
A Case Study of Rock Type Prediction Using Random Forests: Erdenet Copper Mine, Mongolia


Abstract
:1. Introduction
2. Methodology
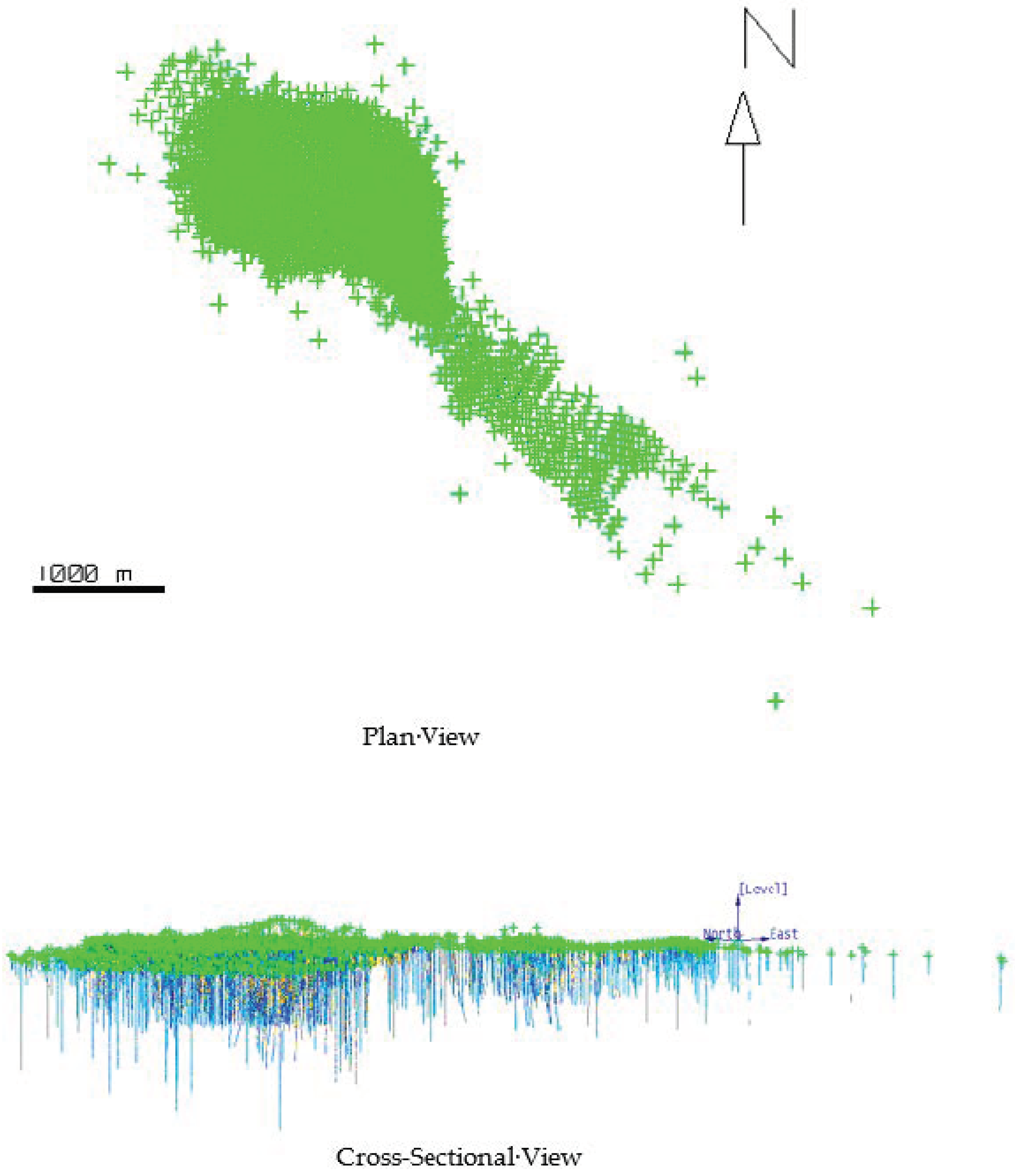
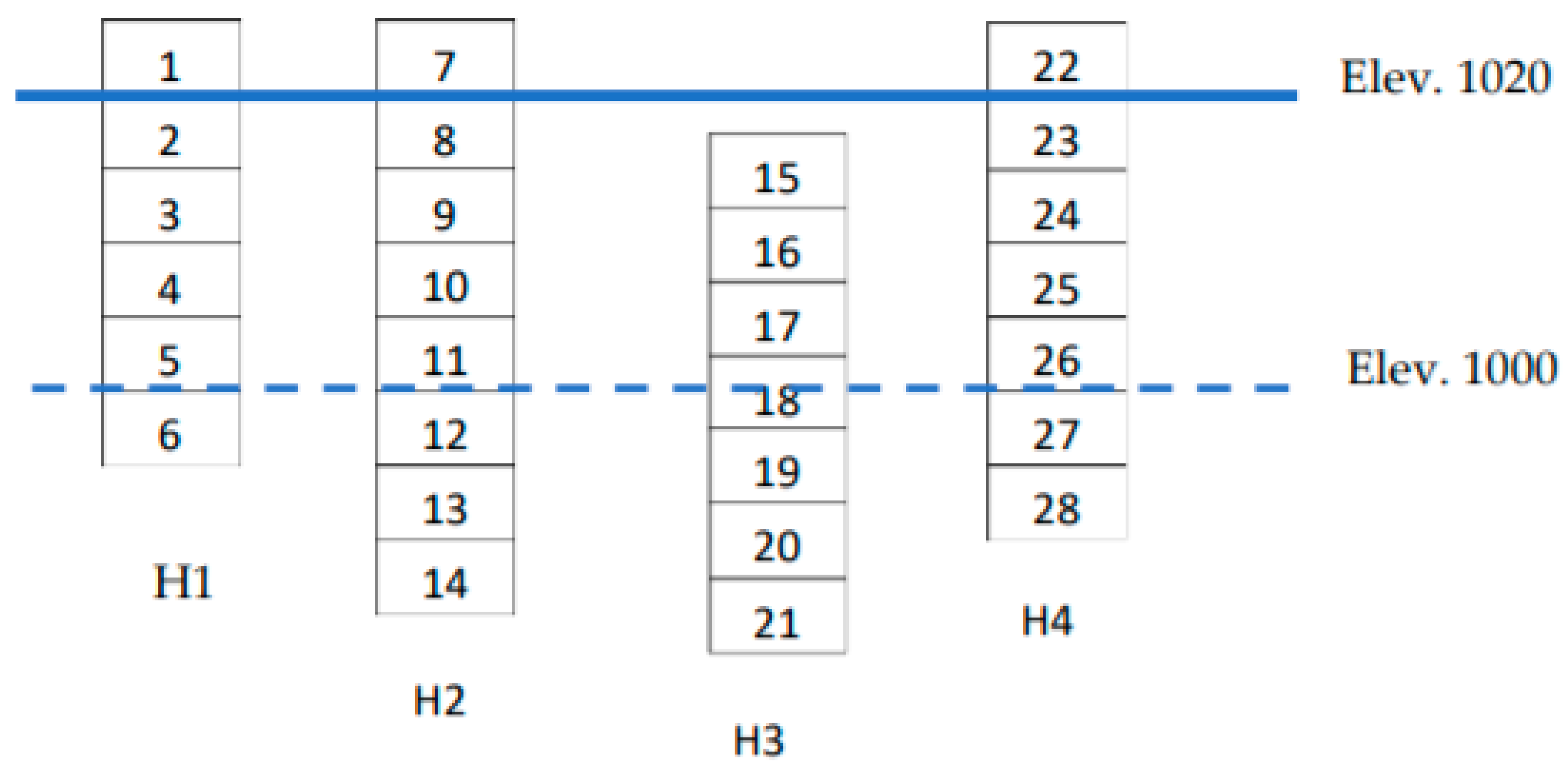
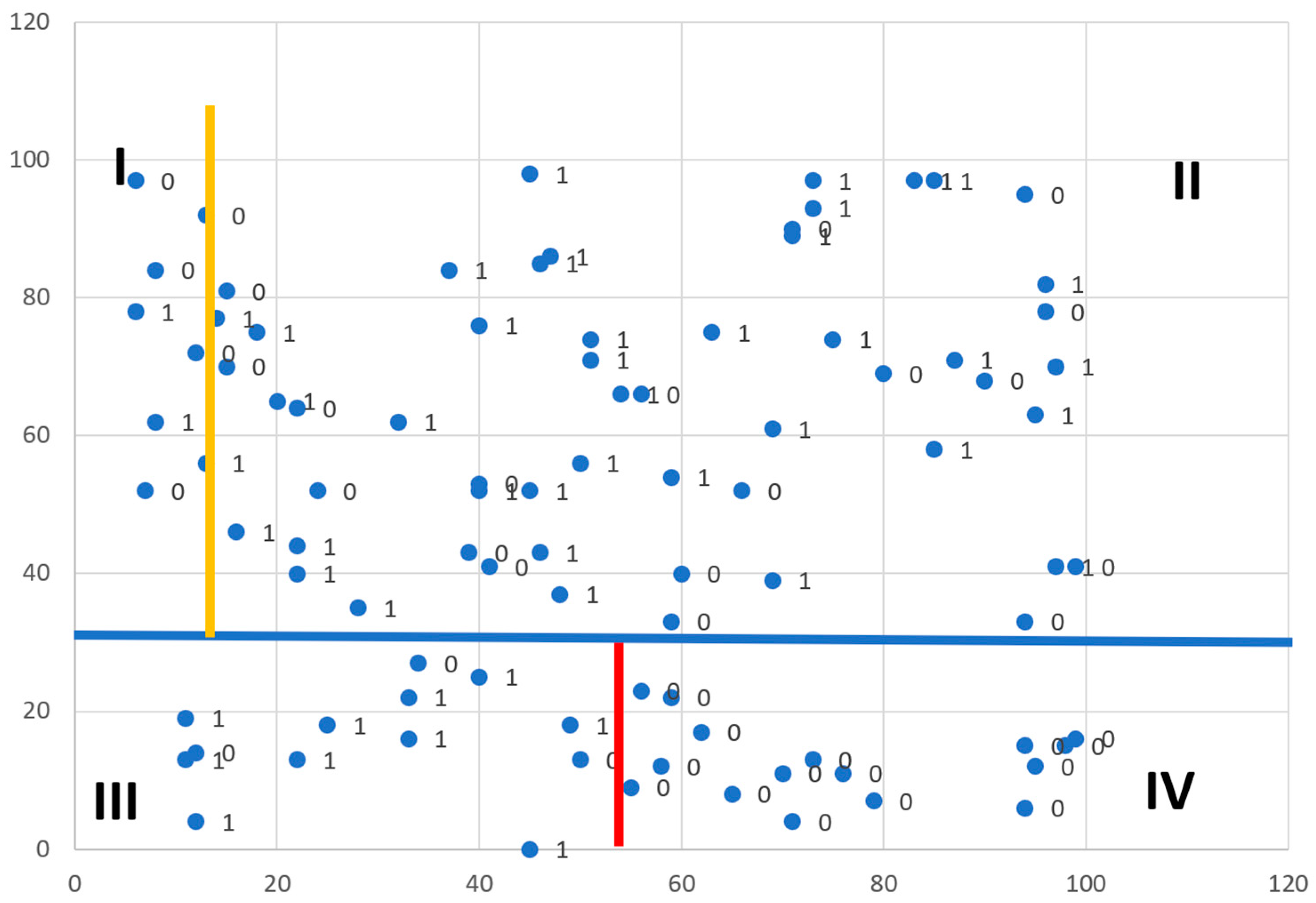
2.1. Data Selection Approaches
2.2. Operational Situations and Their Relationship to Evaluation Methods
2.3. Random Forest: Background
3. RF Modeling and Results
- The proportion of GDIR in the training and testing subsets depend on the evaluation strategy.
- ○
- In SB and HB, despite random shuffling, GDIR is split about evenly between training and testing subsets. This similarity between training and testing subsets is appropriate as both represent the same 3D space.
- ○
- In the SBE strategies, the training subsets are much larger than the testing subsets, since the training interval (e.g. 1600–1300 implies a 300 m training interval) is much larger than the evaluation widths (e.g. 30 m). Since the two subsets represent completely different 3D spaces, the proportion of GDIR and non-GDIR in the two subsets can be quite different.
- SBE models were developed for elevations of 1300 and 1200 m, as the mine is currently operating approximately between those levels.
- RF performs quite well in the SB strategy. 81% of GDIR in the test subset is detected, while 90% of non-GDIR is detected. The overall success rate (OSR) was 87%, i.e., 87% of the rocks are recognized correctly as GDIR or non-GDIR.
