. Univariate time series forecasting is generally simpler than multivariate time series forecasting because it involves only predicting the future values of a single variable. As a result, transfer learning is often more effective in univariate time series forecasting. However, this assertion needs to be demonstrated empirically through an appropriate sensitivity analysis.
3.5.3. Contextual Dimensions Related to the Source-Target Domains Distribution and Distance Characteristics
- Domain (dataset) characterization: This refers to determining the (dis)similarity between the domains. For instance, in the case of time series, we can compute (evaluate) the Pearson or DTW distance [20], the degree of non-linearity of the time series [70], the degree of homogeneity of the time series [71], and/or the degree of unpredictability [72].
- Data size: The size of the source and target datasets also affects the performance of transfer learning [73]. A larger source dataset will typically lead to better performance, as it provides the model with more information to learn from. However, it is also important to have a sufficient amount of labeled data in the target domain, as this is what the model will be fine-tuned on.
- Data distribution: It is essential to consider the similarity between the source and target data distributions [21] by computing the maximum mean discrepancy (MMD) between the two domains. If the data distributions are too different, the model may not be able to generalize well to the target domain. In this case, domain adaptation techniques may be necessary.
- Data quality: The quality of both the source and target datasets is important for transfer learning. High-quality data with good labeling will help the model learn more effectively and generalize better to the target domain.
3.5.4. Contextual Dimensions Related to the TL Technique
- What to transfer: This refers to which part of the knowledge can be transferred from the source to the target in order to improve the performance of the target task. In short, this has to do with the approach of transfer learning, whether model-based, feature-based, instance-based, or hybrid-based.
- How to transfer: This refers to the design of the transfer learning algorithm.
3.5.5. Contextual Dimensions Related to Robustness to Adversarial Noise
4. A Brief Discussion of the Ensemble Learning Techniques
5. Implementation of the Ensemble Transfer Learning Sensitivity Analysis: A Use Case (RQ3 and RQ4)
5.1. Dimensions and Parameters to Be Considered in a Comprehensive Ensemble TL Sensitivity Analysis
5.2. Selected Dimensions and Parameters Considered for Implementation as a Proof of Concept
5.3. Presentation of the Datasets and Network Parameters
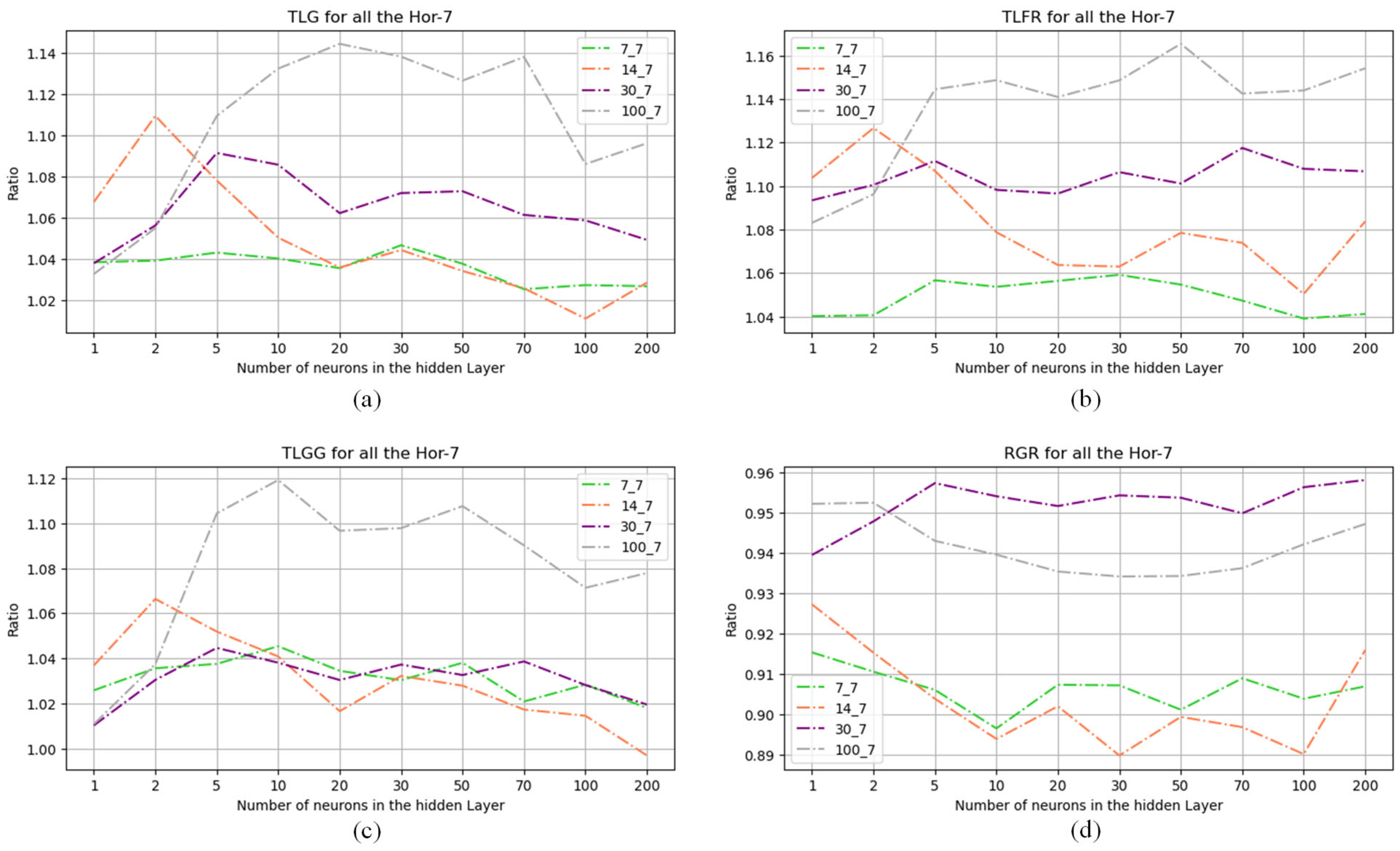
5.4. Results Discussion
5.5. Assessment of the Use Case According to the Specification Book for a Comprehensive TSF TL Sensitivity Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep learning for time series forecasting: A survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef]
- Boyko, N. Data Interpretation Algorithm for Adaptive Methods of Modeling and Forecasting Time Series. WSEAS Trans. Math. 2023, 22, 359–372. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Amaral, T.; Silva, L.M.; Alexandre, L.A.; Kandaswamy, C.; de Sá, J.M.; Santos, J.M. Transfer Learning Using Rotated Image Data to Improve Deep Neural Network Performance. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; Springer: Cham, Switzerland, 2014; pp. 290–300. [Google Scholar]