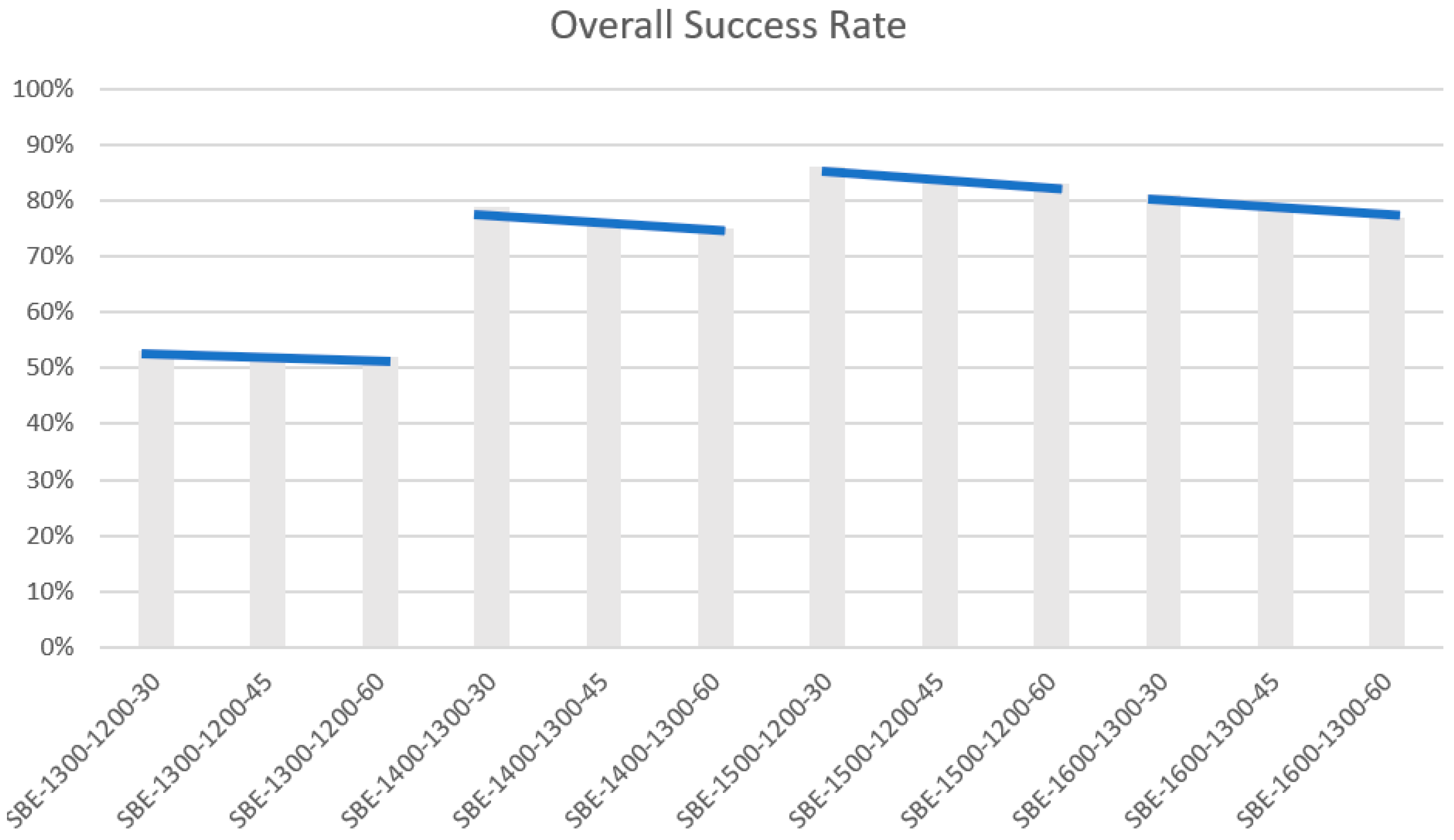
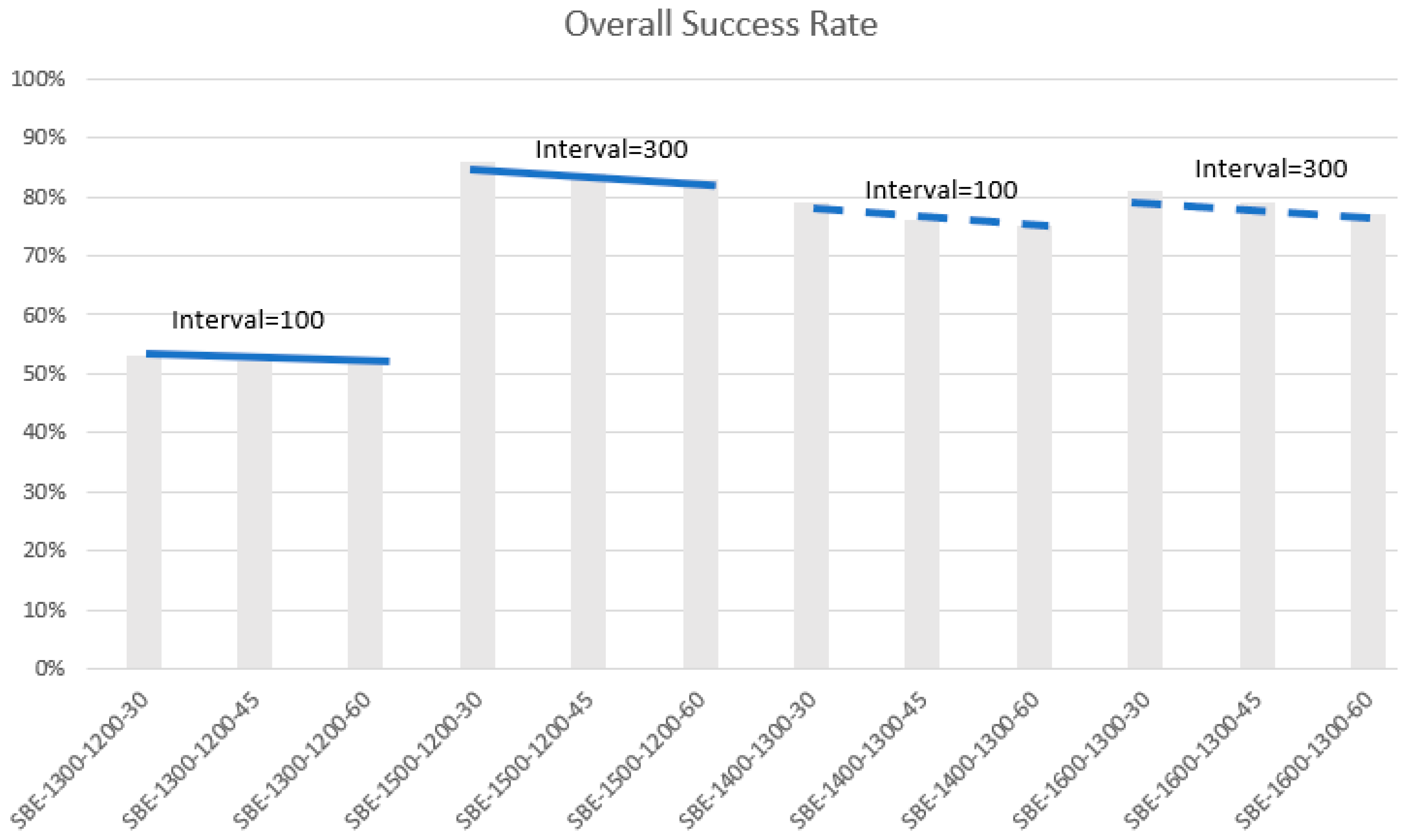
- In the SBE strategy (also see Figure 5):
- ○
- Notice how the performance lines in Figure 5 are inclined downwards to the right. In each scenario, the performance falls as the evaluation width increases from 30 m to 60 m. This is not surprising, as a larger evaluation width tests space farther away from the modeling space.
- ○
- The overall accuracy is higher for higher training intervals (Figure 6). Thus, at 1300 m, 1600–1300 (training interval = 300) outperforms 1400–1300 (training interval = 100). Similarly, at 1200 m, 1500–1200 outperforms 1300–1200. The effect is more pronounced at 1200 m elevation.
- ○
- The seemingly flawless performance for SBE-1300-1200 is misleading (Table 2, column GDIR_success_prop). The ability to classify 95% of the GDIR rock type as GDIR is paired with a 71% false positive rate. In other words, the classification of rock as GDIR is unreliable. This strategy classifies most segments as GDIR. Though that results in capturing all the GDIR, it also ends up classifying non-GDIR as GDIR. This is seen in the low success rate for classifying non-GDIR.