- Vu, N.T.; Imseng, D.; Povey, D.; Motlicek, P.; Schultz, T.; Bourlard, H. Multilingual deep neural network based acoustic modeling for rapid language adaptation. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7639–7643. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- He, Q.Q.; Pang, P.C.I.; Si, Y.W. Transfer learning for financial time series forecasting. In PRICAI 2019: Trends in Artificial Intelligence: 16th Pacific Rim International Conference on Artificial Intelligence, Cuvu, Yanuca Island, Fiji, 26–30 August 2019; Springer: Cham, Switzerland, 2019; Volume 2, pp. 24–36. [Google Scholar]
- Mensink, T.; Uijlings, J.; Kuznetsova, A.; Gygli, M.; Ferrari, V. Factors of Influence for Transfer Learning Across Diverse Appearance Domains and Task Types. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9298–9314. [Google Scholar] [CrossRef]
- Weber, M.; Auch, M.; Doblander, C.; Mandl, P.; Jacobsen, H.-A. Transfer Learning with Time Series Data: A Systematic Mapping Study. IEEE Access 2021, 9, 165409–165432. [Google Scholar] [CrossRef]
- Yan, P.; Abdulkadir, A.; Rosenthal, M.; Schatte, G.A.; Grewe, B.F.; Stadelmann, T. A comprehensive survey of deep transfer learning for anomaly detection in industrial time series: Methods, applications, and directions. arXiv 2023, arXiv:2307.05638. [Google Scholar] [CrossRef]
- Kumar, J.S.; Anuar, S.; Hassan, N.H. Transfer Learning based Performance Comparison of the Pre-Trained Deep Neural Networks. Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Wang, B.; Mendez, J.; Cai, M.; Eaton, E. Transfer learning via minimizing the performance gap between domains. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Weiss, K.R.; Khoshgoftaar, T.M. Analysis of transfer learning performance measures. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 338–345. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Willard, J.D.; Read, J.S.; Appling, A.P.; Oliver, S.K.; Jia, X.; Kumar, V. Predicting Water Temperature Dynamics of Unmonitored Lakes with Meta-Transfer Learning. Water Resour. Res. 2021, 57, e2021WR029579. [Google Scholar] [CrossRef]
- Gaddipati, S.K.; Nair, D.; Plöger, P.G. Comparative evaluation of pretrained transfer learning models on automatic short answer grading. arXiv 2020, arXiv:2009.01303. [Google Scholar]
- Bao, Y.; Li, Y.; Huang, S.-L.; Zhang, L.; Zheng, L.; Zamir, A.; Guibas, L. An Information-Theoretic Approach to Transferability in Task Transfer Learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2309–2313. [Google Scholar]
- Ben-David, S.; Schuller, R. Exploiting Task Relatedness for Multiple Task Learning; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 567–580. [Google Scholar]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer Learning with Dynamic Distribution Adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–25. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, L.; Zhang, L.; Wu, D. A Survey on Negative Transfer. IEEE/CAA J. Autom. Sin. 2022, 10, 305–329. [Google Scholar] [CrossRef]
- Kemker, R.; McClure, M.; Abitino, A.; Hayes, T.; Kanan, C. Measuring Catastrophic Forgetting in Neural Networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Abraham, W.C.; Robins, A. Memory retention—The synaptic stability versus plasticity dilemma. Trends Neurosci. 2005, 28, 73–78. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Fu, B.; Long, M.; Wang, J. Catastrophic forgetting meets negative transfer: Batch spectral shrinkage for safe transfer learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Mahmoud, R.A.; Hajj, H. Multi-objective Learning to Overcome Catastrophic Forgetting in Time-series Applications. ACM Trans. Knowl. Discov. Data 2022, 16, 1–20. [Google Scholar] [CrossRef]
- Ge, L.; Gao, J.; Ngo, H.; Li, K.; Zhang, A. On Handling Negative Transfer and Imbalanced Distributions in Multiple Source Transfer Learning. Stat. Anal. Data Min. ASA Data Sci. J. 2014, 7, 254–271. [Google Scholar] [CrossRef]
- Niu, S.; Liu, Y.; Wang, J.; Song, H. A decade survey of transfer learning (2010–2020). IEEE Trans. Artif. Intell. 2020, 1, 151–166. [Google Scholar] [CrossRef]