- The false positive rate of 9–15% (for most cases) is decent. This means that when a rock is classified as GDIR, it is most likely to be GDIR.
- HB strategy showed that predicting entire holes is difficult. When a hole is hidden in its entirety, only 42% of the GDIR rock segments in the hole are classified accurately. This is accompanied by a 29% false positive rate, which is not good.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dutta, S.; Ganguli, R.; Samanta, B. Investigation of Two Neural Network Methods in an Automatic Mapping Exercise. Appl. GIS 2005, 1, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Dutta, S.; Bandopadhyay, S.; Ganguli, R.; Misra, D. Machine Learning Algorithms and Their Application to Ore Reserve Estimation of Sparse and Imprecise Data. J. Intell. Learn. Syst. Appl. 2010, 2, 86–96. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Ganguli, R.; Bandopadhyay, S.; Patil, S.L.; Walsh, D.E. Calibration of online ash analyzers using neural networks. Min. Eng. 2004, 56, 99–102. [Google Scholar]
- LaBelle, D. Lithological Classification by Drilling; Carnegie Mellon University: Pittsburgh, PA, USA, 2001. [Google Scholar]
- Wu, X.; Zhou, Y. Reserve estimation using neural network techniques. Comput. Geosci. 1993, 19, 567–575. [Google Scholar] [CrossRef]
- Fathi, M.; Alimoradi, A.; Hemati Ahooi, H.R. Optimizing Extreme Learning Machine Algorithm using Particle Swarm Optimization to Estimate Iron Ore Grade. J. Min. Environ. 2021, 12, 397–411. [Google Scholar] [CrossRef]
- Samanta, B.; Bandopadhyay, S.; Ganguli, R.; Dutta, S. A comparative study of the performance of single neural network vs. Adaboost algorithm based combination of multiple neural networks for mineral resource estimation. J. S. Afr. Inst. Min. Metall. 2005, 105, 237–246. [Google Scholar]
- Samanta, B.; Bandopadhyay, S.; Ganguli, R.; Dutta, S. An Application of Neural Networks to Gold Grade Estimation in Nome Placer Deposit. J. S. Afr. Inst. Min. Met. 2005, 105, 237–246. [Google Scholar]
- Chatterjee, S.; Bandopadhyay, S.; Ganguli, R.; Bhattacherjee, A.; Samanta, B.; Pal, S.K. General regression neural network residual estimation for ore grade prediction of limestone deposit. Min. Technol. 2007, 116, 89–99. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Hezarkhani, A. A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation. Comput. Geosci. 2012, 42, 18–27. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudabadi, H.; Izadi, M.; Menhaj, M.B. A hybrid method for grade estimation using genetic algorithm and neural networks. Comput. Geosci. 2009, 13, 91–101. [Google Scholar] [CrossRef]
- Jafrasteh, B.; Fathianpour, N. A hybrid simultaneous perturbation artificial bee colony and back-propagation algorithm for training a local linear radial basis neural network on ore grade estimation. Neurocomputing 2017, 235, 217–227. [Google Scholar] [CrossRef]
- Jahangiri, M.; Ghavami Riabi, S.R.; Tokhmechi, B. Estimation of geochemical elements using a hybrid neural network-Gustafson-Kessel algorithm. J. Min. Environ. 2018, 9, 499–511. [Google Scholar] [CrossRef]
- Jalloh, A.B.; Kyuro, S.; Jalloh, Y.; Barrie, A.K. Integrating artificial neural networks and geostatistics for optimum 3D geological block modeling in mineral reserve estimation: A case study. Int. J. Min. Sci. Technol. 2016, 26, 581–585. [Google Scholar] [CrossRef]
- Dutta, S.; Misra, D.; Ganguli, R.; Samanta, B.; Bandopadhyay, S. A hybrid ensemble model of kriging and neural network for ore grade estimation. Int. J. Min. Reclam. Environ. 2006, 20, 33–45. [Google Scholar] [CrossRef]
- Ganguli, R. A critical review of on-line quality analyzers. Miner. Resour. Eng. 2001, 10, 435–444. [Google Scholar] [CrossRef]
- Samanta, B.; Ganguli, R.; Bandopadhyay, S. Comparing the predictive performance of neural networks with ordinary kriging in a bauxite deposit. Min. Technol. 2005, 114, 129–139. [Google Scholar] [CrossRef]
- Samanta, B.; Bhattacherjee, A.; Ganguli, R. A genetic algorithms approach for grade control planning in a bauxite deposit. In Proceedings of the 32nd International Symposium on the Application of Computers and Operations Research in the Mineral Industry; APCOM: Tucson, AZ, USA, 2005. [Google Scholar]
- Ganguli, R.; Dagdelen, K.; Grygiel, E. Systems engineering. In Mining Engineering Handbook; Darling, P., Ed.; Society for Mining, Metallurgy and Exploration, Inc.: Littleton, CO, USA, 2011. [Google Scholar]
- Klyuchnikov, N.; Zaytsev, A.; Gruzdev, A.; Ovchinnikov, G.; Antipova, K.; Ismailova, L.; Muravleva, E.; Burnaev, E.; Semenikhin, A.; Cherepanov, A.; et al. Data-driven model for the identification of the rock type at a drilling bit. J. Pet. Sci. Eng. 2019, 178, 506–516. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Hatherly, P.; Monteiro, S.T.; Ramos, F.; Oppolzer, F.; Nettleton, E.; Scheding, S. Automatic rock recognition from drilling performance data. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA; 2012; pp. 3407–3412. [Google Scholar]
- Koch, P.-H.; Lund, C.; Rosenkranz, J. Automated drill core mineralogical characterization method for texture classification and modal mineralogy estimation for geometallurgy. Miner. Eng. 2019, 136, 99–109. [Google Scholar] [CrossRef]
- Sinaice, B.; Owada, N.; Saadat, M.; Toriya, H.; Inagaki, F.; Bagai, Z.; Kawamura, Y. Coupling NCA Dimensionality Reduction with Machine Learning in Multispectral Rock Classification Problems. Minerals 2021, 11, 846. [Google Scholar] [CrossRef]
- Gerel, O.; Munkhtsengel, B. Erdenetiin Ovoo Porphyry Copper-Molybdenum Deposit in Central Mongolia. In Super Porphyry Copper & Gold Deposits: A Global Perspective; Porter, T.M., Ed.; PGC Publishing: Adelaide, Australia, 2004. [Google Scholar]
- Humphries, G.W.; Magness, D.R.; Huettmann, F. Machine Learning for Ecology and Sustainable Natural Resource Management; Springer: New York, NY, USA, 2018; ISBN 9783319969763. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jafrasteh, B.; Fathianpour, N.; Suárez, A. Comparison of machine learning methods for copper ore grade estimation. Comput. Geosci. 2018, 22, 1371–1388. [Google Scholar] [CrossRef]
- McKay, G.; Harris, J.R. Comparison of the Data-Driven Random Forests Model and a Knowledge-Driven Method for Mineral Prospectivity Mapping: A Case Study for Gold Deposits Around the Huritz Group and Nueltin Suite, Nunavut, Canada. Nat. Resour. Res. 2016, 25, 125–143. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997; Volume 45, ISBN 0070428077. [Google Scholar]
- Scikit-Learn. Scikit-Learn: Machine Learning in Python. Scikit-Learn. 2020. Available online: https://scikit-learn.org/stable/ (accessed on 15 July 2021).