- Peirelinck, T.; Kazmi, H.; Mbuwir, B.V.; Hermans, C.; Spiessens, F.; Suykens, J.; Deconinck, G. Transfer learning in demand response: A review of algorithms for data-efficient modelling and control. Energy AI 2021, 7, 100126. [Google Scholar] [CrossRef]
- Zhang, R.; Tao, H.; Wu, L.; Guan, Y. Transfer Learning with Neural Networks for Bearing Fault Diagnosis in Changing Working Conditions. IEEE Access 2017, 5, 14347–14357. [Google Scholar] [CrossRef]
- Kearney, D.; McLoone, S.; Ward, T.E. Investigating the Application of Transfer Learning to Neural Time Series Classification. In Proceedings of the 2019 30th Irish Signals and Systems Conference (ISSC), Maynooth, Ireland, 17–18 June 2019; pp. 1–5. [Google Scholar]
- Fan, C.; Sun, Y.; Xiao, F.; Ma, J.; Lee, D.; Wang, J.; Tseng, Y.C. Statistical investigations of transfer learning-based methodology for short-term building energy predictions. Appl. Energy 2020, 262, 114499. [Google Scholar] [CrossRef]
- Taleb, C.; Likforman-Sulem, L.; Mokbel, C.; Khachab, M. Detection of Parkinson’s disease from handwriting using deep learning: A comparative study. Evol. Intell. 2020, 16, 1813–1824. [Google Scholar] [CrossRef]
- Marczewski, A.; Veloso, A.; Ziviani, N. Learning transferable features for speech emotion recognition. In Proceedings of the Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 529–536. [Google Scholar]
- Mun, S.; Shon, S.; Kim, W.; Han, D.K.; Ko, H. Deep Neural Network based learning and transferring mid-level audio features for acoustic scene classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 796–800. [Google Scholar]
- Matsui, S.; Inoue, N.; Akagi, Y.; Nagino, G.; Shinoda, K. User adaptation of convolutional neural network for human activity recognition. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 753–757. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Proc. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2015, 17, 2030–2096. [Google Scholar] [CrossRef]
- Tang, Y.; Qu, A.; Chow, A.H.; Lam, W.H.; Wong, S.C.; Ma, W. Domain adversarial spatial-temporal network: A transferable framework for short-term traffic forecasting across cities. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 1905–1915. [Google Scholar]
- Chen, L.; Peng, C.; Yang, C.; Peng, H.; Hao, K. Domain adversarial-based multi-source deep transfer network for cross-production-line time series forecasting. Appl. Intell. 2023, 53, 22803–22817. [Google Scholar] [CrossRef]
- Hernandez, J.; Morris, R.R.; Picard, R.W. Call Center Stress Recognition with Person-Specific Models. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Memphis, TN, USA, 9–12 October 2011; pp. 125–134. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.-Q. Multi-Layer domain adaptation method for rolling bearing fault diagnosis. Signal Process. 2018, 157, 180–197. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Shen, C. A New Deep Transfer Learning Method for Bearing Fault Diagnosis Under Different Working Conditions. IEEE Sens. J. 2019, 20, 8394–8402. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, C.; Jiang, J. A deep learning and ensemble learning based architecture for metro passenger flow forecast. IET Intell. Transp. Syst. 2023, 17, 487–502. [Google Scholar] [CrossRef]
- Dai, W.; Yang, Q.; Xue, G.-R.; Yu, Y. Boosting for transfer learning. In Proceedings of the ICML ‘07 & ILP ‘07: The 24th Annual International Conference on Machine Learning held in conjunction with the 2007 International Conference on Inductive Logic Programming, Corvallis, OR, USA, 19–21 June 2007; pp. 193–200. [Google Scholar]
- Deo, R.V.; Chandra, R.; Sharma, A. Stacked transfer learning for tropical cyclone intensity prediction. arXiv 2017, arXiv:1708.06539. [Google Scholar]
- Daumé, H., III. Frustratingly easy domain adaptation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 256–263. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing (EMNLP), Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse Autoencoder-Based Feature Transfer Learning for Speech Emotion Recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Banerjee, D.; Islam, K.; Mei, G.; Xiao, L.; Zhang, G.; Xu, R.; Ji, S.; Li, J. A Deep Transfer Learning Approach for Improved Post-Traumatic Stress Disorder Diagnosis. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New orleans, LA, USA, 18–21 November 2017; pp. 11–20. [Google Scholar]
- Wang, T.; Huan, J.; Zhu, M. Instance-based deep transfer learning. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 367–375. [Google Scholar]
- Kim, J.; Lee, J. Instance-based transfer learning method via modified domain-adversarial neural network with influence function: Applications to design metamodeling and fault diagnosis. Appl. Soft Comput. 2022, 123, 108934. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, Y.; Liu, L.; Zhang, W.; Zhang, J. Cross-Subject EEG Feature Selection for Emotion Recognition Using Transfer Recursive Feature Elimination. Front. Neurorobot. 2017, 11, 19. [Google Scholar] [CrossRef]
- Villar, J.R.; de la Cal, E.; Fañez, M.; González, V.M.; Sedano, J. Usercentered fall detection using supervised, on-line learning and transfer learning. Prog. Artif. Intell. 2019, 8, 453–474. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Shen, S.; Sadoughi, M.; Li, M.; Wang, Z.; Hu, C. Deep convolutional neural networks with ensemble learning and transfer learning for capacity estimation of lithium-ion batteries. Appl. Energy 2020, 260, 114296. [Google Scholar] [CrossRef]
- Di, Z.; Shao, H.; Xiang, J. Ensemble deep transfer learning driven by multisensor signals for the fault diagnosis of bevel-gear cross-operation conditions. Sci. China Technol. Sci. 2021, 64, 481–492. [Google Scholar] [CrossRef]
- Ingalls, B. Sensitivity analysis: From model parameters to system behaviour. Essays Biochem. 2008, 45, 177–194. [Google Scholar] [CrossRef]
- Tu, W.; Sun, S. A subject transfer framework for EEG classification. Neurocomputing 2012, 82, 109–116. [Google Scholar] [CrossRef]
- Natarajan, A.; Angarita, G.; Gaiser, E.; Malison, R.; Ganesan, D.; Marlin, B.M. Domain adaptation methods for improving lab-to-field generalization of cocaine detection using wearable ECG. In Proceedings of the UbiComp ‘16: The 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 875–885. [Google Scholar]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 29. [Google Scholar] [CrossRef]
- Ritter, H.; Botev, A.; Barber, D. Online structured laplace approximations for overcoming catastrophic forgetting. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Peng, J.; Hao, J.; Li, Z.; Guo, E.; Wan, X.; Min, D.; Zhu, Q.; Li, H. Overcoming Catastrophic Forgetting by Soft Parameter Pruning. arXiv 2018, arXiv:1812.01640. [Google Scholar]
- Solak, A.; Ceylan, R. A sensitivity analysis for polyp segmentation with U-Net. Multimed. Tools Appl. 2023, 82, 34199–34227. [Google Scholar] [CrossRef]
- . Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Yu, P.S. Adaptation Regularization: A General Framework for Transfer Learning. IEEE Trans. Knowl. Data Eng. 2013, 26, 1076–1089. [Google Scholar] [CrossRef]
- . Abbas, A.; Abdelsamea, M.M.; Gaber, M.M. DeTrac: Transfer Learning of Class Decomposed Medical Images in Convolutional Neural Networks. IEEE Access 2020, 8, 74901–74913. [Google Scholar] [CrossRef]
- . Guo, H.; Zhuang, X.; Chen, P.; Alajlan, N.; Rabczuk, T. Analysis of three-dimensional potential problems in non-homogeneous media with physics-informed deep collocation method using material transfer learning and sensitivity analysis. Eng. Comput. 2022, 38, 5423–5444. [Google Scholar] [CrossRef]
- Tsay, R.S. Nonlinearity tests for time series. Biometrika 1986, 73, 461–466. [Google Scholar] [CrossRef]