- Kaplan, U.; Topal, E. A New Ore Grade Estimation Using Combine Machine Learning Algorithms. Minerals 2020, 10, 847. [Google Scholar] [CrossRef]
- Hengl, T.; Nussbaum, M.; Wright, M.; Heuvelink, G.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scikit-Learn. Nearest Neighbors. Available online: https://scikit-learn.org/stable/modules/neighbors.html#neighbors (accessed on 15 September 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | MTD | NTrain | GDIR_Train | GDIR_Train_Prop | NTest | GDIR_Test | GDIR_Test_Prop | nonGDIR_Test |
|---|---|---|---|---|---|---|---|---|
| SB | 20 | 45,016 | 18,696 | 42% | 45,017 | 18,404 | 41% | 26,613 |
| SBE-1600-1300-30 | 25 | 45,603 | 20,872 | 46% | 5473 | 2198 | 40% | 3275 |
| SBE-1600-1300-45 | 25 | 45,603 | 20,872 | 46% | 7995 | 3216 | 40% | 4779 |
| SBE-1600-1300-60 | 25 | 45,603 | 20,872 | 46% | 10,468 | 4230 | 40% | 6238 |
| SBE-1400-1300-30 | 25 | 28,531 | 12,744 | 45% | 5473 | 2198 | 40% | 3275 |
| SBE-1400-1300-45 | 25 | 28,531 | 12,744 | 45% | 7995 | 3216 | 40% | 4779 |
| SBE-1400-1300-60 | 25 | 28,531 | 12,744 | 45% | 10,468 | 4230 | 40% | 6238 |
| SBE-1500-1200-30 | 25 | 61,589 | 27,411 | 45% | 4093 | 1490 | 36% | 2603 |
| SBE-1500-1200-45 | 25 | 61,589 | 27,411 | 45% | 6008 | 2171 | 36% | 3837 |
| SBE-1500-1200-60 | 25 | 61,589 | 27,411 | 45% | 7786 | 2804 | 36% | 4982 |
| SBE-1300-1200-30 | 25 | 16,632 | 6590 | 40% | 4093 | 1490 | 36% | 2603 |
| SBE-1300-1200-45 | 25 | 16,632 | 6590 | 40% | 6008 | 2171 | 36% | 3837 |
| SBE-1300-1200-60 | 25 | 16,632 | 6590 | 40% | 7786 | 2804 | 36% | 4982 |
| HB | 25 | 45,154 | 18,467 | 41% | 44,879 | 18,632 | 42% | 26,247 |
| Strategy | GDIR_success_num | GDIR_success_prop | GDIR False Positive | nonGDIR_success_num | nonGDIR_success_prop | OSR |
|---|---|---|---|---|---|---|
| SB | 15,760 | 86% | 9% | 24,246 | 91% | 89% |
| SBE-1600-1300-30 | 1584 | 72% | 13% | 2865 | 87% | 81% |
| SBE-1600-1300-45 | 2179 | 68% | 14% | 4115 | 86% | 79% |
| SBE-1600-1300-60 | 2758 | 65% | 15% | 5301 | 85% | 77% |
| SBE-1400-1300-30 | 1414 | 64% | 11% | 2909 | 89% | 79% |
| SBE-1400-1300-45 | 1939 | 60% | 13% | 4175 | 87% | 76% |
| SBE-1400-1300-60 | 2444 | 58% | 14% | 5376 | 86% | 75% |
| SBE-1500-1200-30 | 1209 | 81% | 12% | 2302 | 88% | 86% |
| SBE-1500-1200-45 | 1704 | 78% | 13% | 3353 | 87% | 84% |
| SBE-1500-1200-60 | 2146 | 77% | 14% | 4304 | 86% | 83% |
| SBE-1300-1200-30 | 1415 | 95% | 71% | 763 | 30% | 53% |
| SBE-1300-1200-45 | 2053 | 95% | 71% | 1100 | 29% | 52% |
| SBE-1300-1200-60 | 2656 | 95% | 71% | 1424 | 29% | 52% |
| HB | 7756 | 42% | 29% | 18727 | 71% | 59% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarantsatsral, N.; Ganguli, R.; Pothina, R.; Tumen-Ayush, B. A Case Study of Rock Type Prediction Using Random Forests: Erdenet Copper Mine, Mongolia. Minerals 2021, 11, 1059. https://doi.org/10.3390/min11101059
Sarantsatsral N, Ganguli R, Pothina R, Tumen-Ayush B. A Case Study of Rock Type Prediction Using Random Forests: Erdenet Copper Mine, Mongolia. Minerals. 2021; 11(10):1059. https://doi.org/10.3390/min11101059
Chicago/Turabian StyleSarantsatsral, Narmandakh, Rajive Ganguli, Rambabu Pothina, and Batmunkh Tumen-Ayush. 2021. "A Case Study of Rock Type Prediction Using Random Forests: Erdenet Copper Mine, Mongolia" Minerals 11, no. 10: 1059. https://doi.org/10.3390/min11101059
APA StyleSarantsatsral, N., Ganguli, R., Pothina, R., & Tumen-Ayush, B. (2021). A Case Study of Rock Type Prediction Using Random Forests: Erdenet Copper Mine, Mongolia. Minerals, 11(10), 1059. https://doi.org/10.3390/min11101059