- Whitcher, B.; Byers, S.D.; Guttorp, P.; Percival, D.B. Testing for homogeneity of variance in time series: Long memory, wavelets, and the Nile River. Water Resour. Res. 2002, 38, 12-1–12-16. [Google Scholar] [CrossRef]
- Golestani, A.; Gras, R. Can we predict the unpredictable? Sci. Rep. 2014, 4, 6834. [Google Scholar] [CrossRef] [PubMed]
- Soekhoe, D.; Van Der Putten, P.; Plaat, A. On the impact of data set size in transfer learning using deep neural networks. In Proceedings of the Advances in Intelligent Data Analysis XV: 15th International Symposium, IDA 2016, Stockholm, Sweden, 13–15 October 2016; Proceedings 15. Springer International Publishing: Cham, Switzerland, 2016; pp. 50–60. [Google Scholar]
- Liu, A.; Liu, X.; Yu, H.; Zhang, C.; Liu, Q.; Tao, D. Training Robust Deep Neural Networks via Adversarial Noise Propagation. IEEE Trans. Image Process. 2021, 30, 5769–5781. [Google Scholar] [CrossRef] [PubMed]
- Cisse, M.; Bojanowski, P.; Grave, E.; Dauphin, Y.; Usunier, N. Parseval networks: Improving robustness to adversarial examples. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Chin, T.W.; Zhang, C.; Marculescu, D. Renofeation: A simple transfer learning method for improved adversarial robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3243–3252. [Google Scholar]
- Deng, Z.; Zhang, L.; Vodrahalli, K.; Kawaguchi, K.; Zou, J.Y. Adversarial training helps transfer learning via better representations. Adv. Neural Inf. Process. Syst. 2021, 34, 25179–25191. [Google Scholar]
- Littlestone, N.; Warmuth, M. The Weighted Majority Algorithm. Comput. Eng. Inf. Sci. 1994, 108, 212–261. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Duin, R. The combining classifier: To train or not to train? In Proceedings of the 16th International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; pp. 765–770. [Google Scholar]









| Performance Analysis Scenario | Model | Training | Test | Performance Metric |
|---|---|---|---|---|
| Scenario 1 | Model 1 | Training data 1 | Test data 1 | ePerf1 |
| Scenario 2 | Model 2/A | Training data 2 | Test data 2 | ePerf2 |
| Scenario 3 | Model 1 | Training data 1 | Test data 2 | ePerf3 |
| Scenario 4 | Model 2/A | Training data 2 | Test data 1 | ePerf4 |
| Scenario 5 | Model 2/B | Training data 2 | Test data 2 | ePerf5 |
| Type of Transfer Learning | What Is Transferred |
|---|---|
| Model-based | Parameters of a pre-trained model |
| Feature-based | Features learned by a pre-trained model |
| Instance-based | Training examples from the source domain |
| Requirement | Explanation of the Requirement |
|---|---|
| Source model | A pre-trained model is required to serve as the source model for the transfer learning process. The source model should be trained on a related task or domain to the target task or domain. |
| Data | Sufficient data are required for both the source and target tasks. The source task should have a large amount of labeled data, while the target task may have limited labeled data. |
| Similarity | There should be some similarity between the source and target tasks or domains. The more similar they are, the more effective the transfer learning process will be. |
| TL design (layer selection) | A TL design needs to be determined beforehand. For neural networks, the selection of which layers to update and which to fix is an important consideration in transfer learning. The choice of layers will depend on the specific task and data. |
| Hyperparameter tuning | Hyperparameters such as learning rate, batch size, and number of epochs need to be tuned to optimize the performance of the transfer learning model. |
| Evaluation metrics | Appropriate evaluation metrics need to be selected to measure the performance of the transfer learning model. The choice of metrics will depend on the specific task and data. |
| Baseline model | Establish baseline models, either trained from scratch or using other transfer learning techniques, to compare and contrast the performance |
| Computational requirements | Define the acceptable computational time and resources for the transfer learning process. The efficiency of transfer learning is often a consideration, especially when deployment resources are constrained. |
| Model robustness | Define requirements for the model’s stability and robustness against adversarial attacks, noise, or other perturbations, especially in critical applications |
| Negative transfer avoidance | Put mechanisms in place to detect or avoid negative transfer, where transfer learning leads to degraded performance. |
| Reproducibility | The evaluation process should be reproducible. This might involve requirements about documentation, random seed settings, or the clarity of the process and methods used. |
| Parameters | Configuration |
|---|---|
| Ensemble technique used | Bagging |
| Number of ensemble instances | 4 |
| Type of neural network | MLP |
| Number of hidden layers | 1 (shallow network) |
| Number of neurons | 1, 2, 5, 10, 20, 30, 50, 70, 100, and 200 |
| Lag size and horizon size | (7, 1), (14, 1), (30, 1), (100, 1) (7, 7), (14, 7), (30, 7), and (100, 7) |
| Evaluation metrics | TLG, TLFR, RGR, and TLGG (defined in Section 2.4) |
| (Dis)similarity metrics to assess the distance between source and target domains | Pearson, DTW |
| Requirement | Assessment of the Use Case |
|---|---|
| Source model | A source model was pre-trained for later use in the target domain. |
| Data | Sufficient data were available to train the source model. |
| Similarity | The calculated Pearson distance between the source and target datasets (PD = 0.9105) shows a degree of similarity between the source and target domains. |
| TL design (layer selection) | In this case, a shallow MLP was used. |
| Hyperparameter tuning | Hyperparameters (learning rate, batch size, and number of epochs) were set to optimize the performance of the transfer learning model. |
| Evaluation metrics | The proposed TL metrics were used. |
| Baseline model | No baseline model was explicitly chosen; however, various performance analysis scenarios were set up, with selected scenarios being considered as baselines in the analysis (see Table 1). |
| Computational requirements | Computational requirements were not explicitly monitored; the focus was more on the sensitivity analysis of other dimensions. |
| Model robustness | Requirements for the model’s robustness against adversarial attacks, noise, or other perturbations were not considered in the use case. These will be considered in further study. |
| Negative transfer avoidance | The aim set for the study was to gain insight into the possible vulnerability of the network to negative transfer and catastrophic forgetting, not to eliminate them. |
| Reproducibility | The source code is available on request for reproducibility. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kambale, W.V.; Salem, M.; Benarbia, T.; Al Machot, F.; Kyamakya, K. Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies. Symmetry 2024, 16, 241. https://doi.org/10.3390/sym16020241
Kambale WV, Salem M, Benarbia T, Al Machot F, Kyamakya K. Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies. Symmetry. 2024; 16(2):241. https://doi.org/10.3390/sym16020241
Chicago/Turabian StyleKambale, Witesyavwirwa Vianney, Mohamed Salem, Taha Benarbia, Fadi Al Machot, and Kyandoghere Kyamakya. 2024. "Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies" Symmetry 16, no. 2: 241. https://doi.org/10.3390/sym16020241
APA StyleKambale, W. V., Salem, M., Benarbia, T., Al Machot, F., & Kyamakya, K. (2024). Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies. Symmetry, 16(2), 241. https://doi.org/10.3390/sym16020241